आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 | विज्ञान और प्रौद्योगिकी (Science & Technology) for UPSC CSE PDF Download

बिग डेटा एक ऐसा शब्द है जिसका उपयोग उन डेटा सेटों के अध्ययन और अनुप्रयोगों के लिए किया जाता है जो इतने बड़े और जटिल होते हैं कि पारंपरिक डेटा-प्रसंस्करण अनुप्रयोग सॉफ़्टवेयर उन्हें संभालने के लिए अपर्याप्त होते हैं। बिग डेटा की चुनौतियों में डेटा को पकड़ना, डेटा भंडारण, डेटा विश्लेषण, खोज, साझा करना, स्थानांतरण, दृश्यता, पूछताछ, अद्यतन, सूचना गोपनीयता और डेटा स्रोत शामिल हैं। बिग डेटा से जुड़े कई अवधारणाएँ हैं: प्रारंभ में तीन अवधारणाएँ थीं - वॉल्यूम, विविधता, और वेग। बाद में बिग डेटा से संबंधित अन्य अवधारणाएँ सत्यता (यानी, डेटा में कितना शोर है) और मूल्य हैं।
बिग डेटा को निम्नलिखित विशेषताओं द्वारा वर्णित किया जा सकता है:
- वॉल्यूम – उत्पन्न और संग्रहीत डेटा की मात्रा। डेटा का आकार मूल्य और संभावित अंतर्दृष्टि को निर्धारित करता है, और यह तय करता है कि इसे बिग डेटा माना जा सकता है या नहीं।
- विविधता – डेटा का प्रकार और स्वभाव। यह उन लोगों की मदद करता है जो इसका विश्लेषण करते हैं ताकि वे परिणामस्वरूप मिली अंतर्दृष्टि का प्रभावी ढंग से उपयोग कर सकें। बिग डेटा पाठ, चित्र, ऑडियो, वीडियो से लिया जाता है; इसके अलावा यह डेटा फ्यूजन के माध्यम से गायब टुकड़ों को पूरा करता है।
- वेग – इस संदर्भ में, उस गति की बात की जा रही है जिस पर डेटा उत्पन्न और संसाधित होता है, ताकि विकास और प्रगति के मार्ग में आने वाली मांगों और चुनौतियों को पूरा किया जा सके। बिग डेटा अक्सर वास्तविक समय में उपलब्ध होता है।
- सत्यता – पकड़े गए डेटा की गुणवत्ता बहुत भिन्न हो सकती है, जो सटीक विश्लेषण को प्रभावित करती है।
अनुप्रयोग
सरकार: बिग डेटा का उपयोग सरकार द्वारा नीति निर्माण में तेजी से किया जा रहा है। सरकारी प्रक्रियाओं में बिग डेटा का उपयोग और अपनाना लागत, उत्पादकता और नवाचार के मामले में दक्षता प्रदान करता है, लेकिन इसके बिना अपनी कमियों के नहीं आता।
अंतर्राष्ट्रीय विकास: सूचना और संचार प्रौद्योगिकियों के प्रभावी उपयोग पर शोध (जिसे ICT4D भी कहा जाता है) यह सुझाव देता है कि बिग डेटा प्रौद्योगिकी महत्वपूर्ण योगदान कर सकती है लेकिन अंतर्राष्ट्रीय विकास के लिए अनूठी चुनौतियां भी प्रस्तुत करती है। बिग डेटा विश्लेषण में प्रगति स्वास्थ्य देखभाल, रोजगार, आर्थिक उत्पादकता, अपराध, सुरक्षा, और प्राकृतिक आपदा एवं संसाधन प्रबंधन जैसे महत्वपूर्ण विकास क्षेत्रों में निर्णय लेने में सुधार के लिए लागत-कुशल अवसर प्रदान करती है।
निर्माण: पूर्वानुमानात्मक निर्माण का एक वैचारिक ढांचा डेटा अधिग्रहण से शुरू होता है जहाँ विभिन्न प्रकार के संवेदी डेटा उपलब्ध होते हैं, जैसे कि ध्वनि, कंपन, दबाव, धारा, वोल्टेज, और नियंत्रक डेटा। ऐतिहासिक डेटा के साथ-साथ विशाल मात्रा में संवेदी डेटा निर्माण में बिग डेटा का निर्माण करता है। उत्पन्न बिग डेटा पूर्वानुमानात्मक उपकरणों और निवारक रणनीतियों जैसे Prognostics and Health Management (PHM) में इनपुट के रूप में कार्य करता है।
स्वास्थ्य देखभाल: बिग डेटा विश्लेषण ने स्वास्थ्य देखभाल को व्यक्तिगत चिकित्सा और प्रिस्क्रिप्टिव एनालिटिक्स, नैदानिक जोखिम हस्तक्षेप और पूर्वानुमानात्मक एनालिटिक्स, अपशिष्ट और देखभाल में भिन्नता को कम करने, रोगी डेटा की स्वचालित बाहरी और आंतरिक रिपोर्टिंग, मानकीकृत चिकित्सा शर्तों, और रोगी रजिस्ट्रियों और विखंडित बिंदु समाधानों द्वारा सुधारने में मदद की है।
शिक्षा: एक McKinsey Global Institute अध्ययन ने अत्यधिक प्रशिक्षित डेटा पेशेवरों और प्रबंधकों की 1.5 मिलियन की कमी पाई है और कई विश्वविद्यालयों, जैसे कि University of Tennessee और UC Berkeley, ने इस मांग को पूरा करने के लिए मास्टर कार्यक्रम बनाए हैं। निजी बूट कैंप ने भी इस मांग को पूरा करने के लिए कार्यक्रम विकसित किए हैं, जिनमें The Data Incubator जैसे मुफ्त कार्यक्रम या General Assembly जैसे भुगतान किए गए कार्यक्रम शामिल हैं।
मीडिया–
- उपभोक्ताओं का लक्ष्य बनाना (मार्केटर्स द्वारा विज्ञापन के लिए)
- डेटा संग्रहण
- डेटा पत्रकारिता: प्रकाशक और पत्रकार बिग डेटा उपकरणों का उपयोग करके अद्वितीय और नवीन अंतर्दृष्टि और इन्फोग्राफिक्स प्रदान करते हैं।
बीमा: स्वास्थ्य बीमा प्रदाता सामाजिक "स्वास्थ्य के निर्धारकों" जैसे कि खाद्य और टीवी उपभोग, वैवाहिक स्थिति, वस्त्र आकार और खरीदारी की आदतों पर डेटा एकत्र कर रहे हैं, जिनसे वे स्वास्थ्य लागत की भविष्यवाणी करते हैं, ताकि अपने ग्राहकों में स्वास्थ्य समस्याओं का पता लगाया जा सके। यह विवादास्पद है कि क्या ये भविष्यवाणियाँ वर्तमान में मूल्य निर्धारण के लिए उपयोग की जा रही हैं।
इंटरनेट ऑफ थिंग्स (IoT): बिग डेटा और IoT एक साथ काम करते हैं। IoT उपकरणों से निकाला गया डेटा उपकरणों के आपसी संबंध का मानचित्र प्रदान करता है। ऐसे मानचित्रों का उपयोग मीडिया उद्योग, कंपनियों और सरकारों द्वारा अपने लक्षित दर्शकों को अधिक सटीकता से लक्षित करने और मीडिया दक्षता बढ़ाने के लिए किया गया है। IoT को संवेदनशील डेटा एकत्र करने के एक साधन के रूप में भी तेजी से अपनाया जा रहा है, और इस संवेदनशील डेटा का उपयोग चिकित्सा, निर्माण और परिवहन संदर्भों में किया गया है।
एंड-टू-एंड एन्क्रिप्शन (E2EE): एंड-टू-एंड एन्क्रिप्शन (E2EE) एक संचार प्रणाली है जहाँ केवल संचार करने वाले उपयोगकर्ता संदेशों को पढ़ सकते हैं। सिद्धांत में, यह संभावित सुनने वालों – जिसमें टेलीकॉम प्रदाता, इंटरनेट प्रदाता और यहां तक कि संचार सेवा का प्रदाता भी शामिल है – को बातचीत को डिक्रिप्ट करने के लिए आवश्यक क्रिप्टोग्राफिक कुंजी तक पहुँचने से रोकता है।
पॉइंट-टू-पॉइंट एन्क्रिप्शन (P2PE): पॉइंट-टू-पॉइंट एन्क्रिप्शन (P2PE) एक मानक है जिसे PCI सुरक्षा मानक परिषद द्वारा स्थापित किया गया है। भुगतान समाधान जो समान एन्क्रिप्शन प्रदान करते हैं लेकिन P2PE मानक को पूरा नहीं करते हैं, उन्हें एंड-टू-एंड एन्क्रिप्शन (E2Ee) समाधान कहा जाता है। P2Pe और E2Ee का उद्देश्य एक भुगतान सुरक्षा समाधान प्रदान करना है जो कार्ड स्वाइप करते समय गोपनीय भुगतान कार्ड (क्रेडिट और डेबिट कार्ड) डेटा और जानकारी को असंगत कोड में तत्काल परिवर्तित करता है ताकि हैकिंग और धोखाधड़ी को रोका जा सके। इसे एक बढ़ते जटिल नियामक वातावरण में भुगतान कार्ड लेनदेन की सुरक्षा को अधिकतम करने के लिए डिज़ाइन किया गया है।
डीप वेब (Deep Web), अदृश्य वेब (Invisible Web), या हिडन वेब्स (Hidden Webs) विश्वव्यापी वेब का वह हिस्सा है जिसका सामग्री किसी भी कारण से सामान्य वेब सर्च इंजनों द्वारा अनुक्रमित नहीं किया गया है। डीप वेब का विपरीत शब्द सर्फेस वेब (Surface Web) है, जो इंटरनेट का उपयोग करने वाले किसी भी व्यक्ति के लिए सुलभ है। कंप्यूटर वैज्ञानिक माइकल के. बर्गमैन (Michael K. Bergman) को 2001 में खोज अनुक्रमण शब्द के रूप में डीप वेब का नामकरण करने का श्रेय दिया जाता है। डीप वेब की सामग्री HTTP फॉर्म के पीछे छिपी होती है और इसमें कई सामान्य उपयोग शामिल होते हैं जैसे कि वेबमेल (Webmail), ऑनलाइन बैंकिंग (Online Banking), और ऐसी सेवाएँ जिनके लिए उपयोगकर्ताओं को भुगतान करना पड़ता है, और जो पेवाल (Paywall) द्वारा सुरक्षित होती हैं, जैसे कि वीडियो ऑन डिमांड, कुछ ऑनलाइन पत्रिकाएँ और समाचार पत्र आदि। डीप वेब की सामग्री को सीधे URL या IP पता के माध्यम से स्थानांतरित और एक्सेस किया जा सकता है और इसके लिए पासवर्ड या अन्य सुरक्षा पहुँच की आवश्यकता हो सकती है।
डार्क वेब (Dark Web) वह सामग्री है जो डार्कनेट्स (Darknets) पर मौजूद होती है, यह ओवरले नेटवर्क होते हैं जो इंटरनेट का उपयोग करते हैं लेकिन एक्सेस के लिए विशिष्ट सॉफ़्टवेयर, कॉन्फ़िगरेशन, या प्राधिकरण की आवश्यकता होती है। डार्क वेब डीप वेब का एक छोटा हिस्सा है, जो वेब सर्च इंजनों द्वारा अनुक्रमित नहीं किया गया है, हालांकि कभी-कभी "डीप वेब" शब्द का गलत उपयोग विशेष रूप से डार्क वेब का उल्लेख करने के लिए किया जाता है। डार्क वेब का निर्माण करने वाले डार्कनेट्स में छोटे, मित्र-से-मित्र पीयर-टू-पीयर नेटवर्क (Peer-to-Peer Networks) शामिल हैं, साथ ही बड़े, लोकप्रिय नेटवर्क जैसे कि टोर (Tor), फ्रीनेट (Freenet), I2P, और रिफल (Riffle) जो सार्वजनिक संगठनों और व्यक्तियों द्वारा संचालित होते हैं। डार्क वेब के उपयोगकर्ता सामान्य वेब को क्लियरनेट (Clearnet) के रूप में संदर्भित करते हैं क्योंकि यह असंक्रिप्टेड होता है। टोर डार्क वेब को ऑनियनलैंड (Onionland) के रूप में भी संदर्भित किया जा सकता है, जो नेटवर्क के शीर्ष-स्तरीय डोमेन उपसर्ग .onion और ऑनियन राउटिंग (Onion Routing) की ट्रैफ़िक गुमनामी तकनीक का संदर्भ देता है।
डार्क वेब
डार्क वेब वह सामग्री है जो डार्कनेट्स पर मौजूद है, जो ओवरले नेटवर्क हैं जो इंटरनेट का उपयोग करते हैं लेकिन पहुंच के लिए विशिष्ट सॉफ़्टवेयर, कॉन्फ़िगरेशन या अनुमति की आवश्यकता होती है। डार्क वेब गहरे वेब का एक छोटा हिस्सा है, वह हिस्सा जो वेब खोज इंजनों द्वारा अनुक्रमित नहीं किया गया है, हालांकि कभी-कभी गहरे वेब का शब्द विशेष रूप से डार्क वेब के लिए गलत तरीके से उपयोग किया जाता है। डार्कनेट्स जो डार्क वेब का निर्माण करते हैं, उनमें छोटे, मित्र-से-मित्र पीयर-टू-पीयर नेटवर्क के साथ-साथ बड़े, लोकप्रिय नेटवर्क जैसे कि Tor, Freenet, I2P, और Riffle शामिल हैं, जो सार्वजनिक संगठनों और व्यक्तियों द्वारा संचालित होते हैं। डार्क वेब के उपयोगकर्ता नियमित वेब को Clearnet कहते हैं क्योंकि इसकी प्रकृति अनएन्क्रिप्टेड होती है। Tor डार्क वेब को Onionland के रूप में संदर्भित किया जा सकता है, जो नेटवर्क के शीर्ष-स्तरीय डोमेन प्रत्यय .onion और ट्रैफिक गुमनामकरण तकनीक onion routing का संदर्भ है।
वेब के प्रकार

वनाक्राई
वनाक्राई रैंसमवेयर हमले को मई 2017 में विश्वव्यापी साइबर हमले के रूप में जाना जाता है, यह Wannacry रैंसमवेयर क्रिप्टोवॉर्म द्वारा किया गया था, जिसने Microsoft Windows ऑपरेटिंग सिस्टम पर चलने वाले कंप्यूटरों को लक्षित किया, डेटा को एन्क्रिप्ट किया और Bitcoin क्रिप्टोकरेंसी में फिरौती का भुगतान मांगा। यह Eternal Blue के माध्यम से फैल गया, जो पुराने Windows सिस्टम में एक शोषण था जिसे The Shadow Brokers ने हमले से कुछ महीने पहले जारी किया था। जबकि Microsoft ने पहले इस शोषण को बंद करने के लिए पैच जारी किए थे, वनाक्राई के फैलने का अधिकांश हिस्सा उन संगठनों से था जिन्होंने इन्हें लागू नहीं किया था या पुराने Windows सिस्टम का उपयोग कर रहे थे जो अपने अंत-जीवन से बाहर थे। वनाक्राई ने संक्रमित सिस्टम पर बैकडोर स्थापित करने का भी लाभ उठाया।
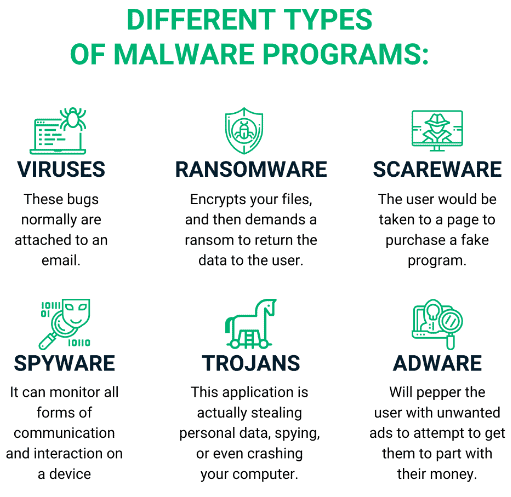
मैलवेयर के प्रकार
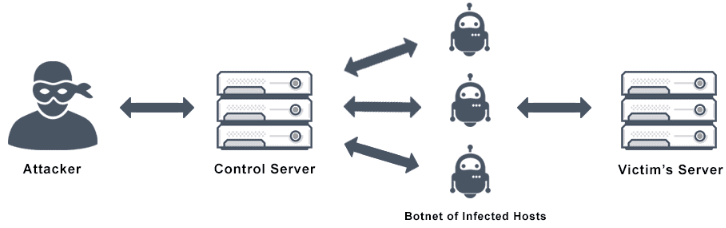
बॉटनेट एक बॉटनेट कई इंटरनेट से जुड़े उपकरणों का समूह है, जिनमें से प्रत्येक एक या अधिक बॉट चला रहा है। बॉटनेट का उपयोग वितरित सेवा अस्वीकृति हमले (DDoS हमला) करने, डेटा चुराने, स्पैम भेजने और हमलावर को उपकरण और उसकी कनेक्शन तक पहुंच प्रदान करने के लिए किया जा सकता है। मालिक कमांड और कंट्रोल (C&C) सॉफ़्टवेयर का उपयोग करके बॉटनेट को नियंत्रित कर सकता है। "बॉटनेट" शब्द "रोबोट" और "नेटवर्क" के शब्दों का संयोजन है। इस शब्द का आमतौर पर नकारात्मक या दुर्भावनापूर्ण अर्थ में उपयोग किया जाता है।
DDoS (वितरित सेवा अस्वीकृति) हमला एक अवैध बड़े पैमाने पर साइबर अभियान है जहां एक बड़ी संख्या में उपकरणों का उपयोग किसी विशेष सर्वर पर ट्रैफ़िक उत्पन्न करने के लिए किया जाता है। यदि शामिल उपकरणों की संख्या पर्याप्त बड़ी है, तो उत्पन्न ट्रैफ़िक उस सर्वर की क्षमता से अधिक हो जाएगा। मैलवेयर पहले बॉट्स का एक नेटवर्क बनाता है — जिसे बॉटनेट कहा जाता है — और फिर उसी समय एकल सर्वर पर पिंग करने के लिए बॉटनेट का उपयोग करता है। ऐसी स्थिति में, सर्वर पर अत्यधिक लोड होने से वह क्रैश हो जाएगा। एक सफल DDoS हमले के बाद, जिन सेवाओं के सर्वर को टारगेट किया गया था, उनके ग्राहक सर्वर क्रैश के कारण उस सेवा का उपयोग नहीं कर पाएंगे।
रीपर एक अत्यधिक विकसित मैलवेयर है जो न केवल WiFi राउटर्स और सुरक्षा कैमरों जैसे उपकरणों को हैक करने में सक्षम है, बल्कि यह बॉट में अपनी उपस्थिति को छिपाने की भी क्षमता रखता है — एक ऐसा उपकरण जो मैलवेयर द्वारा नियंत्रित होता है।
स्पेक्ट्रम पूलिंग एक स्पेक्ट्रम प्रबंधन रणनीति है जिसमें कई रेडियो स्पेक्ट्रम उपयोगकर्ता एक ही रेडियो स्पेक्ट्रम स्पेस के आवंटन में सह-अस्तित्व कर सकते हैं। इस तकनीक का एक उपयोग यह है कि स्पेक्ट्रम आवंटन के प्रमुख उपयोगकर्ता अपने आवंटन केunused भागों का उपयोग द्वितीयक उपयोगकर्ताओं को किराए पर दे सकते हैं। स्पेक्ट्रम पूलिंग योजनाएं आमतौर पर उन्हें लागू करने के लिए संज्ञानात्मक रेडियो तकनीकों की आवश्यकता होती हैं।
संज्ञानात्मक रेडियो (Cognitive Radio) एक ऐसा रेडियो है जिसे डायनामिक रूप से प्रोग्राम और कॉन्फ़िगर किया जा सकता है, ताकि यह अपने आस-पास के सबसे अच्छे वायरलेस चैनलों का उपयोग कर सके और उपयोगकर्ता हस्तक्षेप और भीड़ से बच सके। ऐसा रेडियो स्वचालित रूप से वायरलेस स्पेक्ट्रम में उपलब्ध चैनलों का पता लगाता है, और फिर इसके अनुसार अपने संप्रेषण या स्वीकरण मापदंडों को बदलता है ताकि एक स्थान पर एक ही स्पेक्ट्रम बैंड में अधिक समकालिक वायरलेस संचार की अनुमति मिल सके। यह प्रक्रिया डायनामिक स्पेक्ट्रम प्रबंधन का एक रूप है।
HTTPS (Hypertext Transfer Protocol Secure) एक ऐसा प्रोटोकॉल है जो कंप्यूटर नेटवर्क पर सुरक्षित संचार के लिए Hypertext Transfer Protocol (HTTP) का विस्तार है और इसे इंटरनेट पर व्यापक रूप से उपयोग किया जाता है। HTTPS का मुख्य उद्देश्य एक्सेस किए गए वेबसाइट की प्रमाणीकरण और डेटा की गोपनीयता और अखंडता की सुरक्षा करना है, जबकि यह ट्रांजिट में होता है। यह मैन-इन-द-मिडल हमलों से सुरक्षा प्रदान करता है। क्लाइंट और सर्वर के बीच संचार का द्विदिशात्मक एन्क्रिप्शन ईavesdropping और संचार में छेड़छाड़ से सुरक्षा करता है। वास्तव में, यह एक उचित आश्वासन प्रदान करता है कि कोई उस वेबसाइट के साथ संचार कर रहा है जिसे वह संचारित करना चाहता है, न कि किसी धोखेबाज़ के साथ।

क्वांटम कंप्यूटर (Quantum Computer) क्वांटम-मैकेनिकल घटनाओं, जैसे कि सुपरपोजिशन और एंटैंगलमेंट का उपयोग करके कंप्यूटिंग है। एक क्वांटम कंप्यूटर एक ऐसा उपकरण है जो क्वांटम कंप्यूटिंग करता है। ऐसा कंप्यूटर बाइनरी डिजिटल इलेक्ट्रॉनिक कंप्यूटरों से भिन्न होता है जो ट्रांजिस्टर पर आधारित होते हैं। जबकि सामान्य डिजिटल कंप्यूटिंग में डेटा को बाइनरी अंकों (बिट्स) में एन्कोड किया जाता है, जो हमेशा दो निश्चित स्थितियों (0 या 1) में होते हैं, क्वांटम गणना क्वांटम बिट्स या क्यूबिट्स का उपयोग करती है, जो स्थितियों के सुपरपोजिशन में हो सकते हैं। क्यूबिट क्वांटम कंप्यूटिंग की मूल इकाई है और यह बाइनरी सिस्टम का उपपरमाणवी समकक्ष है जिसमें 0 और 1 होते हैं, जिसका हम आज उपयोग करते हैं। यह कणों की बाइनरी विशेषताओं, इलेक्ट्रॉन स्पिन (ऊपर और नीचे), फोटॉन ध्रुवीकरण (सकारात्मक और नकारात्मक) आदि का उपयोग करता है, लेकिन, श्रोडिंगर की बिल्ली की तरह, वास्तव में दोनों स्थितियों में एक साथ हो सकता है, जिसे सुपरपोजिशन कहा जाता है। भौतिकविदों ने देखा है कि जब एक कण का अवलोकन किया जाता है, तो यह पूरी तरह से अलग, विपरीत कण की स्थिति को प्रभावित करता है, जिसे एंटैंगलमेंट कहा जाता है। यह क्वांटम कंप्यूटिंग और संचार का आधार है।
क्वांटम कंप्यूटर
क्वांटम कंप्यूटिंग एक ऐसा कंप्यूटिंग है जो क्वांटम-यांत्रिक घटनाओं, जैसे कि सुपरपोजिशन और एंटैंगलमेंट का उपयोग करता है। एक क्वांटम कंप्यूटर एक ऐसा उपकरण है जो क्वांटम कंप्यूटिंग करता है। यह कंप्यूटर ट्रांजिस्टर पर आधारित बाइनरी डिजिटल इलेक्ट्रॉनिक कंप्यूटर से भिन्न है। जबकि सामान्य डिजिटल कंप्यूटिंग में डेटा को बाइनरी अंकों (बिट्स) में कोडित किया जाना आवश्यक है, जो हमेशा दो निश्चित अवस्थाओं (0 या 1) में होता है, क्वांटम कंप्यूटिंग क्वांटम बिट्स या क्यूबिट्स का उपयोग करता है, जो अवस्थाओं के सुपरपोजिशन में हो सकते हैं। क्यूबिट क्वांटम कंप्यूटिंग की मूल इकाई है और यह बाइनरी प्रणाली का उपपरमाणु समकक्ष है जिसमें 0 और 1 शामिल हैं, जिसका हम आज उपयोग करते हैं। यह कणों की बाइनरी विशेषताओं, इलेक्ट्रॉन स्पिन (ऊपर और नीचे), फोटोन ध्रुवीकरण (सकारात्मक और नकारात्मक) आदि का उपयोग करता है, लेकिन, जैसे श्रेडिंगर की बिल्ली, वास्तव में दोनों अवस्थाओं में एक साथ हो सकता है, जिसे सुपरपोजिशन कहा जाता है। भौतिकविदों ने देखा है कि जब एक कण का अवलोकन किया जाता है, तो यह पूरी तरह से भिन्न, विपरीत कण की अवस्था को प्रभावित करता है, जिसे एंटैंगलमेंट कहा जाता है। यह क्वांटम कंप्यूटिंग और संचार का आधार है।
क्वांटम सुप्रीमैसी
- क्वांटम सुप्रीमैसी एक क्वांटम कंप्यूटर का उपयोग करके एक ऐसा एकल गणना करने की क्षमता है जिसे कोई पारंपरिक कंप्यूटर, यहां तक कि सबसे बड़ा सुपरकंप्यूटर भी, उचित समय में नहीं कर सकता।
- गूगल के शोधकर्ताओं का दावा है कि उन्होंने कंप्यूटर विज्ञान में "क्वांटम सुप्रीमैसी" के रूप में ज्ञात एक प्रमुख मील का पत्थर हासिल किया है।
- गूगल के शोध में यह जांचना शामिल था कि यादृच्छिक संख्या उत्पन्न करने के लिए एक एल्गोरिदम का आउटपुट वास्तव में यादृच्छिक था या नहीं।
- शोधकर्ताओं ने इस जटिल गणितीय गणना को तीन मिनट और 20 सेकंड में करने के लिए एक क्वांटम कंप्यूटर का उपयोग किया, जैसे कि पेपर में बताया गया है।
- यह दावा किया गया है कि इसे करने में Summit 3—एक आईबीएम द्वारा निर्मित मशीन, जो दुनिया का सबसे शक्तिशाली वाणिज्यिक पारंपरिक कंप्यूटर है—को लगभग 10,000 वर्ष लगते।
साइकामोर: साइकामोर गूगल का अत्याधुनिक क्वांटम कंप्यूटर है जिसे क्वांटम सुप्रीमैसी के लिए उपयोग किया गया था।
क्वांटम-सक्षम विज्ञान और प्रौद्योगिकी (QuEST) कार्यक्रम भारत में अपने पहले चरण में क्वांटम कंप्यूटर विकसित करने के लिए बुनियादी ढाँचे का निर्माण और मानव संसाधनों की अधिग्रहण पर काम शुरू कर रहा है। यह कार्यक्रम विज्ञान और प्रौद्योगिकी मंत्रालय (DST) द्वारा संचालित किया जा रहा है। वर्तमान में, QuEST को DST द्वारा वित्तपोषित किया जा रहा है, जिसने चरण 1 के लिए 80 करोड़ रुपये का निवेश किया है। तीन वर्षों के बाद, रक्षा अनुसंधान और विकास संगठन (DRDO), भारतीय अंतरिक्ष अनुसंधान संगठन (ISRO), और परमाणु ऊर्जा विभाग (DAE) को चरण 2 के लिए 300 करोड़ रुपये का संयुक्त वित्तपोषण करने की उम्मीद है।
ब्लॉकचेन मूल रूप से वित्तीय लेनदेन का एक डिजिटल लेजर या विकेंद्रीकृत डेटाबेस है, जो अपरिवर्तनीय और तुरंत दुनिया भर में अद्यतन होता है। डिज़ाइन के अनुसार, एक ब्लॉकचेन डेटा के संशोधन के प्रति प्रतिरोधी है। यह “दो पक्षों के बीच लेनदेन को कुशलता से और एक प्रमाणिक एवं स्थायी तरीके से रिकॉर्ड करने वाला एक खुला, वितरित लेजर है”। एक वितरित लेजर के रूप में उपयोग के लिए, एक ब्लॉकचेन आमतौर पर एक पीयर-टू-पीयर नेटवर्क द्वारा प्रबंधित किया जाता है जो नोड के बीच संचार और नए ब्लॉकों को मान्य करने के लिए एक प्रोटोकॉल का पालन करता है। एक बार रिकॉर्ड होने के बाद, किसी दिए गए ब्लॉक में डेटा को पूर्ववर्ती रूप से संशोधित नहीं किया जा सकता है बिना सभी बाद के ब्लॉकों के संशोधन के, जिसके लिए नेटवर्क के बहुमत की सहमति आवश्यक होती है। हालांकि ब्लॉकचेन रिकॉर्ड अपरिवर्तनीय नहीं होते हैं, ब्लॉकचेन को डिज़ाइन द्वारा सुरक्षित माना जा सकता है और यह एक वितरित कंप्यूटिंग सिस्टम का उदाहरण प्रस्तुत करता है जिसमें उच्च बिजेंटाइन दोष सहिष्णुता होती है। इसलिए, ब्लॉकचेन के साथ विकेंद्रीकृत सहमति का दावा किया गया है। ब्लॉकचेन का आविष्कार सातोशी नाकामोटो ने 2008 में क्रिप्टोकurrency बिटकॉइन के सार्वजनिक लेनदेन लेजर के रूप में किया था। बिटकॉइन के लिए ब्लॉकचेन का आविष्कार इसे एक विश्वसनीय प्राधिकरण या केंद्रीय सर्वर की आवश्यकता के बिना डबल स्पेंडिंग समस्या को हल करने वाला पहला डिजिटल मुद्रा बना दिया। बिटकॉइन के डिज़ाइन ने अन्य अनुप्रयोगों को प्रेरित किया है, और सार्वजनिक रूप से पढ़े जाने योग्य ब्लॉकचेन का व्यापक रूप से क्रिप्टोकुरेंसी द्वारा उपयोग किया जाता है। व्यवसाय उपयोग के लिए निजी ब्लॉकचेन का प्रस्ताव किया गया है। कुछ ब्लॉकचेन के विपणन को “स्नेक ऑयल” कहा गया है।
बिटकॉइन बिटकॉइन एक क्रिप्टोक्यूरेंसी है, जो एक प्रकार का इलेक्ट्रॉनिक नकद है। यह एक विकेंद्रीकृत डिजिटल मुद्रा है, जिसमें कोई केंद्रीय बैंक या एकल प्रशासक नहीं है, और इसे पियर-टू-पियर बिटकॉइन नेटवर्क पर उपयोगकर्ता से उपयोगकर्ता को मध्यस्थों की आवश्यकता के बिना भेजा जा सकता है। लेन-देन को नेटवर्क नोड्स द्वारा क्रिप्टोग्राफी के माध्यम से सत्यापित किया जाता है और इसे एक सार्वजनिक वितरित खाता-बही, जिसे ब्लॉकचेन कहा जाता है, में दर्ज किया जाता है। बिटकॉइन का आविष्कार एक अज्ञात व्यक्ति या लोगों के समूह द्वारा किया गया था, जिन्होंने सातोशी नाकामोटो के नाम का उपयोग किया और इसे 2009 में ओपन-सोर्स सॉफ़्टवेयर के रूप में जारी किया। बिटकॉइन को खनन (mining) के एक प्रक्रिया के लिए इनाम के रूप में बनाया जाता है। इन्हें अन्य मुद्राओं, उत्पादों और सेवाओं के लिए विनिमय किया जा सकता है। बिटकॉइन की आलोचना इसकी अवैध लेन-देन में उपयोग, उच्च बिजली खपत, मूल्य में उतार-चढ़ाव, एक्सचेंजों से चोरी, और इस संभावना के लिए की गई है कि बिटकॉइन एक आर्थिक बुलबुला हो सकता है। बिटकॉइन को एक निवेश के रूप में भी उपयोग किया गया है, हालांकि कई नियामक एजेंसियों ने बिटकॉइन के बारे में निवेशकों को चेतावनियाँ जारी की हैं।
कृत्रिम बुद्धिमत्ता (AI) "बुद्धिमान मशीनें बनाने के विज्ञान और इंजीनियरिंग" का अध्ययन है, विशेष रूप से बुद्धिमान कंप्यूटर प्रोग्राम। AI बुद्धिमान मशीनों को सक्षम बनाता है जो कार्यों को निष्पादित कर सकती हैं, जो मानव क्षमताओं के समान हैं जैसे बोलना, चेहरे, वस्तु या इशारा पहचानना, सीखना, समस्या-समाधान, तर्क करना, अनुभव और प्रतिक्रिया देना। AI मशीनों को बुद्धिमानी से सोचने में सक्षम बनाता है, जो कुछ हद तक उस बुद्धिमत्ता के समान है जिसका उपयोग मानव अपने दैनिक व्यक्तिगत या पेशेवर जीवन में सीखने, समझने, सोचने, निर्णय लेने या समस्या हल करने के लिए करते हैं। बुद्धिमत्ता अमूर्त है। AI में वर्तमान उत्साह की लहर उद्योग द्वारा समर्थित है, जिसमें Apple, Amazon, Google, Facebook, IBM, Microsoft, और Baidu अग्रणी हैं। ऑटोमोटिव उद्योग भी सेल्फ-ड्राइविंग कारों के लिए AI के लाभों को उजागर कर रहा है, जिसमें Tesla, Mercedez-Benz, Google, और Uber शामिल हैं।
हमारे चारों ओर के वास्तविक जीवन के उदाहरण:
- AI-सक्षम कारें पहले से ही कठोर परीक्षण के अधीन हैं और वे जल्द ही सड़कों पर चलने की संभावना है।
- सोशल ह्यूमनॉइड रोबोट Sophia ने 2017 में सऊदी अरब की नागरिकता प्राप्त की।
- ऐपल का इंटेलिजेंट पर्सनल असिस्टेंट, Siri, निर्देश प्राप्त कर सकता है और मानवों के साथ स्वाभाविक भाषा में बातचीत कर सकता है।
- स्वायत्त हथियार खुद से सैन्य मिशनों को अंजाम दे सकते हैं, लक्ष्यों की पहचान कर सकते हैं और किसी भी मानव हस्तक्षेप के बिना उन पर हमला कर सकते हैं।
- चेहरे की पहचान ने कानून प्रवर्तन और सुरक्षा एजेंसियों से गहरी रुचि पैदा की है।
- चीन एक विशाल चेहरे की पहचान प्रणाली बनाने के लिए जाना जाता है, जो अपने निगरानी कैमरा नेटवर्क से जुड़ी है, ताकि अपराधियों और भगोड़ों का पता लगाने में मदद मिल सके।
- AI सैन्य बलों के आदेश, प्रशिक्षण और तैनाती के तरीकों को भी बदल रहा है।
AI के अनुप्रयोग:
- गेमिंग उद्योग, जहां AI-सक्षम कंप्यूटर चेस, पोकर और गो जैसे खेलों में संभावित स्थितियों की एक बड़ी संख्या पर विचार कर सकते हैं। ये कंप्यूटर उन मानवों की क्षमताओं का परीक्षण कर सकते हैं जो इन AI-सक्षम कंप्यूटरों के खिलाफ खेल रहे हैं, ऐसे खेलों या अनुकरणों में जो अधिक गणितीय और रणनीतिक गहराई की आवश्यकता रखते हैं।
- प्राकृतिक भाषा प्रसंस्करण क्षमता वाले कंप्यूटर मानव भाषा को समझ सकते हैं और उत्पन्न कर सकते हैं, जिसमें भाषण भी शामिल है, जो मानव क्षमताओं को सुनने, समझने, सोचने और प्रतिक्रिया देने की नकल करता है।
- कानून प्रवर्तन या आंतरिक सुरक्षा आवश्यकताएँ व्यक्तियों या अपराधियों का पता लगाने और पहचानने के लिए, पुलिस डेटाबेस या निगरानी कैमरों के नेटवर्क से डेटा की धारा के साथ।
- स्वास्थ्य सेवा उद्योग में अनुकूलित उपचार योजनाओं को डिजाइन करना, दोहराए जाने वाले कार्यों में सहायता, चिकित्सा रिकॉर्ड के लिए डेटा प्रबंधन, या बेहतर विश्लेषण के साथ नैदानिक निर्णय लेने में सहायता करना।
- बैंकिंग और वित्तीय सेवाओं में धोखाधड़ी पहचान के लिए उन्नत एल्गोरिदम का उपयोग करना, लेनदेन और उपभोक्ता व्यवहार में जोखिम-प्रवण पैटर्न की पहचान के लिए।
- ऑटोमोटिव उद्योग पहले से ही AI एल्गोरिदम का उपयोग कर रहा है ताकि वाहनों में ईंधन दक्षता और सुरक्षा को बढ़ाया जा सके, जैसे कि स्वचालित ब्रेकिंग, टकराव से बचने की प्रणाली, पैदल चलने वालों और साइकिल चालकों के लिए चेतावनियाँ, और बुद्धिमान क्रूज नियंत्रण।
डीप लर्निंग
यह कृत्रिम बुद्धिमत्ता (AI) का एक पहलू है जो मानवों द्वारा ज्ञान प्राप्ति के लिए अपनाए जाने वाले लर्निंग दृष्टिकोण की नकल करने से संबंधित है। इसे सरलतम रूप में, डीप लर्निंग को भविष्यवाणी विश्लेषण (predictive analytics) को स्वचालित करने के तरीके के रूप में सोचा जा सकता है। जबकि पारंपरिक मशीन लर्निंग एल्गोरिदम रेखीय होते हैं, डीप लर्निंग एल्गोरिदम जटिलता और अमूर्तता की बढ़ती परतों में व्यवस्थित होते हैं। डीप लर्निंग को समझने के लिए, एक छोटे बच्चे की कल्पना करें जिसका पहला शब्द "कुत्ता" है। बच्चा वस्तुओं की ओर इशारा करके और "कुत्ता" शब्द कहकर यह सीखता है कि कुत्ता क्या है (और क्या नहीं है)। माता-पिता कहते हैं, "हाँ, यह एक कुत्ता है," या, "नहीं, यह कुत्ता नहीं है।" जैसे-जैसे बच्चा वस्तुओं की ओर इशारा करता है, वह सभी कुत्तों में मौजूद विशेषताओं के प्रति अधिक जागरूक हो जाता है। बच्चा जो करता है, वह बिना जाने एक जटिल अमूर्तता (कुत्ते का अवधारणा) को स्पष्ट करता है, एक ऐसी परत बनाकर जिसमें प्रत्येक अमूर्तता का स्तर पूर्ववर्ती परत से प्राप्त ज्ञान के साथ बनाया गया है।
मशीन लर्निंग
मशीन लर्निंग कृत्रिम बुद्धिमत्ता (AI) का एक अनुप्रयोग है जो प्रणालियों को अनुभव से स्वचालित रूप से सीखने और सुधारने की क्षमता प्रदान करता है, बिना स्पष्ट रूप से प्रोग्राम किए। मशीन लर्निंग उन कंप्यूटर प्रोग्रामों के विकास पर ध्यान केंद्रित करता है जो डेटा तक पहुँच सकते हैं और इसका उपयोग करके स्वयं सीख सकते हैं। सीखने की प्रक्रिया अवलोकनों या डेटा, जैसे उदाहरणों, प्रत्यक्ष अनुभव, या निर्देशों से शुरू होती है, ताकि डेटा में पैटर्न की तलाश की जा सके और भविष्य में बेहतर निर्णय लिए जा सकें। इसका मुख्य उद्देश्य यह है कि कंप्यूटर मानव हस्तक्षेप या सहायता के बिना स्वचालित रूप से सीखें और तदनुसार क्रियाएँ समायोजित करें।
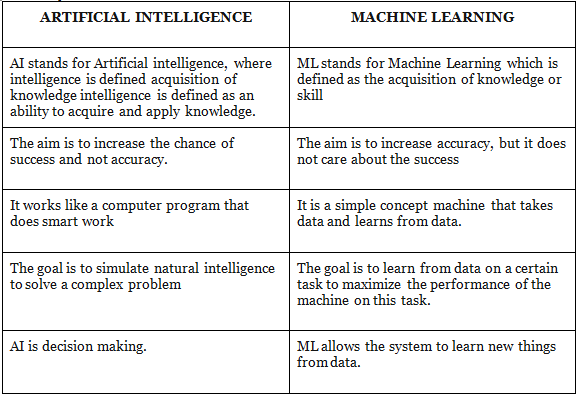
AI और ML के बीच मुख्य अंतर हैं:

प्रोजेक्ट ब्रेनवेव माइक्रोसॉफ्ट ने “प्रोजेक्ट ब्रेनवेव” लॉन्च किया है, जो वास्तविक समय की कृत्रिम बुद्धिमत्ता (AI) के लिए एक गहन शिक्षण प्रवर्धन मंच है। यह विशाल फील्ड-प्रोग्रामेबल गेट एरे (FPGA) अवसंरचना का उपयोग करता है। प्रणाली की आर्किटेक्चर बहुत उच्च थ्रूपुट की अनुमति देती है, जिसमें FPGA अनुरोधों को इतनी तेजी से संसाधित करता है जितनी तेजी से नेटवर्क उन्हें स्ट्रीम कर सकता है। महत्व: वास्तविक समय की AI越来越 महत्वपूर्ण होती जा रही है क्योंकि क्लाउड अवसंरचनाएँ लाइव डेटा स्ट्रीम को प्रोसेस करती हैं, चाहे वे खोज प्रश्न, वीडियो, सेंसर स्ट्रीम, या उपयोगकर्ताओं के साथ इंटरैक्शन हों।
ह्यूमनॉइड रोबोट एक ऐसा रोबोट है जिसका शरीर मानव शरीर के आकार के समान बनाया गया है। इसका डिज़ाइन कार्यात्मक उद्देश्यों के लिए हो सकता है, जैसे मानव उपकरणों और वातावरण के साथ इंटरैक्ट करना, प्रयोगात्मक उद्देश्यों के लिए, जैसे गतिशीलता अध्ययन करना, या अन्य उद्देश्यों के लिए। सामान्य रूप से, ह्यूमनॉइड रोबोट में एक धड़, एक सिर, दो हाथ और दो पैर होते हैं, हालाँकि कुछ प्रकार के ह्यूमनॉइड रोबोट केवल शरीर के एक हिस्से का मॉडल बना सकते हैं, उदाहरण के लिए, कमर से ऊपर। कुछ ह्यूमनॉइड रोबोटों के सिर भी होते हैं जो मानव चेहरे की विशेषताओं जैसे आंखों और मुँह को दोहराने के लिए डिज़ाइन किए जाते हैं। एंड्रॉइड ऐसे ह्यूमनॉइड रोबोट होते हैं जो सौंदर्य की दृष्टि से मानवों के समान बनाए जाते हैं।
ह्यूमनॉइड रोबोट के विशेषताएँ –
- स्व-संरक्षण
- स्वायत्त शिक्षण
- लोगों, संपत्ति और स्वयं के लिए हानिकारक स्थितियों से बचना
- मानवों और पर्यावरण के साथ सुरक्षित इंटरैक्शन
ह्यूमनॉइड रोबोट सोफिया दुनिया की पहली रोबोट नागरिक बनी, जब सऊदी अरब ने उसे नागरिकता दी ताकि कृत्रिम बुद्धिमत्ता को बढ़ावा दिया जा सके।
सोफिया सोफिया एक सामाजिक मानव-रोबोट है जिसे हांगकांग स्थित कंपनी Hanson Robotics द्वारा विकसित किया गया है। सोफिया को 19 अप्रैल, 2015 को सक्रिय किया गया था। वह 50 से अधिक चेहरे के भाव प्रदर्शित करने में सक्षम है। नवंबर 2017 में, सोफिया को संयुक्त राष्ट्र विकास कार्यक्रम का पहला नवाचार चैंपियन नामित किया गया, और वह किसी भी संयुक्त राष्ट्र शीर्षक से सम्मानित होने वाली पहली गैर-मानव बनी।
पारंपरिक ज्ञान डिजिटल पुस्तकालय (TKDL) पारंपरिक ज्ञान डिजिटल पुस्तकालय (TKDL) भारत की एक अग्रणी पहल है जिसका उद्देश्य देश के पारंपरिक औषधीय ज्ञान की अंतरराष्ट्रीय पेटेंट कार्यालयों में गलत व्यावसायिक उपयोग को रोकना है, जिस पर भारत की 70% से अधिक जनसंख्या की स्वास्थ्य आवश्यकताएं और लाखों लोगों की आजीविका निर्भर करती है। इसका उद्गम उस भारतीय प्रयास से है जिसमें USPTO पर हल्दी के घाव भरने वाले गुणों के पेटेंट को निरस्त करने की मांग की गई थी। इसके अतिरिक्त, 2005 में, TKDL विशेषज्ञ समूह ने अनुमान लगाया कि अंतरराष्ट्रीय स्तर पर हर साल लगभग 2000 गलत पेटेंट भारतीय चिकित्सा प्रणालियों से संबंधित दिए जा रहे हैं, मुख्यतः इस तथ्य के कारण कि भारत का पारंपरिक औषधीय ज्ञान जो संस्कृत, हिंदी, अरबी, उर्दू, तमिल आदि स्थानीय भाषाओं में मौजूद है, अंतरराष्ट्रीय पेटेंट कार्यालयों के पेटेंट परीक्षकों के लिए न तो सुलभ है और न ही समझने योग्य।
पारंपरिक ज्ञान डिजिटल पुस्तकालय ने उपलब्ध सामग्री (अब तक 0.29 मिलियन औषधीय सूत्र) को वैज्ञानिक रूप से परिवर्तित और संरचित करके भाषा और प्रारूप की बाधा को पार किया है, जो भारतीय चिकित्सा प्रणालियों जैसे कि आयुर्वेद, सिद्ध, यूनानी, और योग पर प्राचीन ग्रंथों में वर्णित है, इसे पांच अंतरराष्ट्रीय भाषाओं - अंग्रेजी, जापानी, फ्रेंच, जर्मन और स्पेनिश में प्रस्तुत किया गया है, सूचना प्रौद्योगिकी उपकरणों और एक नवोन्मेषी वर्गीकरण प्रणाली - पारंपरिक ज्ञान संसाधन वर्गीकरण (TKRC) के माध्यम से।
परंपरागत ज्ञान डिजिटल पुस्तकालय (TKDL)
परंपरागत ज्ञान डिजिटल पुस्तकालय (TKDL) भारत की एक अग्रणी पहल है जिसका उद्देश्य देश के परंपरागत औषधीय ज्ञान के दुरुपयोग को अंतर्राष्ट्रीय पेटेंट कार्यालयों में रोकना है, जिस पर 70% से अधिक जनसंख्या की स्वास्थ्य आवश्यकताएँ और भारत के लाखों लोगों की आजीविका निर्भर करती है। इसका आरंभ उस समय हुआ जब भारत ने USPTO में हल्दी के घाव भरने की गुणों पर पेटेंट रद्द कराने की कोशिश की। इसके अलावा, 2005 में, TKDL विशेषज्ञ समूह ने अनुमान लगाया कि हर वर्ष लगभग 2000 गलत पेटेंट भारतीय चिकित्सा प्रणालियों से संबंधित अंतर्राष्ट्रीय स्तर पर दिए जा रहे हैं, मुख्यतः इस तथ्य के कारण कि भारत का परंपरागत औषधीय ज्ञान स्थानीय भाषाओं जैसे संस्कृत, हिंदी, अरबी, उर्दू, तमिल आदि में है, जो कि अंतर्राष्ट्रीय पेटेंट कार्यालयों के परीक्षकों के लिए न तो सुलभ है और न ही समझ में आता है।
परंपरागत ज्ञान डिजिटल पुस्तकालय ने वैज्ञानिक रूप से उपलब्ध सामग्री (जिसमें अब तक 0.29 मिलियन औषधीय सूत्र हैं) को भारतीय चिकित्सा प्रणालियों जैसे आयुर्वेद, सिद्ध, यूनानी, और योग पर प्राचीन ग्रंथों से रूपांतरित और संरचित करके भाषा और प्रारूप की बाधाओं को पार किया है। यह सामग्री अंग्रेज़ी, जापानी, फ्रेंच, जर्मन और स्पेनिश जैसी पांच अंतर्राष्ट्रीय भाषाओं में उपलब्ध है, जिसमें सूचना प्रौद्योगिकी उपकरणों और एक नवीन वर्गीकरण प्रणाली – परंपरागत ज्ञान संसाधन वर्गीकरण (TKRC) की मदद ली गई है।
TKRC की संरचना
TKRC ने आयुर्वेद, यूनानी, सिद्ध, और योग में भारतीय परंपरागत चिकित्सा प्रणाली को लगभग 25,000 उप-समूहों में संरचित और वर्गीकृत किया है। TKRC ने A61K 36/00 के तहत लगभग 200 उप-समूहों के समावेश की अनुमति दी है, जबकि पहले A61K 35/00 के तहत औषधीय पौधों पर केवल कुछ उप-समूह उपलब्ध थे, जिससे परंपरागत ज्ञान के क्षेत्र में पेटेंट आवेदनों के लिए पूर्व-कलाकृतियों की खोज और परीक्षण की गुणवत्ता में सुधार हुआ है। TKDL ने TKDL विनिर्देशों के आधार पर TK डेटाबेस स्थापित करने के लिए अंतर्राष्ट्रीय मानकों और मानकों को भी निर्धारित किया है। इसे 2003 में WIPO की बौद्धिक संपदा और आनुवंशिक संसाधनों, परंपरागत ज्ञान और लोककथाओं के अभिव्यक्ति पर अंतर-सरकारी समिति (IGC) के पांचवें सत्र में अपनाया गया था।
TKDL प्रौद्योगिकी विविध विषयों और भाषाओं जैसे आयुर्वेद, यूनानी, सिद्ध, योग, संस्कृत, अरबी, उर्दू, फारसी, तमिल, अंग्रेज़ी, जापानी, स्पेनिश, फ्रेंच, जर्मन, आधुनिक विज्ञान और आधुनिक चिकित्सा को समाहित करती है। अब तक, TKDL भारतीय चिकित्सा प्रणालियों की 359 पुस्तकों पर आधारित है, जो कि लगभग 1000 अमेरिकी डॉलर की लागत में खुली डोमेन में उपलब्ध हैं और किसी भी व्यक्ति/संस्थान द्वारा राष्ट्रीय/अंतर्राष्ट्रीय स्तर पर प्राप्त की जा सकती हैं। TKDL इन पुस्तकों (पूर्व-कलाकृतियों) और अंतर्राष्ट्रीय पेटेंट परीक्षकों के बीच एक पुल के रूप में कार्य करती है।
TKDL प्रौद्योगिकी ने एक अद्वितीय तंत्र बनाया है जिससे एक संस्कृत श्लोक को जर्मन, जापानी, अंग्रेज़ी, स्पेनिश और फ्रेंच जैसी भाषाओं में किसी भी अंतर्राष्ट्रीय पेटेंट कार्यालय में परीक्षक द्वारा उसके कंप्यूटर स्क्रीन पर पढ़ा जा सकता है। वर्तमान में, आर्थिक मामलों पर मंत्रिमंडल समिति की स्वीकृति के अनुसार, TKDL का उपयोग नौ अंतर्राष्ट्रीय पेटेंट कार्यालयों (यूरोपीय पेटेंट कार्यालय, संयुक्त राज्य पेटेंट और ट्रेडमार्क कार्यालय, जापान पेटेंट कार्यालय, यूनाइटेड किंगडम पेटेंट कार्यालय, कनाडाई बौद्धिक संपदा कार्यालय, जर्मन पेटेंट कार्यालय, बौद्धिक संपदा ऑस्ट्रेलिया, भारतीय पेटेंट कार्यालय, और चिली पेटेंट कार्यालय) के तहत TKDL एक्सेस (गोपनीयता) समझौते के तहत उपलब्ध है।
गोपनीयता समझौते की शर्तों के अनुसार, पेटेंट कार्यालय के परीक्षक केवल खोज और परीक्षण उद्देश्यों के लिए TKDL का उपयोग कर सकते हैं और उन्हें TKDL की सामग्री को किसी तीसरे पक्ष के सामने प्रकट नहीं करने की अनुमति है, जब तक कि यह संदर्भ के लिए आवश्यक न हो। TKDL एक्सेस समझौता अपनी प्रकृति में अद्वितीय है और भारत के हित की रक्षा के लिए गोपनीयता पर अंतर्निहित सुरक्षा उपाय हैं। इसके अतिरिक्त, विभिन्न अंतर्राष्ट्रीय पेटेंट कार्यालयों में पूर्व-प्रदान विरोध दर्ज किए जा रहे हैं, साथ ही TKDL से पूर्व-कलाकृति साक्ष्य भी।
अब तक महत्वपूर्ण प्रभाव महसूस किया जा चुका है। अब तक, संयुक्त राज्य अमेरिका, ग्रेट ब्रिटेन, स्पेन, इटली, चीन आदि की फार्मास्यूटिकल कंपनियों के लगभग 200 पेटेंट आवेदनों को TKDL डेटाबेस में मौजूद पूर्व-कलाकृति साक्ष्यों के आधार पर या तो रद्द किया गया है, या वापस लिया गया है, या संशोधित किया गया है, बिना किसी लागत के और कुछ हफ्तों/महीनों के भीतर, जबकि APEDA को बासमती चावल पेटेंट रद्द कराने के लिए केवल कानूनी शुल्क के लिए लगभग सात करोड़ खर्च करने पड़े। एक समान परिणाम लगभग 1200 और मामलों में अपेक्षित है, जहाँ TKDL ने पूर्व-प्रदान विरोध किया है। TKDL जैव-चोरी के खिलाफ एक प्रभावी निरोधक साबित हो रहा है और परंपरागत ज्ञान संरक्षण के क्षेत्र में एक वैश्विक नेता के रूप में पहचाना जा रहा है।
2011 में, WIPO द्वारा CSIR के सहयोग से ‘परंपरागत ज्ञान डिजिटल पुस्तकालय का संरक्षण के लिए मॉडल के रूप में उपयोग’ पर एक अंतर्राष्ट्रीय सम्मेलन आयोजित किया गया, जो नई दिल्ली में हुआ। इसके बाद, WIPO ने CSIR और DIPP (वाणिज्य और उद्योग मंत्रालय) के सहयोग से TKDL की पुनरावृत्ति में रुचि रखने वाले 19 देशों के लिए ‘TKDL पर अंतर्राष्ट्रीय अध्ययन यात्रा’ का आयोजन किया। TKDL ने दुनिया भर में, विशेष रूप से TK-समृद्ध देशों में, सक्रिय कार्रवाई के फायदों और मजबूत निरोधक की शक्ति को प्रदर्शित करके हलचल मचाई है। विचार यह नहीं है कि परंपरागत ज्ञान के उपयोग को सीमित किया जाए, बल्कि यह सुनिश्चित करना है कि पेटेंट परीक्षकों के लिए पूर्व-कलाकृति की अनुपलब्धता के कारण गलत पेटेंट जारी न किए जाएं। पेटेंट कार्यालय द्वारा TKDL एक्सेस समझौते में प्रवेश के लिए, CSIR परंपरागत ज्ञान डिजिटल पुस्तकालय इकाई के प्रमुख से संपर्क किया जा सकता है।
डिजीसेटिकल्स
क्या एक ऐप गोली की जगह ले सकता है? यही सवाल है जो एक उभरते हुए ट्रेंड "डिजिटल थेरेपी" के पीछे है। विचार यह है: ऐसा सॉफ़्टवेयर जो एक व्यक्ति के स्वास्थ्य को उतना ही सुधार सकता है जितना कि एक दवा, लेकिन बिना उसी लागत और दुष्प्रभावों के। डिजिटल थेरेपी, या जिन्हें कुछ लोग "डिजीसेटिकल्स" कहते हैं, सिलिकॉन वैली के कुछ हिस्सों में एक पवित्र ग्रेल बन गए हैं, जहाँ निवेशक आपके स्मार्टफोन के माध्यम से चिकित्सा प्रदान करने का अवसर देखते हैं। कुछ डिजीसेटिकल्स पारंपरिक दवाओं के साथ बेहतर काम करेंगे, न कि अकेले - यह तकनीक और फार्मा कंपनियों के बीच सहयोग की संभावनाओं को खोलता है। वोलंटिस, एक स्टार्टअप, विशेष दवाओं या चिकित्सा उपकरणों के लिए सहायक सॉफ़्टवेयर विकसित करता है। ये कार्यक्रम दुष्प्रभावों की निगरानी कर सकते हैं, लक्षणों को प्रबंधित करने में मदद कर सकते हैं और रोगियों को डॉक्टरों और नर्सों से जोड़ सकते हैं।
CIMON (क्रू इंटरएक्टिव मोबाइल साथी)
- यह एक 3D-प्रिंटेड कृत्रिम बुद्धिमत्ता प्रणाली है, जिसे इसके निर्माताओं द्वारा "उड़ता मस्तिष्क" के रूप में वर्णित किया गया है।
- यह प्लास्टिक और धातु से बनी है, जिसे 3D प्रिंटिंग का उपयोग करके बनाया गया है।
- इसे एयरबस द्वारा विकसित किया जा रहा है; जो नीदरलैंड्स में स्थित एक एरोनॉटिक्स कंपनी है।
- यह पहला AI-आधारित मिशन और उड़ान सहायता प्रणाली होगी।
- यह अंतर्राष्ट्रीय अंतरिक्ष स्टेशन (ISS) पर चालक दल में शामिल होगी और अंतरिक्ष यात्रियों की सहायता करेगी।
- इसे अंतरिक्ष यात्रियों को रूटीन काम करने में सहायता करने के लिए डिज़ाइन किया गया है।
क्रिप्टोजैकिंग
- क्रिप्टोजैकिंग को आपके कंप्यूटिंग डिवाइस का गुप्त उपयोग करके क्रिप्टोक्यूरेंसी खनन करने के रूप में परिभाषित किया गया है।
- क्रिप्टोजैकिंग पहले उस समय तक सीमित था जब पीड़ित अनजाने में एक प्रोग्राम इंस्टॉल करता था जो गुप्त रूप से क्रिप्टोक्यूरेंसी खनन करता है।
- हमलावर मालवेयर का उपयोग करके दूरस्थ उपयोगकर्ताओं के कंप्यूटर में प्रवेश करते हैं और फिर उनके हार्डवेयर का उपयोग करके सिक्कों के लिए खनन करते हैं।
- यह वितरण कंप्यूटिंग का यह रूप लाभकारी हो सकता है क्योंकि यह सैकड़ों प्रोसेसर वाले खनन रिग के स्वामित्व की लागत बोझ को समाप्त करता है।
- क्रिप्टोजैकर्स आमतौर पर लोकप्रिय वेबसाइटों को लक्ष्य बनाते हैं जो हर दिन लाखों दर्शकों को आकर्षित करती हैं।
हैप्टिक संचार
हैप्टिक संचार एक तकनीक है जो इंटरनेट के माध्यम से स्पर्श की अनुभूति को संप्रेषित करती है, जिसे बफेलो विश्वविद्यालय (UB) के वर्चुअल रियलिटी प्रयोगशालाओं में इंजीनियरों द्वारा विकसित किया गया है। इस ब्रेकथ्रू ने हैप्टिक तकनीकों के निर्माण की ओर अग्रसर किया है जो स्पर्श की अनुभूति को संप्रेषित करती हैं और उपयोगकर्ताओं को उन कौशल और गतिविधियों को महारत हासिल करने के लिए सिखाती हैं - जैसे कि सर्जरी, मूर्ति निर्माण, ड्रम बजाना या यहां तक कि गोल्फ - जो 'स्पर्श' और गति के सही अनुप्रयोग की आवश्यकता होती है।
डिजी शाला डिजी शाला, एक मुफ्त दूरदर्शन DTH चैनल है जिसे लोगों को डिजिटल भुगतान के विभिन्न तरीकों के बारे में शिक्षित और सूचित करने के लिए लॉन्च किया गया है। डिजी शाला GSAT15 (डीडी डायरेक्ट DTH), 93.5 डिग्री पूर्व, रिसीव फ्रीक्वेंसी: 11590 मेगाहर्ट्ज पर उपलब्ध होगा। यह चैनल लोगों को एकीकृत भुगतान इंटरफेस (UPI), USSD, आधार-सक्षम भुगतान प्रणाली, इलेक्ट्रॉनिक वॉलेट्स, डेबिट और क्रेडिट कार्ड के उपयोग को समझने में मदद करेगा। एक वेबसाइट भी लॉन्च की गई है जो डिजिटल भुगतान के बारे में ज्ञान का भंडार के रूप में कार्य करेगी। चैनल और वेबसाइट दोनों को ‘डिजी धन अभियान’ के हिस्से के रूप में लॉन्च किया गया था, जो आईटी मंत्रालय द्वारा तैयार किया गया एक अभियान है ताकि हर नागरिक, छोटे व्यापारी और दुकानदार अपने दैनिक वित्तीय लेनदेन में डिजिटल भुगतान को अपनाने में सक्षम हो सकें।
- डिजी शाला हर नागरिक, विशेष रूप से किसानों, छात्रों, दलितों और ग्रामीण क्षेत्रों की महिलाओं को डिजिटल भुगतान के उपयोगिता और लाभों को सीखने और इसे बड़े पैमाने पर अपनाने के लिए सक्षम और सशक्त करेगा।
- अर्थव्यवस्था के अर्ध-शहरी और ग्रामीण क्षेत्रों को डिजिटल साक्षरता प्रदान करना सरकार के लिए एक प्रमुख फोकस क्षेत्र बन गया है।
कंप्यूटर फ़ायरवॉल एक ऐसा सिस्टम है जिसे निजी नेटवर्क में अनधिकृत पहुँच को रोकने के लिए डिज़ाइन किया गया है। आप फ़ायरवॉल को हार्डवेयर या सॉफ़्टवेयर रूप में, या दोनों के संयोजन में लागू कर सकते हैं। फ़ायरवॉल अनधिकृत इंटरनेट उपयोगकर्ताओं को इंटरनेट से जुड़े निजी नेटवर्क, विशेष रूप से इंट्रानेट्स, तक पहुँचने से रोकते हैं। सभी संदेश जो इंट्रानेट (यानी, स्थानीय नेटवर्क जिसमें आप जुड़े हैं) में प्रवेश या बाहर जाते हैं, उन्हें फ़ायरवॉल के माध्यम से गुजरना होगा, जो प्रत्येक संदेश की जाँच करता है और उन संदेशों को ब्लॉक करता है जो निर्दिष्ट सुरक्षा मानदंडों को पूरा नहीं करते हैं। निजी जानकारी की सुरक्षा में, फ़ायरवॉल को रक्षा की पहली पंक्ति माना जाता है; हालाँकि, इसे एकमात्र ऐसी पंक्ति नहीं माना जा सकता है। फ़ायरवॉल आमतौर पर नेटवर्क ट्रैफ़िक और कनेक्शनों की सुरक्षा करने के लिए डिज़ाइन किए जाते हैं, और इसलिए वे यह निर्धारित करने के लिए व्यक्तिगत उपयोगकर्ताओं की प्रमाणीकरण करने का प्रयास नहीं करते हैं कि कौन किसी विशेष कंप्यूटर या नेटवर्क तक पहुँच सकता है।
साइबर-हमले साइबर-हमले में कंप्यूटर सिस्टम या नेटवर्क में निहित निजी या गोपनीय जानकारी तक अनधिकृत पहुँच शामिल होती है, लेकिन हमलावर द्वारा उपयोग की जाने वाली तकनीकें और तरीके यह निर्धारित करते हैं कि हमला सक्रिय साइबर-हमला है, एक निष्क्रिय प्रकार का हमला है, या दोनों का संयोजन। Symantec के अनुसार, सक्रिय और निष्क्रिय साइबर-हमले की परिभाषा अद्वितीय विशेषताओं और तकनीकों से की जाती है, और प्रत्येक प्रकार के हमले के लिए पीड़ितों, सिस्टम उपयोगकर्ताओं, सिस्टम प्रशासकों और साइबर सुरक्षा पेशेवरों के लिए अद्वितीय चुनौतियाँ होती हैं। सक्रिय और निष्क्रिय साइबर-हमलों के बीच का अंतर जानना सिस्टम उपयोगकर्ताओं और प्रशासकों को यह पहचानने में मदद कर सकता है कि कब हमला हो रहा है ताकि कार्रवाई की जा सके और हमले को नियंत्रित करने का प्रयास किया जा सके।
सक्रिय साइबर हमले सक्रिय साइबर-हमले अक्सर आक्रामक, स्पष्ट हमले होते हैं जिनके बारे में पीड़ित तुरंत जागरूक हो जाते हैं जब ये होते हैं। सक्रिय हमले स्वभाव से अत्यधिक दुष्ट होते हैं, अक्सर उपयोगकर्ताओं को लॉक आउट कर देते हैं, मेमोरी या फ़ाइलों को नष्ट कर देते हैं, या लक्षित सिस्टम या नेटवर्क में बलात्कारी पहुँच प्राप्त कर लेते हैं। वायरस, वर्म, मैलवेयर, डिनायल ऑफ सर्विस हमले, और पासवर्ड क्रैकर सभी सक्रिय साइबर-हमलों के उदाहरण हैं। आमतौर पर, सक्रिय हमले करने वाले हैकर अपनी गतिविधियों के पकड़े जाने की चिंता नहीं करते हैं क्योंकि जब तक हमला पहचाना जाता है, तब तक नुकसान पहले ही हो चुका होता है या जारी होता है।
निष्क्रिय साइबर हमले निष्क्रिय साइबर-हमले अक्सर गैर-विघटनकारी और गोपनीय तरीकों का उपयोग करते हैं ताकि हैकर हमले पर ध्यान न आकर्षित कर सके। निष्क्रिय हमले का उद्देश्य कंप्यूटर सिस्टम या नेटवर्क तक पहुँच प्राप्त करना और पहचान के बिना डेटा इकट्ठा करना है। कई डेटा सुरक्षा उल्लंघन, जिसमें क्रेडिट कार्ड और डेबिट कार्ड भुगतान जानकारी का खुलासा शामिल है, निष्क्रिय हमलों का परिणाम होते हैं, जैसे कि डेटा उल्लंघन जहाँ लक्षित डेटा जो हमले के दौरान इकट्ठा किया गया था, उपयोगकर्ता नाम, पासवर्ड, और अन्य व्यक्तिगत पहचान जानकारी होते हैं। निष्क्रिय हमले आमतौर पर डेटा-इकट्ठा करने के संचालन होते हैं, जिसका अर्थ है कि वे आमतौर पर किसी प्रकार के मैलवेयर या हैक का उपयोग करते हैं जो सिस्टम संचार पर नज़र रखते हैं (जैसे, व्यक्तिगत पहचान जानकारी के लिए ईमेल को स्क्रब करना) या सिस्टम संचार को रिकॉर्ड करते हैं (जैसे, कीस्ट्रोक रिकॉर्डिंग मैलवेयर)। निष्क्रिय साइबर-हमले में इकट्ठा की गई जानकारी आमतौर पर काले बाजार और डार्क वेब पर बेची जाती है ताकि निष्क्रिय हमले को अंजाम देने वाले व्यक्ति को वित्तीय लाभ मिल सके।
डिजिटल सिग्नेचर सर्टिफिकेट (DSC) एक सुरक्षित डिजिटल कुंजी है जो धारक की पहचान की पुष्टि करती है, जिसे एक प्रमाणन प्राधिकरण (CA) द्वारा जारी किया जाता है। इसमें आमतौर पर आपकी पहचान (नाम, ईमेल, देश, APNIC खाता नाम, और आपकी सार्वजनिक कुंजी) शामिल होती है।
- डिजिटल सर्टिफिकेट सार्वजनिक कुंजी अवसंरचना (Public Key Infrastructure) का उपयोग करते हैं, जिसका अर्थ है कि डेटा जिसे डिजिटल रूप से हस्ताक्षरित या एन्क्रिप्ट किया गया है, उसे एक निजी कुंजी द्वारा किया गया है और इसे केवल इसके संबंधित सार्वजनिक कुंजी द्वारा ही डिक्रिप्ट किया जा सकता है।
- एक डिजिटल सर्टिफिकेट एक इलेक्ट्रॉनिक "क्रेडिट कार्ड" है जो वेब पर व्यापार या अन्य लेनदेन करते समय आपकी योग्यता स्थापित करता है।
- डिजिटल सिग्नेचर कानूनी रूप से एक अदालत में स्वीकार्य होते हैं, जैसा कि IT अधिनियम, 2000 के प्रावधानों के तहत प्रदान किया गया है।
ओपन-सोर्स सॉफ़्टवेयर (OSS) एक कंप्यूटर सॉफ़्टवेयर है जिसका स्रोत कोड एक लाइसेंस के साथ उपलब्ध है जिसमें कॉपीराइट धारक किसी को भी सॉफ़्टवेयर का अध्ययन, परिवर्तन और वितरण करने के अधिकार प्रदान करता है। ओपन-सोर्स सॉफ़्टवेयर को एक सहयोगात्मक सार्वजनिक तरीके से विकसित किया जा सकता है।
- ओपन-सोर्स साझाकरण की मुख्य घटना पहले से ही उस समय की है जब पहला व्यक्तिगत कंप्यूटर (PC) स्थापित नहीं हुआ था। 1911 में, प्रगतिशील ऑटोमोबाइल निर्माता हेनरी फोर्ड मोटर व्हीकल मैन्युफैक्चरर्स एसोसिएशन को आगे बढ़ाने में सहायक थे। यह संघ एक ओपन-सोर्स पहल को प्रोत्साहित करता था जिसमें वास्तविक अमेरिकी वाहन निर्माता सीधे तकनीकी लाइसेंस साझा कर रहे थे बिना किसी आर्थिक लाभ की तलाश के।
सॉफ़्टवेयर-परिभाषित रेडियो
सॉफ़्टवेयर-निर्धारित रेडियो (SDR) एक रेडियो संचार प्रणाली है जिसमें वे घटक जो पारंपरिक रूप से हार्डवेयर (जैसे कि मिक्सर, फ़िल्टर, एम्पलीफायर, मॉड्यूलेटर/डिमोड्यूलेटर, डिटेक्टर्स आदि) में कार्यान्वित होते थे, उन्हें अब एक व्यक्तिगत कंप्यूटर या एम्बेडेड सिस्टम पर सॉफ़्टवेयर के माध्यम से कार्यान्वित किया जाता है। एक बुनियादी SDR प्रणाली में SDR सॉफ़्टवेयर चलाने वाला एक व्यक्तिगत कंप्यूटर शामिल हो सकता है जो USB या ईथरनेट के माध्यम से एनालॉग-टू-डिजिटल कनवर्टर के साथ इंटरफेस करता है, और इसके पहले एक RF फ्रंट एंड होता है जिसमें RF एम्पलीफायर, फ़िल्टर और एटेन्यूएटर्स होते हैं।
LIDAR-(लाइट डिटेक्शन एंड रेंजिंग)
- LIDAR, जिसका अर्थ है लाइट डिटेक्शन एंड रेंजिंग, एक रिमोट सेंसिंग विधि है जो पृथ्वी तक की दूरी (परिवर्तनीय दूरियाँ) मापने के लिए एक पल्स लेज़र के रूप में प्रकाश का उपयोग करती है।
- एक LIDAR उपकरण मुख्यतः एक लेज़र, एक स्कैनर, और एक विशेषीकृत GPS रिसीवर से मिलकर बनता है।
- विमान और हेलीकॉप्टर व्यापक क्षेत्रों में LIDAR डेटा प्राप्त करने के लिए सबसे सामान्यत: उपयोग किए जाने वाले प्लेटफॉर्म हैं।
- LIDAR के दो प्रकार होते हैं: टोपोग्राफिक और बैथमेट्रिक।
टोपोग्राफिक LIDAR सामान्यतः भूमि को मानचित्रित करने के लिए एक निकट-अवक्षीण लेज़र का उपयोग करता है, जबकि बैथमेट्रिक LIDAR पानी-प्रवेशी हरे प्रकाश का उपयोग करके समुद्र तल और नदी तल की ऊँचाइयाँ मापता है।
|
1 videos|326 docs|212 tests
|


Previous Year Questions with Solutions
,Viva Questions
,Summary
,Sample Paper
,Extra Questions
,shortcuts and tricks
,past year papers
,आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 | विज्ञान और प्रौद्योगिकी (Science & Technology) for UPSC CSE
,MCQs
,Exam
,practice quizzes
,Free
,mock tests for examination
,आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 | विज्ञान और प्रौद्योगिकी (Science & Technology) for UPSC CSE
,video lectures
,Important questions
,आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 | विज्ञान और प्रौद्योगिकी (Science & Technology) for UPSC CSE
,ppt
,Semester Notes
,study material
,Objective type Questions
;


आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 Free PDF Download
Importance of आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2
आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 Notes
आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 UPSC Questions
Study आईटी और कंप्यूटर के क्षेत्र में जागरूकता - 2 on the App
|
© EduRev
|
Education Revolution
|



|





