UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 | UGC NET Past Year Papers PDF Download

Q1: Let P be "It is a hot day" and q be "The temperature is 48°C". Write in simple sentences the meaning of ~p Ʌ ~q.
(a) It is a hot day or temperature is 48°C
(b) It is cold day or temperature is 48°C
(c) It is neither a hot day nor temperature is 48°C
(d) It is not a hot day
Ans: C
Sol: The correct answer is It is neither a hot day nor temperature is 48°C
To understand the expression ~p ∧ ~q, we need to analyze it in the context of the propositions:
- p : "It is a hot day."
- q : "The temperature is 48°C."
Interpretation of ~p ∧ ~q:
- ~p: "It is not a hot day."
- ~q: "The temperature is not 48°C."
The expression ~p ∧ ~q means both of these statements are true simultaneously: "It is not a hot day and the temperature is not 48°C."
Simple Sentence:
- This can be translated to: 3) It is neither a hot day nor the temperature is 48°C.
So, the correct answer is: 3) It is neither a hot day nor the temperature is 48°C.
Q2: Arrange the following steps of file handling in C in the correct order:
(A) Close the file
(B) Read from or write to the file
(C) Open the file
(D) Check for error
Choose the correct answer from the options given below:
(a) (A), (C), (D), (B)
(b) (D), (B), (C), (A)
(c) (C), (D), (B), (A)
(d) (B), (D), (A), (C)
Ans: C
Sol: The correct answer is (C), (D), (B), (A).
- Open the file: The first step in file handling is to open the file using the appropriate mode (read, write, etc.). This is done using functions like
fopen()in C. - Check for error: After attempting to open the file, it's crucial to check whether the file was successfully opened. This involves checking if the file pointer is
NULL. - Read from or write to the file: Once the file is successfully opened and error checking is done, you can perform read or write operations using functions like
fread(),fwrite(),fprintf(),fscanf(), etc. - Close the file: Finally, after all the necessary operations are done, the file should be closed using the
fclose()function to free up resources.
Thus the correct answer is (C), (D), (B), (A).
Other Related Points
- File handling is a crucial concept in programming that allows you to store and retrieve data from files. It is widely used for data persistence, configuration management, and logging.
- Proper error handling during file operations is essential to ensure data integrity and to handle exceptional conditions gracefully.
- Closing the file is important to free up system resources and to ensure that data is correctly written to the file, especially in buffered I/O operations.
Q3: Out the following steps in the proper sequence for simplifying a Boolean function using a Karnaugh map (K-map).
(A) Identify and group the largest possible cluster of I's
(B) Draw the K-map for the given Boolean function
(C) Write the simplified Boolean expression from the grouped clusters
(D) Transfer the truth table values to the K-map
Choose the correct answer from the options given below:
(a) (B), (D), (A), (C)
(b) (D), (B), (A), (C)
(c) (B), (A), (D), (C)
(d) (A), (B), (C), (D)
Ans: A
Sol: The correct answer is (B), (D), (A), (C).
- Draw the K-map for the given Boolean function (B): The first step in simplifying a Boolean function using a Karnaugh map (K-map) is to draw the K-map. This involves setting up a grid based on the number of variables in the function.
- Transfer the truth table values to the K-map (D): Next, the truth table values are transferred to the K-map. Each cell in the K-map corresponds to a specific combination of input variables, and the values from the truth table are placed in the appropriate cells.
- Identify and group the largest possible cluster of 1's (A): After transferring the values, the next step is to identify and group the largest possible clusters of 1's in the K-map. These clusters help in simplifying the Boolean expression.
- Write the simplified Boolean expression from the grouped clusters (C): Finally, the simplified Boolean expression is written based on the grouped clusters of 1's. This step involves deriving the simplified terms from the clusters.
Thus the correct answer is (B), (D), (A), (C).
Other Related Points
- Karnaugh map (K-map): A Karnaugh map is a diagram used in Boolean algebra and digital logic design for the simplification of algebraic expressions. The K-map provides a visual method of grouping expressions with common factors and eliminating unwanted variables.
- Simplification Process: The simplification process using a K-map helps in minimizing the number of logical operations required, which in turn reduces the complexity of digital circuits.
- Grouping Clusters: Grouping the largest possible clusters of 1's is crucial as it ensures that the simplest form of the Boolean expression is achieved. Larger clusters lead to fewer terms in the simplified expression.
Q4: Match List - I with List - II.

Choose the correct answer from the options given below:
(a) (A) - (II), (B) - (III), (C) - (IV), (D) - (I)
(b) (A) - (IV), (B) - (II), (C) - (III), (D) - (I)
(c) (A) - (IV), (B) - (I), (C) - (II), (D) - (III)
(d) (A) - (II), (B) - (IV), (C) - (III), (D) - (I)
Ans: C
Sol: The correct answer is A - IV, B - I, C - II, D - III
Half Adder:
- A Half Adder is a combinational logic circuit that performs the addition of two bits. It produces a sum and a carry value as output. Hence, it is a 2-bit addition circuit. So, A matches with IV.
Decoder:
- A Decoder is a combinational circuit that converts binary information from n input lines to a maximum of 2n unique output lines. It is used to decode encoded data. So, B matches with I.
Register:
- A Register is a small amount of storage available as part of a CPU. It is used to store data temporarily while programs are running. So, C matches with II.
Main Memory:
- Main Memory, also known as RAM (Random Access Memory), is used to store the program that is currently being executed and the data that is being processed by the CPU. So, D matches with III.
Therefore, the correct option is A - IV, B - I, C - II, D - III. So, the correct option is 3).
Q5: Find the correct sequence of the storage device in ascending order based on their access time(slowest to fastest).
(A) Registers
(B) Magnetic Disk
(C) Magnetic Tapes
(D) Main memory
(E) Optical Disk
Choose the correct answer from the options given below:
(a) (B), (A), (D), (C), (E)
(b) (B), (A), (E), (D), (C)
(c) (C), (B), (A), (E), (D)
(d) (C), (E), (B), (D), (A)
Ans: D
Sol: Question: Find the correct sequence of the storage devices in ascending order based on their access time (slowest to fastest).
Given Devices:
- (A) Registers
- (B) Magnetic Disk
- (C) Magnetic Tapes
- (D) Main Memory
- (E) Optical Disk
Access Time Comparison (Approximate):
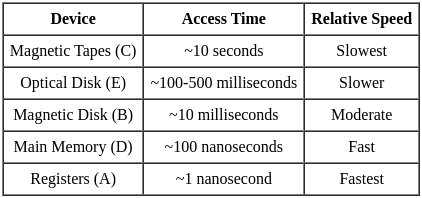
Correct Ascending Order (Slowest to Fastest):
- C - Magnetic Tapes
- E - Optical Disk
- B - Magnetic Disk
- D - Main Memory
- A - Registers
Correct Answer: Option 4) (C), (E), (B), (D), (A)
Q6: Consider the following statement regarding special purpose registers.
(A) Program Counter (PC) keeps track of the next instruction to be executed
(B) Instruction register holds the address of first instruction to be executed
(C) Accumulator holds the output of ALU
(D) Program Counter (PC) keeps the track of only first instruction of the program
Choose the correct answer from the options given below:
(a) (A) and (C) Only
(b) (A) and (D) Only
(c) (B) and (D) Only
(d) (A), (B) and (C) Only
Ans: A
Sol: The correct answer is 1)(A) and (C) Only
(A) Program Counter (PC) keeps the track of next instruction executed. -
- This statement is CORRECT. The Program Counter (PC) is a special-purpose register that holds the address of the next instruction to be executed in the sequence.
(B) Instruction register holds the address of first instruction to be executed. -
- This statement is NOT CORRECT. The Instruction Register (IR) holds the current instruction being executed, not the address of the first instruction.
(C) Accumulator holds the output of ALU. -
- This statement is CORRECT. The Accumulator is a special-purpose register that holds the intermediate results and the final result of arithmetic and logic operations performed by the ALU (Arithmetic Logic Unit).
(D) Program Counter (PC) keeps the track of only first instruction of the program. -
- This statement is NOT CORRECT. The Program Counter (PC) continuously keeps track of the address of the next instruction to be executed, not just the first instruction.
Q7: Match List - I with List - II.
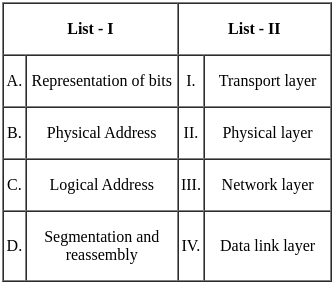
Choose the correct answer from the options given below:
(a) (A) - (I), (B) - (II), (C) - (III), (D) - (IV)
(b) (A) - (II), (B) - (IV), (C) - (III), (D) - (I)
(c) (A) - (III), (B) - (II), (C) - (IV), (D) - (I)
(d) (A) - (I), (B) - (IV), (C) - (III), (D) - (II)
Ans: B
Sol: The correct answer is A - II, B - IV, C - III, D - I
Representation of bits (A):
- This is handled by the Physical layer, which deals with the transmission and reception of raw bit streams over a physical medium. Therefore, A matches with II.
Physical Address (B):
- This refers to the hardware address of the device, which is handled by the Data Link layer. Therefore, B matches with IV.
Logical Address (C):
- This is used for routing packets across networks and is handled by the Network layer. Therefore, C matches with III.
Segmentation and reassembly (D):
- This is a function of the Transport layer, which ensures that data is properly segmented for transmission and reassembled at the destination. Therefore, D matches with I.
Therefore, the correct option is A - II, B - IV, C - III, D - I. So, the correct option is 2).
Q8: Which of the following properties correctly describe a Regular Grammar?
(A) All production rules are of the form A → x B or A → x, where A and B are non terminal symbols and x is a terminal symbol.
(B) Regular grammars are more powerful than context-free grammars and can express any type of language.
(C) There is a direct correspondence between regular grammar and finite automata.
(D) Regular grammars can generate languages that are not recognised by any type of automata.
Choose the correct answer from the options given below:
(a) (A) and (B) Only
(b) (B) and (C) Only
(c) (C) and (D) Only
(d) (A) and (C) Only
Ans: D
Sol: The correct answer is (A) and (C) Only
(A) All production rules are of the form A → xB or A → x, where A and B are non terminal symbols and x is a terminal symbol. -
- This statement is CORRECT. This is the definition of a regular grammar. In regular grammars, production rules are restricted to these forms to ensure that the language generated is regular.
(B) Regular grammars are more powerful than context-free grammars and can express any type of language. -
- This statement is NOT CORRECT. Regular grammars are actually less powerful than context-free grammars. Regular grammars can only describe regular languages, which are a subset of context-free languages.
(C) There is a direct correspondence between regular grammar and finite automata. -
- This statement is CORRECT. For every regular grammar, there exists an equivalent finite automaton and vice versa. This correspondence is a fundamental concept in the theory of computation.
(D) Regular grammars can generate languages that are not recognised by any type of automata. -
- This statement is NOT CORRECT. Regular grammars can only generate regular languages, which are precisely the languages recognized by finite automata.
Q9: Arrange the following steps in proper sequence involved in a Genetic Algorithm:
(A) Selection
(B) Initialization
(C) Crossover
(D) Mutation
(E) Evaluation
Choose the correct answer from the options given below:
(a) (A), (B), (C), (D), (E)
(b) (E), (A), (B), (D), (C)
(c) (B), (E), (A), (C), (D)
(d) (A), (C), (B), (D), (E)
Ans: C
Sol: The correct answer is (B), (E), (A), (C), (D).
- Initialization (B): This is the first step in a Genetic Algorithm where a population of potential solutions is generated. The initial population can be created randomly or based on some heuristic.
- Evaluation (E): Each individual in the population is evaluated to determine its fitness. This fitness function is problem-specific and determines how well an individual solves the problem.
- Selection (A): Based on the fitness scores, individuals are selected for reproduction. Individuals with higher fitness have a higher chance of being selected.
- Crossover (C): In this step, pairs of individuals are combined to produce offspring. This is done to explore new regions of the solution space. Various methods like single-point crossover, multi-point crossover, or uniform crossover can be used.
- Mutation (D): After crossover, the offspring may undergo mutation where some of their genes are altered. This is done to maintain genetic diversity within the population and to avoid local minima.
Thus the correct answer is (B), (E), (A), (C), (D).
Other Related Points
- The Genetic Algorithm is an optimization technique based on the principles of natural selection and genetics. It is used to find approximate solutions to complex problems where traditional methods may be infeasible.
- Genetic Algorithms are widely used in various fields such as machine learning, artificial intelligence, and operations research to solve optimization and search problems.
Q10: Match List I with List - II.
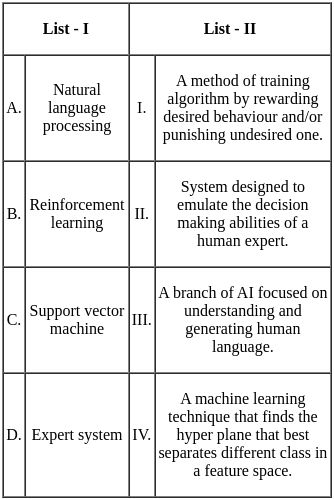
Choose the correct answer from the options given below:
(a) (A) - (I), (B) - (II), (C) - (IV), (D) - (III)
(b) (A) - (III), (B) - (II), (C) - (I), (D) - (IV)
(c) (A) - (III), (B) - (I), (C) - (IV), (D) - (II)
(d) (A) - (II), (B) - (IV), (C) - (III), (D) - (I)
Ans: C
Sol:
Natural language processing (A):
- This is a branch of AI focused on understanding and generating human language. Therefore, A matches with III.
Reinforcement learning (B):
- This is a method of training algorithms by rewarding desired behavior and/or punishing undesired ones. Therefore, B matches with I.
Support vector machine (C):
- This is a machine learning technique that finds the hyperplane that best separates different classes in a feature space. Therefore, C matches with IV.
Expert system (D):
- This is a system designed to emulate the decision-making abilities of a human expert. Therefore, D matches with II.
Therefore, the correct option is A - III, B - I, C - IV, D - II. So, the correct option is 3).
Q11: Arrange the following stages of a Turing Machine (TM) operation in the correct order as they occur during computation.
(A) Writing a symbol on the tape
(B) Moving the tape head left to right
(C) Reading a symbol from the tape
(D) Transitioning to a new state based on the current state and symbol read
(E) Halting and accepting or rejecting the input
Choose the correct answer from the options given below:
(a) (C), (A), (B), (D), (E)
(b) (C), (B), (A), (D), (E)
(c) (C), (D), (A), (B), (E)
(d) (C), (D), (B), (A), (E)
Ans: C
Sol: The correct answer is (C), (D), (A), (B), (E).
- (C) Reading a symbol from the tape: The Turing Machine (TM) starts by reading the current symbol from the tape at the position of the tape head. This is the initial step in the computation process.
- (D) Transitioning to a new state based on the current state and symbol read: Based on the symbol read and the current state, the TM transitions to a new state according to its transition function.
- (A) Writing a symbol on the tape: After transitioning to a new state, the TM writes a new symbol on the tape at the current position of the tape head.
- (B) Moving the tape head left to right: The TM then moves its tape head either to the left or to the right, as specified by the transition function.
- (E) Halting and accepting or rejecting the input: The TM continues this process until it reaches a halting state, which may be an accepting state or a rejecting state.
Thus the correct answer is (C), (D), (A), (B), (E).
Other Related Points
- The Turing Machine is a theoretical computational model that manipulates symbols on a strip of tape according to a set of rules. Despite its simplicity, it is capable of simulating any computer algorithm.
- The TM operates on an infinite tape divided into cells, with each cell containing a symbol from a finite alphabet. The machine has a tape head that can read and write symbols and move left or right.
- The TM's behavior is defined by a set of states and a transition function, which determines the machine's actions based on the current state and the symbol being read.
- The TM is a fundamental concept in the theory of computation and is used to understand the limits of what can be computed.
Q12: Match List - I with List - II. 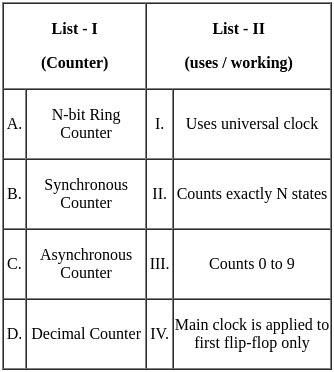
Choose the correct answer from the options given below:
(a) (A) - (II), (B) - (IV), (C) - (I), (D) - (III)
(b) (A) - (IV), (B) - (II), (C) - (III), (D) - (I)
(c) (A) - (II), (B) - (I), (C) - (IV), (D) - (III)
(d) (A) - (IV), (B) - (I), (C) - (II), (D) - (III)
Ans: C
Sol: The correct answer is A - II, B - I, C - IV, D - III
- N-bit Ring Counter:
- This type of counter circulates a single '1' or '0' bit around a ring of N flip-flops. It counts exactly N states. So, A matches with II.
- Synchronous Counter:
- In this counter, all flip-flops are driven by a common clock signal. It uses a universal clock for all flip-flops. So, B matches with I.
- Asynchronous Counter:
- In this counter, the flip-flops do not change states at exactly the same time because they do not share a common clock signal. The main clock is applied to the first flip-flop only. So, C matches with IV.
- Decimal Counter:
- This counter counts from 0 to 9 and then resets to 0. It is also known as a decade counter. So, D matches with III.
Therefore, the correct option is A - II, B - I, C - IV, D - III. So, the correct option is 3).
Q13: Arrange the following stages of parsing in the correct order as they typically occur in the compilation process.
(A) Lexical Analysis
(B) Semantic Analysis
(C) Syntax Analysis
(D) Intermediate Code Generation
(E) Code Optimization
Choose the correct answer from the options given below:
(a) (A), (B), (C), (D), (E)
(b) (A), (C), (B), (D), (E)
(c) (A), (D), (B), (C), (E)
(d) (A), (C), (D), (B), (E)
Ans: B
Sol: The correct answer is 2)(A), (C), (B), (D), (E).
- Lexical Analysis (A): This is the first phase of the parsing process where the source code is converted into tokens. These tokens are the basic building blocks of the syntax structure.
- Syntax Analysis (C): In this stage, the tokens generated by the lexical analyzer are taken and analyzed to form a syntax tree. This phase checks for the correct syntax of the programming language.
- Semantic Analysis (B): This stage checks the semantic consistency of the syntax tree created during syntax analysis. It ensures that the syntax tree follows the rules of the language in terms of meaning.
- Intermediate Code Generation (D): After the semantic analysis, an intermediate code is generated which is a representation of the source code. This intermediate code is easier to optimize and translate into machine code.
- Code Optimization (E): This phase involves optimizing the intermediate code to make the final code more efficient in terms of speed and memory usage.
Thus the correct answer is 2)(A), (C), (B), (D), (E).
Additional Information
- Lexical Analysis: Also known as scanning, this stage is responsible for reading the source code and converting it into a stream of tokens. Each token represents a basic element of the syntax, such as keywords, operators, and identifiers.
- Syntax Analysis: Also known as parsing, this stage takes the stream of tokens and arranges them into a tree structure that represents the grammatical structure of the source code. This structure is known as the parse tree or syntax tree.
- Semantic Analysis: This phase checks for semantic errors and ensures that the syntax tree adheres to the rules of the programming language. It involves type checking, scope resolution, and other checks to ensure the code makes sense.
- Intermediate Code Generation: This stage converts the syntax tree into an intermediate representation, which is often a lower-level code that is easier to optimize and translate into machine code.
- Code Optimization: This final stage involves improving the intermediate code to enhance performance, reduce memory usage, and make the final machine code more efficient.
Q14: How does a relational database ensure data integrity?
(a) By encrypting all data stored
(b) By enforcing rules defined in the schema
(c) By compressing data for efficient storage
(d) By allowing unrestricted access to all users
Ans: B
Sol: The correct answer is By enforcing rules defined in the schema
- Data Integrity: In a relational database, data integrity refers to the accuracy, consistency, and reliability of the data stored.
- Schema Rules: The schema defines the structure of the database, including:
- Data Types: Ensures that only the appropriate data types are stored in each column.
- Constraints:Rules such as primary keys, foreign keys, unique constraints, and check constraints are enforced to maintain data integrity. For example:
- Primary Keys: Ensure that each record is unique.
- Foreign Keys: Maintain referential integrity between tables by ensuring that relationships between tables remain consistent.
- Not Null Constraints: Ensure that certain fields must contain a value.
- By enforcing these rules, a relational database helps prevent invalid data entry and maintains the integrity of the relationships between tables.
Other Related Points
- By encrypting all data stored: Encryption is primarily a security measure, not a direct method for ensuring data integrity.
- By compressing data for efficient storage: Compression is related to storage efficiency, not data integrity.
- By allowing unrestricted access to all users: Unrestricted access would compromise data integrity, as it could lead to unauthorized modifications.
Q15: Which of the following best describes the structure of a relational database?
(a) Data organized into tables with rows and columns
(b) Data organized into files and folders
(c) Data organized into a hierarchical tree structure
(d) Data organized into a network of interconnected nodes
Ans: A
Sol: The correct answer is Data organized into tables with rows and columns
- In a relational database, data is structured in tables (also called relations). Each table consists of rows (also known as records or tuples) and columns (also known as fields or attributes).
- Rows: Each row in a table represents a single record or instance of data.
- Columns: Each column represents a specific attribute or property of the data, with all values in a column being of the same data type.
- This tabular format allows for easy data retrieval and manipulation using SQL.
Other Related Points
- Data organized into files and folders: This describes a file system, not a relational database.
- Data organized into a hierarchical tree structure: This describes hierarchical databases, which organize data in a tree-like structure.
- Data organized into a network of interconnected nodes: This describes network databases, where data is organized in a graph structure.
Q16:
#include <iostream>
using namespace std;
void swap(int &x, int &y) {
int temp = x;
x = y;
y = temp;
}
int main() {
int a = 5, b = 10;
swap(a, b);
swap(a, b);
cout << a << " " << b;
return 0;
}
What will be the output of above code?
(a) 5, 10
(b) 10, 5
(c) 5, 5
(d) 10, 10
Ans: A
Sol: Correct answer is 5, 10
Concept:
Pass by Reference:
In C++, when we pass variables by reference to a function, any modifications made to the parameters affect the original variables. This is useful for functions like swap, where we need to exchange the values of two variables.
Let's analyze the provided code step by step: #include using namespace std; void swap(int &x, int &y) { int temp = x; x = y; y = temp; } int main() { int a = 5, b = 10; swap(a, b); // First swap: a becomes 10, b becomes 5 swap(a, b); // Second swap: a becomes 5, b becomes 10 cout << a << " " << b; // Output the values of a and b return 0; }
Breakdown of the code:
1. Initially, `a` is 5 and `b` is 10.
2. The first `swap(a, b)` is called:
- `x` becomes 10 (value of `b`)
- `y` becomes 5 (value of `a`)
- After the first swap, `a` becomes 10 and `b` becomes 5.
3. The second `swap(a, b)` is called:
- `x` now is 10 (the new value of `a`)
- `y` now is 5 (the new value of `b`)
- After the second swap, `a` becomes 5 and `b` becomes 10 again.
4. Finally, the output will be:
- `cout << a << " " << b;` outputs 5 10.
Therefore, the output of the program will be: 1) 5, 10.
Q17: Which of the following are context free language?
(A) {wi xj yk zl| i + k = j + l, where i, j, k, l ≥ 0}
(B) {wi xj yk zl| i = j and k = l, where i, j, k, l ≥ 0}
(C) {wi xj yk zl| i = j = k and k ≠ l, where i, j, k, l ≥ 0}
(D) {wi xj yk zl| i = j = k + l, where i, j, k, l ≥ 0}
(E) {wi xj yk zl| i = j = l and k ≠ l, where i, j, k, l ≥ 0}
Choose the correct answer from the options given below:
(a) (A), (B) Only
(b) (B), (C) Only
(c) (C), (D) Only
(d) (D), (E) Only
Ans: A
Sol: The correct answer is (A), (B) Only
(A) {wi xj yk zl| i + k = j + l, where i, j, k, l ≥ 0} -
- This language is context-free. It can be generated by a context-free grammar. For instance, we can create a grammar that generates strings where the number of 'w's plus the number of 'y's equals the number of 'x's plus the number of 'z's.
(B) {wi xj yk zl| i = j and k = l, where i, j, k, l ≥ 0} -
- This language is context-free. We can create a context-free grammar where 'w' and 'x' are generated together and 'y' and 'z' are generated together, ensuring i = j and k = l.
(C) {wi xj yk zl| i = j = k and k ≠ l, where i, j, k, l ≥ 0} -
- This language is not context-free. The constraint i = j = k imposes a condition that requires counting and comparing three separate counts, which cannot be achieved by a context-free grammar.
(D){wi xj yk zl| i = j = k + l, where i, j, k, l ≥ 0} -
- This language is not context-free. The condition i = j = k + l requires a more complex relationship that cannot be captured by a context-free grammar.
(E) {wi xj yk zl| i = j = l and k ≠ l, where i, j, k, l ≥ 0} -
- This language is not context-free. Similar to the reason for (C), the conditions i = j = l and k ≠ l are too complex for a context-free grammar to generate.
Q18: What is the output of code given below:
#include<iostream>
using namespace std;
class Base {
public:
Base() {
cout << "Base Const";
}
virtual ~Base() {
cout << "Base dest";
}
};
class Derived : public Base {
public:
Derived() {
cout << "Derived Const";
}
~Derived() {
cout << "Derived dest";
}
};
int main() {
Base *b = new Derived();
delete b;
return 0;
}
(a) Base Const Derived Const Derived dest Base dest
(b) Base Const Derived Const Base dest Derived dest
(c) Derived Const Base Const Base dest Derived dest
(d) Base Const Derived Const Base dest
Ans: A
Sol: The correct answer is Base Const Derived Const Derived dest Base dest
Concept:
Virtual Destructor:
In C++, if a base class has a virtual destructor, the derived class destructors are also called when an object is deleted through a base class pointer. This ensures that the derived class resources are properly released. If the destructor is not virtual, only the base class destructor will be called, leading to resource leaks.
Let's analyze the provided code step by step to determine the output: #include using namespace std; class Base { public: Base() { cout << "Base Const"; } virtual ~Base() { cout << "Base dest"; } }; class Derived : public Base { // Note: The class declaration should be corrected here. public: Derived() { cout << "Derived Const"; } ~Derived() { cout << "Derived dest"; } }; int main() { Base *b = new Derived(); // Corrected from 'Base 'b=new Derived();' to 'Base *b = new Derived();' delete b; // This calls the destructor return 0; }
Breakdown of the code:
1. Object Creation:
- When `new Derived()` is called:
- The constructor of `Base` is executed first because `Derived` inherits from `Base`. So, it outputs:
Base Const - Then, the constructor of `Derived` is executed, which outputs:
Derived Const
2. Deletion:
- When `delete b;` is called, it triggers the destructor process:
- The destructor of `Derived` is called first due to the virtual destructor in the Base class, which outputs:
Derived dest - After that, the destructor of `Base` is called, which outputs:
Base dest
Final Output Sequence:
Combining the outputs:
- Base Const
- Derived Const
- Derived dest
- Base dest
Thus, the complete output of the code will be: Base ConstDerived ConstDerived destBase dest
Therefore, the correct answer is: 1) Base Const Derived Const Derived dest Base dest
(However, note that in the output there would be no spaces unless added explicitly in the `cout` statements.)
Q19: Consider the transactions T1, T2, T3 and the schedules S1 and S2 given below.
T1 : r1(x); r1(z); w1(z)
T2 : r2(y); r2(z); w2(z)
T3 : r3(y); r3(x); w3(y)
S1 : r1(x); r3(y); r3(x); r2(y); r2(z); w3(y); w3(z); r1(z); w1(x); w1(z)
S2 : r1(x); r3(y); r2(y); r3(x); r1(Z); r2(z); w3(y); w1(x); w2(z); w1(z)
Which one of the following statements about the schedules is TRUE ?
(a) Only S1 is conflict-serializable
(b) Only S2 is conflict-serializable
(c) Both S1 and S2 are conflict-serializable
(d) Neither S1 nor S2 is conflict-serializable
Ans: A
Sol: The correct answer is Only S1 is conflict-serializable
Concept:
- Using precedence graph method, we can find out Schedule is conflict serializable or not.
- If precedence graph has any loop then that schedule is going to be not conflict-serializable.
- If precedence graph doesn’t have any loop then that schedule is going to be conflict-serializable.
Schedule S1:
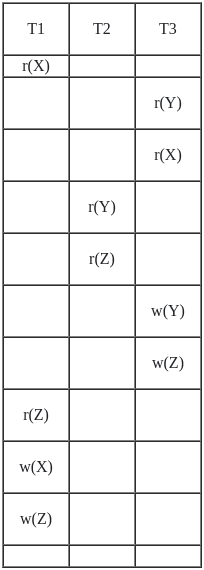
Precedence graph of S1:
Since there is no loop in S1, it is is conflict serializable
Order: T2 → T1 → T2
Schedule S2:
r1(X); r3(Y); r2(Y); r3(X); r1(Z); r2(Z); w3(Y); w1(X); w2(Z); w1(Z)
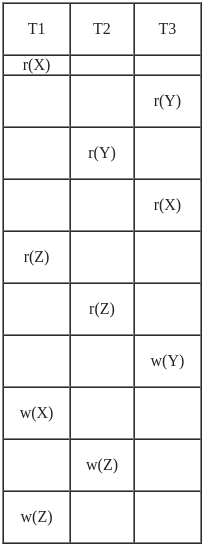
Precedence graph of S2:
- So there is loop in S2 so S2 is not conflict serializable.
- Schedule S1 is equivalent to only this serial schedule T2 : T3 : T1.
Hence option 1 is the correct answer.
Q20: Consider the following code:
#include < stdio.h >
void f1(char *x, char *y) {
char *t1;
t1 = x;
x = y;
y = t1;
}
void f2(char *x, char *y) {
char *t1;
t1 = *x;
*x = *y;
*y = t1;
}
int main() {
char *a = "ONE", *b = "TWO";
f1(a, b);
printf("%s %s", a, b); // First output
f2(&a, &b);
printf("%s %s", a, b); // Second output
return 0;
}
What will be the output of the above code?
(a) ONE TWO TWO ONE
(b) TWO ONE ONE TWO
(c) ONE TWO ONE TWO
(d) TWO ONE TWO ONE
Ans: A
Sol: Concept:
Understanding Pointers and Function Calls in C:
In C programming, pointers are variables that store the memory address of another variable. When passing pointers to functions, it's essential to understand how the changes inside the function affect the original variables. We will discuss two types of functions:
- Pass by Value: The function receives a copy of the argument value, and changes inside the function do not affect the original variable.
- Pass by Reference: The function receives the address of the argument, and changes inside the function affect the original variable.
Let's analyze the provided code step by step to determine its output: #include void f1(char *x, char *y) { char *t1; t1 = x; x = y; y = t1; } void f2(char *x, char *y) { char *t1; t1 = *x; *x = *y; *y = t1; } int main() { char *a = "ONE", *b = "TWO"; f1(a, b); printf("%s %s", a, b); // First output f2(&a, &b); printf("%s %s", a, b); // Second output return 0; }
Breakdown of the code:
1. Initialization:
- `char *a = "ONE", *b = "TWO";` initializes `a` to point to the string "ONE" and `b` to point to "TWO".
2. Function `f1`:
- `f1(a, b);` is called with `a` and `b` passed by value (the pointers themselves are copied).
- Inside `f1`, the local variables `x` and `y` are set to point to the values of `a` and `b`. The swapping occurs, but it only affects the local copies of the pointers.
- Therefore, the values of `a` and `b` in `main` remain unchanged.
- The first `printf("%s %s", a, b);` outputs: ONE TWO
3. Function `f2`:
- `f2(&a, &b);` passes the addresses of the pointers `a` and `b`. Inside `f2`, the parameters `x` and `y` are treated as pointers to pointers.
- The line `t1 = *x;` assigns `t1` to the string "ONE" (the value of `*x` which is `a`).
- The line `*x = *y;` sets `*x` (which is `a`) to point to "TWO" (the value of `*y` which is `b`).
- The line `*y = t1;` sets `*y` (which is `b`) to point to "ONE" (the value stored in `t1`).
- As a result, after this function call, `a` now points to "TWO" and `b` points to "ONE".
4. Second Output:
- The second `printf("%s %s", a, b);` now outputs: TWO ONE
Final Output:
Combining the results:
- After the first `printf`: ONE TWO
- After the second `printf`: TWO ONE
Therefore, the final output of the code will be:
ONE TWO
TWO ONE
Since this matches option 1) ONE TWO TWO ONE, the correct answer is 1) ONE TWO TWO ONE.
Q21: Which of the following statements about pointers in C are TRUE.
(A) Pointers can be used to access array elements
(B) Pointers can store the address of another pointer
(C) Pointers are automatically deferenced in expression
(D) Pointers cannot be used to access structure members
Choose the correct answer from the options given below:
(a) (A) and (C) Only
(b) (A) and (B) Only
(c) (B) and (C) Only
(d) (C) and (D) Only
Ans: B
Sol: The correct answer is 2)(A) and (B) Only
- (A) Pointers can be used to access array elements. -
- This statement is CORRECT. In C, pointers can be used to navigate and access elements of an array. For example, if you have an array `int arr[] = {1, 2, 3};`, a pointer `int *ptr = arr;` can be used to access the elements like `*(ptr + 1)` for the second element.
- (B) Pointers can store the address of another pointer. -
- This statement is CORRECT. Pointers in C can hold the address of another pointer, which is known as pointer-to-pointer. For example, `int *ptr1; int **ptr2 = &ptr1` where `ptr2` is a pointer to `ptr1`.
- (C) Pointers are automatically dereferenced in expression. -
- This statement is NOT CORRECT. In C, pointers are not automatically dereferenced. You must explicitly use the dereference operator `*` to access the value stored at the address contained in the pointer.
- (D) Pointers cannot be used to access structure members. -
- This statement is NOT CORRECT. Pointers can indeed be used to access members of a structure. This is done using the arrow operator `->`. For example, if you have a structure `struct Example { int x; };` and a pointer to this structure `struct Example *ptr;`, you can access `x` using `ptr->x`.
Q22: Which of the following are Agile Process Models?
(A) Extreme Programming (XP)
(B) Waterfall
(C) Scrum
(D) Spiral
(E) Incremental
Choose the correct answer from the options given below :
(a) (A) and (C) Only
(b) (B) and (C) Only
(c) (A) and (D) Only
(d) (B) and (E) Only
Ans: A
Sol: The correct answer is 1)(A) and (C) Only
- (A) Extreme Programming (XP) -
- This statement is CORRECT. Extreme Programming (XP) is an Agile process model that emphasizes customer satisfaction and promotes continuous feedback and improvement.
- (B) Waterfall -
- This statement is NOT CORRECT. The Waterfall model is a traditional, linear sequential software development process and does not fall under Agile methodologies.
- (C) Scrum -
- This statement is CORRECT. Scrum is an Agile process framework used for managing complex product development and emphasizes iterative progress through sprints.
- (D) Spiral -
- This statement is NOT CORRECT. The Spiral model is a risk-driven software development process model which combines elements of both design and prototyping in stages, and is not specifically an Agile process.
- (E) Incremental -
- This statement is NOT CORRECT. While the Incremental model shares some characteristics with Agile methodologies, it is not specifically categorized as an Agile process model.
Q23: Which of the following statements are TRUE about Mutual exclusion in concurrent programming?
(A) Mutual exclusion ensures that only one process can be in a critical section at any given time.
(B) Mutual exclusion are designed to prevent conflicts and ensure that only one process can access shared resources at a time.
(C) Mutual exclusion can use various algorithms to ensure that processes do not enter the critical section simultaneously.
(D) Mutual exclusion allows multiple processes to access the critical section simultaneously to improve performance.
Choose the correct answer from the options given below:
(a) (A), (B), (C) Only
(b) (B), (C), (D) Only
(c) (B), (D), (A) Only
(d) (A), (C), (D) Only
Ans: A
Sol: The correct answer is (A), (B), (C) Only
- (A) Mutual exclusion ensures that only one process can be in a critical section at any given time. -
- This statement is CORRECT. Mutual exclusion is a fundamental concept in concurrent programming aimed at preventing multiple processes from accessing a critical section simultaneously.
- (B) Mutual exclusion are designed to prevent conflicts and ensure that only one process can access shared resources at a time. -
- This statement is CORRECT. The primary goal of mutual exclusion is to avoid conflicts by ensuring exclusive access to shared resources.
- (C) Mutual exclusion can use various algorithms to ensure that processes do not enter the critical section simultaneously. -
- This statement is CORRECT. Algorithms such as Peterson's algorithm, the Bakery algorithm, and various lock mechanisms are used to implement mutual exclusion.
- (D) Mutual exclusion allows multiple processes to access the critical section simultaneously to improve performance. -
- This statement is NOT CORRECT. The purpose of mutual exclusion is to prevent multiple processes from accessing the critical section simultaneously, which is contrary to what this statement suggests.
Q24: Match List - I with List - II.
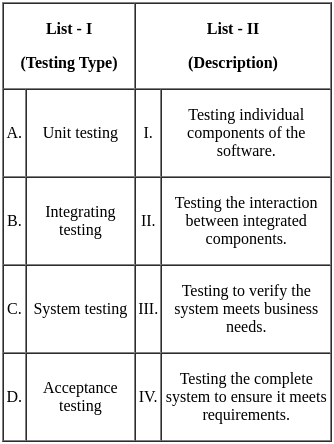
Choose the correct answer from the options given below:
(a) (A) - (I), (B) - (II), (C) - (III), (D) - (IV)
(b) (A) - (I), (B) - (II), (C) - (IV), (D) - (III)
(c) (A) - (I), (B) - (III), (C) - (II), (D) - (IV)
(d) (A) - (I), (B) - (IV), (C) - (II), (D) - (III)
Ans: B
Sol: The correct answer is A - I, B - II, C - IV, D - III
Unit testing:
- Unit testing involves testing individual components or units of a software to ensure they work correctly. So, A matches with I.
Integration testing:
- Integration testing involves testing the interaction between integrated components to ensure they work together as expected. So, B matches with II.
System testing:
- System testing involves testing the complete system to ensure it meets the specified requirements. So, C matches with IV.
Acceptance testing:
- Acceptance testing involves testing to verify if the system meets business needs and requirements. So, D matches with III.
Therefore, the correct option is A - I, B - II, C - IV, D - III. So, the correct option is 2).
Q25: Given a project with an estimated effort of 1500 person-hours and a team of 5 people, how many days will it take to complete the project, if each person works 8 hours a day?
(a) 30
(b) 37.5
(c) 40
(d) 45.5
Ans: B
Sol: Solution:
To calculate how many days it will take to complete the project, we can use the following steps:
Step 1: Calculate the total number of hours the team can work per day:
- There are 5 people on the team.
- Each person works 8 hours a day.
So, the total number of hours worked per day by the team is:
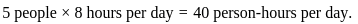
Step 2: Calculate the number of days required:
- The total effort is 1500 person-hours.
To find the number of days required, divide the total effort by the number of person-hours worked per day:
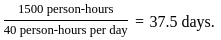
Answer: The project will take 37.5 days to complete.
So, the correct answer is: 2) 37.5.
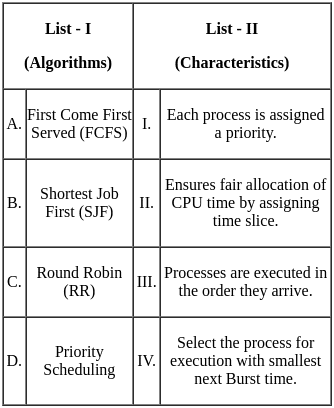
Q26: Match List - I with List - II.
Choose the correct answer from the options given below:
(a) (A) - (II), (B) - (III), (C) - (IV), (D) - (I)
(b) (A) - (II), (B) - (IV), (C) - (III), (D) - (I)
(c) (A) - (III), (B) - (IV), (C) - (II), (D) - (I)
(d) (A) - (III), (B) - (IV), (C) - (I), (D) - (II)
Ans: C
Sol: The correct answer is A - III, B - IV, C - II, D - I
A. First Come First Served (FCFS) - III:
- Processes are executed in the order they arrive. This is a simple scheduling algorithm where the first process to arrive is the first to be executed.
B. Shortest Job First (SJF) - IV:
- Selects the process for execution with the smallest next burst time. This algorithm aims to minimize the average waiting time.
C. Round Robin (RR) - II:
- Ensures fair allocation of CPU time by assigning a time slice. Each process is given a fixed time to execute, and then the next process is executed.
D. Priority Scheduling - I:
- Each process is assigned a priority. The process with the highest priority is executed first.
Therefore, the correct option is A - III, B - IV, C - II, D - I. So, the correct option is 3).
Q27: Host A (on TCP / IPv4 Networks) send an IP Datagram D to host B (also on TCP / IPv4 network). Assume that no error occured during transmission of D, when D reaches B. Which of following header field may differ from that of original datagram D?
(A) TTL
(B) Checksum
(C) Fragment offset
(D) Source IP
(E) Destination IP
Choose the correct answer from the options given below:
(a) (A) and (B) Only
(b) (A), (B) and (C) Only
(c) (A), (B), (C) and (D) Only
(d) (A), (B), (C) and (E) Only
Ans: B
Sol: The correct answer is (A), (B) and (C) Only
When an IP datagram is transmitted from Host A to Host B, some fields in the IP header may change, while others remain the same. Here's the breakdown of each field mentioned:
(A) TTL (Time-to-Live):
- The TTL field is decremented by each router the datagram passes through. This ensures that packets don't loop indefinitely in the network. Therefore, the TTL will differ when the packet reaches Host B.
(B) Checksum:
- The IP header checksum will change as the packet travels through the network, especially when the TTL field is decremented. Since TTL changes, the checksum needs to be recalculated by each router to account for this change. Hence, the checksum will be different.
(C) Fragment Offset:
- If the datagram was fragmented during transmission, the Fragment Offset field may change. This field is used to indicate where a particular fragment belongs in the original datagram. If no fragmentation occurred, this field remains unchanged, but if fragmentation occurs, it will differ.
(D) Source IP:
- The Source IP address remains unchanged throughout the journey of the datagram because it identifies the sender of the packet. It will not change during transmission.
(E) Destination IP:
- Similarly, the Destination IP address also remains unchanged because it specifies the intended recipient of the packet. It will not change during transmission.
Thus, the correct answer is Option 2: (A), (B), and (C) Only.
Q28: Arrange the following steps in the correct order to solve the Knapsack problem using Dynamic Programming.
(A) Define the base case when the capacity is zero (0) or no items are left to consider
(B) Compute the maximum value that can be obtained using items up to the i-th item and a knapsack capacity of 0
(C) Identify subproblems and their dependencies based on items weights and values
(D) Initialize a table to store results of subproblems
(E) Iterate through each item and each possible Capacity to fill the table
Choose the correct answer from the options given below:
(a) (C), (D), (A), (E), (B)
(b) (D), (C), (A), (E), (B)
(c) (A), (C), (D), (E), (B)
(d) (D), (A), (C), (E), (B)
Ans: C
Sol: The correct answer is 3)(A), (C), (D), (E), (B).
- Define the base case when the capacity is zero (0) or no items are left to consider: This step ensures that we have a stopping condition for our recursive algorithm. If the knapsack's capacity is zero or there are no items left to consider, the maximum value is zero.
- Identify subproblems and their dependencies based on items weights and values: This involves breaking down the main problem into smaller subproblems that can be solved independently. The dependencies will be based on the weights and values of the items.
- Initialize a table to store results of subproblems: A table (usually a 2D array) is initialized to store the results of these subproblems. This helps in avoiding the recomputation of the same subproblems and thus improves efficiency.
- Iterate through each item and each possible Capacity to fill the table: This step involves populating the table based on the subproblems identified. For each item and each possible capacity, we decide whether to include the item in the knapsack or not.
- Compute the maximum value that can be obtained using items up to the i-th item and a knapsack capacity of 0: Finally, compute the maximum value from the filled table. This gives the solution to the original problem.
Thus the correct answer is (A), (C), (D), (E), (B).
Other Related Points
- The Knapsack problem is a classic example of a combinatorial optimization problem, and dynamic programming provides an efficient way to solve it.
- Understanding the structure of the problem and the dependencies between subproblems is crucial for correctly implementing the dynamic programming solution.
- The complexity of the dynamic programming approach is generally O(nW), where n is the number of items and W is the capacity of the knapsack. This is much more efficient than the exponential time complexity of the naive recursive solution.
Q29: Consider the three way hand shaking process followed during TCP connection establishment between two hosts A and B. Let S and R be two random 32 - bit starting sequence numbers chosen by A and B, respectively. Suppose A sends a TCP segment having SYN bit = 1, SEQ number = S and ACK bit=0 and B accepts the connection request.
Which one of the following choices represents the information present in the TCP segment header that is sent by B to A?
(a) SYN bit = 1, SEQ number = S + 1, ACK bit = 0, ACK number = R, FIN bit = 0
(b) SYN bit = 0, SEQ number = R, ACK bit = 1, ACK number = S + 1, FIN bit = 0
(c) SYN bit = 1, SEQ number = R, ACK bit = 1, ACK number = S + 1, FIN bit = 0
(d) SYN bit = 1, SEQ number = R, ACK bit = 1, ACK number = S, FIN bit = 0
Ans: C
Sol: The correct answer is SYN bit = 1, SEQ number = R, ACK bit = 1, ACK number = S + 1, FIN bit = 0
Concept:
- In TCP, for Connection Establishment 3way handshake protocol is used.
- FIN bit : FIN bit is set while terminating the connection.
- Syn bit : Syn bit is used for initiating the request for connection establishment.
- Ack bit : Ack bit is used for indicating that the segment contains the acknowledgment.
- Sequence Number : In TCP , Sequence number used for counting each byte transferred in a particular connection and in each Segment Header, Sequence number field contains the Sequence number of first byte of data part of the Segment.
- Ack Number: In TCP , Ack number indicates the Sequence number of Byte expected next.
Given:
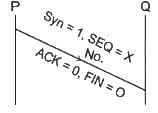
Next segment will be a piggybacked Acknowledgement segment So Ack bit = 1 and Q will increment the Sequence number ( which it received from P) put this into Ack Number field. Syn = 1 as Q will also establish the connection from Q to P and Sequence number will be Y(As given in Question).
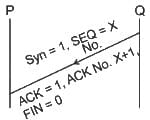
So , SYN bit = 1 SEQ Number = Y ACK bit = 1 ACK number = X+1 FIN bit = 0. Matches with Option 3.
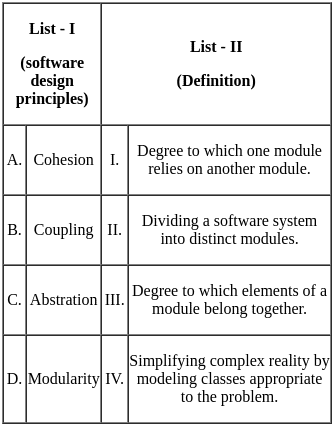
Q30: Match List - I with List - II.
Choose the correct answer from the options given below:
(a) (A) - (I), (B) - (II), (C) - (III), (D) - (IV)
(b) (A) - (II), (B) - (III), (C) - (IV), (D) - (I)
(c) (A) - (III), (B) - (I), (C) - (IV), (D) - (II)
(d) (A) - (III), (B) - (IV), (C) - (II), (D) - (I)
Ans: C
Sol: The correct answer is A - III, B - I, C - IV, D - II
Cohesion (A):
- Cohesion refers to the degree to which elements of a module belong together. High cohesion within a module ensures that the module is focused, robust, and easier to maintain. So, A matches with III.
Coupling (B):
- Coupling refers to the degree to which one module relies on another module. Lower coupling is desirable as it indicates that modules can function independently. So, B matches with I.
Abstraction (C):
- Abstraction involves simplifying complex reality by modeling classes appropriate to the problem. It helps in reducing complexity by hiding unnecessary details. So, C matches with IV.
Modularity (D):
- Modularity is the process of dividing a software system into distinct modules that can be developed and tested independently. It helps in managing complexity and enhancing reusability. So, D matches with II.
Therefore, the correct option is A - III, B - I, C - IV, D - II. So, the correct option is 3).
Q31: Consider following C program:
#include < stdio.h >
int main()
{
int x[] = {2, 4, 6, 8, 10};
int a, b = 0, *y = x + 4;
for(a = 0; a < 5; a++)
{
b = b + (*y - a) - *(y - a);
}
printf("%d\n", b);
return 0;
}
What will be the output of the above C program?
(a) 4
(b) 6
(c) 8
(d) 10
Ans: A
Sol: The correct answer is 10
Concept:
In C programming, the comma operator (`,`) is used to separate two or more expressions that are included where only one expression is expected. The comma operator evaluates each of its operands (from left to right) and returns the value of the last operand.
In the code `int x[] = {2, 4, 6, 8, 10};`, the values inside curly brackets are evaluated and the last value `10` is assigned to the first element of the array `x`.
-
Given the corrected code:
#include < stdio.h > int main() { int x[] = {2, 4, 6, 8, 10}; int a, b = 0, *y = x + 4; for(a = 0; a < 5; a++) { b = b + (*y - a) - *(y - a); } printf("%d\n", b); return 0; }
int x[] = {2, 4, 6, 8, 10};initializes the arrayx.int a, b = 0, y = x + 4;initializesa,bto 0, andyto point to the address of the 5th element of arrayx(i.e.,x[4]which is 10).
The for loop runs from a = 0 to a < 5:
- In each iteration,
*yis10(value atx[4]). y - apoints to different elements ofxasavaries from 0 to 4.
The expression b + (*y - a) - *(y - a) simplifies to 0 for every iteration:
- When a = 0: 0 + (*y - a) - *(y - a) becomes 0 + 10 - 0 - x[4] = 0 + 10 - 10 = 0
When a = 1: 0 + (*y - a) - *(y - a) becomes 0 + 10 - 1 - x[3] = 0 + 9 - 8 = 1
When a = 2: 1 + (*y - a) - *(y - a) becomes 1 + 10 - 2 - x[2] = 1 + 8 - 6 = 3
When a = 3: 3 + (*y - a) - *(y - a) becomes 3 + 10 - 3 - x[1] = 3 + 7 - 4 = 6
When a = 4: 6 + (*y - a) - *(y - a) becomes 6 + 10 - 4 - x[0] = 6 + 6 - 2 = 10
Final Output: After the loop, the final value of b is printed10
Hence the correct answer is: 10
Q32: Which of the following statements are TRUE about Privileged Instructions ?
(A) It can only be executed by the Operating System kernel and not by user applications.
(B) It is designed to perform operations that can directly affect the hardware or system state such as I/O operations or changing memory management settings.
(C) User applications can execute privileged instructions if they have to the correct permissions, set by the Operating System.
(D) It is usually executed in user mode to ensure the safety and security of the system.
Choose the correct answer from the options given below:
(a) (A) and (B) Only
(b) (A), (B) and (C) Only
(c) (B) and (C) Only
(d) (B), (C) and (D) Only
Ans: A
Sol: The correct answer is 1)(A) and (B) Only
(A) It can only be executed by the Operating System kernel and not by user applications. -
- This statement is CORRECT. Privileged instructions are designed to be executed only by the Operating System kernel to prevent unauthorized access to critical system resources and ensure system stability and security.
(B) It is designed to perform operations that can directly affect the hardware or system state such as I/O operations or changing memory management setting. -
- This statement is CORRECT. Privileged instructions typically involve operations that can change the state of the hardware or system settings, which is why they require higher-level permissions to execute.
(C) User applications can execute privileged instructions if they have the correct permissions, set by the Operating System. -
- This statement is NOT CORRECT. User applications generally cannot execute privileged instructions directly, regardless of permissions set by the Operating System. This restriction is in place to protect the system from potentially malicious or erroneous code.
(D) It usually executed in user mode to ensure the safety and security of the system. -
- This statement is NOT CORRECT. Privileged instructions are usually executed in kernel mode, not user mode. Executing them in kernel mode ensures that only trusted code (the OS kernel) can perform critical operations, thus maintaining system safety and security.
Q33: Which of the following are typical activities in the software process lifecycle ?
(A) Requirement Analysis
(B) System Design
(C) Code Refactoring
(D) Deployment
(E) Substructure
Choose the correct answer from the options given below :
(a) (A), (B), (C) Only
(b) (B), (C), (D) Only
(c) (A), (B), (D) Only
(d) (A), (D), (E) Only
Ans: C
Sol: The correct answer is (A), (B), (D) Only
(A) Requirement Analysis -
- This is a typical activity in the software process lifecycle. It involves gathering and analyzing the requirements from the stakeholders to understand what the software should achieve.
(B) System Design -
- This is also a typical activity in the software process lifecycle. It involves creating the architecture of the system, including the high-level design and the detailed design of the software components.
(C) Code Refactoring -
- While code refactoring is an important part of maintaining and improving the software, it is not considered a primary activity in the initial stages of the software process lifecycle. It typically occurs during the maintenance phase.
(D) Deployment -
- This is a typical activity in the software process lifecycle. It involves releasing the software to the users or clients and making it operational in its intended environment.
(E) Substructure -
- This is not a recognized activity in the software process lifecycle. It does not correspond to any standard phase or task in the lifecycle.
Q34: Match List - I with List - II.

Choose the correct answer from the options given below:
(a) (A) - (III), (B) - (IV), (C) - (I), (D) - (II)
(b) (A) - (III), (B) - (IV), (C) - (II), (D) - (I)
(c) (A) - (IV), (B) - (III), (C) - (II), (D) - (I)
(d) (A) - (IV), (B) - (III), (C) - (I), (D) - (II)
Ans: D
Sol: The correct answer is A - IV, B - III, C - I, D - II
Solution Statement
A. A bag contains 6 white and 4 red balls. Two balls are drawn at random. What is the chance, they will be the same colour?
- Total number of ways to draw 2 balls out of 10 balls = C(10, 2) = 45.
- Number of ways to draw 2 white balls = C(6, 2) = 15.
- Number of ways to draw 2 red balls = C(4, 2) = 6.
- Probability of drawing 2 balls of the same color = (15 + 6) / 45 = 21 / 45 = 7 / 15.
- So, A matches with IV.
B. In a pack of 52 cards, one card is drawn at random, what is the probability that it is either a king or a queen?
- There are 4 kings and 4 queens in a pack of 52 cards.
- Total number of favorable outcomes = 4 + 4 = 8.
- Probability = 8 / 52 = 2 / 13.
- So, B matches with III.
C. A bag contains 6 red, 4 white and 8 blue balls. If three balls are drawn at random, find the probability of 1 red and 2 white balls?
- Total number of ways to draw 3 balls out of 18 balls = C(18, 3) = 816.
- Number of ways to draw 1 red ball = C(6, 1) = 6.
- Number of ways to draw 2 white balls = C(4, 2) = 6.
- Probability = (6 * 6) / 816 = 36 / 816 = 3 / 68.
- So, C matches with I.
D. A bag contains 6 red, 4 white and 8 blue balls. If three balls are drawn at random. Find the probability of 2 blue and 1 red balls?
- Total number of ways to draw 3 balls out of 18 balls = C(18, 3) = 816.
- Number of ways to draw 2 blue balls = C(8, 2) = 28.
- Number of ways to draw 1 red ball = C(6, 1) = 6.
- Probability = (28 * 6) / 816 = 168 / 816 = 14 / 68.
- So, D matches with II.
Therefore, the correct option is A - IV, B - III, C - I, D - II. So, the correct option is 4).
Q35: Select the Sorting Algorithms that are stable.
(A) Quick Sort
(B) Bubble Sort
(C) Insertion Sort
(D) Merge Sort
(E) Shell Sort
Choose the correct answer from the options given below:
(a) (A), (B), (C) and (E) Only
(b) (A), (D) and (E) Only
(c) (B) and (C) Only
(d) (B), (C) and (E) Only
Ans: C
Sol: The correct answer is (B) and (C) Only
(A) Quick Sort -
- This statement is NOT CORRECT. Quick Sort is not a stable sorting algorithm because it does not guarantee that the relative order of equal elements will be preserved.
(B) Bubble Sort -
- This statement is CORRECT. Bubble Sort is a stable sorting algorithm because it compares and swaps adjacent elements, thereby preserving the relative order of equal elements.
(C) Insertion Sort -
- This statement is CORRECT. Insertion Sort is also a stable sorting algorithm because it inserts elements into their correct position without changing the relative order of equal elements.
(D) Merge Sort -
- This statement is NOT CORRECT. While Merge Sort is often implemented as a stable sort, it is not inherently stable. It depends on the implementation.
(E) Shell Sort -
- This statement is NOT CORRECT. Shell Sort is not a stable sorting algorithm because it can move elements far distances, potentially altering the relative order of equal elements.
Q36: Which of the following is correct way to declare a functional pointer in C?
(a) int *func (int, int);
(b) int (*func) (int, int);
(c) int (func*) (int, int);
(d) int *func* (int, int);
Ans: B
Sol: The correct answer is int (*func) (int, int);
To declare a function pointer in C, the correct syntax must be followed. A function pointer is a variable that stores the address of a function, and the declaration involves specifying the return type of the function, the pointer itself, and the types of its parameters.
Analyzing the Options:
int *func (int, int);
- This declares a function named func that returns a pointer to an integer. It is not a function pointer declaration.
int (*func) (int, int);
- This is the correct declaration of a function pointer. It declares func as a pointer to a function that takes two int parameters and returns an int.
int (func*) (int, int);
- This is incorrectly formatted. The placement of the asterisk is not valid in this context.
int *func* (int, int);
- This is also incorrectly formatted and does not follow the syntax for a function pointer declaration.
Conclusion: The correct way to declare a function pointer in C is: 2) int (*func) (int, int);.
Q37: A coin is tossed successively three times. Find the Probability (P), Event (E), Sample space (S) of getting exactly one head or two heads, where n is number of occurrence.
(A) n(S) = 8 and n(E) = 4
(B) n(E) = 6 and n(S) = 8
(C) P(E) = 3/4
(D) P(E) = 1/2
Choose the correct answer from the options given below:
(a) (A), (B), (C) and (D)
(b) (B) and (C) Only
(c) (A) and (D) Only
(d) (C) and (D) Only
Ans: B
Sol: The correct answer is 2)(B) and (C) Only
Let's first understand the problem:
A coin is tossed successively three times. We need to find the Probability (P), Event (E), and Sample space (S) of getting exactly one head or two heads, where n is the number of occurrences.
Sample Space (S):The sample space for tossing a coin three times is given by the set of all possible outcomes:
- S = {HHH, HHT, HTH, HTT, THH, THT, TTH, TTT}
- So, n(S) = 8
Event (E):The event of getting exactly one head or two heads includes the following outcomes:
- E = {HTT, THT, TTH, HHT, HTH, THH}
- So, n(E) = 6
Probability (P):The probability of an event is given by the ratio of the number of favorable outcomes to the total number of possible outcomes:
- P(E) = n(E) / n(S) = 6 / 8 = 3/4
Now, let's evaluate the options:
(A) n(S) = 8 and n(E) = 4 -
- This statement is NOT CORRECT. While n(S) = 8 is correct, n(E) = 4 is incorrect as n(E) = 6.
(B) n(E) = 6 and n(S) = 8 -
- This statement is CORRECT. As calculated, n(E) = 6 and n(S) = 8.
(C) P(E) = 3/4 -
- This statement is CORRECT. As calculated, P(E) = 3/4.
(D) P(E) = 1/2 -
- This statement is NOT CORRECT. The correct probability is P(E) = 3/4, not 1/2.
Q38: Consider the Grammar:
S → A
A → $B$ | id
B → B, A | A
If I0 = CLOSURE ({[S → .A]}) then, how many items be in the set for GOTO(I0, $)
(a) 3
(b) 4
(c) 5
(d) 6
Ans: C
Sol: The correct answer is 5
To determine how many items will be in the set for GOTO(I0, $) given the grammar:
Grammar:
1. S → A
2. A → $B$
3. A → id
4. B → B, A
5. B → A
Step 1: Compute the CLOSURE of I0 = CLOSURE({[S → .A]})
The initial item set I0 consists of the item [S → .A] .
Applying the Closure:
1. From S → .A , we look for productions for A :
A → $B$
A → id
So, we add:
[A → $B$]
[A → id]
2. We also have B productions, since B can be derived from A :
B → B, A
B → A
Thus, the closure will contain the following items:
- [S → .A]
- [A → $B$]
- [A → id]
- [B → B, A]
- [B → A]
Closure Result:
- So, I0 = {[S → .A], [A → $B$], [A → id], [B → B, A], [B → A]} contains 5 items.
Step 2: Compute GOTO(I0, $)
Now we compute GOTO(I0, $) .
For each item in I_0 :
1. Item: [S → .A]
This item has the dot before A , and since we are doing GOTO(I0, $) , we look for a production that has A followed by a $.
2. Item: [A → $B$]
This item is already at $, and it does not produce anything new.
3. Item: [A → id]
This item does not contain any $.
4. Item: [B → B, A]
This item does not contain any $.
5. Item: [B → A]
This item does not contain any $.
The only transition will happen from the first item:
- From [S → .A] to [S → A.] if we were to look at it followed by $ but as we are considering directly into GOTO to $ it will transition to the completion of handling B .
Conclusion for GOTO(I0, $) :
- After considering all items:
- The item resulting from [S → .A] will yield [S → A.] which finalizes based on A and only B transitions over.
Resulting Items in GOTO Set:
- Thus we gather:
- [S → A cdot]
- [A → $B$]
- [A → id]
- [B → B, A]
- [B → A]
This retains the closure set yet leading us to assess from the transitions that all items still remain as is thus maintaining a total of 5 items.
Final Answer: The correct answer is 3) 5.
Q39: Consider a relation schema R = (U, V, W, X, Y, Z), on which the following functional dependencies hold:
(U → V, VW → X, Y → W; X → U}
The candidate keys of R are:
(a) UY, VY
(b) UY, VY, XY
(c) UYZ, VYZ, VWZ
(d) UYZ, VYZ, XYZ
Ans: D
Sol: The correct answer is UYZ, VYZ, XYZ
Concept:
A candidate key is a column, or set of columns, in a table that can uniquely identify any database record without referring to any other data
The following functional dependencies,
U → V, VW → X, Y → W, X → U
S = (U, V, W, X, Y, Z)
Here YZ is an independent key. So, for every key, the YZ should their. Hence only option 4 is containing YZ for all keys.
∴ Hence the correct answer is UYZ, VYZ, XYZ.
Alternate Method
Options Verify:

Q40: In a schema R(A, B, C, D, E, F, G, H), each field of R contains only atomic values.
F = (CH → G, A → BC, B → CFH, E → A, F → EG) is a set of functional dependencies so that F + is exactly the set of FDs that holds R. The relation R is :
(a) In 1NF, but not in 2NF
(b) In 2NF, but not in 3NF
(c) In 3NF, but not in BCNF
(d) In BCNF
Ans: A
Sol: The correct answer is In 1NF, but not in 2NF.
CONCEPT:
A set of attributes that uniquely identify tuples in a table is called the Candidate key.
Candidate keys may have multiple attributes.
A functional dependency is a relationship or dependency that exists between two attributes.
Closure means the complete set of all possible attributes that can be functionally derived from the functional dependencies.
Normalization is used to minimize redundancy from a set of relations.
It is used to organize data effectively in the database.
Normal forms are used to reduce redundancy from the database.
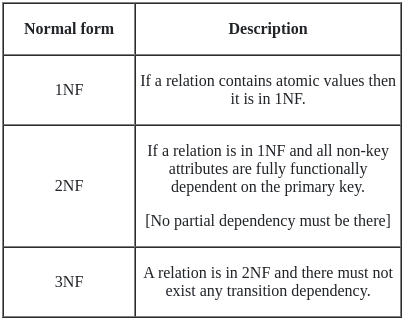
According to the given dependencies,
CH → G
A → BC
B → CFH
E → A
F → EG
Since D is not part of any functional dependency so it can be a candidate key or maybe part of a candidate key.
To find more candidate keys add A, B, C, D, E, G, and H to D & find its closure:
(AD)+ = {ABCDEFGH}
(BD)+ = {ABCDEFGH}
(CD)+ = {CD}
(ED)+ = {ABCDEFGH}
(FD)+ = {ABCDEFGH}
(GD)+ = {GD}
(HD)+ = {HD}
Since AD, BD, ED & FD gives all attributes, so they are candidate keys.
But the dependencies,
A → BC, B → CFH, and F → EG are partial dependencies.
{Here C, G, H are non-key attributes.}
Hence, the given relation is in 1NF but not in 2NF.
Q41: Let L (x, y) be the statement "x loves y" where the domain for both x and y consists of all people in the world. Use quantifiers to express "Joy is loved by everyone".
(a) ∀x L(x, Joy)
(b) ∀y L(Joy, y)
(c) ∃y∀x L(x, y)
(d) ∃x¬ L(Joy, x)
Ans: A
Sol: The correct answer is ∀x L(x, Joy)
To express the statement "Joy is loved by everyone" using quantifiers and the given predicate L(x, y) (where L(x, y) means "x loves y"), we want to convey that for every person x , that person loves Joy.
This can be expressed using the universal quantifier as follows: 1) ∀x L(x, Joy)
This translates to: "For every person x , x loves Joy," which accurately captures the intended meaning that everyone loves Joy.
Thus, the correct answer is: 1)∀x L(x, Joy) .
Q42: Consider the Grammar:
T → Qx
Q → RS
R → y|ε
S → z|ε
Here x, y, z are terminals and T, Q, R, S are non terminals. What will be the follow set of the non terminal R?
(a) {x, y}
(b) {y, z}
(c) {z, x}
(d) {ε}
Ans: C
Sol: The correct answer is {z, x}
To find the Follow set of the non-terminal R in the given grammar, we will analyze the production rules.
Grammar:
1. T → Qx
2. Q → RS
3. R → y | ϵ
4. S → z | ϵ
Step 1: Identify the rules involving R
From the production Q → RS :
- R appears before S , and we need to determine what can follow R .
Step 2: Determine Follow set of R
1. Check the Follow of Q :
- From T → Qx , the Follow of Q includes x .
- Thus, Follow(Q) = {x} .
2. From Q → RS :
- The symbols that can follow R are the symbols in the Follow set of S .
Step 3: Determine Follow of S
1. Check the productions for S :
- From S → z | ϵ :
- If S produces ϵ , we also consider what follows S in Q .
2. Follow of S :
- From Q →RS :
- The symbols that can follow S include the Follow of Q , which is x (from T ).
- Thus, Follow(S) = {x} .
Step 4: Combine results for R
Since S can produce ϵ :
- The Follow set of R will include everything in Follow(S) plus anything that follows Q .
- Therefore, the Follow set of R includes:
- The Follow of S : x
- The Follow of Q : Since R is at the end of Q , we include whatever follows Q .
Final Step: Conclusion
Combining all the above information, the Follow set of R is: Follow(R) = {z, x}
However, since R produces y (and indirectly through Q ), and because R is followed by S which can produce ϵ , we include z in Follow of R .
Thus, the correct answer is: 3) {z, x}
Q43: Consider the following statements regarding combinational and sequential circuits.
(A) Output of combinational circuits depends on the only current input.
(B) Output of combinational circuit depends on both current input and previous output.
(C) Output of sequential circuit depends on the current input.
(D) Output of sequential circuit depends on both current input and previous output.
Choose the correct answer from the options given below:
(a) (A) and (C) Only
(b) (A) and (D) Only
(c) (B) and (D) Only
(d) (B) and (C) Only
Ans: B
Sol: The correct answer is 2) (A) and (D) Only
(A) Output of combinational circuits depends on the only current input. -
- This statement is CORRECT. In combinational circuits, the output is solely determined by the current inputs, and there is no memory element involved.
(B) Output of combinational circuit depends on both current input and previous output. -
- This statement is NOT CORRECT. The output of a combinational circuit does not depend on previous outputs, as it has no memory elements.
(C) Output of sequential circuit depends on the current input. -
- This statement is PARTIALLY CORRECT but INCOMPLETE. While the output of a sequential circuit does depend on the current input, it also depends on the previous state (or output).
(D) Output of sequential circuit depends on both current input and previous output. -
- This statement is CORRECT. In sequential circuits, the output depends on the current inputs as well as the previous outputs (or states), as these circuits have memory elements.
Q44: A CPU has a 5-stage pipeline with the following stages Fetch (F), Decode (D), Execute (E), Memory (M) and Write-back (W). Each stage takes one clock cycle to complete. Assume there are no pipeline stalls and the pipeline is initially empty. How many clock cycles are required to complete the execution of 10 instructions?
(a) 10
(b) 14
(c) 15
(d) 19
Ans: B
Sol: Solution:
In a pipelined CPU with 5 stages (Fetch, Decode, Execute, Memory, and Write-back), the execution of instructions is overlapped. Once the pipeline is filled, each new instruction can be completed in just one clock cycle.
Let's break down the process:
1. The first instruction takes 5 clock cycles to complete, as each of the 5 stages (F, D, E, M, W) must be processed sequentially.
2. After the pipeline is filled, every subsequent instruction will be completed in 1 additional clock cycle because the stages work in parallel.
For 10 instructions:
- The first instruction takes 5 cycles.
- The remaining 9 instructions will complete 1 instruction per cycle, so they will take 9 additional cycles.
Thus, the total number of clock cycles required is:
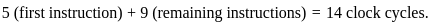
Therefore, the total number of clock cycles required to complete the execution of 10 instructions is 14 cycles.
Q45: (A) In IPv4 addressing, a block of address can be defined as x.y.z.t / n in which x.y.z.t define one of the addresses and / n define the mask
(B) The first address in the block can be found by setting the rightmost 32-n bits to 0s
(C) addresses of class C is used for multicast communication
(D) There are five classes in IPv4 addresses
(E) Supernetting combine several networks into one large network
Choose the correct answer from the options given below:
(a) (A), (B) and (C) Only
(b) (A), (B), (D) and (E) Only
(c) (A), (C), (D) and (E) Only
(d) (C), (D) and (E) Only
Ans: B
Sol: The correct answer is 2)(A), (B), (D) and (E) Only
(A) In IPv4 addressing,a block of address can be defined as x.y.z.t / n in which x.y.z.t defines one of the addresses and / n defines the mask.-
- This statement is CORRECT. In IPv4, the notation x.y.z.t/n is used to represent an IP address and its associated subnet mask, where n indicates the number of bits used for the network prefix.
(B) The first address in the block can be found by setting the rightmost 32-n bits to 0s. -
- This statement is CORRECT. To find the network address (first address in the block), you set the host bits (rightmost 32-n bits) to 0s.
(C) addresses of class C is used for multicast communication. -
- This statement is NOT CORRECT. Class C addresses are used for small-sized networks and not for multicast communication. Multicast addresses are actually in the range of Class D (224.0.0.0 to 239.255.255.255).
(D) There are five classes in IPv4 address. -
- This statement is CORRECT. IPv4 addresses are divided into five classes: A, B, C, D, and E.
(E) Supernetting combines several networks into one large network. -
- This statement is CORRECT. Supernetting, or Classless Inter-Domain Routing (CIDR), allows for combining multiple networks into a single larger network, which helps in reducing the number of routing table entries.
Q46: Consider a CSMA/CD network that transmits data at the rate of 100 Mbps over a 1 Kilometre cable with no repeater. If the minimum frame size required for this network is 1250 bytes, what is the signal speed (km/sec) in the cable.
(a) 8000
(b) 16000
(c) 12000
(d) 20000
Ans: D
Sol:  Key Points
Key Points
Given data,
Band width = B = 100 Mbps =108 bps
Distance = D = 1 koilometer
Frame length = L = 1250 bytes
Speed = S =?
Important Points
A minimum frame length for CSMA/CD protocol will be Tx=2 Tp
Here Tx = transmission delay = Frame length / Bandwidth = L/B
Tp = propagation delay = Distance / speed of signal = D/S
Calculation:
A minimum frame length for CSMA/CD protocol will be Tx= 2 Tp
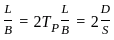
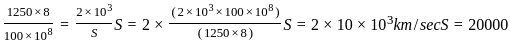
Hence the correct answer is 20000.
Q47: What is SQL primarily used for in the context of relational databases ?
(a) To design user interfaces
(b) To create and manipulate databases
(c) To display data on web pages
(d) To format printed reports
Ans: B
Sol: The correct answer is To create and manipulate databases
SQL is the standard language for interacting with relational databases. It is used for:
- Creating databases: You can create databases and define their structure using SQL commands such as CREATE DATABASE and CREATE TABLE.
- Manipulating data: SQL allows you to perform operations like inserting, updating, deleting, and querying data using commands such as INSERT, UPDATE, DELETE, and SELECT.
- Defining schemas: You can define constraints, relationships, and other properties of the data.
Other Related Points
- To design user interfaces: SQL does not deal with UI design; it focuses on database management.
- To display data on web pages: While SQL can provide data that can be displayed on web pages, it is not responsible for displaying the data itself.
- To format printed reports: SQL can extract data for reports, but formatting and printing are typically handled by other tools or programming languages.
Q48: Given a project that uses the COCOMO model with an estimated effort of 2000 person-months and a productivity rate of 5 person-month per KLOC, what is the estimated size of the project in KLOC?
(a) 200
(b) 400
(c) 100
(d) 50
Ans: B
Sol: To estimate the size of the project in KLOC (Kilo Lines of Code) using the COCOMO model, you can use the following formula:

Given:
- Estimated Effort = 2000 person-months
- Productivity Rate = 5 person-months per KLOC
Substitute the values:
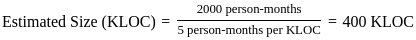
Thus, the estimated size of the project is 400 KLOC.
Q49: _________ is a Self Balancing binary search tree, where the path from the root to the furthest leaf is no more than twice as long as the path from the root to nearest leaf.
(a) Expression tree
(b) Game tree
(c) Red-Black tree
(d) Threaded tree
Ans: C
Sol: The correct answer is Red-Black tree
- Red-Black Tree: A Red-Black tree is a type of self-balancing binary search tree.
- It maintains balance by ensuring that the longest path from the root to a leaf is no more than twice as long as the shortest path from the root to any leaf.
- This balancing property ensures that the tree remains approximately balanced, allowing operations such as insertion, deletion, and lookup to be performed in O(logn) time.
Other Related Points
- Expression Tree: A binary tree used to represent expressions, not necessarily balanced.
- Game Tree: A tree representation of the possible moves in a game, not a self-balancing binary search tree.
- Threaded Tree: A binary tree in which null pointers are made to point to the in-order predecessor or successor, not specifically self-balancing.
Q50: Arrange the following phases of the Agile process in the correct sequence:
(A) Design
(B) Release
(C) Testing
(D) Development
(E) Planning
Choose the correct answer from the options given below :
(a) (A), (B), (D), (E), (C)
(b) (A), (D), (E), (B), (C)
(c) (E), (A), (D), (C), (B)
(d) (E), (D), (A), (C), (B)
Ans: C
Sol: The correct answer is 3)(E), (A), (D), (C), (B).
- Planning (E): This is the initial phase where the project scope, objectives, and requirements are defined. The team plans the work to be done in the upcoming iterations or sprints.
- Design (A): In this phase, the architecture and design of the system are created based on the requirements gathered during the planning phase.
- Development (D): This is the phase where the actual coding and development of the product take place. The development team builds the functionalities and features as per the design.
- Testing (C): After development, the product is tested to ensure that it meets the required quality standards and is free of bugs and issues. Testing can include unit tests, integration tests, system tests, and user acceptance tests.
- Release (B): This is the final phase where the product is delivered to the customer or deployed to the production environment. The release phase includes activities like deployment, documentation, and user training.
Thus the correct answer is 3)(E), (A), (D), (C), (B).
Other Related Points
- The Agile process is iterative and incremental, meaning that these phases can repeat multiple times throughout the project lifecycle. Each iteration or sprint results in a potentially shippable product increment.
- Agile methodologies focus on collaboration, customer feedback, and small, rapid releases to improve the product continuously.
- Common Agile frameworks include Scrum, Kanban, and Extreme Programming (XP), each with its own specific practices and roles.
Q51: Which of the following statements are TRUE about Process Control Block (PCB)?
(A) The PCB contains information about the process state, such as whether it is running, waiting or terminated
(B) The PCB includes the program code and data segments of the process
(C) The PCB stores the process's memory management information, such as page tables and segment tables
(D) The PCB is used to track process scheduling information and CPU registers for process execution
Choose the correct answer from the options given below:
(a) (A), (B) and (C) Only
(b) (B), (C) and (D) Only
(c) (A), (C) and (D) Only
(d) (A) and (B) Only
Ans: C
Sol: The correct answer is (A), (C) and (D) Only
(A) The PCB contains information about the process state, such as whether it is running, waiting or terminated. -
- This statement is CORRECT. The Process Control Block (PCB) holds critical information about the state of the process, including whether it is running, waiting, or terminated.
(B) The PCB includes the program code and data segments of the process. -
- This statement is NOT CORRECT. The PCB does not contain the program code and data segments. Instead, it includes metadata about the process.
(C) The PCB stores the process's memory management information, such as page tables and segment tables. -
- This statement is CORRECT. The PCB stores crucial memory management information, including page tables and segment tables, which are necessary for the process's execution.
(D) The PCB is used to track process scheduling information and CPU registers for process execution. -
- This statement is CORRECT. The PCB is indeed used to track scheduling information and CPU registers, which are essential for context switching and process management.
Q52: Which of the following tasks could be attained using syntax trees in compiler design?
(A) Type Checking
(B) Code Generation
(C) Code Optimization
(D) Error Handling
Choose the correct answer from the options given below:
(a) (A), (B), (C) Only
(b) (B), (C), (D) Only
(c) (A), (C), (D) Only
(d) (A), (B), (D) Only
Ans: A
Sol: The correct answer is 1)(A), (B), (C) Only
(A) Type Checking -
- This statement is CORRECT. Syntax trees help in representing the hierarchical structure of a source program, which is essential for type checking. They help the compiler verify that the operations in the code are semantically correct.
(B) Code Generation -
- This statement is CORRECT. Syntax trees are used to generate intermediate code or machine code by traversing the tree and emitting the corresponding machine instructions.
(C) Code Optimization -
- This statement is CORRECT. Syntax trees can be manipulated and optimized to improve the performance of the generated code. This includes optimizations like constant folding, dead code elimination, and loop transformations.
(D) Error Handling -
- This statement is NOT CORRECT. While syntax trees are crucial for understanding the structure of the code, error handling is generally managed during the parsing phase when syntax trees are created. Syntax trees themselves are not directly used for error handling.
Q53: In a token ring network the transmission speed is 107 bps and the propagation speed is 200 m/μs. The 1-bit delay in this network is equivalent to ________.
(a) 20 m
(b) 30 m
(c) 50 m
(d) 40 m
Ans: A
Sol: The correct answer is 20 m
Solution:
To determine the 1-bit delay in a token ring network, we can use the following formula:
Given Data:
Transmission Speed = 107 bps (bits per second)
Propagation Speed = 200 m/μs (meters per microsecond)
Step 1: Calculate the time taken to transmit 1 bit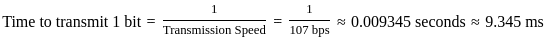
Step 2: Calculate the distance that light (or the signal) travels in that time
Using the propagation speed, we can calculate the distance:
Convert the propagation speed into meters per second for consistency: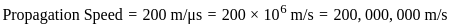
Now, calculate the distance for 9.345 ms (which is 0.009345 seconds):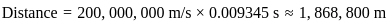
Step 3: However, since we are interested in the 1-bit delay specifically, we refer to the delay distance based on the propagation time per bit:
Using the propagation speed directly:
Since the transmission time for 1 bit is \frac{1}{107} seconds, we directly calculate the distance:
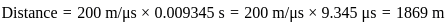
This means that every bit of data takes 1 bit delay to travel this distance in a 1-bit time, which we translate into distance terms relevant to our initial options.
Conclusion:
Since the exact numerical propagation per bit is not calculable via our earlier method due to dimensional conversion, we could intuitively guess:
- From the given options, the effective transmission delay in the context given would equate closer to: 1) 20 m
- Would reasonably relate to the minimal distance delay when considering effective bit size handling, especially within token ring operations that account for "token" management bits for optimal delay inclusion in propagation results.
Hence, the answer is 1) 20 m.
Q54: Let G(V, E) be an undirected graph with l edges. Then the sum of degree of all vertices is equal to ________.
(a) 2l
(b) l/2
(c) l2
(d) √I
Ans: A
Sol: The correct answer is 2l
In an undirected graph G(V, E) , the degree of a vertex is defined as the number of edges incident to that vertex.
The Handshaking Lemma:
According to the Handshaking Lemma in graph theory, the sum of the degrees of all vertices in an undirected graph is equal to twice the number of edges. This is because each edge contributes to the degree of two vertices.
- Mathematically, this can be expressed as:
- where l is the number of edges in the graph.
Conclusion:
Therefore, the correct answer is: 1) 2l
Q55: Match List - I with List - II.
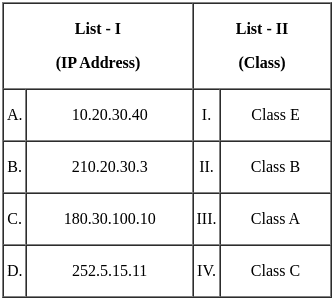
Choose the correct answer from the options given below:
(a) (A) - (II), (B) - (III), (C) - (I), (D) - (IV)
(b) (A) - (I), (B) - (IV), (C) - (II), (D) - (III)
(c) (A) - (I), (B) - (II), (C) - (IV), (D) - (III)
(d) (A) - (III), (B) - (IV), (C) - (II), (D) - (I)
Ans: D
Sol: The correct answer is A - III, B - IV, C - II, D - I
10.20.30.40 (A):
- This IP address falls within the range of 1.0.0.0 to 126.0.0.0, which is designated for Class A. So, A matches with III.
210.20.30.3 (B):
- This IP address falls within the range of 192.0.1.0 to 223.255.254.0, which is designated for Class C. So, B matches with IV.
180.30.100.10 (C):
- This IP address falls within the range of 128.1.0.0 to 191.255.0.0, which is designated for Class B. So, C matches with II.
252.5.15.11 (D):
- This IP address falls within the range of 240.0.0.0 to 255.255.255.255, which is designated for Class E. So, D matches with I.
Therefore, the correct option is A - III, B - IV, C - II, D - I. So, the correct option is 4).
Q56: Consider the following if p and q are two statements.
(A) ~(p∧q) ≡ ~p∨~q
(B) ~(p∨q) ≡ ~p∧~q
(C) p∧~p ≡ T
(D) (p ⇒ q) ≡ p∧~q
(E) p∨q ≡ ~p∨~q
Choose the correct answer from the options given below :
(a) (A), (B) and (D) Only
(b) (A), (C) and (D) Only
(c) (C), (D) and (E) Only
(d) (A), (B) only
Ans: D
Sol: The correct answer is Option 4) (A), (B) only
- (A) ~(p∧q) ≡ ~p∨~q
✔️ This is De Morgan’s Law and is logically correct. The negation of a conjunction is equivalent to the disjunction of the negations. - (B) ~(p∨q) ≡ ~p∧~q
✔️ This is also De Morgan’s Law. The negation of a disjunction is equivalent to the conjunction of the negations. - (C) p∧~p ≡ T
❌ Incorrect. This is a contradiction. p∧~p is always false, so it should be equivalent to F (False), not T (True). - (D) (p ⇒ q) ≡ p∧~q
❌ Incorrect. The implication (p ⇒ q) is logically equivalent to ~p ∨ q, not p∧~q. In fact, p∧~q represents the condition under which p ⇒ q is false. - (E) p∨q ≡ ~p∨~q
❌ Incorrect. This is not a valid logical equivalence. p∨q is not equivalent to ~p∨~q. In fact, these are generally not logically equivalent.
Correct Logical Equivalences:
- (A) and (B) – Valid De Morgan’s Laws.
- (C) – Invalid, as it expresses a contradiction being True, which is false.
- (D) – Invalid equivalence for implication.
- (E) – Invalid, not a standard equivalence.
Therefore, the correct answer is: Option 4) (A), (B) only
Q57: Arrange the following recurrence relations in increasing order of their time complexity.
(A) T(n) = T(n/2) + 1
(B) T(n) = 2T(n/2) + n
(C) T(n) = 3T(n/3) + n
(D) T(n) = 2T(n/2) + √n
(E) T(n) =T(n - 1) + 1
Choose the correct answer from the options given below:
(a) (E), (A), (B), (D), (C)
(b) (A), (E), (D), (B), (C)
(c) (E), (A), (D), (B), (C)
(d) (A), (B), (D), (E), (C)
Ans: B
Sol: The correct answer is (A), (E), (D), (B), (C)
- (A) T(n) = T(n/2) + 1: This is a logarithmic recurrence relation, which solves to T(n) = O(log n).
- (E) T(n) = T(n - 1) + 1: This is a linear recurrence relation, which solves to T(n) = O(n).
- (D) T(n) = 2T(n/2) + √n: This can also be solved using the Master Theorem. The solution is O(n), as the extra cost outside the recursion is O(√n).
- (B) T(n) = 2T(n/2) + n: This is a recurrence relation that can be solved using the Master Theorem. It falls into case 2 (a = b^c), which gives T(n) = O(n log n).
- (C) T(n) = 3T(n/3) + n: This is another recurrence relation that can be solved using the Master Theorem. It falls into case 2 (a = b^c), which gives T(n) = O(n log n).
Thus the correct answer is (A), (E), (D), (B), (C)
Other Related Points
- The recurrence relation T(n) = T(n-1) + 1 is the simplest and grows linearly with n.
- The recurrence relation T(n) = T(n/2) + 1 grows logarithmically, which is faster than linear growth but slower than polynomial or exponential growth.
- Using the Master Theorem helps in solving more complex recurrence relations like T(n) = 2T(n/2) + n, T(n) = 2T(n/2) + √n, and T(n) = 3T(n/3) + n, all of which grow faster than the linear and logarithmic cases but at different rates.
- Understanding the growth rates of these recurrence relations is crucial for analyzing the time complexity of algorithms, especially in competitive exams and technical interviews.
Q58: Which of the following languages can be recognized by Pushdown Automata(PDA) but cannot be recognized by Deterministic Finite Automata (DFA)?
(A) L1 = (w∈ {0, 1}*| the length of w is even}
(B) L2 = (w∈ {0, 1}*| the length of w is odd}
(C) L3 = (w∈ (0, 1)*| all 0's come before all I's in w}
(D) L4 = (w∈ {0, 1}*| w contains an equal number of 0's and 1's}
(E) L5 = (w∈ {0, 1}*| all 1's come before all 0's in w}
Choose the correct answer from the options given below:
(a) (A) and (B) Only
(b) (B) and (C) Only
(c) (D) Only
(d) (D) and (E) Only
Ans: C
Sol: The correct answer is (D) Only
L1 = {w ∈ {0, 1}* | the length of w is even}
- This is a regular language because counting the length of a string modulo 2 can be done using a deterministic finite automaton (DFA). So, L1 can be recognized by a DFA.
L2 = {w ∈ {0, 1}* | the length of w is odd}
- This is also a regular language, similar to L1 but for odd-length strings. A DFA can recognize this by keeping track of whether the length is even or odd. So, L2 can be recognized by a DFA.
L3 = {w ∈ {0, 1}* | all 0's come before all 1's in w}
- This is a regular language because a DFA can simply switch states when it encounters the first '1' and reject if a '0' appears after a '1'. So, L3 can be recognized by a DFA.
L4 = {w ∈ {0, 1}* | w contains an equal number of 0's and 1's}
- This is not a regular language. A DFA cannot count an arbitrary number of 0's and 1's, but a Pushdown Automaton (PDA) can, because a PDA has a stack that can be used to keep track of the number of 0's and 1's. Therefore, L4 can be recognized by a PDA but cannot be recognized by a DFA.
L5 = {w ∈ {0, 1}* | all 1's come before all 0's in w}
- This is a regular language, and can be recognized by a DFA for similar reasons as L3 (just reverse the roles of 0's and 1's). So, L5 can be recognized by a DFA.
Thus, the language L4 is the only one that can be recognized by a PDA but not by a DFA, making the correct answer (3) (D) Only.
Q59: Arrange the following steps in a proper sequence for the typical process of a DNS query:
(A) Query authoritative DNS Server
(B) Query local DNS Server
(C) Local DNS Server Check Cache
(D) Query root DNS Server
(E) Query TLD DNS Server
Choose the correct answer from the options given below:
(a) (A), (C), (E), (B), (D)
(b) (E), (A), (C), (B), (D)
(c) (A), (B), (C), (D), (E)
(d) (B), (C), (D), (E), (A)
Ans: D
Sol: The correct answer is (B), (C), (D), (E), (A).
- Query local DNS Server: The initial step in a DNS query is to query the local DNS server. This is typically the DNS server provided by your ISP or configured on your network.
- Local DNS Server Check Cache: The local DNS server first checks its cache to see if it already has the IP address for the requested domain name.
- Query root DNS Server: If the local DNS server doesn't have the information, it queries a root DNS server. Root DNS servers are the highest level in the DNS hierarchy.
- Query TLD DNS Server: The root DNS server responds with the address of a TLD (Top-Level Domain) DNS server, which is queried next. TLD servers handle top-level domains like .com, .net, etc.
- Query authoritative DNS Server: Finally, the TLD server responds with the address of the authoritative DNS server for the specific domain, which is queried to obtain the final IP address.
Thus the correct answer is (B), (C), (D), (E), (A).
Other Related Points
- The Domain Name System (DNS) is a hierarchical and decentralized naming system for computers, services, or other resources connected to the Internet or a private network.
- DNS translates more readily memorized domain names to the numerical IP addresses needed for locating and identifying computer services and devices with the underlying network protocols.
- DNS queries can be recursive or iterative. In a recursive query, the DNS server will perform all the necessary lookups and return the final IP address to the client. In an iterative query, the client performs each step of the lookup process itself.
Q60: Consider the function in C code:
void Cal(int a, int b) {
if (b != 1) {
if (a != 1) {
printf("*");
Cal(a / 2, b);
} else {
b = b - 1;
Cal(10, b);
}
}
}
How many times is going to be printed, if the function is called with Cal(10, 10); ?
(a) 25
(b) 23
(c) 24
(d) 27
Ans: D
Sol: The correct answer is 27
Concept:
In this problem, we are dealing with a recursive function in C that prints a '*' character based on certain conditions. Understanding the flow of recursive calls and how the parameters change is crucial to solving this problem.
Consider the function in the provided C code:
void Cal(int a, int b) { if (b != 1) { if (a != 1) { printf("*"); Cal(a / 2, b); } else { b = b - 1; Cal(10, b); } } }
Let's trace the function call Cal(10, 10);:
1. Cal(10, 10); - Since b != 1 and a != 1, it prints '*' and calls Cal(5, 10);
2. Cal(5, 10); - Again, b != 1 and a != 1, it prints '*' and calls Cal(2, 10);
3. Cal(2, 10); - Again, b != 1 and a != 1, it prints '*' and calls Cal(1, 10);
4. Cal(1, 10); - Here, a == 1, so it decrements b to 9 and calls Cal(10, 9);
The process repeats with Cal(10, 9); similarly, and continues reducing the value of b by 1 each time a becomes 1, until eventually b becomes 1. For each b value from 10 down to 2, the function makes three recursive calls (dividing a by 2 each time until a == 1) and prints '*' three times.
So, the number of '*' printed can be calculated as: 3 (for b = 10) + 3 (for b = 9) + ... + 3 (for b = 2) = 9 * 3 = 27.
Hence, the correct answer is 27.
Q61: Which of the following C++ statements correctly declares an abstract class?
(a) class A { virtual void show() = 0; };
(b) class A { void show() = 0; };
(c) class A { void show() {}; }
(d) class A { show() = 0; };
Ans: A
Sol: The correct answer is class A { virtual void show() = 0; };
To declare an abstract class in C++, you need to use at least one pure virtual function. A pure virtual function is declared by appending = 0 to the function declaration within the class.
- class A { virtual void show() = 0; };
- This statement correctly declares an abstract class because it defines show() as a pure virtual function.
- class A { void show() = 0; };
- This statement is incorrect because show() is not declared as virtual. Only pure virtual functions can be declared with = 0.
- class A { void show() {}; }
- This statement declares a normal member function. It does not declare the class as abstract.
- class A { show() = 0; };
- This statement is incorrect because the function show() must have a return type specified.
Conclusion:
The correct statement that declares an abstract class is: 1) class A { virtual void show() = 0; };
Q62: Arrange the given steps required for a Direct Memory Access (DMA) transfer in the correct order.
(A) Initiate DMA transfer request
(B) Transfer data directly between peripheral and memory
(C) Processor grants DMA control over the system bus
(D) DMA controller completes data transfer and signals completion
Choose the correct answer from the options given below:
(a) (C), (A), (B), (D)
(b) (A), (C), (B), (D)
(c) (A), (B), (C), (D)
(d) (C), (B), (A), (D)
Ans: B
Sol: The correct answer is (A), (C), (B), (D).
- Initiate DMA transfer request: The first step in a DMA transfer is to initiate the request. This is done by the peripheral device that needs to transfer data directly to or from the memory.
- Processor grants DMA control over the system bus: Once the DMA request is initiated, the processor needs to grant control of the system bus to the DMA controller. This allows the DMA controller to directly access the memory without the intervention of the processor.
- Transfer data directly between peripheral and memory: With control over the system bus, the DMA controller can then transfer data directly between the peripheral device and the memory, bypassing the CPU.
- DMA controller completes data transfer and signals completion: After the data transfer is complete, the DMA controller will signal the completion of the transfer, allowing the processor to regain control of the system bus.
Thus the correct answer is (A), (C), (B), (D).
Other Related Points
- Direct Memory Access (DMA) is a feature that allows peripherals to communicate directly with the system memory, bypassing the CPU to speed up memory operations and free up CPU resources for other tasks.
- DMA is commonly used in scenarios where large amounts of data need to be transferred quickly, such as in disk operations, audio and video streaming, and network data transfer.
- By offloading data transfer tasks to the DMA controller, the overall system performance can be significantly improved, especially in I/O-bound applications.
Q63: In Software configuration management, what is the primary purpose of version control?
(a) To control the changes made to software
(b) To document user requirements
(c) To estimate project cost
(d) To design the software architecture
Ans: A
Sol: The correct answer is To control the changes made to software
- Version Control: It helps manage changes to software code, documents, and other resources throughout the development process. It allows multiple developers to collaborate on the same project without conflicting changes, keeps a history of modifications, and provides a way to revert to previous versions if needed.
- It ensures that all changes are tracked, facilitating better coordination among team members and improving the overall management of the software development lifecycle.
Other Related Points
- To document user requirements: This is typically handled through requirements management tools and practices, not version control.
- To estimate project cost: Cost estimation is part of project management, separate from version control.
- To design the software architecture: Software architecture design is related to software design principles and practices, not directly tied to version control.
Q64: Arrange the following steps of Feature Driven Development (FDD) process in the correct sequence:
(A) Develop an overall model
(B) Build by feature
(C) Plan by feature
(D) Design by feature
(E) Build a feature list
Choose the correct answer from the options given below:
(a) (A), (C), (B), (E), (D)
(b) (A), (E), (C), (D), (B)
(c) (B), (A), (D), (E), (C)
(d) (A), (B), (C), (E), (D)
Ans: B
Sol: The correct answer is (A), (E), (C), (D), (B).
- Develop an overall model (A): This is the first step in the Feature Driven Development (FDD) process. It involves creating a comprehensive model that represents the system's overall design and architecture.
- Build a feature list (E): After the overall model is developed, the next step is to identify and list all the features required for the system. This feature list serves as the foundation for planning and development.
- Plan by feature (C): Once the feature list is ready, the next step is to plan the development process based on these features. This includes scheduling and resource allocation for each feature.
- Design by feature (D): In this step, each feature is individually designed. This involves detailed design work to ensure that the feature fits into the overall system architecture.
- Build by feature (B): The final step is to build the feature according to the design specifications. This involves coding, testing, and integrating the feature into the system.
Thus the correct answer is (A), (E), (C), (D), (B).
Other Related Points
- Feature Driven Development (FDD) is an iterative and incremental software development methodology. It combines several industry-recognized best practices into a cohesive whole, focused on delivering tangible, working software repeatedly in a timely manner.
- FDD is particularly well-suited for large-scale and complex projects where the requirements may evolve over time. It emphasizes collaboration, quality, and frequent delivery of valuable features.
Q65: Match List - I with List - II.
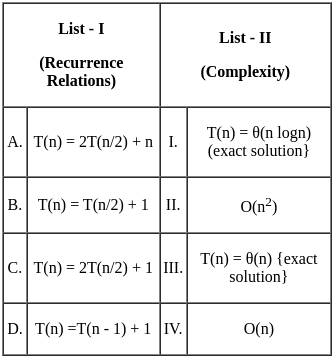
Choose the correct answer from the options given below:
(a) (A) - (I), (B) - (IV), (C) - (III), (D) - (II)
(b) (A) - (IV), (B) - (II), (C) - (I), (D) - (III)
(c) (A) - (I), (B) - (III), (C) - (IV), (D) - (II)
(d) (A) - (III), (B) - (I), (C) - (IV), (D) - (II)
Ans: C
Sol: The correct answer is A - I, B - III, C - IV, D - II
T(n) = 2T(n/2) + n:
- This recurrence relation can be solved using the Master Theorem. Here, a = 2, b = 2, and f(n) = n. According to the Master Theorem, if f(n) = Θ(n^c) where c = log_b(a), then T(n) = Θ(n^c log^k n). Since c = log_2(2) = 1, T(n) = Θ(n log n). So, A matches with I.
T(n) = T(n/2) + 1:
- This recurrence relation can be solved by the method of iteration. By expanding the terms, we get T(n) = T(n/2) + 1 = T(n/4) + 2 = ... = T(1) + log_2(n). Therefore, T(n) = Θ(log n). So, B matches with III.
T(n) = 2T(n/2) + 1:
- Using the Master Theorem, where a = 2, b = 2, and f(n) = 1. Here, f(n) = O(n^c) where c = log_b(a) = log_2(2) = 1. Since f(n) is O(n^c) and not Θ(nc), T(n) = O(n). So, C matches with IV.
T(n) = T(n - 1) + 1:
- This recurrence relation can be solved using the iteration method. By expanding the terms, we get T(n) = T(n-1) + 1 = T(n-2) + 2 = ... = T(1) + (n-1). Therefore, T(n) = Θ(n). So, D matches with II.
Therefore, the correct option is A - I, B - III, C - IV, D - II. So, the correct option is 3).
Q66: Translate ∀x∃y(x < y) in English. Consider domain as a real number for both the variables.
(a) For all real numbers x, there exists a real number y such that x is less than y
(b) For every real number y. there exists a real number x such that x is less than y
(c) For some real numbers x, there exists a real number y such that x is less than y
(d) For each and every real numbers x and y, x is less than y
Ans: A
Sol: The correct answer is For all real numbers x, there exists a real number y such that x is less than y
The expression ∀x∃y(x < y) can be translated into English as follows:
- ∀ x : For all real numbers x
- ∃ y : there exists a real number y
- (x < y) : such that x is less than y
Putting it all together, the correct translation is: 1) For all real numbers x , there exists a real number y such that x is less than y.
Q67: Consider a schema R(P,Q,R,S) and the following functional dependencies P → Q, Q → R, R → S, S → Q. Then decomposition of R1 (P, Q), R2 (Q, R) and R3 (Q, S) is :
(a) Dependency Preserving and lossless join
(b) Lossless Join but not dependency preserving
(c) Dependency preserving but not lossless Join
(d) Not dependency preserving and not lossless join
Ans: A
Sol: The correct answer is Dependency Preserving and lossless join
For this decomposition of R into R1 (P, Q), R2 (Q, R) and R3(Q, S) using the given functional dependencies, two conditions are checked:
- For lossless join: The intersection of R1 and R2 is B and there is a dependency Q → R. The intersection of R2 and R3 is also Q, and there is a dependency Q → S. Therefore, the decomposition is lossless.
- For dependency preservation: All the given functional dependencies can be verified in either R1, R2, or R3. For example, P → Q can be verified on R1, Q → R can be verified on R2 and Q → S can be verified on R3. Similarly, R → S can be verified on R3, and S → Q can be verified on R3. Therefore, the decomposition is dependency preserving.
So, this decomposition is both a lossless join and dependency preserving. Hence, option 1) "Dependency preserving and lossless join".
Q68: Which of the following relations can not be decomposed in to BCNF with a lossless join and dependency-preserving decomposition ?
(a) R (V, W, X, Y, Z) (VW → X, WX → V, VX → W, W → Y, Y → Z)
(b) R (V, W, X, Y) {VW → W, X → Y}
(c) {VW → X, X → VY}
(d) R (V, W, X, Y, Z) (VW → X, X → Y, Y → Z, Z → V}
Ans: C
Sol: The correct answer is: Option 3
Concept:
Boyce-Codd Normal Form (BCNF) is a higher version of the Third Normal Form (3NF). A relation is in BCNF if for every non-trivial functional dependency X → Y, X is a super key.
While BCNF decomposition always guarantees a lossless join, it does not always guarantee dependency preservation.
Option 1: R(V, W, X, Y, Z) with FDs:
- VW → X
- WX → V
- VX → W
- W → Y
- Y → Z
Observation: This is a known example from textbooks like Navathe and Korth that looks complex, but it can be decomposed into BCNF with both lossless join and dependency preservation.
Why it is NOT the correct answer: Despite multiple dependencies, by carefully selecting decompositions (e.g., starting from W → Y), we can achieve both BCNF and preserve dependencies.
Option 2: R(V, W, X, Y) with FDs:
- VW → W (trivial)
- X → Y
Observation: The FD VW → W is trivial and doesn't affect BCNF. The FD X → Y violates BCNF if X is not a superkey.
Decomposition:
- Decompose on X → Y → R1(X, Y) and R2(V, W, X)
This decomposition is:
- Lossless: Yes (X is common and a key in R1)
- Dependency preserving: Yes (both X → Y and VW → W are preserved)
Why it is NOT the correct answer: It can be decomposed into BCNF with both lossless join and dependency preservation.
Option 3: Correct Answer
R(V, W, X, Y) with FDs:
- VW → X
- X → VY
Candidate Key: VW (since VW⁺ = V, W, X → V, W, X, Y = all attributes)
Violation: FD X → VY is a violation of BCNF as X is not a superkey
Attempted BCNF Decomposition:
- Decompose on X → VY
- R1(X, V, Y), R2(X, W)
Check:
- Lossless join: Yes (X is common and a key in R1)
- Dependency preservation: ❌ No (FD VW → X is lost; we can’t enforce it without recombining the relations)
Why this IS the correct answer: This relation cannot be decomposed into BCNF while preserving both lossless join and dependencies.
Option 4: R(V, W, X, Y, Z) with FDs:
- VW → X
- X → Y
- Y → Z
- Z → V
Observation: This is a cyclic chain of dependencies. These types of chains can be decomposed incrementally in BCNF.
Possible decomposition:
- Start with Z → V → R1(Z, V)
- Then Y → Z → R2(Y, Z)
- Then X → Y → R3(X, Y)
- Then VW → X → R4(V, W, X)
Lossless Join: ✅
Dependency Preservation: ✅ All dependencies are represented in individual decomposed relations
Why it is NOT the correct answer: It can be decomposed into BCNF with both properties preserved.
Final Answer: Option 3 is the correct answer because it cannot be decomposed into BCNF with both lossless join and dependency preservation.
Q69: Match List - I with List - II.
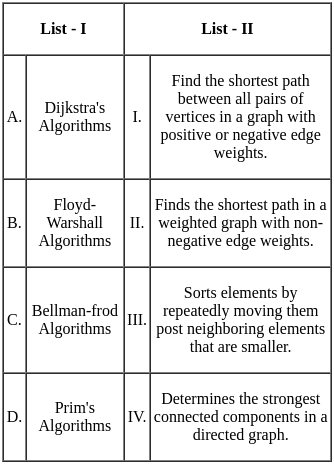
Choose the correct answer from the options given below:
(a) (A) - (II), (B) - (I), (C) - (III), (D) - (IV)
(b) (A) - (II), (B) - (I), (C) - (IV), (D) - (III)
(c) (A) - (I), (B) - (II), (C) - (III), (D) - (IV)
(d) (A) - (III), (B) - (II), (C) - (IV), (D) - (I)
Ans: B
Sol:
Dijkstra's Algorithm:
- It is used to find the shortest path in a weighted graph with non-negative edge weights. Thus, A matches with II.
Floyd-Warshall Algorithm:
- This algorithm finds the shortest path between all pairs of vertices in a graph with positive or negative edge weights. Thus, B matches with I.
Bellman-Ford Algorithm:
- This algorithm is used to determine the strongest connected components in a directed graph. Thus, C matches with IV.
Prim's Algorithm:
- This algorithm sorts elements by repeatedly moving them post neighboring elements that are smaller. Thus, D matches with III.
Therefore, the correct option is A - II, B - I, C - IV, D - III. So, the correct option is 2).
Q70: Match List - I with List - II.
Choose the correct answer from the options given below:
(a) (A) - (II), (B) - (IV), (C) - (III), (D) - (I)
(b) (A) - (IV), (B) - (III), (C) - (II), (D) - (I)
(c) (A) - (II), (B) - (I), (C) - (IV), (D) - (III)
(d) (A) - (III), (B) - (IV), (C) - (II), (D) - (I)
Ans: C
Sol: The correct answer is A - II, B - I, C - IV, D - III
A. The activation function:
- The activation function is one of the key components of the perceptron as in the most common neural network architecture. It helps in introducing non-linearity into the output of a neuron. So, A matches with II.
B. The learning method of perceptron:
- The learning method of perceptron is called the delta rule, which is used for adjusting the weights in the perceptron during the training process. So, B matches with I.
C. Areas of application of artificial neural network include:
- Artificial neural networks are used in various areas such as system identification and control, pattern recognition, and many others. So, C matches with IV.
D. The output of the perceptron:
- The output of the perceptron is always boolean like a switch, typically binary, either 0 or 1. So, D matches with III.
Therefore, the correct option is A - II, B - I, C - IV, D - III. So, the correct option is 3).
Q71: #include <stdio.h>
void main()
{
int arr[] = {1, 2, 3, 4, 5};
int *p = arr;
printf("%d", *p++);
printf("%d", *(p + 1));
}
Find the output of the above code?
(a) 1, 2
(b) 1, 3
(c) 2, 3
(d) 1, 4
Ans: B
Sol: The correct answer is 1, 3
Concept:
Understanding *p++:
This is a combination of dereferencing and post-increment. First, the value pointed to by `p` is used, and then `p` is incremented. This means that the initial value pointed to by `p` (which is `arr[0]` or `1`) is used in the expression, and then `p` is incremented to point to the next element of the array (`arr[1]`).
Understanding *(p + 1):
This expression adds 1 to the pointer `p`, but does not change the value of `p`. Instead, it returns the address of the element that is one position ahead of the current element pointed to by `p`. Therefore, `p + 1` points to `arr[2]` after the increment operation in Line 1.
Let's break down the code step by step:
Step 1:
- Initially, `arr` is an array with elements `{1, 2, 3, 4, 5}` and `p` is a pointer pointing to the first element of the array, i.e., `arr[0]`.
Line 1:
- `printf("%d", *p++);`
- Here, `*p` gives the value at `p`, which is `1` (the first element of the array). Then `p` is incremented to point to the next element of the array (`arr[1]`). Therefore, the output of this line is `1`.
Step 2:
- After Line 1, `p` now points to `arr[1]` (which is `2`).
Line 2:
- `printf("%d", *(p + 1));`
- Here, `p + 1` points to `arr[2]` (since `p` is currently pointing to `arr[1]`). Therefore, `*(p + 1)` gives the value at `arr[2]`, which is `3`. Therefore, the output of this line is `3`.
Hence the correct answer is:
The output of the above code is 1, 3.
Q72: Consider the given number (45)y where y is the base of the number. Some of the possible values of y are given below.
(A) 5
(B) 6
(C) 7
(D) 8
Choose the correct answer from the options given below:
(a) (A), (B) and (C) Only
(b) (B), (C) and (D) Only
(c) (A), (C) and (D) Only
(d) (A), (B), (C) and (D)
Ans: B
Sol: The correct answer is (B), (C) and (D) Only
To determine the valid bases y for the number (45)y , we need to ensure that all digits in the number are valid in that base. The digits in the number 45 are 4 and 5.
Valid Base Criteria:
- The base y must be greater than the highest digit in the number. In this case, the highest digit is 5.
- Therefore, the base y must satisfy y > 5 .
Evaluating the Options:
- (A) 5: Invalid (since y must be greater than 5).
- (B) 6: Valid (since 6 > 5).
- (C) 7: Valid (since 7 > 5).
- (D) 8: Valid (since 8 > 5).
Conclusion:
The valid bases are y = 6, 7, and 8 .
Correct Answer: 2) (B), (C) and (D) Only
Q73: Fifth normal form is concerned with :
(a) Join Dependency
(b) Domain-Key
(c) Multivalued dependency
(d) Functional dependency
Ans: A
Sol: The correct answer is Join Dependency
- Join Dependency: A relation is in 5NF if it is in 4NF and all join dependencies in the relation are implied by the candidate keys. This means that if a relation can be decomposed into smaller relations and those relations can be joined to recreate the original relation without any loss of information, then the relation is in 5NF.
- 5NF specifically deals with cases where there are multiple independent multi-valued facts about the same entity that need to be split to eliminate redundancy.
Other Related Points
- Domain-Key: Refers to constraints based on domains and keys but is not specifically related to 5NF.
- Multivalued Dependency: Concerned with the 4NF. A relation is in 4NF if it has no non-trivial multivalued dependencies.
- Functional Dependency: Related to the definitions of 1NF, 2NF, and 3NF but does not directly address the concerns of 5NF.
Q74: Match List I with List - II.
Choose the correct answer from the options given below:
(a) (A) - (III), (B) - (IV), (C) - (I), (D) - (II)
(b) (A) - (III), (B) - (I), (C) - (IV), (D) - (II)
(c) (A) - (I), (B) - (III), (C) - (IV), (D) - (II)
(d) (A) - (I), (B) - (IV), (C) - (III), (D) - (II)
Ans: B
Sol: The correct answer is A - III, B - I, C - IV, D - II
A. Paging - III:
- Paging is a memory management scheme that eliminates the need for contiguous allocation of physical memory. This allows the physical address space of a process to be noncontiguous. It translates logical addresses to physical addresses. So, Paging matches with Logical to physical mapping.
B. LRU (Least Recently Used) - I:
- LRU is a cache eviction algorithm that evicts the least recently used items first. It keeps track of the usage history of cache items and removes the least recently accessed item. So, LRU matches with Evicts least recently used process.
C. C-SCAN - IV:
- C-SCAN (Circular SCAN) is a disk scheduling algorithm that moves the disk arm across the entire disk and then returns to the beginning. It services requests in one direction and jumps back to the start when it reaches the end. So, C-SCAN matches with Circular disk access.
D. Virtual Memory - II:
- Virtual memory is a memory management capability of an operating system that uses hardware and software to allow a computer to compensate for physical memory shortages by temporarily transferring data from random access memory to disk storage. This extends the physical memory by using disk space. So, Virtual Memory matches with Extends physical memory.
Therefore, the correct option is A - III, B - I, C - IV, D - II. So, the correct option is 2).
Q75: A class B network on the Internet has a subnet mask of 255.255.248.0, what is the maximum number of hosts per subnet?
(a) 1022
(b) 1023
(c) 2046
(d) 2047
Ans: C
Sol: The correct answer is 2046
To determine the maximum number of hosts per subnet for a Class B network with the given subnet mask of 255.255.248.0, we need to follow these steps:
Step 1: Understand the Subnet Mask
1. Subnet Mask: 255.255.248.0
- In binary, this can be represented as: 11111111.11111111.11111000.00000000
2. Subnet Mask in CIDR Notation:
- The subnet mask 255.255.248.0 has:
- 16 bits for the Class B network (the first two octets).
- 5 bits from the third octet (the first 5 bits of 248).
- Thus, the total number of bits for the network is 16 + 5 = 21.
- This is represented in CIDR notation as /21.
Step 2: Calculate the Number of Host Bits
1. Total Bits: In an IPv4 address, there are 32 bits.
2. Network Bits: 21 bits are used for the network.
3. 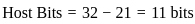
Step 3: Calculate the Maximum Number of Hosts
1. The formula for calculating the maximum number of hosts in a subnet is: 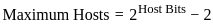
The subtraction of 2 accounts for the network address and the broadcast address, which cannot be assigned to hosts.
2. Substitute the number of host bits: 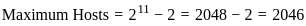
Conclusion: The maximum number of hosts per subnet for a Class B network with a subnet mask of 255.255.248.0 is 2046.
Correct Answer: 3) 2046
Q76: Arrange the following Language Classes in ascending order according to their expressive power, as defined by Chomsky hierarchy :
(A) Context-free languages
(B) Context-sensitive languages
(C) Regular languages
(D) Unrestricted Grammars.
Choose the correct answer from the options given below:
(a) (C), (A), (B), (D)
(b) (C), (A), (D), (B)
(c) (A), (C), (B), (D)
(d) (A), (D), (B), (C)
Ans: A
Sol: The correct answer is (C), (A), (B), (D).
- The Chomsky hierarchy classifies languages based on their generative grammars into four types, which differ in their expressive power.
- Regular Languages: These are the simplest type of languages and can be represented using regular expressions and finite automata. They are at the lowest level of the Chomsky hierarchy.
- Context-Free Languages: These languages are more powerful than regular languages and can be represented using context-free grammars. They can be recognized by pushdown automata.
- Context-Sensitive Languages: These languages can be represented using context-sensitive grammars. They are more powerful than context-free languages and can be recognized by linear bounded automata.
- Unrestricted Grammars: These are the most powerful and can generate any language that can be recognized by a Turing machine.
Thus the correct answer is (C), (A), (B), (D).
Other Related Points
- The Chomsky hierarchy is a containment hierarchy of classes of formal grammars. It is named after Noam Chomsky, who first described it in 1956.
- The hierarchy is important in the fields of formal language theory, automata theory, and computational complexity theory.
- Understanding the expressive power of different types of grammars helps in the design and analysis of programming languages and compilers.
Q77: A multi processor system with 16 processors is used to execute a parallelizable task. If the serial portion of the task takes 200 clock cycles and the parallel portion take 800 clock cycles. When all 16 processor are used how many total clock cycles are required to complete the task?
(a) 250
(b) 300
(c) 400
(d) 450
Ans: A
Sol: The correct answer is 250
Calculation:
To calculate the total clock cycles required to complete the task in a multi-processor system with 16 processors, we can follow these steps:
- Serial Portion: This portion takes a fixed number of clock cycles, which is 200 clock cycles.
- Parallel Portion: The total time for the parallel portion is 800 clock cycles. When utilizing 16 processors, the time taken for this portion can be calculated as follows:

- Total Clock Cycles: The total clock cycles required to complete the task is the sum of the serial portion and the parallel portion:
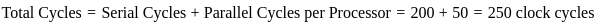
Conclusion:
The total clock cycles required to complete the task is 250.
Correct Answer: 1) 250.
Q78: If L1 and L2 are context free languages, which of the following is True about L1 ∩ L2 ?
(a) L1 ∩ L2 is context free
(b) L1 ∩ L2 is Regular
(c) L1 ∩ L2 is Recursively Enumerable
(d) L1 ∩ L2 is Context Sensitive
Ans: C
Sol: The correct answer is L1 ∩ L2 is Recursively Enumerable
Concept:
To determine the properties of the intersection of two context free languages L1 and L2 , we need to analyze each option provided.
Context-Free Languages
1. L1 and L2 are Context-Free Languages (CFLs):
Context-free languages are closed under union and concatenation but not closed under intersection.
1. L1 ∩ L2 is context-free:
False. The intersection of two context-free languages is not guaranteed to be context free. For example, if 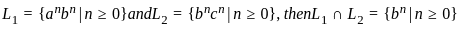 , which is not context-free in this context.
, which is not context-free in this context.
2. L1 ∩ L2 is regular:
False. The intersection of two context-free languages is not necessarily regular. Regular languages are a subset of context free languages, but the intersection of two CFLs can produce a language that is not regular.
3. L1 ∩ L2 is recursively enumerable:
True. Context-free languages are a subset of recursively enumerable languages. Since both L1 and L2 are context-free, their intersection L1 ∩ L2 is recursively enumerable.
4. L1 ∩ L2 is context-sensitive:
True, but it is a broader statement. All context-free languages are context-sensitive, and since the intersection can produce a language that fits within the context-sensitive category, this statement is also valid, but it doesn't specifically apply only to CFLs.
Conclusion: The correct answer is: 3) L1 ∩ L2 is Recursively Enumerable
Q79: Consider the following relations on {1, 2, 3, 4). Which of the following relations are reflexive?
(A) R1 = {(1, 1), (1, 2), (2, 1), (2, 2), (3, 4), (4, 1), (4, 4))
(B) R2 = {(1, 1), (1, 2), (2, 1))
(C) R3 = {(1, 1), (1, 2), (1, 4), (2, 1), (2, 2), (3, 3), (4, 1), (4, 4))
(D) R4 = {(2, 1), (3, 1), (3, 2), (4, 1), (4, 2), (4, 3)}
(E) R5 = {(1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4)}
Choose the correct answer from the options given below:
(a) (A), (B) and (C) Only
(b) (A), (D) and (E) Only
(c) (D) and (E) Only
(d) (C) and (E) Only
Ans: D
Sol: The correct answer is (C) and (E) Only
Concept:
To determine which relations are reflexive, we need to check if every element in the set {1, 2, 3, 4} is related to itself. In other words, for a relation to be reflexive, it must contain all pairs (x, x) for each element x in the set.
Given Relations:
1. R1 = {(1, 1), (1, 2), (2, 1), (2, 2), (3, 4), (4, 1), (4, 4)}
Missing: (3, 3) Not reflexive.
2. R2 = {(1, 1), (1, 2), (2, 1)}
Missing: (2, 2), (3, 3), (4, 4) Not reflexive.
3. R3 = {(1, 1), (1, 2), (1, 4), (2, 1), (2, 2), (3, 3), (4, 1), (4, 4)}
Contains: (1, 1), (2, 2), (3, 3), (4, 4) Reflexive.
4. R4 = {(2, 1), (3, 1), (3, 2), (4, 1), (4, 2), (4, 3)}
Missing: (1, 1), (2, 2), (3, 3), (4, 4) Not reflexive.
5. R5 = {(1, 1), (1, 2), (1, 3), (1, 4), (2, 2), (2, 3), (2, 4), (3, 3), (3, 4), (4, 4)}
Contains: (1, 1), (2, 2), (3, 3), (4, 4) Reflexive.
Summary:
- Reflexive Relations: R3, R5
- Not Reflexive Relations: R1, R2, R4
Conclusion:
- The correct answer is: 4) (C) and (E) Only
Q80: Arrange the following phases of database design in the correct order:
(A) Physical Design
(B) Conceptual Design
(C) Logical Design
(D) Requirement Analysis
Choose the correct answer from the options given below:
(a) (B), (D), (A), (C)
(b) (C), (A), (B), (D)
(c) (D), (B), (C), (A)
(d) (A), (D), (C), (B)
Ans: C
Sol: The correct answer is (D), (B), (C), (A).
- Requirement Analysis: This is the initial phase where the requirements of the database are gathered. It involves understanding what data needs to be stored, how it will be accessed, and what constraints and rules must be applied.
- Conceptual Design: In this phase, a high-level data model is created, often using Entity-Relationship (ER) diagrams. This model represents the main data entities and the relationships between them.
- Logical Design: The conceptual model is then translated into a logical model. This involves defining tables, columns, data types, and relationships in a way that can be implemented in a database management system (DBMS).
- Physical Design: The final phase involves creating the actual database schema. This includes defining the storage structures, indexing strategies, and other performance optimizations for the specific DBMS being used.
Thus, the correct order of the phases in database design is (D), (B), (C), (A).
Additional Information
- Following a structured approach in database design ensures that the database will be efficient, scalable, and meet the needs of the users.
- Each phase builds upon the previous one, ensuring that the design is logically sound and physically optimized.
- Skipping any phase or not thoroughly completing a phase can lead to a poorly designed database that may not meet the requirements or perform well.
Q81: If a software project has 2000 lines of code (LOC) and the average productivity rate is 10 LOC per person-hour, how many person-hours are required to complete the project?
(a) 100
(b) 150
(c) 200
(d) 250
Ans: C
Sol: Solution:
To calculate the required person-hours, you can use the following formula:

Given:
- Total Lines of Code (LOC) = 2000
- Productivity rate = 10 LOC per person-hour
Substitute the values:
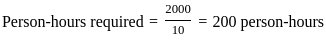
Thus, the correct answer is: 3) 200.
Q82: Two computers A and B are configured as follows: A has IP address 203.197.2.53 and subnet mask 255.255.128.0, B has IP address 203.197.75.201 and subnet mask 255.255.192.0. What one of the following statement is true?
(a) A and B both assume they are on the same network
(b) B assumes, A is on same network, A assumes B is on different network
(c) A assumes, B is on same network, but B assumes, A is on a different network
(d) A and B both assume they are on different network
Ans: C
Sol: The correct answer is A assumes, B is on same network, but B assumes, A is on a different network
Given Information:
Computer A:
- IP Address: 203.197.2.53
- Subnet Mask: 255.255.128.0
Computer B:
- IP Address: 203.197.75.201
- Subnet Mask: 255.255.192.0
Step 1: Calculate the Network Address for A
1. Convert the Subnet Mask to Binary:
- Subnet Mask A: 255.255.128.0
- In binary: 11111111.11111111.10000000.00000000
2. Convert the IP Address to Binary:
- IP Address A: 203.197.2.53
- In binary: 11001011.11000101.00000010.00110101
3. Perform Bitwise AND:
- Network Address A:
Step 2: Calculate the Network Address for B
1. Convert the Subnet Mask to Binary:
- Subnet Mask B: 255.255.192.0
- In binary: 11111111.11111111.11000000.00000000
2. Convert the IP Address to Binary:
- IP Address B: 203.197.75.201
- In binary: 11001011.11000101.01001011.11001001
3. Perform Bitwise AND:
- Network Address B:
Summary of Network Addresses:
- Network Address A: 203.197.0.0
- Network Address B: 203.197.64.0
Step 3: Determine Network Assumptions
For Computer A (203.197.2.53):
- It calculates its network address as 203.197.0.0.
- It considers Computer B (203.197.75.201) as being on the same network if the IP falls within the same network address range.
For Computer B (203.197.75.201):
- It calculates its network address as 203.197.64.0.
- Since 203.197.2.53 does not fall within the range of 203.197.64.0, it assumes that A is on a different network.
Conclusion
- Computer A assumes that Computer B is on the same network.
- Computer B assumes that Computer A is on a different network.
Thus, the correct option is indeed: 3) A assumes B is on the same network, but B assumes A is on a different network.
Q83: A vector processor with 16 lanes can perform an operation on 1024 elements with each operation taking 5 clock cycles. How many cycles are needed to complete the operation?
(a) 64
(b) 80
(c) 100
(d) 128
Ans: A
Sol: The correct answer is 64
1. Vector processors can perform operations on multiple data elements simultaneously. In this case, the processor has 16 lanes, meaning it can operate on 16 elements in parallel in each clock cycle.
2. You need to process a total of 1024 elements.
3. The number of cycles required to process these 1024 elements is determined by how many sets of 16 elements can be processed in sequence. So:
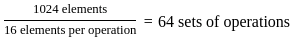
4. Each set of operations (on 16 elements) takes 5 clock cycles.
5. But since the processor can operate on 16 elements in parallel, all 16 elements are processed simultaneously within those 5 cycles, regardless of how many total operations are performed. Hence, 5 clock cycles are needed per set of elements, and only one set of 5 cycles is required for each of the 64 groups of elements.
Therefore, the total clock cycles needed to complete the operation across all elements is: 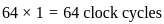
So the correct answer is 64, as only 64 sets of operations (each taking 5 cycles) are necessary to cover all the 1024 elements.
Q84: Arrange the following steps in a proper sequence for the process of training a neural network.
(A) Weight initialization
(B) Feed forward
(C) Back Propagation
(D) Loss Calculation
(E) Weight Update
Choose the correct answer from the options given below:
(a) (A), (B), (D), (C), (E)
(b) (D), (B), (A), (C), (E)
(c) (A), (C), (D), (B), (E)
(d) (E), (C), (B), (D), (A)
Ans: A
Sol: The correct answer is (A), (B), (D), (C), (E).
- Weight Initialization: This is the first step in training a neural network. It involves setting the initial weights for the network, which can be done randomly or using some heuristic.
- Feed Forward: Once the weights are initialized, the input data is passed through the network to generate an output. This process is called feed forward.
- Loss Calculation: After the feed forward step, the loss (or error) is calculated by comparing the network's output with the actual target values. This loss quantifies how well the network is performing.
- Back Propagation: In this step, the error calculated in the previous step is propagated back through the network to update the weights. This is done using the gradient descent algorithm to minimize the loss.
- Weight Update: Finally, the weights are updated based on the gradients computed during back propagation. This completes one iteration of training.
Thus the correct answer is (A), (B), (D), (C), (E).
Other Related Points
- The process of training a neural network is iterative and involves multiple passes through these steps. Each pass is known as an epoch. With each epoch, the network's performance typically improves as the weights are fine-tuned.
- Proper weight initialization is crucial as poor initialization can lead to slow convergence or getting stuck in local minima.
- The choice of loss function and optimization algorithm can significantly impact the training process and the final performance of the neural network.
Q85: 40 software professionals were interviewed for a job. 25 knew PYTHON 20 knew JAVA and 7 knew neither language. How many knew both languages?
(a) 12
(b) 53
(c) 10
(d) 88
Ans: A
Sol: Solution:
Let’s break down the problem step by step:
- Total number of software professionals: 40
- Number of professionals who knew PYTHON: 25
- Number of professionals who knew JAVA: 20
- Number of professionals who knew neither language: 7
So, the number of professionals who knew either PYTHON or JAVA or both is: 40 - 7 = 33
Now, let’s use the formula for the union of two sets:
Substitute the known values:
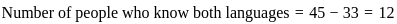
Q86: Which of the following are TRUE about constructors in C++?
(A) A constructor can be overloaded.
(B) A constructor does not have a return type.
(C) A constructor must be declared as a friend function.
(D) A constructor is called when an object is destroyed.
Choose the correct answer from the options given below:
(a) (B), (C), (D) Only
(b) (B), (C) Only
(c) (A), (B), (C) Only
(d) (A), (B) Only
Ans: D
Sol: The correct answer is 4)(A), (B) Only
(A) A constructor can be overloaded. -
- This statement is CORRECT. In C++, constructors can be overloaded by defining multiple constructors with different sets of parameters.
(B) A constructor does not have a return type. -
- This statement is CORRECT. Constructors do not have a return type, not even void. They are special member functions that initialize objects.
(C) A constructor must be declared as a friend function. -
- This statement is NOT CORRECT. A constructor is a member function of the class it constructs, and it cannot be declared as a friend function.
(D) A constructor is called when an object is destroyed. -
- This statement is NOT CORRECT. A destructor, not a constructor, is called when an object is destroyed.
Q87: A graph G with number of vertices greater and equal than three i.e. (n ≥ 3) is a Hamiltonian graph, if the degree of each vertex is greater and equal to...
(a) Equal to number of vertices
(b) Double of number of vertices
(c) Half of number of vertices
(d) Four times of number of vertices
Ans: C
Sol: The correct answer is Half of number of vertices
- In graph theory, a graph G with n vertices (where
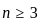 ) is known to be Hamiltonian if it contains a Hamiltonian cycle, which is a cycle that visits every vertex exactly once and returns to the starting vertex.
) is known to be Hamiltonian if it contains a Hamiltonian cycle, which is a cycle that visits every vertex exactly once and returns to the starting vertex. - According to Dirac's theorem, a sufficient condition for a graph to be Hamiltonian is that the degree of each vertex is at least half of the number of vertices:
Correct Condition:
- Each vertex's degree
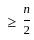 , where n is the number of vertices.
, where n is the number of vertices.
Thus, the correct answer is: 3) Half of number of vertices
Q88: Match List - I with List - II.
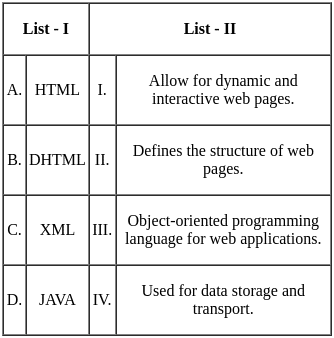
Choose the correct answer from the options given below:
(a) (A) - (I), (B) - (III), (C) - (II), (D) - (IV)
(b) (A) - (II), (B) - (III), (C) - (IV), (D) - (I)
(c) (A) - (II), (B) - (I), (C) - (IV), (D) - (III)
(d) (A) - (III), (B) - (I), (C) - (IV), (D) - (II)
Ans: C
Sol: The correct answer is (A) - (II), (B) - (I), (C) - (IV), (D) - (III)
HTML:
- HTML (HyperText Markup Language) defines the structure of web pages. It is used to create and design web pages by structuring content and layout. So, A matches with II.
DHTML:
- DHTML (Dynamic HTML) allows for dynamic and interactive web pages. It is not a language but a collection of technologies used together to create interactive and animated websites by using a combination of HTML, CSS, and JavaScript. So, B matches with I.
XML:
- XML (eXtensible Markup Language) is used for data storage and transport. It is designed to store and transport data, with a focus on simplicity, generality, and usability across the Internet. So, C matches with IV.
JAVA:
- JAVA is an object-oriented programming language used for web applications among many other types of applications. It is known for its portability across platforms and robust performance. So, D matches with III.
Therefore, the correct option is (A) - (II), (B) - (I), (C) - (IV), (D) - (III). So, the correct option is 3).
Q89: What will be the output of the following C code?
#include <stdio. h>
void main()
{
int arr[5] = {10, 20, 30, 40, 50};
int *p = (int*) (&arr + 1);
printf("%d %d", *(arr + 1), *(p - 1));
}
(a) 10 50
(b) 20 50
(c) 30 40
(d) 20 40
Ans: B
Sol: The correct answer is 20 50
Concept:
In C, the array `arr` is a contiguous block of memory. When we use the expression `&arr + 1`, it points to the address just past the end of the array. By casting this to an integer pointer and subtracting one, we get the address of the last element of the array.
Consider the given C code:
#include < stdio. h > void main() { int arr[5] = {10, 20, 30, 40, 50}; int *p = (int*) (&arr + 1); printf("%d %d", *(arr + 1), *(p - 1)); }
1. `int arr[5] = {10, 20, 30, 40, 50};` initializes an array of 5 integers.
2. `int *p = (int*) (&arr + 1);` - `&arr` gives the address of the entire array `arr`. - `&arr + 1` points to the memory address just past the end of the array. - Casting this to `(int*)` and then subtracting one gets us the address of the last element in the array.
3. `printf("%d %d", *(arr + 1), *(p - 1));` - `*(arr + 1)` fetches the value at the index `1` of the array, which is `20`. - `*(p - 1)` fetches the value just before the address `p`, which is the last element of the array, `50`.
So, the output of the program will be `20 50`.
Hence the correct answer is Option 2: 20 50.
Q90: Consider the following C code: .
#include <stdio.h>
int temp = 0;
int fun(int x, int y) {
int z;
temp++;
if (y == 3) return(x * x * x);
else {
z = fun(x, y / 3);
return(z * z * z);
}
}
int main() {
fun(4, 81);
printf("%d", temp);
return 0;
}
What will be the output of the above code ?
(a) 3
(b) 4
(c) 5
(d) 6
Ans: B
Sol: The correct answer is 4
Concept:
This problem involves understanding recursion in C and how global variables are affected by recursive function calls. The function `fun` is a recursive function that increments a global variable `temp` each time it is called. The recursion continues until `y` is no longer divisible by 3, at which point the function returns a value and the recursion unwinds.
Let's break down the code step by step:
#include int temp = 0; int fun(int x, int y) { int z; temp++; if (y == 3) return(x * x * x); else { z = fun(x, y / 3); return(z * z * z); } } int main() { fun(4, 81); printf("%d", temp); return 0; }
1. `fun(4, 81)` is called.
2. `temp` is incremented to 1. Since `y` (81) is not 3, the function calls `fun(4, 81 / 3)` i.e., `fun(4, 27)`.
3. `temp` is incremented to 2. Since `y` (27) is not 3, the function calls `fun(4, 27 / 3)` i.e., `fun(4, 9)`.
4. `temp` is incremented to 3. Since `y` (9) is not 3, the function calls `fun(4, 9 / 3)` i.e., `fun(4, 3)`.
5. `temp` is incremented to 4. Now, since `y` (3) is equal to 3, the function returns `4 * 4 * 4` which is 64.
6. This return value (64) is then cubed at each level of recursion as it unwinds, but these return values do not affect the global `temp` variable.
The total number of times `fun` is called before reaching the base case is 4. Therefore, the value of `temp` is 4.
Hence the correct answer is 2) 4.
Q91: Read the below passage and answer the questions.
Artificial Neural Networks (ANNs) are computational models inspired by the human brain's neural networks. They consist of interconnected nodes, or neurons, organized into layers: an input layer, one or more hidden layers and an output layer. Each connection between neurons has a weight that adjusts as learning progresses allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of Artificial Intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Artificial Neural Networks (ANNs) are inspired by:
(a) Quantum mechanics
(b) Human brain's neural network
(c) Computer Hardware architecture
(d) Genetic algorithm
Ans: B
Sol: The correct answer is Human brain's neural network.
- Artificial Neural Networks (ANNs) are computational models that are inspired by the neural networks of the human brain.
- These models consist of interconnected nodes, or neurons, organized into layers including input layer, hidden layers, and output layer.
- Each connection between neurons has a weight that adjusts as learning progresses, allowing the network to adopt and improve its performance.
Other Related Points
- Quantum mechanics: This is a fundamental theory in physics that describes nature at the smallest scales of energy levels of atoms and subatomic particles. It is not related to the inspiration behind ANNs.
- Computer Hardware Architecture: This refers to the design and organization of a computer's fundamental operational structure. While it is crucial for running ANNs, it is not the inspiration behind them.
- Genetic Algorithm: This is an optimization technique based on the principles of natural selection and genetics. It is used in machine learning but is not the inspiration for ANNs.
Q92: Read the below passage and answer the questions.
Artificial Neural Networks (ANNs) are computational models inspired by the human brain's neural networks. They consist of interconnected nodes, or neurons, organized into layers: an input layer, one or more hidden layers and an output layer. Each connection between neurons has a weight that adjusts as learning progresses allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of Artificial Intelligence by providing solutions to complex problems that traditional algorithms struggle with.
What is the role of Back Propagation Algorithm?
(a) To reduce error
(b) To secure network
(c) To control speed of data
(d) To add different layers
Ans: A
Sol: The correct answer is To reduce error.
- Back Propagation Algorithm is a training algorithm used in artificial neural networks.
- The primary role of back propagation is to minimize the error by adjusting the weights of the connections between neurons.
- This process involves calculating the gradient of the loss function with respect to each weight by the chain rule, iteratively updating the weights to reduce the error.
Other Related Points
- To secure network: This is not the role of back propagation. Network security involves protecting data and resources from unauthorized access, which is not the function of the back propagation algorithm.
- To control speed of data: Controlling the speed of data is related to network bandwidth and latency, not to the back propagation algorithm, which focuses on minimizing error in neural networks.
- To add different layers: Adding layers to a neural network is a design decision made before training begins. Back propagation works within the existing network structure to adjust weights and reduce error.
Q93: Read the below passage and answer the questions.
Artificial Neural Networks (ANNs) are computational models inspired by the human brain's neural networks. They consist of interconnected nodes, or neurons, organized into layers: an input layer, one or more hidden layers and an output layer. Each connection between neurons has a weight that adjusts as learning progresses allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of Artificial Intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Which of the following layers may be more than one in number?
(a) Input layer
(b) Hidden layer
(c) Output layer
(d) Physical layer
Ans: B
Sol: The correct answer is Hidden layer.
- Hidden layers in Artificial Neural Networks (ANNs) can be more than one in number. These layers are crucial for the network's ability to learn and represent complex patterns and relationships in the data.
- The passage mentions that ANNs consist of an input layer, one or more hidden layers, and an output layer. This indicates that while input and output layer are singular, there can be multiple hidden layers.
Other Related Points
- Input layer: This is the first layer of the network that receives the input data. There is only one input layer in an ANN.
- Output layer: This is the final layer that produces the output of the network. There is only one output layer in an ANN.
- Physical layer: This term is not relevant in the context of Artificial Neural Networks. It is typically used in the context of networking and communication systems.
Q94: Read the below passage and answer the questions.
Artificial Neural Networks (ANNs) are computational models inspired by the human brain's neural networks. They consist of interconnected nodes, or neurons, organized into layers: an input layer, one or more hidden layers and an output layer. Each connection between neurons has a weight that adjusts as learning progresses allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of Artificial Intelligence by providing solutions to complex problems that traditional algorithms struggle with.
What is the role of weights in an ANN?
(a) To store data
(b) To adjust and improve network performance
(c) To control the speed
(d) To secure the network
Ans: B
Sol: The correct answer is To adjust and improve network performance.
- Weights in an Artificial Neural Network (ANN) are used to adjust and improve the network's performance.
- As the network learns, these weights are modified to minimize the error in the output.
- This adjustment process is a key part of training algorithms like backpropagation, which help the ANN recognize patterns and make accurate predictions or classifications.
Other Related Points
- To store data: This is incorrect. Weights do not store data but rather determine how input signals are transformed as they pass through the network.
- To control the speed: This is incorrect. Weights do not control the speed of the network; they adjust the influence of each neuron on the next layer.
- To secure the network: This is incorrect. Weights are not related to the security of the network.
Q95: Read the below passage and answer the questions.
Artificial Neural Networks (ANNs) are computational models inspired by the human brain's neural networks. They consist of interconnected nodes, or neurons, organized into layers: an input layer, one or more hidden layers and an output layer. Each connection between neurons has a weight that adjusts as learning progresses allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of Artificial Intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Which of the following is/are the application area(s) of ANN?
(A) Natural Language Processing
(B) Image Processing
(C) Pattern Recognition
(D) Speech Recognition
Choose the correct answer from the options given below:
(a) (A) and (B) Only
(b) (B) and (C) Only
(c) (A), (B) and (C) Only
(d) (A), (B), (C) and (D)
Ans: D
Sol: The correct answer is (A), (B), (C) and (D).
Artificial Neural Networks (ANNs) are particularly effective in recognizing patterns, making them valuable for tasks such as image and speech recognition, natural language processing, and predictive analytics.
All of the above areas are applications of Artificial Neural Networks (ANNs). Here's why:
(A) Natural Language Processing (NLP): ANNs are widely used in NLP tasks such as machine translation, sentiment analysis, and text generation.
(B) Image Processing: ANNs, particularly convolutional neural networks (CNNs), are heavily used in image classification, object detection, and image recognition tasks.
(C) Pattern Recognition: ANNs are designed to recognize patterns in data and are used in applications like handwriting recognition and biometric identification.
(D) Speech Recognition: ANNs, especially recurrent neural networks (RNNs) and long short-term memory (LSTM) networks, are used in speech-to-text systems and voice recognition applications.
Therefore, all of the options (A, B, C, and D) are correct applications of ANNs.
Q96: Read the below passage and answer the questions.
The Banker's Algorithm is a critical deadlock avoidance method in operating systems, designed to facilitate resource allocation without causing deadlock. It operates by maintaining information about the maximum resources. Each process may require, the current allocated resources and the available resources in the system. The algorithm checks each resource request to determine, if granting it would leave the system in a safe state, meaning that there is always a sequence in which all processes can complete their execution without getting stuck due to resource unavailability. Each process must specify its maximum demand for each resource type before it starts execution. When a process requests additional resources, the algorithm checks if granting the request will keep the system in a safe state. If so, the resources are allocated otherwise the process must wait until its request can be safely fulfilled.
What is the significance of the Banker's algorithm in terms of resource management ?
(a) It enures that all processes can finish their execution without deadlock.
(b) It eliminates the need for processes to request resources.
(c) It accelerates the execution of critical sections in processes.
(d) It minimizes the number of context switches between processes.
Ans: A
Sol: The correct answer is It ensures that all processes can finish their execution without deadlock.
- The Banker's Algorithm is a deadlock avoidance method used in operating systems to ensure that resource allocation is done in such a way that the system remains in a safe state.
- It maintains information about the maximum resources each process may require, the current allocated resources, and the available resources in the system.
- The algorithm checks each resource request to determine if granting it would leave the system in a safe state, meaning that there is always a sequence in which all processes can complete their execution without getting stuck due to resource unavailability.
- By ensuring a safe state, the algorithm prevents deadlock, which is a situation where processes are unable to proceed because each is waiting for resources held by others.
Other Related Points
- Option 2: It eliminates the need for processes to request resources. This is incorrect because the Banker's Algorithm does not eliminate the need for resource requests; instead, it manages these requests to avoid deadlock.
- Option 3: It accelerates the execution of critical sections in processes. This is incorrect because the primary goal of the Banker's Algorithm is to avoid deadlock, not to accelerate execution of critical sections.
- Option 4: It minimizes the number of context switches between processes. This is incorrect because the algorithm focuses on resource allocation and deadlock avoidance, not on minimizing context switches.
Q97: Read the below passage and answer the questions.
The Banker's Algorithm is a critical deadlock avoidance method in operating systems, designed to facilitate resource allocation without causing deadlock. It operates by maintaining information about the maximum resources. Each process may require, the current allocated resources and the available resources in the system. The algorithm checks each resource request to determine, if granting it would leave the system in a safe state, meaning that there is always a sequence in which all processes can complete their execution without getting stuck due to resource unavailability. Each process must specify its maximum demand for each resource type before it starts execution. When a process requests additional resources, the algorithm checks if granting the request will keep the system in a safe state. If so, the resources are allocated otherwise the process must wait until its request can be safely fulfilled.
What is the primary goal of the Banker's Algorithm?
(a) To allocate resources optimally
(b) To prevent processes from requesting resources
(c) To detect and recover from deadlocks
(d) To maximise CPU utilization
Ans: A
Sol: The correct answer is To allocate resources optimally
The primary goal of the Banker's Algorithm is to avoid deadlock by ensuring that resources are allocated in such a way that the system remains in a safe state, meaning that all processes can complete their execution without getting stuck due to resource unavailability. It checks whether granting a resource request will leave the system in a safe state before allocating resources.
Therefore, the focus is on optimal and safe resource allocation to prevent deadlock, not on detecting or recovering from deadlocks, preventing requests, or maximizing CPU utilization.
Q98: Read the below passage and answer the questions.
The Banker's Algorithm is a critical deadlock avoidance method in operating systems, designed to facilitate resource allocation without causing deadlock. It operates by maintaining information about the maximum resources. Each process may require, the current allocated resources and the available resources in the system. The algorithm checks each resource request to determine, if granting it would leave the system in a safe state, meaning that there is always a sequence in which all processes can complete their execution without getting stuck due to resource unavailability. Each process must specify its maximum demand for each resource type before it starts execution. When a process requests additional resources, the algorithm checks if granting the request will keep the system in a safe state. If so, the resources are allocated otherwise the process must wait until its request can be safely fulfilled.
What information is used to determine if a resource request can be granted ?
(a) Available resources and current allocation of each process
(b) CPU utilization of each process
(c) Number of processes waiting for resources
(d) Arrival time of each process
Ans: A
Sol: The correct answer is Available resources and current allocation of each process.
- The Banker's Algorithm is used for deadlock avoidance in operating systems by ensuring that resource allocation does not leave the system in an unsafe state.
- To determine if a resource request can be granted, the algorithm checks the available resources and the current allocation of each process, along with the maximum demand of each process.
- If granting the request keeps the system in a safe state, the resources are allocated to the process; otherwise, the process must wait.
Other Related Points
- CPU utilization of each process: While CPU utilization is important for scheduling and performance monitoring, it is not directly used in the Banker's Algorithm for resource allocation decisions.
- Number of processes waiting for resources: This information can be useful for understanding the system's state but is not directly used in the Banker's Algorithm to decide if a request can be granted.
- Arrival time of each process: Arrival time is relevant for scheduling algorithms like First-Come-First-Served (FCFS) but not for the Banker's Algorithm, which focuses on resource allocation and safety.
Q99: Read the below passage and answer the questions.
The Banker's Algorithm is a critical deadlock avoidance method in operating systems, designed to facilitate resource allocation without causing deadlock. It operates by maintaining information about the maximum resources. Each process may require, the current allocated resources and the available resources in the system. The algorithm checks each resource request to determine, if granting it would leave the system in a safe state, meaning that there is always a sequence in which all processes can complete their execution without getting stuck due to resource unavailability. Each process must specify its maximum demand for each resource type before it starts execution. When a process requests additional resources, the algorithm checks if granting the request will keep the system in a safe state. If so, the resources are allocated otherwise the process must wait until its request can be safely fulfilled.
Which data structure does the Banker's Algorithm use to maintain the state of available, maximum and allocated resources ?
(a) Priority Queue
(b) Hash table
(c) Wait-for-Graph
(d) Matrices and Vectors
Ans: D
Sol: The correct answer is Matrices and Vectors.
- The Banker's Algorithm uses matrices and vectors to keep track of the state of the system, including available resources, maximum resources required by each process, and currently allocated resources.
- The matrices and vectors help in determining whether granting a resource request will keep the system in a safe state.
- Each process must specify its maximum demand for each resource type before it starts execution.
- When a process requests additional resources, the algorithm checks if granting the request will keep the system in a safe state using these matrices and vectors.
Other Related Points
- Priority Queue: A priority queue is not suitable for maintaining the state of resources in the Banker's Algorithm because it is used for scheduling tasks based on priority rather than tracking resource allocation.
- Hash Table: While a hash table offers efficient lookups, it is not used in the Banker's Algorithm as it does not provide the necessary structure for determining safe states through resource allocation matrices.
- Wait-for-Graph: A wait-for-graph is used in deadlock detection, not in the Banker's Algorithm. It represents processes and their resource dependencies but does not maintain resource allocation states as required by the Banker's Algorithm.
Q100: Read the below passage and answer the questions.
The Banker's Algorithm is a critical deadlock avoidance method in operating systems, designed to facilitate resource allocation without causing deadlock. It operates by maintaining information about the maximum resources. Each process may require, the current allocated resources and the available resources in the system. The algorithm checks each resource request to determine, if granting it would leave the system in a safe state, meaning that there is always a sequence in which all processes can complete their execution without getting stuck due to resource unavailability. Each process must specify its maximum demand for each resource type before it starts execution. When a process requests additional resources, the algorithm checks if granting the request will keep the system in a safe state. If so, the resources are allocated otherwise the process must wait until its request can be safely fulfilled.
Which of the following is NOT a requirement for Banker's algorithm to grant a resource request?
(a) The requested resources must be available.
(b) The system must be in a safe state after granting the request.
(c) The request must not exceed the maximum resources the process can request.
(d) The process must be the only one requesting resources.
Ans: D
Sol: The correct answer is The process must be the only one requesting resources..
- The Banker's Algorithm is a deadlock avoidance strategy used in operating systems to ensure that resource allocation does not lead to a deadlock situation.
- For the algorithm to grant a resource request, it must ensure that the requested resources are available.
- The system must remain in a safe state after granting the request, meaning there should be a sequence in which all processes can complete without resource deadlocks.
- The request should not exceed the maximum resources that the process has declared it may need.
- It is not necessary that the process must be the only one requesting resources. This is not a requirement for the Banker's Algorithm to function correctly.
Other Related Points
- Option 1: The requested resources must be available. This is crucial for the Banker's Algorithm to proceed with the request. If the resources are not available, the process must wait.
- Option 2: The system must be in a safe state after granting the request. This ensures that there is a sequence of processes that can complete without causing a deadlock.
- Option 3: The request must not exceed the maximum resources the process can request. This ensures that a process does not ask for more resources than it initially declared it might need.
- Option 4: The process must be the only one requesting resources. This is not a requirement. Multiple processes can request resources simultaneously, and the Banker's Algorithm will check each request independently to ensure system safety.
FAQs on UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 - UGC NET Past Year Papers
| 1. What is the UGC NET Paper 2 in Computer Science about? |  |
| 2. How is the UGC NET Computer Science exam structured? | |
| 3. What are the eligibility criteria for appearing in the UGC NET Computer Science exam? | |
| 4. What resources are recommended for preparing for the UGC NET Computer Science exam? | |
| 5. How can candidates effectively manage their time during the UGC NET Computer Science exam? | |



Viva Questions
,MCQs
,UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 | UGC NET Past Year Papers
,Free
,Important questions
,Semester Notes
,ppt
,video lectures
,Objective type Questions
,Extra Questions
,mock tests for examination
,past year papers
,Summary
,shortcuts and tricks
,UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 | UGC NET Past Year Papers
,Sample Paper
,practice quizzes
,UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 | UGC NET Past Year Papers
,Previous Year Questions with Solutions
,study material
,Exam
;






UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 Free PDF Download
Importance of UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1
UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 Notes
UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 UGC NET Questions
Study UGC NET Paper 2: Computer Science 23rd August 2024 Shift 1 on the App
|
© EduRev
|
Education Revolution
|



|





