डेटा का संग्रहण | SSC CGL Tier 2 - Study Material, Online Tests, Previous Year (Hindi) PDF Download
| Table of contents |
|
| परिचय |
|
| डेटा के स्रोत |
|
| प्राथमिक और द्वितीयक डेटा के बीच अंतर |
|
| डेटा संग्रहण के सांख्यिकी विधियाँ |
|
| नमूनाकरण विधियाँ |
|
| डेटा संग्रह में सामान्य चुनौतियाँ क्या हैं? |
|

परिचय
डेटा संग्रहण एक संगठित तरीके से जानकारी इकट्ठा करने की प्रक्रिया है, जिसका उद्देश्य उपयोगी अंतर्दृष्टि प्राप्त करना है। SSC CGL टियर 2 परीक्षा के अभ्यर्थियों के लिए डेटा संग्रहण को समझना महत्वपूर्ण है क्योंकि यह परीक्षा का एक प्रमुख भाग है। डेटा संग्रहण किसी भी अनुसंधान प्रक्रिया में एक महत्वपूर्ण कदम है, जो विश्लेषण और व्याख्या के लिए आधार प्रदान करता है। इसमें विशेष प्रश्नों का उत्तर देने, परिकल्पनाओं का परीक्षण करने, और परिणामों का मूल्यांकन करने के लिए जानकारी इकट्ठा करना शामिल है। एकत्रित डेटा की गुणवत्ता सीधे अनुसंधान निष्कर्षों की विश्वसनीयता और वैधता को प्रभावित करती है। यह अध्याय डेटा के विभिन्न स्रोतों, उपलब्ध डेटा के प्रकारों, और डेटा संग्रहण के लिए उपयोग की जाने वाली सांख्यिकीय विधियों का अन्वेषण करता है, साथ ही उनके फायदे और नुकसान भी।

डेटा के स्रोत
डेटा को दो मुख्य स्रोतों से इकट्ठा किया जा सकता है:
प्राथमिक डेटा का स्रोत
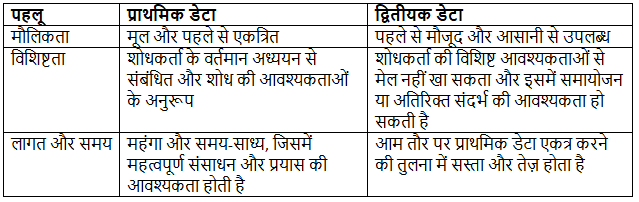
- परिभाषा: प्राथमिक डेटा वह मूल डेटा है जिसे शोधकर्ता द्वारा विशेष शोध उद्देश्य के लिए सीधे उसके स्रोत से एकत्रित किया जाता है।
- उदाहरण: सर्वेक्षणों, प्रयोगों, या शोधकर्ता द्वारा किए गए प्रत्यक्ष अवलोकनों के माध्यम से एकत्रित डेटा।
द्वितीयक डेटा का स्रोत
- परिभाषा: द्वितीयक डेटा वह डेटा है जो पहले से किसी अन्य द्वारा एकत्रित किया गया है और उपयोग के लिए उपलब्ध है।
- उदाहरण: पुस्तकों, पत्रिकाओं, सरकारी रिपोर्टों, और अन्य शोधकर्ताओं या संस्थानों द्वारा बनाए गए डेटाबेस से डेटा।
प्राथमिक और द्वितीयक डेटा के बीच अंतर
डेटा संग्रहण के सांख्यिकी विधियाँ
1. प्रत्यक्ष व्यक्तिगत जांच:
लाभ:
- असलीपन: संग्रहित डेटा असली और अद्वितीय होता है।
- विश्वसनीयता: प्रत्यक्ष संग्रहण उच्च विश्वसनीयता और सटीकता सुनिश्चित करता है।
- सटीकता: विस्तृत और सटीक जानकारी प्राप्त होती है।
- विस्तृत जानकारी: गहन डेटा एकत्र किया जा सकता है।
- लचीलापन: यह विधि विभिन्न परिस्थितियों के अनुसार लचीली और अनुकूलनीय है।
नुकसान:
- कवरेज सीमा: बड़े या फैलाव वाले जनसंख्याओं को कवर करना मुश्किल होता है।
- लागत: आवश्यक संसाधनों के कारण अक्सर महंगी होती है।
- व्यक्तिगत पूर्वाग्रह: जांचकर्ता के पूर्वाग्रह डेटा को प्रभावित कर सकते हैं।
- सीमित दायरा: समय और संसाधनों की सीमाओं के कारण सभी आवश्यक क्षेत्रों को कवर नहीं कर सकता।
2. अप्रत्यक्ष मौखिक जांच
डेटा अनुभवी व्यक्तियों या विशेषज्ञों से एकत्र किया जाता है जो अपने अनुभव के आधार पर जानकारी प्रदान करते हैं। यह विधि उत्तरदाता की सटीक जानकारी प्रदान करने की क्षमता पर निर्भर करती है।
लाभ:
- व्यापक कवरेज: एक विस्तृत क्षेत्र से जानकारी एकत्र की जा सकती है।
- त्वरित संग्रहण: डेटा एकत्र करने का तेज़ तरीका।
- लागत-कुशल: सामान्यत: प्रत्यक्ष विधियों की तुलना में कम महंगा।
- पूर्वाग्रह-रहित: जांचकर्ता के पूर्वाग्रह का जोखिम कम होता है।
- सटीकता की समस्याएँ: डेटा दूसरी हाथ की जानकारी पर निर्भर होने के कारण कम सटीक हो सकता है।
- उत्तरदाताओं में पूर्वाग्रह: उत्तरदाता के अपने पूर्वाग्रह हो सकते हैं।
- सामान्य निष्कर्ष: जानकारी में विवरण और विशिष्टता की कमी हो सकती है।
3. स्थानीय स्रोतों या संवाददाताओं से जानकारी
स्थानीय संवाददाताओं या व्यक्तियों को विभिन्न स्थानों से डेटा एकत्र करने के लिए नियुक्त किया जाता है। यह विधि तब उपयोग की जाती है जब कई क्षेत्रों से जानकारी की आवश्यकता होती है।
- आर्थिक: व्यापक क्षेत्रीय कार्य की तुलना में लागत-कुशल।
- व्यापक कवरेज: बड़े भौगोलिक क्षेत्रों को कवर करने में सक्षम।
- निरंतरता: डेटा संग्रहण में निरंतरता प्रदान करता है।
- विशेष उद्देश्य: विशिष्ट, स्थानीय अध्ययन के लिए उपयुक्त।
- असलीपन की हानि: डेटा दूसरी हाथ की होने के कारण असलीपन खो सकता है।
- एकरूपता की कमी: डेटा गुणवत्ता और संग्रहण विधियों में भिन्नता।
- व्यक्तिगत पूर्वाग्रह: संवाददाताओं के पूर्वाग्रह डेटा की गुणवत्ता को प्रभावित कर सकते हैं।
4. प्रश्नावली और अनुसूचियों के माध्यम से जानकारी
डेटा प्रश्नावली और अनुसूचियों का उपयोग करके संग्रहित किया जाता है जो सूचनाकर्ताओं को मेल करके या गणनाकारों द्वारा प्रशासनित की जाती हैं।

(a) मेलिंग विधि: उपयुक्त जब:
- अध्ययन का क्षेत्र बड़ा हो।
- सूचनाकर्ता शिक्षित हों।
(b) गणनाकार की विधि: उपयुक्त जब:
- जांच में विस्तृत और कुशल जांच की आवश्यकता हो।
- जांचकर्ता को स्थानीय भाषा और सांस्कृतिक मानकों में प्रवीण होना चाहिए।
ध्यान देने योग्य कारक:
- संग्रहण संगठन की क्षमता
- उद्देश्य और दायरा
- संग्रहण की विधि
- संगठन का समय और स्थिति
- इकाई की परिभाषा
- सटीकता
5. जनगणना विधि
डेटा को समस्या से संबंधित जनसंख्या के हर तत्व को कवर करते हुए संग्रहित किया जाता है।

गुण:
- विश्वसनीय और सटीक
- कम पक्षपाती
- व्यापक जानकारी
- विविध विशेषताओं का अध्ययन
- जटिल जांच के लिए उपयुक्त
- अप्रत्यक्ष जांच
दोष:
- महंगा
- बड़ी संख्या में जनशक्ति की आवश्यकता
- बड़े पैमाने पर जांच के लिए उपयुक्त नहीं
6. नमूना विधि
डेटा एक नमूने के बारे में एकत्र किया जाता है, और नमूने के आधार पर पूरी जनसंख्या के बारे में निष्कर्ष निकाले जाते हैं।
गुण:
- किफायती
- समय की बचत
- सूचना त्रुटि में कमी
- बड़ी जांच संभव
- प्रशासनिक सुविधा
- अधिक वैज्ञानिक
दोष:
- आंशिक निष्कर्ष
- संभावित गलत निष्कर्ष
- प्रतिनिधि नमूना चुनने में कठिनाई
- विशेषज्ञ ज्ञान की आवश्यकता
नमूनाकरण विधियाँ
1. यादृच्छिक नमूनाकरण
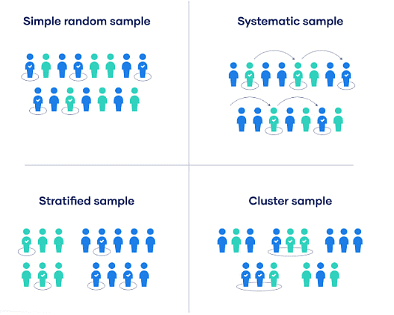
यादृच्छिक नमूनाकरण यह सुनिश्चित करता है कि जनसंख्या का हर सदस्य चयनित होने का समान मौका रखता है। यह विधि चयन पूर्वाग्रह को कम करती है और प्रतिनिधित्व सुनिश्चित करती है।
(a)लॉटरी विधि:
जनसंख्या के प्रत्येक सदस्य को एक अद्वितीय संख्या आवंटित की जाती है। फिर नमूना चुनने के लिए संख्याएँ यादृच्छिक रूप से निकाली जाती हैं।
उदाहरण: 30 छात्रों की कक्षा में, प्रत्येक छात्र को 1 से 30 तक एक संख्या आवंटित की जाती है। 5 छात्रों का सर्वेक्षण करने के लिए संख्याएँ यादृच्छिक रूप से निकाली जाती हैं।
यादृच्छिक संख्याओं की तालिकाएँ:
- विवरण: एक पूर्व-निर्मित यादृच्छिक संख्याओं की तालिका का उपयोग जनसंख्या के सदस्यों को चुनने के लिए किया जाता है।
- उदाहरण: एक तालिका का उपयोग करते हुए, एक शोधकर्ता 100 की सूची में से यादृच्छिक संख्याओं के आधार पर छात्रों का चयन कर सकता है।
2. उद्देश्यपूर्ण या जानबूझकर नमूनाकरण
उद्देश्यपूर्ण नमूनाकरण में अध्ययन के लिए महत्वपूर्ण माने जाने वाले कुछ मानदंडों के आधार पर विशिष्ट व्यक्तियों को चुना जाता है। इसका उपयोग तब किया जाता है जब विशिष्ट अंतर्दृष्टियों की आवश्यकता होती है। शोधकर्ता उन व्यक्तियों की पहचान करता है जिनके बारे में माना जाता है कि उनके पास अध्ययन से संबंधित विशेष ज्ञान या अनुभव है।
उदाहरण: जलवायु परिवर्तन पर विशेषज्ञों की राय के अध्ययन में, शोधकर्ता केवल पर्यावरण वैज्ञानिकों और नीति निर्माताओं का चयन कर सकते हैं।
3. विभाजित या मिश्रित नमूनाकरण
विभाजित नमूनाकरण में जनसंख्या को विशिष्ट उप-समूहों (स्तर) में विभाजित किया जाता है और फिर प्रत्येक स्तर से यादृच्छिक रूप से नमूनाकरण किया जाता है। यह सुनिश्चित करता है कि सभी उप-समूहों का प्रतिनिधित्व किया जाए। जनसंख्या को आयु, लिंग, आय आदि जैसे लक्षणों के आधार पर विभाजित किया जाता है। प्रत्येक स्तर से एक यादृच्छिक नमूना निकाला जाता है।
- उदाहरण: एक शहर की जनसंख्या के सर्वेक्षण में, शहर को आयु समूहों (जैसे, 18-30, 31-50, 51+) में विभाजित किया जा सकता है और प्रत्येक समूह से प्रतिनिधित्व सुनिश्चित करने के लिए यादृच्छिक नमूना लिया जाता है।
4. प्रणालीबद्ध नमूनाकरण
प्रणालीबद्ध नमूनाकरण में जनसंख्या की सूची से हर nवें आइटम का चयन किया जाता है। एक प्रारंभिक बिंदु यादृच्छिक रूप से चुना जाता है, और फिर सूची में हर nवें आइटम को चुना जाता है।
- उदाहरण: 1000 नामों की सूची में, सूची में एक यादृच्छिक बिंदु से शुरू करके हर 10वें व्यक्ति का चयन किया जा सकता है।
5. क्लस्टर नमूनाकरण
क्लस्टर नमूनाकरण में जनसंख्या को क्लस्टर में विभाजित किया जाता है और फिर उन क्लस्टरों में से कुछ को यादृच्छिक रूप से चुना जाता है ताकि उन क्लस्टरों के सभी सदस्यों को शामिल किया जा सके। जनसंख्या को भौगोलिक या संगठनात्मक इकाइयों के रूप में क्लस्टरों में विभाजित किया जाता है। क्लस्टरों को यादृच्छिक रूप से चुना जाता है, और इन क्लस्टरों के सभी सदस्यों को नमूने में शामिल किया जाता है।
- उदाहरण: एक राष्ट्रीय सर्वेक्षण में, शहरों (क्लस्टर) को यादृच्छिक रूप से चुना जाता है, और उन शहरों के सभी निवासियों का सर्वेक्षण किया जाता है।
6. कोटा नमूनाकरण
कोटा नमूनाकरण में जनसंख्या को समूहों में विभाजित किया जाता है और फिर प्रत्येक समूह से नमूनों का चयन किया जाता है ताकि एक विशेष कोटा पूरा किया जा सके। यह विधि विभाजित नमूनाकरण के समान है लेकिन समूहों के भीतर यादृच्छिक चयन शामिल नहीं है। जनसंख्या को समूहों में विभाजित किया जाता है, और प्रत्येक समूह से निर्धारित संख्या के व्यक्तियों को शामिल करने तक नमूनों का चयन किया जाता है।
- उदाहरण: एक सर्वेक्षण को लिंग, आयु और पेशे के लिए विशेष कोटा के साथ 100 उत्तरदाताओं की आवश्यकता होती है। जब कोटा पूरे हो जाते हैं, तो नमूनाकरण बंद हो जाता है।
7. सुविधाजनक नमूनाकरण
सुविधाजनक नमूनाकरण में उन व्यक्तियों का चयन किया जाता है जो शोधकर्ता के लिए सबसे आसान होते हैं या जिन तक पहुंचना सबसे सुविधाजनक होता है। नमूना पहुंच के आधार पर चुना जाता है न कि यादृच्छिकता के आधार पर।
- उदाहरण: एक स्थानीय किराने की दुकान पर लोगों का सर्वेक्षण करना क्योंकि यह आसानी से सुलभ है, न कि व्यापक जनसंख्या तक पहुंचने का प्रयास करना।
नमूना डेटा की विश्वसनीयता
नमूना डेटा की विश्वसनीयता कई कारकों से प्रभावित हो सकती है:
नमूने का आकार: बड़े नमूने आमतौर पर जनसंख्या के अधिक विश्वसनीय अनुमान प्रदान करते हैं और नमूना त्रुटि को कम करते हैं।
नमूनाकरण की विधि: नमूनाकरण विधि का चुनाव यह प्रभावित करता है कि नमूना कितना प्रतिनिधि और पूर्वाग्रह रहित है। यादृच्छिक विधियाँ गैर-यादृच्छिक विधियों की तुलना में अधिक विश्वसनीय होती हैं।
संबंधित व्यक्तियों और गणक की कौशल: डेटा संग्रह करने वाले व्यक्तियों की दक्षता और क्षमता डेटा की विश्वसनीयता में महत्वपूर्ण भूमिका निभाती है। कुशल व्यक्ति अधिक सटीक और सुसंगत जानकारी एकत्रित करने की संभावना रखते हैं।
गणकों का प्रशिक्षण: उचित प्रशिक्षण यह सुनिश्चित करता है कि डेटा संग्रह समान रूप से और सही तरीके से किया जाए, जिससे त्रुटियों और पूर्वाग्रहों को कम किया जा सके।
डेटा संग्रह के लिए महत्वपूर्ण संगठन

डेटा संग्रह में सामान्य चुनौतियाँ क्या हैं?
डेटा संग्रह के दौरान कई सामान्य चुनौतियाँ सामने आती हैं। आइए इनमें से कुछ को समझते हैं ताकि हम इन्हें बेहतर तरीके से जान सकें और इनसे बच सकें।
- डेटा गुणवत्ता संबंधी मुद्दे: मशीन लर्निंग के व्यापक उपयोग को प्रभावित करने वाली मुख्य चुनौती खराब डेटा गुणवत्ता है। मशीन लर्निंग जैसी तकनीकों को प्रभावी बनाने के लिए डेटा गुणवत्ता सुनिश्चित करना महत्वपूर्ण है।
- असंगत डेटा: विभिन्न डेटा स्रोतों के साथ काम करते समय, समान जानकारी में भिन्नताएँ हो सकती हैं, जैसे प्रारूप, इकाइयाँ, या यहां तक कि वर्तनी। ये भिन्नताएँ कंपनी के विलय या स्थानांतरण के दौरान उत्पन्न हो सकती हैं। यदि असंगत डेटा को निरंतर नहीं संबोधित किया गया, तो यह समय के साथ डेटा के मूल्य को कम कर सकता है।
- डेटा ड downtime: डेटा डेटा-केंद्रित व्यवसायों के निर्णयों और संचालन के लिए महत्वपूर्ण है। हालाँकि, ऐसा हो सकता है कि डेटा कुछ समय के लिए अविश्वसनीय या अनुपलब्ध हो। डेटा की इस अनुपलब्धता के कारण ग्राहक शिकायतें और औसत विश्लेषणात्मक परिणाम हो सकते हैं।
- अस्पष्ट डेटा: सावधानीपूर्वक देखरेख के बावजूद, बड़ी डेटाबेस या डेटा लेक्स में त्रुटियाँ हो सकती हैं, विशेष रूप से तेजी से स्ट्रीमिंग डेटा के साथ। इन त्रुटियों में अनदेखी वर्तनी की गलतियाँ, प्रारूपिंग समस्याएँ, या भ्रामक कॉलम शीर्षक शामिल हो सकते हैं। अस्पष्ट डेटा रिपोर्टिंग और विश्लेषण के लिए विभिन्न चुनौतियाँ प्रस्तुत कर सकता है।
- डुप्लिकेट डेटा: आधुनिक व्यवसायों को स्ट्रीमिंग डेटा, स्थानीय डेटाबेस, और क्लाउड डेटा लेक्स का प्रबंधन करना होता है। इसके साथ ही, उनके पास एप्लिकेशन और सिस्टम साइलो भी हो सकते हैं, जिससे महत्वपूर्ण डुप्लिकेशन और ओवरलैप हो सकता है। उदाहरण के लिए, डुप्लिकेट संपर्क विवरण ग्राहक अनुभव पर बड़ा प्रभाव डाल सकते हैं।
- बहुत अधिक डेटा: जबकि डेटा-संचालित विश्लेषण और इसके लाभों पर जोर दिया जाता है, बहुत अधिक डेटा होना भी एक डेटा गुणवत्ता समस्या हो सकती है। विश्लेषणात्मक प्रयासों से संबंधित जानकारी की खोज करते समय बड़े डेटा के समुद्र में खो जाने का खतरा होता है।
- असत्यापित डेटा: स्वास्थ्य सेवा जैसे अत्यधिक विनियमित क्षेत्रों के लिए, डेटा की सटीकता आवश्यक है। COVID-19 और भविष्य की महामारी के लिए डेटा गुणवत्ता में सुधार करना महत्वपूर्ण है। असत्यापित जानकारी स्थिति का सटीक प्रतिनिधित्व नहीं करती और इसका उपयोग सर्वोत्तम पाठ्यक्रम की योजना बनाने के लिए नहीं किया जा सकता।
- छिपा हुआ डेटा: अधिकांश व्यवसाय अपने डेटा का केवल एक भाग ही उपयोग करते हैं, जबकि शेष कभी-कभी डेटा साइलो में खो जाता है या डेटा कब्रगाहों में फेंक दिया जाता है। नए उत्पाद विकसित करने, सेवाओं में सुधार करने, और प्रक्रियाओं को सरल बनाने के अवसरों को चूकना छिपे हुए डेटा के परिणाम हैं।
- संबंधित डेटा खोजना: संबंधित डेटा की पहचान हमेशा सीधी नहीं होती। संबंधित डेटा खोजने के लिए विभिन्न कारकों पर विचार करना पड़ता है, जैसे डोमेन प्रासंगिकता, जनसांख्यिकी, और समय अवधि। यदि डेटा इन पहलुओं में से किसी में भी अप्रासंगिक है, तो यह अप्रचलित हो जाता है और प्रभावी विश्लेषण में बाधा डालता है।
- संग्रह करने के लिए डेटा का निर्णय लेना: यह निर्धारित करना कि किस डेटा को संग्रह करना है, डेटा संग्रह का एक महत्वपूर्ण पहलू है और इसे प्राथमिकता दी जानी चाहिए। डेटा के विषयों, डेटा स्रोतों, और आवश्यक जानकारी के संबंध में निर्णय डेटा उपयोग के लक्ष्यों या उद्देश्यों पर निर्भर करते हैं।
- बिग डेटा से निपटना: बिग डेटा में अत्यधिक बड़े और जटिल डेटा सेट शामिल होते हैं, जो संग्रहण, विश्लेषण, और परिणाम प्राप्त करने में चुनौतियाँ प्रस्तुत करते हैं। पारंपरिक डेटा प्रसंस्करण उपकरण बिग डेटा को प्रभावी ढंग से संभालने के लिए पर्याप्त नहीं हो सकते हैं।
- कम प्रतिक्रिया और अन्य शोध मुद्दे: खराब डिज़ाइन और कम प्रतिक्रिया दर डेटा संग्रह में चुनौतियों के रूप में पहचानी जाती हैं, विशेष रूप से प्रश्नावली का उपयोग करने वाले स्वास्थ्य सर्वेक्षणों में। एक प्रोत्साहक डेटा संग्रह कार्यक्रम स्थापित करने से प्रतिक्रिया दरों में सुधार करने में मदद मिल सकती है।
संक्षेप में, उच्च गुणवत्ता वाले डेटा का संग्रह सटीक विश्लेषण और निर्णय लेने के लिए आवश्यक है। डेटा की निरंतरता, सटीकता, और विश्वसनीयता सुनिश्चित करने के लिए उचित विधियों का चयन करें और नियमित रूप से डेटा को साफ करें ताकि त्रुटियों और डुप्लिकेट को हटाया जा सके। डेटा संग्रहकर्ताओं को उचित प्रशिक्षण देना उच्च मानकों को बनाए रखने में मदद करता है, और उन्नत उपकरणों का उपयोग बड़े डेटा सेट को कुशलतापूर्वक प्रबंधित कर सकता है। प्रभावी डेटा प्रबंधन जानकारी को आसानी से सुलभ और मूल्यवान बनाता है, जिससे इसकी समग्र उपयोगिता बढ़ती है।
|
374 videos|1072 docs|1174 tests
|
FAQs on डेटा का संग्रहण - SSC CGL Tier 2 - Study Material, Online Tests, Previous Year (Hindi)
| 1. प्राथमिक और द्वितीयक डेटा में क्या भिन्नताएँ हैं? |  |
| 2. डेटा संग्रहण में सामान्य चुनौतियाँ क्या हैं? | |
| 3. SSC CGL परीक्षा में डेटा संग्रहण से संबंधित प्रश्न कैसे तैयार करें? | |
| 4. प्राथमिक डेटा संग्रहण के फायदे क्या हैं? | |
| 5. द्वितीयक डेटा का उपयोग कब करना चाहिए? | |



Online Tests
,Previous Year (Hindi)
,practice quizzes
,डेटा का संग्रहण | SSC CGL Tier 2 - Study Material
,Free
,Online Tests
,study material
,Important questions
,Extra Questions
,MCQs
,Semester Notes
,डेटा का संग्रहण | SSC CGL Tier 2 - Study Material
,mock tests for examination
,Exam
,shortcuts and tricks
,past year papers
,ppt
,Previous Year Questions with Solutions
,Previous Year (Hindi)
,video lectures
,Objective type Questions
,Online Tests
,Viva Questions
,डेटा का संग्रहण | SSC CGL Tier 2 - Study Material
,Previous Year (Hindi)
,Summary
,Sample Paper
;


डेटा का संग्रहण Free PDF Download
Importance of डेटा का संग्रहण
डेटा का संग्रहण Notes
डेटा का संग्रहण SSC CGL Questions
Study डेटा का संग्रहण on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!