Case-Based Questions: Evaluating Models

Q1. Identify which metric (Precision or Recall) is to be used in the following cases and why?
a) Email Spam Detection
Ans: Precision, Email, classifiers identify if the email is spam and have evolved into other categories such as social, advertisement, notifications, etc. Similar models are increasingly being used in messaging applications.
b) Cancer Diagnosis
Ans: Recall, The recall is the measure of our model correctly identifying True Positives. Thus, for all the patients who actually have Cancer, recall tells us how many we correctly identified as having a Cancer. The metrics Recall is generally used for unbalanced dataset when dealing with the False Negatives become important and the model needs to reduce the FNs as much as possible.
c) Legal Cases(Innocent until proven guilty)
Ans: Precision, The metrics Precision is generally used for unbalanced datasets when dealing with the False Positives become important, and the model needs to reduce the FPs as much as possible.
d) Fraud Detection
Ans: Recall, The recall is the measure of our model correctly identifying True Positives. Thus, for all the patients who actually have Cancer, recall tells us how many we correctly identified as having a Cancer. The metrics Recall is generally used for unbalanced dataset when dealing with the False Negatives become important and the model needs to reduce the FNs as much as possible.
e) Safe Content Filtering (like Kids YouTube)
Ans: Recall, The recall is the measure of our model correctly identifying True Positives. Thus, for all the patients who actually have Cancer, recall tells us how many we correctly identified as having a Cancer. The metrics Recall is generally used for unbalanced dataset when dealing with the False Negatives become important and the model needs to reduce the FNs as much as possible.
Q2. Examine the following case studies. Draw the confusion matrix and calculate metrics such as accuracy, precision, recall, and F1-score for each one of them.
a. Case Study 1:
A spam email detection system is used to classify emails as either spam (1) or not spam (0). Out of 1000 emails:
- True Positives(TP): 150 emails were correctly classified asspam.
- False Positives(FP): 50 emails were incorrectly classified asspam.
- True Negatives(TN): 750 emails were correctly classified as not spam.
- False Negatives(FN): 50 emails were incorrectly classified as not spam.
Ans:
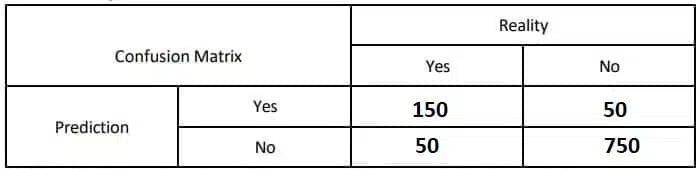
Accuracy=(TP+TN) / (TP+TN+FP+FN)
=(150+750)/(150+750+50+50)
=900/1000
=0.90
Precision=(TP/(TP+FP))100
=150/(150+50)
=150/200
=0.75
Recall=TP/(TP+FN)
=150/(150+50)
=150/200
=0.75
F1 Score = 2 * Precision * Recall / ( Precision + Recall )
=2 * 0.75 * 0.75 / (0.75+0.75)
=0.75
=75%
b. Case Study 2:
A credit scoring model is used to predict whether an applicant is likely to default on a loan (1) or not (0). Out of 1000 loan applicants:
- True Positives(TP): 90 applicants were correctly predicted to default on the loan.
- False Positives(FP): 40 applicants were incorrectly predicted to default on the loan.
- True Negatives(TN): 820 applicants were correctly predicted not to default on the loan.
- False Negatives (FN): 50 applicants were incorrectly predicted not to default on the loan.
Calculate metrics such as accuracy, precision, recall, and F1-score.
Ans:
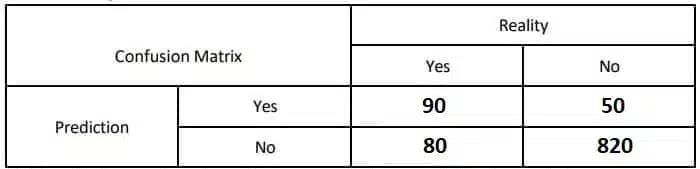
Accuracy=(TP+TN) / (TP+TN+FP+FN)
=(90+820)/(90+820+40+50)
=910/1000
=0.91
Precision=TP/(TP+FP)
=90/(90+40)
=90/130
=0.692
Recall=TP/(TP+FN)
=90/(90+50)
=90/140
=0.642
F1 Score = 2 * Precision * Recall / ( Precision + Recall )
=2 * 0.692 * 0.642 / (0.692+0.642)
=0.666
=66.6%
c. Case Study 3:
A fraud detection system is used to identify fraudulent transactions(1) from legitimate ones (0). Out of 1000 transactions:
- True Positives(TP): 80 transactions were correctly identified asfraudulent.
- False Positives(FP): 30 transactions were incorrectly identified asfraudulent.
- True Negatives(TN): 850 transactions were correctly identified aslegitimate.
- False Negatives(FN): 40 transactions were incorrectly identified aslegitimate.
Ans:
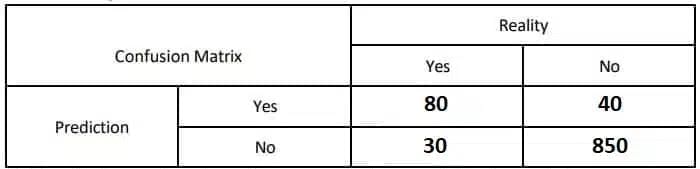
Accuracy=(TP+TN) / (TP+TN+FP+FN)
=(80+850)/(80+850+30+40)
=930/1000
=0.93
Precision=TP/(TP+FP)
=80/(80+30)
=80/110
=0.727
Recall=TP/(TP+FN)
=80/(80+40)
=80/120
=0.667
F1 Score = 2 * Precision * Recall / ( Precision + Recall )
=2 * 0.727 * 0.667 / (0.727+0.667)
=0.696
=69.6%
d. Case Study 4:
A medical diagnosis system is used to classify patients as having a certain disease (1) or not having it (0). Out of 1000 patients:
- True Positives(TP): 120 patients were correctly diagnosed with the disease.
- False Positives(FP): 20 patients were incorrectly diagnosed with the disease.
- True Negatives(TN): 800 patients were correctly diagnosed as not having the disease.
- False Negatives(FN): 60 patients were incorrectly diagnosed as not having the disease.
Ans:
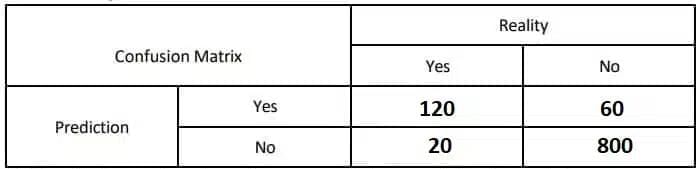
Accuracy=(TP+TN) / (TP+TN+FP+FN)
=(120+800)/(120+800+20+60)
=920/1000
=0.92
Precision=TP/(TP+FP)
=120/(120+20)
=120/140
=0.857
Recall=TP/(TP+FN)
=120/(120+60)
=120/180
=0.667
F1 Score = 2 * Precision * Recall / ( Precision + Recall )
=2 * 0.857 * 0.667 / (0.857+0.667)
=0.75
=75%
e. Case Study 5:
An inventory management system is used to predict whether a product will be out of stock (1) or not (0) in the next month. Out of 1000 products:
- True Positives (TP): 100 products were correctly predicted to be out of stock.
- False Positives (FP): 50 products were incorrectly predicted to be out of stock. True Negatives (TN): 800 products were correctly predicted not to be out of stock.
- True Negatives(TN): 800 products were correctly predicted not to be out of stock.
- False Negatives(FN): 50 products were incorrectly predicted not to be out of stock.
Ans:
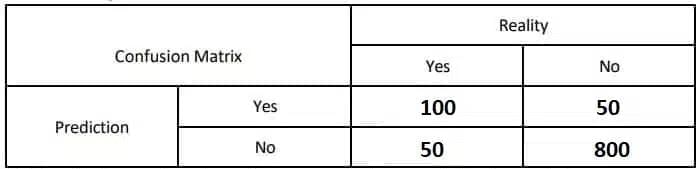
Accuracy=(TP+TN) / (TP+TN+FP+FN)
=(100+800)/(100+800+50+50)
=900/1000
=0.90
Precision=TP/(TP+FP)
=100/(100+50)
=100/150
=0.667
Recall=TP/(TP+FN)
=100/(100+50)
=100/150
=0.667
F1 Score = 2 * Precision * Recall / ( Precision + Recall )
=2 * 0.667 * 0.667 / (0.667+0.667)
=0.667
=66.7%
FAQs on Case-Based Questions: Evaluating Models
| 1. What is the importance of case-based questions in evaluating models? |  |
| 2. How can students effectively prepare for case-based questions on model evaluation? | |
| 3. What are some common types of models used in evaluations? | |
| 4. How do case studies help in understanding the strengths and weaknesses of different models? | |
| 5. What role does data play in the evaluation of models? | |



