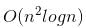1. Finding the Median:
-
The algorithm uses a method to find the median in linear time, which is O(n).
-
This median is used as the pivot in QuickSort.
-
Using the median ensures that the array is split into two nearly equal halves, which avoids the worst-case unbalanced splits of standard QuickSort.
2. Partitioning:
-
Partitioning the array around the median also takes O(n) time.
3. Recursive Calls:
-
Since the array is split into two equal (or nearly equal) parts, the recurrence relation for the time complexity becomes:
T(n) = 2T(n/2) + O(n) + O(n)
-
The first O(n) is for finding the median, and the second O(n) is for partitioning the array.
-
This simplifies to:
T(n) = 2T(n/2) + O(n)
4. Solving the Recurrence:
-
This recurrence relation is similar to the one used in MergeSort.
-
Its solution is O(n log n).
Final Answer:
B: O(n log n)
So, the worst-case time complexity of this modified QuickSort (that uses the median as pivot) is O(n log n).

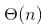 time when input array is already sorted.
time when input array is already sorted.