Thrashing & Spooling | Operating System - Computer Science Engineering (CSE) PDF Download
Techniques to Handle Thrashing
Thrashing is a condition or a situation when the system is spending a major portion of its time in servicing the page faults, but the actual processing done is very negligible.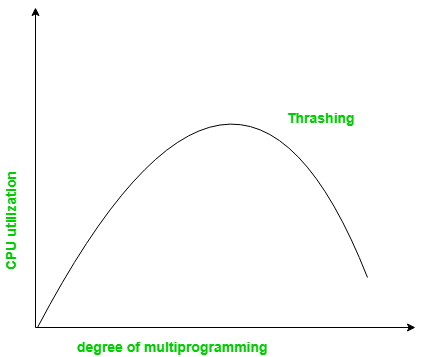
The basic concept involved is that if a process is allocated too few frames, then there will be too many and too frequent page faults. As a result, no useful work would be done by the CPU and the CPU utilisation would fall drastically. The long-term scheduler would then try to improve the CPU utilisation by loading some more processes into the memory thereby increasing the degree of multiprogramming. This would result in a further decrease in the CPU utilization triggering a chained reaction of higher page faults followed by an increase in the degree of multiprogramming, called Thrashing.
Locality Model:
A locality is a set of pages that are actively used together. The locality model states that as a process executes, it moves from one locality to another. A program is generally composed of several different localities which may overlap.
For example when a function is called, it defines a new locality where memory references are made to the instructions of the function call, it’s local and global variables, etc. Similarly, when the function is exited, the process leaves this locality.

Techniques to Handle
1. Working Set Model
This model is based on the above-stated concept of the Locality Model. The basic principle states that if we allocate enough frames to a process to accommodate its current locality, it will only fault whenever it moves to some new locality. But if the allocated frames are lesser than the size of the current locality, the process is bound to thrash.
According to this model, based on a parameter A, the working set is defined as the set of pages in the most recent ‘A’ page references. Hence, all the actively used pages would always end up being a part of the working set.
The accuracy of the working set is dependant on the value of parameter A. If A is too large, then working sets may overlap. On the other hand, for smaller values of A, the locality might not be covered entirely.
If D is the total demand for frames and WSSi is the working set size for a process i, D= ΣWSSi
Now, if ‘m’ is the number of frames available in the memory, there are 2 possibilities:
- D > m i.e. total demand exceeds the number of frames, then thrashing will occur as some processes would not get enough frames.
- D <= m, then there would be no thrashing.
If there are enough extra frames, then some more processes can be loaded in the memory. On the other hand, if the summation of working set sizes exceeds the availability of frames, then some of the processes have to be suspended(swapped out of memory).
This technique prevents thrashing along with ensuring the highest degree of multiprogramming possible. Thus, it optimizes CPU utilisation.
2. Page Fault Frequency:
A more direct approach to handle thrashing is the one that uses Page-Fault Frequency concept.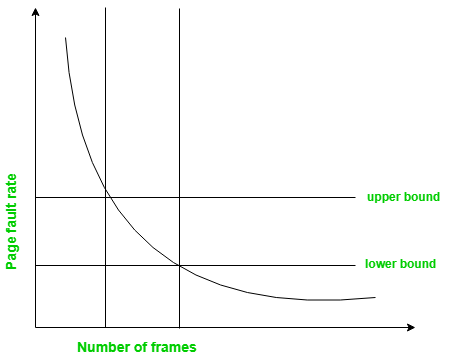
The problem associated with Thrashing is the high page fault rate and thus, the concept here is to control the page fault rate.
If the page fault rate is too high, it indicates that the process has too few frames allocated to it. On the contrary, a low page fault rate indicates that the process has too many frames.
Upper and lower limits can be established on the desired page fault rate as shown in the diagram.
If the page fault rate falls below the lower limit, frames can be removed from the process. Similarly, if the page fault rate exceeds the upper limit, more number of frames can be allocated to the process.
In other words, the graphical state of the system should be kept limited to the rectangular region formed in the given diagram.
Here too, if the page fault rate is high with no free frames, then some of the processes can be suspended and frames allocated to them can be reallocated to other processes. The suspended processes can then be restarted later.
What exactly Spooling is all about?
SPOOL is an acronym for simultaneous peripheral operations on-line. It is a kind of buffering mechanism or a process in which data is temporarily held to be used and executed by a device, program or the system. Data is sent to and stored in memory or other volatile storage until the program or computer requests it for execution.
In a computer system peripheral equipments, such as printers and punch card readers etc (batch processing), are very slow relative to the performance of the rest of the system. Getting input and output from the system was quickly seen to be a bottleneck. Here comes the need for spool.
Spooling works like a typical request queue where data, instructions and processes from multiple sources are accumulated for execution later on. Generally, it is maintained on computer’s physical memory, buffers or the I/O device-specific interrupts. The spool is processed in FIFO manner i.e. whatever first instruction is there in the queue will be popped and executed.
 |
Download the notes
Thrashing & Spooling
|
Download as PDF |
Applications/Implementations of Spool
- The most common can be found in I/O devices like keyboard printers and mouse. For example, In printer, the documents/files that are sent to the printer are first stored in the memory or the printer spooler. Once the printer is ready, it fetches the data from the spool and prints it.
Even experienced a situation when suddenly for some seconds your mouse or keyboard stops working? Meanwhile, we usually click again and again here and there on the screen to check if its working or not. When it actually starts working, what and wherever we pressed during its hang state gets executed very fast because all the instructions got stored in the respective device’s spool. - A batch processing system uses spooling to maintain a queue of ready-to-run jobs which can be started as soon as the system has the resources to process them.
- Spooling is capable of overlapping I/O operation for one job with processor operations for another job. i.e. multiple processes can write documents to a print queue without waiting and resume with their work.
- E-mail: an email is delivered by a MTA (Mail Transfer Agent) to a temporary storage area where it waits to be picked up by the MA (Mail User Agent)
- Can also be used for generating Banner pages (these are the pages used in computerized printing in order to separate documents from each other and to identify example: the originator of the print request by username, an account number or a bin for pickup. Such pages are used in office environments where many people share the small number of available resources).
 |
Take a Practice Test
Test yourself on topics from Computer Science Engineering (CSE) exam
|
Practice Now |
Difference between Spooling and Buffering
There are two ways by which Input/output subsystems can improve the performance and efficiency of the computer by using a memory space in the main memory or on the disk and these two are spooling and buffering.
Spooling: Spooling stands for Simultaneous peripheral operation online. A spool is similar to buffer as it holds the jobs for a device until the device is ready to accept the job. It considers disk as a huge buffer that can store as many jobs for the device till the output devices are ready to accept them.
Buffering: The main memory has an area called buffer that is used to store or hold the data temporarily that is being transmitted either between two devices or between a device or an application. Buffering is an act of storing data temporarily in the buffer. It helps in matching the speed of the data stream between the sender and the receiver. If the speed of the sender’s transmission is slower than the receiver, then a buffer is created in the main memory of the receiver, and it accumulates the bytes received from the sender and vice versa.
The basic difference between Spooling and Buffering is that Spooling overlaps the input/output of one job with the execution of another job while the buffering overlaps the input/output of one job with the execution of the same job.
Differences between Spooling and Buffering
- The key difference between spooling and buffering is that Spooling can handle the input/output of one job along with the computation of another job at the same time while buffering handles input/output of one job along with its computation.
- Spooling stands for Simultaneous Peripheral Operation online. Whereas buffering is not an acronym.
- Spooling is more efficient than buffering, as spooling can overlap processing two jobs at a time.
- Buffering uses limited area in main memory while Spooling uses the disk as a huge buffer.
Comparison chart

|
10 videos|104 docs|33 tests
|



video lectures
,Sample Paper
,Thrashing & Spooling | Operating System - Computer Science Engineering (CSE)
,mock tests for examination
,study material
,Exam
,shortcuts and tricks
,ppt
,MCQs
,Objective type Questions
,practice quizzes
,Semester Notes
,Thrashing & Spooling | Operating System - Computer Science Engineering (CSE)
,past year papers
,Free
,Viva Questions
,Extra Questions
,Important questions
,Summary
,Previous Year Questions with Solutions
,Thrashing & Spooling | Operating System - Computer Science Engineering (CSE)
;


Thrashing & Spooling Free PDF Download
Importance of Thrashing & Spooling
Thrashing & Spooling Notes
Thrashing & Spooling Computer Science Engineering (CSE) Questions
Study Thrashing & Spooling on the App
|
© EduRev
|
Education Revolution
|



|





