Analysis of variance and covariance, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

Analysis of variance (ANOVA) and analysis of covariance (ANACOVA) are statistical techniques most suited for the analysis of data collected using experimental methods. As a result, they have been used more frequently in the fields of psychology and medicine and less frequently in sociological studies where survey methods predominate. These techniques can be, and have been, used on survey data, but usually they are performed within the analysis framework of linear regression or the ”general linear model.” Given their applicability to experimental data, the easiest way to convey the logic and value of these techniques is to first review the basics of experimental design and the analysis of experimental data. Basic concepts and procedures will then be described, summary measures and assumptions reviewed, and the applicability of these techniques for sociological analysis discussed.
EXPERIMENTAL DESIGN AND ANALYSIS
In a classical experimental design, research subjects are randomly assigned in equal numbers to two or more discrete groups. Each of these groups is then given a different treatment or stimulus and observed to determine whether or not the different treatments or stimuli had predicted effects on some outcome variable. In most cases this outcome variable has continuous values rather than discrete categories. In some experiments there are only two groups—one that receives the stimulus (the experimental group) and one that does not (the control group). In other studies, different levels of a stimulus are administered (e.g., studies testing the effectiveness of different levels of drug dosages) or multiple conditions are created by administering multiple stimuli separately and in combination (e.g., exposure to a violent model and reading pacifist literature).
In all experiments, care is taken to eliminate any other confounding influences on subjects’ behaviors by randomly assigning subjects to groups. As a result of random assignment, preexisting differences between subjects (such as age, gender, temperament, experience, etc.) are randomly distributed across groups making the groups equal in terms of the potential effects of these preexisting differences. Since each group contains approximately equal numbers of subjects of any given age, gender, temperament, experience, etc., there should be no differences between the groups on the outcome variable that are due to these confounding influences. In addition, experiments are conducted in standardized or ”physically controlled” situations (e.g., a laboratory), thus eliminating any extraneous external sources of difference between the groups. Through random assignment and standardization of experimental conditions, the researcher is able to make the qualifying statement ”Other things being equal. . .” and assert that any differences found between groups on the outcome measure(s) of interest are due solely to the fact that one or more groups received the experimental stimulus (stimuli) and the other group did not.
Logic of analysis procedures. Analysis of variance detects effects of an experimental stimulus by first computing means on the outcome variable for the experimental and control groups and then comparing those means. If the means are the same, then the stimulus didn’t ”make a difference” in the outcome variable. If the means are different, then, because of random assignment to groups and standardization of conditions, it is assumed that the stimulus caused the difference. Of course, it is necessary to establish some guidelines for interpreting the size of the difference in order to draw conclusions regarding the strength of the effect of the experimental stimulus. The criterion used by analysis of variance is the amount of random variation that exists in the scores within each group. For example, in a three-group comparison, the group mean scores on some outcome measure may be 3, 6, and 9 on a ten-point scale. The meaningfulness of these differences can only be assessed if we know something about the variation of scores in the three groups. If everyone in group one had scores between 2 and 4, everyone in group two had scores between 5 and 7, and everyone in group three had scores between 8 and 10, then in every instance the variation within each group is low and there is no overlap across the within group distributions. As a result, whenever the outcome score of an individual in one group is compared to the score of an individual in a different group, the result of the comparison will be very similar to the respective group mean score comparison and the conclusions about who scores higher or lower will be the same as that reached when the means were compared. As a result, a great deal of confidence would be placed in the conclusion that group membership makes a difference in one’s outcome score. If, on the other hand, there were several individuals in each group who scored as low or as high as individuals in other groups—a condition of high variability in scores— then comparisons of these subjects’ scores would lead to a conclusion opposite to that represented by the mean comparisons. For example, if group one scores varied between 1 and 5 and group two scores varied between 3 and 10, then in some cases individuals in group one scored higher than individuals in group two (e.g., 5 vs. 3) even though the mean comparisons show the opposite trend (e.g., 3 vs. 6). As a result, less confidence would be placed in the differences between means.
Although analysis of variance results reflect a comparison of group means, conceptually and computationally this procedure is best understood through a framework of explained variance. Rather than asking ”How much difference is there between group means?,” the question becomes ”How much of the variation in subjects’ scores on the outcome measure can be explained or accounted for by the fact that subjects were exposed to different treatments or stimuli?” To the extent that the experimental stimulus has an effect (i.e., group mean differences exist), individual scores should differ from one another because some have been exposed to the stimulus and others have not. Of course, individuals will differ from one another for other reasons as well, so the procedure involves a comparison of how much of the total variation in scores is due to the stimulus effect (i.e., group differences) and how much is due to extraneous factors. Thus, the total variation in outcome scores is ”decomposed” into two elements: variation due to the fact that individuals in the different groups were exposed to different conditions, experiences, or stimuli (explained variance); and variation due to random or chance processes (error variance). Random or chance sources of variation in outcome scores can be such things as measurement error or other causal factors that are randomly distributed across groups through the randomization process. The extent to which variation is due to group differences rather than these extraneous factors is an indication of the effect of the stimulus on the outcome measure. It is this type of comparison of components of variance that provides the foundation for analysis of variance.
BASIC CONCEPTS AND PROCEDURES
The central concept in analysis of variance is that of variance. Simply put, variance is the amount of difference in scores on some variable across subjects. For example, one might be interested in the effect of different school environments on the self-esteem of seventh graders. To examine this effect, random samples of students from different school environments could be selected and given questionnaires about their self-esteem. The extent to which the students’ self-esteem scores differ from each other both within and across groups is an example of the variance.
Variance can be measured in a number of ways. For example, simply stating the range of scores conveys the degree of variation. Statistically, the most useful measures of variation are based on the notion of the sums of squares. The sums of squares is obtained by first characterizing a sample or group of scores by calculating an average or mean. The mean score can be thought of as the score for a ”typical” person in the study and can be used as a reference point for calculating the amount of differences in scores across all individuals. The difference between each score and the mean is analogous to the difference of each score from every other score. The variation of scores is calculated, then, by subtracting each score from the mean, squaring it, and summing the squared deviations (squaring the deviations before adding them is necessary because the sum of nonsquared deviations from the mean will always be 0). A large sums of squares indicates that the total amount of deviation of scores from a central point in the distribution of scores is large. In other words, there is a great deal of variation in the scores either because of a few scores that are very different from the rest or because of many scores that are slightly different from each other.
Decomposing the sums of squares. The total amount of variation in a sample on some outcome measure is referred to as the total sums of squares (SStotal). This is a measure of how much the subjects’ scores on the outcome variable differ from one another and it represents the phenomenon that the researcher is trying to explain (e.g., Why do some seventh graders have high self-esteem, while others have low or moderate self-esteem?). The procedure for calculating the total sums of squares is represented by the following equation:

The total sums of squares can then be ”decomposed” or mathematically divided into two components: the between-groups sums of squares (SSBETWEEN) and the within-groups sums of squares (SSWITHIN).
The between-groups sums of squares is a measure of how much variation in outcome scores exists between groups. It uses the group mean as the best single representation of how each individual in the group scored on the outcome measure. It essentially assigns the group mean score to every subject in the group and then calculates how much total variation there would be from the grand mean (the average of all scores regardless of group membership) if there was no variation within the groups and the only variation comes from cross-group comparisons. For example, in trying to explain variation in adolescent self-esteem, a researcher might argue that junior high schools place children at risk because of schools’ size and impersonal nature. If the school environment is the single most powerful factor in shaping adolescent self-esteem, then when adolescents are compared to each other in terms of their self-esteem, the only comparisons that will create differences will be those occurring between students in different school types, and all comparisons involving children in the same school type will yield no difference. The procedure for calculating the be-tween-groups sums of squares is represented by the following equation:
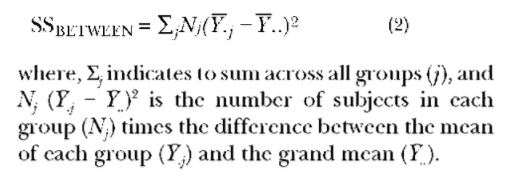
In terms of the comparison of means, the between-groups sums of squares directly reflects the difference between the group means. If there is no difference between the group means, then the group means will be equal to the grand mean and the between-groups sums of squares will be 0. If the group means are different from one another, then they will also differ from the grand mean and the magnitude of this difference will be reflected in the between-groups sums of squares. In terms of explaining variance, the between-groups sums of squares represents only those differences in scores that come about because the individuals in one group are compared to individuals in a different group (e.g., What if all students in a given type of school had the same level of self-esteem, but students in a different school type had different levels?). By multiplying the group mean difference score by the number of subjects in the group, this component of the total variance assumes that there is no other source of influence on the scores (i.e., that the variance within groups is 0). If this assumption is true, then the SSBETWEEN will be equal to the SSTOTAL and the group effect could be said to be extremely strong (i.e., able to overshadow any other source of influence). If, on the other hand, this assumption is not true, then the SSBETWEEN will be small relative to the SSTOTAL because other influences randomly dispersed across groups are generating differences in scores not reflected in mean score differences. This situation indicates that group differences in experimental conditions add little to our ability to predict or explain differences in outcome scores. In the extreme case, when there is no difference in the group means, the SSBETWEEN will equal 0, indicating no effect.
The within-groups sums of squares is a measure of how much variation exists in the outcome scores within the groups. Using the same example as above, adolescents in a given type of school might differ in their self-esteem in spite of the esteem-inflating or -depressing influence of their school environment. For example, elementary school students might feel good about themselves because of the supportive and secure nature of their school environment, but some of these students will feel worse than others because of other factors such as their home environments (e.g., the effects of parental conflict and divorce) or their neighborhood conditions (e.g., wealth vs. poverty). The procedure for calculating the within-groups sums of squares is represented by the following equation:
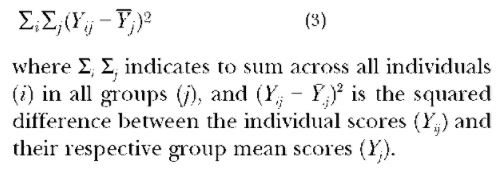
Both in terms of comparing means and explaining variance, the within-groups sums of squares represents the variance due to other factors or ”error”; it is the degree of variation in scores despite the fact that individuals in a given group were exposed to the same influences or stimuli. This component of variance can also serve as an estimate of how much variability in outcome scores occurs in the population from which each group of respondents was drawn. If the within-groups sums of squares is high relative to the between-groups sums of squares (or the difference between the means), then less confidence can be placed in the conclusion that any group differences are meaningful.
SUMMARY MEASURES
Analysis of variance procedures produce two summary statistics. The first of these—ETA2—is a measure of how much effect the predictor variable or factor has on the outcome variable. The second statistic—F— tests the null hypothesis that there is no difference between group means in the larger population from which the sample data was randomly selected.
ETA2. As noted above, a large between-groups sums of squares is indicative of a large difference in the mean scores between groups. The meaning-fulness of this difference, however, can only be judged against the overall variation in the scores. If there is a large amount of variation in scores relative to the variation due exclusively to be-tween-groups differences, then group effects can only explain a small proportion of the total variation in scores (i.e., a weak effect). ETA2 takes into account the difference between means and the total variation in scores. The general equation for computing ETA2 is as follows:

As can be seen from this equation, ETA2 is the proportion of the total sums of squares explained by group differences. When all the variance is explained, there will be no within-group variance, leaving SSTOTAL SSBETWEEN (SSTOTAL= SSBETWEEN + 0). Thus, ETA2 will be equal to 1, indicating a perfect relationship. When there is no effect, there will be no difference in the group means (SSBETWEEN = 0) and ETA2 will be equal to 0.
F Tests. Even if ETA2 indicates that a sizable proportion of the total variance in the sample scores is explained by group differences, the possibility exists that the sample results do not reflect true differences in the larger population from which the samples were selected. For example, in a study of the effects of cohabitation on marital stability, a researcher might select a sample of the population and find that, among those in his or her sample, previous cohabitors have lower marital satisfaction than those without a history of cohabitation. Before concluding that cohabitation has a negative effect on marriage in the broader population, however, the researcher must assess the probability that, by chance, the sample used in this study included a disproportionate number of unhappy cohabitors or overly satisfied noncohabitors, or both. There is always some probability that the sample will not be representative, and the F statistic utilizes probability theory (under the assumption that the sample was obtained through random selection) to assess that likelihood.
The logic behind the F statistic is that chance fluctuations in sampling are less likely to account for differences in sample means if the differences are large, if the variation in outcome scores in the population from which the sample was drawn is small, if the sample size is large, or if all these situations have occurred. Obviously, large mean differences are unlikely due to chance because they would require many more extremely unrepresentative cases to be selected into the sample. Selecting extreme cases, however, is more likely if there are many extremes in the population (i.e., the variation of scores is great). Large samples, however, reduce the likelihood of unrepresentative samples because any extreme cases are more likely to be counteracted by extremes in the opposite direction or by cases that are more typical.
The general equation for computing F is as follows:

The MS between is the mean square for be-tween-group differences. It is an adjusted version of the SSBETWEEN and reflects the degree of difference between group means expressed as individual differences in scores. An adjustment is made to the SSBETWEEN because this value can become artificially high by chance as a function of the number of group comparisons being made. This adjustment factor is called the degrees of freedom (DF BETWEEN) and is equal to the number of group comparisons (k-1, where k is the number of groups). The formula for the MSBETWEEN is:
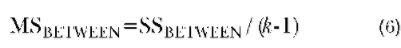
The larger the MSBETWEEN the greater the value of F and the lower the probability that the sample results were due to chance.
The MSWITHIN is the mean square for within-group differences. This is equivalent to the SSWITHIN, with an adjustment made for the size of the sample minus the number of groups (DFWITHIN). Since the SSWITHIN represents the amount of variation in scores within each group, it is used in the F statistic as an estimate of the amount of variation in scores that exists in the populations from which the sample groups were drawn. This is essentially a measure of the potential for error in the sample means. This potential for error is reduced, however, as a function of the sample size. The formula for the MSWITHIN is:
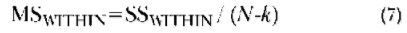
As can be seen in equations six and seven, when the number of groups is high, the estimate of variation between groups is adjusted downward to account for the greater chance of variation. When the number of cases is high, the estimation of variation within groups is adjusted downward. As a result, the larger the number of cases being analyzed, the higher the F statistic. A high F value reflects greater confidence that any differences in sample means reflect differences in the populations. Using certain assumptions, the possibility that any given F value can be obtained by chance given the number of groups (DF1) and the number of cases (DF2) can be calculated and compared to the actual F value. If the chance probability is only 5 percent or less, then the null hypothesis is rejected and the sample mean differences are said to be ”significant” (i.e., not likely due to chance, but to actual effects in the population).
ADJUSTING FOR COVARIATES
Analysis of variance can be used whenever the predictor variable(s) has a limited number of discrete categories and the outcome variable is continuous. In some cases, however, an additional continuous predictor variable needs to be included in the analysis or some continuous source of extraneous effect needs to be ”controlled for” before the group effects can be assessed. In these cases, analysis of covariance can be used as a simple extension of the analysis of variance model.
In the classical experimental design, the vari-able(s) being controlled for—the covariate(s)—is frequently some background characteristics or pretest scores on the outcome variable that were not adequately randomized across groups. As a result, group differences in outcome scores may be found and erroneously attributed to the effect of the experimental stimulus or group condition, when in fact the differences between groups existed prior to, or independent of, the presence of the stimulus or group condition.
One example of this situation is provided by Roberta Simmons and Dale Blyth (1987). In a study of the effects of different school systems on the changing self-esteem of boys and girls as they make the transition from sixth to seventh grade, these researchers had to account for the fact that boys and girls in these different school systems had different levels of self-esteem in sixth grade. Since those who score high on a measure at one point in time (T1) will have a statistical tendency to score lower at a later time (T2) and vice versa (a negative relationship), these initial differences could lead to erroneous conclusions. In their study, if boys had higher self-esteem than girls in sixth grade, the statistical tendency would be for boys to experience negative change in self-esteem and girls to experience positive change even though seventh-grade girls in certain school systems experience more negative influences on their self-esteem.
The procedure used in adjusting for covariates involves a combination of analysis of variance and linear regression techniques. Prior to comparing group means or sources of variation, the outcome scores are adjusted based upon the effect of the covariate(s). This is done by computing predicted outcome scores based on the equation:

where Y is the new adjusted outcome score, a is a constant, and b1 is the linear effect of the covariate (X1) on the outcome score (Y). The difference between the actual score and the predicted score (Yj – Yj) is the residual. These residuals represent that part of the individuals’ scores that is not explained by the covariate. It is these residuals that are then analyzed using the analysis of variance techniques described above. If the effect of the covariate is negative, then those who scored high on the covariate will have their scores adjusted upward. Those who scored lower on the covariate would have their scores adjusted downward. This would counteract the reverse effect that the covariate has had. Group differences could then be assessed after the scores have been corrected.
This model can be expanded to include any number of covariates and is particularly useful when analyzing the effects of a discrete independent variable (e.g., gender, race, etc.) on a continuous outcome variable using survey data, where other factors cannot be randomly assigned and where conditions cannot be standardized. In such situations, other preexisting difference between groups (often, variables measured on continuous scales) need to be statistically controlled for. In these cases, researchers often perform analysis of variance and analysis of covariance within the context of what has been termed the ”general linear model.”
GENERAL LINEAR MODEL
The general linear model refers to the application of the linear regression equation to solve analysis problems that initially do not meet the assumptions of linear regression analysis. Specifically, there are three situations where the assumptions of linear regression are violated but regression techniques can still be used: (1) the use of nominal level measures (e.g., race, religion, marital status) as independent variables—a violation of the assumption that all variables be measured at the interval or ratio level; (2) the existence of interaction effects between independent variables—a violation of the assumption of additivity of effects; and (3) the existence of a curvilinear effect of the independent variable on the dependent variable— a violation of the assumption of linearity. The linear regression equation can be applied in all of these situations provided that certain procedures and operations on the variables are carried out. The use of the general linear model for performing analysis of variance and analysis of covariance is described in greater detail below.
Regression with dummy variables. In situations where the dependent variable is measured at the interval level of measurement (ordered values at fixed intervals) but one or more independent variables are measured at the nominal level (no order implied between values), analysis of variance and covariance procedures are usually more appropriate than linear regression. Linear regression analysis can be used in these circumstances, however, as long as the nominal level variables are first ”dummy coded.” The results will be consistent with those obtained from an analysis of variance and covariance, but can also be interpreted within a regression framework.
Dummy coding is a procedure where a separate dichotomous variable is created for each category of the nominal level variable. For example, in a study of the effects of racial experience, the variable for race can have several values that imply no order or degree. Some of the categories might be white, black, Latino, Indian, Asian, and other. Since these categories imply no order or degree, the variable for race cannot be used in a linear regression analysis.
The alternative is to create five dummy variables—one for each race category except one. Each of these variables measures whether or not the respondent is the particular race or not. For example, the first variable might be for the category ”white,” where a value of 0 is assigned if the person is any other race but white, and a value of 1 is assigned if the person is white. Similarly, separate variables would be created to identify membership in the black, Latino, Indian, and Asian groups. A dummy variable is not created for the ”other” category because its values are completely determined by values on the other dummy variables (e.g., all persons with the racial category ”other” will have a score of 0 on all of the dummy variables). This determination is illustrated in the table below.
Since there are only two categories or values for each variable, the variables can be said to have interval-level characteristics and can be entered into a single regression equation such as the following:
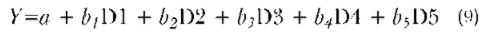
where Y is the score on the dependent variable, a is the constant or Y-intercept, b1, b2, b3, b4, and b5 are the regression coefficients representing the effects of each category of race on the dependent variable, and D1, D2, D3, D4, and D5 are dummy variables representing separate categories of race. If a person is black, then his or her predicted Y score would be equal to a + b2, since D2 would have a value of 1 (b2D2 = b2 * 1 = b2) and D1, D3, D4, and D5 would all be 0 (e.g., b1D1 = b1 * 0 = 0). The effect of race would then be the addition of each of the dummy variable effects. Other dummy or interval-level variables could then be included in the analysis and their effects could be interpreted as ”controlling for” the effects of race.
Values on Dummy Variables
Respondent’s Race | D1 | D2 | D3 | D4 | D5 |
White | 1 | 0 | 0 | 0 | 0 |
Black | 0 | 1 | 0 | 0 | 0 |
Latino | 0 | 0 | 1 | 0 | 0 |
Indian | 0 | 0 | 0 | 1 | 0 |
Asian | 0 | 0 | 0 | 0 | 1 |
Other | 0 | 0 | 0 | 0 | 0 |
Estimating analysis of variance models. The use of dummy variables in regression makes it possible to estimate analysis of variance models as well. In the example above, the value of a is equal to the mean score on the dependent variable for those who had a score of ”other” on the race variable (i.e., the omitted category). The mean scores for the other racial groups can then be calculated by adding the appropriate b value (regression coefficient) to the a value. For example, the mean for the Latino group would be a + b3. In addition, the squared multiple correlation coefficient (R2) is equivalent to the measure of association used in analysis of variance (ETA2), and the F test for statistical significance is also equivalent to the one computed using conventional analysis of variance procedures. This general model can be further extended by adding additional terms into the prediction equation for other control variables measured on continuous scales. In effect, such an analysis is equivalent to an analysis of covariance.
APPLICABILITY
In sociological studies, the researcher is rarely able to manipulate the stimulus (or independent variable) and tends to be more interested in behavior in natural settings rather than controlled experimental settings. As a result, randomization of preexisting differences through random assignment of subjects to experimental and control groups is not possible and physical control over more immediate outside influences on behavior cannot be attained. In sociological studies, ”other things” are rarely equal and must be ruled out as possible alternative explanations for group differences through ”statistical control.” This statistical control is best accomplished through correlational techniques, although in certain circumstances the analysis of covariance can be used to statistically control for possible extraneous sources of influence.
Where analysis of variance and covariance are more appropriate in sociological studies is: (1) where the independent variable can be manipulated (e.g., field experiments investigating natural reactions to staged incidences, or studies of the effectiveness of different modes of intervention or teaching styles); (2) analyses of typologies or global variables that capture a set of unspecified, interrelated causes or stimuli (e.g., comparisons of industrialized vs. nonindustrialized countries, or differences between white collar vs. blue collar workers); or (3) where independent (or predictor) variables are used that have a limited number of discrete categories (e.g., race, gender, religion, country, etc.).
|
556 videos|198 docs
|
FAQs on Analysis of variance and covariance, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is the purpose of analysis of variance and covariance? |  |
| 2. What is the difference between analysis of variance and analysis of covariance? | |
| 3. How does analysis of variance work? | |
| 4. When should analysis of covariance be used instead of analysis of variance? | |
| 5. What are some limitations of analysis of variance and covariance? | |



Free
,shortcuts and tricks
,Analysis of variance and covariance
,Analysis of variance and covariance
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,mock tests for examination
,CSIR NET
,Previous Year Questions with Solutions
,MCQs
,Sample Paper
,UGC NET
,UGC NET
,Important questions
,CSIR NET
,video lectures
,Objective type Questions
,study material
,GATE
,Analysis of variance and covariance
,GATE
,Extra Questions
,GATE
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Exam
,Summary
,practice quizzes
,ppt
,past year papers
,Viva Questions
,UGC NET
,Semester Notes
,CSIR NET
;






Analysis of variance and covariance, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Analysis of variance and covariance, CSIR-NET Mathematical Sciences
Analysis of variance and covariance, CSIR-NET Mathematical Sciences Notes
Analysis of variance and covariance, CSIR-NET Mathematical Sciences Mathematics Questions
Study Analysis of variance and covariance, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|





