Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences | Mathematics for IIT JAM, GATE, CSIR NET, UGC NET PDF Download

4.3 Univariate graphical EDA
If we are focusing on data from observation of a single variable on n subjects, i.e., a sample of size n, then in addition to looking at the various sample statistics discussed in the previous section, we also need to look graphically at the distribution of the sample. Non-graphical and graphical methods complement each other. While the non-graphical methods are quantitative and objective, they do not give a full picture of the data; therefore, graphical methods, which are more qualitative and involve a degree of subjective analysis, are also required.
4.3.1 Histograms
The only one of these techniques that makes sense for categorical data is the histogram (basically just a barplot of the tabulation of the data). A pie chart is equivalent, but not often used. The concepts of central tendency, spread and skew have no meaning for nominal categorical data. For ordinal categorical data, it sometimes makes sense to treat the data as quantitative for EDA purposes; you need to use your judgment here.
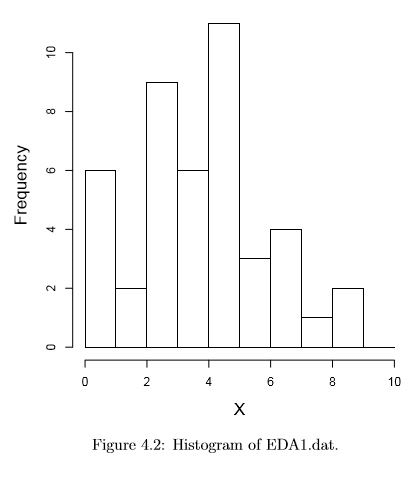
The most basic graph is the histogram, which is a barplot in which each bar represents the frequency (count) or proportion (count/total count) of cases for a range of values. Typically the bars run vertically with the count (or proportion) axis running vertically. To manually construct a histogram, define the range of data for each bar (called a bin), count how many cases fall in each bin, and draw the bars high enough to indicate the count. For the simple data set found in EDA1.dat the histogram is shown in figure 4.2. Besides getting the general impression of the shape of the distribution, you can read off facts like “there are two cases with data values between 1 and 2” and “there are 9 cases with data values between 2 and 3”. Generally values that fall exactly on the boundary between two bins are put in the lower bin, but this rule is not always followed.
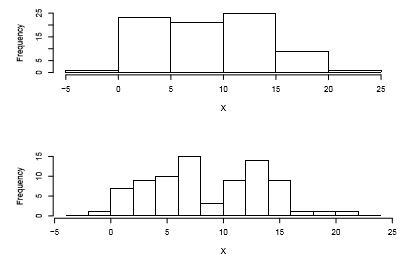
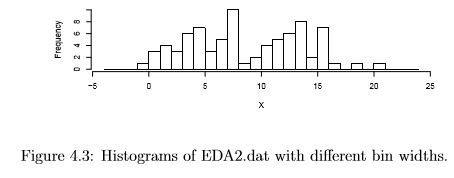
Generally you will choose between about 5 and 30 bins, depending on the amount of data and the shape of the distribution. Of course you need to see the histogram to know the shape of the distribution, so this may be an iterative process. It is often worthwhile to try a few different bin sizes/numbers because, especially with small samples, there may sometimes be a different shape to the histogram when the bin size changes. But usually the difference is small. Figure 4.3 shows three histograms of the same sample from a bimodal population using three different bin widths (5, 2 and 1). If you want to try on your own, the data are in EDA2.dat. The top panel appears to show a unimodal distribution. The middle panel correctly shows the bimodality. The bottom panel incorrectly suggests many modes. There is some art to choosing bin widths, and although often the automatic choices of a program like SPSS are pretty good, they are certainly not always adequate.
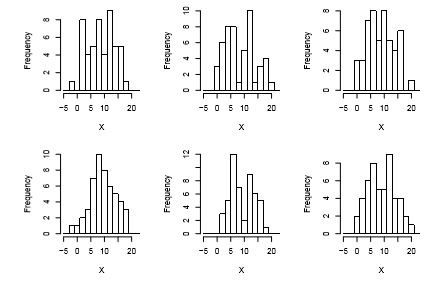
It is very instructive to look at multiple samples from the same population to get a feel for the variation that will be found in histograms. Figure 4.4 shows histograms from multiple samples of size 50 from the same population as figure 4.3, while 4.5 shows samples of size 100. Notice that the variability is quite high, especially for the smaller sample size, and that an incorrect impression (particularly of unimodality) is quite possible, just by the bad luck of taking a particular sample.
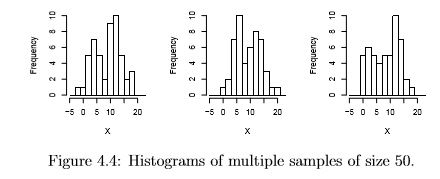
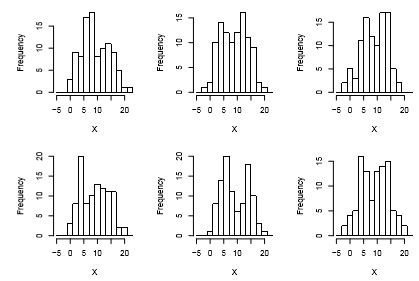
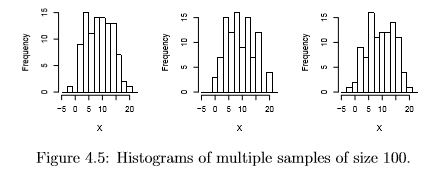
With practice, histograms are one of the best ways to quickly learn a lot about your data, including central tendency, spread, modality, shape and outliers. |
4.3.2 Stem-and-leaf plots
A simple substitute for a histogram is a stem and leaf plot. A stem and leaf plot is sometimes easier to make by hand than a histogram, and it tends not to hide any information. Nevertheless, a histogram is generally considered better for appreciating the shape of a sample distribution than is the stem and leaf plot. Here is a stem and leaf plot for the data of figure 4.2:

Because this particular stem and leaf plot has the decimal place at the stem, each of the 0’s in the first line represent 1.0, and each zero in the second line represents 2.0, etc. So we can see that there are six 1’s, two 2’s etc. in our data.
A stem and leaf plot shows all data values and the shape of the distribution. |
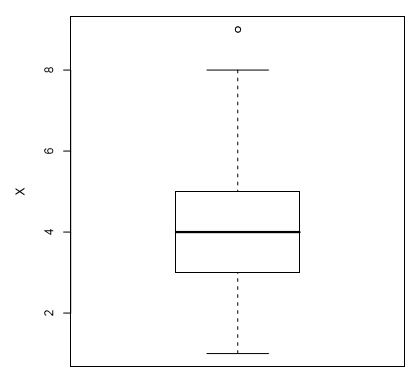
Figure 4.6: A boxplot of the data from EDA1.dat.
4.3.3 Boxplots
Another very useful univariate graphical technique is the boxplot. The boxplot will be described here in its vertical format, which is the most common, but a horizontal format also is possible. An example of a boxplot is shown in figure 4.6, which again represents the data in EDA1.dat.
Boxplots are very good at presenting information about the central tendency, symmetry and skew, as well as outliers, although they can be misleading about aspects such as multimodality. One of the best uses of boxplots is in the form of side-by-side boxplots (see multivariate graphical analysis below).
Figure 4.7 is an annotated version of figure 4.6. Here you can see that the boxplot consists of a rectangular box bounded above and below by “hinges” that represent the quartiles Q3 and Q1 respectively, and with a horizontal “median”
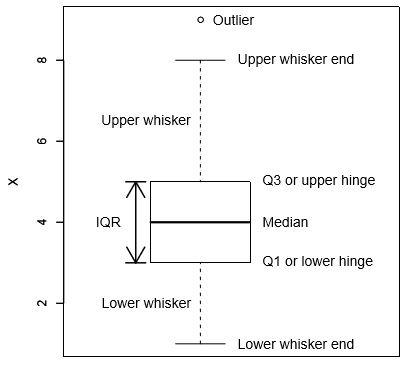
Figure 4.7: Annotated boxplot.
line through it. You can also see the upper and lower “whiskers”, and a point marking an “outlier”. The vertical axis is in the units of the quantitative variable.
Let’s assume that the subjects for this experiment are hens and the data represent the number of eggs that each hen laid during the experiment. We can read certain information directly off of the graph. The median (not mean!) is 4 eggs, so no more than half of the hens laid more than 4 eggs and no more than half of the hens laid less than 4 eggs. (This is based on the technical definition of median; we would usually claim that half of the hens lay more or half less than 4, knowing that this may be only approximately correct.) We can also state that one quarter of the hens lay less than 3 eggs and one quarter lay more than 5 eggs (again, this may not be exactly correct, particularly for small samples or a small number of different possible values). This leaves half of the hens, called the “central half”, to lay between 3 and 5 eggs, so the interquartile range (IQR) is Q3-Q1=5-3=2.
The interpretation of the whiskers and outliers is just a bit more complicated. Any data value more than 1.5 IQRs beyond its corresponding hinge in either direction is considered an “outlier” and is individually plotted. Sometimes values beyond 3.0 IQRs are considered “extreme outliers” and are plotted with a different symbol. In this boxplot, a single outlier is plotted corresponding to 9 eggs laid, although we know from figure 4.2 that there are actually two hens that laid 9 eggs. This demonstrates a general problem with plotting whole number data, namely that multiple points may be superimposed, giving a wrong impression. (Jittering, circle plots, and starplots are examples of ways to correct this problem.) This is one reason why, e.g., combining a tabulation and/or a histogram with a boxplot is better than either alone.
Each whisker is drawn out to the most extreme data point that is less than 1.5 IQRs beyond the corresponding hinge. Therefore, the whisker ends correspond to the minimum and maximum values of the data excluding the “outliers”.
Important: The term “outlier” is not well defined in statistics, and the definition varies depending on the purpose and situation. The “outliers” identified by a boxplot, which could be called “boxplot outliers” are defined as any points more than 1.5 IQRs above Q3 or more than 1.5 IQRs below Q1. This does not by itself indicate a problem with those data points. Boxplots are an exploratory technique, and you should consider designation as a boxplot outlier as just a suggestion that the points might be mistakes or otherwise unusual. Also, points not designated as boxplot outliers may also be mistakes. It is also important to realize that the number of boxplot outliers depends strongly on the size of the sample. In fact, for data that is perfectly Normally distributed, we expect 0.70 percent (or about 1 in 150 cases) to be “boxplot outliers”, with approximately half in either direction.
The boxplot information described above could be appreciated almost as easily if given in non-graphical format. The boxplot is useful because, with practice, all of the above and more can be appreciated at a quick glance. The additional things you should notice on the plot are the symmetry of the distribution and possible evidence of “fat tails”. Symmetry is appreciated by noticing if the median is in the center of the box and if the whiskers are the same length as each other. For this purpose, as usual, the smaller the dataset the more variability you will see from sample to sample, particularly for the whiskers. In a skewed distribution we expect to see the median pushed in the direction of the shorter whisker. If the longer whisker is the top one, then the distribution is positively skewed (or skewed to the right, because higher values are on the right in a histogram). If the lower whisker is longer, the distribution is negatively skewed (or left skewed.) In cases where the median is closer to the longer whisker it is hard to draw a conclusion.
The term fat tails is used to describe the situation where a histogram has a lot of values far from the mean relative to a Gaussian distribution. This corresponds to positive kurtosis. In a boxplot, many outliers (more than the 1/150 expected for a Normal distribution) suggests fat tails (positive kurtosis), or possibly many data entry errors. Also, short whiskers suggest negative kurtosis, at least if the sample size is large.
Boxplots are excellent EDA plots because they rely on robust statistics like median and IQR rather than more sensitive ones such as mean and standard deviation. With boxplots it is easy to compare distributions (usually for one variable at different levels of another; see multivariate graphical EDA, below) with a high degree of reliability because of the use of these robust statistics.
It is worth noting that some (few) programs produce boxplots that do not conform to the definitions given here.
Boxplots show robust measures of location and spread as well as providing information about symmetry and outliers. |
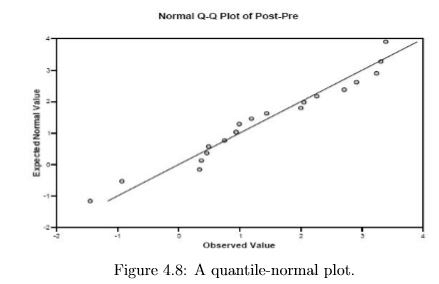
4.3.4 Quantile-normal plots
The final univariate graphical EDA technique is the most complicated. It is called the quantile-normal or QN plot or more generality the quantile-quantile or QQ plot. It is used to see how well a particular sample follows a particular theoretical distribution. Although it can be used for any theoretical distribution, we will limit our attention to seeing how well a sample of data of size n matches a Gaussian distribution with mean and variance equal to the sample mean and variance. By examining the quantile-normal plot we can detect left or right skew, positive or negative kurtosis, and bimodality.
The example shown in figure 4.8 shows 20 data points that are approximately normally distributed. Do not confuse a quantile-normal plot with a simple scatter plot of two variables. The title and axis labels are strong indicators that this is a quantile-normal plot. For many computer programs, the word “quantile” is also in the axis labels.
Many statistical tests have the assumption that the outcome for any fixed set of values of the explanatory variables is approximately normally distributed, and that is why QN plots are useful: if the assumption is grossly violated, the p-value and confidence intervals of those tests are wrong. As we will see in the ANOVA and regression chapters, the most important situation where we use a QN plot is not for EDA, but for examining something called “residuals” (see section 9.4). For basic interpretation of the QN plot you just need to be able to distinguish the two situations of “OK” (points fall randomly around the line) versus “non-normality” (points follow a strong curved pattern rather than following the line).
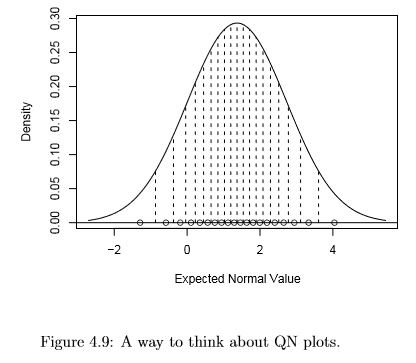
If you are still curious, here is a description of how the QN plot is created. Understanding this will help to understand the interpretation, but is not required in this course. Note that some programs swap the x and y axes from the way described here, but the interpretation is similar for all versions of QN plots. Consider the 20 values observed in this study. They happen to have an observed mean of 1.37 and a standard deviation of 1.36. Ideally, 20 random values drawn from a distribution that has a true mean of 1.37 and sd of 1.36 have a perfect bell-shaped distribution and will be spaced so that there is equal area (probability) in the area around each value in the bell curve. In figure 4.9 the dotted lines divide the bell curve up into 20 equally probable zones, and the 20 points are at the probability mid-points of each zone. These 20 points, which are more tightly packed near the middle than in the ends, are used as the “Expected Normal Values” in the QN plot of our actual data. In summary, the sorted actual data values are plotted against “Expected Normal Values”, and some kind of diagonal line is added to help direct the eye towards a perfect straight line on the quantile-normal plot that represents a perfect bell shape for the observed data. The interpretation of the QN plot is given here. If the axes are reversed in the computer package you are using, you will need to correspondingly change your interpretation. If all of the points fall on or nearly on the diagonal line (with a random pattern), this tells us that a histogram of the variable will show a bell shaped (Normal or Gaussian) distribution. Figure 4.10 shows all of the points basically on the reference line, but there are several vertical bands of points. Because the x-axis is “observed values”, these bands indicate ties, i.e., multiple points with the same values. And all of the observed values are at whole numbers. So either the data are rounded or we are looking at a discrete quantitative (counting) variable. Either way, the data appear |
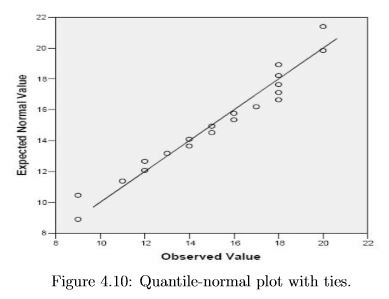
to be nearly normally distributed.
In figure 4.11 note that we have many points in a row that are on the same side of the line (rather than just bouncing around to either side), and that suggests that there is a real (non-random) deviation from Normality. The best way to think about these QN plots is to look at the low and high ranges of the Expected Normal Values. In each area, see how the observed values deviate from what is expected, i.e., in which “x” (Observed Value) direction the points appear to have moved relative to the “perfect normal” line. Here we observe values that are too high in both the low and high ranges. So compared to a perfect bell shape, this distribution is pulled asymmetrically towards higher values, which indicates positive skew.
Also note that if you just shift a distribution to the right (without disturbing its symmetry) rather than skewing it, it will maintain its perfect bell shape, and the points remain on the diagonal reference line of the quantile-normal curve.
Of course, we can also have a distribution that is skewed to the left, in which case the high and low range points are shifted (in the Observed Value direction) towards lower than expected values.
In figure 4.12 the high end points are shifted too high and the low end points are shifted too low. These data show a positive kurtosis (fat tails). The opposite pattern is a negative kurtosis in which the tails are too “thin” to be bell shaped.
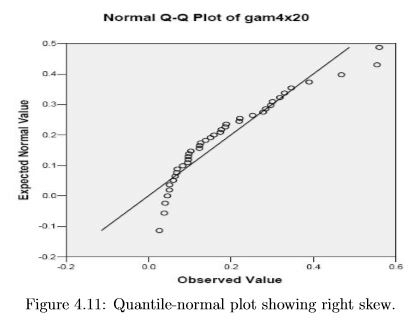
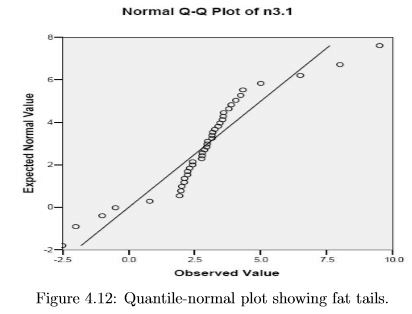
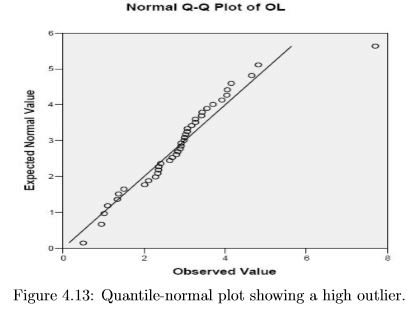
In figure 4.13 there is a single point that is off the reference line, i.e. shifted to the right of where it should be. (Remember that the pattern of locations on the Expected Normal Value axis is fixed for any sample size, and only the position on the Observed axis varies depending on the observed data.) This pattern shows nearly Gaussian data with one “high outlier”.
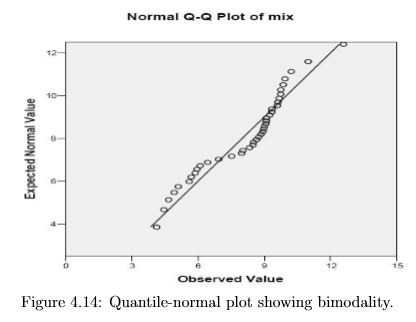
Finally, figure 4.14 looks a bit similar to the “skew left” pattern, but the most extreme points tend to return to the reference line. This pattern is seen in bi-modal data, e.g. this is what we would see if we would mix strength measurements from controls and muscular dystrophy patients.
Quantile-Normal plots allow detection of non-normality and diagnosis of skewness and kurtosis. |
|
556 videos|198 docs
|
FAQs on Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences - Mathematics for IIT JAM, GATE, CSIR NET, UGC NET
| 1. What is univariate graphical EDA in statistics? |  |
| 2. How does univariate graphical EDA assist in data analysis? | |
| 3. What are the commonly used graphical techniques in univariate graphical EDA? | |
| 4. How can univariate graphical EDA be applied in practical data analysis? | |
| 5. What are the limitations of univariate graphical EDA in statistical analysis? | |



Summary
,Objective type Questions
,Important questions
,UGC NET
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,video lectures
,GATE
,Viva Questions
,practice quizzes
,GATE
,Extra Questions
,Semester Notes
,past year papers
,Exam
,MCQs
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,ppt
,CSIR NET
,Univariate Graphical EDA - Statistics
,UGC NET
,mock tests for examination
,Sample Paper
,study material
,CSIR-NET Mathematical Sciences | Mathematics for IIT JAM
,Free
,UGC NET
,Univariate Graphical EDA - Statistics
,Previous Year Questions with Solutions
,Univariate Graphical EDA - Statistics
,shortcuts and tricks
,GATE
,CSIR NET
,CSIR NET
;


Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences Free PDF Download
Importance of Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences
Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences Notes
Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences Mathematics Questions
Study Univariate Graphical EDA - Statistics, CSIR-NET Mathematical Sciences on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!