Introduction
Data collection is the process of gathering information in an organized way to gain useful insights. For SSC CGL Tier 2 exam aspirants, understanding data collection is important because it is a key part of the exam. Data collection is a crucial step in any research process, providing the foundation for analysis and interpretation. It involves gathering information to answer specific questions, test hypotheses, and evaluate outcomes. The quality of data collected directly impacts the reliability and validity of research findings. This chapter explores the different sources of data, the types of data available, and the statistical methods used for data collection, along with their merits and demerits.

Sources of Data
Data can be gathered from two main sources: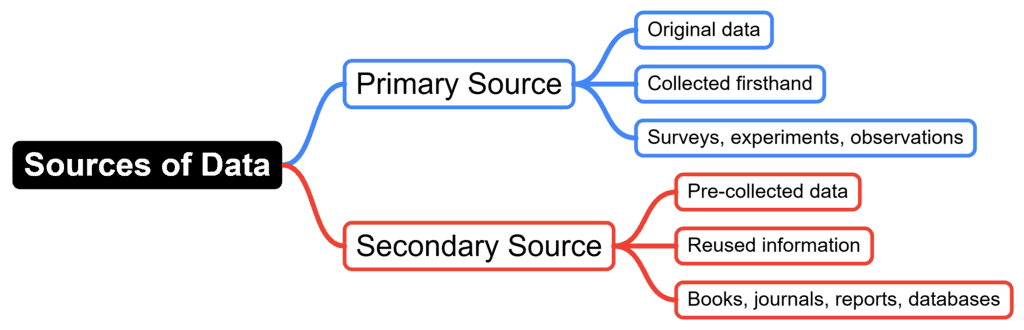
Primary Source of Data
- Definition: Primary data is original data collected directly from its source by the researcher for a specific research purpose.
- Example: Data collected through surveys, experiments, or direct observations conducted by the researcher.
Secondary Source of Data
- Definition: Secondary data is data that has already been collected by someone else and is available for use.
- Example: Data from books, journals, government reports, and databases created by other researchers or institutions.
Differences Between Primary and Secondary Data
Aspect | Primary Data | Secondary Data |
|---|
Originality | Original and collected firsthand | Already exists and can be readily accessed |
Specificity | Specific to the researcher’s current study and tailored to research needs | May not perfectly match the researcher’s specific needs and may require adjustment or additional context |
Cost and Time | Expensive and time-consuming, requiring significant resources and effort | Generally less expensive and quicker compared to collecting primary data |
Question for Collection of Data
Try yourself:What is the primary source of data?
Explanation
Primary data refers to the first hand data gathered by the researcher himself.
Surveys, observations, experiments, questionnaire, personal interview, etc.
Report a problem
Statistical Methods of Data Collection
1. Direct Personal Investigation: The investigator personally collects data from the respondents through direct interaction. This method ensures that the data is accurate and reliable due to the investigator's close involvement.
 Merits:
Merits:- Originality: Data collected is original and unique.
- Reliability: Direct collection ensures high reliability and accuracy.
- Accuracy: Detailed and precise information is obtained.
- Detailed Information: In-depth data can be gathered.
- Elasticity: The method is flexible and adaptable to various situations.
Demerits:
- Coverage Limitation: Difficult to cover large or dispersed populations.
- Cost: Often costly due to the resources required.
- Personal Bias: Investigator’s biases can influence the data.
- Limited Scope: May not cover all necessary areas due to time and resource constraints.
2. Indirect Oral Investigation
Data is collected from knowledgeable individuals or experts who provide information based on their experience. This method relies on the respondent’s ability to provide accurate information.
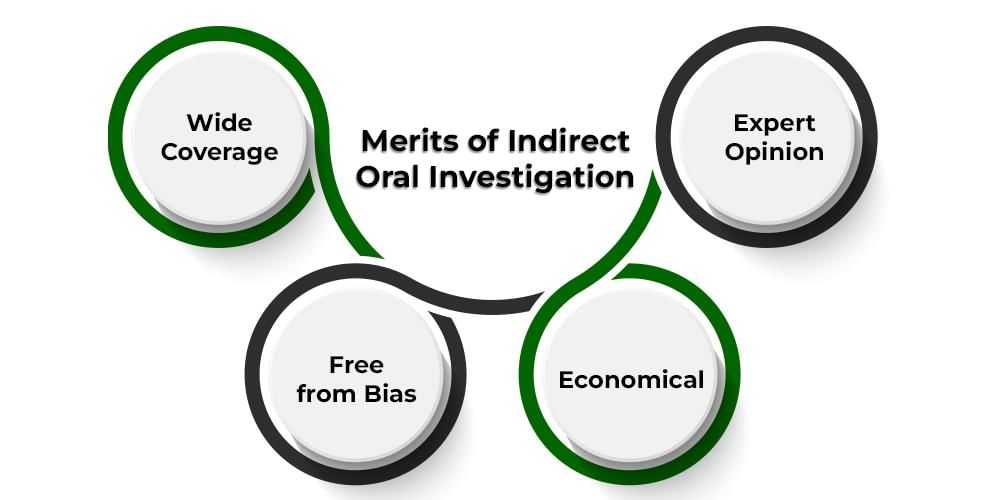
Merits:
- Wide Coverage: Can gather information from a broad area.
- Rapid Collection: Quick way to collect data.
- Cost-Effective: Generally less expensive than direct methods.
- Bias-Free: Reduces the risk of investigator bias.
Demerits:
- Accuracy Issues: Data may be less accurate due to reliance on second-hand information.
- Bias in Responses: Respondents may have their own biases.
- General Conclusions: Information may lack detail and specificity.
3.Information from Local Sources or Correspondents
Local correspondents or individuals are appointed to gather data from different locations. This method is often used when information is needed from multiple regions.

Merits:
- Economical: Cost-effective compared to extensive fieldwork.
- Wide Coverage: Capable of covering large geographical areas.
- Continuity: Provides ongoing data collection.
- Special Purposes: Suitable for specific, localized studies.
Demerits:
- Originality Loss: Data may lose originality due to being second-hand.
- Lack of Uniformity: Variability in data quality and collection methods.
- Personal Bias: Correspondents' biases can affect data quality.
4.Information Through Questionnaires and Schedules
Data is collected using questionnaires and schedules mailed to informants or administered by enumerators.

(a) Mailing Method: Suitable when:
- The area of study is large.
- Informants are educated.
(b) Enumerator’s Method: Suitable when:
- The investigation requires detailed and skilled investigation.
- The investigator needs to be well-versed in the local language and cultural norms.
Factors to Consider:
- Ability of the collecting organization
- Objective and scope
- Method of collection
- Time and condition of organization
- Definition of the unit
- Accuracy
5.Census Method
Data is collected covering every item of the population related to the problem under investigation.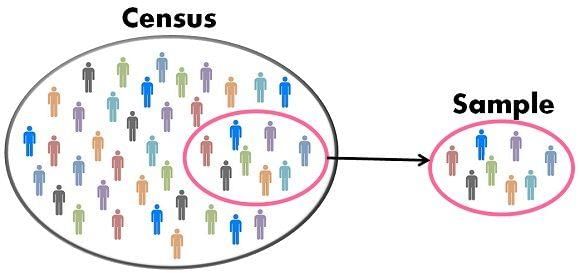
Merits:
- Reliable and accurate
- Less biased
- Extensive information
- Study of diverse characteristics
- Suitable for complex investigation
- Indirect investigation
Demerits:
- Costly
- Large manpower needed
- Not suitable for large-scale investigations
6.Sample Method
Data is collected about a sample, and conclusions are drawn about the entire population based on the sample.
Merits:
- Economical
- Time-saving
- Information error reduction
- Large investigations possible
- Administrative convenience
- More scientific
Demerits:
- Partial conclusions
- Possible wrong conclusions
- Difficulty in selecting a representative sample
- Specialized knowledge required
Question for Collection of Data
Try yourself:
Which method of data collection involves collecting data from respondents through direct interaction with the investigator?Explanation
- Direct Personal Investigation involves the investigator collecting data directly from the respondents through personal interaction, ensuring accuracy and reliability.
Report a problem
Sampling Methods
 1. Random Sampling
1. Random Sampling
Random sampling ensures that every member of a population has an equal chance of being selected. This method minimizes selection bias and ensures representativeness.
(a)Lottery Method:
Each member of the population is assigned a unique number. Numbers are then randomly drawn to select the sample.
Example: In a class of 30 students, each student is assigned a number from 1 to 30. Numbers are drawn randomly to select 5 students for a survey.
Tables of Random Numbers:
- Description: A pre-generated table of random numbers is used to select members from the population.
- Example: Using a table, a researcher might randomly select students from a list of 100 based on random numbers that fall within the list.
2. Purposeful or Deliberate Sampling
Purposeful sampling involves selecting specific individuals based on certain criteria deemed important for the study. This is often used when specific insights are required. The researcher identifies individuals who are thought to have particular knowledge or experience relevant to the study.
Example: In a study about expert opinions on climate change, researchers might only select environmental scientists and policy makers.
3. Stratified or Mixed Sampling
Stratified sampling involves dividing the population into distinct sub-groups (strata) and then randomly sampling from each stratum. This ensures that all sub-groups are represented.
The population is divided based on characteristics like age, gender, income, etc. A random sample is drawn from each stratum.
- Example: In a survey of a city's population, the city might be divided into age groups (e.g., 18-30, 31-50, 51+) and a random sample taken from each group to ensure representation across all ages.
4. Systematic Sampling
Systematic sampling involves selecting every nth item from a list of the population. A starting point is selected at random, and then every nth item in the list is chosen.
- Example: In a list of 1000 names, every 10th person might be selected for a survey, starting from a random point in the list.
5. Cluster Sampling
Cluster sampling involves dividing the population into clusters and then randomly selecting some clusters to include all members from those clusters. The population is divided into clusters, which could be geographic or organizational units. Clusters are randomly chosen, and all members of these clusters are included in the sample.
- Example: In a national survey, cities (clusters) are randomly selected, and all residents within those cities are surveyed.
6. Quota Sampling
Quota sampling involves dividing the population into groups and then selecting samples from each group to meet a specific quota. This method is similar to stratified sampling but does not involve random selection within groups. The population is segmented into groups, and samples are taken until a pre-set number of individuals from each group are included.
- Example: A survey requires 100 respondents with specific quotas for gender, age, and occupation. Once quotas are met, sampling stops.
7. Convenience Sampling
Convenience sampling involves selecting individuals who are easiest to reach or most convenient for the researcher. The sample is chosen based on ease of access rather than randomness.
- Example: Surveying people at a local grocery store because it is easily accessible, rather than attempting to reach a broader population.
|
|
Download the notes
Collection of Data
|
Download as PDF
|
Reliability of Sampling Data
The reliability of sampling data can be influenced by several factors:
Size of the Sample: Larger samples generally provide more reliable estimates of the population and reduce sampling error.
Method of Sampling: The choice of sampling method impacts how representative and unbiased the sample is. Random methods tend to be more reliable compared to non-random methods.
Skills of Correspondents and Enumerators: The effectiveness and competence of those collecting the data play a crucial role in data reliability. Skilled individuals are more likely to gather accurate and consistent information.
Training of Enumerators: Proper training ensures that data collection is done uniformly and correctly, minimizing errors and biases.
|
|
Take a Practice Test
Test yourself on topics from SSC CGL exam
|
Practice Now
|
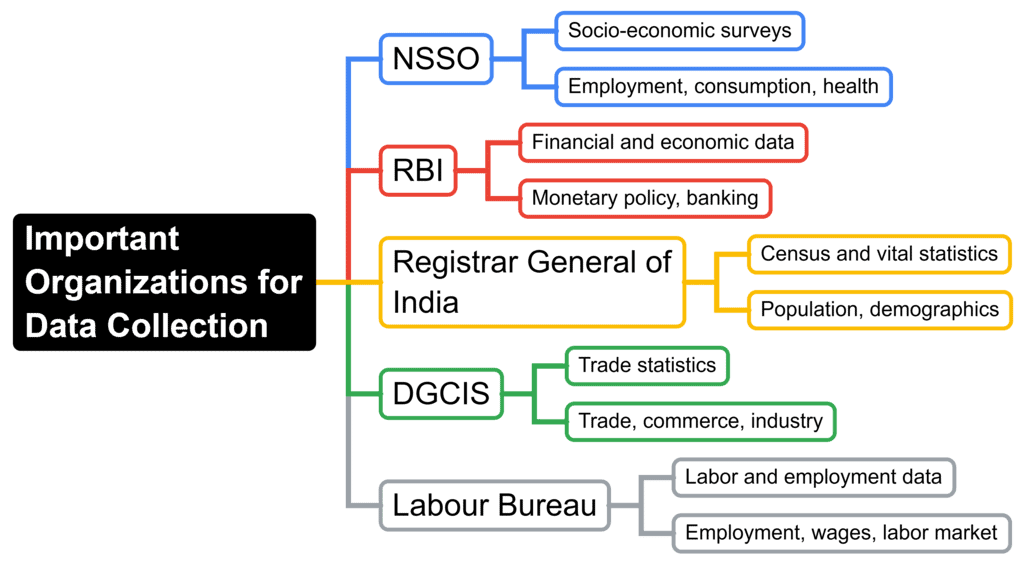
Important Organizations for Data Collection
Question for Collection of Data
Try yourself:
Which sampling method involves dividing the population into distinct sub-groups and then randomly sampling from each stratum?Explanation
- Stratified sampling involves dividing the population into distinct sub-groups (strata) and then randomly sampling from each stratum. This method ensures that all sub-groups are represented and helps in obtaining a more accurate representation of the population.
Report a problem
What are Common Challenges in Data Collection?
There are some prevalent challenges faced while collecting data, let us explore a few of them to understand them better and avoid them.
- Data Quality Issues: The main challenge affecting the widespread use of machine learning is poor data quality. To make technologies like machine learning effective, it is important to focus on ensuring data quality.
- Inconsistent Data: When dealing with different data sources, there can be variations in the same information, such as formats, units, or even spellings. These variations can occur during company mergers or relocations. If inconsistent data is not addressed consistently, it can diminish the value of the data over time.
- Data Downtime: Data is vital for the decisions and operations of data-centric businesses. However, there may be brief periods when data is unreliable or unavailable. This unavailability of data can lead to customer complaints and subpar analytical results.
- Ambiguous Data: Even with careful oversight, errors can occur in large databases or data lakes, particularly with rapidly streaming data. These errors can involve unnoticed spelling mistakes, formatting issues, or misleading column headings. Unclear data can pose various challenges for reporting and analytics.
- Duplicate Data: Modern businesses have to manage streaming data, local databases, and cloud data lakes. They may also have application and system silos, leading to significant duplication and overlap. Duplicate contact details, for instance, can greatly impact the customer experience.
- Too Much Data: While the emphasis is on data-driven analytics and its advantages, having too much data can be a data quality issue. There is a risk of getting lost in a large volume of data when searching for information relevant to analytical efforts.
- Inaccurate Data: For heavily regulated sectors like healthcare, data accuracy is essential. Improving data quality for situations like COVID-19 and future pandemics is crucial. Inaccurate information does not provide an accurate representation of the situation and cannot be used to plan the best course of action.
- Hidden Data: Most businesses utilize only a portion of their data, with the remainder sometimes lost in data silos or discarded in data graveyards. Missing opportunities to develop new products, enhance services, and streamline processes are consequences of hidden data.
- Finding Relevant Data: Identifying relevant data is not always straightforward. Various factors need to be considered when trying to find relevant data, such as domain relevance, demographics, and time period. Data that is irrelevant in any of these aspects becomes obsolete and hinders effective analysis.
- Deciding the Data to Collect: Determining what data to collect is a crucial aspect of data collection and should be prioritized. Choices regarding the subjects covered by the data, data sources, and required information depend on the goals or objectives of data usage.
- Dealing With Big Data: Big data involves extremely large and complex data sets, posing challenges in storage, analysis, and deriving results. Traditional data processing tools may not be adequate for handling big data effectively.
- Low Response and Other Research Issues: Poor design and low response rates are identified as challenges in data collection, particularly in health surveys using questionnaires. Establishing an incentivized data collection program can help improve response rates.
In conclusion, collecting high-quality data is essential for accurate analysis and decision-making. Ensure data consistency, accuracy, and reliability by choosing appropriate methods and regularly cleaning the data to remove errors and duplicates. Properly training data collectors helps maintain high standards, and using advanced tools can efficiently manage large data sets. Effective data management makes information easily accessible and valuable, enhancing its overall usability.



























