डेटाबेस अवधारणाएँ | SSC CGL Tier 2 - Study Material, Online Tests, Previous Year (Hindi) PDF Download

एक डेटाबेस एक सुव्यवस्थित तरीके से संगठित संबंधित जानकारी का संग्रह है जो आसानी से पहुँच, प्रबंधन और अपडेट करने की अनुमति देता है। यह विभिन्न कार्यों का समर्थन करता है, जिसमें डेटा को जोड़ना, अपडेट करना और हटाना शामिल है।
डेटाबेस के मूलभूत तत्व

- डेटा: ये कच्चे और अप्रसंस्कृत तथ्य होते हैं, जिनमें पाठ, संख्याएँ, चित्र या ध्वनि के डिजिटल प्रतिनिधित्व शामिल होते हैं। उदाहरण के लिए, एक छात्र का परीक्षा स्कोर एक डेटा है।
- जानकारी: जब डेटा को संसाधित, व्यवस्थित, या संदर्भ के भीतर संरचित किया जाता है ताकि इसका अर्थ निकाला जा सके, तब यह जानकारी बन जाती है। उदाहरण के लिए, व्यक्तिगत परीक्षा स्कोर से निकाला गया कक्षा का औसत स्कोर जानकारी है।
डेटाबेस के प्रकार
- नेटवर्क डेटाबेस: डेटा को रिकॉर्ड के सेट के रूप में प्रदर्शित किया जाता है और उनके बीच के संबंध लिंक के रूप में दिखाए जाते हैं।
- हाइरार्किकल डेटाबेस: डेटा को एक पेड़ जैसी संरचना में व्यवस्थित किया जाता है जिसमें नोड्स लिंक द्वारा जुड़े होते हैं।
- रिलेशनल डेटाबेस: जिसे संरचित डेटाबेस भी कहा जाता है, डेटा को तालिकाओं में संग्रहित किया जाता है जहाँ कॉलम डेटा के प्रकार को परिभाषित करते हैं और पंक्तियाँ व्यक्तिगत रिकॉर्ड का प्रतिनिधित्व करती हैं।
डेटाबेस के घटक
एक डेटाबेस कई घटकों से बना होता है, जिसे वस्तु के रूप में संदर्भित किया जाता है:
- तालिकाएँ: ये एक रिलेशनल डेटाबेस के मूल तत्व होते हैं जहाँ वास्तविक डेटा परिभाषित और संग्रहीत किया जाता है। तालिकाएँ पंक्तियों और कॉलम के चौराहे पर बने सेल से मिलकर बनती हैं, जिनमें डेटा को संग्रहित, फ़िल्टर, पुनः प्राप्त और संपादित करने जैसी क्रियाएँ शामिल होती हैं।
- क्षेत्र: यह एक रिकॉर्ड के भीतर एक विशिष्ट क्षेत्र है जो विशेष डेटा के लिए आरक्षित होता है, जैसे ग्राहक संख्या, नाम, या पता। क्षेत्रों को कॉलम भी कहा जाता है।
- रिकॉर्ड: यह एक एकल इकाई, जैसे व्यक्ति या लेनदेन से संबंधित क्षेत्रों का संग्रह है। रिकॉर्ड को पंक्तियाँ या ट्यूपल भी कहा जाता है, और रिकॉर्ड की कुल संख्या को तालिका की कार्डिनलिटी कहा जाता है।
- क्वेरी: ये प्रश्न होते हैं जो डेटाबेस से विशिष्ट डेटा पुनः प्राप्त करने के लिए तैयार किए जाते हैं। एक क्वेरी यह निर्दिष्ट करती है कि कौन से क्षेत्र, रिकॉर्ड, और संक्षेप की आवश्यकता है, जिससे उपयोगकर्ता परिभाषित मानदंडों के आधार पर डेटा निकाल सकें।
- फार्म: ये तालिकाओं की तुलना में डेटा को अधिक नियंत्रित तरीके से देखने और संशोधित करने के लिए उपयोग किए जाते हैं। फार्म उपयोगकर्ताओं को एक रिकॉर्ड पर एक बार इंटरएक्ट करने की अनुमति देते हैं और इन्हें कागजी फार्मों के समान डिज़ाइन किया जा सकता है, जिससे डेटा प्रविष्टि आसान और अधिक सहज होती है।
- रिपोर्ट: ये डेटाबेस से पुनः प्राप्त रिकॉर्ड को प्रिंट करने के लिए डिज़ाइन की जाती हैं। रिपोर्ट्स को विभिन्न उद्देश्यों के लिए अनुकूलित किया जा सकता है, जैसे मेलिंग लेबल का उत्पादन, और कुछ डेटाबेस सिस्टम रिपोर्ट निर्माण में सहायता के लिए विज़ार्ड प्रदान करते हैं।
डेटाबेस प्रबंधन प्रणाली (DBMS)
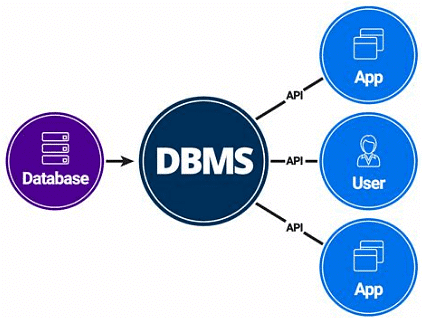
- डेटाबेस प्रबंधन प्रणाली (DBMS) एक प्रोग्रामों का समूह है जिसे एक डेटाबेस से डेटा प्रबंधित और पुनर्प्राप्त करने के लिए डिज़ाइन किया गया है। यह डेटा को एक संगठित संपूर्ण के रूप में व्यवस्थित करता है, बजाय कि इसे अलग, अप्रासंगिक फ़ाइलों के रूप में माना जाए।
- DBMS का मुख्य उद्देश्य डेटा को संग्रहीत और पुनर्प्राप्त करने के लिए एक सुविधाजनक और कुशल वातावरण बनाना है।
- DBMS के उदाहरणों में MySQL, Oracle, FoxPro, dBASE, Sybase, और MS Access शामिल हैं।
- DBMS डेटा और उससे निकाली गई जानकारी के बीच की खाई को पाटने का कार्य करता है।
DBMS के मूल कार्य
- डेटा प्रकार और संरचनाओं को परिभाषित करना: एक अनुप्रयोग में उपयोग किए जाने वाले डेटा के लिए प्रकार, संरचनाएं, और बाधाओं को निर्दिष्ट करना।
- डेटा संग्रहण: डेटा को एक संरचित प्रारूप में सहेजना।
- डेटा हेरफेर करना: डेटा को संशोधित या प्रबंधित करने के लिए संचालन करना।
- डेटा क्वेरी करना: उपयोगकर्ता की क्वेरी के आधार पर डेटाबेस से विशिष्ट जानकारी पुनर्प्राप्त करना।
- डेटा अद्यतन करना: डेटाबेस के भीतर सामग्री को संशोधित करना।
DBMS आर्किटेक्चर
DBMS की आर्किटेक्चर आमतौर पर तीन स्तरों में विभाजित होती है:
- आंतरिक स्तर: जिसे भौतिक स्तर भी कहा जाता है, यह डेटा अमूर्तता का सबसे निचला स्तर है। यह कंप्यूटर पर डेटा के भौतिक संग्रहण से संबंधित है, यह परिभाषित करता है कि डेटा वास्तव में कैसे संग्रहीत और व्यवस्थित किया जाता है।
- सांकेतिक स्तर: जिसे तार्किक स्तर भी कहा जाता है, यह डेटाबेस का उच्च-स्तरीय दृश्य प्रदान करता है। यह वर्णन करता है कि कौन सा डेटा संग्रहीत है, डेटा के बीच के संबंध क्या हैं, और यह भौतिक संग्रहण से स्वतंत्र है।
- बाहरी स्तर: जिसे दृश्य स्तर भी कहा जाता है, यह डेटा अमूर्तता का सबसे ऊँचा स्तर है। यह परिभाषित करता है कि उपयोगकर्ता प्रणाली के साथ कैसे इंटरैक्ट करते हैं और उपयोगकर्ता की आवश्यकताओं के अनुसार डेटा को विभिन्न तरीकों से देखने की अनुमति देता है।
DBMS के लाभ
DBMS के लाभ
- डेटा पुनरावृत्ति में कमी: DBMS डेटा संग्रहण को केंद्रीकृत करता है, जिससे डेटा का डुप्लीकेशन टाला जाता है और सभी एप्लिकेशन एक ही, नियंत्रित डेटा स्रोत का संदर्भ लेते हैं।
- उपयोगकर्ता इंटरैक्शन में सुधार: अपडेट की गई जानकारी डेटा तक पहुँच और उपयोगकर्ता प्रश्नों के प्रति प्रतिक्रिया को बढ़ाती है।
- डेटा सुरक्षा में वृद्धि: DBMS सुरक्षा विशेषताएँ जैसे उपयोगकर्ता नाम और पासवर्ड प्रदान करते हैं ताकि पहुँच को नियंत्रित किया जा सके।
- डेटा अखंडता बनाए रखना: DBMS अखंडता प्रतिबंधों को लागू करता है ताकि कई उपयोगकर्ताओं के बीच डेटा की सटीकता सुनिश्चित की जा सके।
- बैकअप और पुनर्प्राप्ति: हार्डवेयर या सॉफ़्टवेयर विफलताओं की स्थिति में डेटा का बैकअप लेने और उसे पुनर्प्राप्त करने के लिए तंत्र प्रदान करता है।
DBMS के नुकसान
- उच्च लागत: DBMS महंगे हार्डवेयर और सॉफ़्टवेयर की आवश्यकता होती है, जिसके लिए उन्नयन और निवेश की आवश्यकता होती है।
- जटिलता: DBMS की उन्नत कार्यक्षमता उन्हें जटिल और प्रबंधित करने में कठिन बना सकती है, यदि सही ढंग से समझा न जाए तो संभावित डिज़ाइन समस्याएँ उत्पन्न हो सकती हैं।
- प्रशिक्षण लागत: जटिल DBMS सॉफ़्टवेयर का उपयोग करने के लिए कर्मचारियों को प्रशिक्षित करना महंगा हो सकता है।
- तकनीकी स्टाफिंग: डेटाबेस प्रशासकों और एप्लिकेशन प्रोग्रामरों जैसे कुशल पेशेवरों को नियुक्त करना लागत बढ़ाता है।
- डेटाबेस विफलता: सभी डेटा को एक ही डेटाबेस में केंद्रीकृत करने से यदि डेटाबेस भ्रष्ट हो जाए तो महत्वपूर्ण डेटा हानि या सिस्टम डाउनटाइम का जोखिम उत्पन्न हो सकता है।
DBMS के अनुप्रयोग
- बैंकिंग: ग्राहक जानकारी, खातों, ऋणों और लेनदेन का प्रबंधन।
- आरक्षण प्रणाली: आरक्षण और अनुसूची जानकारी को संभालना।
- विश्वविद्यालय: छात्र जानकारी, पाठ्यक्रम पंजीकरण और ग्रेड का ट्रैक रखना।
- क्रेडिट कार्ड लेनदेन: क्रेडिट कार्ड खरीददारी को प्रोसेस करना और विवरण उत्पन्न करना।
- टेलीकम्युनिकेशन: कॉल विवरण रिकॉर्ड करना और बिल उत्पन्न करना।
- वित्त: वित्तीय संपत्तियों, बिक्री और खरीद की जानकारी को संग्रहित करना।
- बिक्री: ग्राहक, उत्पाद, और खरीद डेटा का प्रबंधन।
संबंधित डेटाबेस
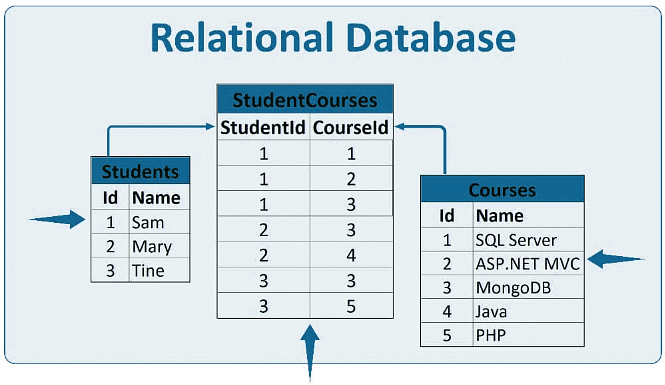
एक संबंधपरक डेटाबेस में, डेटा को कई तालिकाओं में संग्रहीत किया जाता है, जिनमें आपस में संबंध परिभाषित होते हैं। एक रिलेशनल डेटाबेस प्रबंधन प्रणाली (RDBMS) इन तालिकाओं और उनके संबंधों का प्रबंधन करती है। एक RDBMS एकल डेटाबेस के डेटा को कई तालिकाओं में फैला सकता है। उदाहरणों में Base, Oracle, DB2, Sybase, और Informix शामिल हैं।
संबंधपरक डेटाबेस से संबंधित शर्तें
- संबंध: एक संबंध एक तालिका है जिसमें पंक्तियाँ और स्तंभ होते हैं, जो डेटा आइटम और उनके संबंधों का प्रतिनिधित्व करते हैं। इसके तीन मुख्य गुण हैं:
- नाम: संबंध का नाम, जिसे तालिका का नाम या एंटिटी पहचानकर्ता भी कहा जाता है।
- कार्डिनैलिटी: संबंध में ट्यूपल की संख्या (पंक्तियाँ)।
- डिग्री: प्रत्येक ट्यूपल में गुणों की संख्या (स्तंभ)।
- डोमेन: डोमेन उन सभी संभावित मानों का सेट है जो तालिका में एक गुण या स्तंभ ले सकता है। यदि एक डोमेन के तत्व अपारिभाषित हैं, तो डोमेन को परमाणु माना जाता है।
- गुण: गुण तालिका में स्तंभ शीर्षक होते हैं, जिनमें से प्रत्येक का एक विशिष्ट नाम होता है।
- ट्यूपल: ट्यूपल संबंध में पंक्तियाँ होती हैं, प्रत्येक में गुणों के लिए मानों का सेट होता है।
- की: एक की वह स्तंभ या स्तंभों का सेट है जिसका उपयोग तालिका में पंक्तियों की अद्वितीय पहचान के लिए या अन्य तालिकाओं के साथ संबंध स्थापित करने के लिए किया जाता है। उदाहरण के लिए, एक तालिका में जैसे ID, नाम, और पता जैसे स्तंभ हो सकते हैं, इनमें से प्रत्येक स्तंभ रिकॉर्ड की अद्वितीय पहचान के लिए एक की के रूप में कार्य कर सकता है।
किस्म की कुंजी
- प्राथमिक कुंजी: यह एक या एक से अधिक गुणों का सेट है जो संबंध में प्रत्येक ट्यूपल की अद्वितीय पहचान करता है। प्राथमिक कुंजी अद्वितीय और नॉन-नल होनी चाहिए। यह या तो परमाणु (एकल गुण) या संयुक्त (कई गुण) हो सकती है।
- उम्मीदवार कुंजी: ये सभी संभावित गुणों का सेट हैं जो संबंध में प्रत्येक ट्यूपल की अद्वितीय पहचान कर सकते हैं। इनमें से एक को प्राथमिक कुंजी के रूप में चुना जाता है। उम्मीदवार कुंजी न्यूनतम कुंजी होती हैं, जिसका अर्थ है कि इनमें कोई अनावश्यक गुण नहीं हो सकते।
- वैकल्पिक कुंजी: प्राथमिक कुंजी चुनने के बाद, शेष उम्मीदवार कुंजी को वैकल्पिक कुंजी कहा जाता है।
- विदेशी कुंजी: यह एक तालिका में एक गैर-कुंजी गुण है जो दूसरी तालिका की प्राथमिक कुंजी को संदर्भित करता है, जिससे दोनों तालिकाओं के बीच संबंध स्थापित होता है। एक तालिका में कई विदेशी कुंजी हो सकती हैं, जो विभिन्न तालिकाओं को संदर्भित करती हैं।
डेटाबेस भाषाएँ
डाटा परिभाषा भाषा (DDL): DDL का उपयोग डेटाबेस तालिकाओं और अन्य वस्तुओं की संरचना को परिभाषित करने के लिए किया जाता है। यह विभिन्न परिभाषाओं के माध्यम से डेटाबेस स्कीमा को निर्दिष्ट करता है।
डाटा हेरफेर भाषा (DML): DML डेटाबेस के भीतर डेटा तक पहुँचने और उसे हेरफेर करने के लिए आदेश प्रदान करता है, जिसमें डेटा डालना, प्राप्त करना, हटाना और संशोधित करना शामिल है।
डाटा नियंत्रण भाषा (DCL): DCL आदेश डेटाबेस सुरक्षा और उपयोगकर्ता पहुँच को प्रबंधित करने के लिए उपयोग होते हैं, उपयोगकर्ताओं को भूमिकाएँ और विशेषताएँ सौंपते हैं।
एंटिटी-रिलेशनशिप मॉडल (E-R मॉडल)
E-R मॉडल डेटाबेस में एंटिटीज और उनके संबंधों का चित्रात्मक प्रतिनिधित्व है। इसे E-R आरेख के रूप में भी जाना जाता है।
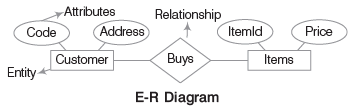
- एंटिटी: एक एंटिटी एक वस्तु है जो वास्तविक दुनिया में मौजूद है और जिसके बारे में डेटा एकत्र किया जाता है। E-R आरेखों में एंटिटीज को आयतों द्वारा प्रदर्शित किया जाता है। उदाहरण के लिए, एक परिदृश्य में जहाँ एक ग्राहक वस्तुएं खरीदता है, "ग्राहक" और "वस्तुएं" दोनों एंटिटीज हैं।
- गुण: गुण एक एंटिटी की विशेषताओं या गुणों का वर्णन करते हैं। तालिकाओं में, गुण कॉलम द्वारा प्रदर्शित किए जाते हैं और E-R आरेखों में अंडाकार के रूप में खींचे जाते हैं। उदाहरण के लिए, "वस्तुएं" एंटिटी में "ItemId" और "Price" जैसे गुण हो सकते हैं।
- एंटिटी सेट: एक एंटिटी सेट समान प्रकार की एंटिटीज का संग्रह है जिनकी साझा विशेषताएँ या गुण होते हैं। उदाहरण के लिए, एक डेटाबेस में सभी छात्र एंटिटीज एक एंटिटी सेट बनाते हैं।
एंटिटी सेट के दो प्रकार होते हैं:
- मजबूत एंटिटी सेट: एक एंटिटी सेट जिसमें एक प्राथमिक कुंजी या प्रत्येक एंटिटी को अद्वितीय रूप से पहचानने के लिए पर्याप्त गुण होते हैं।
- कमजोर एंटिटी सेट: एक एंटिटी सेट जिसमें प्राथमिक कुंजी बनाने के लिए पर्याप्त गुण नहीं होते हैं।
रिश्ता: एक रिश्ता यह दर्शाता है कि कई एंटिटीज एक-दूसरे से कैसे संबंधित हैं। इसे E-R आरेखों में हीरे के आकार से प्रदर्शित किया जाता है। रिश्तों को तीन प्रकारों में वर्गीकृत किया जा सकता है:
एक-से-एक: टेबल A में एक रिकॉर्ड टेबल B में एक रिकॉर्ड से संबंधित है, और इसके विपरीत।
एक-से-बहुत: टेबल A में एक रिकॉर्ड कई रिकॉर्ड से टेबल B में संबंधित है, लेकिन टेबल B में प्रत्येक रिकॉर्ड केवल एक रिकॉर्ड से संबंधित है टेबल A में।
बहुत-से-बहुत: टेबल A में प्रत्येक रिकॉर्ड कई रिकॉर्ड से टेबल B में संबंधित हो सकता है, और टेबल B में प्रत्येक रिकॉर्ड कई रिकॉर्ड से संबंधित हो सकता है टेबल A में।
टिप्स
- डॉ. EF Codd ने 1970 में रिलेशनल डेटाबेस प्रबंधन प्रणाली (RDBMS) के लिए 12 सिद्धांत प्रस्तुत किए।
- स्कीमा डेटाबेस की तार्किक संरचना के लिए खड़ा है।
- इंस्टेंस उस विशेष समय पर डेटाबेस में मौजूद वास्तविक डेटा को संदर्भित करते हैं।
- डेटा डुप्लीकेशन न केवल अनावश्यक स्थान का उपयोग करता है बल्कि इसे डेटा असंगतता के रूप में ज्ञात एक गंभीर समस्या का कारण भी बनाता है।
- डेटा माइनिंग व्यापक डेटा संग्रह के माध्यम से पैटर्न को पहचानने और समस्याओं को हल करने के लिए डेटा विश्लेषण के माध्यम से संबंध स्थापित करने की प्रक्रिया है।
|
374 videos|1072 docs|1174 tests
|


Viva Questions
,practice quizzes
,Previous Year (Hindi)
,Extra Questions
,video lectures
,Previous Year Questions with Solutions
,mock tests for examination
,Online Tests
,Sample Paper
,Previous Year (Hindi)
,past year papers
,Online Tests
,Semester Notes
,study material
,डेटाबेस अवधारणाएँ | SSC CGL Tier 2 - Study Material
,Exam
,ppt
,Previous Year (Hindi)
,डेटाबेस अवधारणाएँ | SSC CGL Tier 2 - Study Material
,Free
,Summary
,डेटाबेस अवधारणाएँ | SSC CGL Tier 2 - Study Material
,Online Tests
,MCQs
,Important questions
,Objective type Questions
,shortcuts and tricks
;


डेटाबेस अवधारणाएँ Free PDF Download
Importance of डेटाबेस अवधारणाएँ
डेटाबेस अवधारणाएँ Notes
डेटाबेस अवधारणाएँ SSC CGL Questions
Study डेटाबेस अवधारणाएँ on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!