Introduction
The goal of the design phase is to transform the requirements specified in the SRS document into a structure that is suitable for implementation in some programming language. A good software design is seldom arrived by using a single step procedure, but requires several iterations through a series of steps. Design activities can be broadly classified into two important parts:
• Preliminary (or high-level) design and
• Detailed design
High-level design means identification of different modules and the control relationships among them and the definition of the interfaces among these modules. The outcome of highlevel design is called the program structure or software architecture. During detailed design, the data structure and the algorithms of the different modules are designed. The outcome of the detailed design stage is usually known as the module-specification document.
Characteristics of a Good Software Design
However, most researchers and software engineers agree on a few desirable characteristics that every good software design for general application must possess. They are listed below:
Correctness: A good design should correctly implement all the functionalities identified in the SRS document.
Understandability: A good design is easily understandable.
Efficiency: It should be efficient.
Maintainability: It should be easily amenable to change.
Current Design Approaches
Most researchers and engineers agree that a good software design implies clean decomposition of the problem into modules, and the neat arrangement of these modules in a hierarchy. The primary characteristics of neat module decomposition are high cohesion and low coupling.
Cohesion
Most researchers and engineers agree that a good software design implies clean decomposition of the problem into modules, and the neat arrangement of these modules in a hierarchy. The primary characteristics of neat module decomposition are high cohesion and low coupling. Cohesion is a measure of functional strength of a module. A module having high cohesion and low coupling is said to be functionally independent of other modules. By the term functional independence, we mean that a cohesive module performs a single task or function. The different classes of cohesion that a module may possess are depicted in fig. 36.1.

Coincidental cohesion: A module is said to have coincidental cohesion, if it performs a set of tasks that relate to each other very loosely, if at all. In this case, the module contains a random collection of functions. It is likely that the functions have been put in the module out of pure coincidence without any thought or design.
Logical cohesion: A module is said to be logically cohesive, if all elements of the module perform similar operations, e.g. error handling, data input, data output, etc. An example of logical cohesion is the case where a set of print functions generating different output reports are arranged into a single module.
Temporal cohesion: When a module contains functions that are related by the fact that all the functions must be executed in the same time span, the module is said to exhibit temporal cohesion. The set of functions responsible for initialization, start-up, shutdown of some process, etc. exhibit temporal cohesion.
Procedural cohesion: A module is said to possess procedural cohesion, if the set of functions of the module are all part of a procedure (algorithm) in which a certain sequence of steps have to be carried out for achieving an objective, e.g. the algorithm for decoding a message.
Communicational cohesion: A module is said to have communicational cohesion, if all functions of the module refer to or update the same data structure, e.g. the set of functions defined on an array or a stack.
Sequential cohesion: A module is said to possess sequential cohesion, if the elements of a module form the parts of sequence, where the output from one element of the sequence is input to the next.
Functional cohesion: Functional cohesion is said to exist, if different elements of a module cooperate to achieve a single function. For example, a module containing all the functions required to manage employees’ pay-roll displays functional cohesion. Suppose a module displays functional cohesion, and we are asked to describe what the module does, then we would be able to describe it using a single sentence.
Coupling
Coupling between two modules is a measure of the degree of interdependence or interaction between the two modules. A module having high cohesion and low coupling is said to be functionally independent of other modules. If two modules interchange large amounts of data, then they are highly interdependent. The degree of coupling between two modules depends on their interface complexity. The interface complexity is basically determined by the number of types of parameters that are interchanged while invoking the functions of the module. Even if no techniques to precisely and quantitatively estimate the coupling between two modules exist today, classification of the different types of coupling will help to quantitatively estimate the degree of coupling between two modules. Five types of coupling can occur between any two modules as shown in fig. 36.2.
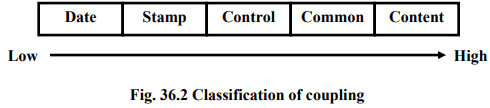
Stamp Coupling: Two modules are stamped coupled, if they communicate using a composite data item such as a record in PASCAL or a structure in C.
Control coupling: Control coupling exists between two couples, if data from one module is used to direct the order of instructions execution in another. An example of control coupling is a flag set in one module and tested in another module.
Common coupling: Two modules are common coupled, if they share some global data items.
Content coupling: Content coupling exists between two modules, if their code is shared, e.g. a branch from one module into another module.
Functional Independence
A module having high cohesion and low coupling is said to be functionally independent of other modules. By the term functional independence, we mean that a cohesive module performs a single task or function. A functionally independent module has minimal interaction with other modules. Functional independence is a key to any good design primarily due to the following reasons:
Error isolation: Functional independence reduces error propagation. The reason behind this is that if a module is functionally independent, its degree of interaction with the other modules is less. Therefore, any error existing in a module would not directly effect the other modules.
Scope of reuse: Reuse of a module becomes possible- because each module does some welldefined and precise function and the interaction of the module with the other modules is simple and minimal. Therefore, a cohesive module can be easily taken out and reused in a different program.
Understandability: Complexity of the design is reduced, because different modules can be understood in isolation as modules are more or less independent of each other.
Function-Oriented Design Approach
The following are the salient features of a typical function-oriented design approach: 1. A system is viewed as something that performs a set of functions. Starting at this highlevel view of the system, each function is successively refined into more detailed functions. For example, consider a function create-new-library member which essentially creates the record for a new member, assigns a unique membership number to him, and prints a bill towards his membership charge. This function may consist of the following sub-functions:
• assign-membership-number
• create-member-record
• print-bill
Each of these sub-functions may be split into more detailed sub-functions and so on. 2. The system state is centralized and shared among different functions, e.g. data such as member-records is available for reference and updating to several functions such as:
• create-new-member
• delete-member
• update-member-record
Object-Oriented Design Approach
In the object-oriented design approach, the system is viewed as collection of objects (i.e. entities). The state is decentralized among the objects and each object manages its own state information. For example, in a Library Automation Software, each library member may be a separate object with its own data and functions to operate on these data. In fact, the functions defined for one object cannot refer or change data of other objects. Objects have their own internal data which define their state. Similar objects constitute a class. In other words, each object is a member of some class. Classes may inherit features from super class. Conceptually, objects communicate by message passing.
Function-Oriented Vs. Object-Oriented Design
The following are some of the important differences between function-oriented and objectoriented design.
• Unlike function-oriented design methods, in OOD, the basic abstraction are not realworld functions such as sort, display, track, etc, but real-world entities such as employee, picture, machine, radar system, etc. For example in OOD, an employee pay-roll software is not developed by designing functions such as update-employeerecord, get-employee-address, etc. but by designing objects such as employees, departments, etc.
• In object-oriented design, software is not developed by designing functions such as update-employee-record, get-employee-address, etc., but by designing objects such as employee, department, etc.
• In OOD, state information is not represented in a centralized shared memory but is distributed among the objects of the system. For example, while developing an employee pay-roll system, the employee data such as the names of the employees, their code numbers, basic salaries, etc. are usually implemented as global data in a traditional programming system; whereas in an object-oriented system these data are distributed among different employee objects of the system. Objects communicate by passing messages. Therefore, one object may discover the state information of another object by interrogating it. Of course, somewhere or the other the real-world functions must be implemented.
• Function-oriented techniques such as SA/SD group functions together if, as a group, they constitute a higher-level function. On the other hand, object-oriented techniques group functions together on the basis of the data they operate on.
To illustrate the differences between the object-oriented and the function-oriented design approaches, an example can be considered.
Example: Fire-Alarm System
The owner of a large multi-storied building wants to have a computerized fire alarm system for his building. Smoke detectors and fire alarms would be placed in each room of the building. The fire alarm system would monitor the status of these smoke detectors. Whenever a fire condition is reported by any of the smoke detectors, the fire alarm system should determine the location at which the fire condition is reported by any of the smoke detectors. The fire alarm system should determine the location at which the fire condition has occurred and then sound the alarms only in the neighboring locations. The fire alarm system should also flash an alarm message on the computer consol. Fire fighting personnel man the console round the clock. After a fire condition has been successfully handled, the fire alarm system should support resetting the alarms by the fire fighting personnel.
Function-Oriented Approach:
/* Global data (system state ) accessible by various functions */
BOOL detector_status[MAX_ROOMS];
int detector_locs[MAX_ROOMS];
BOOL alarm_status[MAX_ROOMS];/* alarm activated when status is set */
int alarm_locs[MAX_ROOMS]; /* room number where alarm is located */
int neighbor-alarm[MAX_ROOMS][10]; /*
each detector has at most 10 neighboring locations */
The functions which operate on the system state are:
interrogate_detectors();
get_detector_location();
determine_neighbor();
ring_alarm();
reset_alarm();
report_fire_location();
Object-Oriented Approach:
class detector
attributes: status, location, neighbors
operations: create, sense-status, get-location, find-neighbors
class alarm
attributes: location, status
operations: create, ring-alarm, get_location, reset-alarm
In the object oriented program, an appropriate number of instances of the class detector and alarm should be created. If the function-oriented and the object-oriented programs are examined, then it is seen that in the function-oriented program the system state is centralized and several functions on this central data is defined. In case of the object-oriented program, the state information is distributed among various objects.
It is not necessary that an object-oriented design be implemented by using an object-oriented language only. However, an object-oriented language such as C++, supports the definition of all the basic mechanisms of class, inheritance, objects, methods, etc., and also supports all key object-oriented concepts that we have just discussed. Thus, an object-oriented language facilitates the implementation of an OOD. However, an OOD can as well be implemented using a conventional procedural language – though it may require more effort to implement an OOD using a procedural language as compared to the effort required for implementing the same design using an object-oriented language. Even though object-oriented and function-oriented approaches are remarkably different approaches to software design, they do not replace each other but complement each other in some sense. For example, usually one applies the top-down function oriented techniques to design the internal methods of a class, once the classes are identified. In this case, though outwardly the system appears to have been developed in an object-oriented fashion, inside each class there may be a small hierarchy of functions designed in a top-down manner.
Function-Oriented Software Design
Function-oriented design techniques view a system as a black-box that performs a set of high-level functions. During the design process, these high-level functions are successively decomposed into more detailed functions and finally the different identified functions are mapped to modules. The term top-down decomposition is often used to denote such successive decompositions of a set of high-level functions into more detailed functions.
Structured Analysis
Structured analysis is used to carry out the top-down decomposition of a set of high-level functions depicted in the problem description and to represent them graphically. During structured analysis, functional decomposition of the system is achieved. That is, each function that the system performs is analysed and hierarchically decomposed into more detailed functions. Structured analysis technique is based on the following essential underlying principles:
• Top-down decomposition approach.
• Divide and conquer principle. Each function is decomposed independently.
• Graphical representation of the analysis results using Data Flow Diagrams (DFDs).
Data Flow Diagrams
The DFD (also known as a bubble chart) is a simple graphical formalism that can be used to represent a system in terms of the input data to the system, various processing carried out on these data, and the output data generated by the system. A DFD model uses a very limited number of primitive symbols (as shown in fig. 36.3) to represent the functions performed by a system and the data flow among these functions.

The main reason why the DFD technique is so popular is probably because of the fact that DFD is a very simple formalism – it is simple to understand and use. Starting with a set of highlevel functions that a system performs, a DFD model hierarchically represents various subfunctions. In fact, any hierarchical model is simple to understand. The human mind is such that it can easily understand any hierarchical model of a system – because in a hierarchical model, starting with a very simple and abstract model of a system, different details of the system are slowly introduced through different hierarchies. The data flow diagramming technique also follows a very simple set of intuitive concepts and rules. DFD is an elegant modeling technique that turns out to be useful not only to represent the results of structured analysis of a software problem but also for several other applications such as showing the flow of documents or items in an organization.
Data Dictionary
A data dictionary lists all data items appearing in the DFD model of a system. The data items listed include all data flows and the contents of all data stores appearing on the DFDs in the DFD model of a system. A data dictionary lists the purpose of all data items and the definition of all composite data items in terms of their component data items. For example, a data dictionary entry may represent that the data grossPay consists of the components regularPay and overtimePay.
grossPay = regularPay + overtimePay
For the smallest units of data items, the data dictionary lists their name and their type.
A data dictionary plays a very important role in any software development process because of the following reasons:
• A data dictionary provides a standard terminology for all relevant data for use by engineers working in a project. A consistent vocabulary for data items is very important, since in large projects different engineers of the project have a tendency to use different terms to refer to the same data, which unnecessarily causes confusion.
• The data dictionary provides the analyst with a means to determine the definition of different data structures in terms of their component elements.




















