Phases of a Compiler | Compiler Design - Computer Science Engineering (CSE) PDF Download

2. PHASES OF A COMPILER:
A compiler operates in phases. A phase is a logically interrelated operation that takes source program in one representation and produces output in another representation. The phases of a compiler are shown in below There are two phases of compilation.
a. Analysis (Machine Independent/Language Dependent)
b. Synthesis (Machine Dependent/Language independent) Compilation process is partitioned into no-of-sub processes called ‘phases’
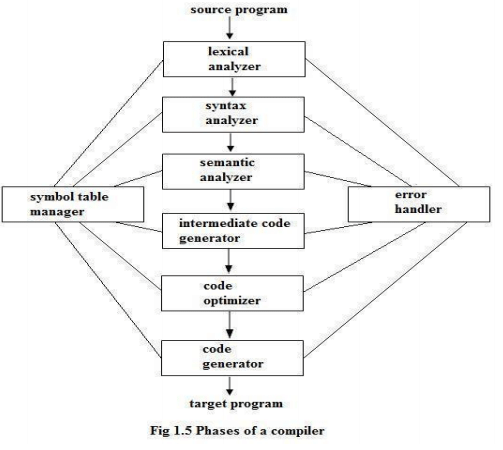
Lexical Analysis:-
LA or Scanners reads the source program one character at a time, carving the source program into a sequence of automatic units called tokens. Syntax Analysis:-
The second stage of translation is called syntax analysis or parsing. In this phase expressions, statements, declarations etc… are identified by using the results of lexical analysis. Syntax analysis is aided by using techniques based on formal grammar of the programming language.
Intermediate Code Generations:-
An intermediate representation of the final machine language code is produced. This phase bridges the analysis and synthesis phases of translation.
Code Optimization:- This is optional phase described to improve the intermediate code so that the output runs faster and takes less space.
Code Generation:- The last phase of translation is code generation. A number of optimizations to
Reduce the length of machine language program are carried out during this phase. The output of the code generator is the machine language program of the specified computer.
Table Management (or) Book-keeping:-
This is the portion to keep the names used by the program and records essential information about each. The data structure used to record this information called a ‘Symbol Table’.
Error Handlers:- It is invoked when a flaw error in the source program is detected. The output of LA is a stream of tokens, which is passed to the next phase, the syntax analyzer or parser. The SA groups the tokens together into syntactic structure called as expression. Expression may further be combined to form statements. The syntactic structure can be regarded as a tree whose leaves are the token called as parse trees.
The parser has two functions. It checks if the tokens from lexical analyzer, occur in pattern that are permitted by the specification for the source language. It also imposes on tokens a tree-like structure that is used by the sub-sequent phases of the compiler.
Example, if a program contains the expression A+/B after lexical analysis this expression might appear to the syntax analyzer as the token sequence id+/id. On seeing the /
the syntax analyzer should detect an error situation, because the presence of these two adjacent binary operators violates the formulations rule of an expression. Syntax analysis is to make explicit the hierarchical structure of the incoming token stream by identifying which parts of the token stream should be grouped.
Example, (A/B*C has two possible interpretations.)
1- divide A by B and then multiply by C or
2- multiply B by C and then use the result to divide A. Each of these two interpretations can be represented in terms of a parse tree.
Intermediate Code Generation:- The intermediate code generation uses the structure produced by the syntax analyzer to create a stream of simple instructions. Many styles of intermediate code are possible. One common style uses instruction with one operator and a small number of operands.The output of the syntax analyzer is some representation of a parse tree. The intermediate code generation phase transforms this parse tree into an intermediate language representation of the source program.
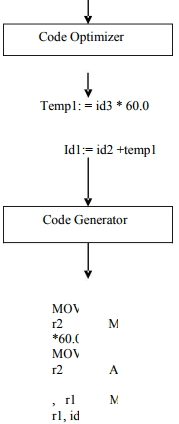
Code Optimization:- This is optional phase described to improve the intermediate code so that the output runs faster and takes less space. Its output is another intermediate code program that does the same job as the original, but in a way that saves time and / or spaces.
/* 1, Local Optimization:-
There are local transformations that can be applied to a program to make an improvement. For example,
If A > B
goto L2 Goto L3 L2 :
This can be replaced by a single statement If A < B goto L3
Another important local optimization is the elimination of common sub-expressions
A := B + C + D
E := B + C + F
Might be evaluated as
T1 := B + C
A := T1 + D
E := T1 + F
Take this advantage of the common sub-expressions B + C.
Loop Optimization:- Another important source of optimization concerns about increasing the speed of loops. A typical loop improvement is to move a computation that produces the same result each time around the loop to a point, in the program just before the loop is entered.*/
Code generator :- C produces the object code by deciding on the memory locations for data, selecting code to access each data and selecting the registers in which each computation is to be done. Many computers have only a few high speed registers in which computations can be performed quickly. A good code generator would attempt to utilize registers as efficiently as possible.
Error Handing :- One of the most important functions of a compiler is the detection and reporting of errors in the source program. The error message should allow the programmer to determine exactly where the errors have occurred. Errors may occur in all or the phases of a compiler.
Whenever a phase of the compiler discovers an error, it must report the error to the error handler, which issues an appropriate diagnostic msg. Both of the table-management and errorHandling routines interact with all phases of the compiler.
Example:
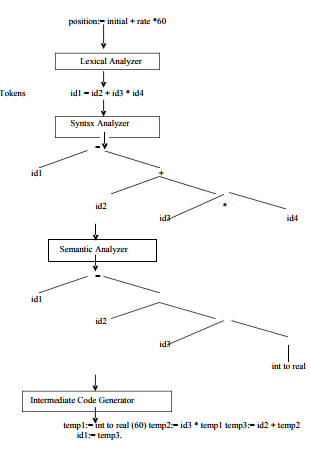
2.1 LEXICAL ANALYZER:
The LA is the first phase of a compiler. Lexical analysis is called as linear analysis or scanning. In this phase the stream of characters making up the source program is read from left-to-right and grouped into tokens that are sequences of characters having a collective meaning.
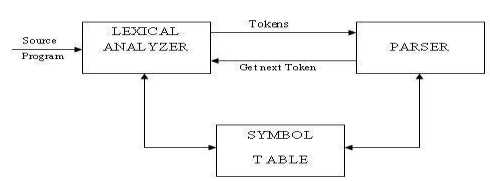
Upon receiving a ‘get next token’ command form the parser, the lexical analyzer reads the input character until it can identify the next token. The LA return to the parser representation for the token it has found. The representation will be an integer code, if the token is a simple construct such as parenthesis, comma or colon. LA may also perform certain secondary tasks as the user interface. One such task is striping out from the source program the commands and white spaces in the form of blank, tab and new line characters. Another is correlating error message from the compiler with the source program.
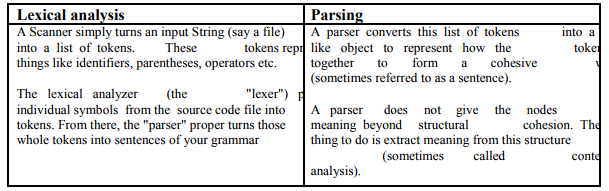
2.1.1Lexical Analysis Vs Parsing:
2.1.2Token, Lexeme, Pattern:
Token:
Token is a sequence of characters that can be treated as a single logical entity. Typical tokens are,
1) Identifiers 2) keywords 3) operators 4) special symbols 5) constants
Pattern: A set of strings in the input for which the same token is produced as output. This set of strings is described by a rule called a pattern associated with the token.
Lexeme: A lexeme is a sequence of characters in the source program that is matched by the pattern for a token.
Example:
Description of token
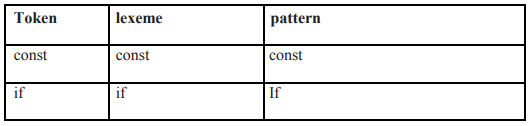

A pattern is a rule describing the set of lexemes that can represent a particular token in source program.
2.1.3 Lexical Errors:
Lexical errors are the errors thrown by the lexer when unable to continue. Which means that there’s no way to recognise a lexeme as a valid token for you lexer? Syntax errors, on the other side, will be thrown by your scanner when a given set of already recognized valid tokens don't match any of the right sides of your grammar rules. Simple panic-mode error handling system requires that we return to a high-level parsing function when a parsing or lexical error is detected.
Error-recovery actions are:
- Delete one character from the remaining input.
- Insert a missing character in to the remaining input.
- Replace a character by another character.
- Transpose two adjacent characters.
3. Difference Between Compiler And Interpreter:
1. A compiler converts the high level instruction into machine language while an interpreter converts the high level instruction into an intermediate form.
2. Before execution, entire program is executed by the compiler whereas after translating the first line, an interpreter then executes it and so on.
3. List of errors is created by the compiler after the compilation process while an interpreter stops translating after the first error.
4. An independent executable file is created by the compiler whereas interpreter is required by an interpreted program each time.
5. The compiler produce object code whereas interpreter does not produce object code. In the process of compilation the program is analyzed only once and then the code is generated whereas source program is interpreted every time it is to be executed and every time the source program is analyzed. Hence interpreter is less efficient than compiler.
6. Examples of interpreter: A UPS Debugger is basically a graphical source level debugger but it contains built in C interpreter which can handle multiple source files. 7. Example of compiler: Borland c compiler or Turbo C compiler compiles the programs written in C or C++.
|
26 videos|90 docs|30 tests
|
FAQs on Phases of a Compiler - Compiler Design - Computer Science Engineering (CSE)
| 1. What are the different phases of a compiler? |  |
| 2. What is the purpose of the lexical analysis phase? | |
| 3. What is the role of the syntax analysis phase in a compiler? | |
| 4. Why is semantic analysis important in a compiler? | |
| 5. What is the purpose of code optimization in a compiler? | |




Phases of a Compiler | Compiler Design - Computer Science Engineering (CSE)
,Exam
,Free
,past year papers
,video lectures
,Objective type Questions
,study material
,Sample Paper
,ppt
,shortcuts and tricks
,practice quizzes
,mock tests for examination
,Summary
,Important questions
,Previous Year Questions with Solutions
,Semester Notes
,MCQs
,Viva Questions
,Extra Questions
,Phases of a Compiler | Compiler Design - Computer Science Engineering (CSE)
,Phases of a Compiler | Compiler Design - Computer Science Engineering (CSE)
;


Phases of a Compiler Free PDF Download
Importance of Phases of a Compiler
Phases of a Compiler Notes
Phases of a Compiler Computer Science Engineering (CSE) Questions
Study Phases of a Compiler on the App
|
© EduRev
|
Education Revolution
|



|





