Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

The Markov and Chebyshev inequalities
As you’ve probably seen in today’s front page: the upper tenth percentile earns 12 times more than the average salary. The following theorem will show that this is not possible.
Theorem 6.1 (Markov inequality) Let X be a random variable assuming nonnegative values. Then for every a ≥ 0,
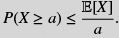
Comment: Note first that this is a vacuous statement for a < E[X]. For a > E[X] this inequality limits the probability that X assumes values larger than its mean.
This is the first time in this course that we derive an inequality. Inequalities, in general, are an important tool for analysis, where estimates (rather than exact identities) are needed.
Proof : We will assume a continuous variable. A similar proof holds in the discrete case.
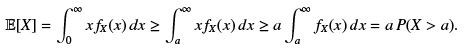
Theorem 6.2 (Chebyshev inequality) Let X be a random variable with mean value µ and variance σ2. Then, for every a > 0
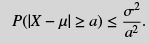
Comment: If we write a = k σ, this theorem states that the probability that a random variable assumes a value whose absolute distance from its mean is more that k times its standard deviation is less that 1/k2 .
The notable thing about these inequalities is that they make no assumption about the distribution. As a result, of course, they may provide very loose estimates.
Proof : Since |X − µ|2 is a positive variable we may apply the Markov inequality,
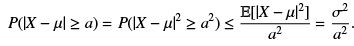
Example: On average, an alcoholic drinks 25 liters of wine every week. What is the probability that he drinks more than 50 liters of wine on a given week?
Here we apply the Markov inequality. If X is the amount of wine he drinks on a given week, then
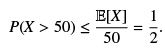
Example: Let X ∼ U (0, 10) what is the probability that |X − E[X]| > 4?
Since E[X] = 5, the answer is 0.2. The Chebyshev inequality, on the other hand gives,
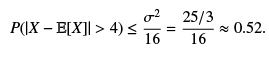
Jensen’s inequality
Recall that a function f : R → R is called convex if it is always below its secants, i.e., if for every x, y and 0 < λ< 1,
f (λ x + (1 − λ)y) ≤ λ f ( x) + (1 − λ) f (y).
Proposition 6.1 (Jensen’s inequality) If g is a convex real valued function and X is a real valued random variable, then
g(E[X ]) ≤ E[g(X )],
provided that the expectations exist.
Proof : Let’s start with an easy proof for a particular case. Consider a continuous random variable and assume that g is twice differentiable (therefore g((( x) ≥ 0).
Taylor expanding g about µ = E[X]
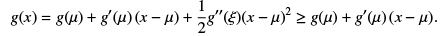
Multiplying both sides by the non-negative functions fX and integrating over x we get
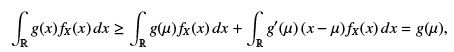
which is precisely what we need to show.
What about the more general case? Any convex function is continuous, and has one-sided derivatives with
For every m ∈ [g'(−(µ), g'(+(µ)]
g( x) ≥ g(µ) + m( x − µ),
so the same proof holds with m replacing g((µ). If X is a discrete variable, we use summation instead of integration.
Example: Since exp is a convex function,
exp(t E[X ]) ≤ E[etX ] = MX (t),
or,
for all t > 0.
Example: Consider a discrete random variable assuming the positive values x1, . . . , xn with equal probability 1/n. Jensen’s inequality for g( x) = − log( x) gives,
Reversing signs, and exponentiating, we get
which is the classical arithmetic mean - geometric mean inequality. In fact, this inequality can be generalized for arbitrary distributions, pX ( xi ) = pi , yielding
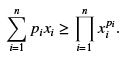
Kolmogorov’s inequality
The Kolmogorov inequality may first seem to be of similar flavor as Chebyshev’s inequality, but it is considerably stronger. I have decided to include it here because its proof involves some interesting subtleties. First, a lemma:
Lemma 6.1 If X, Y, Z are random variables such that Y is independent of X and Z , then
E[XY |Z ] = E[X|Z ] E[Y ].
Proof : The fact that Y is independent of both X, Z implies that (in the case of discrete variables), pX,Y,Z ( x, y, z) = pX,Z ( x, z) pY (y).
Now, for every z,
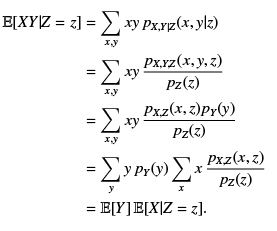
Theorem 6.3 (Kolmogorov’s inequality) Let X1, . . . , Xn be independent random variables such that 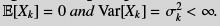 . Then, for all a > 0,
. Then, for all a > 0,
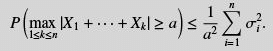
Comment: For n = 1 this is nothing but the Chebyshev inequality. For n > 1 it would still be Chebyshev’s inequality if the maximum over 1 ≤ k ≤ n was replaced by k = n, since by independence
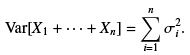
Proof : We introduce the notation S k = X1 + · · · + Xk . This theorem is concerned with the probability that |Sk | > a for some k. We define the random variable N (ω) to be the smallest integer k for which|Sk| > a; if there is no such number we set N(ω) = n. We observe the equivalence of events,
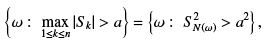
and from the Markov inequality
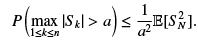
We need to estimate the righth and side. If we could replace
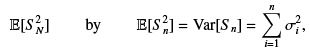
then we would be done. The trick is to show that 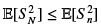 by using conditional expectations. If
by using conditional expectations. If
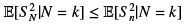
for all 1 ≤ k ≤ n then the inequality holds, since we have then an inequality between random variables 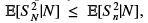 and applying expectations on both sides gives the desired result.
and applying expectations on both sides gives the desired result.
For k = n, the identity
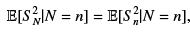
hold trivially. Otherwise, we write
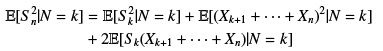
The first term on the right hand side equals 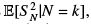 , whereas the second terms is non-negative. Remains the third term for which we remark that Xk+1 + · · · + Xn is independent of both S k and N , and by the previous lemma,
, whereas the second terms is non-negative. Remains the third term for which we remark that Xk+1 + · · · + Xn is independent of both S k and N , and by the previous lemma,
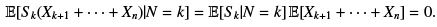
Putting it all together,
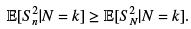
Since this holds for all k’s we have thus shown that
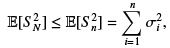
which completes the proof.
|
556 videos|198 docs
|
FAQs on Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What are probability inequalities and how are they used in mathematical sciences? |  |
| 2. What is Chebyshev's inequality and how is it applied in probability theory? | |
| 3. How does Markov's inequality provide an upper bound on the probability of a random variable exceeding a certain threshold? | |
| 4. How does Jensen's inequality relate to probability theory and convex functions? | |
| 5. Can probability inequalities be used to analyze the convergence rates of algorithms in mathematical sciences? | |



Objective type Questions
,study material
,Jensen)
,GATE
,mock tests for examination
,ppt
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Exam
,shortcuts and tricks
,UGC NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,past year papers
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,UGC NET
,Summary
,GATE
,MCQs
,Free
,video lectures
,Probability inequalities (chebyshev
,practice quizzes
,GATE
,CSIR NET
,Probability inequalities (chebyshev
,Sample Paper
,UGC NET
,CSIR NET
,Previous Year Questions with Solutions
,Extra Questions
,Important questions
,Markov
,Markov
,Jensen)
,Jensen)
,Semester Notes
,Probability inequalities (chebyshev
,Markov
,Viva Questions
,CSIR NET
;


Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences Free PDF Download
Importance of Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences
Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences Notes
Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences Mathematics Questions
Study Probability inequalities (chebyshev, Markov, Jensen), CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!