Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

Chi-Square Goodness of Fit Test
When an analyst attempts to fit a statistical model to observed data, he or she may wonder how well the model actually reflects the data. How "close" are the observed values to those which would be expected under the fitted model? One statistical test that addresses this issue is the chi-square goodness of fit test. This test is commonly used to test association of variables in two-way tables (see "Two-Way Tables and the Chi-Square Test"), where the assumed model of independence is evaluated against the observed data. In general, the chi-square test statistic is of the form
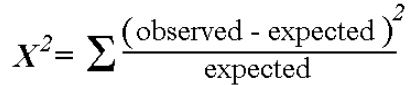 .
.
If the computed test statistic is large, then the observed and expected values are not close and the model is a poor fit to the data.
Example
A new casino game involves rolling 3 dice. The winnings are directly proportional to the total number of sixes rolled. Suppose a gambler plays the game 100 times, with the following observed counts:
Number of Sixes Number of Rolls |
The casino becomes suspicious of the gambler and wishes to determine whether the dice are fair. What do they conclude?
If a die is fair, we would expect the probability of rolling a 6 on any given toss to be 1/6. Assuming the 3 dice are independent (the roll of one die should not affect the roll of the others), we might assume that the number of sixes in three rolls is distributed Binomial(3,1/6). To determine whether the gambler's dice are fair, we may compare his results with the results expected under this distribution. The expected values for 0, 1, 2, and 3 sixes under the Binomial(3,1/6) distribution are the following:
Null Hypothesis:
p1 = P(roll 0 sixes) = P(X=0) = 0.58
p2 = P(roll 1 six) = P(X=1) = 0.345
p3 = P(roll 2 sixes) = P(X=2) = 0.07
p4 = P(roll 3 sixes) = P(X=3) = 0.005.
Since the gambler plays 100 times, the expected counts are the following:
Number of Sixes Expected Counts Observed Counts |
The two plots shown below provide a visual comparison of the expected and observed values:
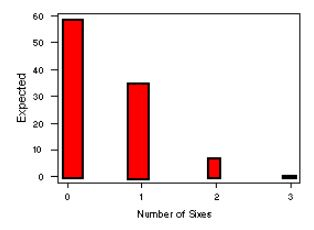
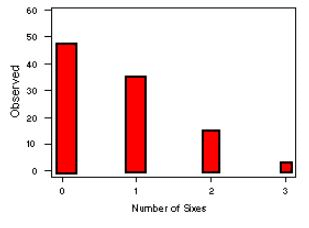
From these graphs, it is difficult to distinguish differences between the observed and expected counts. A visual representation of the differences is the chi-gram, which plots the observed - expected counts divided by the square root of the expected counts, as shown below:
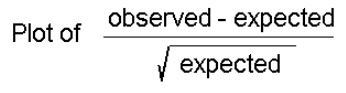
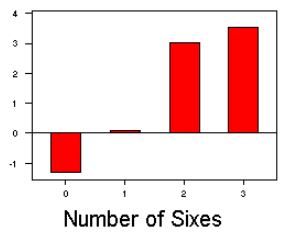
The chi-square statistic is the sum of the squares of the plotted values,
(48-58)²/58 + (35-34.5)²/58 + (15-7)²/7 + (3-0.5)²/0.5
= 1.72 + 0.007 + 9.14 + 12.5 = 23.367.
Given this statistic, are the observed values likely under the assumed model?
A random variable x2is said to have a chi-square distribution with m degrees of freedom if it is the sum of the squares of m independent standard normal random variables (the square of a single standard normal random variable has a chi-square distribution with one degree of freedom). This distribution is denoted x2(m), with associated probability values available in Table G in Moore and McCabe and in MINITAB.
The standardized counts (observed - expected )/sqrt(expected) for k possibilities are approximately normal, but they are not independent because one of the counts is entirely determined by the sum of the others (since the total of the observed and expected counts must sum to n). This results in a loss of one degree of freedom, so it turns out the the distribution of the chi-square test statistic based on k counts is approximately the chi-square distribution with m = k-1 degrees of freedom, denoted x2(k-1).
Hypothesis Testing
We use the chi-square test to test the validity of a distribution assumed for a random phenomenon. The test evaluates the null hypotheses H0 (that the data are governed by the assumed distribution) against the alternative (that the data are not drawn from the assumed distribution).
Let p1, p2, ..., pk denote the probabilities hypothesized for k possible outcomes. In n independent trials, we let Y1, Y2, ..., Yk denote the observed counts of each outcome which are to be compared to the expected counts np1, np2, ..., npk. The chi-square test statistic is qk-1 =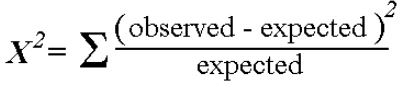
= (Y1 - np1)² + (Y2 - np2)² + ... + (Yk - npk)²
---------- ---------- --------
np1 np2 npk
Reject H0 if this value exceeds the upper α critical value of the x2(k-1) distribution, where α is the desired level of significance.
Example
In the gambling example above, the chi-square test statistic was calculated to be 23.367. Since k = 4 in this case (the possibilities are 0, 1, 2, or 3 sixes), the test statistic x2 is associated with the chi-square distribution with 3 degrees of freedom. If we are interested in a significance level of 0.05 we may reject the null hypothesis (that the dice are fair) if x2 > 7.815, the value corresponding to the 0.05 significance level for the x2(3) distribution. Since 23.367 is clearly greater than 7.815, we may reject the null hypothesis that the dice are fair at the 0.05 significance level.
Given this information, the casino asked the gambler to take his dice (and his business) elsewhere.
Example
Consider a binomial random variable Y with mean (expected value) np and variance σ y2 = np(1-p).
From the Central Limit Theorem, we know that Z = (Y-np)/σy has an approximately Normal(0,1) distribution for large values of n. Then Z² is approximately x2(1), since the square of a normal random variable has a chi-square distribution.
Suppose the random variable Y1 has a Bin(n,p1) distribution, and let Y2 = n - Y1 and p2 = 1 - p1.
Then Z² = (Y1 - np1)²
----------
np1(1-p1)
= (Y1 - np1)²(1 - p1) + (Y1 - np1)²(p1)
---------------------------------------
np1(1-p1)
= (Y1 - np1)² + (Y1 - np1)²
---------- ----------
np1 n(1-p1)
Since (Y1 - np1)² = (n - Y2 - n + np2)² = (Y2 - np2)²,
we have Z² = (Y1 - np1)² + (Y2 - np2)²
---------- ----------
np1 np2
where Z² has a chi-square distribution with 1 degree of freedom. If the observed values Y1 and Y2 are close to their expected values np1 and np2, then the calculated value Z² will be close to zero. If not, Z² will be large.
In general, for k random variables Yi, i = 1, 2,..., k, with corresponding expected values npi, a statistic measuring the "closeness" of the observations to their expectations is the sum
(Y1 - np1)² + (Y2 - np2)² + ... + (Yk - npk)²
---------- ---------- --------
np1 np2 npk
which has a chi-square distribution with k-1 degrees of freedom.
Estimating Parameters
Often, the null hypothesis involves fitting a model with parameters estimated from the observed data. In the above gambling example, for instance, we might wish to fit a binomial model to evaluate the probability of rolling a six with the gambler's loaded dice. We know that this probability is not equal to 1/6, so we might estimate this value by calculating the probability from the data. By estimating a parameter, we lose a degree of freedom in the chi-square test statistic. In general, if we estimate d parameters under the null hypothesis with k possible counts the degrees of freedom for the associated chi-square distribution will be k - 1 - d.
Example
A two-way table for two categorical variables X and Y with r and c levels, respectively, will have r rows and c columns. The table will have rc cells, with any one cell entirely determined by the sum of the others, so k-1 = rc - 1 in this case. A chi-square test of this table tests the null hypothesis of independence against the alternative hypothesis of association between the variables. Under the assumption of independence, we estimate (r-1) + (c-1) parameters to give the marginal probabilities that determine the expected counts, so d = (r-1) + (c-1). The degrees of freedom for the chi-square test statistic are
(rc - 1) - [(r-1) + (c-1)]
= rc -1 - r + 1 - c + 1
= rc - r - c + 1
= (r - 1)(c - 1).
The chi-square goodness of fit test may also be applied to continuous distributions. In this case, the observed data are grouped into discrete bins so that the chi-square statistic may be calculated. The expected values under the assumed distribution are the probabilities associated with each bin multiplied by the number of observations. In the following example, the chi-square test is used to determine whether or not a normal distribution provides a good fit to observed data.
Example
The MINITAB data file "GRADES.MTW" contains data on verbal and mathematical SAT scores and grade point average for 200 college students. Suppose we wish to determine whether the verbal SAT scores follow a normal distribution. One method is to evaluate the normal probability plot for the data, shown below:
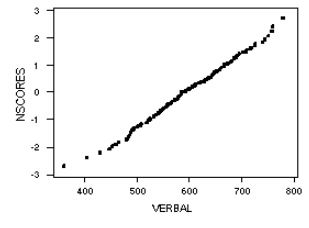
The plot indicates that the assumption of normality is not unreasonable for the verbal scores data.
To compute a chi-square test statistic, I first standardized the verbal scores data by subtracting the sample mean and dividing by the sample standard deviation. Since these are estimated parameters, my value for d in the test statistic will be equal to two. The 200 standardized observations are the following:
[1] -2.11801 -2.69073 0.76066 1.04702 0.91138 -0.09842 0.23316 1.04702 0.65516 0.77573 |
I chose to divide the observations into 10 bins, as follows:
Bin Observed Counts |
The corresponding standard normal probabilities and the expected number of observations (with n=200) are the following:
Bin Normal Prob. Expected Counts Observed - Expected Chi-Value |
The chi-square statistic is the sum of the squares of the values in the last column, and is equal to 2.69.
Since the data are divided into 10 bins and we have estimated two parameters, the calculated value may be tested against the chi-square distribution with 10 -1 -2 = 7 degrees of freedom. For this distribution, the critical value for the 0.05 significance level is 14.07. Since 2.69 < 14.07, we do not reject the null hypothesis that the data are normally distributed.
|
558 videos|198 docs
|
FAQs on Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is a chi-square test of goodness of fit? |  |
| 2. When should one use a chi-square test of goodness of fit? | |
| 3. How does a chi-square test of goodness of fit work? | |
| 4. What are the assumptions of a chi-square test of goodness of fit? | |
| 5. What are the limitations of a chi-square test of goodness of fit? | |



GATE
,Important questions
,MCQs
,practice quizzes
,CSIR NET
,Chi-square test of goodness of fit
,video lectures
,Previous Year Questions with Solutions
,ppt
,shortcuts and tricks
,GATE
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Free
,study material
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Chi-square test of goodness of fit
,CSIR NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Semester Notes
,Viva Questions
,Chi-square test of goodness of fit
,mock tests for examination
,Extra Questions
,Sample Paper
,Summary
,CSIR NET
,Exam
,GATE
,Objective type Questions
,UGC NET
,UGC NET
,past year papers
,UGC NET
;


Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences
Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences Notes
Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences Mathematics Questions
Study Chi-square test of goodness of fit, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|





