









All questions of Operating System for Computer Science Engineering (CSE) Exam
On a disk with 1000 cylinders, numbers 0 to 999, compute the number of tracks the disk arm must move to satisfy all the requests in the disk queue. Assume the last request serviced was at tracks 345 and the head is moving towards track 0. The queue in FIFO order contains requests for the following tracks. 123, 874, 692, 475, 105, 376. Perform the computation using C-SCAN scheduling algorithm. What is the total distance?- a)1219
- b)1009
- c)1967
- d)1507
Correct answer is option 'C'. Can you explain this answer?
On a disk with 1000 cylinders, numbers 0 to 999, compute the number of tracks the disk arm must move to satisfy all the requests in the disk queue. Assume the last request serviced was at tracks 345 and the head is moving towards track 0. The queue in FIFO order contains requests for the following tracks. 123, 874, 692, 475, 105, 376. Perform the computation using C-SCAN scheduling algorithm. What is the total distance?
a)
1219
b)
1009
c)
1967
d)
1507
|
|
Sanya Agarwal answered |
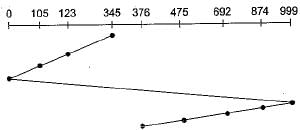
∴ Total distance covered by the head
= (345 -123) + (123 -105) + (105 - 0) + (999 - 0)
+ (999-874) + (874-692) + (692-475) + (475 -376)
= 222 + 18 + 105 + 999 + 125 + 182 + 217 + 99
= 1967

In a time-sharing operating system, when the time slot given to a process is completed, the process goes from the RUNNING state to the- a)BLOCKED state
- b)READY state
- c)SUSPENDED state
- d)TERMINATED state
Correct answer is option 'B'. Can you explain this answer?
In a time-sharing operating system, when the time slot given to a process is completed, the process goes from the RUNNING state to the
a)
BLOCKED state
b)
READY state
c)
SUSPENDED state
d)
TERMINATED state
|
|
Yash Patel answered |
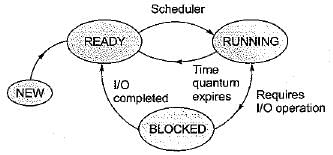
In time-sharing operating system (example in Round-Robin), whenever the time slot given to a process expires, it goes back to READY state and if it requests for same I/O operation, then it goes to BLOCKED state.
Consider three CPU-intensive processes, which require 10, 20 and 30 time units and arrive at times 0, 2 and 6, respectively. How many context switches are needed if the operating system implements a shortest remaining time first scheduling algorithm? Do not count the context switches at time zero and at the end.- a)1
- b)2
- c)3
- d)4
Correct answer is option 'B'. Can you explain this answer?
Consider three CPU-intensive processes, which require 10, 20 and 30 time units and arrive at times 0, 2 and 6, respectively. How many context switches are needed if the operating system implements a shortest remaining time first scheduling algorithm? Do not count the context switches at time zero and at the end.
a)
1
b)
2
c)
3
d)
4

|
Rahul Chatterjee answered |
Explanation:
Shortest remaining time, also known as shortest remaining time first (SRTF), is a scheduling method that is a pre-emptive version of shortest job next scheduling. In this scheduling algorithm, the process with the smallest amount of time remaining until completion is selected to execute. Since the currently executing process is the one with the shortest amount of time remaining by definition, and since that time should only reduce as execution progresses, processes will always run until they complete or a new process is added that requires a smaller amount of time.
Solution:
Let three process be P0, P1 and P2 with arrival times 0, 2 and 6 respectively and CPU burst times 10, 20 and 30 respectively. At time 0, P0 is the only available process so it runs. At time 2, P1 arrives, but P0 has the shortest remaining time, so it continues. At time 6, P2 also arrives, but P0 still has the shortest remaining time, so it continues. At time 10, P1 is scheduled as it is the shortest remaining time process. At time 30, P2 is scheduled. Only two context switches are needed. P0 to P1 and P1 to P2.
Which of the following strategy is employed for overcoming the priority inversion problem?- a)Temporarily raise the priority of lower priority level process
- b)Have a fixed priority level scheme
- c)Implement kernel pre-emption scheme
- d)Allow lower priority process to complete its job
Correct answer is option 'A'. Can you explain this answer?
Which of the following strategy is employed for overcoming the priority inversion problem?
a)
Temporarily raise the priority of lower priority level process
b)
Have a fixed priority level scheme
c)
Implement kernel pre-emption scheme
d)
Allow lower priority process to complete its job

|
Riverdale Learning Institute answered |
Priority inversion is a scenario in scheduling when a higher priority process is indirectly preempted by a lower priority process, thereby inverting the relative priorities of the process. This problem can be eliminated by temporarily raising the priority of lower priority level process, so that it can not preempt the higher priority process.
Option (A) is correct.
Consider a set of 5 processes whose arrival time, CPU time needed and the priority are given below:
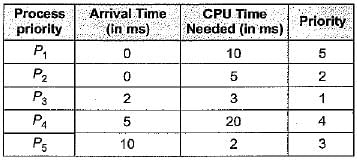
Note: Smaller the number, higher the priority.If the CPU scheduling policy is FCFS, the average waiting time will be - a)12.8 ms
- b)8 ms
- c)16 ms
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
Consider a set of 5 processes whose arrival time, CPU time needed and the priority are given below:
Note: Smaller the number, higher the priority.
Note: Smaller the number, higher the priority.
If the CPU scheduling policy is FCFS, the average waiting time will be
a)
12.8 ms
b)
8 ms
c)
16 ms
d)
None of the above

|
Crack Gate answered |
According to FCFS process solve are p1 p2 p3 p4 p5 so
For p1 waiting time = 0 process time = 10 then
For p2 waiting time = (process time of p1-arrival time of p2) = 10 - 0 = 10 then
For p3 waiting time = (pr. time of (p1+p2) - arrival time of p3) = (10 + 5) - 2 = 13 and
Same for p4 waiting time = 18 - 5 = 13
Same for p5 waiting time = 38 - 10 = 28
So total average waiting time = (0 + 10 + 13 + 13 + 28) / 5
= 12.8
User level threads are threads that are visible to the programmer and are unknown to the kernel. The operating system kernel supports and manages kernel level threads. Three different types of models relate user and kernel level threads. Which of the following statements is/are true ?(a)(i) The Many - to - one model maps many user threads to one kernel thread(ii) The one - to - one model maps one user thread to one kernel thread(iii) The many - to - many model maps many user threads to smaller or equal kernel threads(b)(i) Many - to - one model maps many kernel threads to one user thread(ii) One - to - one model maps one kernel thread to one user thread(iii) Many - to - many model maps many kernel threads to smaller or equal user threads- a)(a) is true; (b) is false
- b)(a) is false; (b) is true
- c)Both (a) and (b) are true
- d)Both (a) and (b) are false
Correct answer is option 'A'. Can you explain this answer?
User level threads are threads that are visible to the programmer and are unknown to the kernel. The operating system kernel supports and manages kernel level threads. Three different types of models relate user and kernel level threads. Which of the following statements is/are true ?
(a)
(i) The Many - to - one model maps many user threads to one kernel thread
(ii) The one - to - one model maps one user thread to one kernel thread
(iii) The many - to - many model maps many user threads to smaller or equal kernel threads
(b)
(i) Many - to - one model maps many kernel threads to one user thread
(ii) One - to - one model maps one kernel thread to one user thread
(iii) Many - to - many model maps many kernel threads to smaller or equal user threads
a)
(a) is true; (b) is false
b)
(a) is false; (b) is true
c)
Both (a) and (b) are true
d)
Both (a) and (b) are false
|
|
Ashutosh Mukherjee answered |
Explanation:
User-level threads and kernel-level threads are two different types of threads used in operating systems. The operating system kernel supports and manages kernel-level threads, while user-level threads are managed by the programmer.
User-Level Threads:
- User-level threads are threads that are visible to the programmer and are unknown to the kernel.
- These threads are created and managed by the application or programming language without any intervention from the operating system.
- User-level threads are lightweight and have low overhead since they do not require kernel involvement for thread management.
- However, user-level threads are limited by the fact that if one thread blocks or performs a system call, all other threads in the process are also blocked.
Kernel-Level Threads:
- Kernel-level threads are threads that are managed and supported by the operating system kernel.
- The kernel provides system calls and services for creating, scheduling, and managing kernel-level threads.
- Kernel-level threads have the advantage of being able to run in parallel on multiple processors or cores.
- However, they have higher overhead compared to user-level threads due to the involvement of the kernel in thread management.
Models of User and Kernel Level Threads:
There are three different models that relate user-level threads to kernel-level threads:
1. Many-to-One Model:
- In this model, many user threads are mapped to a single kernel thread.
- All user-level threads of a process share the same kernel-level thread.
- This model has low overhead and is easy to implement but lacks the ability to run threads in parallel on multiple processors or cores.
2. One-to-One Model:
- In this model, each user thread is mapped to a separate kernel thread.
- Each user-level thread has a corresponding kernel-level thread.
- This model allows threads to run in parallel on multiple processors or cores, but it has higher overhead compared to the many-to-one model.
3. Many-to-Many Model:
- In this model, many user threads are mapped to smaller or equal kernel threads.
- The mapping between user and kernel threads can be dynamic and change over time.
- This model provides a balance between the flexibility of the one-to-one model and the efficiency of the many-to-one model.
Correct Answer:
The correct answer is option (a) - (a) is true; (b) is false.
- The many-to-one model maps many user threads to one kernel thread.
- The one-to-one model maps one user thread to one kernel thread.
- The many-to-many model maps many user threads to smaller or equal kernel threads.
User-level threads and kernel-level threads are two different types of threads used in operating systems. The operating system kernel supports and manages kernel-level threads, while user-level threads are managed by the programmer.
User-Level Threads:
- User-level threads are threads that are visible to the programmer and are unknown to the kernel.
- These threads are created and managed by the application or programming language without any intervention from the operating system.
- User-level threads are lightweight and have low overhead since they do not require kernel involvement for thread management.
- However, user-level threads are limited by the fact that if one thread blocks or performs a system call, all other threads in the process are also blocked.
Kernel-Level Threads:
- Kernel-level threads are threads that are managed and supported by the operating system kernel.
- The kernel provides system calls and services for creating, scheduling, and managing kernel-level threads.
- Kernel-level threads have the advantage of being able to run in parallel on multiple processors or cores.
- However, they have higher overhead compared to user-level threads due to the involvement of the kernel in thread management.
Models of User and Kernel Level Threads:
There are three different models that relate user-level threads to kernel-level threads:
1. Many-to-One Model:
- In this model, many user threads are mapped to a single kernel thread.
- All user-level threads of a process share the same kernel-level thread.
- This model has low overhead and is easy to implement but lacks the ability to run threads in parallel on multiple processors or cores.
2. One-to-One Model:
- In this model, each user thread is mapped to a separate kernel thread.
- Each user-level thread has a corresponding kernel-level thread.
- This model allows threads to run in parallel on multiple processors or cores, but it has higher overhead compared to the many-to-one model.
3. Many-to-Many Model:
- In this model, many user threads are mapped to smaller or equal kernel threads.
- The mapping between user and kernel threads can be dynamic and change over time.
- This model provides a balance between the flexibility of the one-to-one model and the efficiency of the many-to-one model.
Correct Answer:
The correct answer is option (a) - (a) is true; (b) is false.
- The many-to-one model maps many user threads to one kernel thread.
- The one-to-one model maps one user thread to one kernel thread.
- The many-to-many model maps many user threads to smaller or equal kernel threads.
Consider data given in the above question. What is the minimum number of page colours needed to guarantee that no two synonyms map to different sets in the processor cache of this computer? - a)2
- b)4
- c)8
- d)16
Correct answer is option 'C'. Can you explain this answer?
Consider data given in the above question. What is the minimum number of page colours needed to guarantee that no two synonyms map to different sets in the processor cache of this computer?
a)
2
b)
4
c)
8
d)
16
|
|
Riverdale Learning Institute answered |
1 MB 16-way set associative virtually indexed physically tagged cache(VIPT). The cache block size is 64 bytes.
No of blocks is 2^20/2^6 = 2^14.
No of sets is 2^14/2^4 = 2^10.
No of blocks is 2^20/2^6 = 2^14.
No of sets is 2^14/2^4 = 2^10.
VA(46)
+-------------------------------+
tag(30) , Set(10) , block offset(6)
+-------------------------------+
+-------------------------------+
tag(30) , Set(10) , block offset(6)
+-------------------------------+
In VIPT if the no. of bits of page offset = (Set+block offset) then only one page color is sufficient.
but we need 8 colors because the number bits where the cache set index and physical page number over lap is 3 so 2^3 page colors is required.(option c is ans).
but we need 8 colors because the number bits where the cache set index and physical page number over lap is 3 so 2^3 page colors is required.(option c is ans).
Consider a fully associative cache with 8 cache blocks (numbered 0-7) and the following sequence of memory block requests: 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 If LRU replacement policy is used, which cache block will have memory block 7? - a)4
- b)5
- c)6
- d)7
Correct answer is option 'B'. Can you explain this answer?
Consider a fully associative cache with 8 cache blocks (numbered 0-7) and the following sequence of memory block requests: 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 If LRU replacement policy is used, which cache block will have memory block 7?
a)
4
b)
5
c)
6
d)
7
|
|
Pranab Banerjee answered |
Block size is =8 Given 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 So from 0 to 7 ,we have
- 4 3 25 8 19 6 16 35 //25,8 LRU so next 16,35 come in the block.
- 45 3 25 8 19 6 16 35
- 45 22 25 8 19 6 16 35
- 45 22 25 8 19 6 16 35
- 45 22 25 8 3 6 16 35 //16 and 25 already there
- 45 22 25 8 3 7 16 35 //7 in 5th block Therefore , answer is B
A scheduling algorithm assigns priority proportional to the waiting time of a process. Every process starts with priority zero (the lowest priority). The scheduler re-evaluates the process priorities every T time units and decides the next process to schedule. Which one of the following is TRUE if the processes have no I/O operations and all arrive at time zero?- a)This algorithm is equivalent to the first-come-first-serve algorithm
- b)This algorithm is equivalent to the round-robin algorithm.
- c)This algorithm is equivalent to the shortest-job-first algorithm..
- d)This algorithm is equivalent to the shortest-remaining-time-first algorithm
Correct answer is option 'B'. Can you explain this answer?
A scheduling algorithm assigns priority proportional to the waiting time of a process. Every process starts with priority zero (the lowest priority). The scheduler re-evaluates the process priorities every T time units and decides the next process to schedule. Which one of the following is TRUE if the processes have no I/O operations and all arrive at time zero?
a)
This algorithm is equivalent to the first-come-first-serve algorithm
b)
This algorithm is equivalent to the round-robin algorithm.
c)
This algorithm is equivalent to the shortest-job-first algorithm..
d)
This algorithm is equivalent to the shortest-remaining-time-first algorithm
|
|
Tanishq Joshi answered |
The scheduling algorithm works as round robin with quantum time equals to T. After a process's turn comes and it has executed for T units, its waiting time becomes least and its turn comes again after every other process has got the token for T units.
An operating system uses Shortest Remaining Time first (SRT) process scheduling algorithm. Consider the arrival times and execution times for the following processes:Process Execution time Arrival time
P1 20 0
P2 25 15
P3 10 30
P4 15 45Q. What is the total waiting time for process P2?- a)5
- b)15
- c)40
- d)55
Correct answer is option 'B'. Can you explain this answer?
An operating system uses Shortest Remaining Time first (SRT) process scheduling algorithm. Consider the arrival times and execution times for the following processes:
Process Execution time Arrival time
P1 20 0
P2 25 15
P3 10 30
P4 15 45
P1 20 0
P2 25 15
P3 10 30
P4 15 45
Q. What is the total waiting time for process P2?
a)
5
b)
15
c)
40
d)
55
|
|
Nidhi Desai answered |
Shortest remaining time, also known as shortest remaining time first (SRTF), is a scheduling method that is a pre-emptive version of shortest job next scheduling. In this scheduling algorithm, the process with the smallest amount of time remaining until completion is selected to execute. Since the currently executing process is the one with the shortest amount of time remaining by definition, and since that time should only reduce as execution progresses, processes will always run until they complete or a new process is added that requires a smaller amount of time. The Gantt chart of execution of processes:

At time 0, P1 is the only process, P1 runs for 15 time units. At time 15, P2 arrives, but P1 has the shortest remaining time. So P1 continues for 5 more time units. At time 20, P2 is the only process. So it runs for 10 time units. at time 30, P3 is the shortest remaining time process. So it runs for 10 time units. at time 40, P2 runs as it is the only process. P2 runs for 5 time units. At time 45, P3 arrives, but P2 has the shortest remaining time. So P2 continues for 10 more time units. P2 completes its execution at time 55.
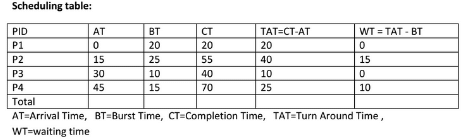
As we know, turn around time is total time between submission of the process and its completion. Waiting time is the time The amount of time that is taken by a process in ready queue and waiting time is the difference between Turn around time and burst time. Total turnaround time for P2 = Completion time - Arrival time = 55 - 15 = 40 Total Waiting Time for P2= turn around time - Burst time = 40 – 25 = 15
In Round Robin CPU scheduling, as the time quantum is increased, the average turn around time- a)Increases
- b)Decreases
- c)Remains constant
- d)Varies irregularly
Correct answer is option 'D'. Can you explain this answer?
In Round Robin CPU scheduling, as the time quantum is increased, the average turn around time
a)
Increases
b)
Decreases
c)
Remains constant
d)
Varies irregularly
|
|
Tanishq Chakraborty answered |
Explanation:
In Round Robin CPU scheduling, the time quantum is the maximum amount of time a process can run before it is preempted and moved to the back of the ready queue. When the time quantum is increased, it affects the scheduling of the processes and can have an impact on the average turnaround time.
Definition of Average Turnaround Time:
The average turnaround time is the total amount of time it takes for a process to complete, including both the waiting time and the execution time.
Effect of Increasing Time Quantum on Average Turnaround Time:
When the time quantum is increased, the following effects can be observed:
1. Decreased Context Switching: A larger time quantum means that each process is allowed to run for a longer period before being preempted. This reduces the frequency of context switching, which is the overhead involved in switching between processes. As a result, the average turnaround time may decrease.
2. Increased Waiting Time: With a larger time quantum, each process is allowed to run for a longer period. This can lead to an increase in the waiting time for processes that are waiting in the ready queue. As a result, the average turnaround time may increase.
3. Variation in Burst Times: Processes typically have varying burst times, which is the amount of time they require to complete their execution. When the time quantum is increased, processes with shorter burst times may be able to complete their execution within the time quantum, while processes with longer burst times may be preempted multiple times. This can lead to irregular variations in the average turnaround time.
Conclusion:
In conclusion, as the time quantum is increased in Round Robin CPU scheduling, the average turnaround time can vary irregularly. The effects of increasing the time quantum include decreased context switching, increased waiting time, and variations in burst times, which can impact the overall average turnaround time of the processes.
In Round Robin CPU scheduling, the time quantum is the maximum amount of time a process can run before it is preempted and moved to the back of the ready queue. When the time quantum is increased, it affects the scheduling of the processes and can have an impact on the average turnaround time.
Definition of Average Turnaround Time:
The average turnaround time is the total amount of time it takes for a process to complete, including both the waiting time and the execution time.
Effect of Increasing Time Quantum on Average Turnaround Time:
When the time quantum is increased, the following effects can be observed:
1. Decreased Context Switching: A larger time quantum means that each process is allowed to run for a longer period before being preempted. This reduces the frequency of context switching, which is the overhead involved in switching between processes. As a result, the average turnaround time may decrease.
2. Increased Waiting Time: With a larger time quantum, each process is allowed to run for a longer period. This can lead to an increase in the waiting time for processes that are waiting in the ready queue. As a result, the average turnaround time may increase.
3. Variation in Burst Times: Processes typically have varying burst times, which is the amount of time they require to complete their execution. When the time quantum is increased, processes with shorter burst times may be able to complete their execution within the time quantum, while processes with longer burst times may be preempted multiple times. This can lead to irregular variations in the average turnaround time.
Conclusion:
In conclusion, as the time quantum is increased in Round Robin CPU scheduling, the average turnaround time can vary irregularly. The effects of increasing the time quantum include decreased context switching, increased waiting time, and variations in burst times, which can impact the overall average turnaround time of the processes.
Concurrent processes are processes that- a)Do not overlap in time
- b)Overlap in time
- c)Are executed by a processor at the same time
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Concurrent processes are processes that
a)
Do not overlap in time
b)
Overlap in time
c)
Are executed by a processor at the same time
d)
None of the above
|
|
Roshni Kumar answered |
Concurrent processes are processes that share the CPU and memory. They do overlap in time while execution. At a time CPU entertain only one process but it can switch to other without completing it as a whole.
A disk drive has 100 cyclinders, numbered 0 to 99. Disk requests come to the disk driver for cyclinders 12, 26, 24, 4, 42, 8 and 50 in that order. The driver is currently serving a request at cyclinder 24. A seek takes 6 msec per cyclinder moved. How much seek time is needed for shortest seek time first (SSTF) algorithm?- a)0.984 sec
- b)0.396 sec
- c)0.738 sec
- d)0.42 sec
Correct answer is option 'D'. Can you explain this answer?
A disk drive has 100 cyclinders, numbered 0 to 99. Disk requests come to the disk driver for cyclinders 12, 26, 24, 4, 42, 8 and 50 in that order. The driver is currently serving a request at cyclinder 24. A seek takes 6 msec per cyclinder moved. How much seek time is needed for shortest seek time first (SSTF) algorithm?
a)
0.984 sec
b)
0.396 sec
c)
0.738 sec
d)
0.42 sec

|
Cstoppers Instructors answered |
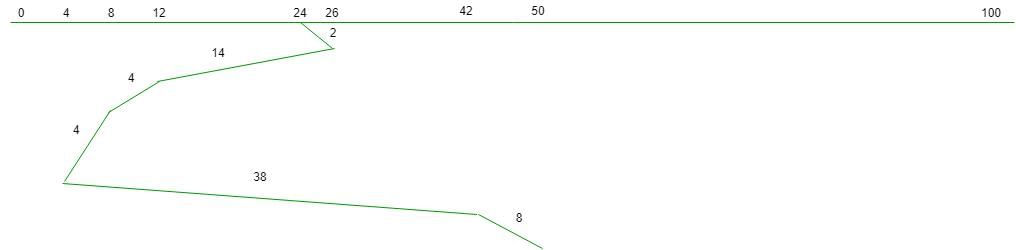
seek time = 2 =(2 + 14 + 4 + 4 + 38 + 8) = 420 msec 1000 msec = 1 sec 420 msec = 0.42 sec So, option (D) is correct.
A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?- a)On per-thread basis, the OS maintains only CPU register state
- b)The OS does not maintain a separate stack for each thread
- c)On per-thread basis, the OS does not maintain virtual memory state
- d)On per-thread basis, the OS maintains only scheduling and accounting information
Correct answer is option 'C'. Can you explain this answer?
A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?
a)
On per-thread basis, the OS maintains only CPU register state
b)
The OS does not maintain a separate stack for each thread
c)
On per-thread basis, the OS does not maintain virtual memory state
d)
On per-thread basis, the OS maintains only scheduling and accounting information
|
|
Sanya Agarwal answered |
Threads share address space of Process. Virtually memory is concerned with processes not with Threads. A thread is a basic unit of CPU utilization, consisting of a program counter, a stack, and a set of registers, (and a thread ID.) As you can see, for a single thread of control - there is one program counter, and one sequence of instructions that can be carried out at any given time and for multi-threaded applications-there are multiple threads within a single process, each having their own program counter, stack and set of registers, but sharing common code, data, and certain structures such as open files.
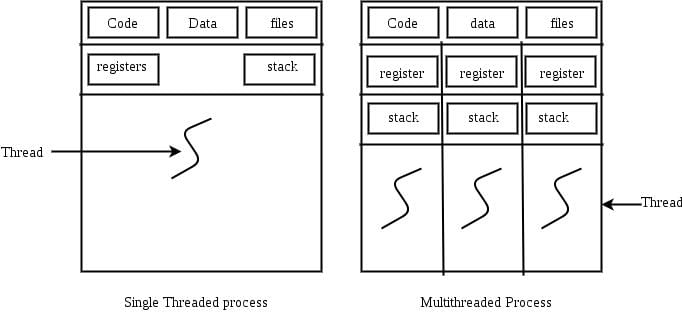
Option (A): as you can see in the above diagram, NOT ONLY CPU Register but stack and code files, data files are also maintained. So, option (A) is not correct as it says OS maintains only CPU register state.
Option (B): according to option (B), OS does not maintain a separate stack for each thread. But as you can see in above diagram, for each thread, separate stack is maintained. So this option is also incorrect.
Option (C): according to option (C), the OS does not maintain virtual memory state. And It is correct as Os does not maintain any virtual memory state for individual thread.
Option (D): according to option (D), the OS maintains only scheduling and accounting information. But it is not correct as it contains other information like cpu registers stack, program counters, data files, code files are also maintained.
A certain computation generates two arrays a and b such that a[i]=f(i) for 0 ≤ i < n and b[i]=g(a[i]) for 0 ≤ i < n. Suppose this computation is decomposed into two concurrent processes X and Y such that X computes the array a and Y computes the array b. The processes employ two binary semaphores R and S, both initialized to zero. The array a is shared by the two processes. The structures of the processes are shown below.Process X: Process Y:private i; private i;
for (i=0; i < n; i++) { for (i=0; i < n; i++) {
a[i] = f(i); EntryY(R, S);
ExitX(R, S); b[i]=g(a[i]);
} } Q. Which one of the following represents the CORRECT implementations of ExitX and EntryY?- a)ExitX(R, S) {
P(R);
V(S);
}
EntryY (R, S) {
P(S);
V(R);
} - b)ExitX(R, S) {
V(R);
V(S);
}
EntryY(R, S) {
P(R);
P(S);
} - c)ExitX(R, S) {
P(S);
V(R);
}
EntryY(R, S) {
V(S);
P(R);
} - d)ExitX(R, S) {
V(R);
P(S);
}
EntryY(R, S) {
V(S);
P(R);
}
Correct answer is option 'C'. Can you explain this answer?
A certain computation generates two arrays a and b such that a[i]=f(i) for 0 ≤ i < n and b[i]=g(a[i]) for 0 ≤ i < n. Suppose this computation is decomposed into two concurrent processes X and Y such that X computes the array a and Y computes the array b. The processes employ two binary semaphores R and S, both initialized to zero. The array a is shared by the two processes. The structures of the processes are shown below.
Process X: Process Y:
private i; private i;
for (i=0; i < n; i++) { for (i=0; i < n; i++) {
a[i] = f(i); EntryY(R, S);
ExitX(R, S); b[i]=g(a[i]);
} }
for (i=0; i < n; i++) { for (i=0; i < n; i++) {
a[i] = f(i); EntryY(R, S);
ExitX(R, S); b[i]=g(a[i]);
} }
Q. Which one of the following represents the CORRECT implementations of ExitX and EntryY?
a)
ExitX(R, S) {
P(R);
V(S);
}
EntryY (R, S) {
P(S);
V(R);
}
P(R);
V(S);
}
EntryY (R, S) {
P(S);
V(R);
}
b)
ExitX(R, S) {
V(R);
V(S);
}
EntryY(R, S) {
P(R);
P(S);
}
V(R);
V(S);
}
EntryY(R, S) {
P(R);
P(S);
}
c)
ExitX(R, S) {
P(S);
V(R);
}
EntryY(R, S) {
V(S);
P(R);
}
P(S);
V(R);
}
EntryY(R, S) {
V(S);
P(R);
}
d)
ExitX(R, S) {
V(R);
P(S);
}
EntryY(R, S) {
V(S);
P(R);
}
V(R);
P(S);
}
EntryY(R, S) {
V(S);
P(R);
}

|
Bijoy Kapoor answered |
The purpose here is neither the deadlock should occur nor the binary semaphores be assigned value greater
than one.
A leads to deadlock
B can increase value of semaphores b/w 1 to n
D may increase the value of semaphore R and S to 2 in some cases
Which of the following statements are true?I. Shortest remaining time first scheduling may cause starvation
II. Preemptive scheduling may cause starvation
III. Round robin is better than FCFS in terms of response time- a)I only
- b)I and III only
- c)II and III only
- d)I, II and III
Correct answer is option 'D'. Can you explain this answer?
Which of the following statements are true?
I. Shortest remaining time first scheduling may cause starvation
II. Preemptive scheduling may cause starvation
III. Round robin is better than FCFS in terms of response time
II. Preemptive scheduling may cause starvation
III. Round robin is better than FCFS in terms of response time
a)
I only
b)
I and III only
c)
II and III only
d)
I, II and III
|
|
Shubham Ghoshal answered |
I) Shortest remaining time first scheduling is a pre-emptive version of shortest job scheduling. In SRTF, job with the shortest CPU burst will be scheduled first. Because of this process, It may cause starvation as shorter processes may keep coming and a long CPU burst process never gets CPU.
II) Pre-emptive just means a process before completing its execution is stopped and other process can start execution. The stopped process can later come back and continue from where it was stopped. In pre-emptive scheduling, suppose process P1 is executing in CPU and after some time process P2 with high priority then P1 will arrive in ready queue then p1 is pre-empted and p2 will brought into CPU for execution. In this way if process which is arriving in ready queue is of higher priority then p1, then p1 is always pre-empted and it may possible that it suffer from starvation.
III) round robin will give better response time then FCFS ,in FCFS when process is executing ,it executed up to its complete burst time, but in round robin it will execute up to time quantum. So Round Robin Scheduling improves response time as all processes get CPU after a specified time. So, I,II,III are true which is option (D). Option (D) is correct answer.
II) Pre-emptive just means a process before completing its execution is stopped and other process can start execution. The stopped process can later come back and continue from where it was stopped. In pre-emptive scheduling, suppose process P1 is executing in CPU and after some time process P2 with high priority then P1 will arrive in ready queue then p1 is pre-empted and p2 will brought into CPU for execution. In this way if process which is arriving in ready queue is of higher priority then p1, then p1 is always pre-empted and it may possible that it suffer from starvation.
III) round robin will give better response time then FCFS ,in FCFS when process is executing ,it executed up to its complete burst time, but in round robin it will execute up to time quantum. So Round Robin Scheduling improves response time as all processes get CPU after a specified time. So, I,II,III are true which is option (D). Option (D) is correct answer.
Which of the following statements is not true?- a)Deadlock can never occur if resources can be shared by competing processes.
- b)Deadlock can never occur if resources must be requested in the same order by processes.
- c)The Banker’s algorithm for avoiding deadlock requires knowing resource requirements in advance
- d)If the resource allocation graph depicts a cycle then deadlock has certainly occured.
Correct answer is option 'B'. Can you explain this answer?
Which of the following statements is not true?
a)
Deadlock can never occur if resources can be shared by competing processes.
b)
Deadlock can never occur if resources must be requested in the same order by processes.
c)
The Banker’s algorithm for avoiding deadlock requires knowing resource requirements in advance
d)
If the resource allocation graph depicts a cycle then deadlock has certainly occured.
|
|
Madhurima Chakraborty answered |
Deadlock can’t take place if resources must be requested in same order by process. For deadlock, circular wait is a must condition.
Suppose we have a system in which processes is in hold and wait condition then which of the following approach prevent the deadlock.- a)Request all resources initially
- b)Spool everything
- c)Take resources away
- d)Order resources numerically
Correct answer is option 'A'. Can you explain this answer?
Suppose we have a system in which processes is in hold and wait condition then which of the following approach prevent the deadlock.
a)
Request all resources initially
b)
Spool everything
c)
Take resources away
d)
Order resources numerically
|
|
Ruchi Sengupta answered |
Preventing Deadlock by Requesting All Resources Initially
Deadlock is a situation in which two or more processes are unable to proceed because each is waiting for the other to release resources. It can occur in a system with limited resources and processes that are holding resources while waiting for other resources to be released.
One approach to prevent deadlock is to request all resources initially. This means that when a process needs to execute, it requests all the resources it will need for its entire execution before it starts. This approach can help prevent deadlock by ensuring that a process has all the necessary resources before it begins execution.
Advantages of Requesting All Resources Initially:
-Preventing Resource Deadlock: By requesting all resources initially, a process can ensure that it has all the resources it needs for its execution. This prevents the situation where a process holds some resources and waits for others, leading to deadlock.
-Efficient Resource Allocation: Requesting all resources initially allows the system to allocate resources more efficiently. Since a process requests all the resources it needs at once, the system can determine if there are enough resources available to satisfy the request. If there are not enough resources, the system can allocate them to other processes that can make progress, avoiding resource wastage.
Disadvantages of Requesting All Resources Initially:
-Resource Overallocation: Requesting all resources initially may lead to resource overallocation, where a process requests more resources than it actually needs. This can result in resource wastage and inefficient resource utilization.
-Low Concurrency: Requesting all resources initially can reduce the level of concurrency in the system. Since a process needs to wait until it acquires all the resources it needs, other processes may have to wait for a long time before they can execute, leading to decreased system performance.
Overall, requesting all resources initially can be an effective approach to prevent deadlock in a system. However, it is important to carefully consider the resource requirements of each process and balance the need for preventing deadlock with the need for efficient resource utilization and system performance.
Deadlock is a situation in which two or more processes are unable to proceed because each is waiting for the other to release resources. It can occur in a system with limited resources and processes that are holding resources while waiting for other resources to be released.
One approach to prevent deadlock is to request all resources initially. This means that when a process needs to execute, it requests all the resources it will need for its entire execution before it starts. This approach can help prevent deadlock by ensuring that a process has all the necessary resources before it begins execution.
Advantages of Requesting All Resources Initially:
-Preventing Resource Deadlock: By requesting all resources initially, a process can ensure that it has all the resources it needs for its execution. This prevents the situation where a process holds some resources and waits for others, leading to deadlock.
-Efficient Resource Allocation: Requesting all resources initially allows the system to allocate resources more efficiently. Since a process requests all the resources it needs at once, the system can determine if there are enough resources available to satisfy the request. If there are not enough resources, the system can allocate them to other processes that can make progress, avoiding resource wastage.
Disadvantages of Requesting All Resources Initially:
-Resource Overallocation: Requesting all resources initially may lead to resource overallocation, where a process requests more resources than it actually needs. This can result in resource wastage and inefficient resource utilization.
-Low Concurrency: Requesting all resources initially can reduce the level of concurrency in the system. Since a process needs to wait until it acquires all the resources it needs, other processes may have to wait for a long time before they can execute, leading to decreased system performance.
Overall, requesting all resources initially can be an effective approach to prevent deadlock in a system. However, it is important to carefully consider the resource requirements of each process and balance the need for preventing deadlock with the need for efficient resource utilization and system performance.
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore .void P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
} Q. Which one of the following is true?- a)The implementation may not work if context switching is disabled in P.
- b)Instead of using fetch-and-set, a pair of normal load/store can be used
- c)The implementation of V is wrong
- d)The code does not implement a binary semaphore
Correct answer is option 'A'. Can you explain this answer?
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore .
void P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
Q. Which one of the following is true?
a)
The implementation may not work if context switching is disabled in P.
b)
Instead of using fetch-and-set, a pair of normal load/store can be used
c)
The implementation of V is wrong
d)
The code does not implement a binary semaphore
|
|
Riverdale Learning Institute answered |
Let us talk about the operation P(). It stores the value of s in x, then it fetches the old value of x, stores it in y and sets x as 1. The while loop of a process will continue forever if some other process doesn't execute V() and sets the value of s as 0. If context switching is disabled in P, the while loop will run forever as no other process will be able to execute V().
The crew performed experiments such as pollinatary planets and faster computer chips price tag is- a)51 million dollars
- b)52 million dollars
- c)54 million dollars
- d)56 million dollars
Correct answer is option 'D'. Can you explain this answer?
The crew performed experiments such as pollinatary planets and faster computer chips price tag is
a)
51 million dollars
b)
52 million dollars
c)
54 million dollars
d)
56 million dollars

|
Gayatri Chavan answered |
Kalpana Chawla’s first mission was in the space shuttle Columbia. It was a 15 days, 16
hours and 34 minutes. During this time, she went around the earth 252 times traveling 1.45
million km. The crew performed experiments such as pollinating plants to observe food
growth in space. It also made test for making stronger metals and faster computer chips. It
was all done for a price tag of 56 million dollars.
A virtual memory system uses First In First Out (FIFO) page replacement policy and allocates a fixed number of frames to a process. Consider the following statements:P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference.
Q. Which one of the following is TRUE?- a)Both P and Q are true, and Q is the reason for P
- b)Both P and Q are true, but Q is not the reason for P.
- c)P is false, but Q is true
- d)Both P and Q are false
Correct answer is option 'B'. Can you explain this answer?
A virtual memory system uses First In First Out (FIFO) page replacement policy and allocates a fixed number of frames to a process. Consider the following statements:
P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference.
Q: Some programs do not exhibit locality of reference.
Q. Which one of the following is TRUE?
a)
Both P and Q are true, and Q is the reason for P
b)
Both P and Q are true, but Q is not the reason for P.
c)
P is false, but Q is true
d)
Both P and Q are false

|
Kritika Shah answered |
First In First Out Page Replacement Algorithms: This is the simplest page replacement algorithm. In this algorithm, operating system keeps track of all pages in the memory in a queue, oldest page is in the front of the queue. When a page needs to be replaced page in the front of the queue is selected for removal. FIFO Page replacement algorithms suffers from Belady’s anomaly : Belady’s anomaly states that it is possible to have more page faults when increasing the number of page frames. Solution:
Statement P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate. Correct, as FIFO page replacement algorithm suffers from belady’s anomaly which states above statement.
Statement Q: Some programs do not exhibit locality of reference. Correct, Locality often occurs because code contains loops that tend to reference arrays or other data structures by indices. So we can write a program does not contain loop and do not exhibit locality of reference. So, both statement P and Q are correct but Q is not the reason for P as Belady’s Anomaly occurs for some specific patterns of page references.
Statement P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate. Correct, as FIFO page replacement algorithm suffers from belady’s anomaly which states above statement.
Statement Q: Some programs do not exhibit locality of reference. Correct, Locality often occurs because code contains loops that tend to reference arrays or other data structures by indices. So we can write a program does not contain loop and do not exhibit locality of reference. So, both statement P and Q are correct but Q is not the reason for P as Belady’s Anomaly occurs for some specific patterns of page references.
Which of the following DMA transfer modes and interrupt handling mechanisms will enable the highest I/O band-width? - a)Transparent DMA and Polling interrupts
- b)Cycle-stealing and Vectored interrupts
- c)Block transfer and Vectored interrupts
- d)Block transfer and Polling interrupts
Correct answer is option 'C'. Can you explain this answer?
Which of the following DMA transfer modes and interrupt handling mechanisms will enable the highest I/O band-width?
a)
Transparent DMA and Polling interrupts
b)
Cycle-stealing and Vectored interrupts
c)
Block transfer and Vectored interrupts
d)
Block transfer and Polling interrupts
|
|
Yash Patel answered |
CPU get highest bandwidth in transparent DMA and polling. but it asked for I/O bandwidth not cpu bandwidth so option (A) is wrong.
In case of Cycle stealing, in each cycle time device send data then wait again after few CPU cycle it sends to memory . So option (B) is wrong.
In case of Polling CPU takes the initiative so I/O bandwidth can not be high so option (D) is wrong .
Consider Block transfer, in each single block device send data so bandwidth ( means the amount of data ) must be high . This makes option (C) correct.
In case of Cycle stealing, in each cycle time device send data then wait again after few CPU cycle it sends to memory . So option (B) is wrong.
In case of Polling CPU takes the initiative so I/O bandwidth can not be high so option (D) is wrong .
Consider Block transfer, in each single block device send data so bandwidth ( means the amount of data ) must be high . This makes option (C) correct.
Which of the following algorithms favour CPU bound processes?
1. Round-robin
2. Rirst-come-first-served
3. Multilevel feedback queues- a)1 only
- b)2 only
- c)1 and 2 only
- d)1 and 3 only
Correct answer is option 'B'. Can you explain this answer?
Which of the following algorithms favour CPU bound processes?
1. Round-robin
2. Rirst-come-first-served
3. Multilevel feedback queues
1. Round-robin
2. Rirst-come-first-served
3. Multilevel feedback queues
a)
1 only
b)
2 only
c)
1 and 2 only
d)
1 and 3 only
|
|
Saanvi Bajaj answered |
Only FCFS and non-preempting algorithms favour CPU bound processes.
Which one of the following is FALSE?- a)User level threads are not scheduled by the kernel.
- b)When a user level thread is blocked, all other threads of its process are blocked.
- c)Context switching between user level threads is faster than context switching between kernel level threads.
- d)Kernel level threads cannot share the code segmen
Correct answer is option 'D'. Can you explain this answer?
Which one of the following is FALSE?
a)
User level threads are not scheduled by the kernel.
b)
When a user level thread is blocked, all other threads of its process are blocked.
c)
Context switching between user level threads is faster than context switching between kernel level threads.
d)
Kernel level threads cannot share the code segmen
|
|
Rithika Tiwari answered |

A shared variable x, initialized to zero, is operated on by four concurrent processes W, X, Y, Z as follows. Each of the processes W and X reads x from memory, increments by one, stores it to memory, and then terminates. Each of the processes Y and Z reads x from memory, decrements by two, stores it to memory, and then terminates. Each process before reading x invokes the P operation (i.e., wait) on a counting semaphore S and invokes the V operation (i.e., signal) on the semaphore S after storing x to memory. Semaphore S is initialized to two. What is the maximum possible value of x after all processes complete execution?- a)-2
- b)-1
- c)1
- d)2
Correct answer is option 'D'. Can you explain this answer?
A shared variable x, initialized to zero, is operated on by four concurrent processes W, X, Y, Z as follows. Each of the processes W and X reads x from memory, increments by one, stores it to memory, and then terminates. Each of the processes Y and Z reads x from memory, decrements by two, stores it to memory, and then terminates. Each process before reading x invokes the P operation (i.e., wait) on a counting semaphore S and invokes the V operation (i.e., signal) on the semaphore S after storing x to memory. Semaphore S is initialized to two. What is the maximum possible value of x after all processes complete execution?
a)
-2
b)
-1
c)
1
d)
2

|
Sandeep Sen answered |
Processes can run in many ways, below is one of the cases in which x attains max value
Semaphore S is initialized to 2 Process W executes S=1, x=1 but it doesn't update the x variable.
Then process Y executes S=0, it decrements x, now x= -2 and signal semaphore S=1
Now process Z executes s=0, x=-4, signal semaphore S=1
Now process W updates x=1, S=2 Then process X executes X=2
Semaphore S is initialized to 2 Process W executes S=1, x=1 but it doesn't update the x variable.
Then process Y executes S=0, it decrements x, now x= -2 and signal semaphore S=1
Now process Z executes s=0, x=-4, signal semaphore S=1
Now process W updates x=1, S=2 Then process X executes X=2
So correct option is D
A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?- a)On per-thread basis, the OS maintains only CPU register state
- b)The OS does not maintain a separate stack for each thread
- c)On per-thread basis, the OS does not maintain virtual memory state
- d)On per-thread basis, the OS maintains only scheduling and accounting information
Correct answer is option 'C'. Can you explain this answer?
A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?
a)
On per-thread basis, the OS maintains only CPU register state
b)
The OS does not maintain a separate stack for each thread
c)
On per-thread basis, the OS does not maintain virtual memory state
d)
On per-thread basis, the OS maintains only scheduling and accounting information
|
|
Naina Shah answered |
Threads share address space of Process. Virtually memory is concerned with processes not with Threads. A thread is a basic unit of CPU utilization, consisting of a program counter, a stack, and a set of registers, (and a thread ID.) As you can see, for a single thread of control - there is one program counter, and one sequence of instructions that can be carried out at any given time and for multi-threaded applications-there are multiple threads within a single process, each having their own program counter, stack and set of registers, but sharing common code, data, and certain structures such as open files.
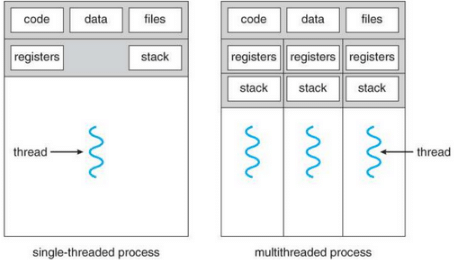
Option (A): as you can see in the above diagram, NOT ONLY CPU Register but stack and code files, data files are also maintained. So, option (A) is not correct as it says OS maintains only CPU register state.
Option (B): according to option (B), OS does not maintain a separate stack for each thread. But as you can see in above diagram, for each thread, separate stack is maintained. So this option is also incorrect.
Option (C): according to option (C), the OS does not maintain virtual memory state. And It is correct as Os does not maintain any virtual memory state for individual thread.
Option (D): according to option (D), the OS maintains only scheduling and accounting information. But it is not correct as it contains other information like cpu registers stack, program counters, data files, code files are also maintained.
Option (B): according to option (B), OS does not maintain a separate stack for each thread. But as you can see in above diagram, for each thread, separate stack is maintained. So this option is also incorrect.
Option (C): according to option (C), the OS does not maintain virtual memory state. And It is correct as Os does not maintain any virtual memory state for individual thread.
Option (D): according to option (D), the OS maintains only scheduling and accounting information. But it is not correct as it contains other information like cpu registers stack, program counters, data files, code files are also maintained.
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphorevoid P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}void V (binary_semaphore *s) {
S->value = 0;
}Which one of the following is true?- a)The implementation may not work if context switching is disabled in P.
- b)Instead of using fetch-and-set, a pair of normal load/store can be used
- c)The implementation of V is wrong
- d)The code does not implement a binary semaphore
Correct answer is option 'A'. Can you explain this answer?
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore
void P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
S->value = 0;
}
Which one of the following is true?
a)
The implementation may not work if context switching is disabled in P.
b)
Instead of using fetch-and-set, a pair of normal load/store can be used
c)
The implementation of V is wrong
d)
The code does not implement a binary semaphore
|
|
Parth Sen answered |
&(s->value);
do {
fetch_and_set(x, 1, y);
} while (y);
}
void V (binary_semaphore *s) {
s->value = 0;
}
In this implementation, the P function first gets the address of the value field of the binary semaphore using the "&" operator. Then, it uses a do-while loop to repeatedly call the fetch_and_set function with arguments x (the address of the value field), 1 (the new value to be set), and y (a variable to store the old value). The fetch_and_set function atomically sets the value field to 1 and returns the old value. The loop continues as long as the old value (stored in y) is not 0, indicating that the semaphore was already locked. Once the loop exits, the P function has successfully acquired the semaphore.
The V function simply sets the value field of the binary semaphore to 0, indicating that it is now available for other processes to acquire.
Overall, this implementation ensures that only one process can acquire the binary semaphore at a time, preventing multiple processes from accessing a shared resource simultaneously.
do {
fetch_and_set(x, 1, y);
} while (y);
}
void V (binary_semaphore *s) {
s->value = 0;
}
In this implementation, the P function first gets the address of the value field of the binary semaphore using the "&" operator. Then, it uses a do-while loop to repeatedly call the fetch_and_set function with arguments x (the address of the value field), 1 (the new value to be set), and y (a variable to store the old value). The fetch_and_set function atomically sets the value field to 1 and returns the old value. The loop continues as long as the old value (stored in y) is not 0, indicating that the semaphore was already locked. Once the loop exits, the P function has successfully acquired the semaphore.
The V function simply sets the value field of the binary semaphore to 0, indicating that it is now available for other processes to acquire.
Overall, this implementation ensures that only one process can acquire the binary semaphore at a time, preventing multiple processes from accessing a shared resource simultaneously.
A process executes the following codefor (i = 0; i < n; i++) fork();The total number of child processes created is- a)n
- b)2^n - 1
- c)2^n
- d)2^(n+1) - 1
Correct answer is option 'B'. Can you explain this answer?
A process executes the following code
for (i = 0; i < n; i++) fork();
The total number of child processes created is
a)
n
b)
2^n - 1
c)
2^n
d)
2^(n+1) - 1
|
|
Anshu Mehta answered |
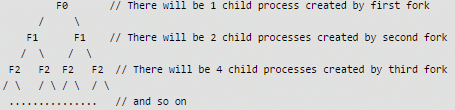
If we sum all levels of above tree for i = 0 to n-1, we get 2^n - 1. So there will be 2^n – 1 child processes. Also see this post for more details.
Consider a computer C1 has n CPUs and k processes. Which of the following statements are False?- a)The maximum number of processes in ready state is K.
- b)The maximum number of processes in block state is K.
- c)The maximum number of processes in running state is K.
- d)The maximum number of processes in running state is n.
Correct answer is option 'B,C'. Can you explain this answer?
Consider a computer C1 has n CPUs and k processes. Which of the following statements are False?
a)
The maximum number of processes in ready state is K.
b)
The maximum number of processes in block state is K.
c)
The maximum number of processes in running state is K.
d)
The maximum number of processes in running state is n.
|
|
Baishali Reddy answered |
Understanding Process States in a Multi-CPU Environment
In a computer system with n CPUs and k processes, various states exist for processes: ready, blocked, and running. Let's analyze the statements to identify which are false.
Statement A: Maximum Processes in Ready State
- The ready state represents processes that are prepared to run but are not currently executing.
- Since there can be many processes waiting, the maximum number of processes in the ready state is indeed k.
Statement B: Maximum Processes in Block State
- The blocked state comprises processes waiting for resources (like I/O operations) to become available.
- Unlike the ready state, there can be many processes blocked, but the number of blocked processes is not constrained by k in a direct manner.
- Processes can be blocked without necessarily competing for a CPU, meaning this statement is false.
Statement C: Maximum Processes in Running State
- The running state indicates processes currently being executed by CPUs.
- In a system with n CPUs, only n processes can be running simultaneously. Hence, the maximum number of processes in the running state is not k but n. This statement is false.
Statement D: Maximum Processes in Running State is n
- This statement accurately reflects the system's constraints, as only n CPUs can execute n processes at any given time.
Conclusion
- The false statements are B and C because:
- B incorrectly implies an upper limit on blocked processes based solely on k.
- C inaccurately suggests that k processes can run simultaneously when limited by the number of CPUs, n.
Understanding these distinctions is crucial in process management within operating systems.
In a computer system with n CPUs and k processes, various states exist for processes: ready, blocked, and running. Let's analyze the statements to identify which are false.
Statement A: Maximum Processes in Ready State
- The ready state represents processes that are prepared to run but are not currently executing.
- Since there can be many processes waiting, the maximum number of processes in the ready state is indeed k.
Statement B: Maximum Processes in Block State
- The blocked state comprises processes waiting for resources (like I/O operations) to become available.
- Unlike the ready state, there can be many processes blocked, but the number of blocked processes is not constrained by k in a direct manner.
- Processes can be blocked without necessarily competing for a CPU, meaning this statement is false.
Statement C: Maximum Processes in Running State
- The running state indicates processes currently being executed by CPUs.
- In a system with n CPUs, only n processes can be running simultaneously. Hence, the maximum number of processes in the running state is not k but n. This statement is false.
Statement D: Maximum Processes in Running State is n
- This statement accurately reflects the system's constraints, as only n CPUs can execute n processes at any given time.
Conclusion
- The false statements are B and C because:
- B incorrectly implies an upper limit on blocked processes based solely on k.
- C inaccurately suggests that k processes can run simultaneously when limited by the number of CPUs, n.
Understanding these distinctions is crucial in process management within operating systems.
Consider a system having 'm' resources of the same type. These resources are shared by 3 processes A, B, C, which have peak time demands of 3, 4, 6 respectively. The minimum value of ‘m’ that ensures that deadlock will never occur is
- a)13
- b)12
- c)11
- d)14
Correct answer is option 'A'. Can you explain this answer?
Consider a system having 'm' resources of the same type. These resources are shared by 3 processes A, B, C, which have peak time demands of 3, 4, 6 respectively. The minimum value of ‘m’ that ensures that deadlock will never occur is
a)
13
b)
12
c)
11
d)
14
|
|
Anisha Chavan answered |
M for which the system is deadlock-free is 9.
To determine the minimum value of m, we need to consider the worst-case scenario where all processes are requesting their peak time demands simultaneously.
In this case, process A requires 3 resources, process B requires 4 resources, and process C requires 6 resources. Therefore, the total number of resources required in the system is 3 + 4 + 6 = 13.
To avoid deadlock, the system should have enough resources to satisfy the maximum resource demand of any process. Therefore, the minimum value of m should be equal to or greater than 13.
However, since all processes are requesting their peak time demands simultaneously, it is possible for the system to enter a deadlock state if the number of available resources is exactly equal to the total resource demand.
Therefore, the minimum value of m for which the system is deadlock-free is m = 13 + 1 = 14.
However, since all resources in the system are of the same type, it is not possible to allocate fractional resources. Therefore, the minimum value of m should be an integer.
Therefore, the minimum value of m for which the system is deadlock-free is m = 14.
To determine the minimum value of m, we need to consider the worst-case scenario where all processes are requesting their peak time demands simultaneously.
In this case, process A requires 3 resources, process B requires 4 resources, and process C requires 6 resources. Therefore, the total number of resources required in the system is 3 + 4 + 6 = 13.
To avoid deadlock, the system should have enough resources to satisfy the maximum resource demand of any process. Therefore, the minimum value of m should be equal to or greater than 13.
However, since all processes are requesting their peak time demands simultaneously, it is possible for the system to enter a deadlock state if the number of available resources is exactly equal to the total resource demand.
Therefore, the minimum value of m for which the system is deadlock-free is m = 13 + 1 = 14.
However, since all resources in the system are of the same type, it is not possible to allocate fractional resources. Therefore, the minimum value of m should be an integer.
Therefore, the minimum value of m for which the system is deadlock-free is m = 14.
In a multi-user operating system, 20 requests are made to use a particular resource per hour, on an average. The probability that no requests are made in 45 minutes is- a)e-15
- b)e-5
- c)1 - e-5
- d)1 - e-10
Correct answer is option 'A'. Can you explain this answer?
In a multi-user operating system, 20 requests are made to use a particular resource per hour, on an average. The probability that no requests are made in 45 minutes is
a)
e-15
b)
e-5
c)
1 - e-5
d)
1 - e-10
|
|
Arpita Gupta answered |
The arrival pattern is a Poission distribution.
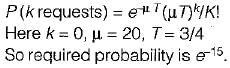
Suppose that a process is in ‘BLOCKED’ state waiting for some I/O service. When the service is completed, it goes to the- a)RUNNING state
- b)READY state
- c)SUSPENDED state
- d)TERMINATED state
Correct answer is option 'B'. Can you explain this answer?
Suppose that a process is in ‘BLOCKED’ state waiting for some I/O service. When the service is completed, it goes to the
a)
RUNNING state
b)
READY state
c)
SUSPENDED state
d)
TERMINATED state
|
|
Shivam Dasgupta answered |
When process in blocked state waiting for some I/O services, whenever the services is completed it goes in the ready queue of the ready state.
In which of the following scheduling policies doe context switching never take place?
1. Round-robin
2. Shortest job first(non pre-emptive)
3. Pre-emptive
4. First-cum-first-served- a)4 only
- b)1 and 3
- c)2 and 3
- d)2 and 4
Correct answer is option 'D'. Can you explain this answer?
In which of the following scheduling policies doe context switching never take place?
1. Round-robin
2. Shortest job first(non pre-emptive)
3. Pre-emptive
4. First-cum-first-served
1. Round-robin
2. Shortest job first(non pre-emptive)
3. Pre-emptive
4. First-cum-first-served
a)
4 only
b)
1 and 3
c)
2 and 3
d)
2 and 4
|
|
Mahi Datta answered |
Explanation:
In the given options, the scheduling policies are as follows:
1. Round-robin: In round-robin scheduling, each process is given a fixed time quantum to execute. When a time quantum expires, the currently executing process is preempted and moved to the end of the ready queue. This policy involves context switching as the processor switches between processes at regular intervals.
2. Shortest job first (non pre-emptive): In shortest job first scheduling, the process with the shortest burst time is executed first. Once a process starts execution, it is not preempted until it completes. Since there is no preemption, context switching does not occur in this policy.
3. Preemptive: Preemptive scheduling policies allow processes to be interrupted and moved out of the running state before they complete. This is usually based on priority or time quantum. Context switching is an essential part of preemptive scheduling as it involves moving the running process out and bringing another process in.
4. First-come-first-served: In first-come-first-served scheduling, the processes are executed in the order they arrive in the ready queue. Once a process starts execution, it is not preempted until it completes. Similar to shortest job first, there is no preemption in this policy, and hence, context switching does not occur.
Conclusion:
Considering the above explanations, the scheduling policies where context switching never takes place are:
- Shortest job first (non pre-emptive) - Option 2
- First-come-first-served - Option 4
Therefore, the correct answer is option 'D' - 2 and 4.
In the given options, the scheduling policies are as follows:
1. Round-robin: In round-robin scheduling, each process is given a fixed time quantum to execute. When a time quantum expires, the currently executing process is preempted and moved to the end of the ready queue. This policy involves context switching as the processor switches between processes at regular intervals.
2. Shortest job first (non pre-emptive): In shortest job first scheduling, the process with the shortest burst time is executed first. Once a process starts execution, it is not preempted until it completes. Since there is no preemption, context switching does not occur in this policy.
3. Preemptive: Preemptive scheduling policies allow processes to be interrupted and moved out of the running state before they complete. This is usually based on priority or time quantum. Context switching is an essential part of preemptive scheduling as it involves moving the running process out and bringing another process in.
4. First-come-first-served: In first-come-first-served scheduling, the processes are executed in the order they arrive in the ready queue. Once a process starts execution, it is not preempted until it completes. Similar to shortest job first, there is no preemption in this policy, and hence, context switching does not occur.
Conclusion:
Considering the above explanations, the scheduling policies where context switching never takes place are:
- Shortest job first (non pre-emptive) - Option 2
- First-come-first-served - Option 4
Therefore, the correct answer is option 'D' - 2 and 4.
Which of the following are real-time systems?
1. An on-line railway reservation system ,
2. A process control system
3. Aircraft control system
4. Payroll processing system- a)1 and 2
- b)3 and 4
- c)2 and 3
- d)1,2, 3 and 4
Correct answer is option 'C'. Can you explain this answer?
Which of the following are real-time systems?
1. An on-line railway reservation system ,
2. A process control system
3. Aircraft control system
4. Payroll processing system
1. An on-line railway reservation system ,
2. A process control system
3. Aircraft control system
4. Payroll processing system
a)
1 and 2
b)
3 and 4
c)
2 and 3
d)
1,2, 3 and 4
|
|
Nabanita Basak answered |
Real-time system are very fast and quick respondents systems. Response time of such systems is very low, to the tune of 10 ms or 100 ms or even less.
- Such systems are used where real-life scenario are being implemented like missile system, aircraft system extra.
- In process control system, the time quantum in reality is very less (to give a feel of multiprocessing so real time system is needed.
The state of a process after it encounters an I/O instruction is- a)ready
- b)blocked
- c)idle
- d)running
Correct answer is option 'B'. Can you explain this answer?
The state of a process after it encounters an I/O instruction is
a)
ready
b)
blocked
c)
idle
d)
running
|
|
Yash Patel answered |
Whenever a process is just created, it is kept in Ready queue. When it starts execution, it is in Running state, as soon as it starts doing input/output operation, it is kept in the blocked state.
Which of the following is an example of a SPOOLED device?- a)The terminal used to enter the input data for a program being executed.
- b)The secondary memory device in a virtual memory system.
- c)A line printer used to print the output of a no. of Jobs.
- d)One tries to divide a number by 0.
Correct answer is option 'C'. Can you explain this answer?
Which of the following is an example of a SPOOLED device?
a)
The terminal used to enter the input data for a program being executed.
b)
The secondary memory device in a virtual memory system.
c)
A line printer used to print the output of a no. of Jobs.
d)
One tries to divide a number by 0.
|
|
Malavika Banerjee answered |
Spool means simultaneous peri-pheral operations on line, a printer is a spooling device.
Consider the following statements with respect to user-level threads and Kernel-supported threads
(i) Context switching is faster with Kernel- supported threads.
(ii) For user-level threads, a system call can block the entire process.
(iii) Kernel-supported threads can be scheduled independently.
(iv) User-level threads are transparent to the Kernel.
Which of the above statements are true?- a)(ii), (iii), (iv) only
- b)(ii) and (iii) only
- c)(i) and (iii) only
- d)(i) and (ii) only
Correct answer is option 'B'. Can you explain this answer?
Consider the following statements with respect to user-level threads and Kernel-supported threads
(i) Context switching is faster with Kernel- supported threads.
(ii) For user-level threads, a system call can block the entire process.
(iii) Kernel-supported threads can be scheduled independently.
(iv) User-level threads are transparent to the Kernel.
Which of the above statements are true?
(i) Context switching is faster with Kernel- supported threads.
(ii) For user-level threads, a system call can block the entire process.
(iii) Kernel-supported threads can be scheduled independently.
(iv) User-level threads are transparent to the Kernel.
Which of the above statements are true?
a)
(ii), (iii), (iv) only
b)
(ii) and (iii) only
c)
(i) and (iii) only
d)
(i) and (ii) only
|
|
Suyash Chauhan answered |
Kernel level threads can be scheduled independently. For user level threads a system call can block the entire process and are not transparent to Kernel.
One of the disadvantages of user level threads compared to Kernel level threads is- a)If a user-level thread of a process executes a system call, all threads in that process are blocked.
- b)Scheduling is application dependent.
- c)Thread switching doesn’t require kernel mode privileges.
- d)The library procedures invoked for thread management in user level threads are local procedures.
Correct answer is option 'A'. Can you explain this answer?
One of the disadvantages of user level threads compared to Kernel level threads is
a)
If a user-level thread of a process executes a system call, all threads in that process are blocked.
b)
Scheduling is application dependent.
c)
Thread switching doesn’t require kernel mode privileges.
d)
The library procedures invoked for thread management in user level threads are local procedures.
|
|
Sanya Agarwal answered |
Advantage of User level thread:
1- Scheduling is application dependent.
2- Thread switching doesn’t require kernel mode privileges.
3- The library procedures invoked for thread management in user level threads are local procedures.
4- User level threads are fast to create and manage.
5- User level thread can run on any operating system.
Disadvantage of User-level thread:
1- Most system calls are blocked on a typical OS.
2- Multiprocessing is not supported for multi-threaded application.
So, Option (A) is correct.
Determine the number of page faults when references to pages occur in the order -1, 2,4, 5, 2,1,2, 4. Assume that the main memory can accommodate 3 pages and the main memory already has the pages 1 and 2, with page 1 having been brought earlier than page 2. (Assume LRU algorithm is used)- a)3
- b)5
- c)4
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
Determine the number of page faults when references to pages occur in the order -1, 2,4, 5, 2,1,2, 4. Assume that the main memory can accommodate 3 pages and the main memory already has the pages 1 and 2, with page 1 having been brought earlier than page 2. (Assume LRU algorithm is used)
a)
3
b)
5
c)
4
d)
None of the above
|
|
Aditya Nair answered |
1, 2, 4, 5, 2, 1 , 2 , 4
Since 1 and 2 are already in the memory which can accomodate 3 pages

Since 1 and 2 are already in the memory which can accomodate 3 pages
The address sequence generated by tracing a particular program executing in a pure demand paging system with 100 records per page, with 1 free main memory frame is recorded as follows. What is the number of page faults?
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370 - a)13
- b)8
- c)7
- d)10
Correct answer is option 'C'. Can you explain this answer?
The address sequence generated by tracing a particular program executing in a pure demand paging system with 100 records per page, with 1 free main memory frame is recorded as follows. What is the number of page faults?
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370
a)
13
b)
8
c)
7
d)
10
|
|
Sonal Nair answered |
When it tries to access 0100, it results in a page fault as the memory is empty right now. So, it loads the second page (which has the addresses 100 - 199). Trying to access 200 will result in a page fault, as it is not in memory right now. So the third page with the addresses from 200 to 299 will replace the second page in memory. Trying to access 430 will result in another page fault. Proceeding this way, we find trying to access the addresses 0510,0120,0220 and 0320 will all result in page faults. So, altogether 7 page faults.
Disk scheduling involves deciding- a)Which disk should be accessed next
- b)The order in which disk access requests must be serviced
- c)The physical location where files should be accessed in the disk
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Disk scheduling involves deciding
a)
Which disk should be accessed next
b)
The order in which disk access requests must be serviced
c)
The physical location where files should be accessed in the disk
d)
None of the above
|
|
Samarth Ghosh answered |
Disk scheduling manages the disk access and order of request to be fulfilled. It does not have the bounds in determining the physical location, where actually the files are stored.
Thrashing- a)Reduces page I/O
- b)Decreases the degree of multiprogramming
- c)Implies excessive page I/O
- d)Improves the system performance
Correct answer is option 'C'. Can you explain this answer?
Thrashing
a)
Reduces page I/O
b)
Decreases the degree of multiprogramming
c)
Implies excessive page I/O
d)
Improves the system performance
|
|
Rohan Shah answered |
When to increase multi-programming, a lot of processes are brought into memory. Then, what happens is, no process gets enough memory space and processor needs to keep bringing new pages into the memory to satisfy the requests. (A lot of page faults occurs). This process of excessive page replacements is called thrashing, which in turn reduces the overall performance.
There are five virtual pages, numbered from 0 to 4. The page are referenced in the following order
0 1 2 3 0 1 4 0 1 2 3 4
If FIFO page replacement algorithm is used then find:
1. Number of page replacement faults that occur if 3 page frames are present.
2. Number of page faults that occur if 4 page frames are present.- a)10,9
- b)9,10
- c)9, 8
- d)10,11
Correct answer is option 'B'. Can you explain this answer?
There are five virtual pages, numbered from 0 to 4. The page are referenced in the following order
0 1 2 3 0 1 4 0 1 2 3 4
If FIFO page replacement algorithm is used then find:
1. Number of page replacement faults that occur if 3 page frames are present.
2. Number of page faults that occur if 4 page frames are present.
0 1 2 3 0 1 4 0 1 2 3 4
If FIFO page replacement algorithm is used then find:
1. Number of page replacement faults that occur if 3 page frames are present.
2. Number of page faults that occur if 4 page frames are present.
a)
10,9
b)
9,10
c)
9, 8
d)
10,11
|
|
Vaibhav Banerjee answered |
If 3 page frames are used
Page hit : 0, 1, 4.
∴ Number of page fault = 9
If 4 pages frames are used
Page faults ; 0, 1, 2, 3, 4, 0, 1,2, 3, 4 Page hit : 0, 1
∴ Number of page faults = 10
Page hit : 0, 1, 4.
∴ Number of page fault = 9
If 4 pages frames are used
Page faults ; 0, 1, 2, 3, 4, 0, 1,2, 3, 4 Page hit : 0, 1
∴ Number of page faults = 10
Assume that 'C' is counting semaphore. Consider the following program segment:
C= 10;
P(C);
V(C);
P(C);
P(C);
P(C);
V(C);
P(C);
P(C);
What is the value of 'C' at the end of the above program execution?- a)2
- b)4
- c)6
- d)10
Correct answer is option 'C'. Can you explain this answer?
Assume that 'C' is counting semaphore. Consider the following program segment:
C= 10;
P(C);
V(C);
P(C);
P(C);
P(C);
V(C);
P(C);
P(C);
What is the value of 'C' at the end of the above program execution?
C= 10;
P(C);
V(C);
P(C);
P(C);
P(C);
V(C);
P(C);
P(C);
What is the value of 'C' at the end of the above program execution?
a)
2
b)
4
c)
6
d)
10
|
|
Sreemoyee Singh answered |
Number of P(C) wait process = 6 i.e. decrement
Number of V(C) signal process = 2 i.e. increment
Therefore value of ‘C’ at the end of program execution
= Initial value - Number of P(C) + Number of V(C)
= 10 - 6 + 2 = 6
= Initial value - Number of P(C) + Number of V(C)
= 10 - 6 + 2 = 6
Each process Pi, i = 1,2, 3,...., 9 is coded as
follows:
repeat
P (mutex)
{ critical section }
V (mutex)
forever
The code for P 10 is identical except that is uses V (mutex) instead of P (mutex). What is the largest number of processes that can be inside the critical section at any moment?- a)1
- b)2
- c)3
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
Each process Pi, i = 1,2, 3,...., 9 is coded as
follows:
repeat
P (mutex)
{ critical section }
V (mutex)
forever
The code for P 10 is identical except that is uses V (mutex) instead of P (mutex). What is the largest number of processes that can be inside the critical section at any moment?
follows:
repeat
P (mutex)
{ critical section }
V (mutex)
forever
The code for P 10 is identical except that is uses V (mutex) instead of P (mutex). What is the largest number of processes that can be inside the critical section at any moment?
a)
1
b)
2
c)
3
d)
None of the above
|
|
Garima Bose answered |
Let the mutex be initialized to 1. Any one of the 9 processes Pi, i = 1 , 2 , 3 , ... 9 can get into the critical section after executing P (mutex) which decrements the mutex value to 0. At this time P10 can enter into the critical section as it uses V (mutex) instead of P(mutex) to get into the critical section. As a result of this, mutex will be incremented by 1. Now any one of the 9 processes Pi, i — 1, 2 , 3 , ... 9 (excepting the one that is already inside the critical section) can get into the critical section after decrementing the mutex to 0. None of the remaining processes can get into the critical section.
If the mutex is initialized to 0, only 2 processes can get into the critical section. So the largest number of processes is 3.
If the mutex is initialized to 0, only 2 processes can get into the critical section. So the largest number of processes is 3.
Mutual exclusion problem occurs- a)Between two disjoint processes that do not interact.
- b)Among processes that share resources.
- c)Among processes that do not use the same resource.
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Mutual exclusion problem occurs
a)
Between two disjoint processes that do not interact.
b)
Among processes that share resources.
c)
Among processes that do not use the same resource.
d)
None of the above
|
|
Shruti Tiwari answered |
Whenever process shared the common data and resources, there is a chance of violating the consistency among the data. This problem which is related to the global data is known as mutual exclusion.
A process has been allocated 3 page frames. Assume that none of the pages of the process are available in the memory initially. The process makes the following sequence of page references (reference string): 1, 2, 1, 3, 7, 4, 5, 6, 3, 1 If optimal page replacement policy is used, how many page faults occur for the above reference string?- a)7
- b)8
- c)9
- d)10
Correct answer is option 'A'. Can you explain this answer?
A process has been allocated 3 page frames. Assume that none of the pages of the process are available in the memory initially. The process makes the following sequence of page references (reference string): 1, 2, 1, 3, 7, 4, 5, 6, 3, 1 If optimal page replacement policy is used, how many page faults occur for the above reference string?
a)
7
b)
8
c)
9
d)
10
|
|
Nilanjan Chavan answered |
Optimal replacement policy looks forward in time to see which frame to replace on a page fault. 1 23 -> 1,2,3 //page faults 173 ->7 143 ->4 153 -> 5 163 -> 6 Total=7
So Answer is A
So Answer is A
Consider a system with a two-level paging scheme in which a regular memory access takes 150 nanoseconds, and servicing a page fault takes 8 milliseconds. An average instruction takes 100 nanoseconds of CPU time, and two memory accesses. The TLB hit ratio is 90%, and the page fault rate is one in every 10,000 instructions. What is the effective average instruction execution time?- a)645 nanoseconds
- b)1050 nanoseconds
- c)1215 nanoseconds
- d)1230 nanoseconds
Correct answer is option 'D'. Can you explain this answer?
Consider a system with a two-level paging scheme in which a regular memory access takes 150 nanoseconds, and servicing a page fault takes 8 milliseconds. An average instruction takes 100 nanoseconds of CPU time, and two memory accesses. The TLB hit ratio is 90%, and the page fault rate is one in every 10,000 instructions. What is the effective average instruction execution time?
a)
645 nanoseconds
b)
1050 nanoseconds
c)
1215 nanoseconds
d)
1230 nanoseconds
|
|
Tarun Saini answered |
Figure : Translation Lookaside Buffer[5]
As shown in figure, to find frame number for corresponding page number, at first TLB (Translation Lookaside Buffer) is checked whether it has that desired page number- frame number pair entry or not, if yes then it’s TLB hit otherwise it’s TLB miss. In case of miss the page number is searched into page table. In two-level paging scheme, the memory is referred two times to obtain corresponding frame number.
• If a virtual address has no valid entry in the page table, then any attempt by your pro- gram to access that virtual address will cause a page fault to occur .In case of page fault, the required frame is brought in main memory from secondary memory,time taken to service the page fault is called page fault service time.
• We have to caculate average execution time(EXE), lets suppose average memory ac- cess time to fetch is M, then EXE = 100ns + 2*150 (two memory references to fetch instruction) + M ...1
• Now we have to calculate average memory access time M, since page fault is 1 in 10,000 instruction and then M = (1 − 1/104 )(M EM ) + (1/104) ∗ 8ms ...2
• Where MEM is memory access time when page is present in memory. Now we calcu- late MEM MEM = .9(TLB Access Time)+.1(TLB Access Time+2*150ns)
• Here TLB Acess Time is not given lets assume it 0. So MEM=.9(0)+.1(300ns) =30ns , put MEM value in equation(2). M = (1 − 1/104 )(30ns) + (1/104 ) ∗ 8ms = 830ns
• Put this M's value in equation(1), EXE=100ns+300ns+830ns=1230ns , so Ans is option(4).
Consider a 2-way set associative cache memory with 4 sets and total 8 cache blocks (0-7) and a main memory with 128 blocks (0-127). What memory blocks will be present in the cache after the following sequence of memory block references if LRU policy is used for cache block replacement. Assuming that initially the cache did not have any memory block from the current job? 0 5 3 9 7 0 16 55 - a)0 3 5 7 16 55
- b)0 3 5 7 9 16 55
- c)0 5 7 9 16 55
- d)3 5 7 9 16 55
Correct answer is option 'C'. Can you explain this answer?
Consider a 2-way set associative cache memory with 4 sets and total 8 cache blocks (0-7) and a main memory with 128 blocks (0-127). What memory blocks will be present in the cache after the following sequence of memory block references if LRU policy is used for cache block replacement. Assuming that initially the cache did not have any memory block from the current job? 0 5 3 9 7 0 16 55
a)
0 3 5 7 16 55
b)
0 3 5 7 9 16 55
c)
0 5 7 9 16 55
d)
3 5 7 9 16 55
|
|
Atharva Das answered |
2-way set associative cache memory, .i.e K = 2.
No of sets is given as 4, i.e. S = 4 ( numbered 0 - 3 )
No of blocks in cache memory is given as 8, i.e. N =8 ( numbered from 0 -7)
Each set in cache memory contains 2 blocks.
The number of blocks in the main memory is 128, i.e M = 128. ( numbered from 0 -127)
A referred block numbered X of the main memory is placed in the set numbered ( X mod S ) of the the cache memory. In that set, the
block can be placed at any location, but if the set has already become full, then the current referred block of the main memory should replace a block in that set according to some replacement policy. Here the replacement policy is LRU ( i.e. Least Recently Used block should be replaced with currently referred block).
X ( Referred block no ) and
the corresponding Set values are as follows:
X-->set no ( X mod 4 )
0--->0 ( block 0 is placed in set 0, set 0 has 2 empty block locations,
block 0 is placed in any one of them )
5--->1 ( block 5 is placed in set 1, set 1 has 2 empty block locations,
block 5 is placed in any one of them )
3--->3 ( block 3 is placed in set 3, set 3 has 2 empty block locations,
block 3 is placed in any one of them )
9--->1 ( block 9 is placed in set 1, set 1 has currently 1 empty block location,
block 9 is placed in that, now set 1 is full, and block 5 is the
least recently used block )
7--->3 ( block 7 is placed in set 3, set 3 has 1 empty block location,
block 7 is placed in that, set 3 is full now,
and block 3 is the least recently used block)
0--->block 0 is referred again, and it is present in the cache memory in set 0,
so no need to put again this block into the cache memory.
16--->0 ( block 16 is placed in set 0, set 0 has 1 empty block location,
block 0 is placed in that, set 0 is full now, and block 0 is the LRU one)
55--->3 ( block 55 should be placed in set 3, but set 3 is full with block 3 and 7,
hence need to replace one block with block 55, as block 3 is the least
recently used block in the set 3, it is replaced with block 55.
Hence the main memory blocks present in the cache memory are : 0, 5, 7, 9, 16, 55 .
(Note: block 3 is not present in the cache memory, it was replaced with block 55 )
A processor uses 2-level page tables for virtual to physical address translation. Page tables for both levels are stored in the main memory. Virtual and physical addresses are both 32 bits wide. The memory is byte addressable. For virtual to physical address translation, the 10 most significant bits of the virtual address are used as index into the first level page table while the next 10 bits are used as index into the second level page table. The 12 least significant bits of the virtual address are used as offset within the page. Assume that the page table entries in both levels of page tables are 4 bytes wide. Further, the processor has a translation look-aside buffer (TLB), with a hit rate of 96%. The TLB caches recently used virtual page numbers and the corresponding physical page numbers. The processor also has a physically addressed cache with a hit rate of 90%. Main memory access time is 10 ns, cache access time is 1 ns, and TLB access time is also 1 ns. Suppose a process has only the following pages in its virtual address space: two contiguous code pages starting at virtual address 0x00000000, two contiguous data pages starting at virtual address 0×00400000, and a stack page starting at virtual address 0×FFFFF000. The amount of memory required for storing the page tables of this process is:- a)8 KB
- b)12 KB
- c)16 KB
- d)20 KB
Correct answer is option 'C'. Can you explain this answer?
A processor uses 2-level page tables for virtual to physical address translation. Page tables for both levels are stored in the main memory. Virtual and physical addresses are both 32 bits wide. The memory is byte addressable. For virtual to physical address translation, the 10 most significant bits of the virtual address are used as index into the first level page table while the next 10 bits are used as index into the second level page table. The 12 least significant bits of the virtual address are used as offset within the page. Assume that the page table entries in both levels of page tables are 4 bytes wide. Further, the processor has a translation look-aside buffer (TLB), with a hit rate of 96%. The TLB caches recently used virtual page numbers and the corresponding physical page numbers. The processor also has a physically addressed cache with a hit rate of 90%. Main memory access time is 10 ns, cache access time is 1 ns, and TLB access time is also 1 ns. Suppose a process has only the following pages in its virtual address space: two contiguous code pages starting at virtual address 0x00000000, two contiguous data pages starting at virtual address 0×00400000, and a stack page starting at virtual address 0×FFFFF000. The amount of memory required for storing the page tables of this process is:
a)
8 KB
b)
12 KB
c)
16 KB
d)
20 KB
|
|
Hrishikesh Unni answered |
Breakup of given addresses into bit form:- 32bits are broken up as 10bits (L2) | 10bits (L1) | 12bits (offset)
first code page:
0x00000000 = 0000 0000 00 | 00 0000 0000 | 0000 0000 0000
so next code page will start from 0x00001000 = 0000 0000 00 | 00 0000 0001 | 0000 0000 0000
first data page:
0x00400000 = 0000 0000 01 | 00 0000 0000 | 0000 0000 0000
so next data page will start from 0x00401000 = 0000 0000 01 | 00 0000 0001 | 0000 0000 0000
only one stack page:
0xFFFFF000 = 1111 1111 11 | 11 1111 1111 | 0000 0000 0000
Now, for second level page table, we will just require 1 Page which will contain following 3 distinct entries i.e. 0000 0000 00, 0000 0000 01, 1111 1111 11. Now, for each of these distinct entries, we will have 1-1 page in Level-1.
Hence, we will have in total 4 pages and page size = 2^12 = 4KB.
Therefore, Memory required to store page table = 4*4KB = 16KB.
first code page:
0x00000000 = 0000 0000 00 | 00 0000 0000 | 0000 0000 0000
so next code page will start from 0x00001000 = 0000 0000 00 | 00 0000 0001 | 0000 0000 0000
first data page:
0x00400000 = 0000 0000 01 | 00 0000 0000 | 0000 0000 0000
so next data page will start from 0x00401000 = 0000 0000 01 | 00 0000 0001 | 0000 0000 0000
only one stack page:
0xFFFFF000 = 1111 1111 11 | 11 1111 1111 | 0000 0000 0000
Now, for second level page table, we will just require 1 Page which will contain following 3 distinct entries i.e. 0000 0000 00, 0000 0000 01, 1111 1111 11. Now, for each of these distinct entries, we will have 1-1 page in Level-1.
Hence, we will have in total 4 pages and page size = 2^12 = 4KB.
Therefore, Memory required to store page table = 4*4KB = 16KB.
Chapter doubts & questions for Operating System - GATE Computer Science Engineering(CSE) 2026 Mock Test Series 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Operating System - GATE Computer Science Engineering(CSE) 2026 Mock Test Series in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up within 7 days!
Access 1000+ FREE Docs, Videos and Tests
Takes less than 10 seconds to signup