Genetic Code | Biology for EmSAT Achieve PDF Download

What is a Genetic Code?
The genetic code can be defined as the set of certain rules using which the living cells translate the information encoded within genetic material (DNA or mRNA sequences). The ribosomes are responsible to accomplish the process of translation. They link the amino acids in an mRNA-specified (messenger RNA) order using tRNA (transfer RNA ) molecules to carry amino acids and to read the mRNA three nucleotides at a time.
Genetic Code Table
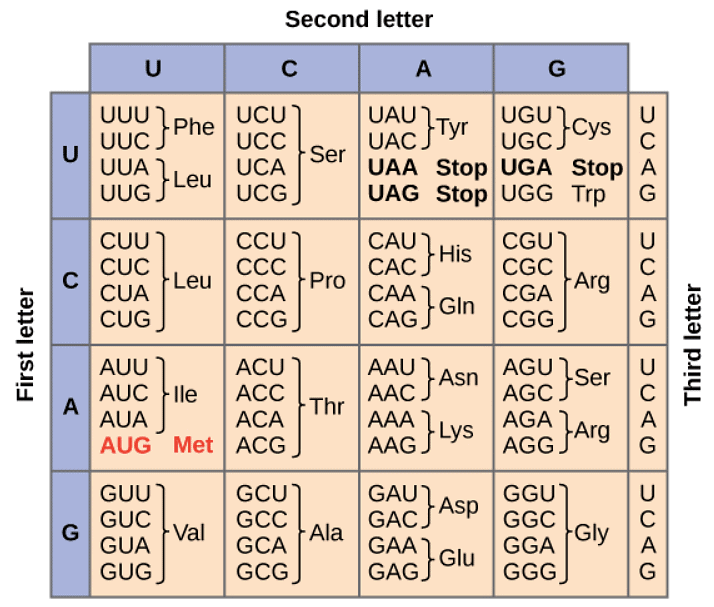
The complete set of relationships among amino acids and codons is said to be a genetic code which is often summarized in a table.
It can be seen that many amino acids are shown in the table by more than one codon. For example, there are six ways to write leucine in mRNA language.
Note: A codon is a sequence of three nucleotides which together form a unit of genetic code in a DNA or RNA molecule.
A key point of the genetic code is its universal nature. This indicates that virtually all species with minor exceptions use the genetic code for protein synthesis.
In other words, genetic code is defined as the nucleotide sequence of the base on DNA which is translated into a sequence of amino acids of the protein to be synthesized.
Properties of Genetic Code
- Triplet code
- Non-ambiguous and Universal
- Degenerate code
- Nonoverlapping code
- Commaless
- Start and Stop Codons
- Polarity
1. Triplet Code
A codon or a code word is defined as a group of bases that specify an amino acid. There is strong evidence, which proves that a sequence of three nucleotides codes for an amino acid in the protein, i.e., the code is a triplet.
The four bases of nucleotide i.e, (A, G, C, and U) are used to produce three-base codons. The 64 codons involve sense codons (that specify amino acids). Hence, there are 64 codons for 20 amino acids since every codon for one amino acid means that there exist more than code for the same amino acid.
2. Commaless Code
No room for punctuation in between which indicates that every codon is adjacent to the previous one without any nucleotides between them.
3. Non-overlapping Code
The code is read sequentially in a group of three and a nucleotide which becomes a part of triplet never becomes part of the next triplet.
For example:
5’-UCU-3’ codes for Serine
5’-AUG-3’ codes for methionine
4. Polarity
Each triplet is read from 5’ → 3’ direction and the beginning base is 5’ followed by the base in the middle then the last base which is 3’. This implies that the codons have a fixed polarity and if the codon is read in the reverse direction, the base sequence of the codon would reverse and would specify two different proteins.
5. Degenerate Code
Every amino acid except tryptophan (UGG) and methionine (AUG) is coded by various codons, i.e, a few codons are synonyms and this aspect is known as the degeneracy of genetic code. For instance, UGA codes for tryptophan in yeast mitochondria.
6. Start and Stop Codons
Generally, AUG codon is the initiating or start codon. The polypeptide chain starts either with eukaryotes (methionine) or prokaryotes (N- formylmethionine).
On the other hand, UAG, UAA and UGA are called as termination codons or stop codons. These are not read by any tRNA molecules and they never code for any amino acids.
7. Non-ambiguous and Universal
The genetic code is non-ambiguous which means a specific codon will only code for a particular amino acid. Also, the same genetic code is seen valid for all the organisms i.e. they are universal.
Exceptions to the Code
The genetic code is universal since similar codons are assigned to identical amino acids along with similar START and STOP signals in the majority of genes in microorganisms and plants. However, a few exceptions have been discovered and most of these include assigning one or two of the STOP codons to an amino acid.
Apart from this, both the codons GUG and AUG may code for methionine as a starting codon, although GUG is meant for valine. This breaks the property of non-ambiguousness. Thus, it can be said that few codes often differs from the universal code or non-ambiguous code.
|
157 videos|173 docs|136 tests
|
FAQs on Genetic Code - Biology for EmSAT Achieve
| 1. What is the genetic code? |  |
| 2. How is the genetic code read? | |
| 3. Can the genetic code be altered or mutated? | |
| 4. Are all organisms' genetic codes the same? | |
| 5. How does the genetic code contribute to genetic diseases? | |



Previous Year Questions with Solutions
,Extra Questions
,Viva Questions
,shortcuts and tricks
,study material
,Summary
,past year papers
,ppt
,Genetic Code | Biology for EmSAT Achieve
,video lectures
,Free
,Exam
,Semester Notes
,Genetic Code | Biology for EmSAT Achieve
,Important questions
,Genetic Code | Biology for EmSAT Achieve
,mock tests for examination
,MCQs
,Objective type Questions
,practice quizzes
,Sample Paper
;


Genetic Code Free PDF Download
Importance of Genetic Code
Genetic Code Notes
Genetic Code EmSAT Achieve Questions
Study Genetic Code on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!