Introduction: Statistics | Mathematics (Maths) Class 11 - Commerce PDF Download

Statistics is the Science of collection, organization, presentation, analysis and interpretation of the numerical data.
Useful Terms
1. Limit of the Class
The starting and end values of each class are called Lower and Upper limit.
2. Class Interval
The difference between upper and lower boundary of a class is called class interval or size of the class.
3. Primary and Secondary Data
The data collected by the investigator himself is known as the primary data, while the data collected by a person, other than the investigator is known as the secondary data.
4. Variable or Variate
A characteristics that varies in magnitude from observation to observation. e.g., weight, height, income, age, etc, are variables.
5. Frequency
The number of times an observation occurs in the given data, is called the frequency of the observation.
6. Discrete Frequency Distribution
A frequency distribution is called a discrete frequency distribution, if data are presented in such a way that exact measurements of the units are clearly shown.
7. Continuous Frequency Distribution
A frequency distribution in which data are arranged in classes groups which are not exactly measurable.
Cumulative Frequency Distribution
Suppose the frequencies are grouped frequencies or class frequencies. If however, the frequency of the first class is added to that of the second and this sum is added to that of the third and so on, then the frequencies, so obtained are known as cumulative frequencies (cf).
Graphical Representation of Frequency Distributions
(i) Histogram To draw the histogram of a given continuous frequency distribution, we first mark off all the class intervals along X-axis on a suitable scale. On each of these class intervals on the horizontal axis, we erect (vertical) a rectangle whose height is proportional to the frequency of that particular class, so that the area of the rectangle is proportional to the frequency of the class.
If however the classes are of unequal width, then the height of the rectangles will be proportional to the ratio of the frequencies to the width of the classes.
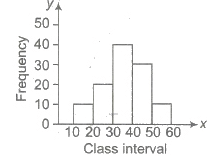
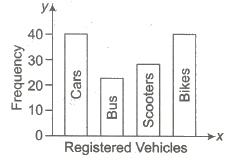
(ii) Bar Diagrams In bar diagrams, only the length of the bars are taken into consideration. To draw a bar diagram, we first mark equal lengths for the different classes on the axis, i.e., X-axis.
On each of these lengths on the horizontal axis, we erect (vertical) a rectangle whose heights is proportional to the frequency of the class.
(iii) Pie Diagrams Pie diagrams are used to represent a relative frequency distribution. A pie diagram consists of a circle divided into as many sectors as there are classes in a frequency distribution.
The area of each sector is proportional to the relative frequency of the class. Now, we make angles at the centre proportional to the relative frequencies.
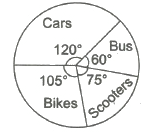
And in order to get the angles of the desired sectors, we divide 360° in the proportion of the various relative frequencies. That is,
Central angle = [Frequency x 360° / Total frequency]
(iv) Frequency Polygon To draw the frequency polygon of an ungrouped frequency distribution, we plot the points with abscissae as the variate values and the ordinate as the corresponding frequencies. These plotted points are joined by straight lines to obtain the frequency polygon.
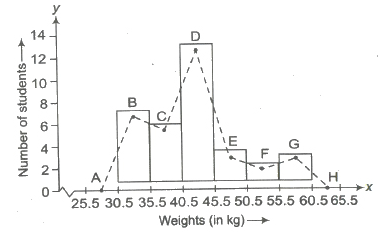
(v) Cumulative Frequency Curve (Ogive) Ogive is the graphical representation of the cumulative frequency distribution. There are two methods of constructing an Ogive, viz (i) the ‘less than’ method (ii) the ‘more than’ method.
Important Points to be Remembered
(i) The ratio of SD (σ) and the AM (x) is called the coefficient of standard deviation (σ / x).
(ii) The percentage form of coefficient of SD i.e., (σ / x) * 100 is called coefficient of variation.
(iii) The distribution for which the coefficient of variation is less is called more consistent.
(iv) Standard deviation of first n natural numbers is √n2 – 1 / 12
(v) Standard deviation is independent of change of origin, but it is depend on change of scale.
Root Mean Square Deviation (RMS)
The square root of the AM of squares of the deviations from an assumed mean is called the root mean square deviation. Thus,
(i) For simple (discrete) distribution
S = √Σ (x – A’)2 / n, A’ = assumed mean
(ii) For frequency distribution
S = √Σ f (x – A’)2 / Σ f
if A’ — A (mean), then S = σ
Important Points to be Remembered
(i) The RMS deviation is the least when measured from AM.
(ii) The sum of the squares of the deviation of the values of the variables is the least when measured from AM.
(iii) σ2 + A2 = Σ fx2 / Σ f
(iv) For discrete distribution f =1, thus σ2 + A2 = Σ x2 / n.
(v) The mean deviation about the mean is less than or equal to the SD. i.e., MD ≤ σ
Correlation
The tendency of simultaneous variation between two variables is called correlation or covariance. It denotes the degree of inter-dependence between variables.
1. Perfect Correlation
If the two variables vary in such a manner that their ratio is always constant, then the correlation is said to be perfect.
2. Positive or Direct Correlation
If an increase or decrease in one variable corresponds to an increase or decrease in the other, then the correlation is said to the negative.
3. Negative or Indirect Correlation
If an increase of decrease in one variable corresponds to a decrease or increase in the other, then correlation is said to be negative.
Covariance
Let (xi, yi), i = 1, 2, 3, , n be a bivariate distribution where x1, x2,…, xn are the values of variable x and y1, y2,…, yn those as y, then the cov (x, y) is given by
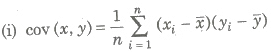
where, x and y are mean of variables x and y.
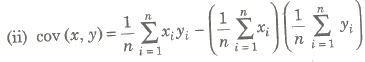
Karl Pearson’s Coefficient of Correlation
The correlation coefficient r(x, y) between the variable x and y is given
r(x, y) = cov(x, y) / √var (x) var (y) or cov (x, y) / σx σy
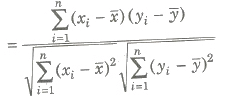
If (xi, yi), i = 1, 2, … , n is the bivariate distribution, then

Properties of Correlation
(i) – 1 ≤ r ≤ 1
(ii) If r = 1, the coefficient of correlation is perfectly positive.
(iii) If r = – 1, the correlation is perfectly negative.
(iv) The coefficient of correlation is independent of the change in origin and scale.
(v) If -1 < r < 1, it indicates the degree of linear relationship between x and y, whereas its sign tells about the direction of relationship.
(vi) If x and y are two independent variables, r = 0
(vii) If r = 0, x and y are said to be uncorrelated. It does not imply that the two variates are independent.
(viii) If x and y are random variables and a, b, c and d are any numbers such that a ≠ 0, c ≠ 0, then
r(ax + b, cy + d) = |ac| / ac r(x, y)
(ix) Rank Correlation (Spearman’s) Let d be the difference between paired ranks and n be the number of items ranked. The coefficient of rank correlation is given by
ρ = 1 – Σd2 / n(n2 – 1)
(a) The rank correlation coefficient lies between – 1 and 1.
(b) If two variables are correlated, then points in the scatter diagram generally cluster around a curve which we call the curve of regression.
(x) Probable Error and Standard Error If r is the correlation coefficient in a sample of n pairs of observations, then it standard error is given by
1 – r2 / √n
And the probable error of correlation coefficient is given by (0.6745) (1 – r2 / √n).
Regression
The term regression means stepping back towards the average.
Lines of Regression
The line of regression is the line which gives the best estimate to the value of one variable for any specific value of the other variable. Therefore, the line of regression is the line of best fit and is obtained by the principle of least squares.
Regression Analysis
(i) Line of regression of y on x,
y — y = r σy / σx (x – x)
(ii) Line of regression of x and y,
x – x = r σx / σy (y — y)
(iii) Regression coefficient of y on x and x on y is denoted by
byx = r σy / σx, byx = cov (x, y) / σ2x and byx = r σx / σy, bxy = cov (x, y) / σ2y
(iv) Angle between two regression lines is given by
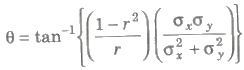
(a) If r = 0, θ = π / 2 , i.e., two regression lines are perpendicular to each other.
(b) If r = 1 or — 1, θ = 0, so the regression lines coincide.
Properties of the Regression Coefficients
(i) Both regression coefficients and r have the same sign.
(ii) Coefficient of correlation is the geometric mean between the regression coefficients.
(iii) 0 < |bxy byx| le; 1, if r ≠ 0
i.e., if |bxy|> 1, then | byx| < 1
(iv) Regression coefficients are independent of the change of origin but not of scale.
(v) If two regression coefficient have different sign, then r = 0.
(vi) Arithmetic mean of the regression coefficients is greater than the correlation coefficient.
|
73 videos|264 docs|91 tests
|
FAQs on Introduction: Statistics - Mathematics (Maths) Class 11 - Commerce
| 1. What is statistics and why is it important? |  |
| 2. How is statistics used in research? | |
| 3. What are the different types of statistical analysis methods? | |
| 4. How can statistics be misused or misrepresented? | |
| 5. What are some practical applications of statistics in everyday life? | |




Introduction: Statistics | Mathematics (Maths) Class 11 - Commerce
,Summary
,Viva Questions
,past year papers
,ppt
,Extra Questions
,study material
,Important questions
,Introduction: Statistics | Mathematics (Maths) Class 11 - Commerce
,Free
,Introduction: Statistics | Mathematics (Maths) Class 11 - Commerce
,Exam
,Previous Year Questions with Solutions
,practice quizzes
,Sample Paper
,Objective type Questions
,Semester Notes
,video lectures
,mock tests for examination
,MCQs
,shortcuts and tricks
;


Introduction: Statistics Free PDF Download
Importance of Introduction: Statistics
Introduction: Statistics Notes
Introduction: Statistics Commerce Questions
Study Introduction: Statistics on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!