Structuring Database for Accounting Chapter Notes | SSC CGL Tier 2 - Study Material, Online Tests, Previous Year PDF Download

CHAPTER - 7
STRUCTURING DATABASE FOR ACCOUNTING
- Structuring Database for Accounting
It is a complex yet crucial function of a business. Before we get into the intricacies of the topic, it is essential to understand two primary introductory concepts:
• Documentation of transactions
• Computerized accounting
• Accounting database
The process of computerised accounting involves identifying, storing and retrieving the data content of an accounting transaction. This requires a mechanism to store such data content of vouchers in a manner that allows its easy and convenient retrieval as and when required. This is achieved by designing suitable database for accounting. Such a database consists of inter-related data tables that are structured in a manner that ensures data consistency and integrity.
In this chapter we shall discuss the basic concepts of database system of accounting.
- Data Processing
Cycle Data processing involves the technique of collecting, sorting, relating, interpreting and computing data items in such a manner as to provide meaningful and useful information for decision-making. The necessary steps involved in data processing cycle are data capturing, inputing, processing and generating information available to the user. Data processing cycle, when thought of in the context of accounting, requires a series of steps that have been described below briefly:
1) Source Documents: The first step is to capture accounting data from transaction(s) so as to prepare a document, called voucher (as already stated earlier), that expresses and documents an accounting transaction.
2) Input of Data: The accounting data contained in vouchers is to be entered in a computer’s storage device. This is achieved by using a pre-designed Data Entry Form. This data entry form is designed in a manner that it is similar to physical voucher document. The data entry form is designed using software and it is made to appear on the computer monitor so that the data is entered.
3) Data Storage: A suitable data storage structure is required to provide for a blank data record. Blank record that is used for storing the input of data pertaining code of account, name of account and the category type to which it belongs.
4) Manipulation of Data: The stored data is manipulated for necessary transformation to generate final reports. Such transformed data may be stored separately and subsequently used for generating final reports.
5) Output of Data: The accounting reports such as ledger, trial balance, etc. are obtained in a pre-designed format by accessing the transformed data.
-Designing Database for Accounting
Both computerised and computer-based AIS require a definite data structure for storing the accounting data. As already mentioned, the databases are used for storing accounting data. The process of designing database (for accounting) begins with a reality (or accounting reality) that is expressed using elements of a conceptual data model.
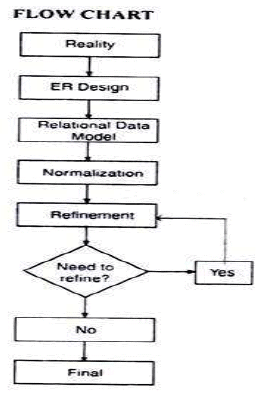
1) Reality: It refers to some aspect of real world situation, for which database is to be designed. In the context of accounting, it is accounting reality that is to be expressed with complete description.
2) ER Design: This is a formal blue print, with a pictorial presentation, in which Entity Relationship (ER) Model concepts are used to represent description of reality.
3) Relational Data Model: It is representational data model through which ER design is transformed into inter-related data tables along with the restriction in the form of rules that are specified to ensure the consistency and integrity of stored data.
4) Normalisation: This is process of refining a database design (that consists of inter-related data tables) through which the possibility of duplicate or redundant data items is reduced or eliminated.
5) Refinement: This is the outcome of the process of normalisation as mentioned above. The final database design is arrived at after the process of normalisation is completed.
- Entity Relationship (ER) Model
It is a popular conceptual data model, which is mostly used in database-oriented applications. The major elements of ER Model are entities, attributes, identifiers and relationships that are used to express a reality for which a database is to be designed. The model is best depicted with the help of ER symbols and list. ER symbol depict ions are stated below:

The ER database model has 5 major elements: entities, identifiers, attributes, and relationships and weak entity. Each of the element depicts unique functions.
1) Entities
Entities are similar to reality because of having a real-world and inter-dependent existence. They could either be objects having physical existence (trees, buildings, clothes) or conceptual existence (employment, education, poverty). The 5 entities of accounting are vouchers, employees, accounts, support documents, and accounts type.
2) Attributes
Attributes are a certain set of features or characteristics that further describe an entity. They can be composite or simple, single-valued or multi-valued, stored or derived, null or complex.
3) Identifiers
Key attributes is another name for identifiers. They are certainly unique to every entity. For example, the voucher number for every transaction.
4) Relationships
Relationships refer to the relation between 2 or more entities and their relevant and respective attributes.
5) Weak Entity Types
Entity Types, which do not have identifier (or key attributes) of their own are, called weak entity types. Such entity types are identified by being related to specific entities from another entity type in combination with some of their attribute values.
- Database Technology
Database technologies a set of unique techniques that are crucial and essential to design a database. The techniques include concepts which are important in order to develop a database structure or a database design. A few of such concepts are briefly explained below:
1) Reality: It implies so me aspect of the real world. It consists of an organisation, its different components and the environment in which the organisation exists and operates. Any organisation includes people, facilities and other resources that are organised to achieve certain goals. Each organisation operates within an environment.
2) Data: Data are known facts that can be recorded and which have implicit meaning. Data represent facts concerning people, places, objects, entities, events or even concepts. Data can be quantitative and qualitative or they can be financial and non-financial in character.
3) Database: The data, after being collected, has to be stored so that different people can use them. This requires the creation of a database. A database is a shared collection of interrelated data tables, files or structures, which are designed to meet the varied informational needs of an organization.
4) Information: refers to data that have been processed and organised in a form, which is suitable for decision-making. The raw data when processed in accordance with decision usefulness of a decision-maker becomes information.
- How does structuring database for accounting benefit the organization?
In order to understand the benefits of structuring database for accounting, it is important to remember that accounting database has been made possible by adopting computers for accounting. Because of this advancement:
1) Accounting data can be stored for a longer duration of time.
2) Retrieval of accounting data can be done within minutes.
3) Emergency decisions and amendments in policies are quicker than ever.
4) Financial reports are more accurate and precise.
5) Decisions are made with more confidence and integrity.
- Relational Data Model
The relational data model represents the database as collection of relations, which resembles a table of values (or data table). Each row of the table, therefore, represents a collection of related data values and hence typically corresponds to real world entity or relationship. The table name and column names are used to help in interpreting the meaning of values in each row. Each row of a table is called a data record. All values in a column, which belong to a particular domain, are of same data type.
- Relational Databases and Schemas
A relational database schema is a set of relation schemas and a set of integrity constraints. A relational database state is a set of relation states such that every relational database state satisfies the integrity constraints specified on relational database schema.
In this context the following points merit a special consideration:
1) A particular attribute, which stands for the same real word concept, might appear in more than one relation with same or different name. For example, in vouchers relation, the account Number is represented as debit and credit whereas in accounts relation, it is represented as Code.
2) The particular real world concept appearing more than once in a relation must be represented by different names. For example, in employees relation, employee is represented as subordinate, by using EmpId and as superior by using SuperId.
3) The Integrity constraints, specified on database schema, must hold in every database state of that schema.
- Constraints and Database Schemas
There are four different constraints, which can be specified on relational databases. These are: domain constraint; key constraint; entity integrity constraint; referential integrity constraints.
1) Domain: The value of each attribute of a relation must be an indivisible value and drawn out of possible values associated with its domain. The value of an attribute, therefore, must conform to the data type associated with the domain.
2) Key Constraints and NULL Values: Each data record, which corresponds to a tuple of a relation, in a table must be distinct. That means no two tuples (or rows) in a relation (or table) can have the same combination of values for all their data items. This is because that a relation, as set of tuples, has to have all its tuples distinct by definition. Every relation has at least one key by default, which is the combination of all its attributes. This is called super-key by default. Any such super-key, therefore, specifies uniqueness constraint. Such a combination, representing super-key, may have redundant attributes, implying thereby that a more useful concept is that of a key which has not redundancy.
3) Entity integrity constraint: States that no primary key value can be null because it is used to identify individual tuple in a relation. Null value implies that we cannot identify such tuples or identify these as alike. A failure to distinguish them means they are duplicates.
4) Referential integrity constraint: While key and ent it y constraints are specified on individual relation, the referential integrity constraint is specified between two or more relations. This constraint is specified to maintain consistency among the tuples of such relations.
- Operations and Constraint Violations
There are two categories of operations on relational model: updates and retrieval The three basic types of updates are as given below:
1) Insert: This operation is performed to add a new tuple in a relation. For example, an attempt to add another record of an account with data values corresponding to Code, Name and its Type to Accounts relation shall be made by performing Insert operation. The insert operation is capable of violating any of the four constraints discussed above.
2) Delete: This operation is carried out to remove a tuple from a relation. A particular data record from a table can be removed by performing such operation. The delete operation can violate only referential integrity, if tuple being removed is referenced by foreign key from other tuples in the database.
3) Modify: The operation aims at causing a change in the values of some attributes in existing tuples. This is useful in modifying existing values of an accounting record in a data table. Usually, this operation does not cause problems provided the modification is directed on neither primary key nor foreign key.
- Designing Relational Database Schema
The rules or guidelines required to design the relational database schema attempt to provide a step-by-step procedure that transforms ER design into Relational Data model design to constitute the desired database. The following specific steps are required to cause its transformation into relational data model:
1) Create a relation for every strong entity: For each strong entity type (which has primary key) in ER schema, a separate relation that includes all the simple attributes of that entity is created. Either choose one of the key attributes of such an entity as the primary key for this relation, or choose a set of simple attributes that uniquely identify this entity as the primary key of the relation so created.
2) Create a separate relation for each weak entity type: Every weak entity has an owner entity and an identifying relationship through which such weak entity type is identified. For every weak entity type, a separate relation is created by including its attributes. The primary key of this new relation is the combination of its unique attribute(s) for a particular tuple of the owner relation along with primary key attribute of such owner relation. Furthermore, the primary key of owner entity is included as foreign key in such a relation key of owner entity and the partial key of weak entity.
3) Identify entity types participating in binary 1: N relationship type: Identify the first relation on n-side of relationship and second on 1-side of such relationship. The primary key of second relation should be included in first relation as its foreign key.
4) Identify entity types participating in binary M:N relationship type: For each binary M:N relationship type, create a new relation to represent such relationship. This new relation should include as foreign keys, the primary keys of the relations that represent the participating entity types.
- Illustrating the Database Structure for Example Realities
DBMS software is used to implement the data model by creating several tables, setting their interrelationships and imposing constraints as may be set out in database design. After, the design is implemented, it must also allow for retrieval of data and information. This is achieved by querying the database, for which purpose, SQL statements are put to use.
These retrieval requests result in emergence of new virtual tables that may be formed out of one or more of existing tables. A clear understanding of these SQL statements is a first step towards the theoretical foundations for computerised reporting. This is because a report is an organised set of information, which is extracted on the basis of these retrieval requests.
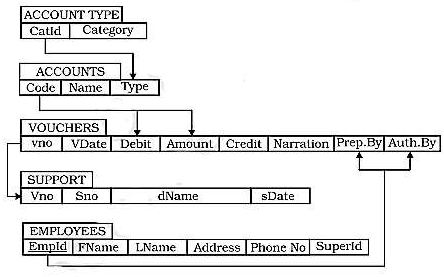
For a practical understanding of these operations, consider the following Models, herein referred to as Model-I and Model-II. Each of these models, which consist of a set of relations (or tables) and the integrity constraints, constitutes the database design for accounting.
Model-I: This is based on initial conceptual design of example reality shown in the figure:
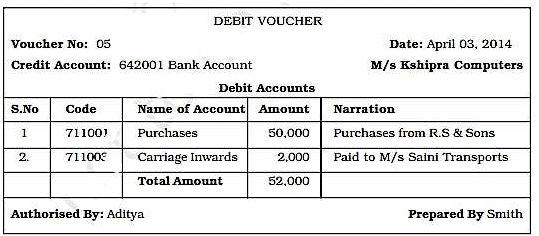
Model-II: The set relations given below are based on modified example reality that uses Credit and Debit vouchers shown in figures:

|
1335 videos|1432 docs|834 tests
|
FAQs on Structuring Database for Accounting Chapter Notes - SSC CGL Tier 2 - Study Material, Online Tests, Previous Year
| 1. How should a database be structured for accounting purposes? |  |
| 2. What are some key considerations when structuring a database for accounting? | |
| 3. How can a well-structured database improve accounting processes? | |
| 4. What role does database normalization play in accounting databases? | |
| 5. How can a structured database help with financial reporting in accounting? | |



practice quizzes
,Online Tests
,Exam
,Previous Year
,shortcuts and tricks
,past year papers
,Objective type Questions
,Structuring Database for Accounting Chapter Notes | SSC CGL Tier 2 - Study Material
,Sample Paper
,ppt
,Structuring Database for Accounting Chapter Notes | SSC CGL Tier 2 - Study Material
,Online Tests
,Structuring Database for Accounting Chapter Notes | SSC CGL Tier 2 - Study Material
,Free
,study material
,Extra Questions
,Important questions
,Previous Year
,Previous Year
,Semester Notes
,Previous Year Questions with Solutions
,mock tests for examination
,video lectures
,Online Tests
,MCQs
,Viva Questions
,Summary
;


Chapter Notes - Structuring Database for Accounting Free PDF Download
Importance of Chapter Notes - Structuring Database for Accounting
Chapter Notes - Structuring Database for Accounting
Chapter Notes - Structuring Database for Accounting SSC CGL Questions
Study Chapter Notes - Structuring Database for Accounting on the App
|
© EduRev
|
Education Revolution
|



|





