









All Exams >
Computer Science Engineering (CSE) >
6 Months Preparation for GATE CSE >
All Questions
All questions of Transport Layer for Computer Science Engineering (CSE) Exam
RIP is- a)Protocol used for transmission of IP datagrams across a serial line
- b)Resource information protocol
- c)Protocol used to exchange information between the routers
- d)Protocol used to exchanger information between the layers
Correct answer is option 'C'. Can you explain this answer?
RIP is
a)
Protocol used for transmission of IP datagrams across a serial line
b)
Resource information protocol
c)
Protocol used to exchange information between the routers
d)
Protocol used to exchanger information between the layers
|
|
Prisha Sharma answered |
Routing Information Protocol (RIP) is a routing protocol based on the distance vector algorithm, In this each router periodically shares its knowledge about the entire network with its neighbours.

Who can send ICMP error-reporting messages?
- a)Routers
- b)Destination hosts
- c)Source host
- d)Both (a) and (b)
Correct answer is option 'D'. Can you explain this answer?
Who can send ICMP error-reporting messages?
a)
Routers
b)
Destination hosts
c)
Source host
d)
Both (a) and (b)
|
|
Krithika Kaur answered |
Both router and destination host can send ICMP error-reporting message to inform the source host about any failure or error occurred in packet.

During normal IP packet forwarding by routers which of the following packet fields are updated?- a)IP header source address
- b)IP header destination address
- c)IP header TTL
- d)IP header check sum
Correct answer is option 'C'. Can you explain this answer?
During normal IP packet forwarding by routers which of the following packet fields are updated?
a)
IP header source address
b)
IP header destination address
c)
IP header TTL
d)
IP header check sum
|
|
Nilesh Mukherjee answered |
During forwarding of an IP packet by routers, the packet fields namely IP header source address and IP header destination address remains same whereas check own and TTL are updated.
How many bits internet address is assigned to each host on a TCP/IP internet which is used in all communication with the host?- a)16 bits
- b)32 bits
- c)48 bits
- d)64 bits
Correct answer is option 'B'. Can you explain this answer?
How many bits internet address is assigned to each host on a TCP/IP internet which is used in all communication with the host?
a)
16 bits
b)
32 bits
c)
48 bits
d)
64 bits
|
|
Krish Datta answered |
Internet address has 32 bits, which is assigned to each host for communication on network.
The frame relay committed information rate represents- a)Maximum data rate on the network
- b)Steady state data rate on the network
- c)Minimum data rate on the network
- d)Interface data rate
Correct answer is option 'C'. Can you explain this answer?
The frame relay committed information rate represents
a)
Maximum data rate on the network
b)
Steady state data rate on the network
c)
Minimum data rate on the network
d)
Interface data rate
|
|
Mainak Kulkarni answered |
Frame relay committed information rate represents minimum data rate on the network.
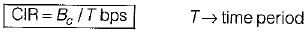
Here cumulative number of bits sent during the predefined period should not exceed Bc.
Here cumulative number of bits sent during the predefined period should not exceed Bc.
An example of a network layer is- a)Internet Protocol (IP)-ARPANET
- b)X.25 Packet Level Protocol (PLP)-ISO
- c)Source routing and domain naming-USENET
- d)All of these
Correct answer is option 'D'. Can you explain this answer?
An example of a network layer is
a)
Internet Protocol (IP)-ARPANET
b)
X.25 Packet Level Protocol (PLP)-ISO
c)
Source routing and domain naming-USENET
d)
All of these
|
|
Mira Rane answered |
Internet protocol (IP-ARPA NET, X.25 packet level protocoi-ISO and source routing and domain naming-USENET are example of network layer.
Return value of the UDP port “Chargen” is- a)String of characters
- b)String of integers
- c)Array of characters with integers
- d)Array of zero’s and one’s
Correct answer is option 'A'. Can you explain this answer?
Return value of the UDP port “Chargen” is
a)
String of characters
b)
String of integers
c)
Array of characters with integers
d)
Array of zero’s and one’s
|
|
Akanksha Chauhan answered |
Answer: a
Explanation: Chargen with port number 19 returns string of characters.
Explanation: Chargen with port number 19 returns string of characters.
“Total length” field in UDP packet header is the length of- a)Only UDP header
- b)Only data
- c)Only checksum
- d)UDP header plus data
Correct answer is option 'D'. Can you explain this answer?
“Total length” field in UDP packet header is the length of
a)
Only UDP header
b)
Only data
c)
Only checksum
d)
UDP header plus data
|
|
Dishani Bajaj answered |
Answer: d
Explanation: Total length is the 16 bit field which contains the length of UDP header and the data.
Explanation: Total length is the 16 bit field which contains the length of UDP header and the data.
Which of the following statements is correct in respect of TCP and UDP protocols?- a)TCP is connection-oriented, whereas UDP is connectionless.
- b)TCP is connectionless, whereas UDP is connection-oriented.
- c)Both are connectionless.
- d)Both are connection-oriented.
Correct answer is option 'A'. Can you explain this answer?
Which of the following statements is correct in respect of TCP and UDP protocols?
a)
TCP is connection-oriented, whereas UDP is connectionless.
b)
TCP is connectionless, whereas UDP is connection-oriented.
c)
Both are connectionless.
d)
Both are connection-oriented.
|
|
Pritam Chatterjee answered |
TCP and UDP Protocols
Introduction:
TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are two widely used transport layer protocols in computer networking. Both protocols are used for data transmission over IP networks, but they have different characteristics and use cases.
Statement:
The correct statement among the given options is option A: TCP is connection-oriented, whereas UDP is connectionless.
Explanation:
TCP:
- TCP is a connection-oriented protocol, which means it establishes a reliable and ordered connection between the sender and receiver before exchanging data.
- It guarantees data delivery, in-order transmission, and error detection through various mechanisms such as sequence numbers, acknowledgments, and retransmissions.
- TCP provides flow control to prevent overwhelming the receiver with data and congestion control to avoid network congestion.
- It is commonly used for applications that require reliable and ordered data delivery, such as web browsing, file transfer, and email.
UDP:
- UDP is a connectionless protocol, which means it does not establish a dedicated connection before transmitting data.
- It is a lightweight protocol that does not provide reliability, ordering, or flow control mechanisms.
- UDP is used for applications that prioritize low latency and can tolerate data loss, such as real-time streaming, online gaming, and DNS queries.
- It is faster than TCP due to its simplicity and lack of overhead associated with establishing and maintaining a connection.
Conclusion:
In summary, TCP is a connection-oriented protocol that provides reliable and ordered data transmission, while UDP is a connectionless protocol that offers faster but less reliable data transmission. Therefore, option A is the correct statement.
Introduction:
TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are two widely used transport layer protocols in computer networking. Both protocols are used for data transmission over IP networks, but they have different characteristics and use cases.
Statement:
The correct statement among the given options is option A: TCP is connection-oriented, whereas UDP is connectionless.
Explanation:
TCP:
- TCP is a connection-oriented protocol, which means it establishes a reliable and ordered connection between the sender and receiver before exchanging data.
- It guarantees data delivery, in-order transmission, and error detection through various mechanisms such as sequence numbers, acknowledgments, and retransmissions.
- TCP provides flow control to prevent overwhelming the receiver with data and congestion control to avoid network congestion.
- It is commonly used for applications that require reliable and ordered data delivery, such as web browsing, file transfer, and email.
UDP:
- UDP is a connectionless protocol, which means it does not establish a dedicated connection before transmitting data.
- It is a lightweight protocol that does not provide reliability, ordering, or flow control mechanisms.
- UDP is used for applications that prioritize low latency and can tolerate data loss, such as real-time streaming, online gaming, and DNS queries.
- It is faster than TCP due to its simplicity and lack of overhead associated with establishing and maintaining a connection.
Conclusion:
In summary, TCP is a connection-oriented protocol that provides reliable and ordered data transmission, while UDP is a connectionless protocol that offers faster but less reliable data transmission. Therefore, option A is the correct statement.
In Three-Way Handshaking process, the situation where both the TCP’s issue an active open is- a)Mutual open
- b)Mutual Close
- c)Simultaneous open
- d)Simultaneous close
Correct answer is option 'C'. Can you explain this answer?
In Three-Way Handshaking process, the situation where both the TCP’s issue an active open is
a)
Mutual open
b)
Mutual Close
c)
Simultaneous open
d)
Simultaneous close
|
|
Mrinalini Deshpande answered |
Client and server simultaneously send a SYN segment to each other is called SYN flood.
Correct expression for UDP user datagram length is- a)UDP length = IP length – IP header’s length
- b)UDP length = UDP length – UDP header’s length
- c)UDP length = IP length + IP header’s length
- d)UDP length = UDP length + UDP header’s length
Correct answer is option 'A'. Can you explain this answer?
Correct expression for UDP user datagram length is
a)
UDP length = IP length – IP header’s length
b)
UDP length = UDP length – UDP header’s length
c)
UDP length = IP length + IP header’s length
d)
UDP length = UDP length + UDP header’s length
|
|
Jyoti Sengupta answered |
Answer: a
Explanation: A user datagram is encapsulated in an IP datagram. There is a field in the IP datagram the defines the total length. There is another field in the IP datagram that defines the length of the header. So if we subtract the length of a UDP datagram that is encapsulated in an IP datagram, we get the length of UDP user datagram.
Explanation: A user datagram is encapsulated in an IP datagram. There is a field in the IP datagram the defines the total length. There is another field in the IP datagram that defines the length of the header. So if we subtract the length of a UDP datagram that is encapsulated in an IP datagram, we get the length of UDP user datagram.
TCP groups a number of bytes together into a packet called- a)Packet
- b)Buffer
- c)Segment
- d)Stack
Correct answer is option 'C'. Can you explain this answer?
TCP groups a number of bytes together into a packet called
a)
Packet
b)
Buffer
c)
Segment
d)
Stack
|
|
Nabanita Basak answered |
Answer: c
Explanation: Segment is a grouping of number of bytes together into a packet.
Explanation: Segment is a grouping of number of bytes together into a packet.
The receiver of the data controls the amount of data that are to be sent by the sender is referred as- a)Flow control
- b)Error control
- c)Congestion control
- d)Error detection
Correct answer is option 'A'. Can you explain this answer?
The receiver of the data controls the amount of data that are to be sent by the sender is referred as
a)
Flow control
b)
Error control
c)
Congestion control
d)
Error detection
|
|
Mahi Yadav answered |
Answer: a
Explanation: Flow control is done to prevent the receiver from being overwhelmed with data.
Explanation: Flow control is done to prevent the receiver from being overwhelmed with data.
Retransmission of packets must not be done when _______- a)Packet is lost
- b)Packet is corrupted
- c)Packet is needed
- d)Packet is error-free
Correct answer is option 'D'. Can you explain this answer?
Retransmission of packets must not be done when _______
a)
Packet is lost
b)
Packet is corrupted
c)
Packet is needed
d)
Packet is error-free
|
|
Prerna Joshi answered |
Explanation:
In a computer network, retransmission of packets is a process where a sender sends the same packet again to the receiver if it does not receive an acknowledgment from the receiver within a certain time period. However, retransmission should only be done when it is necessary. Here are the reasons why retransmission should not be done when a packet is error-free:
1. Efficiency: Retransmission of error-free packets consumes network resources and can lead to unnecessary congestion. Since error-free packets do not need any correction, retransmitting them would be a waste of bandwidth.
2. Latency: Retransmitting error-free packets unnecessarily increases the overall latency of the network. This delay can be especially problematic in real-time applications such as video streaming or online gaming.
3. Network Performance: Retransmission of error-free packets can disrupt the flow of data and degrade the overall performance of the network. It can lead to unnecessary reordering of packets and increase the chances of congestion in the network.
4. Reliability: Retransmission of error-free packets can introduce unnecessary redundancy and increase the chances of duplicate packets being received by the receiver. This can cause confusion and affect the reliability of the data being transmitted.
5. Protocol Efficiency: Most network protocols have mechanisms in place to ensure reliable delivery of packets. These protocols use techniques such as checksums, acknowledgments, and sequence numbers to detect and recover from errors. Retransmission of error-free packets bypasses these mechanisms and can lead to inefficiencies in the protocol.
In conclusion, retransmission of packets should only be done when there is an error or loss of data. Retransmitting error-free packets can have negative effects on network efficiency, latency, performance, reliability, and protocol efficiency. Therefore, it is important to avoid retransmission when packets are error-free.
In a computer network, retransmission of packets is a process where a sender sends the same packet again to the receiver if it does not receive an acknowledgment from the receiver within a certain time period. However, retransmission should only be done when it is necessary. Here are the reasons why retransmission should not be done when a packet is error-free:
1. Efficiency: Retransmission of error-free packets consumes network resources and can lead to unnecessary congestion. Since error-free packets do not need any correction, retransmitting them would be a waste of bandwidth.
2. Latency: Retransmitting error-free packets unnecessarily increases the overall latency of the network. This delay can be especially problematic in real-time applications such as video streaming or online gaming.
3. Network Performance: Retransmission of error-free packets can disrupt the flow of data and degrade the overall performance of the network. It can lead to unnecessary reordering of packets and increase the chances of congestion in the network.
4. Reliability: Retransmission of error-free packets can introduce unnecessary redundancy and increase the chances of duplicate packets being received by the receiver. This can cause confusion and affect the reliability of the data being transmitted.
5. Protocol Efficiency: Most network protocols have mechanisms in place to ensure reliable delivery of packets. These protocols use techniques such as checksums, acknowledgments, and sequence numbers to detect and recover from errors. Retransmission of error-free packets bypasses these mechanisms and can lead to inefficiencies in the protocol.
In conclusion, retransmission of packets should only be done when there is an error or loss of data. Retransmitting error-free packets can have negative effects on network efficiency, latency, performance, reliability, and protocol efficiency. Therefore, it is important to avoid retransmission when packets are error-free.
Consider the following statements.
I. TCP connections are full duplex
II. TCP has no option for selective acknowledgment
III. TCP connections are message streams- a)Only I is correct
- b)Only I and III are correct
- c)Only II and III are correct
- d)All of I, II and III are correct
Correct answer is option 'A'. Can you explain this answer?
Consider the following statements.
I. TCP connections are full duplex
II. TCP has no option for selective acknowledgment
III. TCP connections are message streams
I. TCP connections are full duplex
II. TCP has no option for selective acknowledgment
III. TCP connections are message streams
a)
Only I is correct
b)
Only I and III are correct
c)
Only II and III are correct
d)
All of I, II and III are correct
|
|
Ayush Basu answered |
Understanding TCP Connections
TCP (Transmission Control Protocol) is a fundamental protocol used in network communications. Let's analyze the given statements to determine their correctness.
Statement I: TCP connections are full duplex
- TCP connections indeed support full duplex communication. This means that data can be sent and received simultaneously between two endpoints. Each side of the connection can transmit data independently.
Statement II: TCP has no option for selective acknowledgment
- This statement is incorrect. TCP does have a mechanism for selective acknowledgment (SACK), which allows the receiver to acknowledge specific segments of data, rather than just the last contiguous segment received. This feature enhances efficiency, especially in environments with a lot of packet loss.
Statement III: TCP connections are message streams
- This statement is also correct. TCP treats the data being sent as a continuous stream of bytes rather than discrete packets or messages. This stream-oriented nature allows TCP to manage data flow more effectively, ensuring that data is delivered in order and without duplication.
Conclusion
Based on the evaluation of the statements:
- Only Statement I is correct: TCP connections are indeed full duplex.
- Statement II is incorrect: TCP does support selective acknowledgment.
- Statement III is correct: TCP connections function as message streams.
Thus, the correct answer is option 'A', as it accurately reflects the validity of the statements regarding TCP.
TCP (Transmission Control Protocol) is a fundamental protocol used in network communications. Let's analyze the given statements to determine their correctness.
Statement I: TCP connections are full duplex
- TCP connections indeed support full duplex communication. This means that data can be sent and received simultaneously between two endpoints. Each side of the connection can transmit data independently.
Statement II: TCP has no option for selective acknowledgment
- This statement is incorrect. TCP does have a mechanism for selective acknowledgment (SACK), which allows the receiver to acknowledge specific segments of data, rather than just the last contiguous segment received. This feature enhances efficiency, especially in environments with a lot of packet loss.
Statement III: TCP connections are message streams
- This statement is also correct. TCP treats the data being sent as a continuous stream of bytes rather than discrete packets or messages. This stream-oriented nature allows TCP to manage data flow more effectively, ensuring that data is delivered in order and without duplication.
Conclusion
Based on the evaluation of the statements:
- Only Statement I is correct: TCP connections are indeed full duplex.
- Statement II is incorrect: TCP does support selective acknowledgment.
- Statement III is correct: TCP connections function as message streams.
Thus, the correct answer is option 'A', as it accurately reflects the validity of the statements regarding TCP.
The server program tells its TCP that it is ready to accept a connection. This process is called- a)Active open
- b)Active close
- c)Passive close
- d)Passive open
Correct answer is option 'D'. Can you explain this answer?
The server program tells its TCP that it is ready to accept a connection. This process is called
a)
Active open
b)
Active close
c)
Passive close
d)
Passive open
|
|
Swara Basak answered |
Answer: d
Explanation: This is the first step in the Three-Way Handshaking process and is started by the server.
Explanation: This is the first step in the Three-Way Handshaking process and is started by the server.
Size of TCP segment header ranges between- a)16 and 32 bytes
- b)16 and 32 bits
- c)20 and 60 bytes
- d)20 and 60 bits
Correct answer is option 'C'. Can you explain this answer?
Size of TCP segment header ranges between
a)
16 and 32 bytes
b)
16 and 32 bits
c)
20 and 60 bytes
d)
20 and 60 bits
|
|
Hiral Nair answered |
Answer: c
Explanation: The header is 20 bytes if there are no options and upto 60 bytes if it contains options.
Explanation: The header is 20 bytes if there are no options and upto 60 bytes if it contains options.
Connection establishment in TCP is done by which mechanism?- a)Flow control
- b)Three-Way Handshaking
- c)Forwarding
- d)Synchronisation
Correct answer is option 'B'. Can you explain this answer?
Connection establishment in TCP is done by which mechanism?
a)
Flow control
b)
Three-Way Handshaking
c)
Forwarding
d)
Synchronisation
|
|
Mahi Yadav answered |
Answer: b
Explanation: Three-Way Handshaking is used to terminate the connection between client and server.
Explanation: Three-Way Handshaking is used to terminate the connection between client and server.
IP Security operates in which layer of the OSI model?- a)Network
- b)Transport
- c)Application
- d)Physical
Correct answer is option 'A'. Can you explain this answer?
IP Security operates in which layer of the OSI model?
a)
Network
b)
Transport
c)
Application
d)
Physical
|
|
Hiral Nair answered |
Answer: a
Explanation: Network layer is mainly used for security purpose, so IPsec in mainly operates in network layer.
Explanation: Network layer is mainly used for security purpose, so IPsec in mainly operates in network layer.
______ provides authentication at the IP level.- a)AH
- b)ESP
- c)PGP
- d)SSL
Correct answer is option 'A'. Can you explain this answer?
______ provides authentication at the IP level.
a)
AH
b)
ESP
c)
PGP
d)
SSL
|
|
Arnab Sengupta answered |
Understanding IP-Level Authentication
IP-level authentication is crucial for ensuring the integrity and authenticity of data being transmitted over a network. Among the various protocols that provide this functionality, Authentication Header (AH) stands out.
What is Authentication Header (AH)?
- Purpose: AH is part of the Internet Protocol Security (IPsec) suite, which is designed to secure Internet Protocol (IP) communications.
- Functionality: It provides authentication for the entire IP packet, ensuring that the data has not been tampered with during transmission.
Key Features of AH
- Integrity Protection: AH uses cryptographic checksums to verify that the data has not been altered.
- Replay Protection: It includes mechanisms to protect against replay attacks, where an attacker might intercept and resend packets.
- No Encryption: Unlike other protocols such as the Encapsulating Security Payload (ESP), AH does not provide encryption; it focuses solely on authentication and integrity.
Comparison with Other Protocols
- ESP (Encapsulating Security Payload): While ESP also provides authentication, its primary function is to provide confidentiality through encryption. Thus, it covers both authentication and encryption, making it more versatile for certain applications.
- PGP (Pretty Good Privacy): PGP is primarily used for securing emails, incorporating encryption and authentication, but it operates at a higher level than IP.
- SSL (Secure Sockets Layer): SSL is used for securing communications over a network, particularly in web applications, but it does not operate at the IP level like AH.
Conclusion
In summary, Authentication Header (AH) is specifically designed to provide authentication at the IP level, ensuring the integrity and authenticity of data packets. This makes it an essential component of secure network communications.
IP-level authentication is crucial for ensuring the integrity and authenticity of data being transmitted over a network. Among the various protocols that provide this functionality, Authentication Header (AH) stands out.
What is Authentication Header (AH)?
- Purpose: AH is part of the Internet Protocol Security (IPsec) suite, which is designed to secure Internet Protocol (IP) communications.
- Functionality: It provides authentication for the entire IP packet, ensuring that the data has not been tampered with during transmission.
Key Features of AH
- Integrity Protection: AH uses cryptographic checksums to verify that the data has not been altered.
- Replay Protection: It includes mechanisms to protect against replay attacks, where an attacker might intercept and resend packets.
- No Encryption: Unlike other protocols such as the Encapsulating Security Payload (ESP), AH does not provide encryption; it focuses solely on authentication and integrity.
Comparison with Other Protocols
- ESP (Encapsulating Security Payload): While ESP also provides authentication, its primary function is to provide confidentiality through encryption. Thus, it covers both authentication and encryption, making it more versatile for certain applications.
- PGP (Pretty Good Privacy): PGP is primarily used for securing emails, incorporating encryption and authentication, but it operates at a higher level than IP.
- SSL (Secure Sockets Layer): SSL is used for securing communications over a network, particularly in web applications, but it does not operate at the IP level like AH.
Conclusion
In summary, Authentication Header (AH) is specifically designed to provide authentication at the IP level, ensuring the integrity and authenticity of data packets. This makes it an essential component of secure network communications.
Bytes of data being transferred in each connection are numbered by TCP. These numbers starts with a- a)Random number
- b)Zero
- c)One
- d)Sequence of zero’s and one’s
Correct answer is option 'D'. Can you explain this answer?
Bytes of data being transferred in each connection are numbered by TCP. These numbers starts with a
a)
Random number
b)
Zero
c)
One
d)
Sequence of zero’s and one’s
|
|
Anisha Ahuja answered |
Answer: d
Explanation: These numbers starts with a random number.
Explanation: These numbers starts with a random number.
In Go-Back-N window, when the timer of the packet times out, several packets have to be resent even some may have arrived safe. Whereas in Selective Repeat window, the sender resends ___________- a)Packet which are not lost
- b)Only those packets which are lost or corrupted
- c)Packet from starting
- d)All the packets
Correct answer is option 'B'. Can you explain this answer?
In Go-Back-N window, when the timer of the packet times out, several packets have to be resent even some may have arrived safe. Whereas in Selective Repeat window, the sender resends ___________
a)
Packet which are not lost
b)
Only those packets which are lost or corrupted
c)
Packet from starting
d)
All the packets
|
|
Dhruba Goyal answered |
Explanation:
In the Go-Back-N (GBN) protocol, when the timer of a packet times out, all the packets from that point onwards in the sender's window need to be retransmitted. This is because the sender does not know which packets have been successfully received by the receiver and which packets have been lost or corrupted. Therefore, it assumes that all the packets in the current window are lost and retransmits them.
However, in the Selective Repeat (SR) protocol, the sender resends only those packets which are lost or corrupted. It maintains a separate timer for each packet in the window. When the timer of a specific packet times out, only that particular packet is retransmitted, rather than retransmitting the entire window. This is possible because the receiver in the SR protocol sends individual acknowledgments for each successfully received packet. Therefore, the sender can accurately identify which packets need to be resent.
Comparison between GBN and SR:
1. Go-Back-N (GBN):
- In GBN, the sender maintains a sliding window of packets.
- When the timer for the oldest unacknowledged packet expires, all the packets in the window are retransmitted.
- The receiver acknowledges the correctly received packets cumulatively, indicating the highest consecutive packet it has received.
- If a packet is lost or corrupted, the receiver discards it and waits for the next expected packet.
- GBN provides a cumulative acknowledgment scheme, reducing the number of acknowledgments sent by the receiver.
2. Selective Repeat (SR):
- In SR, the sender maintains a sliding window of packets.
- Each packet in the window has its own individual timer.
- When the timer for a specific packet expires, only that packet is retransmitted.
- The receiver acknowledges each successfully received packet individually.
- If a packet is lost or corrupted, the receiver discards it and sends a negative acknowledgment (NAK) for that specific packet, requesting its retransmission.
- SR provides a selective acknowledgment scheme, allowing the sender to accurately identify and retransmit only the lost or corrupted packets.
Conclusion:
In summary, the Go-Back-N protocol retransmits the entire window of packets when the timer expires, while the Selective Repeat protocol retransmits only the specific packet that has timed out. The Selective Repeat protocol provides more efficiency and reduces unnecessary retransmissions compared to the Go-Back-N protocol.
In the Go-Back-N (GBN) protocol, when the timer of a packet times out, all the packets from that point onwards in the sender's window need to be retransmitted. This is because the sender does not know which packets have been successfully received by the receiver and which packets have been lost or corrupted. Therefore, it assumes that all the packets in the current window are lost and retransmits them.
However, in the Selective Repeat (SR) protocol, the sender resends only those packets which are lost or corrupted. It maintains a separate timer for each packet in the window. When the timer of a specific packet times out, only that particular packet is retransmitted, rather than retransmitting the entire window. This is possible because the receiver in the SR protocol sends individual acknowledgments for each successfully received packet. Therefore, the sender can accurately identify which packets need to be resent.
Comparison between GBN and SR:
1. Go-Back-N (GBN):
- In GBN, the sender maintains a sliding window of packets.
- When the timer for the oldest unacknowledged packet expires, all the packets in the window are retransmitted.
- The receiver acknowledges the correctly received packets cumulatively, indicating the highest consecutive packet it has received.
- If a packet is lost or corrupted, the receiver discards it and waits for the next expected packet.
- GBN provides a cumulative acknowledgment scheme, reducing the number of acknowledgments sent by the receiver.
2. Selective Repeat (SR):
- In SR, the sender maintains a sliding window of packets.
- Each packet in the window has its own individual timer.
- When the timer for a specific packet expires, only that packet is retransmitted.
- The receiver acknowledges each successfully received packet individually.
- If a packet is lost or corrupted, the receiver discards it and sends a negative acknowledgment (NAK) for that specific packet, requesting its retransmission.
- SR provides a selective acknowledgment scheme, allowing the sender to accurately identify and retransmit only the lost or corrupted packets.
Conclusion:
In summary, the Go-Back-N protocol retransmits the entire window of packets when the timer expires, while the Selective Repeat protocol retransmits only the specific packet that has timed out. The Selective Repeat protocol provides more efficiency and reduces unnecessary retransmissions compared to the Go-Back-N protocol.
The packet sent by a node to the source to inform it of congestion is called _______- a)Explicit
- b)Discard
- c)Choke
- d)Backpressure
Correct answer is option 'C'. Can you explain this answer?
The packet sent by a node to the source to inform it of congestion is called _______
a)
Explicit
b)
Discard
c)
Choke
d)
Backpressure
|
|
Prerna Joshi answered |
Understanding Choked Packets in Networking
When a network node detects congestion, it needs a mechanism to inform the source node to slow down its data transmission. The packet used for this communication is known as a "choked" packet.
What is a Choked Packet?
- A choked packet is a signal sent from a receiver back to the source.
- It indicates that the receiver is overwhelmed with data and cannot process any more packets at that moment.
- The term "choked" signifies that the sender should pause or reduce its transmission rate.
Purpose of Choked Packets
- Congestion Control: The primary role is to manage network congestion effectively.
- Flow Regulation: It helps regulate the flow of data, ensuring that the network does not become overloaded.
- Maintaining Performance: By slowing down the sender, it allows the network to recover and maintain optimal performance.
Comparison with Other Options
- Explicit: While explicit signaling can be used in some protocols to inform the sender, it does not specifically refer to congestion notification.
- Discard: Discarding packets is a method used in congestion situations, but it does not involve communication back to the sender.
- Backpressure: Although similar, backpressure is a broader term that refers to the general mechanism of slowing down a sender in response to congestion.
Conclusion
In summary, the correct answer is option 'C', "Choked," as it specifically refers to the packet sent from a node to the source to indicate congestion, ensuring smooth and efficient network operations.
When a network node detects congestion, it needs a mechanism to inform the source node to slow down its data transmission. The packet used for this communication is known as a "choked" packet.
What is a Choked Packet?
- A choked packet is a signal sent from a receiver back to the source.
- It indicates that the receiver is overwhelmed with data and cannot process any more packets at that moment.
- The term "choked" signifies that the sender should pause or reduce its transmission rate.
Purpose of Choked Packets
- Congestion Control: The primary role is to manage network congestion effectively.
- Flow Regulation: It helps regulate the flow of data, ensuring that the network does not become overloaded.
- Maintaining Performance: By slowing down the sender, it allows the network to recover and maintain optimal performance.
Comparison with Other Options
- Explicit: While explicit signaling can be used in some protocols to inform the sender, it does not specifically refer to congestion notification.
- Discard: Discarding packets is a method used in congestion situations, but it does not involve communication back to the sender.
- Backpressure: Although similar, backpressure is a broader term that refers to the general mechanism of slowing down a sender in response to congestion.
Conclusion
In summary, the correct answer is option 'C', "Choked," as it specifically refers to the packet sent from a node to the source to indicate congestion, ensuring smooth and efficient network operations.
Communication offered by TCP is- a)Full-duplex
- b)Half-duplex
- c)Semi-duplex
- d)Byte by byte
Correct answer is option 'A'. Can you explain this answer?
Communication offered by TCP is
a)
Full-duplex
b)
Half-duplex
c)
Semi-duplex
d)
Byte by byte
|
|
Sreemoyee Singh answered |
The correct answer is option 'A': Full-duplex.
Explanation:
TCP (Transmission Control Protocol) is a communication protocol used in computer networks for reliable and ordered delivery of data packets. TCP provides a full-duplex communication, which means that data can be transmitted in both directions simultaneously.● In full-duplex communication, two communicating parties can send and receive data at the same time without needing to take turns or wait for the other party to finish transmitting. This allows for efficient and bidirectional communication, enabling real-time interaction and smooth data flow.
● TCP achieves full-duplex communication by establishing two independent and simultaneous communication channels, one for sending data (transmit channel) and another for receiving data (receive channel). This is often referred to as a "two-way" or "two-sided" communication.
● In contrast, other communication modes such as half-duplex and semi-duplex do not allow simultaneous two-way communication. In a half-duplex communication, data can be transmitted in both directions, but not at the same time. Parties take turns transmitting and receiving data. Semi-duplex communication is similar but allows only one direction of communication at a time.
Therefore, the correct answer is option 'A': Full-duplex, as TCP offers simultaneous bidirectional communication capability
Which of the following protocols uses both TCP and UDP?- a)FTP
- b)SMTP
- c)Telnet
- d)DNS
Correct answer is option 'D'. Can you explain this answer?
Which of the following protocols uses both TCP and UDP?
a)
FTP
b)
SMTP
c)
Telnet
d)
DNS
|
|
Manasa Dey answered |
Explanation:
The correct answer is option D, DNS (Domain Name System).
DNS (Domain Name System):
DNS is a protocol that is used to convert domain names into IP addresses. It is responsible for translating human-readable domain names into machine-readable IP addresses. DNS uses both TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) depending on the type of query and the size of the response.
TCP (Transmission Control Protocol):
TCP is a connection-oriented protocol that provides reliable, ordered, and error-checked delivery of data between applications. It ensures that all data packets are delivered in the correct order and without errors. TCP is used when the size of the DNS response is too large to fit in a single UDP packet.
UDP (User Datagram Protocol):
UDP is a connectionless protocol that provides fast but unreliable delivery of data. It does not guarantee the delivery of packets or their order. UDP is used when the DNS response is small enough to fit in a single packet and reliability is not as important. It is faster than TCP because it does not have the overhead of establishing and maintaining a connection.
Why DNS uses both TCP and UDP:
DNS primarily uses UDP because it is faster and more efficient for smaller requests and responses. Most DNS queries are small and can fit within a single UDP packet. However, if the DNS response is too large to fit in a single UDP packet, TCP is used instead. TCP allows for larger data transfers and ensures reliable delivery of the DNS response.
Conclusion:
In conclusion, DNS uses both TCP and UDP protocols. UDP is used for smaller requests and responses, while TCP is used for larger responses that cannot fit in a single UDP packet. The use of both protocols allows DNS to efficiently translate domain names into IP addresses while ensuring reliable delivery when needed.
The correct answer is option D, DNS (Domain Name System).
DNS (Domain Name System):
DNS is a protocol that is used to convert domain names into IP addresses. It is responsible for translating human-readable domain names into machine-readable IP addresses. DNS uses both TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) depending on the type of query and the size of the response.
TCP (Transmission Control Protocol):
TCP is a connection-oriented protocol that provides reliable, ordered, and error-checked delivery of data between applications. It ensures that all data packets are delivered in the correct order and without errors. TCP is used when the size of the DNS response is too large to fit in a single UDP packet.
UDP (User Datagram Protocol):
UDP is a connectionless protocol that provides fast but unreliable delivery of data. It does not guarantee the delivery of packets or their order. UDP is used when the DNS response is small enough to fit in a single packet and reliability is not as important. It is faster than TCP because it does not have the overhead of establishing and maintaining a connection.
Why DNS uses both TCP and UDP:
DNS primarily uses UDP because it is faster and more efficient for smaller requests and responses. Most DNS queries are small and can fit within a single UDP packet. However, if the DNS response is too large to fit in a single UDP packet, TCP is used instead. TCP allows for larger data transfers and ensures reliable delivery of the DNS response.
Conclusion:
In conclusion, DNS uses both TCP and UDP protocols. UDP is used for smaller requests and responses, while TCP is used for larger responses that cannot fit in a single UDP packet. The use of both protocols allows DNS to efficiently translate domain names into IP addresses while ensuring reliable delivery when needed.
In the slow-start algorithm, the size of the congestion window increases __________ until it reaches a threshold.- a)exponentially
- b)additively
- c)multiplicatively
- d)suddenly
Correct answer is option 'A'. Can you explain this answer?
In the slow-start algorithm, the size of the congestion window increases __________ until it reaches a threshold.
a)
exponentially
b)
additively
c)
multiplicatively
d)
suddenly
|
|
Samridhi Joshi answered |
Slow-start Algorithm and Congestion Window
The slow-start algorithm is a congestion control mechanism used in computer networks to manage the flow of data packets. It is part of the Transmission Control Protocol (TCP) and is designed to prevent network congestion by gradually increasing the amount of data sent.
Increasing the Congestion Window Size
The congestion window represents the number of packets that can be sent before the sender needs to wait for an acknowledgment from the receiver. In the slow-start algorithm, the size of the congestion window starts small and gradually increases until it reaches a certain threshold. This process helps to prevent congestion and ensures that the network can handle the increased data flow.
Exponential Increase
The correct answer to the question is option 'A', which states that the size of the congestion window increases exponentially until it reaches a threshold. This means that the congestion window size is doubled with each successful transmission, resulting in a rapid growth rate.
Exponential increase is a fundamental characteristic of the slow-start algorithm. It allows the sender to probe the network to find the optimal transmission rate without overwhelming it with too much traffic at once. By gradually increasing the congestion window size, the algorithm ensures that the network can handle the increased load and avoids congestion.
Threshold
Once the congestion window size reaches a certain threshold, the slow-start algorithm transitions into the congestion avoidance phase. At this point, the congestion window size is increased additively rather than exponentially. This helps to maintain a stable and efficient flow of data without putting excessive strain on the network.
Conclusion
In summary, the slow-start algorithm gradually increases the size of the congestion window to prevent network congestion. The congestion window size starts small and grows exponentially until it reaches a threshold. This exponential increase allows the sender to probe the network and find the optimal transmission rate. Once the threshold is reached, the algorithm transitions into the congestion avoidance phase, where the congestion window size is increased additively. This mechanism helps to maintain a stable and efficient flow of data while preventing congestion in the network.
The slow-start algorithm is a congestion control mechanism used in computer networks to manage the flow of data packets. It is part of the Transmission Control Protocol (TCP) and is designed to prevent network congestion by gradually increasing the amount of data sent.
Increasing the Congestion Window Size
The congestion window represents the number of packets that can be sent before the sender needs to wait for an acknowledgment from the receiver. In the slow-start algorithm, the size of the congestion window starts small and gradually increases until it reaches a certain threshold. This process helps to prevent congestion and ensures that the network can handle the increased data flow.
Exponential Increase
The correct answer to the question is option 'A', which states that the size of the congestion window increases exponentially until it reaches a threshold. This means that the congestion window size is doubled with each successful transmission, resulting in a rapid growth rate.
Exponential increase is a fundamental characteristic of the slow-start algorithm. It allows the sender to probe the network to find the optimal transmission rate without overwhelming it with too much traffic at once. By gradually increasing the congestion window size, the algorithm ensures that the network can handle the increased load and avoids congestion.
Threshold
Once the congestion window size reaches a certain threshold, the slow-start algorithm transitions into the congestion avoidance phase. At this point, the congestion window size is increased additively rather than exponentially. This helps to maintain a stable and efficient flow of data without putting excessive strain on the network.
Conclusion
In summary, the slow-start algorithm gradually increases the size of the congestion window to prevent network congestion. The congestion window size starts small and grows exponentially until it reaches a threshold. This exponential increase allows the sender to probe the network and find the optimal transmission rate. Once the threshold is reached, the algorithm transitions into the congestion avoidance phase, where the congestion window size is increased additively. This mechanism helps to maintain a stable and efficient flow of data while preventing congestion in the network.
Which of the following is not a service primitive?- a)Connect
- b)Listen
- c)Send
- d)Sound
Correct answer is option 'D'. Can you explain this answer?
Which of the following is not a service primitive?
a)
Connect
b)
Listen
c)
Send
d)
Sound
|
|
Ujwal Nambiar answered |
Service Primitives
Service primitives are the basic building blocks of communication protocols. They define the operations that can be performed on a communication service. There are typically four types of service primitives: connect, listen, send, and receive.
Connect
The connect primitive is used to establish a connection between two entities in a communication network. It allows the initiating entity to request a connection to a specific destination entity.
Listen
The listen primitive is used to wait for incoming connection requests. It allows an entity to passively listen for connection requests and accept them when they arrive.
Send
The send primitive is used to send data from one entity to another. It allows the sending entity to transmit data to the destination entity over an established connection.
Sound
The option 'D' in this question, "Sound," is not a service primitive. Sound refers to auditory perception resulting from vibrations that can be detected by the human ear. It is not a communication operation or a service provided by a communication protocol.
Explanation
In the given options, connect, listen, and send are all service primitives commonly used in communication protocols. These primitives are essential for establishing connections, listening for incoming requests, and transmitting data. However, sound is not a service primitive as it does not relate to communication protocols or network operations.
Sound is a sensory perception and not a service or operation that can be performed on a communication network. Therefore, the correct answer is option 'D' - Sound.
Service primitives are the basic building blocks of communication protocols. They define the operations that can be performed on a communication service. There are typically four types of service primitives: connect, listen, send, and receive.
Connect
The connect primitive is used to establish a connection between two entities in a communication network. It allows the initiating entity to request a connection to a specific destination entity.
Listen
The listen primitive is used to wait for incoming connection requests. It allows an entity to passively listen for connection requests and accept them when they arrive.
Send
The send primitive is used to send data from one entity to another. It allows the sending entity to transmit data to the destination entity over an established connection.
Sound
The option 'D' in this question, "Sound," is not a service primitive. Sound refers to auditory perception resulting from vibrations that can be detected by the human ear. It is not a communication operation or a service provided by a communication protocol.
Explanation
In the given options, connect, listen, and send are all service primitives commonly used in communication protocols. These primitives are essential for establishing connections, listening for incoming requests, and transmitting data. However, sound is not a service primitive as it does not relate to communication protocols or network operations.
Sound is a sensory perception and not a service or operation that can be performed on a communication network. Therefore, the correct answer is option 'D' - Sound.
A Go-Back-N ARQ uses a window of size 15. How many bits are needed to define the sequence number?- a)15
- b)4
- c)16
- d)5
Correct answer is option 'B'. Can you explain this answer?
A Go-Back-N ARQ uses a window of size 15. How many bits are needed to define the sequence number?
a)
15
b)
4
c)
16
d)
5
|
|
Megha Yadav answered |
Formula:
Window size (Go Back N) = 2n-1
Where n is bits needed
So, 15 = 2n-1
16 = 2n
So, n = 4
Window size (Go Back N) = 2n-1
Where n is bits needed
So, 15 = 2n-1
16 = 2n
So, n = 4
To prevent silly window syndrome created by a sender that is sending data at a very slow rate _______ can be used.- a)Clark’s solution
- b)Nagle’s algorithm
- c)Both (a) and (b)
- d)Delayed acknowledgment
Correct answer is option 'B'. Can you explain this answer?
To prevent silly window syndrome created by a sender that is sending data at a very slow rate _______ can be used.
a)
Clark’s solution
b)
Nagle’s algorithm
c)
Both (a) and (b)
d)
Delayed acknowledgment
|
|
Rajveer Chatterjee answered |
Nagle's algo is used to prevent silly window syndrome created by a sender that send data at a very slow rate.
Which protocol use link state routing?- a)BGP
- b)OSPF
- c)RIP
- d)None of these
Correct answer is option 'B'. Can you explain this answer?
Which protocol use link state routing?
a)
BGP
b)
OSPF
c)
RIP
d)
None of these
|
|
Nandini Joshi answered |
Link state routing is a type of routing protocol that is used to determine the best path for data packets to travel through a network. It is based on the concept of each router having a complete map of the network, including the status and cost of each link. This allows the routers to make informed decisions about the best path to forward packets.
The correct answer to the question is option 'B', which states that OSPF (Open Shortest Path First) uses link state routing. OSPF is a widely used routing protocol that is used in IP networks, particularly in large enterprise networks. It is designed to be scalable and efficient, and it uses link state routing to determine the shortest path between routers.
Here is a detailed explanation of why OSPF uses link state routing:
1. Link State Database:
- In OSPF, each router maintains a Link State Database (LSDB) that contains information about the network topology.
- The LSDB is built by exchanging Link State Advertisements (LSAs) between routers.
- LSAs contain information about the router's neighbors, the links it is connected to, and the cost of those links.
- By exchanging LSAs, routers can build a complete map of the network and have the same information about the network topology.
2. SPF Algorithm:
- OSPF uses a Shortest Path First (SPF) algorithm to calculate the best path for packets to travel.
- The SPF algorithm takes into account the cost of each link, which is determined by the administrator.
- It calculates the shortest path by summing up the costs of the links along a path.
- The path with the lowest total cost is considered the best path, and packets are forwarded along that path.
3. Dynamic Updates:
- OSPF supports dynamic updates, which means that routers can exchange LSAs to keep the LSDB up to date.
- When a link goes down or a new link is added to the network, routers exchange LSAs to inform each other about the changes.
- This allows OSPF to adapt to changes in the network and recalculate the best path if necessary.
In conclusion, OSPF is an example of a routing protocol that uses link state routing. It maintains a Link State Database and uses the SPF algorithm to calculate the best path for packets to travel through the network. OSPF is widely used in large networks because of its scalability and efficiency.
The correct answer to the question is option 'B', which states that OSPF (Open Shortest Path First) uses link state routing. OSPF is a widely used routing protocol that is used in IP networks, particularly in large enterprise networks. It is designed to be scalable and efficient, and it uses link state routing to determine the shortest path between routers.
Here is a detailed explanation of why OSPF uses link state routing:
1. Link State Database:
- In OSPF, each router maintains a Link State Database (LSDB) that contains information about the network topology.
- The LSDB is built by exchanging Link State Advertisements (LSAs) between routers.
- LSAs contain information about the router's neighbors, the links it is connected to, and the cost of those links.
- By exchanging LSAs, routers can build a complete map of the network and have the same information about the network topology.
2. SPF Algorithm:
- OSPF uses a Shortest Path First (SPF) algorithm to calculate the best path for packets to travel.
- The SPF algorithm takes into account the cost of each link, which is determined by the administrator.
- It calculates the shortest path by summing up the costs of the links along a path.
- The path with the lowest total cost is considered the best path, and packets are forwarded along that path.
3. Dynamic Updates:
- OSPF supports dynamic updates, which means that routers can exchange LSAs to keep the LSDB up to date.
- When a link goes down or a new link is added to the network, routers exchange LSAs to inform each other about the changes.
- This allows OSPF to adapt to changes in the network and recalculate the best path if necessary.
In conclusion, OSPF is an example of a routing protocol that uses link state routing. It maintains a Link State Database and uses the SPF algorithm to calculate the best path for packets to travel through the network. OSPF is widely used in large networks because of its scalability and efficiency.
The TCP/IP model does not have ____ and _____ layers but _____ layer include required functions of these layers.- a)Session, Application, Presentation
- b)Presentation, Application, Session
- c)Session, Presentation, Application
- d)Link, Internet, Transport
Correct answer is option 'C'. Can you explain this answer?
The TCP/IP model does not have ____ and _____ layers but _____ layer include required functions of these layers.
a)
Session, Application, Presentation
b)
Presentation, Application, Session
c)
Session, Presentation, Application
d)
Link, Internet, Transport
|
|
Sudhir Patel answered |
RFC 1122
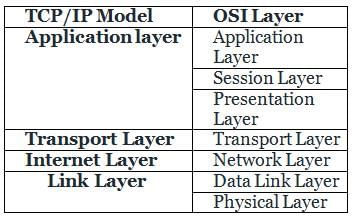
Application Layer of TCP/IP corresponds to the Application layer, Session layer, the Presentation layer of OSI.
Therefore, the TCP/IP model does not have Session and Presentation layers but the Application layer includes the required functions of these layers.
Therefore, the TCP/IP model does not have Session and Presentation layers but the Application layer includes the required functions of these layers.
Which two types of encryption protocols can be used to secure the authentication of computers using IPsec?- a)Kerberos V5
- b)Certificates
- c)SHA
- d)MD5
Correct answer is option 'C,D'. Can you explain this answer?
Which two types of encryption protocols can be used to secure the authentication of computers using IPsec?
a)
Kerberos V5
b)
Certificates
c)
SHA
d)
MD5
|
|
Hiral Nair answered |
Answer: c, d
Explanation: SHA or MD5 can be used. Kerberos V5 is an authentication protocol, not an encryption protocol; therefore, answer A is incorrect. Certificates are a type of authentication that can be used with IPsec, not an encryption protocol; therefore, answer B is incorrect.
Explanation: SHA or MD5 can be used. Kerberos V5 is an authentication protocol, not an encryption protocol; therefore, answer A is incorrect. Certificates are a type of authentication that can be used with IPsec, not an encryption protocol; therefore, answer B is incorrect.
Checksum field in TCP header is- a)one's complement of sum of header and data in bytes
- b)one's complement of sum of header, data and pseudo header in 16 bit words
- c)dropped from IPv6 header format
- d)better than md5 or sh1 methods
Correct answer is option 'B'. Can you explain this answer?
Checksum field in TCP header is
a)
one's complement of sum of header and data in bytes
b)
one's complement of sum of header, data and pseudo header in 16 bit words
c)
dropped from IPv6 header format
d)
better than md5 or sh1 methods
|
|
Soumya Pillai answered |
Explanation:
Checksum field in TCP header:
- The checksum field in the TCP header is the ones complement of the sum of the header, data, and pseudo header in 16-bit words.
- It is used for error-checking purposes to ensure the integrity of the data transmitted over the network.
- The TCP checksum is calculated by taking the 16-bit one's complement of the one's complement sum of all 16-bit words in the header, data, and pseudo header.
- The pseudo header includes information such as source and destination IP addresses, protocol number, and TCP length.
- By including the pseudo header in the checksum calculation, TCP can detect errors not only in the TCP header and data but also in the IP header.
- This helps in ensuring that the data received at the destination is the same as the data sent by the source.
Benefits of using the ones complement checksum:
- Provides a simple and efficient way to check for errors in the transmitted data.
- Helps in detecting errors that may occur during transmission, such as data corruption or packet loss.
- Enhances the reliability of data transfer over the network by ensuring data integrity.
- The ones complement checksum method is widely used in TCP/IP networks for error detection and correction.
In conclusion, the checksum field in the TCP header is the ones complement of the sum of the header, data, and pseudo header in 16-bit words. It plays a crucial role in ensuring the integrity of the data transmitted over the network.
Size of source and destination port address of TCP header respectively are- a)16-bits and 32-bits
- b)16-bits and 16-bits
- c)32-bits and 16-bits
- d)32-bits and 32-bits
Correct answer is option 'B'. Can you explain this answer?
Size of source and destination port address of TCP header respectively are
a)
16-bits and 32-bits
b)
16-bits and 16-bits
c)
32-bits and 16-bits
d)
32-bits and 32-bits
|
|
Pranab Banerjee answered |
Explanation:
TCP Header:
- The TCP header consists of various fields, including source port address and destination port address.
- The size of the source and destination port address in the TCP header is 16 bits each.
Option Analysis:
Option B: 16-bits and 16-bits
- This option correctly states that the size of both the source and destination port address in the TCP header is 16 bits.
- Therefore, option B is the correct answer to the question.
Conclusion:
- The source and destination port address fields in the TCP header are both 16 bits in size, making option B the correct choice.
TCP Header:
- The TCP header consists of various fields, including source port address and destination port address.
- The size of the source and destination port address in the TCP header is 16 bits each.
Option Analysis:
Option B: 16-bits and 16-bits
- This option correctly states that the size of both the source and destination port address in the TCP header is 16 bits.
- Therefore, option B is the correct answer to the question.
Conclusion:
- The source and destination port address fields in the TCP header are both 16 bits in size, making option B the correct choice.
Virtual terminal protocol is an example of _________- a)Network layer
- b)Application layer
- c)Transport layer
- d)Physical layer
Correct answer is option 'B'. Can you explain this answer?
Virtual terminal protocol is an example of _________
a)
Network layer
b)
Application layer
c)
Transport layer
d)
Physical layer
|
|
Sudhir Patel answered |
In open systems, a virtual terminal (VT) is an application service. It allows host terminals on a multi-user network to interact with other hosts regardless of terminal type and characteristics.
In open-loop control, policies are applied to __________- a)Remove after congestion occurs
- b)Remove after sometime
- c)Prevent before congestion occurs
- d)Prevent before sending packets
Correct answer is option 'C'. Can you explain this answer?
In open-loop control, policies are applied to __________
a)
Remove after congestion occurs
b)
Remove after sometime
c)
Prevent before congestion occurs
d)
Prevent before sending packets
|
|
Sudhir Patel answered |
Open loop congestion control techniques are used to prevent congestion before it even happens by enforcing certain policies. Retransmission policy, window policy and acknowledgement policy are some policies that might be enforced.
Life time of a TCP segment is defined as the time for which a TCP segment is permitted to stay in a network. Consider a TCP connection has Bandwidth of 8 GBPS and lifetime of a TCP segment is 4 seconds.Q. The number of extra bits required from options field if the user doesn’t want to decrease the Bandwidth?
Correct answer is '3'. Can you explain this answer?
Life time of a TCP segment is defined as the time for which a TCP segment is permitted to stay in a network. Consider a TCP connection has Bandwidth of 8 GBPS and lifetime of a TCP segment is 4 seconds.
Q. The number of extra bits required from options field if the user doesn’t want to decrease the Bandwidth?
|
|
Athira Reddy answered |
't want to exceed the Maximum Segment Lifetime (MSL) of 2 minutes?
A. The Maximum Segment Lifetime (MSL) is defined as the maximum amount of time a TCP segment can remain in the network before being discarded, which is usually set to 2 minutes (120 seconds).
To calculate the maximum lifetime of a TCP segment without exceeding the MSL, we can use the formula:
Maximum Lifetime = MSL / (2^(n-1))
where n is the number of extra bits required from the options field.
Substituting the values, we get:
4 seconds = 120 seconds / (2^(n-1))
Simplifying the equation, we get:
2^(n-1) = 120 / 4 = 30
Taking the logarithm of both sides, we get:
n-1 = log2(30)
n-1 = 4.91
n = 5.91
Since the number of bits required must be an integer, we need to round up to the nearest integer, which gives us:
n = 6
Therefore, the number of extra bits required from the options field if the user doesn't want to exceed the Maximum Segment Lifetime (MSL) of 2 minutes is 6 bits.
A. The Maximum Segment Lifetime (MSL) is defined as the maximum amount of time a TCP segment can remain in the network before being discarded, which is usually set to 2 minutes (120 seconds).
To calculate the maximum lifetime of a TCP segment without exceeding the MSL, we can use the formula:
Maximum Lifetime = MSL / (2^(n-1))
where n is the number of extra bits required from the options field.
Substituting the values, we get:
4 seconds = 120 seconds / (2^(n-1))
Simplifying the equation, we get:
2^(n-1) = 120 / 4 = 30
Taking the logarithm of both sides, we get:
n-1 = log2(30)
n-1 = 4.91
n = 5.91
Since the number of bits required must be an integer, we need to round up to the nearest integer, which gives us:
n = 6
Therefore, the number of extra bits required from the options field if the user doesn't want to exceed the Maximum Segment Lifetime (MSL) of 2 minutes is 6 bits.
The persist timer is used in TCP to- a)To detect crashes from the other end of the connection
- b)To enable retransmission
- c)To avoid deadlock condition
- d)To timeout FIN_Wait1 condition
Correct answer is option 'C'. Can you explain this answer?
The persist timer is used in TCP to
a)
To detect crashes from the other end of the connection
b)
To enable retransmission
c)
To avoid deadlock condition
d)
To timeout FIN_Wait1 condition
|
|
Aaditya Ghosh answered |
Understanding the TCP Persist Timer
The TCP persist timer plays a crucial role in maintaining reliable connections, particularly in scenarios where data transmission might be interrupted or stalled.
Purpose of the Persist Timer
- The persist timer is primarily designed to prevent deadlock conditions in TCP connections.
- A deadlock can occur when one side of the connection has sent a segment and is waiting for an acknowledgment (ACK), while the other side has no data to send because it is waiting for a window to open, thus blocking further communication.
How the Persist Timer Works
- When a sender receives a zero window size advertisement from the receiver, it must stop sending data.
- The sender then starts the persist timer. If the timer expires before receiving a non-zero window size advertisement, the sender will send a probe (usually a zero-length segment) to check if the receiver's window has opened up.
- This probing mechanism helps in avoiding indefinite stalling of the connection.
Importance of Avoiding Deadlocks
- By using the persist timer, TCP ensures that the connection does not remain idle indefinitely due to a lack of data flow.
- This feature is particularly important in scenarios where one side may be temporarily unable to receive data, ensuring that the connection can recover and continue transmitting data once the receiver is ready.
Conclusion
In summary, the correct answer is indeed option 'C' as the persist timer is fundamentally used to avoid deadlock conditions in TCP connections, allowing for efficient and reliable data transmission.
The TCP persist timer plays a crucial role in maintaining reliable connections, particularly in scenarios where data transmission might be interrupted or stalled.
Purpose of the Persist Timer
- The persist timer is primarily designed to prevent deadlock conditions in TCP connections.
- A deadlock can occur when one side of the connection has sent a segment and is waiting for an acknowledgment (ACK), while the other side has no data to send because it is waiting for a window to open, thus blocking further communication.
How the Persist Timer Works
- When a sender receives a zero window size advertisement from the receiver, it must stop sending data.
- The sender then starts the persist timer. If the timer expires before receiving a non-zero window size advertisement, the sender will send a probe (usually a zero-length segment) to check if the receiver's window has opened up.
- This probing mechanism helps in avoiding indefinite stalling of the connection.
Importance of Avoiding Deadlocks
- By using the persist timer, TCP ensures that the connection does not remain idle indefinitely due to a lack of data flow.
- This feature is particularly important in scenarios where one side may be temporarily unable to receive data, ensuring that the connection can recover and continue transmitting data once the receiver is ready.
Conclusion
In summary, the correct answer is indeed option 'C' as the persist timer is fundamentally used to avoid deadlock conditions in TCP connections, allowing for efficient and reliable data transmission.
In TCP/IP model the Transport layer provides _________.- a)Connection oriented Service
- b)Connection less service
- c)Both (1) and (2)
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
In TCP/IP model the Transport layer provides _________.
a)
Connection oriented Service
b)
Connection less service
c)
Both (1) and (2)
d)
None of the above
|
|
Sudhir Patel answered |
At network layer a connectionless service may mean different paths for different datagrams belonging to the same message.
At transport layer, connectionless service means independency between packets. (Connection orient) means dependency.
At transport layer, connectionless service means independency between packets. (Connection orient) means dependency.
To achieve reliable transport in TCP, ___________ is used to check the safe and sound arrival of data.- a)Packet
- b)Buffer
- c)Segment
- d)Acknowledgment
Correct answer is option 'D'. Can you explain this answer?
To achieve reliable transport in TCP, ___________ is used to check the safe and sound arrival of data.
a)
Packet
b)
Buffer
c)
Segment
d)
Acknowledgment
|
|
Navya Menon answered |
Answer: d
Explanation: Acknowledgment mechanism is used to check the safe and sound arrival of data.
Explanation: Acknowledgment mechanism is used to check the safe and sound arrival of data.
Suppose a TCP connection is transferring a file of 1000 bytes. The first byte is numbered 10001. What is the sequence number of the segment if all data is sent in only one segment.- a)10000
- b)10001
- c)12001
- d)11001
Correct answer is option 'B'. Can you explain this answer?
Suppose a TCP connection is transferring a file of 1000 bytes. The first byte is numbered 10001. What is the sequence number of the segment if all data is sent in only one segment.
a)
10000
b)
10001
c)
12001
d)
11001
|
|
Nabanita Basak answered |
The sequence number given to first byte of a segment, with respect to its order among the previous segments, is the sequence number of that segment.
Hence option (b) is correct
For the complete syllabus of the chapter, Computer Architecture click on the link given below:

The field used to detect errors over the entire user datagram is- a)UDP header
- b)Checksum
- c)Source port
- d)Destination port
Correct answer is option 'B'. Can you explain this answer?
The field used to detect errors over the entire user datagram is
a)
UDP header
b)
Checksum
c)
Source port
d)
Destination port
|
|
Maulik Pillai answered |
Answer: b
Explanation: Checksum field is used to detect errors over the entire user datagram.
Explanation: Checksum field is used to detect errors over the entire user datagram.
TCP/IP is related to __________- a)ARPANET
- b)OSI
- c)DECNET
- d)ALOHA
Correct answer is option 'A'. Can you explain this answer?
TCP/IP is related to __________
a)
ARPANET
b)
OSI
c)
DECNET
d)
ALOHA
|
|
Navya Iyer answered |
TCP/IP is related to ARPANET
TCP/IP stands for Transmission Control Protocol/Internet Protocol, which is a set of networking protocols used for communication on the Internet. It was developed in the 1970s by the Defense Advanced Research Projects Agency (DARPA) for use on the ARPANET, which was the predecessor to the modern Internet.
Below are some key points explaining the relationship between TCP/IP and ARPANET:
- ARPANET: ARPANET was the first wide-area packet-switching network and the foundation of the Internet. It was developed by DARPA, an agency of the United States Department of Defense, and served as a testbed for new networking technologies. TCP/IP was designed to work on ARPANET, making it an integral part of the network's infrastructure.
- Development: TCP/IP was specifically created to be the communication protocol for ARPANET, providing a reliable and standardized way for different types of computers to communicate with each other over the network. It allowed for the transmission of data packets between devices connected to ARPANET.
- Standardization: Over time, TCP/IP became the standard networking protocol for the Internet, replacing other protocols like DECNET and ALOHA. Its robustness, flexibility, and scalability contributed to its widespread adoption and use in various networking environments.
In conclusion, TCP/IP is closely related to ARPANET as it was originally developed for and used on the network, playing a crucial role in the establishment and evolution of the Internet as we know it today.
TCP/IP stands for Transmission Control Protocol/Internet Protocol, which is a set of networking protocols used for communication on the Internet. It was developed in the 1970s by the Defense Advanced Research Projects Agency (DARPA) for use on the ARPANET, which was the predecessor to the modern Internet.
Below are some key points explaining the relationship between TCP/IP and ARPANET:
- ARPANET: ARPANET was the first wide-area packet-switching network and the foundation of the Internet. It was developed by DARPA, an agency of the United States Department of Defense, and served as a testbed for new networking technologies. TCP/IP was designed to work on ARPANET, making it an integral part of the network's infrastructure.
- Development: TCP/IP was specifically created to be the communication protocol for ARPANET, providing a reliable and standardized way for different types of computers to communicate with each other over the network. It allowed for the transmission of data packets between devices connected to ARPANET.
- Standardization: Over time, TCP/IP became the standard networking protocol for the Internet, replacing other protocols like DECNET and ALOHA. Its robustness, flexibility, and scalability contributed to its widespread adoption and use in various networking environments.
In conclusion, TCP/IP is closely related to ARPANET as it was originally developed for and used on the network, playing a crucial role in the establishment and evolution of the Internet as we know it today.
what is the header size of UDP packet?- a)8 bytes
- b)8 bits
- c)16 bytes
- d)124 bytes
Correct answer is option 'A'. Can you explain this answer?
what is the header size of UDP packet?
a)
8 bytes
b)
8 bits
c)
16 bytes
d)
124 bytes
|
|
Snehal Desai answered |
Answer: a
Explanation: The fixed size of the UDP packet header is 8 bytes.
Explanation: The fixed size of the UDP packet header is 8 bytes.
Port number used by Network Time Protocol(NTP) with UDP is- a)161
- b)123
- c)162
- d)124
Correct answer is option 'B'. Can you explain this answer?
Port number used by Network Time Protocol(NTP) with UDP is
a)
161
b)
123
c)
162
d)
124
|
|
Jyoti Sengupta answered |
Answer: b
Explanation: Port number used by Network Time Protocol with UDP is 123.
Explanation: Port number used by Network Time Protocol with UDP is 123.
Packets of the same session may be routed through different paths in- a)TCP, but not UDP
- b)TCP and UDP
- c)UDP, but not TCP
- d)Neither TCP nor UDP
Correct answer is option 'B'. Can you explain this answer?
Packets of the same session may be routed through different paths in
a)
TCP, but not UDP
b)
TCP and UDP
c)
UDP, but not TCP
d)
Neither TCP nor UDP
|
|
Moumita Yadav answered |
Explanation:
In computer networking, packets are the basic units of data that are transmitted over a network. They contain the payload (data) as well as the necessary information for routing and delivering the data to the intended destination.
Routing in TCP:
TCP (Transmission Control Protocol) is a reliable and connection-oriented protocol. It establishes a connection between two endpoints before transmitting data. The packets in a TCP session are sent in a sequential order and they are received at the destination in the same order. TCP ensures that the packets are delivered reliably and in order by using mechanisms like acknowledgment, retransmission, and flow control.
When it comes to routing, TCP packets are routed based on the IP addresses and port numbers of the source and destination. Once the connection is established, the routing path remains fixed for the duration of the session. This means that all the packets of a TCP session will follow the same path from the source to the destination. Therefore, packets of the same TCP session will be routed through the same path.
Routing in UDP:
UDP (User Datagram Protocol) is a connectionless and unreliable protocol. It does not establish a connection before transmitting data and does not guarantee delivery or order of packets. Each UDP packet is independent and can take a different path to reach the destination. UDP does not have any built-in mechanisms for acknowledgment, retransmission, or flow control.
Since UDP does not maintain any connection state, the packets of a UDP session can be routed through different paths. The routing decisions are made by the routers based on factors like network congestion, availability of routes, and load balancing. Therefore, it is possible for packets of the same UDP session to take different paths.
Conclusion:
In conclusion, packets of the same session may be routed through different paths in both TCP and UDP. However, TCP ensures that the packets are delivered reliably and in order, while UDP does not provide such guarantees.
In computer networking, packets are the basic units of data that are transmitted over a network. They contain the payload (data) as well as the necessary information for routing and delivering the data to the intended destination.
Routing in TCP:
TCP (Transmission Control Protocol) is a reliable and connection-oriented protocol. It establishes a connection between two endpoints before transmitting data. The packets in a TCP session are sent in a sequential order and they are received at the destination in the same order. TCP ensures that the packets are delivered reliably and in order by using mechanisms like acknowledgment, retransmission, and flow control.
When it comes to routing, TCP packets are routed based on the IP addresses and port numbers of the source and destination. Once the connection is established, the routing path remains fixed for the duration of the session. This means that all the packets of a TCP session will follow the same path from the source to the destination. Therefore, packets of the same TCP session will be routed through the same path.
Routing in UDP:
UDP (User Datagram Protocol) is a connectionless and unreliable protocol. It does not establish a connection before transmitting data and does not guarantee delivery or order of packets. Each UDP packet is independent and can take a different path to reach the destination. UDP does not have any built-in mechanisms for acknowledgment, retransmission, or flow control.
Since UDP does not maintain any connection state, the packets of a UDP session can be routed through different paths. The routing decisions are made by the routers based on factors like network congestion, availability of routes, and load balancing. Therefore, it is possible for packets of the same UDP session to take different paths.
Conclusion:
In conclusion, packets of the same session may be routed through different paths in both TCP and UDP. However, TCP ensures that the packets are delivered reliably and in order, while UDP does not provide such guarantees.
Which of the following is incorrect regarding the Internet Control Message Protocol (ICMP)?- a)When something unexpected occurs in routers those events are reported by the ICMP.
- b)ICMP is also used to test the connectivity.
- c)ICMP and BOOTP protocols are equivalent in their usage.
- d)Each ICMP message type is encapsulated in a IP packet.
Correct answer is option 'C'. Can you explain this answer?
Which of the following is incorrect regarding the Internet Control Message Protocol (ICMP)?
a)
When something unexpected occurs in routers those events are reported by the ICMP.
b)
ICMP is also used to test the connectivity.
c)
ICMP and BOOTP protocols are equivalent in their usage.
d)
Each ICMP message type is encapsulated in a IP packet.
|
|
Manasa Dey answered |
ICMP is error reporting protocol used when something unexpected occurs in routers, used to test connectivity while BOOTP is IP protocol network to automatically assigned an IP address to network devices from a configuration server.
In ______ , data are sent or processed at a very inefficient rate, such as 1 byte at a time.- a)Nagle’s syndrome
- b)Silly window syndrome
- c)Sliding window syndrome
- d)Delayed acknowledgment
Correct answer is option 'B'. Can you explain this answer?
In ______ , data are sent or processed at a very inefficient rate, such as 1 byte at a time.
a)
Nagle’s syndrome
b)
Silly window syndrome
c)
Sliding window syndrome
d)
Delayed acknowledgment
|
|
Surbhi Kaur answered |
Silly window syndrome problem can degrade TCP performance. This problem occurs when data are passed to the sending TCP entity in large blocks, but interactive application on the receiving side reads data T byte at a time.
Brouter- a)Is a type of bridge
- b)Works at all the layers Of OS I model
- c)Is able to bridge those protocols that are not routable
- d)None of these
Correct answer is option 'C'. Can you explain this answer?
Brouter
a)
Is a type of bridge
b)
Works at all the layers Of OS I model
c)
Is able to bridge those protocols that are not routable
d)
None of these
|
|
Arka Shah answered |
Brouter is a device, which is combination of functionality of bridge and router. So, it works till network layer and is able to bridge those protocol that are not routable.
Chapter doubts & questions for Transport Layer - 6 Months Preparation for GATE CSE 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Transport Layer - 6 Months Preparation for GATE CSE in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
6 Months Preparation for GATE CSE
459 videos|1398 docs|786 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up within 7 days!
Access 1000+ FREE Docs, Videos and Tests
Takes less than 10 seconds to signup