Priority CPU Scheduling | Operating System - Computer Science Engineering (CSE) PDF Download

Overview
Priority scheduling in OS is the scheduling algorithm which schedules processes according to the priority assigned to each of the processes. Higher priority processes are executed before lower priority processes.
Scope
This article talks about the basic concepts of priority scheduling and it's two types
- Preemptive
- Non-preemptive.
It does not contain implementation of the scheduling algorithm in any programming language.
What is Priority Scheduling Algorithm?
The Operating System has a major function of deciding the order in which processes / tasks will have access to the processor and the amount of processing time each of these processes or tasks will have. This function of the operating system is termed as process scheduling.
Under process scheduling, the tasks that the operating system performs are:
- Keeping track of the status of the processes
- Allocation of processor to processes
- De-allocation of processor to processes.
All these processes are stored by the operating system in a process table along with an ID alloted to every process (PID), to help keep track of all of them. And, to keep track of their current state the operating system uses a Process Control Block (PCB). The information is updated in the control block as and when the state of the process changes.
But did you wonder what is the criteria that the Operating System uses for the scheduling of these processes? Which process must be allocated with CPU resources first? Well, there are multiple ways in which the Operating System takes these decisions such as execution of the process that takes the least time first, or execution according to the order in which they requested access to the processor and so on. One such important criteria is the priority of the process.
In priority scheduling in OS, processes are executed on the basis of their priority. The jobs / processes with higher priority are executed first. Naturally, you might want to know how priority of processes is decided.
Priority of processes depends some factors such as:
- Time limit
- Memory requirements of the process
- Ratio of average I/O to average CPU burst time
There can be more factors on the basis of which priority of a process / job is determined. This priority is assigned to the processes by the scheduler.
These priorities of processes are represented as simple integers in a fixed range such as 0 to 7, or maybe 0 to 4095. These numbers depend on the type of systems.
Now that we know that each job is assigned a priority on the basis of which it is scheduled, we can move ahead with it's working and types.
Types of Priority Scheduling algorithm
There are two types of priority scheduling algorithm in OS:
Non-Preemptive Scheduling
In this type of scheduling:
- If during the execution of a process, another process with a higher priority arrives for execution, even then the currently executing process will not be disturbed.
- The newly arrived high priority process will be put in next for execution since it has higher priority than the processes that are in waiting state for execution.
- All the other processes will remain in the waiting queue to be processes. Once the execution of the current process is done, the high priority process will be given the CPU for execution.
Preemptive Scheduling
Preemptive Sheduling as opposed to non-preemptive scheduling will preempt (stop and store the currently executing process) the currently running process if a higher priority process enters the waiting state for execution and will execute the higher priority process first and then resume executing the previous process.
Characteristics of Priority Scheduling Algorithm:
- It is a scheduling algorithm that schedules the incoming processes on the basis of the priority.
- Operating systems use it for performing batch processes
- If there exist two jobs / processes in the ready state (ready for execution) that have the same priority, then priority scheduling executed the processes on first come first serve basis. For every job that exists, we have a priority number assigned to it that indicates its priority level.
- If the integer value of the priority number is low, it means that the process has higher priority. (low number = high priority).
Example of Priority Scheduling algorithm:
You've now understood the basics of priority scheduling in os. Let's better your understanding with an example of preemptive scheduling.
Consider five processes from P1 to P5, with their priority, burst time, and arrival time. If you aren't familiar with the terms burst and arrival time, please Google them! We're going to represent these values associated with these processes in a table.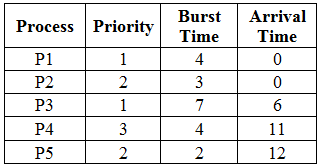
Let's apply whatever we learnt about priority scheduling algorithm. Which process do you think will be executed first? Remember, lower the number, higher the priority. We'll use a gantt chart to keep track of the time, and to check if a process must be preempted.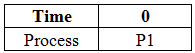
Of course, the processes that arrive first i.e. at time = 0 will be considered for execution first, which are P1 and P2. The priority of process P1 is higher than P2, and hence it will be executed first.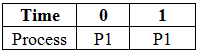
At time = 1, we do not have any new processes arriving, and process P1 continues to execute, and this goes on till time = 4 and that's when the process has finished its execution.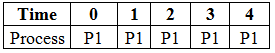
All this while, process P2 was in the waiting queue. Once the execution of process P1 is complete, we pick the next process in the waiting queue according to priority regardless of the arrival time. However, there's just one process in the waiting queue, so we start the execution of process P2 which has a burst time of 3.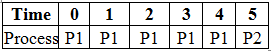
At time = 5, process P2 is still executing and the burst time remaining is 2. At time = 6, we see that another process arrives in the waiting queue. The first thing that we need to check is the priority and since the priority of process P3 is greater than P2 we must preempt the current process and start the execution of P3, keeping P2 in ready queue with a remaining burst time of 1 (it already executed for 2 seconds).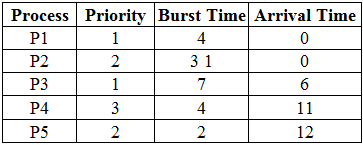
 The process P3 has a burst time of 7, and will obviously continue to execute till another process with a higher priority comes in. At time = 11, another process P4 comes in, but has a priority less than that of P3 and hence P3 will continue to execute with 2 units remaining.
The process P3 has a burst time of 7, and will obviously continue to execute till another process with a higher priority comes in. At time = 11, another process P4 comes in, but has a priority less than that of P3 and hence P3 will continue to execute with 2 units remaining.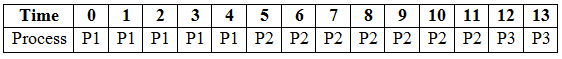
P3 will execute till time = 13. We now go to our waiting queue to check for processes. Remember that we pick processes with higher priority that arrived first. In our waiting queue, we have processes P2, P4 and P5. We see that P2 and P5 have equal priorities but since the arrival time of P2 is before that of process P5, we must execute process P2 first.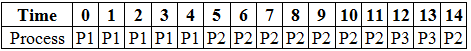
P2 just has one unit time of processing left as we had preempted the process to run P3. At time = 14 P2 process completes it's execution. Again, we look for a process from the waiting queue that can be executed. In the waiting queue we have P4 and P5. Since P5 has the higher priority, we start its execution.
The burst time of process P5 is 2, and hence it completes its execution at time = 16. Now, the only remaining process is process P4, and at time = 16 it starts its execution. Since the burst time of process P4 is 4, and there are no more processes in the waiting queue, and no new processes with higher priority have arrived, P4 continues and completes its execution by time = 20.
You have now understood the working of preemptive priority scheduling in os! Moving on, let's take a look at it's advantages and disadvantages.
Advantages of Priority Scheduling Algorithm
- High priority processes do not have to wait for their chance to be executed due to the current running process.
- We are able to define the relative importance / priority of processes.
- The applications in which the requirements of time and resources fluctuate are useful.
Disadvantages of Priority Scheduling Algorithm
- Since we only execute high priority processes, this can lead to starvation of the processes that have a low priority. Starvation is the phenomenon in which a process gets infinitely postponed because the resources that are required by the process are never allocated to it, since other processes are executed before it. You can research more about starvation on Google.
- If the system eventually crashes, all of the processes that have low priority will get lost since they are stored in the RAM.
Static and Dynamic Priority
When we were learning about priorities being given to proceses, did you ponder about how the priorities were assigned to the process in the first place? Or rather, when was the priority assigned to the process?
In priority based scheduling, we saw that it could be implemented in two ways - preemptive and non-preemptive with the most common implementation being preemptive priority based scheduling. The same way, it can be categorized again on the basis of the method by which the priorities to processes are assigned.
The two classifications are:
- Static priority
- Dynamic priority
The Static Priority algorithm, assigns priorities to processes at design time, and these assigned priorities do not change, they remain constant for the lifetime of that process. However in the dynamic priority algorithm, the priorities are assigned to the processes at run time and this assignment is based on the execution parameters of the processes such as upcoming deadlines.
Of course, the static priority algorithms are simpler than the dynamic priority algorithms. There are other scheduling algorithms, like multilevel queues and multilevel feedback queues scheduling which are important for a system that provides better performance. Let's take a quick look into them.
Multilevel Queues
When we have multiple processes in the ready queue, there are times when there are similar processes in the waiting queue. Similar how? For example, the processes could be interactive or batch processes, and due to their divergent response time requirements, they would have dissimilar scheduling needs. It makes sense if these similar processes are classified into groups.
This is called multilevel queue scheduling. We have different queues for different processes that have different scheduling requirements. For example, for system processes, we can have a separate queue which schedules them according to FCFS method. Interactive processes will have their queue and could be scheduled using SJF scheduling method and so on. These queues have their own priorities as well, and hence known as multilevel queue scheduling.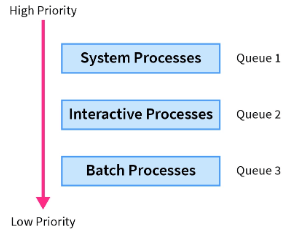
Multilevel Feedback Queues
Multilevel feedback queues are just like the multilevel queues, with one slight difference. If a process is part of Queue 1 in multilevel queue scheduling, then the process cannot switch and move into another queue. But here, it can. This scheduling continues to analyze the time of execution of processes and makes the switch between processes in different queues accordingly, hence the name feedback queues.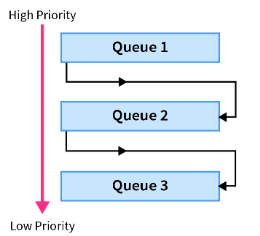
This kind of scheduling in much more flexible than the basic multilevel queue scheduling, and they also reduce the response time. However, the processes in lower priority queues might suffer from starvation in this scheduling method.
Conclusion
- Priority based scheduling in operating systems is the scheduling of processes based on their priority.
- This priority depends on factors such as time limit, memory requirements of the process and ratio of average I/O to average CPU burst time.
- There are mainly two types of priority scheduling -- non-preemptive (where another process can only be executed once the current process is done executing) and preemptive (where a higher priority process pauses the current running process and completes its execution first).
- The main disadvantage of priority scheduling is that lower priority processes can suffer from starvation.
- Priorities of processes can be decided in two ways - static or dynamic.
- There are more types of scheduling such as multilevel queues and multilevel feedback queues which essentially group similar processes and have separate queues for them so that they can follow different scheduling algorithms.
|
10 videos|141 docs|33 tests
|



Sample Paper
,video lectures
,Priority CPU Scheduling | Operating System - Computer Science Engineering (CSE)
,Summary
,past year papers
,Priority CPU Scheduling | Operating System - Computer Science Engineering (CSE)
,Objective type Questions
,ppt
,practice quizzes
,shortcuts and tricks
,Priority CPU Scheduling | Operating System - Computer Science Engineering (CSE)
,study material
,Semester Notes
,mock tests for examination
,Previous Year Questions with Solutions
,Extra Questions
,Free
,Viva Questions
,Important questions
,MCQs
,Exam
,


Priority CPU Scheduling Free PDF Download
Importance of Priority CPU Scheduling
Priority CPU Scheduling Notes
Priority CPU Scheduling Computer Science Engineering (CSE) Questions
Study Priority CPU Scheduling on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!