Test: File Structures- 2 - Computer Science Engineering (CSE) MCQ
10 Questions MCQ Test - Test: File Structures- 2


B+ trees are preferred to binary trees in databases because
AB+ tree index is to be built on the Name attribute of the relation STUDENT. Assume that all student names are of length 8 bytes, disk blocks are of size 512 bytes, and index pointers are of size 4 bytes. Given this scenario, what would be the best choice of the degree (i.e. the number of pointers per node) of the B+ tree?
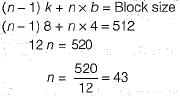
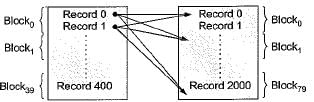
A database table T1 has 2000 records and occupies 80 disk blocks. Another table T2 has 400 records and occupies 20 disk blocks. These two tables have to be joined as per a specified join condition that needs-to be evaluated for every pair of records from these two tables. The memory buffer space available can hold exactly one block of records for T1 and one block of records for T2 simultaneously at any point in time. No index is available on either table.
Q. If Nested-loop join algorithm is employed to perform the join, with the most appropriate choice of table to be used in outer loop, the number of block accesses required for reading the data are
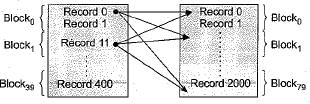
A database table T1 has 2000 records and occupies 80 disk blocks. Another table T2 has 400 records and occupies 20 disk blocks. These two tables have to be joined as per a specified join condition that needs-to be evaluated for every pair of records from these two tables. The memory buffer space available can hold exactly one block of records for T1 and one block of records for T2 simultaneously at any point in time. No index is available on either table.
Q. If, instead of Nested-loop join, Block nested-loop join is used, again with the most appropriate choice of table in the outer loop, the reduction in number of block accesses required for reading the data will be
A clustering index is defined on the fields which are of type
Consider a file of 16384 records. Each record is 32 bytes long and its key field is of size 6 bytes. The file is ordered on a non-key field, and the file organization is unspanned. The file is stored in a file system with block size 1024 bytes, and the size of a block pointer is 10 bytes. If the secondary index is built on the key field of the file, and a multilevel index scheme is used to store the secondary index, the number of first- level and second-level blocks in the multilevel index are respectively
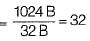
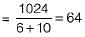
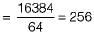
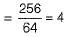




Important Questions for File Structures- 2
File Structures- 2 MCQs with Answers
Online Tests for File Structures- 2
|
© EduRev
|
Education Revolution
|



|








