डेटा का वर्गीकरण | SSC CGL Tier 2 - Study Material, Online Tests, Previous Year (Hindi) PDF Download

डेटा हमेशा अच्छी तरह से व्यवस्थित नहीं होता है। एक विश्लेषक या अन्वेषक को एकत्रित डेटा को बेहतर विश्लेषण और इच्छित परिणाम प्राप्त करने के लिए ठीक से व्यवस्थित करना चाहिए। ऐसे डेटा को व्यवस्थित करने का एक महत्वपूर्ण तरीका है डेटा वर्गीकरण। इस दृष्टिकोण के माध्यम से, कच्चे डेटा को विभिन्न सांख्यिकीय श्रृंखलाओं में परिवर्तित किया जाता है ताकि अधिक मूल्यवान और सूचनापरक परिणाम प्राप्त किए जा सकें।
डेटा का वर्गीकरण
सांख्यिकीय विश्लेषण करने के लिए, विभिन्न प्रकार के डेटा को अन्वेषक या विश्लेषक द्वारा एकत्रित किया जाता है। प्रारंभ में, डेटा कच्चा रूप में होता है, जिससे इसका विश्लेषण करना कठिन होता है। विश्लेषण को अर्थपूर्ण और सरल बनाने के लिए, कच्चे डेटा को उनकी विशेषताओं के आधार पर विभिन्न श्रेणियों में व्यवस्थित या वर्गीकृत किया जाता है। इस प्रक्रिया को डेटा का वर्गीकरण कहा जाता है, जहां समान या समरूप विशेषताओं को विभिन्न श्रेणियों या वर्गों में समूहित किया जाता है। इन श्रेणियों में से प्रत्येक को क्लास कहा जाता है। सांख्यिकीय जानकारी को वर्गीकृत करने के लिए मुख्य आधारों में शामिल हैं:
- भौगोलिक
- कालानुक्रमिक
- गुणात्मक (साधारण और विविध दोनों)
- मात्रात्मक या संख्यात्मक
डेटा का वर्गीकरण
सांख्यिकीय विश्लेषण करने के लिए, विभिन्न प्रकार के डेटा का संग्रह किया जाता है, जो कि अन्वेषक या विश्लेषक द्वारा किया जाता है। प्रारंभ में, डेटा कच्चे रूप में होता है, जिससे इसका विश्लेषण करना कठिन हो जाता है। विश्लेषण को अर्थपूर्ण और सरल बनाने के लिए, कच्चे डेटा को उनके गुणों के आधार पर विभिन्न श्रेणियों में व्यवस्थित या वर्गीकृत किया जाता है। इस प्रक्रिया को डेटा का वर्गीकरण कहा जाता है, जहाँ समान या समान गुणों को विभिन्न श्रेणियों या कक्षाओं में समूहबद्ध किया जाता है। इन कक्षाओं में से प्रत्येक को एक कक्षा कहा जाता है। सांख्यिकीय जानकारी को वर्गीकृत करने के लिए प्राथमिक आधारों में भौगोलिक, कालक्रमिक, गुणात्मक (सरल और विविध दोनों) और मात्रात्मक या संख्यात्मक शामिल हैं।
उदाहरण के लिए, यदि एक अन्वेषक किसी राज्य में गरीबी स्तर का मूल्यांकन करना चाहता है, तो वह राज्य के निवासियों के बारे में जानकारी एकत्र कर सकता है और फिर इसे आय और शिक्षा जैसे कारकों के आधार पर वर्गीकृत कर सकता है।
डेटा के वर्गीकरण के उद्देश्य
- संक्षिप्त और सरल: एकत्रित कच्चे डेटा को बेहतर समझ के लिए विभिन्न समूहों में व्यवस्थित करने की आवश्यकता होती है। डेटा का वर्गीकरण जानकारी को स्पष्ट और संक्षिप्त रूप से प्रस्तुत करने में मदद करता है, जिससे विश्लेषण सरल हो जाता है।
- उपयोगिता: विश्लेषक विभिन्न स्रोतों से जानकारी एकत्र करते हैं और इसे वर्गीकृत करते हैं ताकि समानताओं को उजागर किया जा सके, जिससे इसकी उपयोगिता में सुधार होता है।
- विशिष्टता: डेटा को श्रेणियों में विभाजित करने से भिन्नताएँ अधिक स्पष्ट हो जाती हैं, जिससे विषम डेटा से स्पष्ट निष्कर्ष निकालने में मदद मिलती है।
- तुलनीयता: डेटा वर्गीकरण डेटा सेटों के बीच तुलना की अनुमति देता है, जिससे जानकारी का अनुमान और विश्लेषण करना सरल हो जाता है।
- वैज्ञानिक व्यवस्था: सामान्य गुणों के आधार पर डेटा का आयोजन एक तार्किक और विश्वसनीय व्यवस्था को सुविधाजनक बनाता है, जिससे डेटा की विश्वसनीयता बढ़ती है।
- आकर्षक और प्रभावी: अच्छी तरह से वर्गीकृत डेटा न केवल प्रभावशीलता को बढ़ाता है बल्कि जानकारी को दृष्टिगत रूप से आकर्षक और एक नज़र में समझने में आसान बनाता है।
एक अच्छे वर्गीकरण की विशेषताएँ
अच्छी वर्गीकरण की विशेषताएँ
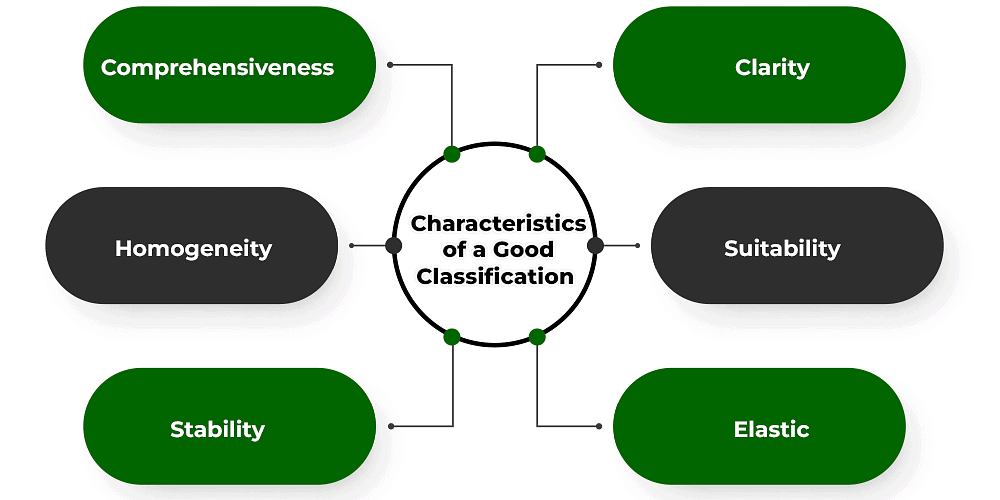
- व्यापकता: बेहतर परिणाम प्राप्त करने के लिए, एकत्रित कच्चे डेटा को एक व्यवस्थित तरीके से व्यवस्थित करना आवश्यक है। इसमें प्रत्येक डेटा को एक विशेष वर्ग, श्रेणी या समूह में रखना शामिल है, यह सुनिश्चित करते हुए कि कुछ भी अनदेखा न हो।
- स्पष्टता: डेटा एकत्र करने और आंकलन करने वाले व्यक्ति को कच्ची जानकारी को स्पष्टता के साथ विभिन्न समूहों में वर्गीकृत करना चाहिए। विभिन्न श्रेणियों में वस्तुओं के स्पष्ट आवंटन को सुनिश्चित करना पाठक या जांचकर्ता के लिए किसी भी भ्रम को रोकता है।
- समरूपता: प्रभावी जांच परिणामों के लिए, एकत्रित कच्चे डेटा को समरूप श्रेणियों में समूहित करना महत्वपूर्ण है। समान विशेषताओं के आधार पर डेटा का वर्गीकरण डेटा के विश्लेषण को आसान और अधिक सटीक बनाता है।
- उपयुक्तता: डेटा वर्गीकरण के लिए उपयोगी होने के लिए, इसे जांच के उद्देश्यों के साथ मेल खाना चाहिए। उदाहरण के लिए, जब किसी देश की साक्षरता दर का निर्धारण किया जा रहा है, तो आय और व्यय के आधार पर डेटा का वर्गीकरण अव्यवहारिक है। डेटा को शिक्षित और अशिक्षित के रूप में वर्गीकृत किया जाना चाहिए।
- स्थिरता: डेटा के वर्गीकरण में स्थिरता आवश्यक है। इसका अर्थ है कि डेटा वर्गीकरण के लिए मानदंडों को जांचों के बीच में स्थिर रहना चाहिए। प्रत्येक प्रकार की जांच को समान वर्गीकरण मानदंडों का उपयोग करना चाहिए।
- लचीला: डेटा वर्गीकरण को लचीला होना चाहिए। यह लचीलापन वर्गीकरण में समायोजन की अनुमति देता है यदि जांच का उद्देश्य या ध्यान बदलता है। जांचकर्ताओं को आवश्यकतानुसार वर्गीकरण में संशोधन करने में सक्षम होना चाहिए।
डेटा का वर्गीकरण करने के आधार
डेटा का वर्गीकरण डेटा को व्यवस्थित ढंग से व्यवस्थित करने की प्रक्रिया है। अब हम सांख्यिकी में डेटा वर्गीकरण के प्रकारों के बारे में सीखते हैं। वर्गीकरण के चार महत्वपूर्ण आधारों पर चर्चा की गई है:
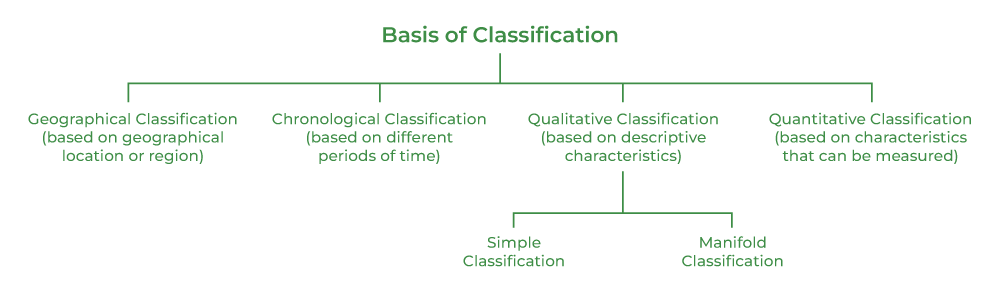
भौगोलिक डेटा वर्गीकरण
- जानकारी का समूह बनाना जिस पर यह आधारित हो, उसे भौगोलिक डेटा वर्गीकरण कहा जाता है।
- सरल शब्दों में, भौगोलिक डेटा वर्गीकरण में जानकारी को भौगोलिक स्थान या क्षेत्र के अनुसार व्यवस्थित करना शामिल है।
- उदाहरण के लिए, यदि हम भारत के चार मुख्य क्षेत्रों के आधार पर गन्ना, दालें, या कपास के उत्पादन का वर्गीकरण करते हैं, तो यह भौगोलिक डेटा वर्गीकरण के अंतर्गत आता है।
| क्षेत्र | दालों का उत्पादन (किलो में) |
|---|---|
| पूर्वी क्षेत्र | 2837 |
| पश्चिमी क्षेत्र | 968 |
| दक्षिणी क्षेत्र | 2149 |
| उत्तर क्षेत्र | 1746 |
इसे ‘स्थानिक डेटा वर्गीकरण’ के रूप में भी जाना जाता है।
कालक्रम अनुसार डेटा वर्गीकरण
डेटा को समय के अनुसार व्यवस्थित करना, जानकारी को उस समय के आधार पर समूहित करना होता है जब यह घटना हुई थी, जैसे वर्ष, महीने, सप्ताह और दिन। यह वर्गीकरण डेटा को समय की इकाइयों जैसे वर्ष, तिमाही, महीने, सप्ताह और दिनों के संदर्भ में बढ़ते या घटते क्रम में व्यवस्थित करता है। इस प्रकार के डेटा वर्गीकरण को कालिक डेटा वर्गीकरण भी कहा जाता है।
| वर्ष | एक स्कूल में छात्रों की संख्या |
|---|---|
| 2015 | 1270 |
| 2017 | 1890 |
| 2019 | 1750 |
| 2020 | 1530 |
गुणात्मक डेटा वर्गीकरण
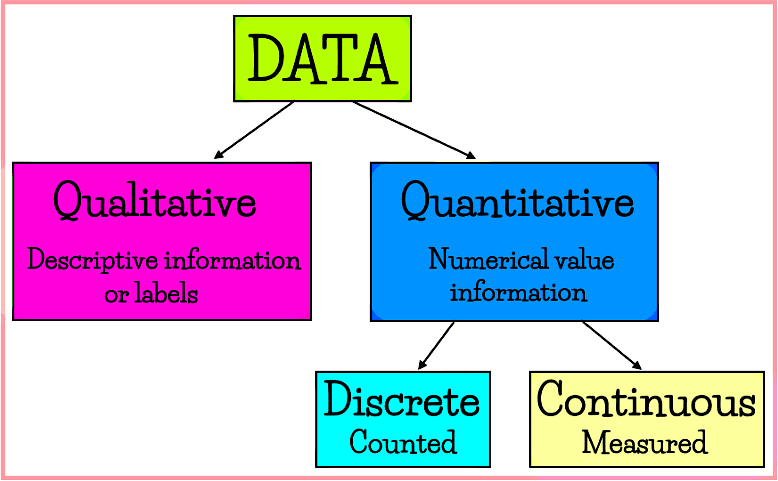
- गुणों और विशेषताओं के आधार पर जानकारी का वर्गीकरण गुणात्मक डेटा वर्गीकरण कहलाता है।
- इस प्रकार के समूह में, डेटा को लिंग, ईमानदारी, बालों का रंग, साक्षरता, बुद्धिमत्ता, धर्म, आदि जैसी विशिष्ट विशेषताओं के द्वारा श्रेणीबद्ध किया जाता है।
- सांख्यिकी में गुणात्मक डेटा वर्गीकरण करते समय, अध्ययन की जा रही विशेषता को मापा नहीं जा सकता; इसे केवल उपस्थित या अनुपस्थित के रूप में पहचाना जा सकता है।
- गुणात्मक डेटा आमतौर पर दो मुख्य श्रेणियों में विभाजित होता है: डेटा को विशेषताओं के आधार पर व्यवस्थित किया जाता है।
- विशेषताओं के उदाहरणों में लिंग, ईमानदारी, बालों का रंग, साक्षरता, बुद्धिमत्ता, और धर्म शामिल हैं।
- विशेषताएँ सीधे मापी नहीं जा सकतीं।
गुणात्मक डेटा के दो प्रमुख प्रकार होते हैं।
- साधारण डेटा वर्गीकरण
साधारण डेटा वर्गीकरण
- उद्देश्य: इस प्रकार की जानकारी को वर्गीकृत करने में, हम डेटा को दो विशिष्ट समूहों में बांटते हैं। उदाहरण के लिए, यदि हम छात्रों को एक विशेषता के आधार पर देख रहे हैं, जैसे उनकी शिक्षा का स्तर, तो हम उन्हें दो श्रेणियों में विभाजित कर सकते हैं: शिक्षित और अशिक्षित। इसी प्रकार, उन्हें प्राथमिक शिक्षा या उच्च शिक्षा के अनुसार भी वर्गीकृत किया जा सकता है।
- विधि: इस वर्गीकरण की विधि जिसमें हम दो अलग-अलग समूह बनाते हैं, इसे साधारण या द्विकीय (dichotomous) डेटा वर्गीकरण कहा जाता है। यहां, हम एक समूह बनाते हैं जिसमें निर्दिष्ट विशेषता होती है और दूसरा समूह जिसमें वह विशेषता नहीं होती।
विभिन्न डेटा वर्गीकरण
- यदि हम केवल दो समूह बनाने के अलावा, उन समूहों में अतिरिक्त विशेषताओं के आधार पर जानकारी को और विभाजित करते हैं, तो इसे विभिन्न वर्गीकरण कहा जाता है। इसका अर्थ है कि एक विशेषता के आधार पर डेटा को दो समूहों में विभाजित करने के बाद, उन समूहों को फिर से किसी अन्य विशेषता के आधार पर दो और में बांटा जाता है। इससे डेटा वर्गीकरण के कई स्तर उत्पन्न हो सकते हैं जिनमें केवल दो श्रेणियाँ नहीं होतीं।
- उदाहरण के लिए, हम छात्र जनसंख्या को पुरुषों और महिलाओं में वर्गीकृत कर सकते हैं। फिर, इन समूहों को शिक्षित और अशिक्षित व्यक्तियों में और फिर प्राथमिक शिक्षा और उच्च शिक्षा स्तरों में वर्गीकृत किया जा सकता है।
मात्रात्मक डेटा वर्गीकरण
- मात्रात्मक डेटा वर्गीकरण ऐसे संख्याओं से संबंधित होता है जिन्हें मापा या गणना की जा सकती है, जो गुणात्मक वर्गीकरण के विपरीत है। यह डेटा को संख्यात्मक श्रेणियों में वर्गीकृत करने की अनुमति देता है।
- एक मात्रात्मक चर एक संख्यात्मक पैमाने पर जानकारी देता है और इसे मापा या संचालित किया जा सकता है। उदाहरणों में वजन, तापमान, मात्रा, ऊंचाई, आय, छात्र ग्रेड, और संख्यात्मक मान शामिल हैं।
- आंकड़ों में, डेटा को विभिन्न मानों की सीमाओं के आधार पर वर्गीकृत किया जाता है, यह दिखाते हुए कि समय के साथ या विभिन्न क्षेत्रों में चीजें कैसे बदलती हैं। मात्रात्मक वर्गीकरण को चर द्वारा वर्गीकरण भी कहा जाता है।
- मात्रात्मक डेटा के दो प्रकार होते हैं: विभाज्य (discrete) और निरंतर (continuous)।
- विभाज्य मात्रात्मक डेटा में वे चर शामिल होते हैं जिन्हें गिना जा सकता है और जिनका एक विशेष, सीमित मान होता है।
- निरंतर मात्रात्मक डेटा वे मान होते हैं जिन्हें मापा जा सकता है और जो एक सीमा में भिन्न हो सकते हैं।
विभाज्य मात्रात्मक डेटा का उदाहरण:
कक्षा में छात्रों की संख्या: USB ड्राइव पर संग्रहीत कुल डेटा।
निरंतर मात्रात्मक डेटा का उदाहरण:
- गर्मी के दिनों में प्रत्येक दिन का तापमान।
- एक ट्रेन पर प्रत्येक यात्री का वजन।
डेटा वर्गीकरण पर महत्वपूर्ण बिंदु
- डेटा का वर्गीकरण: डेटा को प्रकारों में व्यवस्थित किया जाता है, और हम उन्हें एक-एक करके अध्ययन करते हैं। सांख्यिकी में वर्गीकरण की समझ बहुत महत्वपूर्ण है।
- चर: चर का अर्थ है कुछ ऐसा जो बदलता है। यह व्यक्ति से व्यक्ति, समय से समय, या स्थान से स्थान में भिन्न हो सकता है। इसके दो मुख्य प्रकार हैं: अविभाजित और निरंतर चर।
- आवृत्ति और आवृत्ति वितरण: आवृत्ति यह दर्शाती है कि प्रत्येक चर कितनी बार प्रकट होता है। आवृत्ति वितरण में उन मापनीय चर जैसे दरें, वजन या भुगतान के आधार पर डेटा का विश्लेषण किया जाता है।
- तालिका: सांख्यिकीय डेटा को कॉलम और पंक्तियों के साथ व्यवस्थित करने का एक संरचित तरीका। पंक्तियाँ क्षैतिज होती हैं, जबकि कॉलम लंबवत होते हैं।
- डेटा वर्गीकरण के प्रकार:
- एकतरफा वर्गीकरण: एकल विशेषता के आधार पर डेटा को छांटना।
- दोतरफा वर्गीकरण: दो विशेषताओं के आधार पर डेटा को एक साथ छांटना।
- बहुततरफा वर्गीकरण: एक साथ दो से अधिक विशेषताओं के आधार पर डेटा को छांटना।
- माप के स्तर: सांख्यिकीय डेटा माप के चार स्तर होते हैं: नाममात्र, क्रमिक, अंतराल, और अनुपात, जो सबसे कम से सबसे अधिक सटीकता तक फैले होते हैं।
|
374 videos|1072 docs|1174 tests
|


Objective type Questions
,Previous Year (Hindi)
,Extra Questions
,Online Tests
,mock tests for examination
,डेटा का वर्गीकरण | SSC CGL Tier 2 - Study Material
,MCQs
,practice quizzes
,Summary
,Viva Questions
,Free
,Previous Year (Hindi)
,Previous Year Questions with Solutions
,ppt
,study material
,Semester Notes
,डेटा का वर्गीकरण | SSC CGL Tier 2 - Study Material
,Sample Paper
,shortcuts and tricks
,video lectures
,Online Tests
,Important questions
,Online Tests
,past year papers
,Previous Year (Hindi)
,Exam
,डेटा का वर्गीकरण | SSC CGL Tier 2 - Study Material
;






डेटा का वर्गीकरण Free PDF Download
Importance of डेटा का वर्गीकरण
डेटा का वर्गीकरण Notes
डेटा का वर्गीकरण SSC CGL Questions
Study डेटा का वर्गीकरण on the App
|
© EduRev
|
Education Revolution
|



|





