Amazon Web Services - Data Pipeline | Introduction to Amazon Web Services(AWS) - Software Development PDF Download

AWS Data Pipeline is a web service, designed to make it easier for users to integrate data spread across multiple AWS services and analyze it from a single location.
Using AWS Data Pipeline, data can be accessed from the source, processed, and then the results can be efficiently transferred to the respective AWS services.
How to Set Up Data Pipeline?
Following are the steps to set up data pipeline −
Step 1 − Create the Pipeline using the following steps.
Sign-in to AWS account.
Use this link to Open AWS Data Pipeline console − https://console.aws.amazon.com/datapipeline/
Select the region in the navigation bar.
Click the Create New Pipeline button.
Fill the required details in the respective fields.
In the Source field, choose Build using a template and then select this template − Getting Started using ShellCommandActivity.
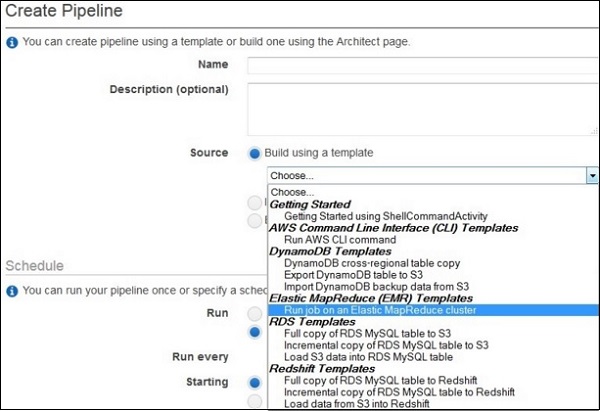
The Parameters section opens only when the template is selected. Leave the S3 input folder and Shell command to run with their default values. Click the folder icon next to S3 output folder, and select the buckets.
In Schedule, leave the values as default.
In Pipeline Configuration, leave the logging as enabled. Click the folder icon under S3 location for logs and select the buckets.
In Security/Access, leave IAM roles values as default.
Click the Activate button.
How to Delete a Pipeline?
Deleting the pipeline will also delete all associated objects.
Step 1 − Select the pipeline from the pipelines list.
Step 2 − Click the Actions button and then choose Delete.
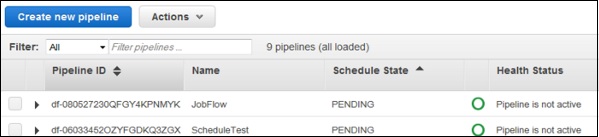
Step 3 − A confirmation prompt window opens. Click Delete.
Features of AWS Data Pipeline
Simple and cost-efficient − Its drag-and-drop features makes it easy to create a pipeline on console. Its visual pipeline creator provides a library of pipeline templates. These templates make it easier to create pipelines for tasks like processing log files, archiving data to Amazon S3, etc.
Reliable − Its infrastructure is designed for fault tolerant execution activities. If failures occur in the activity logic or data sources, then AWS Data Pipeline automatically retries the activity. If the failure continues, then it will send a failure notification. We can even configure these notification alerts for situations like successful runs, failure, delays in activities, etc.
Flexible − AWS Data Pipeline provides various features like scheduling, tracking, error handling, etc. It can be configured to take actions like run Amazon EMR jobs, execute SQL queries directly against databases, execute custom applications running on Amazon EC2, etc.



Extra Questions
,MCQs
,Amazon Web Services - Data Pipeline | Introduction to Amazon Web Services(AWS) - Software Development
,video lectures
,Amazon Web Services - Data Pipeline | Introduction to Amazon Web Services(AWS) - Software Development
,study material
,Objective type Questions
,Previous Year Questions with Solutions
,Amazon Web Services - Data Pipeline | Introduction to Amazon Web Services(AWS) - Software Development
,Sample Paper
,past year papers
,mock tests for examination
,Exam
,Free
,Summary
,shortcuts and tricks
,Viva Questions
,practice quizzes
,Semester Notes
,ppt
,Important questions
;






Amazon Web Services - Data Pipeline Free PDF Download
Importance of Amazon Web Services - Data Pipeline
Amazon Web Services - Data Pipeline Notes
Amazon Web Services - Data Pipeline Software Development Questions
Study Amazon Web Services - Data Pipeline on the App
|
© EduRev
|
Education Revolution
|



|






