Simplification of Context Free Grammars | Theory of Computation - Computer Science Engineering (CSE) PDF Download

Part II. Simplification of Context Free Grammars
3 Simplification of CFGs
We can simplify a CFG and produce an equivalent reduced CFG. This is done by,
a. Eliminating useless symbols,
b. Eliminating ε productions,
c. Eliminating unit productions.
3.1 Eliminating Useless Symbols
Useless symbols are those non-terminals or terminals that do not appear in any derivation of a string.
A symbol, Y is said to be useful if: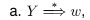
that is Y should lead to a set of terminals. Here Y is said to be ’generating’.
b. If there is a derivation,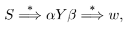
then Y is said to be ’reachable’.
Thus a symbol is useful, if it is ’generating’ and ’useful’.
Thus a symbol is useless, if it is not ’generating’ and not ’reachable’.
Example 1:
Consider the CFG,
S → AB|a
A → b
where S is the start symbol.
Eliminate uselss symbols from this grammar.
By observing the above CFG, it is clear that B is a non generating symbol. Since A derives ’b’, S derives ’a’ but B does not derive any string ’w’.
So we can eliminate S → AB from the CFG.
Now CFG becomes,
S → a
A → b
Here A is a non reachable symbol, since it cannot be reached from the start symbol S.
So we can eliminate the production, A → b from the CFG.
Now the reduced grammar is,
S → a
This grammar does not contain any useless symbols.
Example 2:
Consider the CFG,
S → aB|bX
A → BAd|bSX|a
B → aSB|bBX
X → SBD|aBx|ad
where S is the start symbol.
Eliminate uselss symbols from this grammar.
First we choose those non terminals which derive to the strings of terminals.
The non terminals,
A derives to the terminal ’a’;
X derives to the terminals ’ad’.
So A and X are useful symbols.
Since,
S → bX, and X is a useful symbol, S is also a useful symbol.
From the production, B → aSB|bBX,
B does not derive any terminal string, B is a non-generating symbol. So eliminate those productions containing B.
Grammar becomes,
S → bX
A → bSX|a
X → ad
From the above CFG, A is a non- reachable symbol, since A cannot be reached from the start symbol, S.
So eliminate the production, A → bSX|a.
Now the CFG is,
S → bX
X → ad
This grammar does not contain any useless symbols.
Example 3:
Consider the CFG,
A → xyz|Xyzz
X → Xz|xY z
Y → yY y|Xz
Z → Zy|z
where A is the start symbol.
Eliminate uselss symbols from this grammar.
From the productions,
A → xyz, Z → z,
A and Z derive to the strings of terminals. So A and Z are useful symbols.
X and Y do not lead to a string of terminals; that means X and Y are useless symbols.
Eliminating the productions of X and Y, we get,
A → xyz
Z → Zy|z
From the above, Z is not reachable, since it cannot be reached from the start symbol, A. So eliminate the production
corresponding to Z.
The CFG is,
A → xyz.
This grammar does not contain any useless symbols.
Example 4:
Consider the CFG,
S → aC|SB
A → bSCa
B → aSB|bBC
C → aBC|ad
where S is the start symbol.
Eliminate uselss symbols from this grammar.
Since, C → ad,
C is a generating symbol.
Since, S → aC,
S is also a useful symbol.
Since, A → bSCa,
A is also a useful symbol.
The RHS of B → aSB|bBC contains B. B is not terminating. B is not generating.
So B is a useless symbol. Eliminate those productions containing B.
We get,
S → aC
A → bSCa
C → ad
From the above, A is not reachable, since it cannot be reached from the start symbol, S.
So eliminate the production corresponding to A.
We get the CFG as,
S → aC
C → ad
where S is the start symbol.
This grammar does not contain any useless symbols.
3.2 Removal of Unit Productions
A unit production is defined as,
A → B
where A is a non-terminal, and
B is a non-terminal.
Thus both LHS and RHS contain single non-terminals.
Following examples show how unit productions are removed from a CFG.
Example 1:
Consider the CFG,
S → AB
3 Simplification of CFGs 20
A → a
B → C|b
C → D
D → E
E → a
where S is the start symbol.
Eliminate unit productions from this grammar.
From the above CFG, it is seen that,
B → C
C → D
D → E
are unit productions.
To remove the production, B → C, check whether there exists a production whose LHS is C and RHS is a terminal.
No such production exists.
To remove the production, C → D, check whether there exists a production whose LHS is D and RHS is a terminal.
No such production exists.
To remove the production, D → E, check whether there exists a production whose LHS is E and RHS is a terminal.
There is a production, E → a. So remove, D → E, and add the production, D → a, CFG becomes,
S → AB
A → a
B → C|b
C → D
D → a
E → a
Now remove the production, C → D, and add the production, C → a, we get,
S → AB
A → a
B → C|b
C → a
D → a
E → a
Now remove the production, B → C, and add the production, B → a, we get,
S → AB
A → a
B → a|b
C → a
D → a
E → a
where S is the start symbol.
Now the grammar contains no unit productions.
From the above CFG, it is seen that the productions, C → a, D → a, E → a are useless becuse the symbols C, D and E cannot be reached from the start symbol, S.
By eliminating these productions, we get the CFG as,
S → AB
A → a
B → a|b
Above is a completely reduced grammar.
Example 2:
Consider the CFG,
S → a|b|Sa|Sb|S0|S1
F → S|(E)
T → F|T ∗ F
E → T|E + T
where E is the start symbol.
Eliminate unit productions from this grammar.
From the above CFG,
F → S
T → F
E → T
are unit productions.
The unit production F → S can be removed by rewriting it as, F → a|b|Sa|Sb|S0|S1
Now the CFG is,
S → a|b|Sa|Sb|S0|S1
F → a|b|Sa|Sb|S0|S1|(E)
T → F|T ∗ F
E → T|E + T
The unit production T → F can be removed by rewriting it as, T → a|b|Sa|Sb|S0|S1|(E)
Now the CFG is,
S → a|b|Sa|Sb|S0|S1
F → a|b|Sa|Sb|S0|S1|(E)
T → a|b|Sa|Sb|S0|S1|(E)|T ∗ F
E → T|E + T
The unit production E → T can be removed by rewriting it as, E → a|b|Sa|Sb|S0|S1|(E)|T ∗ F
Now the CFG is,
S → a|b|Sa|Sb|S0|S1
F → a|b|Sa|Sb|S0|S1|(E)
T → a|b|Sa|Sb|S0|S1|(E)|T ∗ F
E → a|b|Sa|Sb|S0|S1|(E)|T ∗ F|E + T
This is the CFG that does not contain any unit productions.
Example 1:
Consider the CFG,
S → A|bb
A → B|b
B → S|a
where S is the start symbol.
Eliminate unit productions from this grammar.
Here unit productions are,
S → A
A → B
B → S
Here,
S → A generates S → b
S → A → B generates S → a
A → B generates A → a
A → B → S generates A → bb
B → S generates B → bb
B → S → A generates B → b
The new CFG is,
S → b|a|bb
A → a|bb|b
B → bb|b|a
which contains no unit productions.
3.3 Removal of ε- Productions
Productions of the form, A → ε are called ε -productions.
We can eliminate ε -productions from a grammar in the following way:
If A → ε is a production to be eliminated, then we look for all productions, whose RHS contains A, and replace every
occurrence of A in each of these productions to obtain non ε -productions. The resultant non ε -productions are added to
the grammar.
Example 1:
Consider the CFG,
S → aA
A → b|ε
where S is the start symbol.
Eliminate epsilon productions from this grammar.
Here, A → ε is an epsilon production.
By following the above procedure, put ε in place of A, at the RHS of productions, we get,
The production, S → aA becomes, S → a.
Then the CFG is,
S → aA
S → a
A → b
OR
S → aA|a
A → b
Thus this CFG does not contain any epsilon productions.
Example 2:
Consider the CFG,
S → ABAC
A → aA|ε
B → bB|ε
C → c
where S is the start symbol.
Eliminate epsilon productions from this grammar.
This CFG contains the epsilon productions, A → ε, B → ε.
To eliminate A → ε, replace A with epsion in the RHS of the productions, S → ABAC, A → aA,
For the production, S → ABAC, replace A with epsilon one by one as,
we get,
S → BAC
S → ABC
S → BC
For the production, A → aA, we get,
A → a,
Now the grammar becomes,
S → ABAC|ABC|BAC|BC
A → aA|a
B → bB|ε
C → c
To eliminate B → ε, replace A with epsion in the RHS of the productions, S → ABAC, B → bB,
For the production, S → ABAC|ABC|BAC|BC , replace B with epsilon as,
we get,
S → AAC|AC|C
For the production, B → bB, we get,
B → b,
Now the grammar becomes,
S → ABAC|ABC|BAC|BC|AAC|AC|C
A → aA|a
B → bB|b
C → c
which does not contain any epsilon production.
Example 3:
Consider the CFG,
S → aSa
3 Simplification of CFGs 25
S → bSb|ε
where S is the start symbol.
Eliminate epsilon productions from this grammar.
Here, S → ε is an epsilon production. Replace the occurrence of S by epsilon, we get,
S → aa,
S → bb
Now the CFG becomes,
S → aSa|bSb|aa|bb
This does not contain epsilon productions.
Example 4:
Consider the CFG,
S → a|Xb|aY a
X → Y |ε
Y → b|X
where S is the start symbol.
Eliminate epsilon productions from this grammar.
Here, X → ε is an epsilon production. Replace the occurrence of X by epsilon, we get,
S → a|b
X → Y
Y → ε
Now the grammar becomes,
S → a|Xb|aY a|a|b
X → Y
Y → b|X|ε
In the above CFG, Y → ε is an epsilon production. Replace the ocurrence of Y by epsilon, we get,
S → aa
X → ε
Now the grammar becomes,
S → a|Xb|aY a|a|b|aa
X → Y
Y → b|X
This grammar does not contain epsilon productions.
Exercises:
Simplify the following context free grammars:
1.
S → AB
A → a
B → b
B → C
E → c|ε
where S is the start symbol.
2.
S → aAa
A → Sb|bCC|DaA
C → abb|DD
E → aC
D → aDA
where S is the start symbol.
3.
S → bS|bA|ε
A → ε
where S is the start symbol.
4.
S → bS|AB
A → ε
B → ε
D → a
where S is the start symbol.
5.
S → A
A → B
B → C
C → a
where S is the start symbol.
3 Simplification of CFGs 27
6.
S → AB
A → a
B → C|b
C → D
D → E
E → a
where S is the start symbol.
7.
S → ABCD
A → a
B → C|b
C → D
D → c
where S is the start symbol.
8.
S → aS|AC|AB
A → ε
C → ε
B → bB|bb
D → c
where S is the start symbol.
9.
S → ABC|A0A
A → 0A|B0C|000|B
B → 1B1|0|D
C → CA|AC
D → ε
where S is the start symbol.
10.
S → AAA|B
A → 0A|B
B → ε
where S is the start symbol.
|
18 videos|93 docs|44 tests
|
FAQs on Simplification of Context Free Grammars - Theory of Computation - Computer Science Engineering (CSE)
| 1. What are Context Free Grammars? |  |
| 2. What is the simplification of Context Free Grammars? | |
| 3. Why is simplification of Context Free Grammars important? | |
| 4. What are some techniques for simplifying Context Free Grammars? | |
| 5. How is the complexity of Context Free Grammars related to the exam? | |




video lectures
,Semester Notes
,practice quizzes
,ppt
,Summary
,Simplification of Context Free Grammars | Theory of Computation - Computer Science Engineering (CSE)
,Extra Questions
,Simplification of Context Free Grammars | Theory of Computation - Computer Science Engineering (CSE)
,Objective type Questions
,Viva Questions
,Sample Paper
,Free
,Simplification of Context Free Grammars | Theory of Computation - Computer Science Engineering (CSE)
,past year papers
,shortcuts and tricks
,Important questions
,Exam
,MCQs
,study material
,Previous Year Questions with Solutions
,mock tests for examination
;






Simplification of Context Free Grammars Free PDF Download
Importance of Simplification of Context Free Grammars
Simplification of Context Free Grammars Notes
Simplification of Context Free Grammars Computer Science Engineering (CSE) Questions
Study Simplification of Context Free Grammars on the App
|
© EduRev
|
Education Revolution
|



|





