Searching, Sorting & Hashing - 2 - Free MCQ Practice Test with solutions,
MCQ Practice Test & Solutions: Test: Searching, Sorting & Hashing - 2 (20 Questions)
You can prepare effectively for Computer Science Engineering (CSE) Question Bank for GATE Computer Science Engineering with this dedicated MCQ Practice Test (available with solutions) on the important topic of "Test: Searching, Sorting & Hashing - 2". These 20 questions have been designed by the experts with the latest curriculum of Computer Science Engineering (CSE) 2026, to help you master the concept.
Test Highlights:
- - Format: Multiple Choice Questions (MCQ)
- - Duration: 55 minutes
- - Number of Questions: 20
Sign up on EduRev for free to attempt this test and track your preparation progress.

The average number of key comparisons required for a successful search for sequential search on items is
Detailed Solution: Question 1
The recurrence relation that arises in relation with the complexity of binary search is:
Detailed Solution: Question 2

The average case occurs in the Linear Search Algorithm when:
Detailed Solution: Question 3
Suppose there are 11 items in sorted order in an array. How many searches are required on the average, if binary search is employed and all searches are successful in finding the item?
Detailed Solution: Question 4
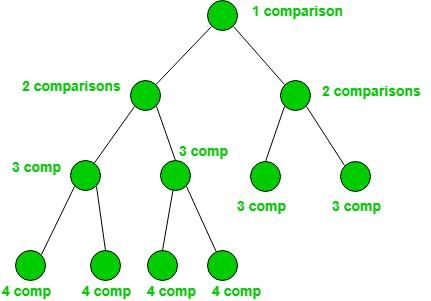
Which of the following statements is true for Branch - and - Bound search?
Detailed Solution: Question 5
Number of comparisons required for an unsuccessful search of an element in a sequential search, organized, fixed length, symbol table of length L is
Detailed Solution: Question 6
The time taken by binary search algorithm to search a key in a sorted array of n elements is
Detailed Solution: Question 7
Suppose we are sorting an array of eight integers using quicksort, and we have just finished the first partitioning with the array looking like this:
2 5 1 7 9 12 11 10
Which statement is correct?
2 5 1 7 9 12 11 10
Detailed Solution: Question 8
What is the best time complexity of bubble sort?
Detailed Solution: Question 9
Suppose we are sorting an array of eight integers using heapsort, and we have just finished some heapify (either maxheapify or minheapify) operations. The array now looks like this: 16 14 15 10 12 27 28 How many heapify operations have been performed on root of heap?
Detailed Solution: Question 10
In a modified merge sort, the input array is splitted at a position one-third of the length(N) of the array. Which of the following is the tightest upper bound on time complexity of this modified Merge Sort.
Detailed Solution: Question 11
You have to sort 1 GB of data with only 100 MB of available main memory. Which sorting technique will be most appropriate?
Detailed Solution: Question 12
Which sorting algorithm will take least time when all elements of input array are identical? Consider typical implementations of sorting algorithms.
Detailed Solution: Question 13
An advantage of chained hash table (external hashing) over the open addressing scheme is
Detailed Solution: Question 14
A hash function h defined h(key)=key mod 7, with linear probing, is used to insert the keys 44, 45, 79, 55, 91, 18, 63 into a table indexed from 0 to 6. What will be the location of key 18?
Detailed Solution: Question 15
The characters of the string K R P C S N Y T J M are inserted into a hash table of size 10 using hash function
h(x) = ((ord(x) - ord(A) + 1)) mod 10
If linear probing is used to resolve collisions, then the following insertion causes collision
h(x) = ((ord(x) - ord(A) + 1)) mod 10
If linear probing is used to resolve collisions, then the following insertion causes collision
Detailed Solution: Question 16
Insert the characters of the string K R P C S N Y T J M into a hash table of size 10. Use the hash function
h(x) = ( ord(x) – ord("a") + 1 ) mod10
If linear probing is used to resolve collisions, then the following insertion causes collision
h(x) = ( ord(x) – ord("a") + 1 ) mod10
If linear probing is used to resolve collisions, then the following insertion causes collision
Detailed Solution: Question 17
Consider a 13 element hash table for which f(key)=key mod 13 is used with integer keys. Assuming linear probing is used for collision resolution, at which location would the key 103 be inserted, if the keys 661, 182, 24 and 103 are inserted in that order?
Detailed Solution: Question 18

What will be the cipher text produced by the following cipher function for the plain text ISRO with key k =7. [Consider 'A' = 0, 'B' = 1, .......'Z' = 25]. Ck(M) = (kM + 13) mod 26
Detailed Solution: Question 19
A hash function h defined h(key)=key mod 7, with linear probing, is used to insert the keys 44, 45, 79, 55, 91, 18, 63 into a table indexed from 0 to 6. What will be the location of key 18 ?
Detailed Solution: Question 20
63 videos|8 docs|165 tests |
63 videos|8 docs|165 tests |