Previous Year Questions: Parsing | Compiler Design - Computer Science Engineering (CSE) PDF Download

Q1: Consider the following grammar G G, with S S as the start symbol. The grammar G G has three incomplete productions denoted by (1), (2), and (3). (2024 SET 1)
S → d a T | ( 1 )
T → a S |b T | ( 2 )
R → (3) ∣ ϵ
The set of terminals is { a , b , c , d , f } . The FIRST and FOLLOW sets of the different non-terminals are as follows.
FIRST ( S ) = { c , d , f } , FIRST ( T ) = { a , b , ϵ } , FIRST ( R ) = { c , ϵ }
FOLLOW ( S ) = FOLLOW ( T ) = { c , f , $ } , FOLLOW ( R ) = { f }
Which one of the following options CORRECTLY fills in the incomplete productions?
(a) (1) S→ Rf (2) T → ϵ (3) R→ cTR
(b) (1) S→ fR (2) T → ϵ (3) R→ cTR
(c) (1) S→ fR (2) T → cT (3) R→ cR
(d) (1) S→ Rf (2) T → ϵ (3) R→ c R
Ans: (a)
Sol: Option ( C , D ) is incorrect as if we substitute T → c T in ( 2 ) it gives
F I R S T ( T ) = a , b , c which is wrong because in question it is given that
F I R S T ( T ) = a , b , ϵ
Option ( B ) is incorrect as if we substitute S → f R in ( 1 ) it gives
F I R S T ( S ) = f , d which is wrong because terminal c is missing.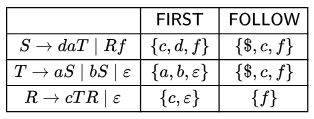 So correct Option is (A).
So correct Option is (A).
Q2: Which of the following is/are Bottom-Up Parser(s)? (2024 SET 1)
(a) Shift-reduce Parser
(b) Predictive Parser
(c) LL(1) Parser
(d) LR Parser
Ans: (a, d)
Sol: 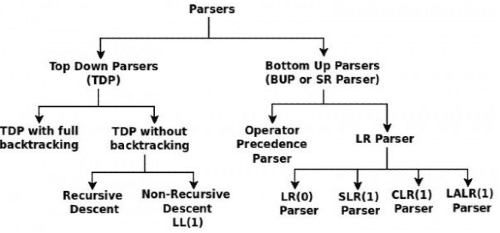
From the above classifications of parsers, it is clear that LR(k) and shift-reduce parse are types of bottom-up parsers while LL(1) and recursive descent parsers belong to top-down parsers.
Option (A,D) is correct.
Q3: Consider the following grammar along with translation rules. (2022)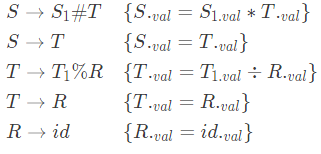 Here # # and % % are operators and i d is a token that represents an integer and i d . val represents the corresponding integer value. The set of non-terminals is { S , T , R , P } and a subscripted non-terminal indicates an instance of the non-terminal. Using this translation scheme, the computed value of S. val for root of the parse tree for the expression 20 # 10 % 5 # 8 % 2 % 2 is
Here # # and % % are operators and i d is a token that represents an integer and i d . val represents the corresponding integer value. The set of non-terminals is { S , T , R , P } and a subscripted non-terminal indicates an instance of the non-terminal. Using this translation scheme, the computed value of S. val for root of the parse tree for the expression 20 # 10 % 5 # 8 % 2 % 2 is
(a) 20
(b) 65
(c) 160
(d) 80
Ans: (d)
Sol: General rules –
Operators which are deeper in the parse tree will have higher precedence, since they are tried by parser first.
Left-recursive rules indicates left associativity
Right-recursive rules indicates right associativity
---------
In the question – # has corresponding operation: ∗
% has corresponding operation: ÷
∗ and ÷ both are left associative and ÷ is having higher precedence.
20 # 10 % 5 # 8 % 2 % 2
=20*(10/5)*((8/2)/2)
=20*2*2=80
Q4: Consider the augmented grammar with { + , ∗ , ( , ) , id } as the set of terminals. (2022)
S′→S
S→S+R| R
R→R∗P | P
P→(S)| id
If I 0 is the set of two L R ( 0 ) items { [ S ′ → S . ] , [ S → S . + R ] } then g o t o ( closure ( I 0 ) , + ) contains exactly ______ items.
(a) 2
(b) 3
(c) 4
(d)5
Ans: (d)
Sol: 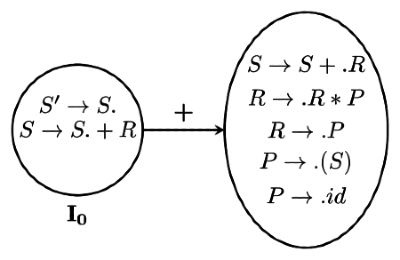
So Goto (closure(I0),+) contains exactly 5 items.
Q5: Which one of the following statements is TRUE? (2022)
(a) The LALR(1) parser for a grammar G cannot have reduce-reduce conflict if the LR(1) parser for G does not have reduce-reduce conflict.
(b) Symbol table is accessed only during the lexical analysis phase.
(c) Data flow analysis is necessary for run-time memory management.
(d) LR(1) parsing is sufficient for deterministic context-free languages.
Ans: (d)
Sol: Option A
Consider a LR(1) DFA with no RR Conflicts. Take two states, say, I3 and I5 in such LR(1) DFA
I3 : [ A → α . , a , B → β . , b ] and
I5: [ A → α . , b , B → β . , a]
Since the core items are same, we will merge I3 and I5 in LALR, say merged state is
I35
I35 [ A → α . , b , B → β . , a ,b]
A common confusion: I35 has RR conflict on a and b.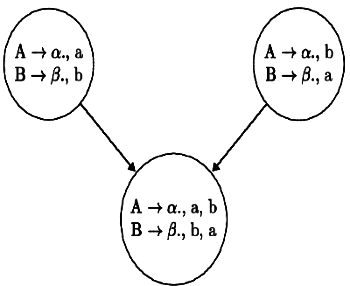 Do I35 really has any conflict ? -yes
Do I35 really has any conflict ? -yes
Option B
Symbol table is accessed among all phases. For example – “in t x”, here lexical analyzer will assign 2 tokens, but lexical analyzer won’t know whether x is of type in t since it reads in t and x as two different tokens. Syntax analyzer will feed type of x to symbol table.
C. It is optional
D. LR(1) = DCFL
Q6: Consider the following augmented grammar with { # , @ , < , > , a , b , c } as the set of terminals. (2021 SET 2)
S′→S
S→S#cS
S→SS
S→S@
S→<S>
S→a
S→b
S→c
Let I 0 = CLOSURE ( { S ′ → . S } ) . The number of items in the set GOTO(GOTO ( I 0 < ) , < ) is
(a) 6
(b) 7
(c) 8
(d) 9
Ans: (c)
Sol: 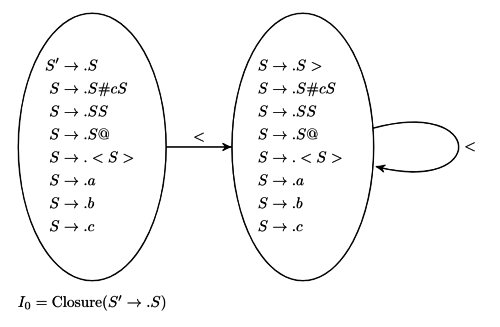 We can count the items in the third collection.
We can count the items in the third collection.
Q7: Consider the following C code segment: (2021 SET 1)
a = b + c;
e = a + 1;
d = b + c;
f = d + 1;
g = e + f;
In a compiler, this code segment is represented internally as a directed acyclic graph (DAG). The number of nodes in the DAG is _____________
(a) 11
(b) 6
(c) 5
(d) 10
Ans: (b)
Sol: Here a and d are same as both add same values ( b c ) (common sub-expression elimination)
Since a and d are same f and e are also same as they compute a + 1 and d + 1 respectively.
- a = d = b +c
- e = f = a + 1
- g = e + e (f and e being same)
So total no of nodes is
Ans: 6 nodes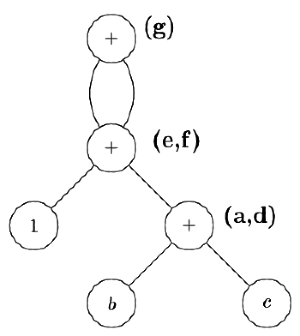
Q8: Consider the following statements. (2021 SET 1)
S1: Every SLR(1) grammar is unambiguous but there are certain unambiguous grammars that are not SLR(1).
S2: For any context-free grammar, there is a parser that takes at most O ( n3 )time to parse a string of length n.
Which one of the following options is correct?
(a) S1 is true and S2 is false
(b) S1 is false and S2 is true
(c) S1 is true and S2 is true
(d) S1 is false and S2 is false
Ans: (c)
Sol: Correct option is C. Both statements are correct.
An unambiguous grammar is not necessarily SLR(1).But every SLR(1) grammar is unambiguous.
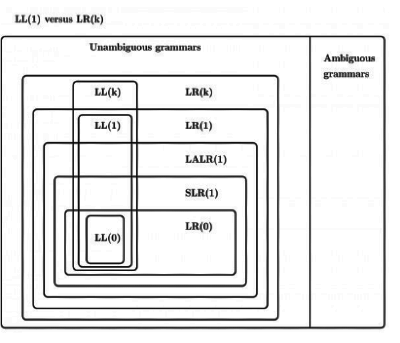 We do have which takes O ( n3 ) time (assuming size of the context-free grammar | G | to be a constant) to parse any string of length n using a context-free grammar G
We do have which takes O ( n3 ) time (assuming size of the context-free grammar | G | to be a constant) to parse any string of length n using a context-free grammar G
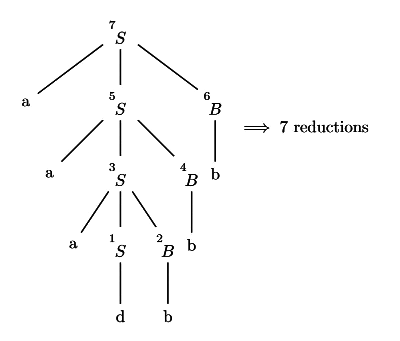
Q9: Consider the following grammar. (2020)
S → a S B ∣ d
B → b
The number of reduction steps taken by a bottom-up parser while accepting the string a a a d b b b b is___________.
(a)5
(b) 6
(c) 7
(d) 8
Ans: (c)
Sol: In parse tree, all the non terminals are reductions. So total 7 reductions.
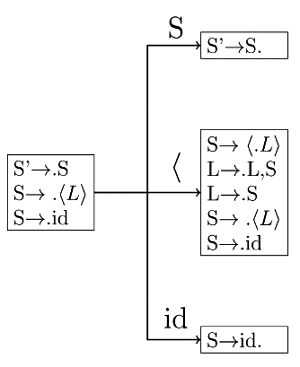
Q10: Consider the augmented grammar given below: (2019)
S ′ → S
S → < L > ∣ i d
L → L , S ∣ S
Let I0 = CLOSURE ( { [ S ′ → ⋅ S ] } ) . The number of items in the set G O T O ( I0 , < is __________.
(a) 2
(b) 4
(c) 5
(d) 6
Ans: (c)
Sol: Total 5 items
Q11: Consider the following given grammar: (2019)
S → Aa
A → BD
B → b| ϵ
D → d| ϵ
Let a, b, d and $ be indexed as follows:
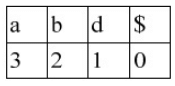
Compute the FOLLOW set of the non-terminal B and write the index values for the symbols in the FOLLOW set in the descending order. (For example, if the FOLLOW set is {a, b, d, $}, then the answer should be 3210).
Answer:_____
(a) 310
(b) 3100
(c) 31
(d) 220
Ans: (c)
Sol: For Follow(B) ⟹ First(D) = { d , ϵ }
Put ϵ in I I production
Follow (B) = Follow (A) = { a }
Follow (B) = { d , a }
According to the question writing Follow set in decreasing order: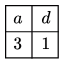
Hence 31 is correct answer
Q12: Which one of the following kinds of derivation is used by LR parsers? (2019)
(a) Leftmost
(b) Leftmost in reverse
(c) Rightmost
(d) Rightmost in reverse
Ans: (d)
Sol: A bottom-up parser traces a rightmost derivation in reverse. Answer (D).
Q13: Consider the following parse tree for the expression a#b$c$d#e#f, involving two binary operators $ and #. (2018)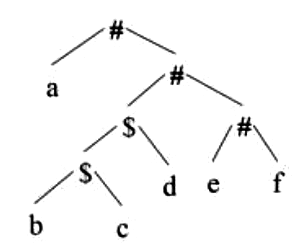
Which one of the following is correct for the given parse tree?
(a) $ has higher precedence and is left associative; # is right associative
(b) # has higher precedence and is left associative; $is right associative
(c)$ has higher precedence and is left associative; # is left associative
(d) # has higher precedence and is right associative; $ is left associative
Ans: (a)
Sol: 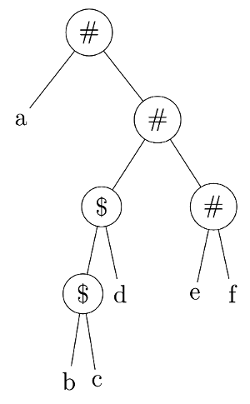 In order : { a # [ ( ( b $ c ) $ d ) # ( e # f ) ] } (given in question)
In order : { a # [ ( ( b $ c ) $ d ) # ( e # f ) ] } (given in question)
If we observe, first evaluation is b $ c
So, ($) has higher priority.
Therefore, either option (A) or (C) is correct
Option A
$ has higher precedence and # is right associative.
From tree, it is clear that (e # f)is evaluating first which is to the right side of the root.
Therefore, #is Right Associative.
So, Option A is correct
Option C
$ has higher precedence and # is left associative.
This is wrong.
Correct Answer: A.
Q14: Consider the following grammar: (2017 SET 1)
stmt → → if expr then else expr; stmt| ˙ O
expr → →term relop term|term
term → → id|number
if → →a|b|c
number → → [0-9]
where relop is a relational operate (e.g < , > ,...), O ˙refers to the empty statement, and if ,then, else are terminals.
Consider a program P following the above grammar containing ten if terminals. The number of control flows paths in P is ____________. For example the program
if e1 then e3 else e3
has 2 controls flow paths e 1 → e2 and e1 → e3.
(a) 10
(b) 100
(c) 1024
(d) 512
Ans: (c)
Sol: This question is picked from area of Counting in Combinatorics.
Given: if e 1 then e 2 else e 3 has 2 control flow paths e1 → e2 and e1 → e3 . (Meaning of "how many control flow" for if structure is clearly mentioned)
What is asked:
Number of control flow paths for 10 if terminals?
Solution:
To get 10 if's we need to use grammar to get,
if <expr> then <expr> else <expr> ; stmt
if <expr> then <expr> else <expr> ; if <expr> then <expr> else <expr> ; stmt
..............
..............
..............
(keep doing it 10 times to get 10 if's)
Observe that there is a semi-colon after every if structure.
We know that every if structure has 2 control flows as given in question. Hence,
We have 2 control flow choices for 1st if terminal.
We have 2 control flow choices for 2nd if terminal.
............
............
............
We have 2 control flow choices for 10th if terminal.
By using multiplicative law of counting we get,
Total choices as 2 ∗ 2 ∗ 2 ∗ 2 ∗ 2 ...... 10 times = 210 = 1024
Once again, one need not know "what control flow" is, but needs to know "how many control flows" are in if structure which is given in question.
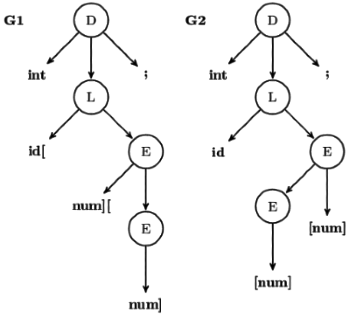
Q15: A student wrote two context-free grammars G1 and G2 for generating a single C-like array declaration. The dimension of the array is at least one. For example, (2016 SET 2)
int a[10][3];
The grammars use D as the start symbol, and use six terminal symbols int ;id[]num.
Grammar G1
D → int L;
L → id [E
E → num]
E → num] [E
Grammar G2
D → int L;
L → id E
E→ E [ num]
E → [num]
Which of the grammars correctly generate the declaration mentioned above?
(a) Both G1 and G2
(b) Only G1
(c) Only G2
(d) Neither G1 nor G2
Ans: (a)
Sol: Correct Option: A (Both G1 and G2)
Q16: Consider the following Syntax Directed Translation Scheme(SDTS),with non-terminals {S, A} and terminals {a, b}. (2016 SET 1)
S → aA {print 1}
S → a { print 2}
A → Sb { print 3}
Using the above SDTS, the output printed by a bottom-up parser, for the input aab is:
(a) 132
(b) 223
(c) 231
(d) syntax error
Ans: (c)
Sol: aab could be derived as follows by the bottom up parser:
S → a A prints 1
→ aSb prints 3
→ aab prints 2
Now since the bottom-up parser will work in reverse of rightmost derivation, so it will print in bottom-up fashion i.e., 231 which is option C. Note that this can be easily visualized by drawing the derivation tree.
Q17: Consider the following grammar (2015 SET 3)
S → F | H
F → p | c
H → d | c
where S,F, and H are non-terminal symbols, p,d, and c are terminal symbols. Which of the following statement(s) is/are correct?
S1. LL(1) can parse all strings that are generated using grammar G
S2. LR(1) can parse all strings that are generated using grammar G
(a) Only S1
(b) Only S2
(c) Both S1 and S2
(d) Neither S1 nor S2
Ans: (d)
Sol: A parser works on the basis of given grammar. It takes the grammar as it is. Parser does not work on the basis of the yield of the grammar. Also, while constructing the LL(1) parser table, that entry for terminal 'c' will contain multiple entries. So, LL(1) parser cannot be constructed for the given grammar.
S → F | H
F → p | c
H → d | c
That { p , d , c } are the strings generated by the grammar is absolutely correct. But LL(1) and LR(1) can parse these strings successfully only if the grammar is unambiguous and like given below...
S → P|D|C
P → p
D → d
C → c
Please note the difference between these two grammars. Both derive the same strings, but in different manner. With the grammar given in the question, both top-down and bottom-up parsers will get confused while deriving " c ". Top-down parser will get confused between F → c and H → c . Similarly, bottom-up parser will get confused while reducing " c ". This confusion in case of bottom-up parsing is technically termed as "reduce-reduce" conflict.
While top-down parsing, first(F) and first(H) are not disjoint, so the grammar cannot be LL(1). Therefore, LL(1) parser cannot parse it.
Hence, the answer should be option (D). Neither S1 nor S2.
Q18: Among simple LR (SLR) , canonical LR, and look-ahead LR (LALR), which of the following pairs identify the method that is very easy to implement and the method that is the most powerful , in that order? (2015 SET 3)
(a) SLR, LALR
(b) Canonical LR, LALR
(c) SLR, canonical LR
(d) LALR, canonical LR
Ans: (c)
Sol: 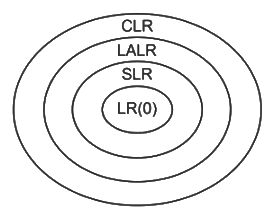
Power: LR(0) < SLR(1) < LALR(1) < CLR(1)
Implementation complexity:
LR(0) < SLR(1) < LALR(1) < CLR(1)|
Hence out of given options, SLR is
Easiest to implement and CLR is most powerful.
Q19: Which one of the following is TRUE at any valid state in shift-reduce parsing? (2015 SET 1)
(a) Viable prefixes appear only at the bottom of the stack and not inside
(b) Viable prefixes appear only at the top of the stack and not inside
(c) The stack contains only a set of viable prefixes
(d) The stack never contains viable prefixes
Ans: (c)
Sol: Explanation:
A handle is actually the one which is always on the top of the stack. A viable prefix(prefix of the Right-hand side of a production or productions), is actually a prefix of the handle and so can never extend past the right end of the handle(i.e. the top of the stack).
The structure of the stack can be considered as a set of viable prefixes -
Stack = { Pre fix 1 Prefix 2 Prefix 3 … Prefixn−1 Prefixn } and so it is not wrong to say that the stack contains a set of viable prefixes.
Answer - C
Q20: Consider the grammar defined by the following production rules, with two operators * and + (2014 SET 2)
S →T *P
T → U| T*U
P → Q +P |Q
Q → Id
U → Id
Which one of the following is TRUE?
(a) + is left associative, while * is right associative
(b) + is right associative, while * is left associative
(c) Both + and * are right associative
(d) Both + and * are left associative
Ans: (b)
Sol: P → Q + P here P is to right of +
So, + is right associative
Similarly, for T → T ∗ U ∗ is left associative as T is to left of ∗
So, answer is B
Q21: A canonical set of items is given below (2014 SET 1)
S → L . > R
Q → R.
On input symbol < the set has
(a) a shift-reduce conflict and a reduce-reduce conflict.
(b) a shift-reduce conflict but not a reduce-reduce conflict
(c) a reduce-reduce conflict but not a shift-reduce conflict.
(d) neither a shift-reduce nor a reduce-reduce conflict
Ans: (d)
Sol: The question is asked with respect to the symbol ' < ' which is not present in the given canonical set of items. Hence it is neither a shift-reduce conflict nor a reduce-reduce conflict on symbol '<'. Hence D is the correct option. But if the question would have asked with respect to the symbol ' > ' then it would have been a shift-reduce conflict.
Q22: Consider the following two sets of LR(1) items of an LR(1) grammar. (2013)
X → c.X , c/ d
X → .cX , c/ d
X → .d, c/ d
- X → c.X , $
- X →.cX , $
- X →.d , $
Which of the following statements related to merging of the two sets in the corresponding LALR parser is/are FALSE?
1. Cannot be merged since look a heads are different.
2. Can be merged but will result in S-R conflict.
3. Can be merged but will result in R-R conflict.
4. Cannot be merged since goto on c will lead to two different sets.
(a) 1 only
(b) 2 only
(c) 1 and 4 only
(d) 1, 2, 3 and 4
Ans: (d)
Sol: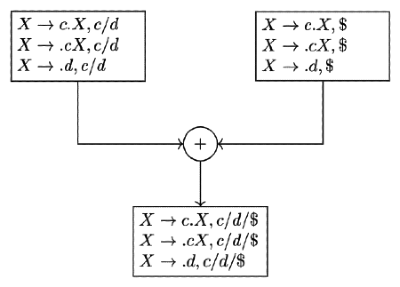 The TRUE statements are about merging of two states for LALR(1) parser from LR(1) parser.
The TRUE statements are about merging of two states for LALR(1) parser from LR(1) parser.
1. The given two states can be merged because kernel of these are same, look a heads don't matter in merging.
2. The two states do not contain shift reduce conflict, so after merging the merged states cannot contain any S-R conflict.
3. There is no final item in both states, so no R-R conflict.
4. Merging of states does not depend on further GOTO part on any terminal.
Therefore, all the given statements in question are FALSE.
Option (D) is correct.
Q23: What is the maximum number of reduce moves that can be taken by a bottom-up parser for a grammar with no epsilon- and unit-production (i.e., of type A → ϵ A → a) to parse a string with n tokens? (2013)
(a) n/2
(b) n-1
(c) 2n-1
(d) 2n
Ans: (b)
Sol: Ans will be B
- A → B C
- B → a a
- C → b b
Now suppose string is aabb . Then
A → BC (reduction 3 )
→ aaC (reduction 2 )
→ aabb (reduction 1 )
n = 4 and number of reductions is 3. So, n - 1
Q24: For the grammar below, a partial LL(1) parsing table is also presented along with the grammar. Entries that need to be filled are indicated as E1, E2, and E3. ε ε is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions. (2012)
S → aAbB |bAaB |ε
A → S
B → S The appropriate entries for E1, E2, and E3 are
The appropriate entries for E1, E2, and E3 are
(a) E1: S → aAbB, A → S
E2: S → bAaB, B → S
E3: B → S
(b) E1: S → aAbB, S → ε
E2: S → bAaB, S → ε
E3: B →εS
(c) E1: S → aAbB, S → εE2: S → bAaB, S → ε
E3: B →S
(d) E1: A → S, S → ε
E2: B → S, S → ε
E3: B → S
Ans: (c)
Sol: To make L L ( 1 ) parsing table first we have to find FIRST and FOLLOW sets from the given grammar.
- FIRST ( S ) = { a , b , ϵ }
- FIRST ( A ) = { a , b , ϵ }
- FIRST ( B ) = { a , b , ϵ }
- FOLLOW ( S ) = { a , b , $ }
- FOLLOW ( A ) = { a , b }
- FOLLOW ( B ) = { a , b , $ }
Now lets make L L ( 1 ) parse table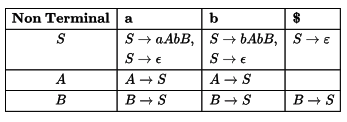
Here is the explanation of entries asked in question
1. For E1 and E2 Look into FIRST ( S ) = { a , b , ϵ } .
a is because of S → a A b B and b is because of S → b A a B
So M [ S , a ] and M [ S , b ] will contain S → aAbB and S → bAaB respectively. For epsilon look into
FOLLOW ( S ) = { a , b , $ } . So S → ϵ will be in M [ S , a ] , M [ S , b ] and M[ S, $]
2. Now for E3 look into FIRST ( B ) = { a , b , ϵ } . a and b are because of B → S .
So M [ B , a ] and M [ B , b ] will contain B → S and for ϵ , look into FOLLOW ( B ) = { a , b , $ } . Hence M [ B , $ ] will
contain B → S .
Now we get the answer as E1 is S → a A b B , S → ϵ , E2 is S → b A a B , S → ϵ and E3 is B → S .
Hence, Option (C) is correct.
Q25: For the grammar below, a partial LL(1) parsing table is also presented along with the grammar. Entries that need to be filled are indicated as E1, E2, and E3. ε ε is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions. (2012)
S → aAbB |bAaB |ε
A → S
B → S The FIRST and FOLLOW sets for the non-terminals A and B are
The FIRST and FOLLOW sets for the non-terminals A and B are
(a) FIRST(A) = {a, b, ε } = FIRST(B)
FOLLOW(A) = {a, b}
FOLLOW(B) = {a, b, $}
(b)FIRST(A) = {a, b, $}
FIRST(B) = {a, b, ε }
FOLLOW(A) = {a, b}
FOLLOW(B) = {$}
(c) FIRST(A) = {a, b, ε } = FIRST(B)
FOLLOW(A) = {a, b}
FOLLOW(B) = ϕ
(d) FIRST(A) = {a, b} = FIRST(B)
FOLLOW(A) = {a, b}
FOLLOW(B) = {a, b}
Ans: (a)
Sol: First ( S ) = First ( A ) = First ( B ) = { a , b , ϵ }
Follow ( A ) = { a , b }
Follow ( B ) = Follow ( S ) = { a , b , $ }
So, the answer is option A.
Q26: Consider two binary operators ' ↑ 'and ' ↓ ' with the precedence of operator ↓ being lower than that of the operator ↑ . Operator ↑ is right associative while operator ↓ is left associative. Which one of the following represents the parse tree for expression (7 ↓ 3 ↑4 ↑ 3 ↓ 2)? (2011)
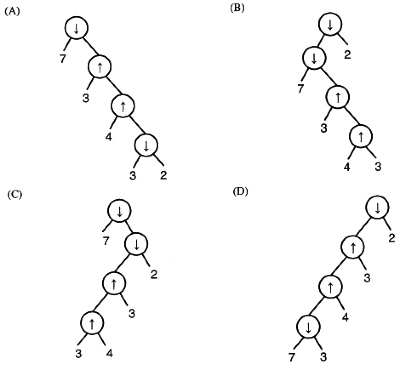 (a) A
(a) A
(b) B
(c) C
(d) D
Ans: (b)
Sol: Higher precedence operators comes at the bottom
↑ has higher precedence so 3 ↑ 4 ↑ 3 will be evaluated first. As ↑ is left associative so 4 ↑ 3 will be evaluated so 4 ↑ 3 should be at last level then
3 ↑ ( 4 ↑ 3 )
↓ i this is left associative so left operand i.e & will be evaluated
( 7 ↓ ( 3 ↑ ( 4 ↑ 3 ) )
and then 2
( ( 7 ↓ ( 3 ↑ ( 4 ↑ 3 ) ) ↓ 2 )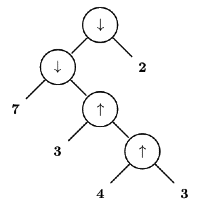
which gives option (B)
Q27: The grammar S→aSa |bS |c is (2010)
(a) LL(1) but not LR(1)
(b) LR(1) but not LR(1)
(c) Both LL(1) and LR(1)
(d) Neither LL(1) nor LR(1)
Ans: (c)
Sol: The LL(1) parsing table for the given grammar is: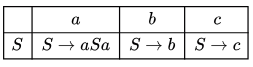
For any given input symbol a, b or c, the parser has a unique move from the start and the only state – so no conflicts.
As there is no conflict in LL(1) parsing table, the given grammar is LL(1) and since
every LL(1) is also LR(1) , the given grammar is LL(1) as well as LR(1)
Q28:Which of the following statements are TRUE? (2009)
I There exist parsing algorithms for some programming languages whose complexities are less than θ(n3 ).
II A programming language which allows recursion can be implemented with static storage allocation.
III No L-attributed definition can be evaluated in the framework of bottom-up parsing.
IV Code improving transformations can be performed at both source language and intermediate code level.
(a) I and II
(b) I and IV
(c) III and IV
(d) I, III and IV
Ans: (b)
Sol: Answer is B.
A. Yes there does exist parsing algorithms (e.g. CYK algorithm) which run in Θ(n3).
B. It cannot be implemented with static storage allocation. It needs dynamic memory allocation.
C. Every S-attributed definition is also an L-attributed definition and can be evaluated in the framework of bottom up parsing.
D. True.
Q29:An LALR(1) parser for a grammar G can have shift-reduce (S-R) conflicts if and only if (2008)
(a) The SLR(1) parser for G has S-R conflicts
(b) The LR(1) parser for G has S-R conflicts
(c) The LR(0) parser for G has S-R conflicts
(d) The LALR(1) parser for G has reduce-reduce conflicts
Ans: (b)
Sol: Both LALR(1) and LR(1) parser uses LR(1) set of items to form their parsing tables. And LALR(1) states can be found by merging LR(1) states of LR(1) parser that have the same set of first components of their items.
i.e. if LR(1) parser has 2 states I and J with items A → a . b P , x and A → a . b P , y respectively, where x and y are look ahead symbols, then as these items are same with respect to their first component, they can be merged together and form one single state, let’s say K . Here we have to take union of look ahead symbols. After merging, State K will have one single item as A → a . b P , x , y . This way LALR(1) states are formed ( i.e. after merging the states of LR(1) ).
Now, S−R conflict in LR(1) items can be there whenever a state has items of the form
:
A-> a.bB , p
C-> d. , b
i.e. it is getting both shift and reduce at symbol b,
hence a conflict.
Now, as LALR(1) have items similar to LR(1) in terms of their first component, shift-reduce form will only take place if it is already there in LR(1) states. If there is no S-R conflict in LR(1) state it will never be reflected in the LALR(1) state obtained by combining LR(1) states.
Correct Answer:
Q30: Match the following: (2008) (a) E - P, F - R, G - Q, H - S
(a) E - P, F - R, G - Q, H - S
(b) E - R, F - P, G - S, H - Q
(c) E - R, F - P, G - Q, H - S
(d) E - P, F - R, G - S, H - Q
Ans: (c)
Sol: H-S is true because strings generated by this grammar satisfy the definition of an even length palindrome string. This rules out B and D options.
G-Q is confirmed as both options A and C has it as true.
E-R is true because R is the only grammar that checks: what(w)has occurred earlier is present afterwards. This equals the definition of E
Hence, option C is true.
Q31: Which of the following describes a handle (as applicable to LR-parsing) appropriately? (2008)
(a) It is the position in a sentential form where the next shift or reduce operation will occur
(b) It is non-terminal whose production will be used for reduction in the next step
(c) It is a production that may be used for reduction in a future step along with a position in the sentential form where the next shift or reduce operation will occur
(d) It is the production p that will be used for reduction in the next step along with a position in the sentential form where the right hand side of the production may be found
Ans: (d)
Sol: A sentential form is the start symbol S of a grammar or any string in (V ∪ T)∗ that can be derived from S.
Consider the linear grammar
( {S, B},{a, b}, S, {S → aS, S →B, B → bB, B → λ} ).
A derivation using this grammar might look like this:
S ⇒ a S ⇒ a B ⇒ a b B ⇒ a b b B ⇒ a b b
Each of { S , a S , a B , a b B , a b b B , a b b } is a sentential form.
Because this grammar is linear, each sentential form has at most one variable. Hence there is never any choice about which variable to expand next.
Here, in option D the sentential forms are same but generated differently coz we are using here Bottom Up production.
Handle:
for example the grammar is:
E→ E+ n
E→ E * n
E→ n
Then say to derive string n +n ∗ n:
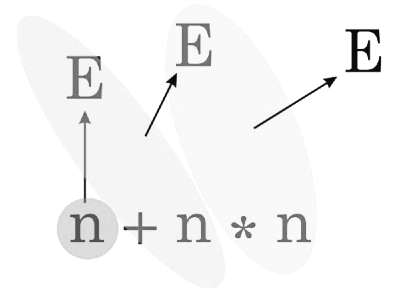 these are three different handles shown in 3 different colors = { n , E + n , E ∗ n }
these are three different handles shown in 3 different colors = { n , E + n , E ∗ n }
that's what option D says
Q32: Consider the following grammars. Names representing terminals have been specified in capital letters. (2007) 
Which one of the following statements is true?
(a) G1 is context-free but not regular and G2 is regular
(b) G2 is context-free but not regular and G1 is regular
(c) Both G1 and G2 are regular
(d) Both G1 and G2 are context-free but neither of them is regular
Ans: (d)
Sol: Regular grammar is either right linear or left linear. A left linear grammar is one in which there is at most 1non-terminal on the right side of any production, and it appears at the left most position. Similarly, in right linear grammar non-terminal appears at the right most position.
Here, we can write a right linear grammar for G1 as
S → w(E
E→ id)S
S → o
(w - WHILE, o - OTHER)
Now for G2 also we can write a right linear grammar:
S → w( E
E → id) S
E→ id + E
E→ id ∗ E
S → o
making its language regular.
So, both G1and G2 have an equivalent regular grammar. But given in the question both these grammars are neither right linear nor left linear and hence not a regular grammar. So, D must be the answer.
Q33: Consider the grammar given below: (2007)
S → x B∣ y A
A → x ∣ x S ∣ y A A
B → y∣ y S ∣ x B B
Consider the following strings.
i. xxyyx
ii. xxyyxy
iii. xyxy
iv. yxxy
v. yxx
vi. xyx
Which of the above strings are generated by the grammar ?
(a) i, ii and iii
(b) ii, v and vi
(c) ii, iii and iv
(d) i, iii and iv
Ans: (c)
Sol: ii, iii and iv.
So, option C is correct.
Above grammar is for equal no of x and y
from Non-terminal S →xB
⇒ x y [as B → y one y for one x ]
S → xB
⇒ x x B B [as B → y B B one B result in one y for one x ]
S → xB
⇒ x y S [as B → y S one y for one x and start again]
Note: Same applies for string start with y i.e . S → y A .
Q34: Consider an ambiguous grammar G and its disambiguated version D. Let the language recognized by the two grammars be denoted by L(G) and L(D) respectively. Which one of the following is true? (2007)
(a) L( D ) ⊂ L( G )
(b) L( D ) ⊃ L( G )
(c) L (D) = L (G)
(d) L (D) is empty
Ans: (c)
Sol: Correct Option: C
L ( D ) = L ( G ) . Both must represent same language. Also, if we are converting a grammar from ambiguous to unambiguous form, we must ensure that our new new grammar represents the same language as previous grammar.
For ex G 1 : S → S a ∣ a S ∣ a ; { Ambiguous ( 2 parse trees for string ' a a ' ) }
G 1 ′ : S → a S ∣ a ; { Unambiguous }
Both represent the language represented by the regular expression: a+
Q35: Consider the CFG with {S, A,B} as the non-terminal alphabet, {a,b} as the terminal alphabet, S as the start symbol and the following set of production rules: (2007)
S → aB S → bA
B → b A → a
B → bS A → aS
B → aBB S → bAA
Which of the following strings is generated by the grammar?
(a) aaaabb
(b) aabbbb
(c) aabbab
(d) abbbba
Ans: (c)
Sol: S→ aB
→ aaBB
→ aabB
→ aabbS
→ aabbaB
→ aabbab
Q36: Consider the grammar with non-terminals N={ S , C , S1 }, terminals T={a,b,i,t,e}, with S as the start symbol, and the following set of rules: (2007)
S → iCtSS1∣a
S1 → eS∣ϵ
C→ b
The grammar is NOT LL(1) because:
(a) it is left recursive
(b) it is right recursive
(c) it is ambiguous
(d) it is not context-free.
Ans: (c)
Sol: Here, we can expand any one of S1to ∈ and other to ea, but which one will it be need not matter, because in the end we will still get the same string.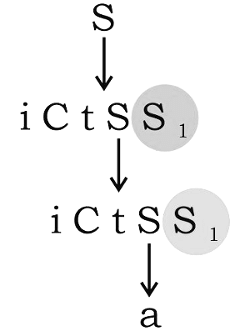
his means that the Grammar is Ambiguous. LL(1) cannot be ambiguous.
LL(1) Derivations
L eft to Right Scan of input
L eftmost Derivation
(1) look ahead 1 token at each step
Alternative characterization of LL (1) Grammars:
Whenever A→ a|β∈ G
1. FIRST(α) ∩ FIRST ( β )={},and
2. If α⟹∗ε then FIRST ( β ) ∩ FOLLOW (A) = {}.
Corollary: No Ambiguous Grammar is LL (1).
Correct Answer: C.
Q37: Which one of the following is a top-down parser? (2007)
(a) Recursive descent parser.
(b) Operator precedence parser
(c) An LR(k) parser
(d) An LALR(k) parser
Ans: (a)
Sol:
1. Recursive descent parser-TOP DOWN PARSER
2. Operator precedence parser-BOTTOM UP PARSER
3. An LR(k) parser.-BOTTOM UP PARSER
4. An LALR(k) parser-BOTTOM UP PARSER
Q38: The grammar (2006)
S → AC|CB
C→ aCb|ε
A → aA|a
B → Bb|b
generates the language L = { a i b j | i ≠ j } ,what is the length of the derivation (number of steps starting from S) to generate the string al bm b with l ≠ m?
(a) max(l,m)+2
(b) l+m+2
(c) l+m+3
(d) max(l,m)+3
Ans: (a)
Sol:
L = al bm ; l ≠ m means either l > m or l < m
Case I [l > m]:
if l > m , al bm can be written as a l − m a m b m [ l − m cannot be 0 as l should be > m]
S → AC, one step
al − m use l − m steps using productions of A
[as l − m = 1 , one step A → a
l−m=2, two steps A→ aA → aa
l−m=3, three steps , A → aA → aaA → aaa … so on]
ambm will be generate in m+1 steps using production C
[ as m=0 one step C→ ∈
m=1, two steps C→ a Cb → ab
m=2, three steps C → aCb → aaCbb → aabb … so on ]
So if l > m, total steps = 1+l-m+m+1=l+2
Case II [l<m]:
Similarly if l<m, albm can be written as a1b1bm−1[m−l cannot be 0 as m should be >l]
S → CB one step
albl will be derived using l + 1 steps
bm−l will be derived using m - l steps
Total steps 1+l+1 + m- 1= m + 2
So L = a l b m ; l ≠ m will take max ( l , m ) + 2 steps
Correct Answer: A.
Q40: Which one of the following grammars generates the language (2006)
L = { a i b j | i ≠ j }
(A)
S → AC| CB
C → aC b| a | b
A → aA| ∈
B→ Bb| ∈
(B)
S → aS| Sb|a| b
(C)
S → AC| CB
C→ aC b | ∈
A → aA| ∈
B→ Bb| ∈
(D)
S → AC| CB
C→ aC b| ∈
A→aA|a
B→Bb| b
(a) A
(b) B
(c) C
(d) D
Ans: (d)
Sol: Lets consider options one by one.
Option A
- C ⇒ a
- or, C ⇒ b
- or, C ⇒ a C b ⇒ a a C b b ⇒ a a a C b b b … so on and at last we have to put
- either C → a or C → b
- So production starting with C is used to derive a n + 1 b n or anbn + 1; n ≥ 0
- S → A C [ A a n b n + 1 ] can make a n + 1 b n + 1 as a single a can be derived from A [ A ⇒ a A ⇒ a as A → ε ], similarly S → CB
- In a simple way, ab can be derived from grammar as
S ⇒ A C ⇒ a A C ⇒ a C ⇒ a b - option A is wrong
option B
- Corresponding language is a + b ∗ or a ∗ b+ , and a b can be derived as
S ⇒ aS ⇒ ab - option B is wrong
Option C
- C ⇒ ε
- or C ⇒ a C b ⇒ a a C b b ⇒ a a a C b b b … so on and at last need to put
C ⇒ ε - Production C will generate a n b n ; n ≥ 0
- S → A C can generate a n b n as A can be ϵ , similarly S →CB
- option C is wrong
Option D .
- Production Cis used to generate anbn as in option C
- S → A C will increase no of a 's before a n b n as A will generate a or a a or
a a a … i , e . , a + , so S → A C will generate a + a n b n , i . e . , a i b j ; i > j - S → C B will generate a n b n b + i . e . , a i b j ; i < j
- option D is right .
Q41: Consider the following translation scheme. (2006)
S → ER
R →* E{print('*');}R|ε
E→F+E{print('+');}|F
F→(S)|id{print(id. value);}
Here id is a taken that represents an integer and id. value represents the corresponding integer value. For an input '2*3+4', this translation scheme prints
(a) 2*3+4
(b) 2*+34
(c) 23*4+
(d) 234+*
Ans: (d)
Sol: Make a tree and perform post order evaluation.
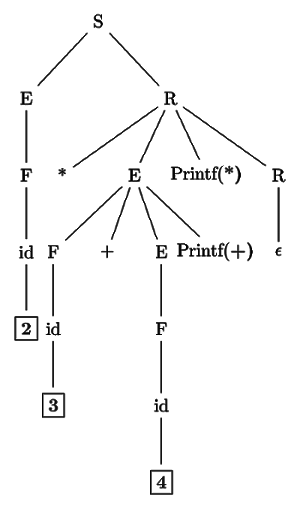
Correct Option: D
Q42: Consider the following grammar (2006)
S → FR
R →* S | ε
F → id
In the predictive parser table, M, of the grammar the entries M[S, id] and M[R,$] respectively
(a) {S → → FR} and {R → ε }
(b) {S → → FR} and {}
(c) {S → → FR} and {R → * S}
(d) {F → → id} and {R → ε }
Ans: (a)
Sol: First S={id}
Follow R = { $ }
so M[S, id]=S → FR
M[ R ,$] =R → ∈
So ans is A
Q43: Consider the following grammar. (2006)
S → S * E
S → E → F + E
E → F
F F → id
Consider the following LR(0) items corresponding to the grammar above.
(i) S → → S * .E
(ii) E → → F. + E
(iii) E → → F + .E
Given the items above, which two of them will appear in the same set in the canonical sets-of-items for the grammar?
(a) (i) and (ii)
(b) (ii) and (iii)
(c) (i) and (iii)
(d) None of these
Ans: (d)
Sol: 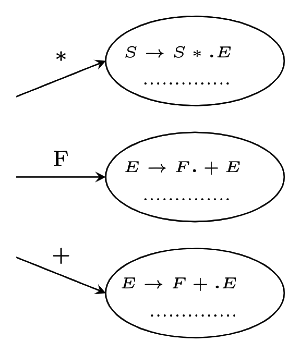
⇒ NOT possible for these three items to be in same state
Correct Answer: D
|
26 videos|90 docs|30 tests
|
FAQs on Previous Year Questions: Parsing - Compiler Design - Computer Science Engineering (CSE)
| 1. What is parsing in computer science engineering? |  |
| 2. What are the different types of parsing techniques used in computer science engineering? | |
| 3. How does parsing play a role in the development of programming languages? | |
| 4. What are some common tools and libraries used for parsing in computer science engineering? | |
| 5. Can you provide an example of parsing in computer science engineering? | |



video lectures
,Semester Notes
,mock tests for examination
,Summary
,Important questions
,Free
,Extra Questions
,practice quizzes
,Exam
,Previous Year Questions with Solutions
,Previous Year Questions: Parsing | Compiler Design - Computer Science Engineering (CSE)
,Previous Year Questions: Parsing | Compiler Design - Computer Science Engineering (CSE)
,study material
,Sample Paper
,past year papers
,Viva Questions
,MCQs
,Objective type Questions
,Previous Year Questions: Parsing | Compiler Design - Computer Science Engineering (CSE)
,ppt
,shortcuts and tricks
;






Previous Year Questions: Parsing Free PDF Download
Importance of Previous Year Questions: Parsing
Previous Year Questions: Parsing Notes
Previous Year Questions: Parsing Computer Science Engineering (CSE)
Study Previous Year Questions: Parsing on the App
|
© EduRev
|
Education Revolution
|



|





