
Best Study Material for Computer Science Engineering (CSE) Exam
Computer Science Engineering (CSE) Exam > Computer Science Engineering (CSE) Notes > Computer Architecture & Organisation (CAO) > Pipeline & Vector Processing
Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE) PDF Download
8086 Processor Family
The x86 organization has evolved dramatically over the years.
Register Organization :
The register organization includes the following types of registers (Table 3.1):
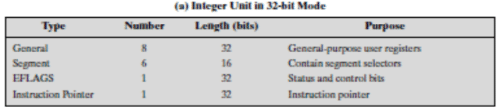


• General:
There are eight 32-bit general-purpose registers. These may be used for all types of x86 instructions; and some of these registers also serve special purposes. For example, string instructions use the contents of the ECX, ESI, and EDI registers as operands without having to reference these registers explicitly in the instruction.
• Segment:
The six 16-bit segment registers contain segment selectors, which index into segment tables, as discussed in Chapter 8. The code segment (CS) register references the segment containing the instruction being executed. The stack segment (SS) register references the segment containing a uservisible stack.The remaining segment registers (DS,ES,FS,GS) enable the user to reference up to four separate data segments at a time.
• Flags:
The 32-bit EFLAGS register contains condition codes and various mode bits. In 64-bit mode, this register is extended to 64 bits and referred to as RFLAGS. In the current architecture definition, the upper 32 bits of RFLAGS are unused.
• Instruction pointer:
Contains the address of the current instruction. There are also registers specifically devoted to the floating-point unit:
• Numeric:
Each register holds an extended-precision 80-bit floating-point number. There are eight registers that function as a stack, with push and pop operations available in the instruction set.
• Control:
The 16-bit control register contains bits that control the operation of the floating-point unit, including the type of rounding control; single, double, or extended precision; and bits to enable or disable various exception conditions.
• Status:
The 16-bit status register contains bits that reflect the current state of the floating-point unit, including a 3-bit pointer to the top of the stack; condition codes reporting the outcome of the last operation; and exception flags.
• Tag word:
This 16-bit register contains a 2-bit tag for each floating-point numeric register, which indicates the nature of the contents of the corresponding register. The four possible values are valid, zero, special (NaN, infinity, denormalized),and empty.
EFLAGS Register
The EFLAGS register (Figure 3.9) indicates the condition of the processor and helps to control its operation. It includes the six condition codes (carry, parity, auxiliary, zero, sign, overflow), which report the results of an integer operation. In addition, there are bits in the register that may be referred to as control bits:

• Trap flag (TF):
When set, causes an interrupt after the execution of each instruction. This is used for debugging.
• Interrupt enable flag (IF):
When set, the processor will recognize external interrupts.
• Direction flag (DF):
Determines whether string processing instructions increment or decrement the 16-bit half-registers SI and DI (for 16-bit operations) or the 32-bit registers ESI and EDI (for 32-bit operations).
• I/O privilege flag (IOPL):
When set, causes the processor to generate an exception on all accesses to I/O devices during protected-mode operation.
• Resume flag (RF): Allows the programmer to disable debug exceptions so that the instruction can be restarted after a debug exception without immediately causing another debug exception.
• Alignment check (AC): Activates if a word or doubleword is addressed on a nonword or nondoubleword boundary.
• Identification flag (ID):
If this bit can be set and cleared, then this processor supports the processorID instruction. This instruction provides information about the vendor, family, and model.
• Nested Task (NT)
flag indicates that the current task is nested within another task in protectedmode operation.
• Virtual Mode (VM)
bit allows the programmer to enable or disable virtual 8086 mode, which determines whether the processor runs as an 8086 machine.
• Virtual Interrupt Flag (VIF)
and Virtual Interrupt Pending (VIP) flag are used in a multitasking environment
Control Register
The x86 employs four control registers (register CR1 is unused) to control various aspects of processor operation . All of the registers except CR0 are either 32 bits or 64 bits long..The flags are are as follows:
• Protection Enable (PE):
Enable/disable protected mode of operation.
• Monitor Coprocessor (MP):
Only of interest when running programs from earlier machines on the x86; it relates to the presence of an arithmetic coprocessor.
• Emulation (EM):
Set when the processor does not have a floating-point unit, and causes an interrupt when an attempt is made to execute floating-point instructions.
• Task Switched (TS):
Indicates that the processor has switched tasks.
• Extension Type (ET):
Not used on the Pentium and later machines; used to indicate support of math coprocessor instructions on earlier machines.
• Numeric Error (NE):
Enables the standard mechanism for reporting floating-point errors on external bus lines.
• Write Protect (WP):
When this bit is clear, read-only user-level pages can be written by a supervisor process. This feature is useful for supporting process creation in some operating systems.
• Alignment Mask (AM):
Enables/disables alignment checking.
• Not Write Through (NW):
Selects mode of operation of the data cache. When this bit is set, the data cache is inhibited from cache write-through operations.
• Cache Disable (CD):
Enables/disables the internal cache fill mechanism.
• Paging (PG):
Enables/disables paging.
1. When paging is enabled, the CR2 and CR3 registers are valid.
2. The CR2 register holds the 32-bit linear address of the last page accessed before a page fault interrupt.
3. The leftmost 20 bits of CR3 hold the 20 most significant bits of the base address of the page directory; the remainder of the address contains zeros. The page-level cache disable (PCD) enables or disables the external cache, and the page-level writes transparent (PWT) bit controls write through in the external cache.
4. Nine additional control bits are defined in CR4:
• Virtual-8086 Mode Extension (VME):
Enables virtual interrupt flag in virtual-8086 mode.
• Protected-mode Virtual Interrupts (PVI):
Enables virtual interrupt flag in protected mode.
• Time Stamp Disable (TSD):
Disables the read from time stamp counter (RDTSC) instruction, which is used for debugging purposes.
• Debugging Extensions (DE):
Enables I/O breakpoints; this allows the processor to interrupt on I/O reads and writes.
• Page Size Extensions (PSE):
Enables large page sizes (2 or 4-MByte pages) when set; restricts pages to 4 KBytes when clear.
• Physical Address Extension (PAE):
Enables address lines A35 through A32 whenever a special new addressing mode, controlled by the PSE, is enabled.
• Machine Check Enable (MCE):
Enables the machine check interrupt, which occurs when a data parity error occurs during a read bus cycle or when a bus cycle is not successfully complete
• Page Global Enable (PGE):
Enables the use of global pages. When PGE = 1 and a task switch is performed, all of the TLB entries are flushed with the exception of those marked global.
• Performance Counter Enable(PCE):
Enables the Execution of the RDPMC (read performance counter) instruction at any privilege level.
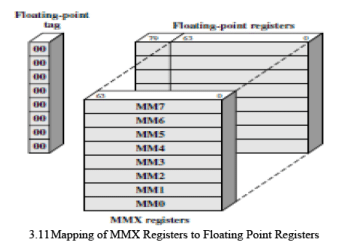
MMX Registers
The MMX instructions make use of 3-bit register address fields, so that eight MMX registers are supported. (Figure 3.11). The existing floating-point registers are used to store MMX values. Specifically, the low-order 64 bits (mantissa) of each floating-point register are used to form the eight MMX registers. Some key characteristics of the MMX use of these registers are as follows:
- Recall that the floating-point registers are treated as a stack for floating-point operations. For MMX operations, these same registers are accessed directly.
- The first time that an MMX instruction is executed after any floating-point operations, the FP tag word is marked valid. This reflects the change from stack operation to direct register addressing.
- The EMMS (Empty MMX State) instruction sets bits of the FP tag word to in dicate that all registers are empty. It is important that the programmer insert this instruction at the end of an MMX code block so that subsequent floating-point operations function properly.
- When a value is written to an MMX register, bits [79:64] of the corresponding FP register (sign and exponent bits) are set to all ones. This sets the value in the FP register to NaN (not a number) or infinity when viewed as a floating-point value. This ensures that an MMX data value will not look like a valid floating-point value.
The document Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE) is a part of the Computer Science Engineering (CSE) Course Computer Architecture & Organisation (CAO).
All you need of Computer Science Engineering (CSE) at this link: Computer Science Engineering (CSE)
|
20 videos|87 docs|48 tests
|




FAQs on Pipeline & Vector Processing - Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
| 1. What is pipeline processing? |  |
| 2. How does pipeline processing work? | |
Ans. Pipeline processing works by dividing the execution of instructions into several stages, such as fetch, decode, execute, and writeback. Each stage performs a specific operation on the instruction and passes it to the next stage. This allows multiple instructions to be in different stages of execution simultaneously, resulting in increased efficiency and faster processing.
| 3. What are the advantages of pipeline processing? | |
Ans. Pipeline processing offers several advantages, including:
- Increased throughput: By allowing multiple instructions to be processed simultaneously, pipeline processing improves the overall throughput of the system.
- Reduced latency: Instructions can be executed faster as they are divided into smaller stages and processed concurrently.
- Resource utilization: Pipeline processing maximizes the utilization of system resources by keeping them busy during the execution of multiple instructions.
- Simplified design: The modular nature of pipeline processing makes it easier to design and implement complex computer architectures.
| 4. What is vector processing? | |
Ans. Vector processing, also known as SIMD (Single Instruction, Multiple Data), is a type of parallel processing that involves performing the same operation on multiple data elements simultaneously. It utilizes vector registers to store and process large sets of data elements in a single instruction cycle, leading to significant speedup in certain types of computations.
| 5. How does vector processing differ from pipeline processing? | |
Ans. The main difference between vector processing and pipeline processing lies in the nature of the computations they handle. Pipeline processing focuses on dividing the execution of instructions into stages to improve efficiency, while vector processing focuses on parallel processing of large sets of data elements using a single instruction. In other words, pipeline processing optimizes instruction execution, whereas vector processing optimizes data processing.
About this Document

4.83/5
Rating

Apr 15, 2025
Last updated
Document Description: Pipeline & Vector Processing for Computer Science Engineering (CSE) 2025 is part of Computer Architecture & Organisation (CAO) preparation.
The notes and questions for Pipeline & Vector Processing have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Pipeline & Vector Processing covers topics
like and Pipeline & Vector Processing Example, for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Pipeline & Vector Processing.
Introduction of Pipeline & Vector Processing in English is available as part of our Computer Architecture & Organisation (CAO)
for Computer Science Engineering (CSE) & Pipeline & Vector Processing in Hindi for Computer Architecture & Organisation (CAO) course.
Download more important topics related with notes, lectures and mock test series for Computer Science Engineering (CSE)
Exam by signing up for free. Computer Science Engineering (CSE): Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
Description
Full syllabus notes, lecture & questions for Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE) - Computer Science Engineering (CSE) | Plus excerises question with solution to help you revise complete syllabus for Computer Architecture & Organisation (CAO) | Best notes, free PDF download
Information about Pipeline & Vector Processing
In this doc you can find the meaning of Pipeline & Vector Processing defined & explained in the simplest way possible. Besides explaining types of
Pipeline & Vector Processing theory, EduRev gives you an ample number of questions to practice Pipeline & Vector Processing tests, examples and also practice Computer Science Engineering (CSE)
tests
|
20 videos|87 docs|48 tests
|
Download as PDF

|
Explore Courses for Computer Science Engineering (CSE) exam
|
|
Related Searches
past year papers
,Summary
,Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,study material
,Important questions
,MCQs
,Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,mock tests for examination
,Viva Questions
,Exam
,Previous Year Questions with Solutions
,practice quizzes
,Sample Paper
,Pipeline & Vector Processing | Computer Architecture & Organisation (CAO) - Computer Science Engineering (CSE)
,ppt
,shortcuts and tricks
,Extra Questions
,Semester Notes
,Free
,Objective type Questions
,video lectures
;


Additional Information about Pipeline & Vector Processing for Computer Science Engineering (CSE) Preparation
Pipeline & Vector Processing Free PDF Download
The Pipeline & Vector Processing is an invaluable resource that delves deep into the core of the Computer Science Engineering (CSE) exam.
These study notes are curated by experts and cover all the essential topics and concepts, making your preparation more efficient and effective.
With the help of these notes, you can grasp complex subjects quickly, revise important points easily,
and reinforce your understanding of key concepts. The study notes are presented in a concise and easy-to-understand manner,
allowing you to optimize your learning process. Whether you're looking for best-recommended books, sample papers, study material,
or toppers' notes, this PDF has got you covered. Download the Pipeline & Vector Processing now and kickstart your journey towards success in the Computer Science Engineering (CSE) exam.
Importance of Pipeline & Vector Processing
The importance of Pipeline & Vector Processing cannot be overstated, especially for Computer Science Engineering (CSE) aspirants.
This document holds the key to success in the Computer Science Engineering (CSE) exam.
It offers a detailed understanding of the concept, providing invaluable insights into the topic.
By knowing the concepts well in advance, students can plan their preparation effectively.
Utilize this indispensable guide for a well-rounded preparation and achieve your desired results.
Pipeline & Vector Processing Notes
Pipeline & Vector Processing Notes offer in-depth insights into the specific topic to help you master it with ease.
This comprehensive document covers all aspects related to Pipeline & Vector Processing.
It includes detailed information about the exam syllabus, recommended books, and study materials for a well-rounded preparation.
Practice papers and question papers enable you to assess your progress effectively.
Additionally, the paper analysis provides valuable tips for tackling the exam strategically.
Access to Toppers' notes gives you an edge in understanding complex concepts.
Whether you're a beginner or aiming for advanced proficiency, Pipeline & Vector Processing Notes on EduRev are your ultimate resource for success.
Pipeline & Vector Processing Computer Science Engineering (CSE) Questions
The "Pipeline & Vector Processing Computer Science Engineering (CSE) Questions" guide is a valuable resource for all aspiring students preparing for the
Computer Science Engineering (CSE) exam. It focuses on providing a wide range of practice questions to help students gauge
their understanding of the exam topics. These questions cover the entire syllabus, ensuring comprehensive preparation.
The guide includes previous years' question papers for students to familiarize themselves with the exam's format and difficulty level.
Additionally, it offers subject-specific question banks, allowing students to focus on weak areas and improve their performance.
Study Pipeline & Vector Processing on the App
Students of Computer Science Engineering (CSE) can study Pipeline & Vector Processing alongwith tests & analysis from the EduRev app,
which will help them while preparing for their exam. Apart from the Pipeline & Vector Processing,
students can also utilize the EduRev App for other study materials such as previous year question papers, syllabus, important questions, etc.
The EduRev App will make your learning easier as you can access it from anywhere you want.
The content of Pipeline & Vector Processing is prepared as per the latest Computer Science Engineering (CSE) syllabus.
|
© EduRev
|
Education Revolution
|



|






Signup on EduRev and stay on top of your study goals
10M+ students crushing their study goals daily