एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण | Indian Economy for Government Exams (Hindi) - Bank Exams PDF Download

पृष्ठ संख्या 561:
संक्षिप्त उत्तर
प्रश्न 1: डेटा मॉडल की मुख्य श्रेणियाँ बताइए।
उत्तर: डेटा मॉडल की विभिन्न श्रेणियाँ निम्नलिखित हैं:
- (i) रिलेशनल डेटा मॉडल
- (ii) हायरार्किकल डेटा मॉडल
- (iii) नेटवर्क डेटा मॉडल
1. रिलेशनल डेटा मॉडल: यह डेटा मॉडल संचित डेटा मानों के संबंध पर आधारित है। इस डेटा मॉडल में, डेटा को पंक्तियों और कॉलम में व्यवस्थित किया जाता है। एक पंक्ति को ट्यूपल माना जाता है, कॉलम का शीर्षक एट्रिब्यूट के रूप में जाना जाता है, और पंक्तियों और कॉलम का समग्र सेट, यानी एक टेबल, को रिलेशन कहा जाता है। टेबल को रिलेशन कहा जाता है क्योंकि यह पंक्तियों और कॉलम के बीच के संबंध को व्यक्त करता है। यह मॉडल संग्रहण और पुनर्प्राप्ति कार्य प्रदान करता है और डेटा संरचना को परिभाषित करता है। रिलेशनल डेटा मॉडल को 1970 में टेड कॉड द्वारा एक क्लासिक पेपर में प्रस्तुत किया गया था। इससे पहले, 1960 के दशक में अन्य डेटा मॉडल जैसे कि हायरार्किकल डेटा मॉडल और नेटवर्क डेटा मॉडल प्रस्तावित किए गए थे। इन मॉडलों को उनके बड़े मौजूदा उपयोगकर्ता आधार के कारण लेगेसी-मॉडल भी कहा जाता है।
2. हायरार्किकल डेटा मॉडल: यह डेटा मॉडल मुख्य रूप से रिकॉर्ड और पालक-वंशज संबंधों से मिलकर बना है। एक रिकॉर्ड को उन मानों के संग्रह के रूप में माना जाता है जो किसी संविधान या रिश्ते के उदाहरण के बारे में जानकारी प्रदान करते हैं, जबकि पालक-वंशज संबंध पालक रिकॉर्ड और बच्चों के रिकॉर्ड प्रकार के बीच के संबंध को स्पष्ट करता है। इस डेटा मॉडल में, रिकॉर्ड को एक पेड़ की संरचना में व्यवस्थित किया जाता है, न कि एक मनमाने ग्राफ के रूप में। डेटा को रिकॉर्ड के संग्रह द्वारा प्रस्तुत किया जाता है और डेटा के बीच के संबंध को लिंक द्वारा दर्शाया जाता है।
3. नेटवर्क डेटा मॉडल: इस प्रकार के डेटा मॉडल को कभी-कभी DBTG मॉडल भी कहा जाता है, क्योंकि मूल नेटवर्क मॉडल को CODASYL डेटा बेस टास्क ग्रुप के 1971 में प्रस्तुत किया गया था, यानी (DBTG)। यह डेटा मॉडल मूल रूप से रिकॉर्ड और सेट्स से मिलकर बना है। जबकि डेटा को रिकॉर्ड में संग्रहीत किया जाता है, जो संबंधित डेटा मानों के एक समूह को शामिल करता है, दूसरी ओर, सेट्स दो रिकॉर्ड प्रकारों के बीच के संबंध को वर्णित करते हैं। इस डेटा मॉडल में, डेटा को रिकॉर्ड के संग्रह द्वारा भी प्रस्तुत किया जाता है और डेटा के बीच के संबंध को सेट्स द्वारा दर्शाया जाता है। यह मॉडल डेटा में कई-से-कई संबंध प्रदान करता है।
प्रश्न 2: कंप्यूटर लेखांकन डेटा को संसाधित करने में कैसे उपयोगी हैं?
उत्तर: डेटा प्रोसेसिंग एक प्रक्रिया है जिसमें डेटा और तथ्यों को इकट्ठा करना, संग्रहीत करना, संक्षेपित करना, विश्लेषण करना और व्याख्या करना शामिल है ताकि कुशल और प्रभावी निर्णय लेने के लिए विश्वसनीय जानकारी प्रस्तुत की जा सके। संक्षेप में, डेटा प्रोसेसिंग कच्चे डेटा को उपयोगी जानकारी में परिवर्तित करने की प्रक्रिया है। कंप्यूटर प्रणाली लेखांकन डेटा को संसाधित करने में बहुत महत्वपूर्ण भूमिका निभाती है। डेटा प्रोसेसिंग के लिए एक तंत्र की आवश्यकता होती है जो डेटा सामग्री को इस प्रकार संग्रहीत करे कि जब आवश्यक हो, तब डेटा को आसानी से और सुविधाजनक रूप से पुनः प्राप्त किया जा सके। यह कंप्यूटर की सहायता से लेखांकन के लिए उपयुक्त डेटाबेस डिज़ाइन करके आसानी से किया जा सकता है। इसके अलावा, कंप्यूटर डेटा की पुनरावृत्ति को समाप्त करने में भी मदद करते हैं। मैनुअल लेखांकन प्रणाली के विपरीत, कंप्यूटर थकान, बोरियत या थकावट के अधीन नहीं होते हैं, इसलिए; कंप्यूटर द्वारा संसाधित डेटा की विश्वसनीयता बहुत अधिक होती है। विश्वसनीयता के अलावा, कंप्यूटर डेटा को अपेक्षाकृत उच्च गति और उच्च स्तर की सटीकता और शुद्धता के साथ संसाधित कर सकते हैं।
प्रश्न 3: आप लेखांकन डेटा से क्या समझते हैं? चर्चा करें कि इसे अंतिम रूप से वित्तीय विवरणों में जानकारी के रूप में प्रस्तुत करने के लिए किन चरणों से गुजरना पड़ता है।
उत्तर: लेखांकन डेटा उन तथ्यों और वित्तीय डेटा को संदर्भित करता है जो जर्नल, लेजर, वित्तीय विवरणों और अन्य खाता पुस्तकों में होते हैं। अर्थात्, लेखांकन डेटा उन वित्तीय डेटा से संबंधित है जो खाता पुस्तकों में दर्ज होती हैं। लेखांकन डेटा को वित्तीय विवरणों में जानकारी के रूप में प्रस्तुत करने के लिए परिवर्तित करने की प्रक्रिया को डेटा प्रोसेसिंग कहा जाता है। डेटा प्रोसेसिंग एक प्रक्रिया है जिसमें डेटा और तथ्यों को इस प्रकार इकट्ठा करना, संग्रहीत करना, संक्षेपित करना, विश्लेषण करना और व्याख्या करना शामिल है ताकि कुशल और प्रभावी निर्णय लेने के लिए विश्वसनीय जानकारी प्राप्त की जा सके। डेटा को जानकारी में परिवर्तित करने के विभिन्न चरण निम्नलिखित हैं ताकि इसे वित्तीय विवरणों में प्रस्तुत किया जा सके:
- 1. स्रोत दस्तावेजों से डेटा एकत्र करना: सबसे पहले, डेटा को स्रोत दस्तावेजों जैसे कि भुगतान पर्ची, रसीद पर्ची आदि से एकत्र किया जाता है ताकि वाउचर तैयार किए जा सकें। वाउचर तैयार करना लेखांकन डेटा को व्यवस्थित और कालानुक्रमिक (तारीख के अनुसार) तरीके से रिकॉर्ड करने के लिए आधार है।
- 2. डेटा इनपुट करना: वाउचर में निहित लेखांकन डेटा दर्ज करने के लिए एक उपयुक्त डेटाबेस डिज़ाइन किया जाता है। यह पूर्व-निर्धारित डेटा एंट्री फॉर्म की सहायता से किया जाता है। यह फॉर्म भौतिक वाउचर फॉर्म के समान होता है।
- 3. डेटा संग्रहण: डेटा संग्रहण इनपुट डेटा को संग्रहीत करने के लिए बनाया जाता है। इसमें उस डेटाबेस को संरचना करना शामिल है जिसका उपयोग लेखांकन डेटा को रिकॉर्ड करने के लिए किया जाता है।
4. डेटा का हेरफेर - इस चरण में संग्रहीत डेटा का परिवर्तन किया जाता है ताकि अंतिम रिपोर्ट उत्पन्न की जा सके।
5. डेटा का आउटपुट - इसका अर्थ है लेखा रिपोर्टों जैसे कि जर्नल, खाता बही, परीक्षण संतुलन, वित्तीय खाते आदि को उपयोगी जानकारी के रूप में प्रस्तुत करना। लेखा उपयोगकर्ता इन रिपोर्टों को केवल परिवर्तित डेटा तक पहुंचकर प्राप्त कर सकते हैं। यह चरण मूल रूप से पूर्व-निर्धारित प्रारूप में अंतिम रिपोर्टों के उत्पादन का संकेत देता है।
प्रश्न 4: आप डेटाबेस से क्या समझते हैं? यह DBMS से कैसे भिन्न है?
उत्तर: डेटाबेस परस्पर संबंधित डेटा, घटनाओं और लेन-देन का संग्रह है। इसे एक विशेष तरीके से व्यवस्थित किया गया है और यह विभिन्न उपयोगकर्ताओं को एक साथ पहुंच प्रदान करता है। इस प्रणाली में, डेटा किसी विशेष ऑपरेशन के लिए एकत्रित और संग्रहीत किया जाता है। डेटाबेस की दो महत्वपूर्ण विशेषताएँ निम्नलिखित हैं:
- साझा संपत्ति - डेटाबेस संबंधित डेटा का एक संयोजन है जिसे उन लोगों द्वारा एक्सेस किया जा सकता है जिनके पास इसे एक्सेस करने का अधिकार है और विभिन्न जानकारी की आवश्यकताओं को पूरा करने के लिए।
- एकीकृत संपत्ति - डेटाबेस को इस तरह से व्यवस्थित किया गया है कि डेटा की दोहराव को टाला जा सके और समाप्त किया जा सके।
एक ओर, डेटाबेस का उपयोग लेखा डेटा को संग्रहीत करने के लिए किया जाता है, जबकि दूसरी ओर, DBMS वह सॉफ़्टवेयर है जो डेटाबेस बनाने, विकसित करने और बनाए रखने में मदद करता है। यह एक प्रणाली है जो डेटाबेस में रिकॉर्ड किए गए डेटा तक आसान पहुंच प्रदान करती है। यह बड़े मात्रा में डेटा को संभालती है और जरूरत के अनुसार विभिन्न कार्यों के लिए डेटाबेस को परिभाषित, व्यवस्थित और परिवर्तित करती है। इसलिए, यह कहा जा सकता है कि DBMS डेटाबेस तक पहुंच को सुगम बनाता है।

प्रश्न 5: एंटिटी प्रकार का क्या अर्थ है? यह एंटिटी सेट से कैसे भिन्न है? लेखा के वास्तविकता से उपयुक्त उदाहरण देकर स्पष्ट करें।
उत्तर: एंटिटी प्रकार का अर्थ है एक सामान्य परिभाषा जो विशेषताओं के संदर्भ में एंटिटी के एक संग्रह द्वारा साझा की जाती है। प्रत्येक एंटिटी को उनके आगे की पहचान के लिए एक अलग नाम दिया जाता है। एंटिटी प्रकार को इसके विभिन्न विशेषताओं के माध्यम से डेटाबेस में वर्णित किया जाता है। किसी विशेष एंटिटी प्रकार से संबंधित एंटिटी की विशेषताओं के मानों को एंटिटी उदाहरण कहा जाता है। दूसरी ओर, एंटिटी सेट को एक विशेष एंटिटी प्रकार के सभी एंटिटी उदाहरणों के संग्रह के रूप में परिभाषित किया जाता है। एंटिटी प्रकार का वर्णन करने के लिए प्रयुक्त विशेषताओं के सेट को स्कीमा कहा जाता है। विशेषता का वही सेट उन एंटिटी के सेट द्वारा साझा किया जाता है जो एक विशेष एंटिटी प्रकार से संबंधित होती हैं। विशेष एंटिटी प्रकार के एंटिटी के संग्रह को एंटिटी प्रकार का विस्तारण कहा जाता है। उदाहरण के लिए, 350967 Sunita and Company 7, एक खाता का एंटिटी उदाहरण है जिसका कोड 350967, नाम Sunita and Company और प्रकार 7 है।
इस उदाहरण में, एंटिटी का संदर्भ खातों से है, दूसरी ओर, एंटिटी सेट एंटिटी प्रकार 'खातों' के एंटिटी उदाहरणों का संग्रह है।
प्रश्न 6: आप संबंध प्रकार से क्या समझते हैं? यह संबंध उदाहरण और संबंध सेट से कैसे भिन्न है?
उत्तर: विभिन्न एंटिटी प्रकारों से संबंधित विभिन्न एंटिटियों के बीच एक विशेष तरीके से जो संबंध होता है, उसे संबंध प्रकार कहा जाता है। उसी संबंध प्रकार से संबंधित विभिन्न संबंधों के संग्रह को संबंध सेट कहा जाता है। संबंध प्रकार से प्राप्त परिणाम को उदाहरण कहा जाता है और इसे एक एंटिटी सेट में प्रदर्शित किया जाता है। दो एंटिटी प्रकार: वेतन पर्ची और कर्मचारी के बीच बनाई गई संबंध प्रत्येक वेतन पर्ची को उस कर्मचारी से जोड़ती है जिसने इसे तैयार किया। इसी तरह, संबंध प्रकार STUDY_IN का एक और उदाहरण एक छात्र एंटिटी और एक कक्षा एंटिटी को जोड़ता है। इस उदाहरण में, छात्र और कक्षा एंटिटी हैं और उनके बीच का संबंध, अर्थात् STUDY_IN, संबंध सेट है। निम्नलिखित ER डायग्राम में संबंध प्रकार को हीरा के आकार के बॉक्स में दिखाया गया है। भाग लेने वाली एंटिटी को आयताकार बॉक्स में दिखाया गया है, जो सीधे रेखाओं के माध्यम से हीरा के आकार के बॉक्स से जुड़ी होती हैं।
प्रश्न 7: बहु-मूल्य वाले विशेषण से आपका क्या तात्पर्य है? यह जटिल और संयोजन विशेषण से कैसे भिन्न है? उपयुक्त उदाहरण देकर स्पष्ट करें।
उत्तर: विशेषणों को उन विशेषताओं के रूप में परिभाषित किया जा सकता है जो किसी इकाई की विशेषताओं को दर्शाते हैं। यदि हम किसी व्यक्ति के बारे में बात करें, तो ये विशेषताएँ ऊँचाई, वजन, नाम, जन्म तिथि, आदि हो सकती हैं और खातों के मामले में यह कोड, प्रकार, नाम, आदि हो सकती हैं। इन विशेषणों का एक मान होता है जो डेटाबेस में डेटा के रूप में संग्रहीत होता है। बहु-मूल्य वाला विशेषण वह विशेषण है जिसके कई मान होते हैं। उदाहरण के लिए, आइसक्रीम के स्वाद। यह एक बहु-मूल्य वाला विशेषण है क्योंकि आइसक्रीम का स्वाद स्ट्रॉबेरी, वनीला, बटर-स्कॉच, आदि हो सकता है। दूसरे शब्दों में, बहु-मूल्य वाले विशेषण एक ही इकाई की विभिन्न विशेषताएँ हैं।
- संयोजन विशेषण संबंधित विशेषणों का संयोजन या संचित होता है। इन विशेषणों को छोटे भागों में विभाजित किया जा सकता है ताकि कुछ मौलिक विशेषणों का स्वतंत्र अर्थ दर्शाया जा सके। उदाहरण के लिए, संपर्क विवरण, जो आमतौर पर टेलीफोन नंबर (STD कोड के साथ), मोबाइल नंबर और ई-मेल आईडी में विभाजित होता है।
- जटिल विशेषण संयोजन और बहु-मूल्य वाले विशेषणों के विशेषणों को एकत्रित करके बनाए जाते हैं। संयोजन विशेषणों के घटकों के समूह को दिखाने के लिए कोष्ठक ( ) का उपयोग किया जाता है और जटिल विशेषणों के घटकों के समूह को दिखाने के लिए ब्रैकेट { } का उपयोग किया जाता है।
प्रश्न 8: डेटा मॉडलिंग में प्रयुक्त कमजोर इकाई के सिद्धांत से आपका क्या तात्पर्य है? ऐसे मॉडलिंग के संदर्भ में मालिक इकाई प्रकार, आंशिक कुंजी और पहचानने वाले संबंध की प्रासंगिकता को स्पष्ट करें।
उत्तर: कमजोर इकाइयाँ उन इकाइयों को संदर्भित करती हैं जिनके पास अपने स्वयं के कुंजी विशेषण या पहचान नहीं होती। कमजोर इकाइयों की पहचान उनके विशेष इकाइयों के साथ संबंध के आधार पर की जाती है। ये अन्य इकाई प्रकार पहचानने वाले या मालिक इकाई प्रकार के रूप में माने जाते हैं। जिन इकाई प्रकारों के इकाइयाँ कमजोर इकाइयों के साथ संबंध में होती हैं, उन्हें पहचानने वाले या मालिक इकाई प्रकार कहा जाता है।
- इसका वर्णन इस प्रकार किया जा सकता है कि कमजोर इकाइयाँ वे इकाइयाँ हैं जिन्हें उनके माता-पिता की इकाई या प्रमुख इकाई के साथ संबंध के कारण पहचाना जाता है, जबकि माता-पिता की इकाई को पहचानने वाली इकाई प्रकार कहा जाता है।
- इस प्रकार, कमजोर इकाई प्रकार का मालिक इकाई के साथ संबंध पहचानने वाले संबंध के रूप में जाना जाता है।
- एक विशेष पहचान के लिए, जो कमजोर इकाई उसी मालिक इकाई से संबंधित है, एक विशेषणों का सेट उपयोग किया जाता है जिसे आंशिक कुंजी कहा जाता है। कभी-कभी, आंशिक कुंजी को विभाजक भी कहा जाता है।
- उदाहरण के लिए, यदि हम मानते हैं कि किसी कर्मचारी के दो बच्चों के नाम समान नहीं हो सकते, तो बच्चों का विशेषण नाम वह आंशिक कुंजी है जिसका उपयोग बच्चों (कमजोर इकाइयाँ) की पहचान के लिए किया जा सकता है जो उसी कर्मचारी (मालिक इकाई) से संबंधित हैं।
प्रश्न 9: भागीदारी भूमिका क्या है? उन परिस्थितियों को बताएं जिनमें संबंध प्रकारों के विवरण में भूमिका नामों का उपयोग आवश्यक हो जाता है।
उत्तर: प्रत्येक इकाई जो संबंध प्रकार में भाग लेती है, एक विशेष भूमिका निभाती है। भागीदारी भूमिका एक इकाई के अस्तित्व को निर्दिष्ट करती है, जो दूसरे इकाई से संबंध में होने पर निर्भर करती है। ऐसे दो प्रकार की बाधाएँ होती हैं: कुल या आंशिक भागीदारी।
- कुल भागीदारी: यदि यह आवश्यक है कि प्रत्येक इकाई एक विशेष संबंध में भाग ले, तो ऐसी इकाई केवल तभी अस्तित्व में आ सकती है जब वह उस विशेष संबंध में भाग ले। इसे कुल भागीदारी कहा जाता है।
- आंशिक भागीदारी: यदि यह आवश्यक नहीं है कि हर इकाई दूसरे इकाई से संबंधित हो, तो संबंध में इकाई की भागीदारी आंशिक रूप से सीमित होती है। ऐसी इकाई का अस्तित्व तब भी हो सकता है जब उसका एक भाग संबंध में संबंधित न हो।
- यदि किसी दो इकाइयों के बीच दो संबंध होते हैं, तो दोनों संबंधों को मैप करने के लिए सामान्य इकाई की प्राथमिक कुंजी को दो बार शामिल करना आवश्यक है। लेकिन एक संबंध का एक ही नाम नहीं हो सकता, इसलिए, हमें संबंधों को इंगित करने के लिए विभिन्न भूमिका नामों का उपयोग करना पड़ता है।
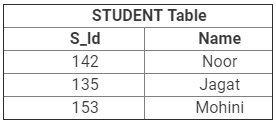
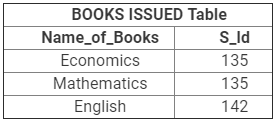
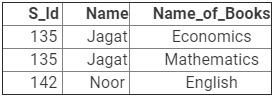
प्रश्न 10: विदेशी कुंजी क्या होती है? यह संबंधात्मक डेटा मॉडल में कैसे उपयोगी है? उपयुक्त उदाहरण देकर स्पष्ट करें।
उत्तर: विदेशी कुंजी को उस कुंजी के रूप में परिभाषित किया जाता है जो दूसरे तालिका के प्राथमिक कुंजी कॉलम को संदर्भित करती है। दूसरे शब्दों में, यह एक संबंधात्मक तालिका में एक फ़ील्ड है जो दूसरी तालिका के प्राथमिक कुंजी से मेल खाती है। ये कुंजी विभिन्न तालिकाओं को एकीकृत डेटाबेस बनाने के लिए संबंधित करती हैं।
- उदाहरण के लिए, मान लीजिए कि हमारे पास दो तालिकाएँ हैं- छात्र तालिका और जारी की गई पुस्तकें तालिका। छात्र तालिका में सभी छात्र डेटा शामिल हैं और जारी की गई पुस्तकें तालिका में स्कूल पुस्तकालय से छात्रों द्वारा जारी की गई सभी पुस्तकें शामिल हैं।
- यहाँ मूल उद्देश्य यह है कि सभी जारी की गई पुस्तकें उन छात्रों से संबंधित होनी चाहिए जो छात्र तालिका में सूचीबद्ध हैं।
- इसके लिए, हमें जारी की गई पुस्तकें तालिका में एक विदेशी कुंजी रखने की आवश्यकता है और इसे छात्र तालिका के प्राथमिक कुंजी से संबंधित करना होगा।
प्रश्न 11: NULL मान का क्या अर्थ है? ऐसे क्या कारण हैं जो डेटाबेस संबंधों में उनके होने का कारण बनते हैं?
उत्तर: डेटा आइटम की अनुपस्थिति जिसे एक विशेष मान से दर्शाया जाता है, उसे NULL मान कहा जाता है। डेटाबेस संबंधों में इसके होने के निम्नलिखित कारण हैं:
- (i) जब एक विशेष विशेषण किसी इकाई पर लागू नहीं होता है।
- (ii) जब किसी विशेषण का मौजूदा मान अज्ञात होता है।
- (iii) जब मान अज्ञात होता है क्योंकि यह अस्तित्व में नहीं होता।
प्रश्न 12: संबंध में डुप्लिकेट टुपल्स की अनुमति क्यों नहीं है?
उत्तर: टुपल तालिका में एक पंक्ति को संदर्भित करता है जो संबंधित डेटा मानों का सेट या संग्रह का प्रतिनिधित्व करता है। यह उस संबंध का प्रतिनिधित्व करता है जो इकाई प्रकार को टुपल्स के सेट के रूप में दर्शाता है, जहाँ प्रत्येक टुपल विशेषणों के लिए मानों की क्रमबद्ध सूची होती है। चूंकि प्रत्येक टुपल एक अलग डेटा रिकॉर्ड इकाई का प्रतिनिधित्व करता है, इसलिए एक संबंध (यानी एक तालिका) में कोई दो टुपल समान डेटा आइटम के लिए समान मानों का संयोजन नहीं रख सकते।
- इसके अलावा, यदि संबंध में एक नया टुपल जोड़ा जाता है, तो इसे मौजूदा डेटा-मानों को नहीं दर्शाना चाहिए, अन्यथा यह अद्वितीयता बाधा का उल्लंघन करेगा और संबंध समग्र रूप से न्यूनतम सुपर-कुंजी नहीं रखेगा।
प्रश्न 13: संबंधों की संघ संगतता से आपका क्या तात्पर्य है? ऐसी कौन सी क्रियाएँ हैं जिनके लिए ऐसी संगतता आवश्यक है और क्यों?
उत्तर: संघ संगतता का तात्पर्य है कि भाग लेने वाले संबंधों को निम्नलिखित शर्तों को पूरा करना चाहिए:
- 1. समान डिग्री: यानि दोनों संबंधों में विशेषणों की संख्या समान होनी चाहिए।
- 2. संबंध A और संबंध B के प्रत्येक संबंधित जोड़े के विशेषणों का समान डोमेन, अर्थात Dom(A) = Dom(B) होना चाहिए। इसका अर्थ है कि संबंधित विशेषणों का डोमेन (डेटा प्रकार) समान होना चाहिए।
इस प्रकार, हम कह सकते हैं कि कोई भी दो संबंध, जैसे संबंध A और संबंध B, संघ संगत होते हैं, यदि (और केवल यदि) दोनों संबंधों में समान संख्या में विशेषण होते हैं और उनके संबंधित विशेषणों के डोमेन समान होते हैं। संघ संगतता की आवश्यकता वाली विभिन्न क्रियाएँ निम्नलिखित हैं:
- 1. संघ (A ∪ B) - इसमें प्रत्येक संबंध से सभी टुपल्स शामिल होते हैं।
- 2. छेदन (A ∩ B) - इसमें वे सभी टुपल्स शामिल होते हैं जो दोनों संबंध A और B में होते हैं।
- 3. अंतर (A - B) - इसमें वे सभी टुपल्स शामिल होते हैं जो संबंध A में होते हैं लेकिन संबंध B में नहीं होते।
- 4. कार्टेशियन उत्पाद (A x B) - इसमें सभी संयोजित टुपल्स (x, y) का सेट होता है, जहाँ x संबंध A में एक टुपल है और y संबंध B में एक टुपल है।
इन क्रियाओं को चलाने के लिए, यह महत्वपूर्ण है कि दोनों संबंध संघ संगत हों। इसका कारण यह है कि संघ संगतता के बिना, अर्थात विशेषणों की समान डिग्री और समान डोमेन न होने पर, ऐसी क्रियाओं को निष्पादित करने में कठिनाई हो सकती है।
प्रश्न 14: डेटाबेस सामान्यीकरण की आवश्यकता क्या है?
उत्तर: डेटाबेस सामान्यीकरण उस प्रक्रिया को संदर्भित करता है जिसमें डेटा को डेटाबेस में कुशलता से व्यवस्थित और बनाए रखा जाता है। डेटाबेस को सामान्यीकृत करने के पीछे के मूल कारण हैं:
- 1. डेटा पुनरावृत्ति को समाप्त करना, यानि एक ही डेटा को एक से अधिक स्थानों पर संग्रहित करने से बचना।
- 2. डेटा निर्भरता सुनिश्चित करना, यानि संबंधित डेटा को डेटाबेस में संग्रहीत करना।
डेटाबेस सामान्यीकरण एक बहुत महत्वपूर्ण प्रक्रिया है क्योंकि यह डेटाबेस को अप्रासंगिक डेटा के संग्रह से मुक्त बनाती है और डेटाबेस से डुप्लिकेट डेटा आइटम को हटा देती है। परिणामस्वरूप, सामान्यीकरण यह सुनिश्चित करता है कि डेटाबेस में अधिक खाली स्थान उपलब्ध हो। इसके अतिरिक्त, सामान्यीकरण डेटाबेस की विश्वसनीयता और स्थिरता को बढ़ाता है और डेटा विसंगतियों जैसे तार्किक और संरचनात्मक समस्याओं के खिलाफ डेटाबेस की रक्षा करता है।

पृष्ठ संख्या: 561
लंबे उत्तर प्रश्न 1: एंटिटी रिलेशनशिप (ER) मॉडल के मूलभूत सिद्धांतों पर चर्चा करें। दर्शाएँ कि एक ER मॉडल को कैसे चित्रित किया जाता है।
उत्तर: एंटिटी रिलेशनशिप (ER) डेटा मॉडल का प्रस्ताव पीटर पिन-शान चेन द्वारा 1976 में किया गया था। यह मॉडल DBMS का उपयोग करके एक अनुप्रयोग डेटाबेस को फ्रेम करने के लिए विकसित किया गया है। ER मॉडल पुराने हाइरार्किकल और नेटवर्क दृष्टिकोण मॉडलों का सामान्यीकरण है। यह मॉडल डेटा को निम्नलिखित तत्वों के संदर्भ में वर्णित करता है:
- एंटिटीज
- एट्रिब्यूट्स
- एंटिटीज के बीच संबंध
ER मॉडल के ये प्रमुख तत्व एक वास्तविकता (रियलिटी) को व्यक्त करने के लिए उपयोग किए जाते हैं जिसके लिए डेटाबेस को डिज़ाइन किया जाना है। ER मॉडल का उपयोग करते हुए डेटाबेस संरचना को ER आरेखों की मदद से चित्रित किया जा सकता है। विभिन्न प्रकार की एंटिटीज, एट्रिब्यूट्स, पहचानकर्ता और संबंधों का प्रतिनिधित्व करने के लिए विभिन्न प्रतीकों का उपयोग किया जाता है।
प्रश्न 2: डेटाबेस स्कीमा पर कौन से इंटीग्रिटी कंस्ट्रेंट्स निर्दिष्ट किए जाते हैं? प्रत्येक को महत्वपूर्ण क्यों माना जाता है?
उत्तर: डेटाबेस स्कीमा का तात्पर्य डेटाबेस की संरचना और डिज़ाइन से है। डेटाबेस स्कीमा को टेबल, कंस्ट्रेंट्स, संबंध, आदि जैसे विभिन्न गुणों के लिए एक सामूहिक शब्द के रूप में माना जाता है। एक रिलेशनल डेटाबेस स्कीमा में रिलेशनल डेटाबेस स्कीमा का एक सेट और इंटीग्रिटी कंस्ट्रेंट्स का एक सेट होता है। एक रिलेशनल डेटाबेस पर लगाए जाने वाले चार प्रमुख इंटीग्रिटी कंस्ट्रेंट्स हैं:
- डोमेन कंस्ट्रेंट्स: ये कंस्ट्रेंट्स डेटाबेस स्कीमा में उन शर्तों को बताते हैं जिन्हें प्रत्येक रिलेशनल उदाहरण को संतुष्ट करना चाहिए।
- की कंस्ट्रेंट्स और NULL मान: ये कंस्ट्रेंट्स उम्मीदवार कुंजियों के अस्तित्व को इंगित करते हैं।
- एंटिटी इंटीग्रिटी कंस्ट्रेंट्स: एक प्राथमिक कुंजी का उपयोग रिलेशन में व्यक्तिगत ट्यूपल की पहचान के लिए किया जाता है।
- रेफेरेंशियल इंटीग्रिटी कंस्ट्रेंट्स: ये कंस्ट्रेंट्स दो या अधिक रिलेशनों के बीच एकता बनाए रखने के लिए निर्दिष्ट किए जाते हैं।
उपरोक्त उल्लेखित इंटीग्रिटी कंस्ट्रेंट्स डेटाबेस स्कीमा पर लगाए जाने वाले कुछ विशेष शर्तें हैं। इंटीग्रिटी कंस्ट्रेंट्स का महत्व यह है कि वे डेटाबेस इंस्टेंस में संग्रहीत डेटा को प्रतिबंधित करते हैं। यदि डेटाबेस इंस्टेंस सभी इंटीग्रिटी कंस्ट्रेंट्स को संतुष्ट करता है, तो इसे एक कानूनी डेटाबेस इंस्टेंस के रूप में माना जाता है।
प्रश्न 3: रिलेशनल डेटाबेस मॉडल में संतुष्ट होने वाले इंटीग्रिटी कंस्ट्रेंट्स के संदर्भ में अपडेट ऑपरेशंस के विभिन्न प्रकारों पर चर्चा करें।
उत्तर: निम्नलिखित रिलेशनल डेटाबेस मॉडल में संतुष्ट होने वाले इंटीग्रिटी कंस्ट्रेंट्स के संदर्भ में विभिन्न प्रकार के अपडेट ऑपरेशंस हैं:
- इंसर्ट: इसका तात्पर्य मौजूदा रिलेशन में एक नए ट्यूपल को जोड़ने से है।
- डिलीट: इस ऑपरेशन का उपयोग रिलेशन से एक मौजूदा ट्यूपल को हटाने के लिए किया जाता है।
- मोफी: इस ऑपरेशन का उपयोग डेटा टेबल में रिकॉर्ड के मौजूदा मानों में बदलाव करने के लिए किया जाता है।
इन अपडेट ऑपरेशंस को लागू करने के बाद, इंटीग्रिटी कंस्ट्रेंट्स को रिलेशनल डेटाबेस स्कीमा पर लागू किया जाता है।
प्रश्न 4: एक ER मॉडल को रिलेशनल डेटा मॉडल के विभिन्न रिश्तों में बदलने के लिए आप कौन से कदम उठाएँगे? उपयुक्त उदाहरण दें।
उत्तर: एक ER मॉडल को रिलेशनल डेटा मॉडल में बदलने के लिए एक ER डिज़ाइन होना आवश्यक है। निम्नलिखित हमारे ER मॉडल का उदाहरण है जिसे हमें रिलेशनल डेटा मॉडल में बदलना है।





ऊपर दिए गए चित्र में, आयताकार बॉक्स का उपयोग संस्थाओं को दर्शाने के लिए किया गया है। हीरे के आकार के बॉक्स का उपयोग दो संस्थाओं के बीच संबंध प्रकार का वर्णन करने के लिए किया गया है। डबल रेखा वाले आयताकार बॉक्स का उपयोग कमजोर संस्थाओं को दिखाने के लिए किया गया है। डबल रेखा वाला हीरे का आकार का बॉक्स पहचानने वाले संबंध प्रकार का वर्णन करता है। अंडाकार में, विशेषता के नाम को शामिल किया गया है और उन्हें सीधे रेखाओं के माध्यम से उनकी संबंधित संस्थाओं के प्रकार से जोड़ा गया है। अगली अनुभाग में ER मॉडल को रिलेशनल डेटा मॉडल में परिवर्तित करने की प्रक्रिया का वर्णन किया गया है।
1. प्रत्येक मजबूत संस्था के लिए संबंध का निर्माण: ER स्कीमा में प्रत्येक मजबूत संस्था के प्रकार के लिए सभी सरल विशेषताओं को शामिल करने वाला एक अलग संबंध बनाया जाएगा। इन विशेषताओं में से एक प्राथमिक कुंजी को आसान और अद्वितीय पहचान के लिए मनमाने तरीके से चुना जाता है। उदाहरण के लिए, ऊपर दिए गए ER डिज़ाइन में, कर्मचारी, वाउचर, खाते और खाता प्रकार मजबूत संस्थाएँ हैं क्योंकि उनके पास प्राथमिक कुंजी होती है जो उनके अद्वितीय विशेषताओं में से एक है। ये विशेषताएँ अंडाकार में दर्शाई गई हैं और सीधे रेखाओं द्वारा उनकी संबंधित संस्थाओं के प्रकार से जोड़ी गई हैं। प्रत्येक मजबूत संस्था के लिए अलग संबंध बनाया जाता है। इसे इस प्रकार दर्शाया जाता है: कर्मचारी (EmpId, नाम, प्रकार) वाउचर (VNo, SNo, वर्णन) खाते (प्रकार, नाम, कोड) खाता प्रकार (CatId, श्रेणी)
2. प्रत्येक कमजोर संस्था प्रकार के लिए संबंध का निर्माण: कमजोर संस्थाएँ अपनी पहचान नहीं रखती हैं और पहचानने वाले संबंध के माध्यम से पहचानी जाती हैं। इसलिए, हम कह सकते हैं कि प्रत्येक कमजोर संस्था का अपना एक पहचानने वाला तत्व होता है जो इसकी पहचान में मदद करता है। प्रत्येक कमजोर संस्था के लिए विशेषताओं को शामिल करने वाला एक अलग संबंध बनाया जाना चाहिए। इस नए संबंध की प्राथमिक कुंजी इसके अद्वितीय विशेषताओं के संयोजन के साथ मालिक संबंध की प्राथमिक कुंजी विशेषता होती है। उदाहरण के लिए, समर्थन संस्था कमजोर संस्था है क्योंकि इसकी अपनी प्राथमिक कुंजी नहीं है; वाउचर समर्थन संस्था का मालिक तत्व है। समर्थन संस्था का एक आंशिक कुंजी है जो प्रत्येक दस्तावेज़ को SNo असाइन करती है। इसलिए, VNo, जो वाउचर की प्राथमिक कुंजी है, के साथ SNo को समर्थन संस्था के लिए संयोजित कुंजी के रूप में डिजाइन किया गया है। इस प्रकार बने संबंध को इस प्रकार दर्शाया जा सकता है: समर्थन (VNo, SNo, dName, sDate)
3. द्विआधारी 1: N संबंध प्रकार में भाग लेने वाले पहचान तत्व प्रकार: सबसे पहले, संबंध के n-पक्ष पर पहले संबंध और 1-पक्ष पर दूसरे संबंध की पहचान की जानी चाहिए। दूसरे संबंध की प्राथमिक कुंजी को पहले संबंध में विदेशी कुंजी के रूप में शामिल किया जाना चाहिए। उदाहरण के लिए, इस उदाहरण में, एक कर्मचारी कई वाउचरों को अधिकृत कर सकता है। इसका मतलब है कि वाउचर तत्व पहचानने वाले संबंध में n-पक्ष पर भाग लेता है, जबकि कर्मचारी तत्व उसी संबंध में 1-पक्ष पर भाग लेता है। इसी प्रकार, कर्मचारियों और वाउचरों के बीच Prep. by संबंध द्विआधारी 1: N संबंध में भाग लेता है।
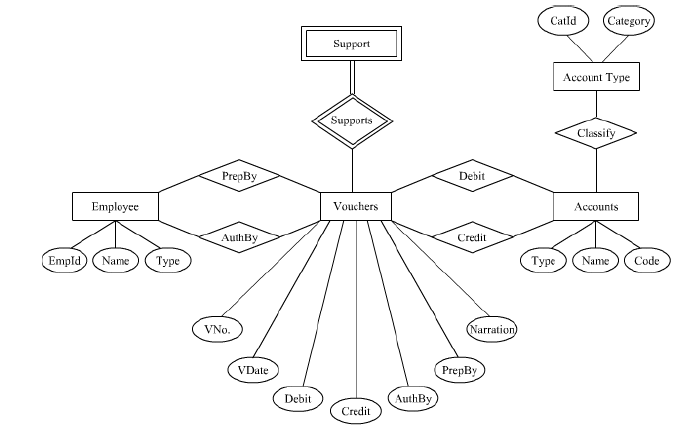
4. बाइनरी M : N संबंध प्रकार में भाग लेने वाले एंटीटी प्रकारों की पहचान करें: प्रत्येक बाइनरी M : N संबंध प्रकार के लिए एक नया संबंध बनाया जाना है। इस नए संबंध में विदेशी कुंजी होनी चाहिए जो नए संबंध की प्राथमिक कुंजी का प्रतिनिधित्व करती है। उदाहरण के लिए, दो एंटीटीज़ पर विचार करें, अर्थात्, Voucher एंटीटी और Account एंटीटी। इन एंटीटीज़ के दो संबंध हैं, debit और credit। Debit संबंध का कार्डिनैलिटी अनुपात N : 1 है, अर्थात् कई debit vouchers एक account से संबंधित होते हैं। दूसरी ओर, credit संबंध का कार्डिनैलिटी अनुपात M : N है। उदाहरण के लिए, कई credit vouchers कई accounts से संबंधित होते हैं।
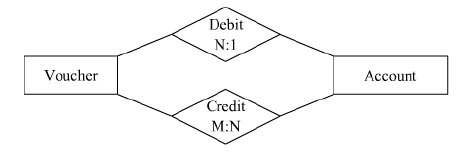
इसलिए, चित्र के आधार पर, निम्नलिखित दो संबंध बनाए जा सकते हैं: (i) Credit (VNo, SNo, Code, Amount, Narration) (ii) Debit (VNo, SNo, Code, Amount, Narration)
Credit संबंध में, Credit Code को Accounts संबंध की प्राथमिक कुंजी का प्रतिनिधित्व करने के लिए विदेशी कुंजी के रूप में शामिल किया गया है। VNo को Vouchers संबंध की प्राथमिक कुंजी का प्रतिनिधित्व करने के लिए विदेशी कुंजी के रूप में शामिल किया गया है। दोनों VNo और Code मिलकर नए संबंध Credit की प्राथमिक कुंजी बनाते हैं।
अंत में, ऊपर दिए गए ER डिज़ाइन के उदाहरण के लिए संबंध डेटा मॉडल बनाने के लिए निम्नलिखित संबंध बनाए गए हैं।
Vouchers (VNo, SNo, Narration)
|
131 docs|110 tests
|


MCQs
,एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण | Indian Economy for Government Exams (Hindi) - Bank Exams
,shortcuts and tricks
,Semester Notes
,Viva Questions
,Exam
,Summary
,Sample Paper
,Previous Year Questions with Solutions
,एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण | Indian Economy for Government Exams (Hindi) - Bank Exams
,practice quizzes
,Important questions
,mock tests for examination
,Objective type Questions
,past year papers
,ppt
,एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण | Indian Economy for Government Exams (Hindi) - Bank Exams
,study material
,Free
,video lectures
,Extra Questions
;


एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण Free PDF Download
Importance of एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण
एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण Notes
एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण Bank Exams Questions
Study एनसीईआरटी समाधान - लेखा के लिए डेटाबेस का संरचनात्मक निर्माण on the App
|
© EduRev
|
Education Revolution
|



|






