Computer Vision Chapter Notes | Artificial Intelligence for Class 10 PDF Download
| Table of contents |
|
| Introduction |
|
| Applications of Computer Vision |
|
| Introduction to Computer Vision |
|
| Image Features |
|
| Introduction to OpenCV |
|
| Convolution |
|
| Understanding Convolutional Neural Networks (CNNs) |
|

Introduction
- In the previous chapter, you learned about how Artificial Intelligence (AI) is used in Data Sciences to bring together various methods like statistics, data analysis, and machine learning. The goal is to understand and analyze real-world situations using data.
- Artificial intelligence involves teaching computers to imitate human intelligence. Just like humans can see, analyze, and take action based on what they see, machines can also be trained to do this.
- This brings us to the field of Computer Vision within Artificial Intelligence. Computer Vision allows machines to "see" and understand images or visual data. Using algorithms and specific methods, computers can process and analyze these visuals to gain insights about real-world phenomena, similar to how humans would.
Applications of Computer Vision
Computer vision, a concept introduced in the 1970s, has seen remarkable advancements over the years, making various applications accessible and practical today. Recent technological leaps have further prioritized computer vision across different industries. Let's explore some of its key applications:
Facial Recognition: Computer vision is crucial in smart cities and homes, particularly for security purposes. It enables facial recognition for guest identification and visitor log maintenance. Additionally, schools utilize facial recognition systems for student attendance.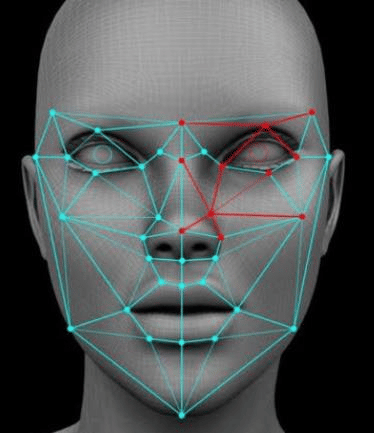
Face Filters: Apps like Instagram and Snapchat employ computer vision for face filters. These applications analyze facial features in real-time and apply selected filters based on facial dynamics.
Google’s Search by Image: While most searches on Google are text-based, the search by image feature utilizes computer vision. It compares features of the input image with a database of images to provide relevant search results.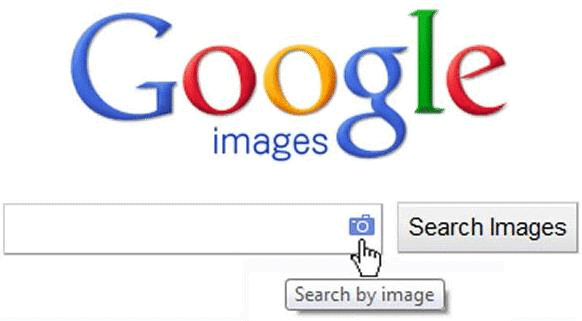
Computer Vision in Retail: Retailers are increasingly using computer vision to enhance customer experiences. Applications include tracking customer movements, analyzing navigational routes, and detecting walking patterns. Computer vision also aids in inventory management by estimating item availability through security camera analysis and optimizing shelf space configurations.
Self-Driving Cars: Computer vision is fundamental in developing autonomous vehicles. Leading car manufacturers leverage artificial intelligence and computer vision for object identification, navigational routing, and environmental monitoring.
Medical Imaging: Computer-supported medical imaging applications assist physicians by creating and analyzing images, as well as aiding in interpretation. These applications convert 2D scan images into interactive 3D models, providing medical professionals with a detailed understanding of patients' health conditions.

Google Translate App: The Google Translate app uses computer vision to translate foreign language signs by overlaying accurate translations using optical character recognition and augmented reality.
Introduction to Computer Vision
Computer vision, a field within artificial intelligence, focuses on enabling machines to interpret and understand visual information from the world, similar to how humans do. It encompasses various tasks and applications that involve analyzing and processing images and videos to extract meaningful insights.Computer Vision Tasks
Computer vision applications are built upon a foundation of specific tasks that extract valuable information from input images. These tasks serve as the basis for predictions or further analysis. Here are some common tasks in computer vision: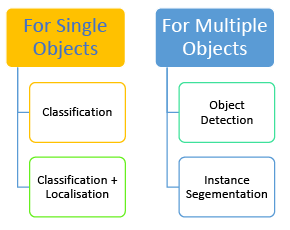
For Single Objects
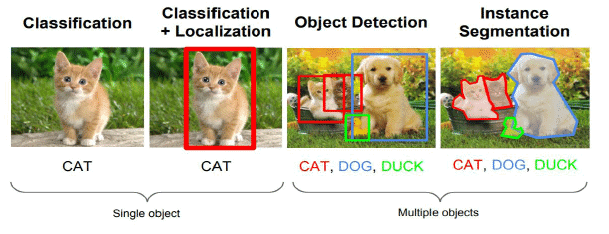
- Classification: This involves assigning a single label to an input image from a predefined set of categories. Despite its simplicity, image classification has a wide range of practical applications in computer vision.
- Classification + Localisation: This task combines identifying the object present in an image with determining its exact location within the image. It is used when there is a single object in the image.
For Multiple Objects
- Object Detection: Object detection aims to locate instances of real-world objects, such as faces, bicycles, and buildings, within images or videos. Algorithms for object detection typically use extracted features and learning techniques to recognize instances of specific object categories. This task is commonly applied in areas like image retrieval and automated vehicle parking systems.
- Instance Segmentation: Instance segmentation involves detecting individual instances of objects, assigning them a category, and labeling each pixel based on that category. A segmentation algorithm takes an image as input and produces a collection of segmented regions or segments.
Basics of Images
Images are an integral part of our daily lives, whether through our mobile devices or computer systems. However, it’s essential to understand some fundamental aspects of images, especially when working with computer vision. Let’s explore the basics of images, starting with pixels, resolution, pixel values, and grayscale images.
Basics of Pixels
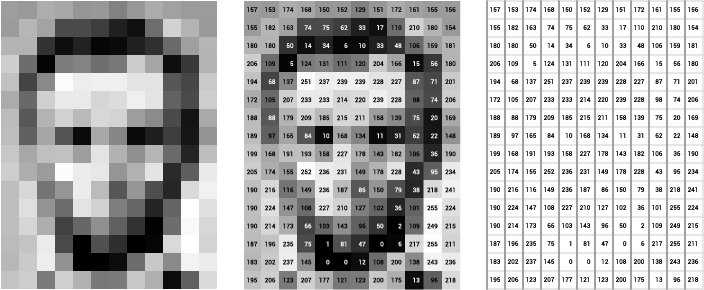
- A pixel, short for “picture element,” is the smallest unit of information in a digital photograph. Every digital image is composed of numerous pixels, which are typically round or square and arranged in a 2-dimensional grid.
- The more pixels an image has, the closer it resembles the original image. Pixels work together to approximate the actual image, and a higher pixel count leads to better image quality.

Resolution
- The resolution of an image refers to the number of pixels it contains. It is often expressed as width by height, such as 1280×1024, indicating the number of pixels from side to side and top to bottom.
- Alternatively, resolution can be expressed as a single number, like a 5-megapixel camera, where a megapixel equals one million pixels. For example, a 1280×1024 monitor has a resolution of approximately 1.31 megapixels.
Pixel Value
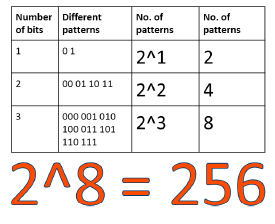
- Each pixel in a computer-stored image has a pixel value that determines its brightness and/or color. The most common format is the byte image, where pixel values are stored as 8-bit integers ranging from 0 to 255.
- In this system, 0 typically represents no color (black), and 255 represents full color (white). The range of values is due to the binary system used in computer data, where each bit can be either 0 or 1.
- Since each pixel uses 1 byte (8 bits) of data, there are 256 possible values (0-255) for each pixel.
Grayscale Images
- Grayscale images consist of varying shades of gray without apparent color. The darkest shade, black, represents the absence of color (pixel value 0), while the lightest shade, white, represents the presence of full color (pixel value 255).
- Intermediate shades of gray are created by equal levels of the three primary colors (red, green, blue).
- In a grayscale image, each pixel is 1 byte in size, and the image is represented as a 2D array of pixels. The size of a grayscale image is defined by its height and width.
Grayscale Images
Grayscale images consist of pixels with varying intensities of gray, ranging from 0 (black) to 255 (white). The computer stores these images as numerical values within this range.
RGB Images
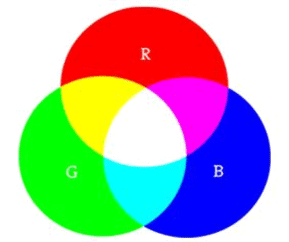
- RGB images are composed of three primary colors: Red, Green, and Blue. By combining different intensities of these colors, all other colors can be created.
- Each pixel in an RGB image has three values corresponding to the intensities of red, green, and blue, which together determine the color of that pixel.
How Computers Store RGB Images
- RGB images are stored as three separate channels: the R channel, G channel, and B channel.
- Each channel contains pixels with values ranging from 0 to 255, representing the intensity of the respective color.
- When these three channels are combined, they form a color image, with each pixel having a set of three values that determine its color.
Example of RGB Storage
- In an RGB image, if the red channel has a high intensity, the green channel has a moderate intensity, and the blue channel has a low intensity, the resulting color might be a shade of yellow or orange, depending on the specific values.
- For instance, a pixel with values R=255, G=200, B=100 would appear as a bright orange color.
Individual RGB Channels
- When the individual RGB channels are separated, they appear as grayscale images, with pixel values ranging from 0 to 255.
- For example, a channel with all pixel values set to 255 would appear white, while a channel with all pixel values set to 0 would appear black.
Combining RGB Values
- The individual RGB values for each pixel are combined to create the final color.
- For example, if a pixel has values R=100, G=150, B=200, the resulting color would be a shade of blue, as blue is the dominant color.
Image Features
In computer vision and image processing, a feature refers to a piece of information that is relevant for solving a computational task related to a specific application. Features can include specific structures in the image, such as points, edges, or objects.

Example:
Imagine a security camera capturing an image. At the top of the image, there are six small patches of images, and the task is to find the exact location of those patches in the image.
Reflection Questions:
Were you able to locate all the patches accurately?
Which patch was the most challenging to find?
Which patch was the easiest to locate?
Let's Analyze Each Patch:
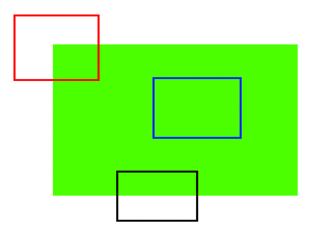
Patch A and B:
- Patches A and B consist of flat surfaces that cover a large area.
- They can be found in various locations within a given area of the image.
Patch C and D:
- Patches C and D are simpler to identify compared to A and B.
- They represent edges of a building, making it possible to estimate their location.
- However, pinpointing the exact location is still challenging because the pattern along the edge is consistent.
Patch E and F:
- Patches E and F are the easiest to locate in the image.
- This is because they depict corners of the building.
- At corners, the patch appears different no matter where it is moved, making it a distinct feature.
Conclusion:
- Image processing allows us to extract various features from an image, such as blobs, edges, or corners.
- These features are crucial for performing different tasks and conducting analyses based on specific applications.
- Good Features:
- The activity highlighted that corners are excellent features to extract because they are unique to specific locations in the image.
- Edges, on the other hand, are less effective since they look the same along their length.
Examples of Good Features:
In the provided images, identifying good features involves recognizing elements that are distinct and not repetitive.
Blue Patch:
- The blue patch represents a flat area, making it challenging to track.
- Black Patch:
- The black patch features an edge.
- Red Patch:
- The red patch is a corner, which is unique because it looks different no matter where it is moved.
- Conclusion on Good Features:
- Corners are considered good features in images because they are unique and easily distinguishable.
Introduction to OpenCV
Now that we understand the features of images and their significance in image processing, we will explore a tool that can help us extract these features from images for further analysis.OpenCV, which stands for Open Source Computer Vision Library, is the tool we will use to extract features from images.
This library is utilized for various types of image and video processing and analysis.
OpenCV has the ability to process images and videos to identify:
- Objects
- Faces
- Handwriting
Convolution
Images are stored in computers as numbers, with pixels arranged in a specific way to form a recognizable picture. Each pixel has a value ranging from 0 to 255, which determines its color. For example, a value of 0 might represent black, while 255 represents white, and values in between represent different shades of gray or colors.- When we edit these numbers, we change the pixel values, and this alters the image. This process of changing pixel values is the foundation of image editing.
- Many of us use image editing software like Photoshop, as well as apps like Instagram and Snapchat, which apply filters to enhance image quality. These filters work by changing pixel values uniformly across the image.
- The technique used to achieve these effects is called convolution, and it involves a convolution operator. Before diving into how convolution works, let’s explore the theory behind it through an online application.

Understanding Convolution in Image Processing
- Convolution is a basic mathematical operation that is crucial for various image processing techniques. It involves multiplying two arrays of numbers, usually of different sizes but the same dimensions, to produce a third array of numbers with the same dimensions.
- In the context of images, convolution refers to the element-wise multiplication of an image array with another array known as the kernel, followed by summing the results.
For example:
- I. Image Array K. Kernel Array I * K. Resulting array after applying the convolution operator
Note: The kernel is moved across the entire image to obtain the resulting array after convolution.
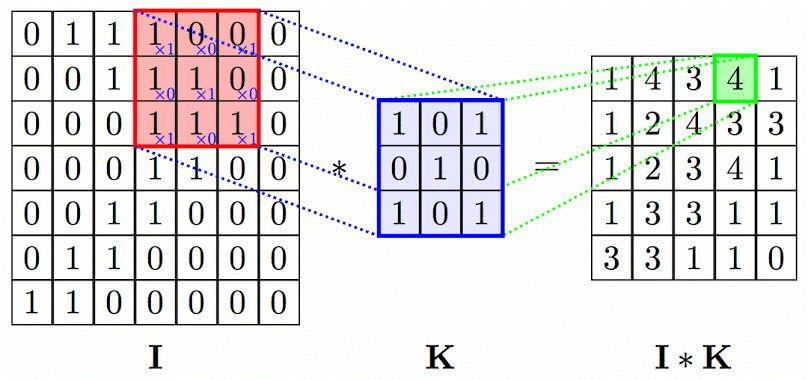
What is a Kernel?
- A kernel is a matrix used in image processing to enhance images in a specific way. It is slid across the image and multiplied with the input to achieve the desired effect.
- Different kernels have different values and are used for various types of effects on an image.
- Convolution is the operation used to extract features from images in image processing, especially for further processing in Convolutional Neural Networks (CNNs).
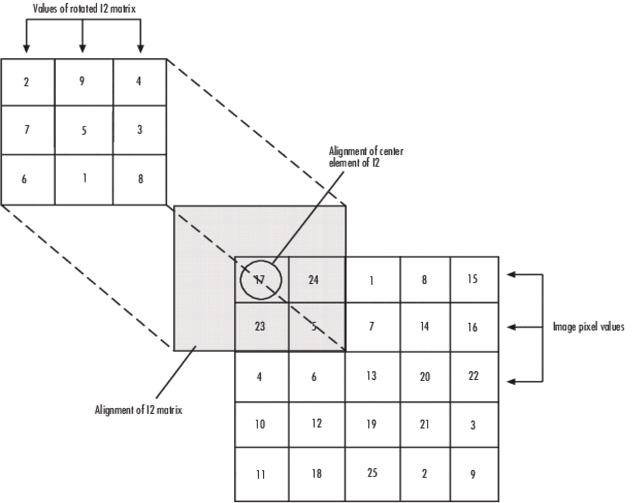
- During convolution, the center of the image is overlapped with the center of the kernel to obtain the output. This process reduces the size of the output image because the overlapping occurs at the edge rows and columns of the image.
- To maintain the same size for the output and input images, the edge values of the original image need to be extended by one pixel while performing the convolution. The extended pixel values are considered as zero.
Understanding Convolutional Neural Networks (CNNs)
A Convolutional Neural Network (CNN) is a type of Deep Learning algorithm designed to analyze and interpret visual data, such as images. CNNs work by assigning different levels of importance to various features within an image, allowing them to differentiate between different objects or aspects present in the image.
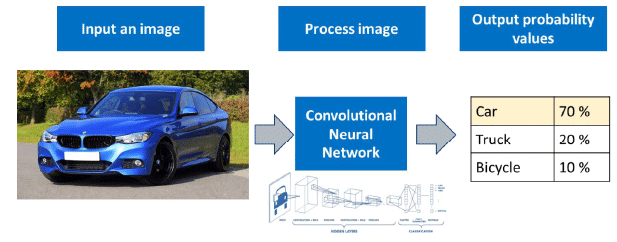
Steps Involved in Deploying a CNN:
- Input Image: The process begins with an input image, which is fed into the CNN for analysis.
- Processing: The CNN processes the image through its multiple layers, each designed to extract and learn different features from the image.
- Prediction: After processing, the CNN makes a prediction based on the learned features and the labels provided in the dataset.
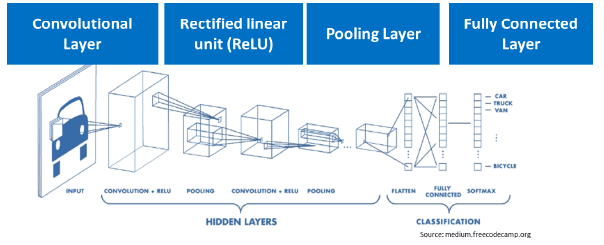
Layers of a Convolutional Neural Network (CNN):
A typical CNN consists of several key layers, each with a specific function:
- Convolution Layer: This is the first layer of a CNN, responsible for performing the convolution operation to extract high-level features from the input image, such as edges. The initial convolution layer captures low-level features like edges, colors, and gradients, while subsequent layers adapt to high-level features, providing a comprehensive understanding of the images in the dataset.
- Rectified Linear Unit (ReLU): This layer applies a non-linear activation function to introduce non-linearity into the model, allowing it to learn complex patterns.
- Pooling Layer: This layer reduces the spatial dimensions of the feature maps, helping to down-sample the data and focus on the most important features.
- Fully Connected Layer: The final layer connects all the neurons and makes the final prediction based on the learned features.
Detailed Look at the Convolution Layer:
- Feature Extraction: In the convolution layer, multiple kernels (small filters) are used to scan the input image and produce various features. The output of this layer is known as the feature map or activation map.
- Image Size Reduction: The feature map helps reduce the image size, making processing more efficient by focusing only on essential features. For instance, to recognize a person, it may be sufficient to identify just the eyes, nose, and mouth, rather than the entire face.
- Enhancing Focus on Relevant Features: By extracting specific features, the CNN can process images more effectively, discarding irrelevant information and concentrating on what matters for the task at hand.

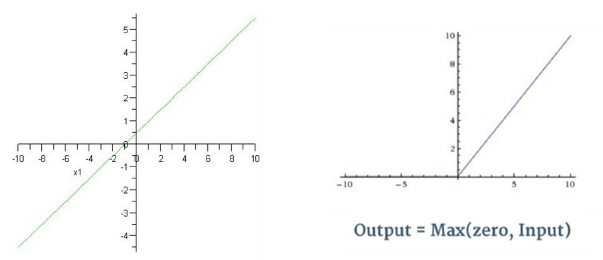
Rectified Linear Unit (ReLU) Function
- After obtaining the feature map, the next step in the Convolutional Neural Network (CNN) is to pass it through the Rectified Linear Unit (ReLU) layer. This layer plays a crucial role in introducing non-linearity to the feature map by eliminating all negative values and retaining positive ones as they are.
- The process of passing the feature map through the ReLU layer enhances the distinctiveness of features by creating a more abrupt transition in colors. This is particularly important for subsequent layers in the CNN, as it improves the effectiveness of the activation layer.
- The ReLU layer takes the feature map and modifies it by setting all negative values to zero while keeping positive values unchanged. This transformation is visually represented by comparing a linear graph to the ReLU graph. The ReLU graph starts with a horizontal line and then increases linearly as it reaches positive values.
- The purpose of passing the feature map through the ReLU layer is to make color changes more pronounced and evident. For instance, in the convolved image, the ReLU function enhances the gradient transition from black to white, making edges more pronounced. This enhancement is beneficial for the subsequent layers in the CNN, as it improves feature detection and activation.

Pooling Layer
Similar to the Convolutional Layer, the Pooling layer is responsible for reducing the spatial size of the Convolved Feature while still retaining the important features.
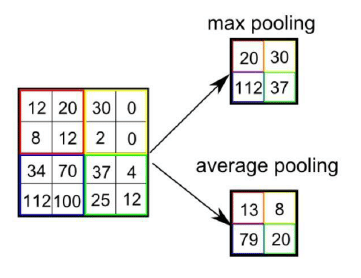 There are two types of pooling which can be performed on an image.
There are two types of pooling which can be performed on an image.
- Max Pooling : Max Pooling returns the maximum value from the portion of the image covered by the Kernel.
- Average Pooling: Average Pooling returns the average value from the portion of the image covered by the Kernel.
The pooling layer is an important layer in the CNN as it performs a series of tasks which are as follows:
- Makes the image smaller and more manageable
- Makes the image more resistant to small transformations, distortions and translations in the input image.
- A small difference in input image will create very similar pooled image.
Fully Connected Layer
The final layer in the CNN is the Fully Connected Layer (FCP). The objective of a fully connected layer is to take the results of the convolution/pooling process and use them to classify the image into a label (in a simple classification example).
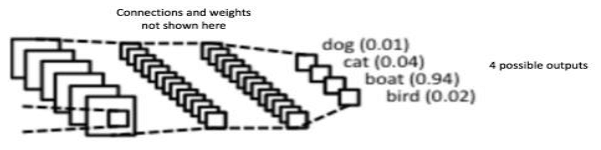
The output of convolution/pooling is flattened into a single vector of values, each representing a probability that a certain feature belongs to a label. For example, if the image is of a cat, features representing things like whiskers or fur should have high probabilities for the label “cat”.
|
31 videos|79 docs|8 tests
|
FAQs on Computer Vision Chapter Notes - Artificial Intelligence for Class 10
| 1. What is computer vision and how is it applied in real-world scenarios? |  |
| 2. What are image features and why are they important in computer vision? | |
| 3. How does OpenCV facilitate computer vision projects? | |
| 4. What is convolution in the context of image processing? | |
| 5. Can you explain the basics of Convolutional Neural Networks (CNNs) and their role in computer vision? | |



Exam
,shortcuts and tricks
,mock tests for examination
,practice quizzes
,Previous Year Questions with Solutions
,Computer Vision Chapter Notes | Artificial Intelligence for Class 10
,Summary
,Computer Vision Chapter Notes | Artificial Intelligence for Class 10
,Computer Vision Chapter Notes | Artificial Intelligence for Class 10
,study material
,past year papers
,ppt
,Semester Notes
,Free
,Important questions
,video lectures
,MCQs
,Objective type Questions
,Viva Questions
,Extra Questions
,Sample Paper
;


Chapter Notes: Computer Vision Free PDF Download
Importance of Chapter Notes: Computer Vision
Chapter Notes: Computer Vision
Chapter Notes: Computer Vision Class 10 Questions
Study Chapter Notes: Computer Vision on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!