ASCII & Alphanumeric Codes | Digital Circuits - Electronics and Communication Engineering (ECE) PDF Download

Introduction
The ASCII stands for American Standard Code for Information Interchange. The ASCII code is an alphanumeric code used for data communication in digital computers. The ASCII is a 7-bit code capable of representing 27 or 128 number of different characters. The ASCII code is made up of a three-bit group, which is followed by a four-bit code.
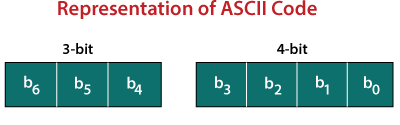
- The ASCII Code is a 7 or 8-bit alphanumeric code.
- This code can represent 127 unique characters.
- The ASCII code starts from 00h to 7Fh. In this, the code from 00h to 1Fh is used for control characters, and the code from 20h to 7Fh is used for graphic symbols.
- The 8-bit code holds ASCII, which supports 256 symbols where math and graphic symbols are added.
- The range of the extended ASCII is 80h to FFh.
The ASCII characters are classified into the following groups:
Control Characters
- The non-printable characters used for sending commands to the PC or printer are known as control characters. We can set tabs, and line breaks functionality by this code. The control characters are based on telex technology. Nowadays, it's not so much popular in use. The character from 0 to 31 and 127 comes under control characters.
Special Characters
- All printable characters that are neither numbers nor letters come under the special characters. These characters contain technical, punctuation, and mathematical characters with space also. The character from 32 to 47, 58 to 64, 91 to 96, and 123 to 126 comes under this category.
Numbers Characters
- This category of ASCII code contains ten Arabic numerals from 0 to 9.
Letters Characters
- In this category, two groups of letters are contained, i.e., the group of uppercase letters and the group of lowercase letters. The range from 65 to 90 and 97 to 122 comes under this category.
ASCII Table
The values are typically represented in ASCII code tables in decimal, binary, and hexadecimal form.

Example 1: (10010101100001111011011000011010100111000011011111101001 110111011101001000000011000101100100110011)2
Step 1: In the first step, we we make the groups of 7-bits because the ASCII code is 7 bit.
1001010 1100001 1110110 1100001 1010100 1110000 1101111 1101001 1101110 1110100 1000000 0110001 0110010 0110011
Step 2: Then, we find the equivalent decimal number of the binary digits either from the ASCII table or 64 32 16 8 4 2 1 scheme.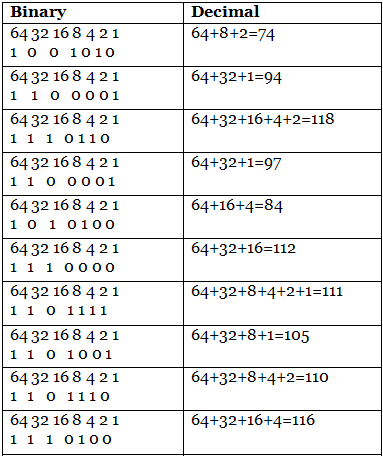
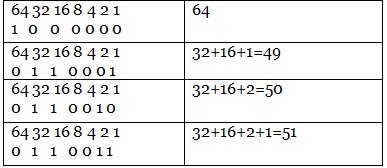 Step 3: Last, we find the equivalent symbol of the decimal number from the ASCII table.
Step 3: Last, we find the equivalent symbol of the decimal number from the ASCII table.
Alphanumeric Codes
Computers started as machines for doing math, but now they do much more—like handling names, addresses, and other information made of letters, numbers, and symbols. Since computers only understand 1s and 0s, we use alphanumeric codes (also called character codes) to turn letters and symbols into binary (1s and 0s) that computers can process. These codes let us use keyboards, screens, printers, and other devices with computers.
Over time, different codes were created to do this. Some old ones, like Morse code and Hollerith code, aren’t used much anymore. Today, the most popular codes are ASCII, EBCDIC, and Unicode. Let’s look at them in simple terms.
Computers were originally built just for math, solving equations and crunching numbers. But today, they manage all sorts of things—like names, addresses, and descriptions—using letters, numbers, and symbols. Since computers only understand 1s and 0s, we rely on character encoding systems, sometimes called alphanumeric codes, to translate human language into binary. These codes make it possible to type on a keyboard, read text on a screen, or print a page. Over the years, people invented different ways to do this, starting with early methods like Morse code and moving to modern ones like Unicode. Let’s explore them in an easy way.
Morse Code
Morse code was the pioneer, dreamed up in 1837 by Samuel Morse for telegraphs. It turned letters and numbers into patterns of short dots and long dashes, letting operators tap out messages across wires. It was a huge leap for communication back then, connecting far-off places before phones existed. Even now, it hangs on in niche spots—radio hobbyists, pilots, and air traffic controllers use it for quick signals. The catch? Its codes vary in length, which made it tough for fancy new machines to handle, so it’s not the star it once was.
Baudot Code
Then came Baudot code in 1870, named after Emile Baudot, a French telegraph whiz. This one was smoother than Morse, giving every character five bits—five 1s or 0s—so they all lined up evenly. That consistency helped telegraph machines send Roman letters, punctuation, and a few extra signals without hiccups. It was a solid upgrade for its era, making communication faster and more reliable. But as computers took over from telegraphs, Baudot couldn’t keep pace with the need for more characters, and newer codes pushed it aside.
Hollerith Code
By the 1890s, Herman Hollerith stepped in with a 12-bit code tied to punched cards. He started a company that grew into IBM, and his system was a hit for early data tasks—like tallying census numbers or tracking payroll. The idea was to punch holes in cards to store information, and machines would read them. It powered computing for a long time, but when storage shifted to tapes and disks, punched cards faded away. With them went the Hollerith code, now just a memory from tech’s past.
ASCII (American Standard Code for Information Interchange)
ASCII hit the scene in 1967, and it’s been a champ ever since—pronounced "as-kee" for short. This 7-bit code covers 128 characters, enough for English letters (big and small), numbers, and symbols like plus signs or question marks. An 8-bit version stretches it to 256 characters, tossing in extras or error checks. It’s the backbone of personal computers, letting you type "hello" or see "123" onscreen. Starting from telegraph roots, it got a big refresh by 1986 and now runs everything from laptops to printers, a true everyday hero.
EBCDIC (Extended Binary Coded Decimal Interchange Code)
IBM took a different road with EBCDIC—say it "eb-see-dick"—an 8-bit code from the 1960s. It also fits 256 characters, but it’s built its own way, especially for numbers, unlike ASCII’s style. It’s the loyal sidekick to IBM’s big machines, like the mainframes that banks or airlines lean on. While ASCII went global, EBCDIC stayed in IBM’s corner, quietly doing its job. It’s not as famous, but it’s still kicking where IBM tech lives on.
Unicode
Unicode showed up later to fix what ASCII and EBCDIC couldn’t handle. With 16 bits, it covers 65,536 characters—think every language from English to Japanese, plus math signs and emojis. Older codes struggled beyond English and sometimes clashed, but Unicode sorts it all out. It’s the go-to for today’s tech—Windows, Macs, the web, and apps all use it. Big players like Microsoft, Apple, and Google jumped on board, making it the key to a world where everyone’s words can fit onscreen.
Character encoding systems turn letters and symbols into 1s and 0s for computers. Morse kicked it off with dots and dashes, Baudot streamlined telegraphs with 5-bit codes, and Hollerith punched data into cards. Now, ASCII powers personal computers, EBCDIC hangs with IBM, and Unicode tackles everything worldwide. They’ve each had their moment, but Unicode’s the one carrying us into tomorrow!
|
76 videos|175 docs|70 tests
|
FAQs on ASCII & Alphanumeric Codes - Digital Circuits - Electronics and Communication Engineering (ECE)
| 1. What is ASCII code and why is it important in computer science? |  |
| 2. How does ASCII differ from Unicode? | |
| 3. What are some common applications of ASCII code in programming? | |
| 4. How can I convert a string to ASCII values in a programming language? | |
| 5. Are there any limitations to using ASCII code? | |



shortcuts and tricks
,Viva Questions
,ASCII & Alphanumeric Codes | Digital Circuits - Electronics and Communication Engineering (ECE)
,study material
,practice quizzes
,Previous Year Questions with Solutions
,Extra Questions
,Exam
,MCQs
,Objective type Questions
,Sample Paper
,Important questions
,ppt
,mock tests for examination
,Semester Notes
,video lectures
,Free
,ASCII & Alphanumeric Codes | Digital Circuits - Electronics and Communication Engineering (ECE)
,ASCII & Alphanumeric Codes | Digital Circuits - Electronics and Communication Engineering (ECE)
,past year papers
,Summary
;






ASCII & Alphanumeric Codes Free PDF Download
Importance of ASCII & Alphanumeric Codes
ASCII & Alphanumeric Codes Notes
ASCII & Alphanumeric Codes Electronics and Communication Engineering (ECE) Questions
Study ASCII & Alphanumeric Codes on the App
|
© EduRev
|
Education Revolution
|



|





