Humanities/Arts Exam > Humanities/Arts Notes > Computer Science for Class 11 > Encoding Schemes
Encoding Schemes | Computer Science for Class 11 - Humanities/Arts PDF Download
Comprehensive
Encoding Schemes: ASCII, UTF8, UTF32, ISCII, and Unicode are used to represent data into computers. Computers are capable to handle all kinds of data including numbers, text, images, audio, and video files.
As you know that computers do not understand English alphabets, numbers other than 0 and 1 as well as text symbols. To convert this we use an encoding.

Basic terms related to encoding
- Encoding Scheme: It is the way or method of conversion in machine language.
- Code Space: It means all the codes that are used to represent the information. For example, 127 in ASCII code.
- Code Point: It is a code that represents a character in an encoding scheme. For ex. 0x43 represents capital C letter.
- Code Unit: It refers to the number of bits used in codes.
Character / String representation
As you know data is a textual fact, figures, or collection of bytes. So to represent this data into computers we need to convert them into machine language i.e. binary language usually in the form of 0s and 1s.
All the 26 alphabets from A to Z (both upper and lower), numeric digits from 0 to 9 as we are using decimal number systems and other special symbols like @,#,$,%, etc need to be converted into machine language.
To do this each and every character or digit or special symbol assigned a specific code to represent them. These codes are as following:
ASCII Code
It is a simple code assigned to a character to represent data. ASCII (pronounced as “askee”) is a 7 – bit character code. It represents all the characters available for writing in the file. Every digit in ASCII code represents one byte. Let us have a look at the following commonly used characters and code range:
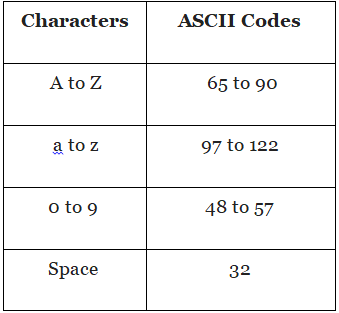
The computer generally converts these ASCII codes into an equivalent binary number. Let’s understand it by the following example:
Suppose you want to use the capital letter D. So its equivalent ASCII code is 68. This code 68 is a decimal number, ASCII. So the equivalent binary number is 1000100. So finally D = 1000100 for the computers.
There are two versions of ASCII codes:
- 7 bit: Represents 27 = 128 characters
- 8 bit: Represents 28 = 256 characters
The next code is the ISCII code for Comprehensive notes Encoding Schemes class 11 cs.
ISCII Code
When computers are used with English language ASCII codes enough to represent data. But as and when the use of computers broadly extended to countries like India, it’s very important to represent data in Indian Languages. So for that in 1991, the Bureau of Indian Standards adopted the Indian Standard Code for Information Interchange has evolved. This code is capable of 8 bits. It is also known as the Indian Scripts Code for Information Interchange. It supports various Indian languages like Devnagri, Gurumukhi, Gujarati, Oriya, Bengali, Assamese, Telugu etc.
Unicode
Unicode is used for a universal set of characters. As ISCII is used for Indian languages, Unicode is used accepted by the universal standards and represent data in different languages. It was designed for the purpose of representing almost all the languages in computers. The Unicode has different versions like UTF – 8, UTF – 16, UTF – 32.
In this, the numbers in UTF like 8 as 8 bits known as an octet, 16 as 2 – octets, and 32 as 4 – octets representation.
The document Encoding Schemes | Computer Science for Class 11 - Humanities/Arts is a part of the Humanities/Arts Course Computer Science for Class 11.
All you need of Humanities/Arts at this link: Humanities/Arts
|
20 videos|20 docs|5 tests
|
Related Exams
About this Document

|
4.60/5 Rating |

|
Dec 23, 2024 Last updated |
Document Description: Encoding Schemes for Humanities/Arts 2024 is part of Computer Science for Class 11 preparation.
The notes and questions for Encoding Schemes have been prepared according to the Humanities/Arts exam syllabus. Information about Encoding Schemes covers topics
like and Encoding Schemes Example, for Humanities/Arts 2024 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Encoding Schemes.
Introduction of Encoding Schemes in English is available as part of our Computer Science for Class 11
for Humanities/Arts & Encoding Schemes in Hindi for Computer Science for Class 11 course.
Download more important topics related with notes, lectures and mock test series for Humanities/Arts
Exam by signing up for free. Humanities/Arts: Encoding Schemes | Computer Science for Class 11 - Humanities/Arts
Description
Full syllabus notes, lecture & questions for Encoding Schemes | Computer Science for Class 11 - Humanities/Arts - Humanities/Arts | Plus excerises question with solution to help you revise complete syllabus for Computer Science for Class 11 | Best notes, free PDF download
Information about Encoding Schemes
In this doc you can find the meaning of Encoding Schemes defined & explained in the simplest way possible. Besides explaining types of
Encoding Schemes theory, EduRev gives you an ample number of questions to practice Encoding Schemes tests, examples and also practice Humanities/Arts
tests

|
Explore Courses for Humanities/Arts exam
|
|
Signup for Free!
Signup to see your scores go up within 7 days! Learn & Practice with 1000+ FREE Notes, Videos & Tests.
Related Searches
Sample Paper
,Semester Notes
,Summary
,Viva Questions
,Important questions
,mock tests for examination
,MCQs
,shortcuts and tricks
,Objective type Questions
,Extra Questions
,video lectures
,Encoding Schemes | Computer Science for Class 11 - Humanities/Arts
,past year papers
,Free
,Previous Year Questions with Solutions
,study material
,ppt
,Encoding Schemes | Computer Science for Class 11 - Humanities/Arts
,Exam
,practice quizzes
,Encoding Schemes | Computer Science for Class 11 - Humanities/Arts
;






Additional Information about Encoding Schemes for Humanities/Arts Preparation
Encoding Schemes Free PDF Download
The Encoding Schemes is an invaluable resource that delves deep into the core of the Humanities/Arts exam.
These study notes are curated by experts and cover all the essential topics and concepts, making your preparation more efficient and effective.
With the help of these notes, you can grasp complex subjects quickly, revise important points easily,
and reinforce your understanding of key concepts. The study notes are presented in a concise and easy-to-understand manner,
allowing you to optimize your learning process. Whether you're looking for best-recommended books, sample papers, study material,
or toppers' notes, this PDF has got you covered. Download the Encoding Schemes now and kickstart your journey towards success in the Humanities/Arts exam.
Importance of Encoding Schemes
The importance of Encoding Schemes cannot be overstated, especially for Humanities/Arts aspirants.
This document holds the key to success in the Humanities/Arts exam.
It offers a detailed understanding of the concept, providing invaluable insights into the topic.
By knowing the concepts well in advance, students can plan their preparation effectively.
Utilize this indispensable guide for a well-rounded preparation and achieve your desired results.
Encoding Schemes Notes
Encoding Schemes Notes offer in-depth insights into the specific topic to help you master it with ease.
This comprehensive document covers all aspects related to Encoding Schemes.
It includes detailed information about the exam syllabus, recommended books, and study materials for a well-rounded preparation.
Practice papers and question papers enable you to assess your progress effectively.
Additionally, the paper analysis provides valuable tips for tackling the exam strategically.
Access to Toppers' notes gives you an edge in understanding complex concepts.
Whether you're a beginner or aiming for advanced proficiency, Encoding Schemes Notes on EduRev are your ultimate resource for success.
Encoding Schemes Humanities/Arts Questions
The "Encoding Schemes Humanities/Arts Questions" guide is a valuable resource for all aspiring students preparing for the
Humanities/Arts exam. It focuses on providing a wide range of practice questions to help students gauge
their understanding of the exam topics. These questions cover the entire syllabus, ensuring comprehensive preparation.
The guide includes previous years' question papers for students to familiarize themselves with the exam's format and difficulty level.
Additionally, it offers subject-specific question banks, allowing students to focus on weak areas and improve their performance.
Study Encoding Schemes on the App
Students of Humanities/Arts can study Encoding Schemes alongwith tests & analysis from the EduRev app,
which will help them while preparing for their exam. Apart from the Encoding Schemes,
students can also utilize the EduRev App for other study materials such as previous year question papers, syllabus, important questions, etc.
The EduRev App will make your learning easier as you can access it from anywhere you want.
The content of Encoding Schemes is prepared as per the latest Humanities/Arts syllabus.
|
© EduRev
|
Education Revolution
|



|





Signup to see your scores
go up within 7 days!
Access 1000+ FREE Docs, Videos and Tests
Takes less than 10 seconds to signup