Test: Data Analysis - 2 - SAT MCQ
15 Questions MCQ Test - Test: Data Analysis - 2

Comprehension:
Directions: Consider the following data and answer questions:
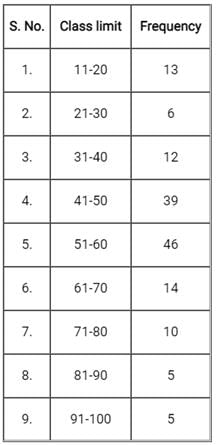
Which one of the following is the mode value for the given data set?
Which one of the following is the mode value for the given data set?
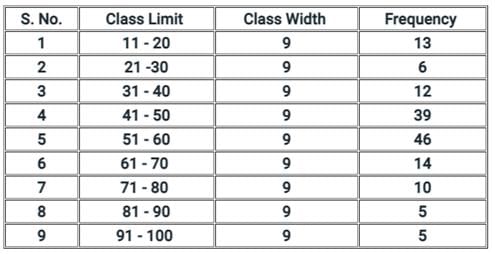
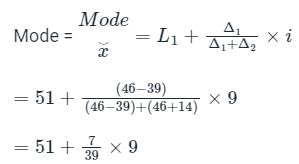
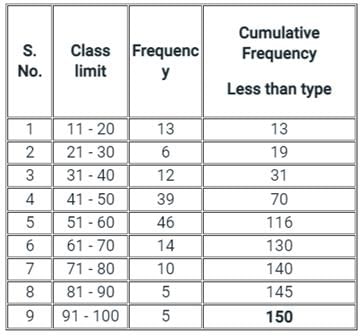
Comprehension:
Directions: Consider the following data and answer questions:
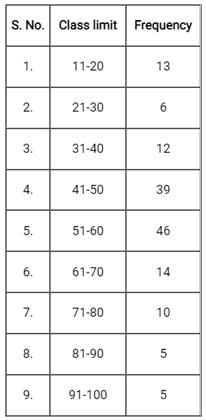
Which one of the following is the cumulative frequency of the entire data set?
Which one of the following is the cumulative frequency of the entire data set?

Comprehension:
Directions: Consider the following data and answer questions:
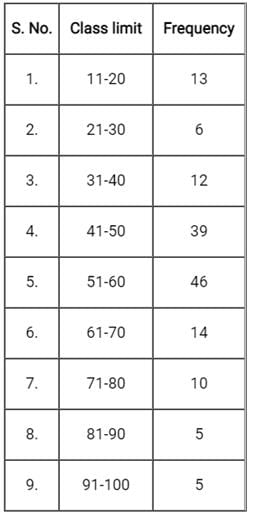
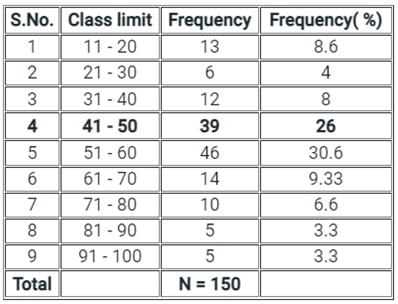
Which one of the following is the relative frequency in percentage for class limit 41-50 from the given data set?
Which one of the following is the relative frequency in percentage for class limit 41-50 from the given data set?
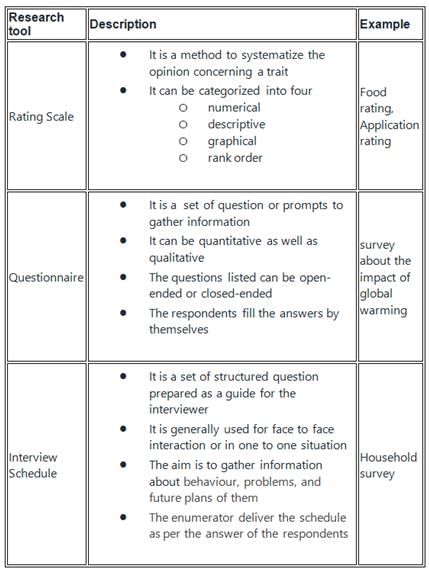
In order to understand the classroom teaching-learning process, which of the following research tool is most appropriate?
If you want to compare the price of wheat over a period, which index will you use?
Which among the following is a software for the analysis of qualitative data?
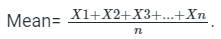
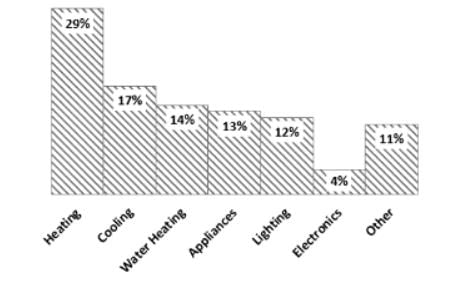
Comprehension:
Directions: Consider the following data and answer questions:
Which one of the following is the arithmetic mean value for the given data set?
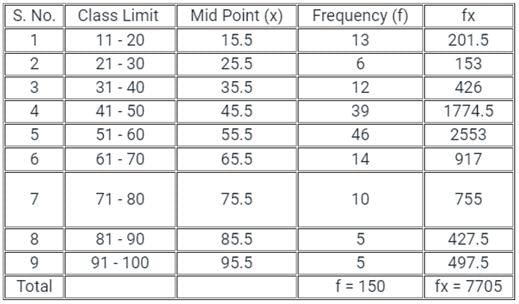
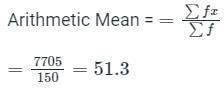
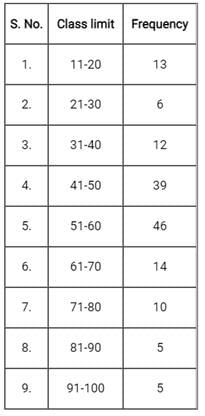
Comprehension:
Directions: Consider the following data and answer questions:
Which one of the following is the cumulative frequency for the class limit 61-70 from the given data set?
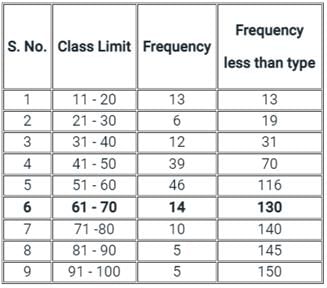
In Data Processing, what does the abbreviation SAP stand for?
Which one of the following is a non‐parametric statistic?
Which company was recently implicated in a global data theft crime?
A researcher administers an achievement test to assess and indicate the possible effect of an independent variable in his/her study. The distribution of scores on the test is found to be negatively skewed. On the basis of this, what can be started with regard to the difficulty level of the test?
A statistical measure that indicates the extent to which changes in one factor are accompanied by changes in another
Important Questions for Data Analysis - 2
Data Analysis - 2 MCQs with Answers
Online Tests for Data Analysis - 2
|
© EduRev
|
Education Revolution
|



|









within 7 days!