Test: Instruction Pipelining - Computer Science Engineering (CSE) MCQ
10 Questions MCQ Test - Test: Instruction Pipelining

Which of the following hazards occurs if the read takes place before the write operation is complete?

Consider an instruction pipeline with four stages (S1, S2, S3 and S4) each with combinational circuit only. The pipeline registers are required between each stage and at the end of the last stage. Delays for the stages and for the pipeline registers are as given in the figure.
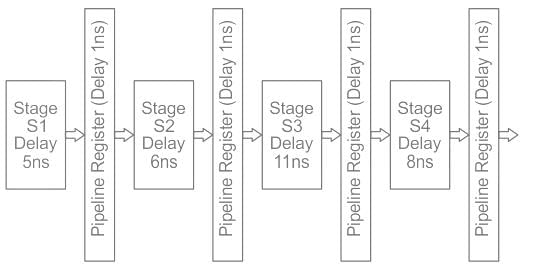
What is the approximate speed up of the pipeline in steady state under ideal conditions when compared to the corresponding non-pipeline implementation?
A non-pipeline system takes 50ns to process a task. The same task can be processed in six-segment pipeline with a clockcycle of 10ns. Determine approximately the speedup ratio of the pipeline for 500 tasks.
The speed gained by an 'n' segment pipeline executing 'm' tasks is:
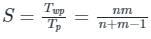
A five-stage pipeline has stage delays of 150, 120, 150, 160 and 140 nanoseconds. The registers that are used between the pipeline stages have a delay of 5 nanoseconds each.
The total time to execute 100 independent instructions on this pipeline, assuming there are no pipeline stalls, is ______ nanoseconds.
In an instruction execution pipeline, the earliest that the instruction TLB and data TLB can be accessed are
A 5-stage pipelined processor has Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Perform Operation (PO) and Write Operand (WO) stages. The IF, ID, OF and WO stages take 1 clock cycle each for any instruction. The PO stage takes 1 clock cycle for ADD and SUB instructions, 3 clock cycles for MUL instruction, and 6 clock cycles for DIV instruction respectively. Operand forwarding is used in the pipeline. What is the number of clock cycles needed to execute the following sequence of instructions?
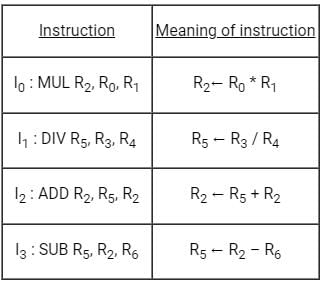
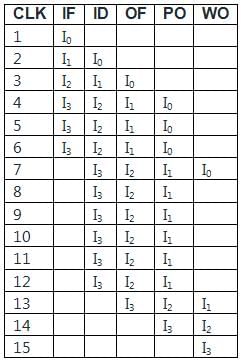
Which one of the following is false about Pipelining?
Important Questions for Instruction Pipelining
Instruction Pipelining MCQs with Answers
Online Tests for Instruction Pipelining
|
© EduRev
|
Education Revolution
|



|








