Proteins - 1 Chapter Notes | Biochemistry - NEET PG PDF Download

Chemistry of Proteins
What are Proteins Made Of?
- Proteins are large molecules made up of smaller units called amino acids. They are primarily composed of four elements: carbon (C), hydrogen (H), oxygen (O), and nitrogen (N).
- One of the distinctive features of proteins is the presence of nitrogen, which constitutes about 16% of the protein's weight on average.
What is a Peptide Bond?
A peptide bond is the link that holds all proteins together. It forms when the alpha carboxyl group of one amino acid reacts with the alpha amino group of another amino acid, creating a bond between them. This process results in the formation of a CO-NH bridge, which is the basis of the protein's structure.
- N-terminal end. This is the end of the protein chain where the amino group (NH2) of the terminal amino acid is free.
- C-terminal end. This is the end of the protein chain where the carboxyl group (CO-OH) is free.
- The sequence of amino acids in a protein is arranged from the N-terminal end to the C-terminal end.
Characteristics of Peptide Bond
- Partial double bond character
- Rigid and planar
- C-N bond is trans in nature
- Uncharged but polar.
Atypical Peptide Bond (Pseudopeptide Bond)(Isopeptide Bond)
An atypical peptide bond, also known as a pseudopeptide bond or isopeptide bond, is a specific type of amide bond that forms between an amino group and a carboxyl group, where at least one of these groups is not an alpha group. This bond is typically found in the side chains of proteins rather than in the standard backbone structure.
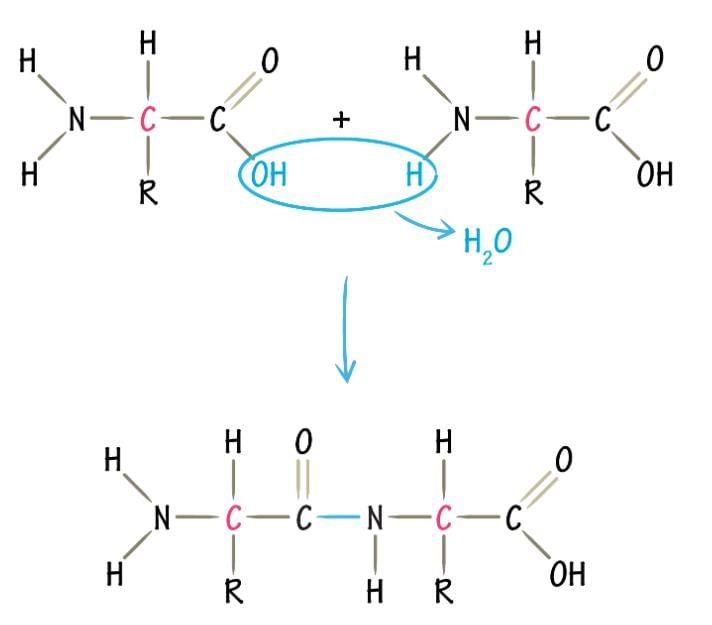 Formation of peptide bond
Formation of peptide bond
Characteristic features of an atypical peptide bond
- Occurs post-translationally. Atypical peptide bonds are formed after the initial translation of the protein has occurred. This means that they are not a part of the primary sequence of the protein but are added later during the protein's lifecycle.
- Can be formed spontaneously or enzymatically. These bonds can form on their own under certain conditions or with the help of enzymes. The ability to form these bonds spontaneously adds to the versatility of protein structures.
- Can produce stably linked protein dimers, multimers, or complexes: Atypical peptide bonds can link proteins together in a stable manner, forming dimers (two proteins), multimers (multiple proteins), or complexes (assemblies of proteins). This is important for the functionality of many proteins that need to work together in groups.
- Makes the protein resistant to hydrolysis by certain proteases. Proteins with atypical peptide bonds are more resistant to being broken down by specific proteases, which are enzymes that cut proteins. This resistance can be crucial for the stability and longevity of certain protein structures.
Examples of Peptides
- Blood Clots: Peptides play a crucial role in the formation of blood clots.
- Cyclic Peptide Antibiotics: Antibiotics such as thyrocidin and gramicidin are examples of cyclic peptide antibiotics that are effective against bacterial infections.
- Heptapeptides: Dermorphin and deltorphin are examples of heptapeptides that have potent analgesic properties.
Application of Spontaneous Isopeptide Bond Formation
- The Isopeptag is a novel peptide tag that has been developed for various applications in protein targeting and imaging.
- In vivo protein targeting: The Isopeptag can be used to target specific proteins within living organisms, allowing for precise manipulation and study of protein functions.
- Fluorescence microscopy imaging: The Isopeptag can also be used in fluorescence microscopy imaging to visualize and track specific proteins within cells and tissues.
Some Biologically Important Peptides
- Tripeptide: Thyrotropin-releasing Hormone (TRH), Glutathione
- Pentapeptide: Enkephalin
- Octapeptide: Angiotensin II
- Nonapeptide: Oxytocin, Vasopressin [ADH], Bradykinin
- Decapeptide: Various biologically active peptides
Classification of Proteins
Proteins can be classified based on their shape into fibrous and globular proteins.
Fibrous Proteins
- Structure: These proteins have an elongated, needle-like, cylindrical, or rod-shaped structure.
- Solubility: Fibrous proteins are not very soluble in water.
- Secondary Structure: They have a regular secondary structure.
- Axial Ratio: The axial ratio of fibrous proteins is greater than 10, indicating their elongated shape compared to globular proteins.
- Function: These proteins primarily function as structural components.
- Examples: Common examples of fibrous proteins include collagen, elastin, and keratin.
Globular Proteins
- Structure: Globular proteins are spherical, oval, or spheroidal in shape.
- Solubility: These proteins are easily soluble in water.
- Axial Ratio: The axial ratio of globular proteins is less than 10.
- Function: Globular proteins perform various dynamic functions within the organism.
- Examples: Examples of globular proteins include albumin, globulin, and most enzymes.
Based on Nutritional Value
Nutritionally Rich (Complete Protein or First Class Proteins)
- These proteins contain all the essential amino acids in the right proportions.
- For instance, casein found in milk is a good example.
Incomplete Protein
- Incomplete proteins are those that lack at least one essential amino acid necessary for human health.
- A crucial example of an essential amino acid is lysine.
- It might be helpful to use a mnemonic to remember the essential amino acids.
Poor Protein
- Poor-quality proteins are deficient in several essential amino acids.
- An example of this is zein, a protein derived from corn, which is low in tryptophan and lysine.
Proteins Based on Composition
Simple Proteins
These proteins are made up entirely of amino acids, without any additional components.
- Examples: Albumin and Globulin.
Conjugated Proteins
Conjugated proteins are composed of both proteins and a non-protein component called a prosthetic group.
Constituents of Conjugated Proteins
- Glycoproteins: These are proteins linked with carbohydrates. For instance, blood group antigens are plasma proteins that do not include albumin, TSHQ, FSHQ, and LHQ.
- Lipoproteins: These consist of proteins and lipids. Examples include Chylomicrons, LDL (Low-Density Lipoprotein), HDL (High-Density Lipoprotein), and VLDL (Very Low-Density Lipoprotein).
- Nucleoproteins: These are proteins associated with nucleic acids. Histones are a common example of nucleoproteins.
- Chromoproteins: These proteins contain a coloured prosthetic group. Hemoglobin, a type of hemoprotein, is a well-known example. Flavoproteins are another category of chromoproteins.
- Phosphoproteins: These proteins contain phosphorus. Casein, found in milk, and Vitellin, found in egg yolk, are examples of phosphoproteins.
- Metalloproteins: These proteins include metal ions as part of their structure. For instance, Tyrosinase contains copper, while Carbonic anhydrase contains zinc.
Levels of Protein Structure
1. Primary Structure
The primary structure of a protein refers to the linear sequence of amino acids linked together by peptide bonds, which are a specific type of covalent bond.
- The order of amino acids in the chain is crucial as it determines the protein's eventual 3D structure.
- Short segments of polypeptides, typically comprising 3 to 30 amino acids, begin to fold into distinct shapes, with the amino acids involved being roughly 3–4 amino acids apart in the sequence.
2. Secondary Structure
The secondary structure of a protein is primarily maintained by non-covalent interactions, which include:
- Hydrogen bonds (the most important type)
- Hydrophobic interactions
- Electrostatic interactions (ionic bonds, salt bridges)
- Van der Waals forces
Common forms of secondary structures are:
- Alpha helix
- Beta pleated sheet
- Loops
- Bends
- Turns
Alpha Helix
- The alpha helix is the most common and stable form of secondary structure in proteins.
- It is characterized by a right-handed spiral formation.
- This structure is primarily stabilized by intrachain hydrogen bonds, which occur between the carbonyl oxygen of one amino acid and the amide nitrogen of another amino acid four residues down the chain.
- Each complete turn of the helix contains 3.6 amino acids, with a distance of 0.54 nm between turns, known as the pitch of the helix.
- Proline is a unique amino acid that fits well within this structure due to its cyclic nature.
Examples of proteins with significant alpha helix content include:
- Hemoglobin
- Myoglobin
Beta-Pleated Sheet
- The beta-pleated sheet is the second most prevalent secondary structure found in proteins.
- In this arrangement, the polypeptide chain is nearly fully extended, and hydrogen bonds form between the carbonyl oxygen of one chain and the amide nitrogen of an adjacent chain, unlike the intrachain bonding seen in alpha helices.
- Strands within a beta sheet can be oriented in the same direction, known as parallel sheets, or in opposite directions, referred to as antiparallel sheets.
Examples of proteins featuring beta sheets include:
- Parallel beta sheet: Flavodoxin
- Antiparallel beta sheet: Silk fibroin
- Both types: Carbonic anhydrase
Turns and Bends
- Turns and bends are short segments of amino acids that connect two units of secondary structures.
- An example of a turn is the beta turn.
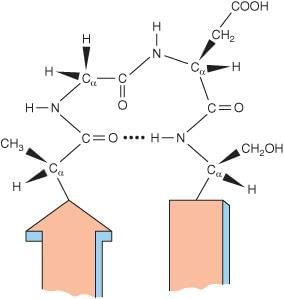 Structure of beta turn
Structure of beta turn
Beta Turn
- A beta turn involves four amino acid residues.
- The first amino acid residue is hydrogen bonded to the fourth, resulting in a tight 180° turn.
- Proline and Glycine are significant in beta turns.
Loops are long segments of amino acids that connect two secondary structures.
Amino acids have different tendencies to form alpha helices, beta sheets, and beta turns.
The frequency of occurrence of specific amino acid residues determines the secondary structure formed.
- Alanine, Glutamate, Methionine, and Leucine are common in the alpha helix.
- The most abundant amino acid is Methionine, followed by Glutamate.
- Proline is the least present amino acid in the alpha helix.
Amino acids that do not favour alpha helices include:
- Valine, Threonine, and Isoleucine disrupt stability.
- Serine, Aspartate, and Asparagine also disrupt stability.
- Proline disrupts the stability of the alpha helix.
- Glycine does not favour alpha helix formation.
Beta Sheet
- Valine and Isoleucine are often found in beta strands.
- Valine is among the amino acids commonly present in beta sheets.
- The amino acid least present in beta sheets is Proline.
- The most abundant amino acid in turns is Proline, followed by Glycine.
Supersecondary Structures (Motifs)
Supersecondary structures are formed when secondary structural elements come together. Some examples of supersecondary structures include:
- Beta-alpha-beta motif: This structure consists of two parallel beta strands connected by an alpha helix.
- Greek key motif: This motif is characterized by a pattern of beta strands that fold back on themselves, resembling a key.
- Beta meander motif: This structure features a series of beta strands that zigzag back and forth.
- Beta barrel: This is a cylindrical structure formed by beta strands that create a barrel-like shape.
DNA-binding motifs are specific examples of supersecondary structures that play a crucial role in binding DNA. These motifs include:
- Helix-Turn-Helix motif: This motif consists of two alpha helices connected by a short turn, allowing it to fit into the DNA groove.
- Leucine zipper motif: This motif features leucine residues at every seventh position, forming a zipper-like structure that helps bind DNA.
- Zinc finger motif: This motif contains zinc ions that stabilize its structure, enabling it to interact with DNA.
Considerations Regarding DNA-binding Motifs
- Leucine Zipper: The Leucine Zipper is a DNA-binding motif characterized by leucine residues located at every seventh position in the protein sequence.
Tertiary Structure
Tertiary structure refers to the complete three-dimensional shape of a polypeptide.
Domains
Domains are distinct regions within a protein that perform specific chemical or physical tasks, such as binding to a substrate.
Rossmann Fold
The Rossmann fold is a specific domain found in a group of enzymes known as oxidoreductases. It is characterized by a shared N-terminal region that binds NAD(P)+.
Examples of oxidoreductases that feature the Rossmann fold include:
- Lactate dehydrogenase
- Alcohol dehydrogenase
- Glyceraldehyde-3-phosphate dehydrogenase
- Malate dehydrogenase
- Quinone oxidoreductase
- 6-phosphogluconate dehydrogenase
- D-glycerate dehydrogenase
- Formate dehydrogenase
Quaternary Structure
The quaternary structure refers to the arrangement of multiple polypeptide subunits that come together to form a single functional protein. This structure is observed when more than one polypeptide chain joins forces to create a working protein.
Bonds in Tertiary and Quaternary Structures
- Hydrophobic Interaction: This type of bond occurs between nonpolar molecules or regions of molecules in an aqueous environment, where they tend to aggregate to avoid water.
- Hydrogen Bond: Hydrogen bonds form between a hydrogen atom covalently bonded to an electronegative atom and another electronegative atom. These bonds play a crucial role in stabilizing the structure of proteins.
- Electrostatic Bond: Electrostatic interactions occur between positively and negatively charged groups within the protein, contributing to its stability.
- Van der Waals Forces: These are weak attractions between molecules or parts of molecules that result from transient local partial charges. Despite being weak individually, they can collectively have a significant impact on protein structure.
Insulin and Quaternary Structure
- Although insulin consists of two polypeptide chains, it exhibits a quaternary structure because these chains are linked together by disulfide bonds.
- In the context of the quaternary structure, the bonds involved are primarily noncovalent, which facilitates the proper arrangement and functionality of the polypeptide subunits.
Structure of Insulin
- The groundbreaking work on the structure of insulin was conducted by Frederick Banting and Charles Best.
- Banting, in collaboration with John Macleod, the director of the research institute, was awarded the Nobel Prize for their significant contributions to this field.
- Frederick Sanger played a crucial role in this research as well.
- He utilized Sanger’s reagent for DNA sequencing, which was instrumental in the study.
- Sanger was also honored with the Nobel Prize for his important contributions to biochemistry.
- The research on insulin's structure was carried out using advanced DNA technology.
Primary Structure of Insulin
- Insulin is made up of a total of 51 amino acids.
- The A chain of insulin consists of 21 amino acids.
- The B chain contains 30 amino acids.
- There are two interchain disulfide bonds in insulin:
- One bond is between the 7th amino acid in the A chain and the 7th amino acid in the B chain.
- The second bond is between the 20th amino acid in the A chain and the 19th amino acid in the B chain.
- Additionally, there is an intrachain disulfide bond within the A chain, connecting the 6th amino acid to the 11th amino acid.
Species Variation in Insulin
- Variations in insulin among different species are limited to the 8th, 9th, and 10th amino acids in the A chain and the C-terminal amino acid of the B chain.
- For example, porcine and human insulin differ only at the terminal amino acid of the B chain.
Denaturation of Proteins
Denaturation involves a nonspecific alteration in the secondary, tertiary, and quaternary structures of protein molecules when they are subjected to denaturing agents.
Denaturing Agents can include:
- Mild heating
- Treating with Urea
- Salicylates
- X-ray radiation
- UV rays
- High pressure
- Vigorous shaking
Two Types of Denaturation
Reversible Denaturation: In some cases, denatured proteins can revert to their original form when the denaturing agents are removed.
Irreversible Denaturation: Some denatured proteins cannot return to their original structure once the denaturing agents are removed. For instance, heated albumin undergoes irreversible denaturation, a process known as Heat Coagulation.
Characteristic Features of Denaturation
- Loss of Biological Activity
- The primary structure, characterized by the peptide bond, remains unchanged.
- Loss of Secondary and Tertiary Structures
- Loss of Folding
- Proteins adopt a Random Coil Structure
Concept: During denaturation, all structural features are lost except for the primary structure, which is defined by the peptide bond. It is essential to understand that while the peptide bond is a robust covalent bond, the overall primary sequence can be affected under specific conditions.
Examination of Protein Structure
Introduction
Proteins are made up of long chains of amino acids, and the way these chains are arranged and folded determines the protein's function. To understand how proteins work, scientists study their structure, which can be divided into four levels: primary, secondary, tertiary, and quaternary. Primary Structure Definition. The primary structure of a protein refers to the unique sequence of amino acids in its polypeptide chain. This sequence is determined by the genetic code and is crucial because it dictates how the protein will fold and function. Importance. The primary structure is fundamental to the protein's identity and function. Even a slight change in the amino acid sequence can lead to a different protein with potentially different functions, which is why this level of structure is so important in biochemistry and molecular biology.
Study of Primary Structure/Sequencing of Proteins
The primary structure of proteins refers to the specific sequence of amino acids in a polypeptide chain. Understanding and determining this sequence is crucial for studying protein function, evolution, and interactions. Several methods are used for protein sequencing, each with its own principles and applications.
Methods of Protein Sequencing
- End group analysis
- Mass spectrometry
- Molecular biology techniques
End Group Analysis
End-group analysis is a method used to determine the amino acid sequence of a polypeptide by examining the end groups of the chain. The end groups provide information about the amino acids present at the ends of the chain, which can help in deducing the sequence. Sanger’s Technique
Sanger's technique, also known as the Sanger sequencing method, is a widely used approach for determining the amino acid sequence of proteins. In this method, Sanger's reagent, which is fluoro-2,4-dinitrobenzene (FDNB), is used to label the amino acids at the N-terminus of the polypeptide chain.
Edman’s Degradation Technique
Edman's degradation technique is a method used to determine the amino acid sequence of a protein by sequentially removing and identifying the amino acids from the N-terminus of the polypeptide chain. In this technique, Edman's reagent, which is phenyl isothiocyanate, is used to label the N-terminal amino acid, which is then cleaved and identified.
Using Carboxypeptidase A and B
Carboxypeptidase A and B are enzymes that can be used in end-group analysis to determine the amino acid sequence of a polypeptide. These enzymes cleave the carboxyl-terminal end of the polypeptide chain, releasing the amino acid at the C-terminus, which can provide information about the sequence.
Sanger's Technique
- Sanger's Reagent is Fluoro-2,4-Dinitrobenzene.
- Sanger's Reagent specifically modifies the amino terminal residues of proteins.
- This method was developed by Frederick Sanger, who received the Nobel Prize in 1958.
- Only dipeptides and tripeptides can be sequenced using this technique.
Edman’s Technique
- This technique uses Edman’s Reagent, which is Phenyl Isothiocyanate.
- Phenyl Isothiocyanate modifies the amino terminal of polypeptides.
- Edman's technique can sequence a significant number of residues (up to 50. of a single polypeptide sample, which is more than Sanger’s method.
Steps for Protein Sequencing
- Protein sequencing involves determining the precise sequence of amino acids in a protein. To achieve this for large peptides, they are first broken down into smaller fragments using specific enzymes and chemicals.
- Trypsin. This enzyme facilitates the cleavage of polypeptides at the carboxyl side of basic amino acids, specifically Lysine (Lys) and Arginine (Arg) residues.
- Chymotrypsin. Chymotrypsin targets the carboxyl group of aromatic amino acids and large nonpolar amino acids. It cleaves at the carboxyl side of residues such as Phenylalanine (Phe), Tryptophan (Trp), Tyrosine (Tyr), Leucine (Leu), and Methionine (Met).
- Cyanogen Bromide (CNBr). CNBr is a chemical reagent that cleaves at the carboxyl side of Methionine (Met) residues in a polypeptide chain.
- Edman’s Sequencing. For short peptides, the sequencing process involves Edman degradation, where the amino terminal residue is sequentially removed and identified. This process is often carried out using automated sequencers for efficiency and accuracy.
Mass Spectrometry
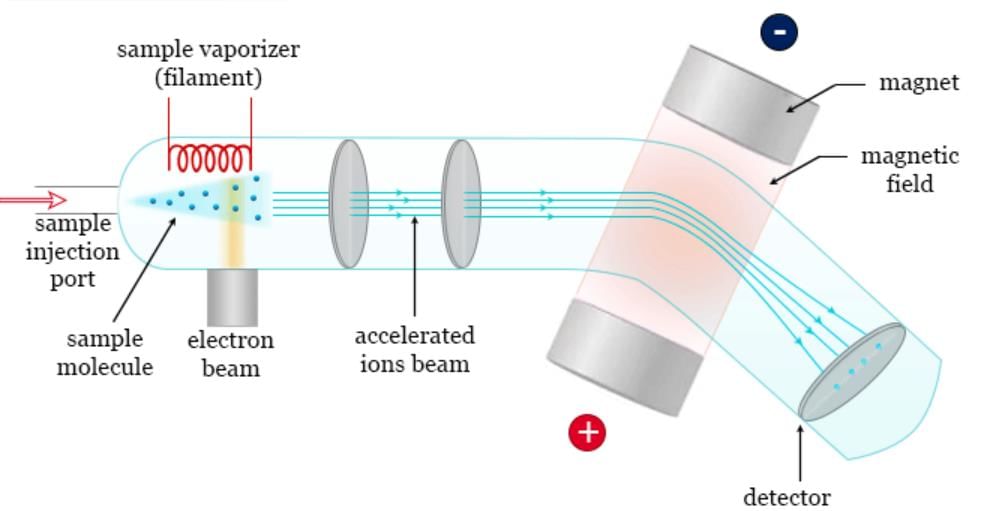 Mass spectrometry
Mass spectrometry
Mass spectrometry has become an essential technique for identifying proteins based on their mass-to-charge ratio.
- Each amino acid has a specific molecular mass, and by analyzing the masses of peptide fragments, researchers can reconstruct the sequence of a peptide, which is crucial for understanding protein structure.
However, there are exceptions in molecular mass that can complicate identification:
- Leucine and isoleucine have similar molecular weights, making it difficult to distinguish between them.
- Glutamine and lysine also pose identification challenges due to their similar masses.
Conversion of Analyte to Vapor Phase
Methods for Dispersion of Analyte into Vapor Phase
- Heating in a Vacuum: This method involves heating the analyte in a vacuum to convert it into the vapor phase. However, it is essential to note that this technique can potentially damage sensitive molecules such as proteins and oligonucleotides due to the application of heat.
- Electrospray Ionization: Electrospray ionization is a technique used to disperse the analyte into the vapor phase by applying a high voltage to a liquid containing the analyte, creating a fine aerosol of charged droplets that evaporate, leaving behind charged analyte ions.
- Matrix-Assisted Laser Desorption and Ionization (MALDI): MALDI is a method that involves mixing the analyte with a matrix material and then using a laser to desorb and ionize the analyte from the matrix, facilitating its transition to the vapor phase.
- Fast Atom Bombardment (FAB): FAB is a technique where a beam of fast-moving atoms is used to bombard the sample, causing it to desorb and ionize, thereby converting it into the vapor phase.
Types of Mass Spectrometers
1. Quadrupole Mass Spectrometers:
- In a basic single quadrupole mass spectrometer, the process begins with placing a sample in a vacuum where it is allowed to vaporize in the presence of a proton donor. This step is crucial as it imparts a positive charge to the ions.
- Once the ions are generated, the current supplied to the electromagnet is gradually increased. This adjustment is vital as it changes the field strength within the quadrupole.
- The key principle here is that for ions with the same net charge, the force required to bend their path is directly proportional to their mass. This means that heavier ions will require more force to bend their path compared to lighter ones.
- Quadrupole mass spectrometers are highly versatile and are commonly used to analyze a wide range of molecular weights. They are particularly effective in detecting molecules with masses exceeding 4000 Da (Daltons).
2. Time of Flight (TOF) Mass Spectrometers:
- In this type of mass spectrometer, the process begins with the vaporization of the sample in the presence of a suitable matrix. Once vaporized, the ions generated from the sample are accelerated towards the detector.
- The acceleration of the ions and the time taken for them to reach the detector are critical factors in this process. The time of flight, which is the duration taken by the ions to travel to the detector, is directly related to their mass. Heavier ions, due to their larger mass, take a longer time to reach the detector compared to lighter ions.
- TOF mass spectrometers are particularly effective in identifying large masses, making them suitable for the analysis of complete proteins with masses greater than 4 kDa (kilodaltons).
3. Tandem Mass Spectrometry (MS-MS):
- Tandem mass spectrometry involves the use of two mass spectrometers connected in series. This setup allows for more detailed analysis and is often referred to as MS-MS.
- The first mass spectrometer (MS1) selects specific ions based on their mass-to-charge ratio (m/z) and fragments them. The fragments are then transferred to the second mass spectrometer (MS2), where they are further analyzed.
- This technique provides enhanced sensitivity and specificity, making it a powerful tool in mass spectrometry.
Benefits of Mass Spectrometers
- Mass spectrometry is highly sensitive, fast, and adaptable, making it the preferred method for determining protein structures.
- It is based on the principles of mass and charge, allowing for the analysis of various biomolecules, including oligonucleotides and carbohydrates.
- The process involves breaking down biomolecules into smaller fragments and measuring their mass-to-charge ratios to identify their composition and structure.
Molecular Biology and Protein Sequencing
- Molecular biology has transformed the way primary structures of proteins are determined.
- By using Edman’s chemistry to sequence a small portion of a protein and then applying data from the genetic code, the remaining sequence can be accurately predicted.
Study of Secondary Structure
- Circular Dichroism
- Optical Rotatory Dispersion
- Chromatography
The study of tertiary structures includes the following methods:
- X-ray Crystallography
- NMR Spectroscopy
- UV Light Spectroscopy (the fastest method)
- Fluorescence Spectroscopy
- Molecular Modeling
Separatory Techniques of Proteins
Protein Separation Techniques
- Salt Fractionation
- Ultracentrifugation
- Electrophoresis
- Chromatography
Salt Fractionation (Salting Out)
Principle
- High salt concentrations generally decrease the solubility of proteins.
- By adding the right amount of salt, some proteins can be made to precipitate while others remain in solution.
- Ammonium sulfate ( (NH4)2SO4. is commonly used for this purpose due to its high solubility in water.
- This method separates proteins based on their mass, density, and shape.
Concept of Electrophoresis
- Samples are typically applied at the cathode end, with negatively charged substances migrating towards the anode.
- Negatively charged particles usually move at a faster rate.
- In a mixture of amino acids, the negatively charged amino acid will travel more quickly.
Classification Based on Supporting Media for Protein Separation
- Agarose Gel Electrophoresis
- Charge-Based Separation
- Cellulose Acetate Electrophoresis
- Utilizes a cellulose acetate membrane for separation due to its selective permeability.
- Polyacrylamide Gel Electrophoresis (PAGE)
- Charge and Molecular Weight (Size) Based Separation
- Sodium Dodecyl Sulfate (SDS)
- SDS and Polyacrylamide
- SDS imparts an equal negative charge, masking the protein's natural charge, allowing separation based solely on size.
- Molecular Weight (Size) Based Separation
- Capillary Electrophoresis
- Separation occurs within a capillary tube.
- Isoelectric Focusing
- Utilizes supporting media with a pH gradient.
- Isoelectric pH Based Separation
Two-Dimensional Electrophoresis
- SDS-PAGE is employed in one direction, while isoelectric focusing is utilized in the perpendicular direction.
- This technique facilitates separation based on molecular weight (size) and isoelectric pH simultaneously.
High-Performance Liquid Chromatography (HPLC)
- HPLC is a flexible method within column chromatography.
- The HPLC process involves high-pressure pumps to expedite the passage of protein molecules through the column, along with the use of superior chromatographic materials.
- By reducing the time proteins spend in the column, HPLC improves separation efficiency and the clarity of protein bands.
- Separation can be based on various properties, including ion exchange and size exclusion.
- This method produces consistent results.
- HPLC, often called high-performance liquid chromatography, is particularly effective for separating hemoglobin fractions.
Densitometry
- Densitometry is a method used to quantify the amount of protein that has been separated.
- It involves measuring the distribution of the analyte (the substance being measured) between the stationary and mobile phases in a chromatographic process.
Concept of Various Chromatographic Techniques
- Thin Layer/Paper Chromatography
- Stationary phase: Water held on support media.
- Mobile phase: A mixture of nonpolar solvents.
- Process: Sample applied on support media; nonpolar solvent rises, separating nonpolar and polar components.
- Size Exclusion Chromatography
- Column: Cross-linked polymer with pores of selected size.
- Process: Larger proteins move faster; smaller proteins are slowed down by entering pores.
- Basis of separation: Molecular weight or size.
- Ion Exchange Chromatography
- Types: Anion Exchange or Cation Exchange.
- Cation Exchange: Uses a solid matrix with negatively charged groups; proteins with a net positive charge move slower.
- Anion Exchange: Opposite process, separating based on charge.
- Phase Used for Separation
- Paper Chromatography. Water on solid support of cellulose based on polarity.
- Thin Layer Chromatography. Silica gel on glass or plastic sheet.
- Ion Exchange Chromatography. Column of ion exchange resins.
- Size Exclusion Chromatography. Also known as molecular sieve chromatography; column of porous beads based on molecular weight.
- Hydrophobic Interaction Chromatography. Based on hydrophobic interaction.
- Absorption Chromatography. Based on absorption property.
- Compare the Different PAGEs
- Proteins are separated based on molecular mass and charge.
- SDS gives a uniform negative charge to proteins, allowing separation based on size.
- At this stage, proteins are separated solely based on molecular weight.
- SDS-PAGE with 2-mercaptoethanol or dithiothreitol separates multimeric proteins.
- Capillary Electrophoresis is the fastest method for protein separation.
- Densitometry is used to quantify the separated protein.
- Thin Layer Chromatography or Paper Chromatography. Hydrophobic amino acids move fastest.
- Electrophoresis: Negatively charged amino acids and proteins move faster.
- Paper and Thin Layer Chromatography: Nonpolar amino acids move faster.
|
50 docs|7 tests
|
FAQs on Proteins - 1 Chapter Notes - Biochemistry - NEET PG
| 1. What is a peptide bond, and why is it important in proteins? |  |
| 2. What are the characteristics of a peptide bond? | |
| 3. What are atypical peptide bonds, such as pseudopeptide and isopeptide bonds? | |
| 4. What are some biologically important peptides, and how are they classified based on shape? | |
| 5. How do the primary and secondary structures of proteins relate to their function? | |


Viva Questions
,Semester Notes
,Free
,Summary
,MCQs
,Proteins - 1 Chapter Notes | Biochemistry - NEET PG
,shortcuts and tricks
,Previous Year Questions with Solutions
,mock tests for examination
,Objective type Questions
,video lectures
,practice quizzes
,study material
,Important questions
,Sample Paper
,past year papers
,Proteins - 1 Chapter Notes | Biochemistry - NEET PG
,Exam
,ppt
,Extra Questions
,Proteins - 1 Chapter Notes | Biochemistry - NEET PG
;


Chapter Notes: Proteins - 1 Free PDF Download
Importance of Chapter Notes: Proteins - 1
Chapter Notes: Proteins - 1
Chapter Notes: Proteins - 1 NEET PG Questions
Study Chapter Notes: Proteins - 1 on the App
|
© EduRev
|
Education Revolution
|



|





