Test: Statistical Description Of Data - 2 - CA Foundation MCQ
30 Questions MCQ Test Quantitative Aptitude for CA Foundation - Test: Statistical Description Of Data - 2

(Direction 1 - 20) Answer the following questions. Each question carries 1 mark.
Q. Pie-diagram is used for

The frequency distribution of a continuous variable is known as
The distribution of shares is an example of the frequency distribution of
The distribution of profits of a blue-chip company relates to
Analysis based on study of price fluctuations, production of commodities and deposits in banks is classified as
Mutually inclusive classification is usually meant for
Mutually exclusive classification is usually meant for
Branch of statistics which deals with development of particular statistical methods is classified as
For a particular class boundary, the less than cumulative frequency and more than cumulative frequency add up to
Frequency density corresponding to a class interval is the ratio of
Relative frequency for a particular class
Mode of a distribution can be obtained from
Median of a distribution can be obtained from
A comparison among the class frequencies is possible only in
Most of the commonly used frequency curves are
The distribution of profits of a company follows
(Direction 21 - 27) Answer the following questions. Each question carries 2 marks.
Q. Out of 1000 persons, 25 per cent were industrial workers and the rest were agricultural workers. 300 persons enjoyed world cup matches on TV. 30 per cent of the people who had not watched world cup matches were industrial workers. What is the number of agricultural workers who had enjoyed world cup matches on TV?
A sample study of the people of an area revealed that total number of women were 40% and the percentage of coffee drinkers were 45 as a whole and the percentage of male coffee drinkers was 20. What was the percentage of female non-coffee drinkers?
Cost of sugar in a month under the heads Raw Materials, labour, direct production and others were 12, 20, 35 and 23 units respectively. What is the difference between the central angles for the largest and smallest components of the cost of sugar?
The number of accidents for seven days in a locality are given below :
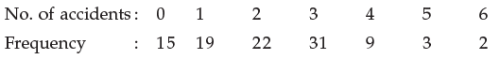
Q. What is the number of cases when 3 or less accidents occurred?
The following data relate to the incomes of 86 persons :

Q. What is the percentage of persons earning more than Rs. 1500?
The following data relate to the marks of a group of students:
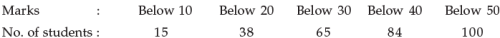
Q. How many students got marks more than 30?
(Direction 28 - 32) Answer the following questions. Each question carries 5 marks.
In a study about the male and female students of commerce and science departments of a college in 5 years, the following datas were obtained :

Q. After combining 1995 and 2000 if x denotes the ratio of female commerce student to female Science student and y denotes the ratio of male commerce student to male Science student, then
In a study relating to the labourers of a jute mill in West Bengal, the following information was collected.
‘Twenty per cent of the total employees were females and forty per cent of them were married. Thirty female workers were not members of Trade Union. Compared to this, out of 600 male workers 500 were members of Trade Union and fifty per cent of the male workers were married. The unmarried non-member male employees were 60 which formed ten per cent of the total male employees. The unmarried non-members of the employees were 80’. On the basis of this information, the ratio of married male non-members to the married female non-members is
The weight of 50 students in pounds are given below :

Q. If the data are arranged in the form of a frequency distribution with class intervals as 81-100, 101-120, 121-140, 141-160 and 161-180, then the frequencies for these 5 class intervals are
The following data relate to the marks of 48 students in statistics :

Q. What are the frequency densities for the class intervals 30-39, 40-49 and 50-59
|
101 videos|276 docs|89 tests
|
Important Questions for Statistical Description Of Data - 2
Statistical Description Of Data - 2 MCQs with Answers
Online Tests for Statistical Description Of Data - 2 Quantitative Aptitude for CA Foundation
|
© EduRev
|
Education Revolution
|



|








