Natural Language Processing Chapter Notes PDF Download

What do you mean by natural languages processing?
Natural Language Processing, or NLP, is the subfield of AI that is focused on enabling computers to understand and process human languages. Natural Language Processing helps machines to understand and interpret human language and operate accordingly. Natural Language are governed by set rules that include syntax, lexicon, and semantics.
Why is NLP important?
Computers can only process electronic signals in the form of binary language. Natural Language Processing facilitates this conversion to digital form from the natural form. Thus, the whole purpose of NLP is to make communication between computer systems and humans possible.
Definition: Natural Language Processing, or NLP, is the sub-field of AI that is focused on enabling computers to analyse, understand and process human languages to derive meaningful information from human language.
Various applications of NLP in everyday life
Voice assistants: Natural language processing is used in voice assistants like Google Assistant, Siri, and Alexa. NLP helps to understand the spoken commands from the users, process the language, and provide some meaningful response. For example:
- Hey Google, set an alarm at 3.30 pm
- Hey Alexa, play some music
- Hey Siri, what’s the weather today.
Auto generated captions: Natural language processing can generate captions automatically; NLP can transcribe spoken words into written text and can enhance the viewing experience. YouTube, Google Meet, Hulu, and Netflix automatically generate captions for their content. For example:
- Auto-generated captions on YouTube and Google Meet.
Language translation: Natural Language Processing uses neural translation algorithms to translate from one language to another language. NLP is the backbone of many translation services like Google Translate. For example:
- Google Translate
Sentiment analysis: Sentiment analysis is a natural language processing technique that judge the emotion and the intent of the text. Sentiment analysis classifies text as positive, negative, or neutral. This technique is used for customer satisfaction and is used in business and in social media.
Text classification: Text classification plays an important role in natural language processing. NLP helps the computer to understand and organize large amounts of unstructured data. Text classification can filter the content, customer feedback, and recommendation system.
Keyword extraction: Keyword extraction is useful in search engine optimization; this feature helps to analyze and summarize large documents. It helps the machine to understand the most important words and phrases from the document.
Keyword Extraction Example
STEP – 1: Click on https://cloud.google.com/natural-language
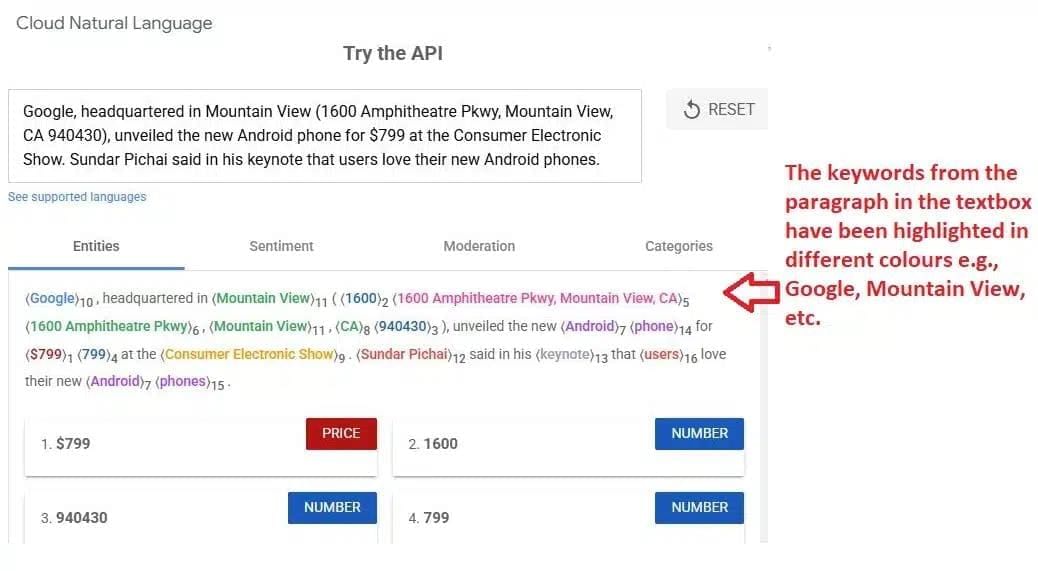
In the above image, you can see that Google Natural Language extracts the keywords from the paragraph. These keywords are used in the search engine to understand the most important words and phrases from the text.
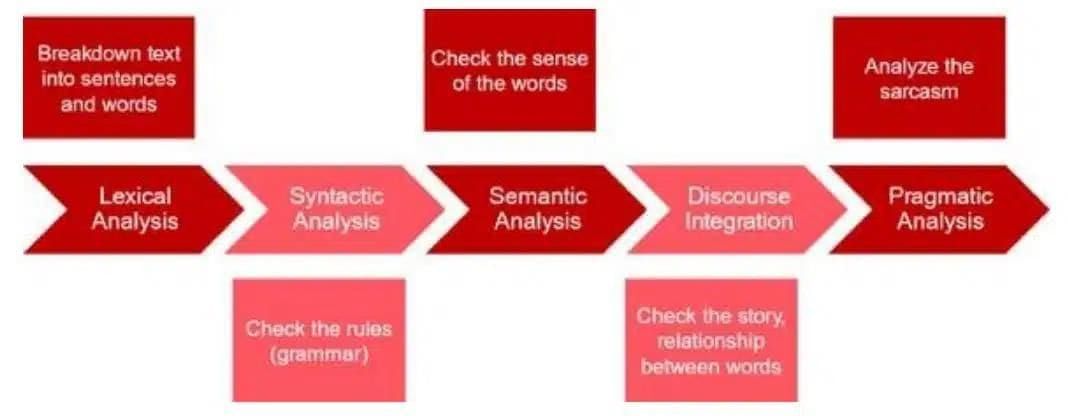
Stages of Natural Language Processing (NLP)
To process human language, machines rely on five different concepts like lexicon, syntax, semantics, discourse integration and pragmatic analysis. This stage works together to convert raw text to meaningful information.

Stage 1: Lexicon Analysis- Lexicon is the first phase in NLP. It works as a collection of words just like a word dictionary. Lexicon first analyzes the text and breaks it into paragraphs, sentences, and words. This is known as tokenization, which helps to identify important information about the words or sentences. Lexicon helps to identify the words, their parts of speech, synonyms, antonyms, and possible meanings in different languages. For example, the word bank can be used as a side of a river, or in a financial institution; the meaning of bank is different.
Example,

Stage 2: Syntactic Analysis- The second phase of NLP is syntactic analysis. Syntactic It is the process of checking the grammar of sentences and phrases. It forms a relationship among words and eliminates logically incorrect sentences. It has a set of rules that helps to check the grammatical errors in the sentences.
Example,

Stage 3: Semantic Analysis- The third phase of NLP is Semantics Analysis. Semantic analysis helps to find the meaning of words and sentences. It helps to identify the meaning behind the words or sentences that make some logical sense.
Example,

Stage 4: Discourse Integration- The fourth phase of NLP is discourse integration. Discourse integration examines how words, phrases, and sentences relate to each other within a text. It also finds the overall meaning of the sentences; it also tries to understand what the overall message convey in the text.
Example,

Stage 5: Pragmatic Analysis – The fifth phase of NLP is pragmatic analysis. In this phase, sentences are checked for their relevance in the real world. the machine wants to understand what the writer or speaker truly wants to convey, because in the human language, words have different meanings in different languages, and the machine wants to understand in what situation the message is conveyed and what the writer intends to convey in the message.
Example,

Summary of NLP?
What is chatbot?
One of the most common applications of Natural Language Processing is a chatbot. Chatbots use artificial intelligence and natural language processing to simulate human conversation through voice commands or text chats or both. There are a lot of chatbots available and many of them use the same approach.

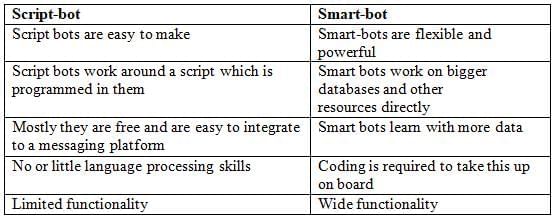
Differences between smart-bots and script-bots
The difference between smart-bots and script-bots are
What is text processing?
Text processing helps to transform the raw text into a machine-level format where the machine can understand and analyze easily.
Text Normalization technique used in NLP
Text normalization helps in cleaning up the textual data in such a way that it comes down to a level where its complexity is lower than the actual data. We undergo several steps to normalize the text to a lower level; normalization makes the sentence easier to understand by the machine.
1. Sentence Segmentation
Under sentence segmentation, the whole corpus is divided into sentences. Each sentence is taken as a different data so now the whole corpus gets reduced to sentences.
Example: Hello! How are you? I am fine.
Output:
- Hello!
- How are you?
- I am fine.
2. Tokenisation
In tokenisation each sentence is then further divided into tokens. Tokens is a term used for any word or number or special character occurring in a sentence. Under tokenisation, every word, number and special character is considered separately and each of them is now a separate token.
Example: I love my School!
Output:
- I
- love
- my
- School
- !
3. Removing Stopwords, Special Characters and Numbers
In this step, the tokens which are not necessary are removed from the token list. What can be the possible words which we might not require?
Example: Hello!!! How’s it going?
Output:
- Hello Hows it going
4. Converting text to a common case
After the stopwords removal, we convert the whole text into a similar case, preferably lower case. This ensures that the case-sensitivity of the machine does not consider same words as different just because of different cases.
Example: I Love my SCHOOL!
Output: i love my school!
5. Stemming
In this step, the remaining words are reduced to their root words. In other words, stemming is the process in which the affixes of words are removed and the words are converted to their base form.
Example: running, runs, runner
Output: run, run, run
6. Lemmatization
Stemming and lemmatization both are alternative processes to each other as the role of both the processes is same – removal of affixes. But the difference between both of them is that in lemmatization, the word we get after affix removal (also known as lemma) is a meaningful one.
Example: running, ran, better
Output: run, run, good
Bag of Word
Bag of Words is a Natural Language Processing model which helps in extracting features out of the text which can be helpful in machine learning algorithms. In bag of words, we get the occurrences of each word and construct the vocabulary for the corpus.
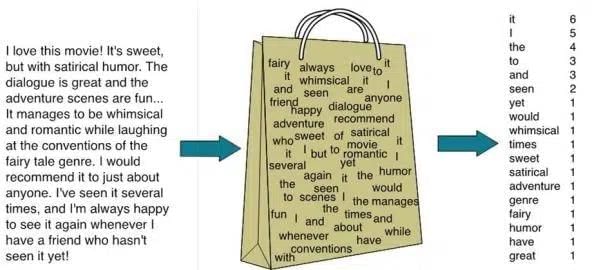
Here is the step-by-step approach to implement bag of words algorithm:
- Text Normalisation: Collect data and pre-process it
- Create Dictionary: Make a list of all the unique words occurring in the corpus. (Vocabulary)
- Create document vectors: For each document in the corpus, find out how many times the word from the unique list of words has occurred.
- Create document vectors for all the documents.
Example of Bag of Words
Step 1: Text Normalisation
- Sentence 1: I love my school.
- Sentence 2: My school is amazing!
Step 2: Create Dictionary
The unique words from both sentences:
I, love, my, school, is, amazing
Step 3: Create document vectors
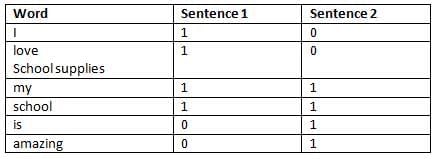
Final Bag of Word Vectors are
- Sentence 1: [1, 1, 1, 1, 0, 0]
- Sentence 2: [0, 0, 1, 1, 1, 1]
TF-IDF: Term Frequency & Inverse Document Frequency
TF-IDF is a statistical method used in natural language processing to retrieve the important word or unique word in a document, or you can say that TF-IDF helps to identify the most meaningful word in the document. TF-IDF combines two components: term frequency and inverse document frequency.
Term frequency
Term frequency is the frequency of a word in one document. Term frequency can easily be found from the document The formula of term frequency are –
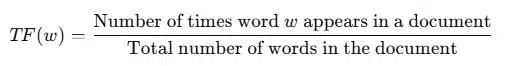
Inverse Document Frequency
Document Frequency is the number of documents in which the word occurs irrespective of how many times it has occurred in those documents.

Finally, the formula of TF-IDF for any word W becomes:
TFIDF(W) = TF(W) * log( IDF(W) )
Example of TF-IDF Calculation
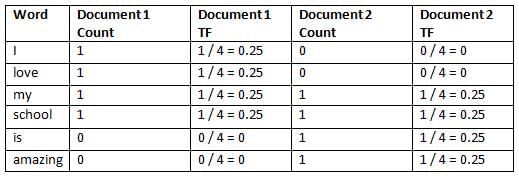
Step 1: Sample Documents
- Document 1: I love my school.
- Document 2: My school is amazing!
Step 2: Calculate TF
Formula for TF calculation are –
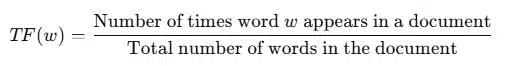
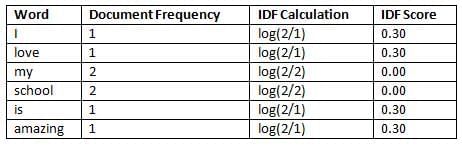
Step 3: Calculate IDF
Formula for IDF calculation are –

Step 4: Calculate TF-IDF Score
Formula for TF-IDF calculation are –
TFIDF(W) = TF(W) * log( IDF(W) )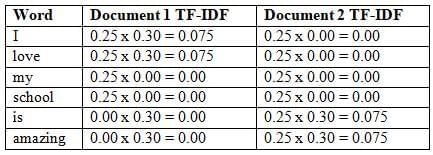
However, “my” and “school” have the lowest importance (TF-IDF = 0) because they appear in both documents, making them less unique.
FAQs on Natural Language Processing Chapter Notes
| 1. What are the main features of natural languages that make them unique? |  |
| 2. Why is Natural Language Processing (NLP) important in today's technology? | |
| 3. What are the different stages of natural language processing? | |
| 4. How does keyword extraction function in NLP? | |
| 5. What role do chatbots play in natural language processing? | |








Chapter Notes: Natural Language Processing Free PDF Download
Importance of Chapter Notes: Natural Language Processing
Chapter Notes: Natural Language Processing
Chapter Notes: Natural Language Processing Questions
Study Chapter Notes: Natural Language Processing on the App
|
© EduRev
|
Education Revolution
|



|





