Nucleic Acids (DNA & RNA) | Biology for ACT PDF Download

DNA :
Discovered by – Meischer
DNA term given by – Zacharis
In DNA pentose sugar is deoxyribose sugar and four types of nitrogen bases A, T, G, C
Wilkins and Franklin studied DNA molecule with the help of X-Ray crystallography.
With the help of this study, Watson and Crick (1953) proposed a double helix molel for DNA. For this model Watson, Crick and Wilkins were awarded by noble prize in 1962.
According to this model, DNA is composed of two polynucleotide chains.
Both polynucleotide chains are complementary and antiparallel to each other.
In both strand of DNA direction of phosphodiester bond is opposite. i.e. If direction of phosphodiester bond in one strand is 5'-3' then it is 3'-5' in another strand.
Both strand of DNA held together by Hydrogen bonds. These hydrogen bond are present between Nitrogen bases of both strand.
Adenine binds to Thymine by two hydrogen bonds and cytosine binds to Guanine by three hydrogen bonds.
chargaff's equivalency rule – In a double stranded DNA amount of purine nucleotides is equal to amount of pyrimidine nucleotides.
Purine = Pyrimidine
[A] + [G] = [T] + [C]
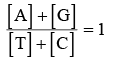
Base ratio =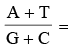 constant for a given species.
constant for a given species.
In a DNA A + T > G + C ⇒ A – T type DNA. Base ratio of A – T type of DNA is more than one. eg. Eucaryotic DNA
In a DNA G + C > A + T ⇒ G – C type DNA. Base ratio of G –C type of DNA is less than one. eg. Procaryotic DNA
Melting point of DNA depends on G – C contents.
More G – C contents then more Melting point.
Tm = Temperature of melting.
Tm = of prokaryotic DNA > Tm of Eucaryotic DNA
DNA absorbs U.V. rays means 2600Å wavelength.
Out of two strand of DNA only one strand participates in transcription, it is called Antisense strand/ Non coding strand/Template strand.
Other strand of DNA which does not participate in transcription is called sense strand/Coding strand.
Denaturation and renaturation of DNA – If a normal DNA molecule is placed at high temperature
(80 – 90°C) then both strand of DNA will separate to each other due to breaking of hydrogen bonds. It is called DNA-denaturation.
When denatured DNA molecule is placed at normal temperature then both strand of DNA attached and recoiled to each other. It is called Renaturation of DNA.
Hyperchromicity – When a double stranded DNA is denatured by heating then denatured DNA molecule absorbs more amount of light, this phenomenon is called hyperchromicity.
Hypochromicity – When denatured DNA molecule cool slowly then it becomes double stranded and it absorb less amount of light. This phenomenon is called hypochromicity.
Configuration of DNA Molecule –
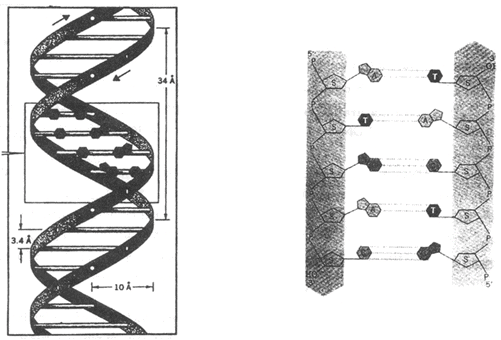
- Two strands of DNA are helically coiled like a revolving ladder. Back bone of this ladder (Reiling) is composed of phosphates and sugars while steps (bars) composed of pairs of nitrogen bases.
- Distance between two successive steps is 3.4Å. In one complete turn of DNA molecule there are such 10 steps (10 pairs of nitrogen bases.) So the length of one complete turn is 34Å. This is called helix length.
- Diameter of DNA molecule i.e. distance between phosphates of two strands is 20Å.
- Distance between sugar of two strands is 11.1 Å.
- Length of hydrogen bonds between nitrogen bases is 2.8-3.0 Å. Angle between nitrogen base and C1 Carbon of pentose is 51°.
- Molecular weight of DNA is 106 to 109 dalton.
- In nucleus of eukaryotes the DNA is associated with histone protein to form nucleoprotein. Histone occupies major groove of DNA at 30° angle.
- Bond between DNA and Histone is salt linkage (Mg+2).
- DNA in chromosomes is linear while in prokaryotes, mitochondria and chloroplast is circular.
- In φ × 174 bacteriophage the DNA is single stranded and circular isolated by Sinsheimer.
G–4, S–13, M–13, F1 and Fd–Bacteriophages also contain ss–circular DNA.
Types of DNA
On the basis of direction of twisting, there are two types of DNA.
1. Right Handed DNA –
Clockwise twisting e.g. The DNA for which Watson and Crick proposed model was 'B' DNA.
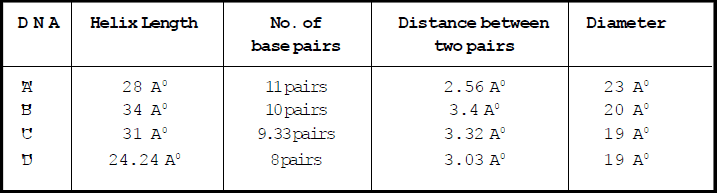
2. Left handed DNA –
Anticlockwise twisting e.g. Z-DNA-discovered by Rich. Phosphate and sugar backbone is zig-zag. Units of Z-DNA are dinucleotides (Purine and pyrimidine in alternate order )
Helix length – 45.6 Å
Diameter – 18.4 Å
No. of Base pairs – 12 (6 dimers)
Distance between base – pairs – 3.75 Å
Palindromic DNA – Wilson and Thomas
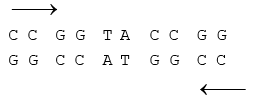
Sequence of nucleotides same from both ends.
Special Points :
DNA molecule is Dextrorotatory while RNA molecule is Laevorotatory.
C–value = Total amount of DNA in a haploid genome of organism.
D.N.A REPLICATION :
D.N.A. is the only molecule capable of self duplication so it is termed as a ''Living molecule''
All living beings have the capacity to reproduce because of this characteristic of D.N.A.
D.N.A replication takes place in '''S - Phase'' of the cell cycle. At the time of cell division, it divides in equal parts in the daughter cells. Delbruck suggested three methods of DNA-replication i.e.
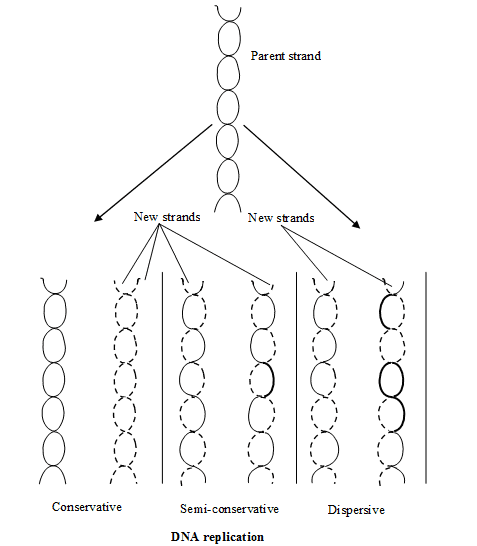
(1) Dispersive
(2) Conservative
(3) Semi-conservative
SEMI CONSERVATIVE MODE OF D.N.A. REPLICATION :
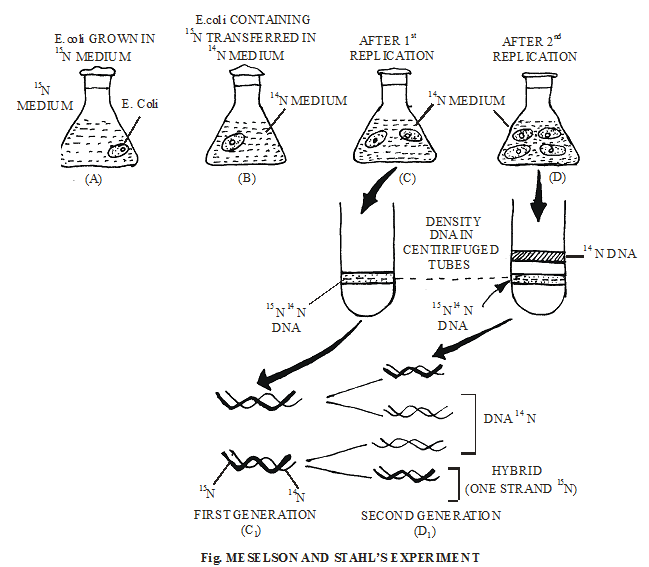
Semi conservative mode of D.N.A. replication was first theoritically proposed by Watson & Crick. Later on it was experimentally proved by Meselson & Stahl (1958) on E-Coli and Taylor on Vicia faba. To prove this method , they used Radiotracer Technique in which Radioisotops are used. Meselson and Stahl used N15 and Cairns (1963) used radioactive Thymidine (with H3).
Due to the replication of active Thymidine containing D.N.A., two D.N.A. molecules were obtained in which 50% radioactivity was found.
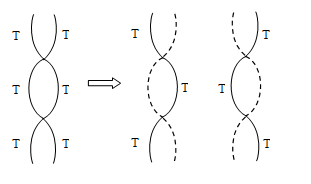
When these two D.N.A. molecules containing active Thymidine were made to replicate, the next time four D.N.A. molecules were obtained. Out of these 4 D.N.A., 2 D.N.A. molecules were radioactive and remaining 2 were not radioactive.
In the same sequence, the obtained D.N.A. molecules were further made to replicate then also, the no. of radioactive D.N.A remains 2.
MECHANISM OF D.N.A. REPLICATION :
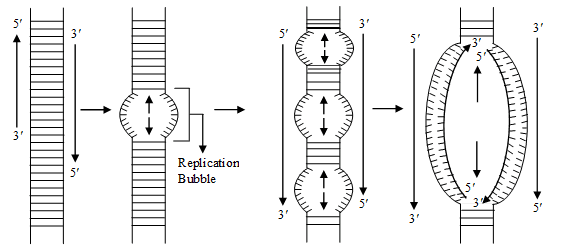
The following steps are included in D.N.A replication –
(1) Unzipping E The separation of 2 chains of D.N.A. is termed as unzipping and it takes place due to the braking of H bonds. The process of unzipping starts at a certain specific point which is termed as initiation point or origin of replication . In procaryotes there occur only one origin of replication but in eucaryotes there occur
many origin of replication i.e. unzipping starts at many points simultaneously.
The enzyme responsible for unzipping (breaking the hydrogen bonds) is Helicase (= Swivelase). In the process of unzipping Mg+2 act as cofactor. Unzipping takes place in alkaline medium.
At the place of origin, the topoisomerase enzyme (a type of endonuclease) induces a cut in one strand of DNA (Nicking) to relax the two strands of DNA.
A protein, ''Helix destabilizing protein'' prevents recoiling of two separated strands during the process of replication. An another protein SSB (single stranded DNA binding protein) prevents the formation of bends of loops in separated strands.
DNA-Gyrase – A type of topoisomerase prevent supercoiling of DNA.
Note –
The process of D.N.A replication takes a few minutes in prokaryotes and few hours in Eukaryotes.
(2) Formation of New Chain –
To start the synthesis of new chain, special type of R.N.A. is required which is termed as R.N.A Primer. The formation of R.N.A. primer is catalysed by an enzyme – R.N.A. Polymerase (primase) Synthesis of RNA – primer takes place in 5' ® 3'' direction. After the formation of new chain, this R.N.A. is removed. For the formation of new chain Nucleotides are obtained from Nucleoplasm. In the nucleoplasm, Nucleotides are present in the form of triphosphate like dATP, dGTP, dCTP, dTTP etc.
During replication, the 2 phosphate groups of all Nucleotides are separated. In this process energy is yielded which is consumed in D.N.A replication. So, it is clear that D.N.A. does not depend on mitochondria for it's energy requirements.
The formation of new chain always takes place in 5' - 3'' direction. As a result of this, one chain of D.N.A is continuously formed and it is termed as Leading strand. The formation of second chain begins from the centre and not from the terminal points, so this chain is discontinuous and is made up of small segement called Okazaki Fragments. This discontinous chain is termed as Lagging strand. Ultimately all these segments joined together and complete new chain is formed.
The Okazaki segment are joined together by an enzyme DNA Ligase. (Khorana)
The formation of new chains is catalysed by an enzyme DNA polymerase. In prokaryotes it is of 3 types :
(1) DNA - Polymerase I : This was discovered by KORNBERG (1957). So it is also called as ' Kornberg 's enzyme'. Kornberg also synthesized DNA first of all, in the laboratory. This enzyme functions
as exonuclease. It separates RNA – primer from DNA and also fills the gap. It is also known as
DNA- repair enzyme.
(2) DNA - Polymerase II : It is least reactive in replication process. It is also helpful in DNA-repairing in absence of DNA-polymerase-I and DNA polymerase-III
(3) DNA - Polymerase III : This is the main enzyme in DNA – Replication . It is most important. It was discovered by Delucia and Cairns. The larger chains are formed by this enzyme. This is also known as Replicase.
DNA – polymerase III is a complex enzyme composed of seven polypeptides a, e, q, b, g, d, g2.
In Eucaryotes, there occur five types of DNA-polymerase enzyme.
(i) a-DNA – polymerase = Similar to DNA – polymerase I
(ii) b-DNA – polymerase = It concerned with DNA repair.
(iii) g-DNA – polymerase = It concerned with replication of cytoplasmic DNA
(iv) d-DNA – polymerase = Similar to DNA – polymerase II
(v) e-DNA – polymerase = Similar to DNA – polymerase III
Thus DNA – Replication process is completed with the effect of different enzymes.
In the semi conservative mode of replication each daughter DNA molecule receives one chain of polynucleotides from the mother DNA – molecule and the second chain is synthesized.
Special Point :
All DNA polymerase I, II and III enzymes have 5'-3'' polymerisation activity and 3'-5'' exonuclease activity.
RIBO NUCLEIC ACID (RNA) :
Structure of RNA is fundamentally the same as DNA, but there are some differences. The differences are as follows .:
(1) In place of De – Oxyribose sugar of DNA, there is present Ribose sugar in RNA.
(2) In place of nitrogen base Thymine present in DNA, there is nitrogen base uracil in RNA.
(3) RNA is made up of only one polynucleotide chain i.e. R.N.A. is Single stranded.
Exception –
RNA found in Reo – virus is double stranded, i.e. it has two polynucleotide chains.
Types of RNA :
1. Genetic RNA or Genomic RNA - In the absence of DNA, sometime RNA working as genetic material and genomic RNA transfer informations from one generation to next generation.
eg. Reo virus, TMV, QB bacteriophage.
Non-genetic RNA - 3 types –
(A) r- RNA (B) t – RNA (C) m – RNA
(1) Ribosomal RNA (r - RNA) :
This RNA is 80% of the cell's total RNA
It is found in ribosomes and it is produced in nucleolus.
It is the most stable form of RNA.
There are present 80s type of ribosomes in Eukaryotic cells. Their subunits are 60s and 40s . In 60s sub unit of ribosome three type of r-RNA are found – 5s, 5.8s, 28s
In the same way 40s sub unit of ribosome has only one type of r-RNA = 18s.
So 80s ribosome has total 4 types of r-RNA.
prokaryotic cells have 70s type of ribosomes and its subunits are 50s and 30s.
50s sub unit of ribosome contains 2 molecules of r-RNA = 5s and 23s.
30s sub unit of ribosome has 16s type of r-RNA.
So 70s RNA has total 3 types of r-RNA.
Functions –
At the time of protein synthesis r-RNA provides attachment site to t-RNA and m-RNA and attaches them on the Ribosome.
The bonds formed between them are known as Salt linkages. It attaches t-RNA to the larger subunit on the Ribosome and m - RNA to smaller sub-unit of ribosome.
(2) Transfer – RNA (t-RNA) –
It is 10-15% of total RNA.
It is synthesized in the nucleus by DNA.
It is also known as soluble RNA (sRNA)
It is also known as Adapter RNA.
It is the smallest RNA (4s).
Function - At the time of protein synthesis it acts as a carrier of amino-acids.
Discovery – t-RNA was discovered by Hogland, zemecknike and Stephenson.
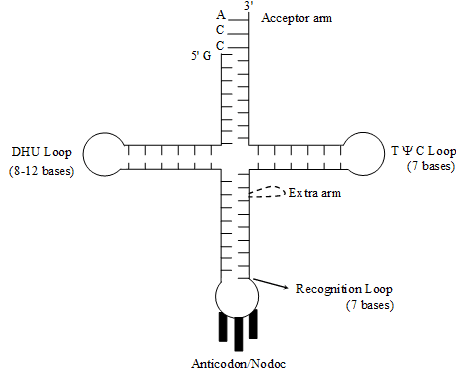
Structure – The structure of t-RNA is most complicated.
A scientist named Holley presented Clover leaf model of its structure. In two dimensional structure the
t-RNA appears clover leaf like but in three dimensional structure (by Kim) it appears L-shaped.
The molecule of t-RNA is of single strand.
There are present three nucleotides in a particular sequence at 3' end of t RNA and that sequence is = CCA.
All the 5' ends i.e. last ends are having G(guanine).
3' end is known as Acceptor end.
t-RNA accepts amino acids at acceptor points. Amino acids binds to 3' end by its –COOH group.
The molecule of t-RNA is folded and due to folding some complementary nitrogenous bases comes across with each other and form hydrogen bonds.
There are some places where hydrogen bonds are not formed, these places are known as loop.
Loops –
There are some abnormal nitrogenous bases in the loops, that is why hydrogen bonds are not formed.
e.g. Inosine (I) Pseudouracil (ψ) Dihydrouridine (DHU)
(i) T ψ C Loop or Attachment loop –
This loop connects t-RNA to the larger subunit of ribosome.
(ii) Recognition Loop –
E This is the most specific loop of t-RNA and different types of t-RNA are different due to this loop. There is a specific sequence of three nucleotides called Anticodon, is present at the end of this loop.
On the basis of Anticodon, there are total 61 types of t-RNA, or, we can also say that there are 61 types of Anticodon.
t-RNA recognizes its place on m-RNA with the help of Anticodon.
The anticodon of t-RNA recognizes its complementary sequence on m-RNA. This complimentary sequence is known as codon.
(iii) DHU Loop –
It is also known as Amino-acyl synthetase recognition loop. Amino-acyl synthetase is a specific type of enzyme. The function of this enzyme is to activate a specific type of amino acid. After activation this enzyme attaches the aminoacid to the 3' end of t-RNA.
There are 20 types of enzymes for 20 types of aminoacids.
The function of DHU loop is to recognize this specific Aminoacyl synthetase enzyme.
(3) Messenger RNA (m-RNA) -
The m-RNA is 1-5% of the cell's total RNA.
Discovery – Messenger RNA was discovered by Huxley, Volkin and Astrachan. The name m-RNA was given by Jacob and Monad.
The m-RNA is produced by genetic DNA in the nucleus. This process is known as Transription.
TRANSCRIPTION :
Formation of RNA over DNA templet is called transcription. Out of two strand of DNA only one strand participates in transcription and called ''Antisense strand''.
The segment of DNA involved in transcription is ''Cistron''.
RNA polymerase enzyme involved in transcription. In eukaryotes there are three types of RNA polymerases.
· RNA polymerase-I for 28s rRNA, 18s RNA, 5.8s rRNA
· RNA polymerase-II for m-RNA.
· RNA polymerase enzyme-III for t-RNA, 5s RNA, SnRNA
In eukaryotes RNA polymerase enzyme composed of 10-15 polypeptide chains.
Prokaryotes have one type of RNA polymerase which synthesizes all types of RNAs.
RNA polymerase of E. Coli has six polypeptide chains β, β', α, α and σ .
s polypeptide chain is also known as s factor (sigma factor).
Core enzyme + Sigma factor ⇒ RNA Polymerase
(β, β', α, α) + (σ)
Following steps are present in transcription –
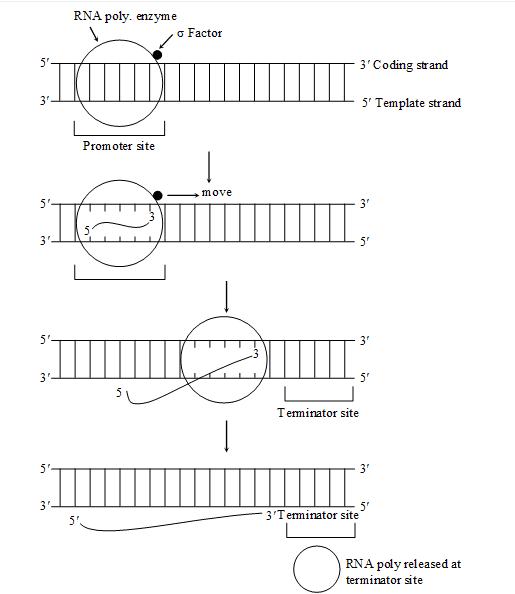
(1) INITIATION –
DNA has a ''Promoter site or initiation site'' where transcription begins and a ''Terminator site'' where transcription stops.
Sigma factor (s) recognizes the promoter site of DNA.
With the help of sigma factor RNA polymerase attached to a specific site of DNA called ''Promoter site'' .
In prokaryotes before the 10 N2 base from ''Structural site'' a sequence of 6 base pairs (TATAAT) is present on DNA, Which is called ''Pribnow box''.
In eukaryotes before the 20 N2 base from ''Structural site'' a sequence of 7 base pairs (TATAAA) or (TATATAT) is present on DNA which is called ''TATA box or Hogness box''
At promoter site RNA polymerase enzyme breaks H-bonds between two DNA strands and separates them One of them strand takes part in Transcription. Transcription proceeds in 5' ® 3'' direction.
Ribonucleotide triphosphate come to lie opposite complementary nitrogen bases of anti sense strand.
These Ribonucleotides present in the form of triphosphate ATP, GTP, UTP and CTP in nucleoplasm. When they used in transcription, pyrophosphates hydrolyse two phosphates from each activated nucleotide. This releases energy.
This energy used in process of transcription.
(2) ELONGATION –
RNA polymerase enzyme establishes phosphodiester bond between adjacent ribonucleotides.
Sigma factor separates and core enzyme moves along the anti sense strand till it reaches terminator site.
(3) TERMINATION –
When RNA polymerase enzyme reaches at terminator site, it separates from DNA templet.
In terminator site on DNA, N2 bases are present in palindromic sequence.
In most cases RNA polymerase enzyme can recognize the ''Terminator site'' and stop the synthesis of RNA chain, but in prokaryotes, it recognizes the terminator site with the help of Rho factor (r factor).
Rho (r) factor is a specific protein which helps RNA polymerase enzyme to recognize the terminator site.
PROTEIN-SYNTHESIS :
- Activation of Amino acid –
20 types of amino acid participate in protein synthesis.
Amino acid reacts with ATP to form ''Amino acyl AMP enzyme complex'', which is also known as 'Activated Amino acid.'
This reaction is catalyzed by a specific 'Amino acyl t-RNA synthetas' enzyme
There is a separate 'Amino acyl t-RNA synthetase' enzyme for each kind of amino acid.
(2) Charging of t-RNA –
Specific activated amino acid is recognized by its specific t-RNA.
Now amino acid attaches to the 'Amino acid attachment site' of its specific t-RNA and AMP and enzyme are separated from it.
Amino acyl t-RNA complex is also called 'Charged t-RNA'
Now Amino acyl t-RNA moves to the ribosome for protein synthesis
(3) Translation :
(A) Initiation of polypeptide chain
In this step 30 's' and 50 's' sub units of Ribosome, GTP, Mg+2, charged t-RNA, m-RNA and some
initiation factors are required
In prokaryotes there are three initiation factors present – IF1, IF2, IF3
In Eukaryotes there are more than 3 initiation factors are present. 16 initiation factors have been identified in red blood cells–
elF1, elF2, elF3, elF4A, elF4B, elF4C, elF4D, elF4F, elF5, elF6
Initiation factors are specific protein.
GTP and initiation factors promote the initiation process.
In starting the both sub units of ribosome are separated with the help of IF3 factor.
In prokaryotes with the help of "S D sequences" (Shine-Delgarno sequence) m-RNA recognizes the smaller sub unit of ribosome. A sequence of 8 N2 base is present before the 4-12 N2 base of initiation Condon on mRNA, called "SD sequence" In smaller subunit of ribosome, a complementary sequence of "SD sequence" is present on 16 'S' rRNA, which is called "Anti Shine-delgarno sequence"
(ASD sequence)
With the help of 'SD' and 'ASD' sequence m-RNA recognizes the smaller sub unit of ribosome.
While in Eukaryotes smaller sub unit of ribosome is recognised by "7mG cap"
In Eukaryotes, 18 'S' rRNA of smaller sub unit has a complementary sequence of "7mG cap"
This "30 'S' m–RNA – complex" reacts with 'Formyl methionyl t-RNA–complex' and "30 'S' mRNA –Formyl methionyl t-RNA–complex" form. This t–RNA attaches with codon part of m–RNA. A GTP molecule is required.
Now larger sub unit of ribosome (50'S' Sub unit) joins this complex. The initiation factor released and complete 70 'S' ribosome is formed.
In larger sub unit of ribosome there are three sites for t-RNA
'P' site = Peptidyl site
'A' site = amino acyl site
E-site = exit site
Starting codon of m-RNA is near to 'P' site of ribosome, so t-RNA with formyl methionine amino acid first attached to 'P' site of ribosome and next codon of m-RNA is near to 'A' site of ribosome. So new t-RNA with new amino acid always attach at 'A' site of ribosome but in initiation step 'A' site is empty
(B) Chain elongation
New tRNA with new Amino acid at 'A' site of Ribosome.
First of all t-RNA of P-site is discharged so-COOH of p-site A.A. becomes free.
Now peptide bond formation takes place between –COOH group of P site amino acid and –NH2 group of A site amino acid.
Peptidyl transferase enzyme induces the formation of peptide bond. In Peptide bond formation, a
23 'S' r-RNA, 28 'S' r-RNA in eukaryotes is also helpful. This r-RNA acylt acts as an enzyme so it is also called "Ribozyme"
After formation of peptide bond t-RNA of P site released from ribosome via E-site and dipeptide attaches with A site.
Now t-RNA of A site is transferred to P site and A site becomes emplty.
Now ribosome slides over m-RNA strand in 5' ® 3" direction. Due to sliding of ribosome on m-RNA, new condon of m–RNA continously available at A site of ribosome and according to new codon of
m-RNA new amino acid attaches in polypeptide chain.
Translocase enzyme helpful in movement of ribosome. GTP provides energy for sliding of ribosome.
In elongation process some protein factors are also helpful, which known as 'Elongation factors'
In prokaryotes three 'Elongation factors' are present –EF – Tu, EF – Ts, EF – G.
In Eukaryotes two elongation factors are present–eEF1, eEF2.
(C) Chain – Termination
Due to sliding of ribosome over m–RNA when any Nonsense codon (UAA, UAG, UGA) available at A site of ribosome, then polypeptide chain terminate.
The linkage between the last t-RNA and the polypeptide chain is broken by three release factor called RF1, RF2, RF3 with the help of GTP.
Peptidyl transferase enzyme also catalysed the releasing process.
In eukaryotes only one Release factor is known – eRF1.
GENETIC CODE :
Term Given by George Gamow.
E The relationship between the sequence of amino acids in a polypeptide chain and nucleotide sequence of DNA or m-RNA is called genetic code.
E There occur 20 types of amino acids which participate in protein synthesis. DNA contains information for the synthesis of any types of polypeptide chain. In the process of transcription, information transfer from DNA to m-RNA in the form of complementary N2-base sequence.
E m-RNA contains code for each amino acid and it is called codon. A codon is the nucleotide sequence in
m-RNA which codes for particular amino acid ; wherease the genetic code is the sequence of nucleotides in m-RNA molecule, which contains information for the synthesis of polypeptide chain.
Triplet Code –
E The main problem of genetic code was to determine the exact number of nucleotide in a codon which codes for one amino acid.
E There are four types of N2-bases in m-RNA (A, U, G, C) for 20 type amino acids.
Fig : Triplet codons of mRNA for amino acids represented in tabular form.
E If genetic code is singlet i.e. codon is the combination of only one nitrogen base, then only four codons are possible A, C, G and U. These are insufficient to code for 20 types amino acids.
· Singlet code = 4' = 4 × 1 = 4 codons
· If genetic code is doublet (i.e. codon is the combination of two nitrogen bases) then 16 codons are formed.
· Doublet code = 42 = 4 × 4 = 16 codons.
· 16 codons insufficient for 20 amino acid
Gamow –
(1954) Pointed out the possibility of three letter code (Triplet code).
Genetic code is triplet i.e. one codon consists of three nitrogen base.
Triplet code = 43 = 4 × 4 × 4 = 64 codons
In this case there occurs 64 codons in dictionary of genetic code.
64 codons are sufficient to code 20 types of amino acids.
Characteristic of Genetic Code –
(1) Triplet in Nature
E A codon is composed of three adjacent nitrogen bases which specifies the one amino acid in polypeptide chain.
For Ex. :
· In m-RNA if there are total 90 N2 – bases.
· Then this m-RNA determines 30 amino acids in polypeptide chain.
· In above example, number of Nitrogen bases are 90 so codons Þ 30 and 30 codons decide 30 amino acid in polypeptide chain.
(2) Universality
The genetic code is applicable universally. The same genetic code is present in all kinds of living organism including viruses, bacteria, unicellular and multicellular organism.
(3) Non-Ambiguous –
Genetic code is non ambiguous i.e. one codon specifies only one amino acid and not any other.
In this case one codon never code two different amino acids. Exception GUG codon which code both valine and methionine amino acid.
(4) Non-Overlapping –
A nitrogen base is a constituent of only one codon.
(5) Comma less –
There is no punctuation (comma) between the adjacent codon i.e. each codon is immediately followed by the next codon.
If a nucleotide is deleted or added, the whole genetic code read differently.
A Polypeptide chain having 50 amino acids shall be specialized by a linear sequence of 150 nucleotides. If a nucleotide is added in the middle of this sequence, the first 25 amino acids of polypeptide will be same but next 25 amino acids will be different.
(6) Degeneracy of Genetic code –
There are 64 codons for 20 types of amino acids, so most of the amino acids (except two) can be coded by more than one codon. Single amino acid coded by more than one codon is called ''Degeneracy of genetic code''. This incident was discovered by Baurnfield and Nirenberg.
Only two amino acids Tryptophan and Methionine are specified by single codon.
All the other amino acid are specified or coded by 2 to 6 codons.
Leucine, serine and arginine are coded or specified by 6-codons.
Leucine = CUU, CUC, CUA, CUG, UUA & UUG
Serine = UCU, UCC, UCA, UCG, AGU, AGC
Arginine = CGU, CGC, CGA, CGG, AGA, AGG
Degeneracy of genetic code is related to third position (3' – end of triplet codon). The third base is described as ''Wobby base''
Exception –
Different Codon –
Normally UAA and UGA are chain termination codon but in Paramecium and some other ciliated, UAA and UGA code for glutamine amino acid.
Mitochondrial Gene –
Normally AGG and AGA code for Arginine amino acid but in human mitochondria these function as stop codon.
UGA, a termination codon corresponds to tryptophan while AUA (Codon for isoleucine) denotes methionine in human mitochondria.
Chain Initiation and Chain Termination Codon –
Polypeptide chain synthesis is signalled by two initiation codons AUG or GUG.
AUG codes methionine amino acid in eukaryotes and in prokaryotes AUG codes N-formyl methionine.
Some times GUG also functions as start codon it codes for valine amino acid normally but when it is present at starting position it code for methionine amino acid.
E Out of 64 codons 3-codons are stopping or nonsense or termination codon.
Nonsense codons do not specify any amino acid.
UAA (Ochre)
UAG (Amber) Non-Sense Codon
UGA (Opal)
So only 61 codons are sense codons which specify 20 amino acid.
WOBBLE HYPOTHESIS :
It was propounded by CRICK.
Normally an anticodon recognizes only one codon, but sometimes an anticodon recognise more than one codon. This known as Wobbling. Wobbling normally occurs for third nucleotide of codon.
For e.g. Anticodon AAG can recognize two anticodons i.e. UUU and UUC, both stand for phenyl alanine.
Types of m-RNA – m-RNA is of 2 types –
- Monocistronic – The m- RNA in which genetic signal for the formation of only one polypeptide chain.
(2) Polycistronic – The m-RNA, in which genetic signal is present for the formation of more than one polypeptide chains.
E Non sense codons are found in middle position in polycistronic m-RNA.
CENTRAL DOGMA :
Central dogma term was given by Crick.
The formation (production) of m-RNA from DNA and then synthesis of protein from it, is known as Central Dogma.
It means, it includes transcription and translation.
The central dogma scheme of protein synthesis was presented by Jacob and Monad.
The delailed study of central dogmas is done by Nirenberg, Mathai and Khorana.
Beedle and Tatum studied central dogma in a fungus Neurospora.
Reverse Transcription –
E The formation of DNA from RNA is known as Reverse - transcription. It was discovered by Temin and Baltimore in Rous – sarcoma virus. So it is also called Teminism.
E ss-RNA of Rous-Sarcoma virus (Retro virus) produces ds-DNA in host's cell with the help of enzyme reverse transcriptase (DNA Polymerase). This DNA is called c-DNA (Complimentary DNA). Some times this DNA moves in host genome. Such mobile DNA is called ''Retroposon'' (Oncogene).
SPECIAL POINTS :
(1) The chargraff's rule is not valid (true) for RNA. It is valid only for double helical DNA.
(2) The duplication of DNA was first of all proved in E. coli bacterium.
(3) E. coli Bacterium is mostly used for the study of DNA duplication.
(4) Hargovind singh Khurana first of all recognized the triple codon for Cysteine and Valine amino acids
(5) Cytoplasmic DNA is 1-5% of total cells DNA.
(6) Three lady scientists named Avery, Mc–Leod and Mc Carty (by their transrformation experiments on bacteria) proved that DNA is a genetic material.
(7) Hershey and chase first of all proved that DNA is genetic material in bacteriophages.
(8) Frankel and Conret proved, RNA as a genetic material in viruses (g-RNA).
(9)
(10) The structure formed by the combination of m-RNA and Ribosomes is known as polyribosomes / Polysomes / Ergosomes.
(11) The formation of t-RNA takes place from the heterochromatin part of DNA.
(12) The formation of m-RNA takes place from the Euchromatin part of DNA.
(13) m-RNA is least stable. It is continuosly formed and finished.
(14) In cytoplasm, t-RNA is present in the form of soluble colloid
(15) Nucleases – These breaking enzyme of nucleic acids are of two types.
(i) Endo – Nucleases – These break down the nucleic acids from the inside.
(ii) Exo-nucleases – These break down the nucleic acids from the ends (terminals ends)
These separate each nucleotide
(16) Tay–Sachs–diseases
This disease takes place due to excess storage of glycolipids
(17) Excess storage of cerebrosides leads to Guacher's disease
Some Inhibitors of Bacterial Protein Synthesis
Antibiotic
Effect
Tetracycline
Inhibits binding of amino-acyl tRNA to ribosome
Streptomycin
Inhibits initiation of translation and causes misreading
Chloramphenicol
Inhibits peptidyl transferase and so formation of peptide bonds
Erythromycin
Inhibits translocation of ribosome along mRNA
Neomycin
Inhibits interaction between t-RNA and mRNA
(19) Spilt gene : Discovered by sharp and Roberts in Adenovirus 2 They were awarded by Nobel Prize in 1993. Gene which contains non functional part along with func
|
208 videos|226 docs|136 tests
|
FAQs on Nucleic Acids (DNA & RNA) - Biology for ACT
| 1. What is the structure of DNA? |  |
| 2. How does DNA replicate? | |
| 3. What is the function of RNA? | |
| 4. How does RNA differ from DNA? | |
| 5. What is the role of DNA in inheritance? | |



study material
,Exam
,Objective type Questions
,Important questions
,shortcuts and tricks
,past year papers
,ppt
,Nucleic Acids (DNA & RNA) | Biology for ACT
,Viva Questions
,Extra Questions
,Nucleic Acids (DNA & RNA) | Biology for ACT
,Nucleic Acids (DNA & RNA) | Biology for ACT
,Summary
,Previous Year Questions with Solutions
,Semester Notes
,video lectures
,MCQs
,practice quizzes
,mock tests for examination
,Free
,Sample Paper
;


Nucleic Acids (DNA & RNA) Free PDF Download
Importance of Nucleic Acids (DNA & RNA)
Nucleic Acids (DNA & RNA) Notes
Nucleic Acids (DNA & RNA) ACT Questions
Study Nucleic Acids (DNA & RNA) on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!