Test: Parsing- 2 - Computer Science Engineering (CSE) MCQ
20 Questions MCQ Test GATE Computer Science Engineering(CSE) 2026 Mock Test Series - Test: Parsing- 2

Consider the following expression grammar. The semantic rules for expression calculation are stated next to each grammar production.
E → number E.val = number. val
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val
Q. The above grammar and the semantic rules are fed to a yacc tool (which is an LALR (1) parser generator) for parsing and evaluating arithmetic expressions. Which one of the following is true about the action of yacc for the given grammar?
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val
Consider the following expression grammar. The semantic rules for expression calculation are stated next to each grammar production.
E → number E.val = number. val
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val
Q. Assume the conflicts in Part (a) of this question are resolved and an LALR(1) parser is generated for parsing arithmetic expressions as per the given grammar. Consider an expression 3 × 2 + 1. What precedence and associativity properties does the generated parser realize?
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val

Which of the following grammar rules violate the requirements of an operator grammar ? P, Q, R are nonterminals, and r, s, t are terminals.
1. P → Q R
2. P → Q s R
3. P → ε
4. P → Q t R r
2. P → Q s R
3. P → ε
4. P → Q t R r
Consider the grammar with the following translation rules and E as the start symbol.
E → E1 # T {E.value = E1.value * T.value}
| T{E.value = T.value}
T → T1 & F {T.value = T1.value + F.value}
| F{T.value = F.value}
F → num {F.value = num.value}
Q. Compute E.value for the root of the parse tree for the expression: 2 # 3 & 5 # 6 & 4.
Which of the following suffices to convert an arbitrary CFG to an LL(1) grammar?
Assume that the SLR parser for a grammar G has n1 states and the LALR parser for G has n2 states. The relationship between n1 and n2 is:
In a bottom-up evaluation of a syntax directed definition, inherited attributes can
Consider the grammar shown below S → i E t S S' | a S' → e S | ε E → b In the predictive parse table. M, of this grammar, the entries M[S', e] and M[S', $] respectively are
Consider the grammar shown below.
S → C C
C → c C | d
The grammar is
Consider the translation scheme shown below
S → T R
R → + T {print ('+');} R | ε
T → num {print (num.val);}
Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string '9 + 5 + 2', this translation scheme will print
Consider the syntax directed definition shown below.
S → id : = E {gen (id.place = E.place;);}
E → E1 + E2 {t = newtemp ( ); gen (t = El.place + E2.place;); E.place = t}
E → id {E.place = id.place;}
Here, gen is a function that generates the output code, and newtemp is a function that returns the name of a new temporary variable on every call. Assume that ti's are the temporary variable names generated by newtemp. For the statement 'X: = Y + Z', the 3-address code sequence generated by this definition is
Which of the following derivations does a top-down parser use while parsing an input string? The input is assumed to be scanned in left to right order.
Given the following expression grammar:
E -> E * F | F + E | F
F -> F - F | id
which of the following is true? (GATE CS 2000)
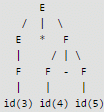
Which one of the following is True at any valid state in shift-reduce parsing?
In the context of abstract-syntax-tree (AST) and control-flow-graph (CFG), which one of the following is True?

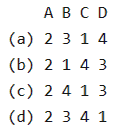
Among simple LR (SLR), canonical LR, and look-ahead LR (LALR), which of the following pairs identify the method that is very easy to implement and the method that is the most powerful, in that order?
Consider the following grammar G.
S → F ⎪ H
F → p ⎪ c
H → d ⎪ c
Q. Where S, F and H are non-terminal symbols, p, d and c are terminal symbols. Which of the following statement(s) is/are correct?
S1: LL(1) can parse all strings that are generated using grammar G.
S2: LR(1) can parse all strings that are generated using grammar G.
Consider the following Syntax Directed Translation Scheme (SDTS), with non-terminals {S, A} and terminals {a, b}}.

Using the above SDTS, the output printed by a bottom-up parser, for the input aab is
|
57 docs|215 tests
|
|
57 docs|215 tests
|




Important Questions for Parsing- 2
Parsing- 2 MCQs with Answers
Online Tests for Parsing- 2 GATE Computer Science Engineering(CSE) 2026 Mock Test Series
|
© EduRev
|
Education Revolution
|



|








