Computer Science And Information Technology - CS 2017 GATE Paper - 1 (Practice Test) - GATE MCQ
30 Questions MCQ Test - Computer Science And Information Technology - CS 2017 GATE Paper - 1 (Practice Test)

Find the smallest number y such that y x 162 (y multiplied by 162) is a perfect cube.
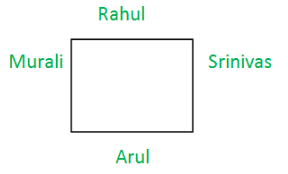
Rahul, Murali, Srinivas and Arul are seated around a square table. Rahul is sitting to the left of Murali. Srinivas is sitting to the right of Arul. Which of the following pairs are seated opposite each other ?

Research in the workplace reveals thatpeople work for many reasons _________.
The probability that a k-digit number does NOT contain the digits 0, 5 or 9 is
After Rajendra Chola returned from his voyage to Indonesia, he ______ to visit the temple in Tanjavur.
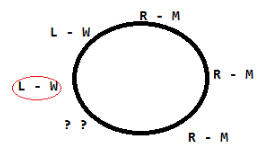
Six people are seated around a circular table. There are at least two men and two women. There are at least three right-handed persons. Every woman has a left-handed person to her immediate right. None of the women are right-handed. The number of women at the table is
"The hold of the nationalist imagination on our colonial past is such that anything inadequately or improperly natinalist is just not history"
Q. Which of the following statements best reflects the author's opinion?
The expression [(x + y) - |x - y|] / 2 is equal to
A contour line joins locations having the same height above the mean sea level. The following is a contour plot of a geographical region. Contour lines are shown at 25 m intervals in this plot.
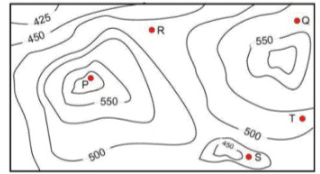
Q. If in a flood, the water level rises to 525 m, which of the villages P, Q, R, S, T get submerged?
Arun, Gulab, Neel and Shweta must choose one shirt each from a pile of four shirts coloured red, pink, blue and white respectively. Arun dislikes the colour red and Shweta dislikes the colour white. Gulab and Neel like all the colours. In how many different ways can they choose the shirts so that no one has a shirt with a colour he or she dislikes?
Let X be a Gaussian random variable with mean 0 and variance σ2. Let Y = max(X,0) where max(a,b) is the maximum of a and b. The median of Y is _____.
Note: This questions appeared as Numerical Answer Type.
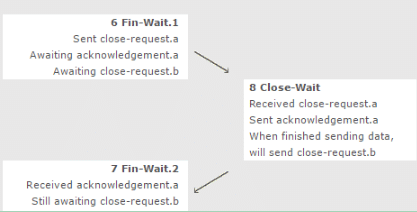
Consider a TCP client and a TCP server running on two different machines. After completing data transfer, the TCP client calls close to terminate the connection and a FIN segment is sent to the TCP server. Server-side TCP responds by sending an ACK which is received by the client-side TCP. As per the TCP connection state diagram(RFC 793), in which state does the client side TCP connection wait for the FIN from the server-side TCP?
A sender S sends a message m to receiver R, which is digitally signed by S with its private key. In this scenario, one or more of the following security violations can take place.
(I) S can launch a birthday attack to replace m with a fraudulent message.
(II) A third party attacker can launch a birthday attack to replace m with a fraudulent message.
(III) R can launch a birthday attack to replace m with a fraudulent message.
Consider the following intermediate program in three address code
p = a - b
q = p * c
p = u * v
q = p + q
Q. Which one of the following corresponds to a static single assignment from the above code?
The following functional dependencies hold true for the relational schema R{V, W, X, Y, Z}:
V -> W
VW -> X
Y -> VX
Y -> Z
Q. Which of the following is irreducible equivalent for this set of functional dependencies?
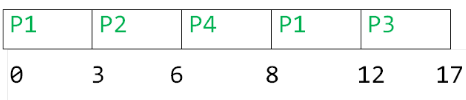
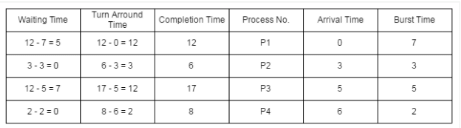
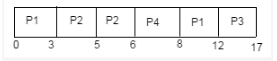
Consider the following CPU processes with arrival times (in milliseconds) and length of CPU bursts (in milliseconds) as given below:
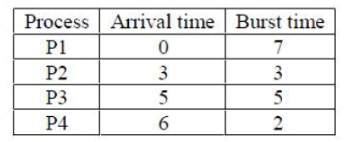
Q. If the pre-emptive shortest remaining time first scheduling algorithm is used to schedule the processes, then the average waiting time across all processes is _______ milliseconds.
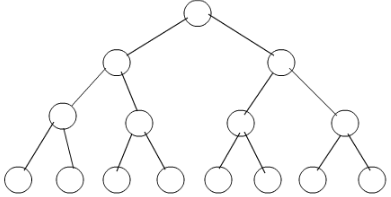
Let T be a binary search tree with 15 nodes. The minimum and maximum possible heights of T are:
Note: The height of a tree with a single node is 0.
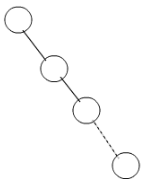
The statement (¬ p) => (¬ q) is logically equivalent to which of the statements below?
I. p => q
II. q => p
III. (¬ q) ∨ p
IV. (¬ p) ∨ q
Consider a database that has the relation schema EMP (EmpId, EmpName, and DeptName). An instance of the schema EMP and a SQL query on it are given below.
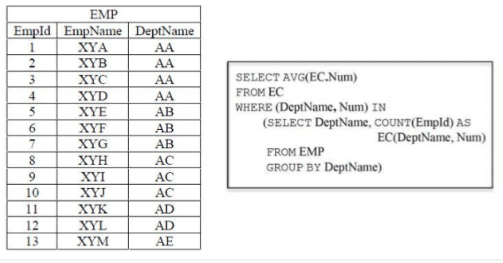
Q. The output of executing the SQL query is _______.
Note: This questions appeared as Numerical Answer Type.
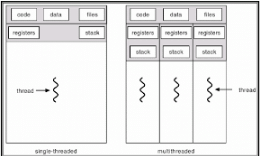
Threads of a process share
Let c1,cn be scalars not all zero. Such that the following expression holds:
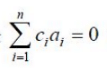
where ai is column vectors in Rn. Consider the set of linear equations.
Ax = B.
where A = [a1.......an] and
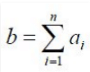
Q. Then, Set of equations has
Consider the first-order logic sentence
F: ∀ x (∃ y R(x,y)).
Q. Assuming non-empty logical domains, which of the sentences below are implied by F?
I. ∃y (∃x R(x,y))
II. ∃y (∀x R(x,y))
III. ∀y (∃x R(x,y))
IV. ∼∃x (∀y R(x,y))
Consider the following grammar
p --> xQRS
Q --> yz|z
R --> w|∈
S -> y
Q. Which is FOLLOW(Q)?
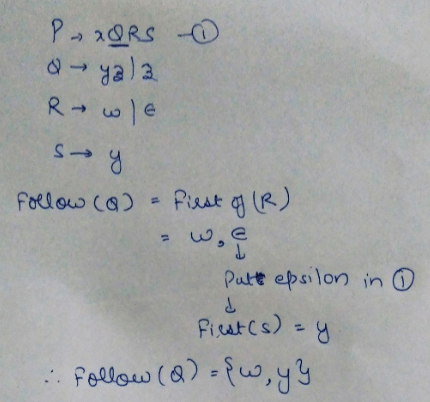
Consider a two-level cache hierarchy L1 and L2 caches. An application incurs 1.4 memory accesses per instruction on average. For this application, the miss rate of L1 cache 0.1, the L2 cache experience on average. 7 misses per 1000 instructions. The miss rate of L2 expressed correct to two decimal places is ______________.
Note: This questions appeared as Numerical Answer Type.
Consider the following functions from positives integers to real numbers 10, √n, n, log2n, 100/n. The CORRECT arrangement of the above functions in increasing order of asymptotic complexity is:
Consider the C struct defines below:
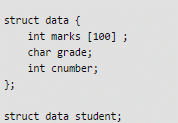
Q. The base address of student is available in register R1. The field student.grade can be accessed efficiently using
Consider the following C code:

Q. The code suffers from which one of the following problems:
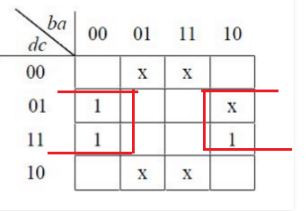
Consider the Karnaugh map given below, where X represents “ don’t care” and blank represents 0.
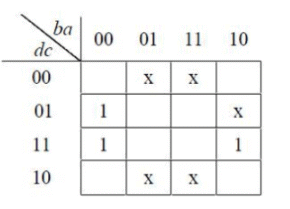
Q. Assume for all inputs (a, c, d) the respective complements (a', b', c', d')are also available. The above logic is implemented 2-input NOR gates only. The minimum number of gates required is ____________.
Consider the following table
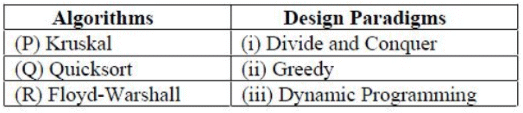
Q. Match the algorithm to design paradigms they are based on:
Consider the C code fragment given below.

Q. Assuming that m and n point to valid NULL- terminated linked lists, invocation of join will
Important Questions for Computer Science And Information Technology - CS 2017 GATE Paper - 1 (Practice Test)
Computer Science And Information Technology - CS 2017 GATE Paper - 1 (Practice Test) MCQs with Answers
Online Tests for Computer Science And Information Technology - CS 2017 GATE Paper - 1 (Practice Test)
|
© EduRev
|
Education Revolution
|



|









within 7 days!