Previous Year Questions: Syntax-directed Translation | Compiler Design - Computer Science Engineering (CSE) PDF Download

Q1: Which of the following statements is/are FALSE? (2024 SET 2)
(a) An attribute grammar is a syntax-directed definition (SDD) in which the functions in the semantic rules have no side effects
(b) The attributes in a L-attributed definition cannot always be evaluated in a depth- first order
(c) Synthesized attributes can be evaluated by a bottom-up parser as the input is parsed
(d) All L-attributed definitions based on LR(1) grammar can be evaluated using a bottom-up parsing strategy
Ans: (b, d)
Sol: There is no fixed procedure of evaluating L-attribute in a depth-first order. Hence, option B is correct.
However, there is a fixed procedure which all L-attributed definitions based on LR(1) grammar can be evaluated using a bottom-up parsing strategy. Hence, Option D is correct.
Therefore, B and D are correct
Q2: Consider the following syntax-directed definition (SDD). (2024 SET 1)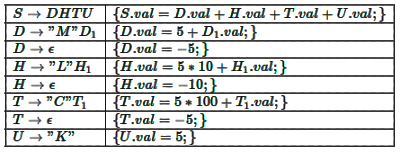 Given "MMLK" as the input, which one of the following options is the CORRECT value computed by the SDD (in the attribute S.val)?
Given "MMLK" as the input, which one of the following options is the CORRECT value computed by the SDD (in the attribute S.val)?
(a) 45
(b) 50
(c) 55
(d) 65
Ans: (a)
Sol: 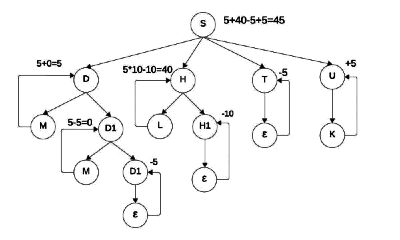
So the output of the given SDT is 45.
Option (A) is correct.
Q3: Consider the syntax directed translation given by the following grammar and semantic rules. Here N , I , F and B are non-terminals. N is the starting non-terminal, and # , 0 and1 are lexical tokens corresponding to input letters " # " , " 0 " a n d " 1 " , respectively. X . val denotes the synthesized attribute (a numeric value) associated with a non-terminal X . I1 and F1 denote occurrences of I and F on the right hand side of a production, respectively. For the tokens 0 and 1, 0. v a l = 0 and 1. v a l = 1. (2023)
The value computed by the translation scheme for the input string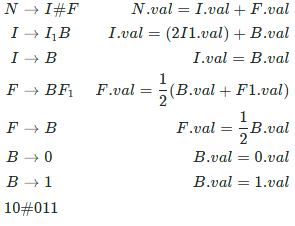 is ____ (Rounded off to three decimal places)
is ____ (Rounded off to three decimal places)
(a) 5.324
(b) 2.375
(c) 6.215
(d) 8.257
Ans: (b)
Sol: 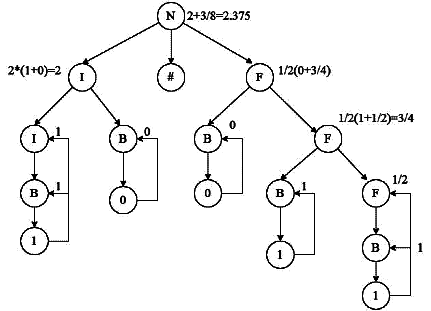
The correct answer is 2.375
Q4: Consider the following ANSI C program: (2021 SET 2)
Which one of the following phases in a seven-phase C compiler will throw an error?
(a) Lexical analyzer
(b) Syntax analyzer
(c) Semantic analyzer
(d) Machine dependent optimizer
Ans: (c)
Sol: This question is difficult to answer from a practical point of view because most of the C compilers (even other language compilers) do not follow the classical ordering of compilation phases. Since this is a one-mark question ignoring the practical implementations and going by just theory answer will be syntax error. Because there are no lexical errors and “Integer” and “x” get read as identifiers as shown in the following output.

Now, when this stream of tokens get passed to the syntax analyzer – we have an identifier followed by another identifier which is not valid in C syntax – so syntax error. And this must be the answer here though we can argue for semantic error as well as follows.
Now consider a typedef usage like “typedef int Integer”. Now, this can be implemented by the compiler in multiple ways. One option is to immediately change the token type of “Integer” from identifier to the given “type”. Otherwise the syntax check can go with the AST generation. But if we go by the classical meaning of the compilation phases here we are matching a string which means it is a semantic phase.
Correct Answer: Syntax Analysis/Semantic analysis
The following three flags will force cc (C compiler) to check that your code complies to the relevant international standard, often referred to as the ANSI standard, though strictly speaking it is an ISO standard.
- -Wall
Enable all the warnings which the authors of cc believe are worthwhile. Despite the name, it will not enable all the warnings cc is capable of.
- -ansi
Turn off most, but not all, of the non-ANSI C features provided by cc. Despite the name, it does not guarantee strictly that your code will comply to the standard
- -pedantic
Turn off all cc's non-ANSI C features.
Without these flags, cc will allow you to use some of its non-standard extensions to the standard. Some of these are very useful, but will not work with other compilers—in fact, one of the main aims of the standard is to allow people to write code that will work with any compiler on any system. This is known as portable code.
Q5: Consider the following grammar (that admits a series of declarations, followed by expressions) and the associated syntax directed translation (SDT) actions, given as pseudo-code (2021 SET 1)
P → D ∗ E ∗
D → int ID { record that ID. lexeme is of type int}
D → bool ID { record that ID. lexeme is of type bool}
E → E1 + E2 { check that E1 . type = E2 . type = int ; set E . type : = int }
E → ! E1 { check that E1 . type = bool ; set E . type : = bool }
E → ID { set E . type : = int }|
With respect to the above grammar, which one of the following choices is correct?
(a) The actions can be used to type-check syntactically correct integer variable declarations and integer expressions
(b) The actions can be used to correctly type-check any syntactically correct program
(c) The actions can be used to type-check syntactically correct boolean variable declarations and boolean expressions.
(d) The actions will lead to an infinite loop
Ans: (a)
Sol: The correct option is A The actions can be used to type-check syntactically correct integer variable declarations and integer expressions. 1. P → D ∗ E ∗
2. D → int ID {record that ID. lexeme is of type int}
3. D → bool ID {record that ID. lexeme is of type bool}
4. E → E1 + E2 { check that E1 . t y p e = E2 . t y p e = int; set E.type = int }
5. E → ! E1 { check that E1 . type = bool;set E.type = bool }
6. E → I D {set E. type = int}
Rules 2 and 3 are used for entry into the symbol table. Rule 4 is used for type checking of the integer expression. But, in rule 6 only int type is set.
Hence answer is option (a).
Q6: Consider the following grammar and the semantic actions to support the inherited type declaration attributes. Let X1 , X2 , X3 , X4 , X5 and X6 be the placeholders for the non-terminals D, T, L or L1 in the following table: (2019)
Which one of the following are the appropriate choices for X1 , X2 , X3 and X4 ?
(a) X1 = L, X2 = T, X3 = L1, X4 = L
(b) X1 = T, X2 = L, X3 =L1, X4 = T
(c) X1 = L, X2 = L, X 3 = L1, X4 = T
(d) X1 = T, X2 = L, X3 = T, X4 = L1
Ans: (a)
Sol: A node in a parse tree can INHERIT an attribute either from its parent or its siblings. This means for a production
S → AB,
A can inherit values from either S or B and similarly B can inherit values from either S or A.
In the given productions, for
L → L1 , i d ,
L1 can inherit from L or , or id with only L being a non-terminal.
So, this means X3 must be L1 and X4 must be L as Xi is a placeholder for non-terminals.
Only option A matches this.
Q7: Which one of the following statements is FALSE? (2018)
(a) Context-free grammar can be used to specify both lexical and syntax rules.
(b) Type checking is done before parsing.
(c) High-level language programs can be translated to different Intermediate Representations.
(d) Arguments to a function can be passed using the program stack
Ans: (b)
Sol: A. Since Lexical rules are nothing but regular expressions, we can use CFGs to represent such rules.(Every Type-3grammar is Type-2
grammar) Additionally, syntax rules can be represented by CFGs. (True)
B. Type checking is done during Semantic Analysis phase which comes after Parsing. (False)
C. We have various types of Intermediate Code Representations, ex 3-address code, Postfix notation, Syntax trees. (True)
D. Program stack holds the activation record of the function called, which stores function parameters, return value, return address etc.(True)
Correct Answer: B
|
26 videos|67 docs|30 tests
|
FAQs on Previous Year Questions: Syntax-directed Translation - Compiler Design - Computer Science Engineering (CSE)
| 1. What is syntax-directed translation? |  |
| 2. How does syntax-directed translation differ from syntax-directed parsing? | |
| 3. What are the phases involved in syntax-directed translation? | |
| 4. How does syntax-directed translation help in code optimization? | |
| 5. Can syntax-directed translation be used in other applications besides compilers? | |



Objective type Questions
,Previous Year Questions: Syntax-directed Translation | Compiler Design - Computer Science Engineering (CSE)
,Previous Year Questions: Syntax-directed Translation | Compiler Design - Computer Science Engineering (CSE)
,Extra Questions
,practice quizzes
,Semester Notes
,study material
,Important questions
,Free
,MCQs
,past year papers
,Summary
,video lectures
,Viva Questions
,ppt
,mock tests for examination
,shortcuts and tricks
,Sample Paper
,Exam
,Previous Year Questions: Syntax-directed Translation | Compiler Design - Computer Science Engineering (CSE)
,Previous Year Questions with Solutions
;






Previous Year Questions: Syntax-directed Translation Free PDF Download
Importance of Previous Year Questions: Syntax-directed Translation
Previous Year Questions: Syntax-directed Translation Notes
Previous Year Questions: Syntax-directed Translation Computer Science Engineering (CSE)
Study Previous Year Questions: Syntax-directed Translation on the App
|
© EduRev
|
Education Revolution
|



|





