









All questions of Compiler Design for Computer Science Engineering (CSE) Exam
The grammar A → AA | (A) | ε is not suitable for predictive-parsing because the grammar is- a)ambiguous
- b)left-recursive
- c)right-recursive
- d)an operator-grammar
Correct answer is option 'B'. Can you explain this answer?
The grammar A → AA | (A) | ε is not suitable for predictive-parsing because the grammar is
a)
ambiguous
b)
left-recursive
c)
right-recursive
d)
an operator-grammar
|
|
Yash Patel answered |
nswer (B) is correct because grammar is left recursive, hence the parser may fall into a loop. Answer A is not correct because ambiguity can occur from both left or right recursion.

The process of assigning load addresses to the various parts of the program and adjusting the code and the data in the program to reflect the assigned addresses is called- a)Assembly
- b)parsing
- c)Relocation
- d)Symbol resolution
Correct answer is option 'C'. Can you explain this answer?
The process of assigning load addresses to the various parts of the program and adjusting the code and the data in the program to reflect the assigned addresses is called
a)
Assembly
b)
parsing
c)
Relocation
d)
Symbol resolution

|
Crack Gate answered |
Relocation is the process of assigning load addresses to position-dependent code of a program and adjusting the code and data in the program to reflect the assigned addresses.
Hence Option C is Ans
Symbol resolution is the process of searching files and libraries to replace symbolic references or names of libraries with actual usable addresses in memory before running a program.
Symbol resolution is the process of searching files and libraries to replace symbolic references or names of libraries with actual usable addresses in memory before running a program.
The number of possible min-heaps containing each value from {1, 2, 3, 4, 5, 6, 7} exactly once is _______.- a) 80
- b) 8
- c)20
- d)210
Correct answer is option 'A'. Can you explain this answer?
The number of possible min-heaps containing each value from {1, 2, 3, 4, 5, 6, 7} exactly once is _______.
a)
80
b)
8
c)
20
d)
210
|
|
Ravi Singh answered |
Set minimum element as root (i.e 1), now 6 are remaining and left subtree will have 3 elements, each left subtree combination can be permuted in 2! ways.
Total ways to design min-heap with 7-elements =  *2! * 2! = 20*2*2 = 80
*2! * 2! = 20*2*2 = 80
*2! * 2! = 20*2*2 = 80Alternative approach – Total number of min or max heap tree with 1 to N elements are using recurrence relation:
► T(N) = (N-1)Ck * T(k) * T(N-k-1), where k = number of nodes on left subtree
► T(1) = 1 T(2) = 1 T(3) = 2 T(4) = 3C2 * T(2) * T(1) = 3 T(5) = 4C3 * T(3) * T(1) = 8 T(6) = 5C3 * T(3) * T(2) = 20 T(7) = 5C3 * T(3) * T(3) = 80
► T(1) = 1 T(2) = 1 T(3) = 2 T(4) = 3C2 * T(2) * T(1) = 3 T(5) = 4C3 * T(3) * T(1) = 8 T(6) = 5C3 * T(3) * T(2) = 20 T(7) = 5C3 * T(3) * T(3) = 80
So, answer is 80.
A language L allows declaration of arrays whose sizes are not known during compilation. It is required to make efficient use of memory. Which one of the following is true?- a) A compiler using static memory allocation can be written for L
- b)A compiler cannot be written for ; an interpreter must be used
- c)A compiler using dynamic memory allocation can be written for L
- d)None of the above
Correct answer is option 'D'. Can you explain this answer?
A language L allows declaration of arrays whose sizes are not known during compilation. It is required to make efficient use of memory. Which one of the following is true?
a)
A compiler using static memory allocation can be written for L
b)
A compiler cannot be written for ; an interpreter must be used
c)
A compiler using dynamic memory allocation can be written for L
d)
None of the above
|
|
Yash Patel answered |
If a language L allows declaration of arrays whose sizes are not known during compilation time. It is required to use efficient use of memory.
So a compiler using dynamic memory allocation can be written for L.
So a compiler using dynamic memory allocation can be written for L.
An array is a collection of data items, all of the same type, accessed using a common name.
C dynamic memory allocation refers to performing manual memory management for dynamic memory allocation in the C programming language via a group of functions in the C standard library, namely malloc, realloc, calloc and free.
Consider the CFG with {S,A,B) as the non-terminal alphabet, {a,b) as the terminal alphabet, S as the start symbol and the following set of production rules: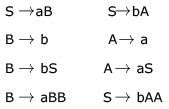 For the string aabbab , how many derivation trees are there?
For the string aabbab , how many derivation trees are there?- a)1
- b)2
- c)3
- d)4
Correct answer is option 'B'. Can you explain this answer?
Consider the CFG with {S,A,B) as the non-terminal alphabet, {a,b) as the terminal alphabet, S as the start symbol and the following set of production rules:
For the string aabbab , how many derivation trees are there?
a)
1
b)
2
c)
3
d)
4
|
|
Yash Patel answered |

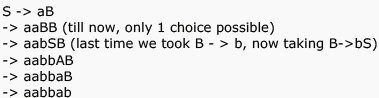
Consider the CFG with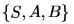 as the non-terminal alphabet,
as the non-terminal alphabet,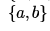 as the terminal alphabet, S as the start symbol and the following set of production rules:
as the terminal alphabet, S as the start symbol and the following set of production rules: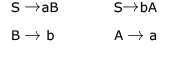
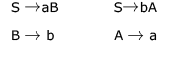 Which of the following strings is generated by the grammar?
Which of the following strings is generated by the grammar?- a)aaaabb
- b)aabbbb
- c)aabbab
- d)abbbba
Correct answer is option 'C'. Can you explain this answer?
Consider the CFG with
as the non-terminal alphabet, as the terminal alphabet, S as the start symbol and the following set of production rules:Which of the following strings is generated by the grammar?
a)
aaaabb
b)
aabbbb
c)
aabbab
d)
abbbba
|
|
Rhea Reddy answered |

Which one of the following is NOT performed during compilation?- a)Dynamic memory allocation
- b)Type checking
- c)Symbol table management
- d)Inline expansion
Correct answer is option 'A'. Can you explain this answer?
Which one of the following is NOT performed during compilation?
a)
Dynamic memory allocation
b)
Type checking
c)
Symbol table management
d)
Inline expansion
|
|
Nabanita Basak answered |
Dynamic means- at runtime. Dynamic memory allocation happens during the execution time and hence (A) is the answer.
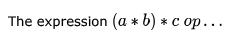 where ‘op’ is one of ‘+’, ‘*’ and ‘ ’ (exponentiation) can be evaluated on a CPU with single register without storing the value of (a * b) if
where ‘op’ is one of ‘+’, ‘*’ and ‘ ’ (exponentiation) can be evaluated on a CPU with single register without storing the value of (a * b) if- a) ‘op’ is ‘+’ or ‘*’
- b) ‘op’ is ‘ ’ or ‘*’
- c) ‘op’ is ‘ ’ or ‘+’
- d)not possible to evaluate without storing
Correct answer is option 'A'. Can you explain this answer?
where ‘op’ is one of ‘+’, ‘*’ and ‘ ’ (exponentiation) can be evaluated on a CPU with single register without storing the value of (a * b) if
a)
‘op’ is ‘+’ or ‘*’
b)
‘op’ is ‘ ’ or ‘*’
c)
‘op’ is ‘ ’ or ‘+’
d)
not possible to evaluate without storing
|
|
Ravi Singh answered |
↑ has higer precedence than {*,+,-,/}
So, if op = ↑ implies, we need to evaluate the right hand side of ↑ first and then do the lhs part, which would definately require us to store the value of lhs
but if its a '+' or '*' , we dont need to store the values evaluated, and on the go can do the operation directly on one register.
Consider the grammar shown below S → i E t S S' | a S' → e S | ε E → b In the predictive parse table. M, of this grammar, the entries M[S', e] and M[S', $] respectively are- a){S' → e S} and {S' → e}
- b){S' → e S} and {}
- c){S' → ε} and {S' → ε}
- d){S' → e S, S'→ ε} and {S' → ε}
Correct answer is option 'D'. Can you explain this answer?
Consider the grammar shown below S → i E t S S' | a S' → e S | ε E → b In the predictive parse table. M, of this grammar, the entries M[S', e] and M[S', $] respectively are
a)
{S' → e S} and {S' → e}
b)
{S' → e S} and {}
c)
{S' → ε} and {S' → ε}
d)
{S' → e S, S'→ ε} and {S' → ε}
|
|
Vaibhav Patel answered |
Here representing the parsing table as M[ X , Y], where X represents rows(Non terminals) and Y represents columns(terminals). Here are the rules to fill the parsing table. For each distinct production rule A->α, of the grammar, we need to apply the given rules:
Rule 1: if A –> α is a production, for each terminal ‘a’ in FIRST(α), add A–>α to M[ A , a]
Rule 2 : if ‘ ε ‘ is in FIRST(α), add A –> α to M [A , b] for each ‘b’ in FOLLOW(A). As Entries have been asked corresponding to Non-Terminal S', hence we only need to consider its productions to get the answer. For S' → eS, according to rule 1, this production rule should be placed at the entry M[ S', FIRST(eS)], and from the given grammar, FIRST(eS) ={e}, hence S'->eS is placed in the parsing table at entry M[S' , e]. Similarly, For S'->ε, as FIRST(ε) = {ε}, hence rule 2 should be applied, therefore, this production rule should be placed in the parsing table at entry M[S',FOLLOW(S')], and FOLLOW(S') = FOLLOW(S) = {e, $}, hence R->ε is placed at entry M[S', e] and M[S' , $]. Therefore Answer is option D. Visit the Following links to Learn how to find First and Follow sets.
Rule 1: if A –> α is a production, for each terminal ‘a’ in FIRST(α), add A–>α to M[ A , a]
Rule 2 : if ‘ ε ‘ is in FIRST(α), add A –> α to M [A , b] for each ‘b’ in FOLLOW(A). As Entries have been asked corresponding to Non-Terminal S', hence we only need to consider its productions to get the answer. For S' → eS, according to rule 1, this production rule should be placed at the entry M[ S', FIRST(eS)], and from the given grammar, FIRST(eS) ={e}, hence S'->eS is placed in the parsing table at entry M[S' , e]. Similarly, For S'->ε, as FIRST(ε) = {ε}, hence rule 2 should be applied, therefore, this production rule should be placed in the parsing table at entry M[S',FOLLOW(S')], and FOLLOW(S') = FOLLOW(S) = {e, $}, hence R->ε is placed at entry M[S', e] and M[S' , $]. Therefore Answer is option D. Visit the Following links to Learn how to find First and Follow sets.
Consider the translation scheme shown below. Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string ‘9 + 5 + 2’, this translation scheme will print
Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string ‘9 + 5 + 2’, this translation scheme will print- a)9 + 5 + 2
- b)9 5 + 2 +
- c)9 5 2 + +
- d)+ + 9 5 2
Correct answer is option 'B'. Can you explain this answer?
Consider the translation scheme shown below.
Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string ‘9 + 5 + 2’, this translation scheme will print
a)
9 + 5 + 2
b)
9 5 + 2 +
c)
9 5 2 + +
d)
+ + 9 5 2

|
Bala Chowdappa answered |
May I know how this can be
Which languages necessarily need heap allocation in the runtime environment?- a)Those that support recursion .
- b)Those that use dynamic scoping
- c)Those that allow dynamic data structure
- d)Those that use global variables
Correct answer is option 'C'. Can you explain this answer?
Which languages necessarily need heap allocation in the runtime environment?
a)
Those that support recursion .
b)
Those that use dynamic scoping
c)
Those that allow dynamic data structure
d)
Those that use global variables
|
|
Sanya Agarwal answered |
Runtime environment means we deal with dynamic memory allocation and Heap is a dynamic data structure.
So it is clear that those languages that allow dynamic data structure necessarily need heap allocation in the runtime environment.
So it is clear that those languages that allow dynamic data structure necessarily need heap allocation in the runtime environment.
Consider the expression 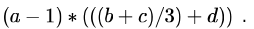 Let X be the minimum number of registers required by an optimal code generation (without any register spill) algorithm for a load/store architecture, in which (i) only load and store instructions can have memory operands a n d (ii) arithmetic instructions can have only register or immediate operands. The value of X is _____________ .
Let X be the minimum number of registers required by an optimal code generation (without any register spill) algorithm for a load/store architecture, in which (i) only load and store instructions can have memory operands a n d (ii) arithmetic instructions can have only register or immediate operands. The value of X is _____________ .
Correct answer is '2'. Can you explain this answer?
Consider the expression Let X be the minimum number of registers required by an optimal code generation (without any register spill) algorithm for a load/store architecture, in which (i) only load and store instructions can have memory operands a n d (ii) arithmetic instructions can have only register or immediate operands. The value of X is _____________ .
Let X be the minimum number of registers required by an optimal code generation (without any register spill) algorithm for a load/store architecture, in which (i) only load and store instructions can have memory operands a n d (ii) arithmetic instructions can have only register or immediate operands. The value of X is _____________ . |
|
Yash Patel answered |


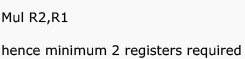
Match the following:
 Codes:
Codes:
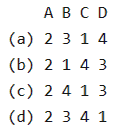
- a)a
- b)b
- c)c
- d)d
Correct answer is option 'C'. Can you explain this answer?
Match the following:
Codes:
a)
a
b)
b
c)
c
d)
d
|
|
Yash Patel answered |
Register allocation is a variation of Graph Coloring problem.
Lexical Analysis uses DFA.
Parsing makes production tree Expression evaluation is done using tree traversal
Lexical Analysis uses DFA.
Parsing makes production tree Expression evaluation is done using tree traversal
The grammar S → aSa | bS | c is- a)LL(1) but not LR(1)
- b)LR(1)but not LR(1)
- c)Both LL(1)and LR(1)
- d)Neither LL(1)nor LR(1)
Correct answer is option 'C'. Can you explain this answer?
The grammar S → aSa | bS | c is
a)
LL(1) but not LR(1)
b)
LR(1)but not LR(1)
c)
Both LL(1)and LR(1)
d)
Neither LL(1)nor LR(1)

|
Arjun Unni answered |
First(aSa) = a
First(bS) = b
First(c) = c
All are mutually disjoint i.e no common terminal between them, the given grammar is LL(1).
As the grammar is LL(1) so it will also be LR(1) as LR parsers are more powerful then LL(1) parsers. and all LL(1) grammar are also LR(1) So option C is correct.
Below are more details. A grammar is LL(1) if it is possible to choose the next production by looking at only the next token in the input string.
Formally, grammar G is LL(1) if and only if
For all productions A → α1 | α2 | ... | αn,
First(αi) ∩ First(αj) = ∅, 1 ≤ i,j ≤ n, i ≠ j.
For every non-terminal A such that First(A) contains ε,
First(A) ∩ Follow(A) = ∅
First(bS) = b
First(c) = c
All are mutually disjoint i.e no common terminal between them, the given grammar is LL(1).
As the grammar is LL(1) so it will also be LR(1) as LR parsers are more powerful then LL(1) parsers. and all LL(1) grammar are also LR(1) So option C is correct.
Below are more details. A grammar is LL(1) if it is possible to choose the next production by looking at only the next token in the input string.
Formally, grammar G is LL(1) if and only if
For all productions A → α1 | α2 | ... | αn,
First(αi) ∩ First(αj) = ∅, 1 ≤ i,j ≤ n, i ≠ j.
For every non-terminal A such that First(A) contains ε,
First(A) ∩ Follow(A) = ∅
Which of the following are language processors?- a)Assembler
- b)compilers
- c)Interpreters
- d)All of these
Correct answer is option 'A'. Can you explain this answer?
Which of the following are language processors?
a)
Assembler
b)
compilers
c)
Interpreters
d)
All of these
|
|
Mira Rane answered |
Assembler is a language processor to process assembly language
Given two DFA’s M1, and M2. They are equivalent if- a)M1, and M2 has the same number of states
- b)M1 and M2 has the same number of final states
- c)M1, and M2 accepts the same language, i.e. L(M1 ) = L(M2)
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
Given two DFA’s M1, and M2. They are equivalent if
a)
M1, and M2 has the same number of states
b)
M1 and M2 has the same number of final states
c)
M1, and M2 accepts the same language, i.e. L(M1 ) = L(M2)
d)
None of the above
|
|
Ayush Basu answered |
Given two DFA’s M1 and M2. They are equivalent if the language generated by them is same i,e, L(M1) = L(M2)
A directed acyclic graph represents one form of intermediate representation. The number of non terminals nodes in DAG of a = (b + c)*(b + c) expression is- a)2
- b)3
- c)4
- d)5
Correct answer is option 'B'. Can you explain this answer?
A directed acyclic graph represents one form of intermediate representation. The number of non terminals nodes in DAG of a = (b + c)*(b + c) expression is
a)
2
b)
3
c)
4
d)
5
|
|
Rohit Mukherjee answered |
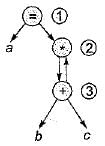
Since indegree of node 3 is 1. So cannot start topological ordering with node 3 only start node will be 1.
A loader is- a)A program that place programs into memory and prepares them for execution.
- b)A program that automates the translations of assembly language into machine language.
- c)A program that accepts a program written in a high level language and produces an object program.
- d)A program that appears to execute a source program as if it were machine language.
Correct answer is option 'A'. Can you explain this answer?
A loader is
a)
A program that place programs into memory and prepares them for execution.
b)
A program that automates the translations of assembly language into machine language.
c)
A program that accepts a program written in a high level language and produces an object program.
d)
A program that appears to execute a source program as if it were machine language.
|
|
Anjana Ahuja answered |
Answer:
A loader is a program that places programs into memory and prepares them for execution. It is responsible for loading executable files into the computer's memory and prepares them for execution by setting up the necessary data structures and resolving any dependencies.
Explanation:
A loader is an essential component of the operating system that is responsible for various tasks related to the execution of programs. Its main purpose is to load executable files into memory so that the CPU can execute them. Here are the main tasks performed by a loader:
1. Loading:
The loader is responsible for loading the executable file into memory. It reads the file from the disk and allocates memory space for the program's instructions and data. It ensures that the program is loaded into the correct memory locations.
2. Relocation:
Many programs are designed to be loaded at different memory locations. The loader performs the necessary operations to relocate the program to the correct memory location specified by the operating system. It updates the memory references in the program's instructions and data to reflect the new memory location.
3. Linking:
In some cases, a program may have external dependencies on other libraries or modules. The loader resolves these dependencies by linking the program with the required libraries. It connects the program's references to external symbols with the actual memory addresses of the corresponding symbols.
4. Symbol Resolution:
The loader resolves any symbolic references in the program. Symbolic references are memory addresses that are represented symbolically rather than numerically. The loader connects these symbolic references with the actual memory addresses during the loading process.
5. Loading Dependencies:
If the program has any shared libraries or dynamically loaded modules, the loader is responsible for loading these dependencies into memory as well. It ensures that all the necessary components for the program's execution are present in memory.
Overall, a loader plays a crucial role in preparing a program for execution by handling the loading, relocation, linking, and symbol resolution tasks. It sets up the program's environment in memory, allowing the CPU to execute the instructions and data contained within the program.
A loader is a program that places programs into memory and prepares them for execution. It is responsible for loading executable files into the computer's memory and prepares them for execution by setting up the necessary data structures and resolving any dependencies.
Explanation:
A loader is an essential component of the operating system that is responsible for various tasks related to the execution of programs. Its main purpose is to load executable files into memory so that the CPU can execute them. Here are the main tasks performed by a loader:
1. Loading:
The loader is responsible for loading the executable file into memory. It reads the file from the disk and allocates memory space for the program's instructions and data. It ensures that the program is loaded into the correct memory locations.
2. Relocation:
Many programs are designed to be loaded at different memory locations. The loader performs the necessary operations to relocate the program to the correct memory location specified by the operating system. It updates the memory references in the program's instructions and data to reflect the new memory location.
3. Linking:
In some cases, a program may have external dependencies on other libraries or modules. The loader resolves these dependencies by linking the program with the required libraries. It connects the program's references to external symbols with the actual memory addresses of the corresponding symbols.
4. Symbol Resolution:
The loader resolves any symbolic references in the program. Symbolic references are memory addresses that are represented symbolically rather than numerically. The loader connects these symbolic references with the actual memory addresses during the loading process.
5. Loading Dependencies:
If the program has any shared libraries or dynamically loaded modules, the loader is responsible for loading these dependencies into memory as well. It ensures that all the necessary components for the program's execution are present in memory.
Overall, a loader plays a crucial role in preparing a program for execution by handling the loading, relocation, linking, and symbol resolution tasks. It sets up the program's environment in memory, allowing the CPU to execute the instructions and data contained within the program.
In analyzing the compilation of PL/I program the description “resolving symbolic address (labies) and generating machine language” is associated with- a)Assembly and output
- b)Codegeneration
- c)Storage assignment
- d)Syntax analysis
Correct answer is option 'A'. Can you explain this answer?
In analyzing the compilation of PL/I program the description “resolving symbolic address (labies) and generating machine language” is associated with
a)
Assembly and output
b)
Codegeneration
c)
Storage assignment
d)
Syntax analysis
|
|
Ameya Goyal answered |
The final phase of the compiler is the generation of target code, consisting of relocatable machine code or assembly code. Intermediate instruction are each translated into a sequence of machine instructions that perform the same task. A crucial aspect is the assignment of variables to registers.
Consider line number 3 of the following C-program.
int main () { /* Line 1 */
int i, n; /* Line 2 */
fro (i = 0, i < n, /+ + ); /* Line 3 */
}Identify the compiler’s response about this line while creating the object - module- a)No compilation error
- b)Only a lexical error
- c)Only syntactic errors
- d)Both lexical and syntactic errors
Correct answer is option 'C'. Can you explain this answer?
Consider line number 3 of the following C-program.
int main () { /* Line 1 */
int i, n; /* Line 2 */
fro (i = 0, i < n, /+ + ); /* Line 3 */
}
int main () { /* Line 1 */
int i, n; /* Line 2 */
fro (i = 0, i < n, /+ + ); /* Line 3 */
}
Identify the compiler’s response about this line while creating the object - module
a)
No compilation error
b)
Only a lexical error
c)
Only syntactic errors
d)
Both lexical and syntactic errors
|
|
Navya Menon answered |
Error is underlined function fro()
Which is a syntactical error rather than lexical.
Which is a syntactical error rather than lexical.
Consider the grammar shown below.S → C C
C → c C | dThe grammar is- a)LL(1)
- b)SLR(1) but not LL(1)
- c)LALR(1) but not SLR(1)
- d)LR(1) but not LALR(1)
Correct answer is option 'A'. Can you explain this answer?
Consider the grammar shown below.
S → C C
C → c C | d
C → c C | d
The grammar is
a)
LL(1)
b)
SLR(1) but not LL(1)
c)
LALR(1) but not SLR(1)
d)
LR(1) but not LALR(1)
|
|
Ayush Mehta answered |
Since there is no conflict, the grammar is LL(1). We can construct a predictive parse table with no conflicts. This grammar also LR(0), SLR(1), CLR(1) and LALR(1).
In some phase of compiler Input
temp1 := Inttoreal (60)
temp2 := id3 * temp1
temp3 := id2 + temp2
id1 := temp3
Output
temp 1 := id3 * 60.0
id1 := id2 + temp1where temp i , temp 2 , temp 3 are temporary storage, id1, id2, Id3 are identifier intto real is converting int 60 to real number. The above phase is- a)Code optimizer
- b)Code generator
- c)intermediate code generator
- d)None of the abov
Correct answer is option 'A'. Can you explain this answer?
In some phase of compiler
Input
temp1 := Inttoreal (60)
temp2 := id3 * temp1
temp3 := id2 + temp2
id1 := temp3
Output
temp 1 := id3 * 60.0
id1 := id2 + temp1
temp1 := Inttoreal (60)
temp2 := id3 * temp1
temp3 := id2 + temp2
id1 := temp3
Output
temp 1 := id3 * 60.0
id1 := id2 + temp1
where temp i , temp 2 , temp 3 are temporary storage, id1, id2, Id3 are identifier intto real is converting int 60 to real number. The above phase is
a)
Code optimizer
b)
Code generator
c)
intermediate code generator
d)
None of the abov
|
|
Aditi Gupta answered |
Input:
temp1: = inttoreal(60)
temp2: = id3*temp1
temp3 : = id2 + temp2
id1 : = temp3
temp1: = inttoreal(60)
temp2: = id3*temp1
temp3 : = id2 + temp2
id1 : = temp3
Output:
temp1 : = id3*60.0
id1 : id2 + temp1
temp1 : = id3*60.0
id1 : id2 + temp1
The above phase is code optimization, because it is optimizing the intermediate code using only storages as temp 1 and id1.
The graph that shows the basic blocks and their successor relationship is called- a)DAG
- b)Flow graph
- c)Control graph
- d)Hamiltonian graph
Correct answer is option 'C'. Can you explain this answer?
The graph that shows the basic blocks and their successor relationship is called
a)
DAG
b)
Flow graph
c)
Control graph
d)
Hamiltonian graph
|
|
Garima Bose answered |
The graph that shows the basic blocks and their successor relationship is called control graph.
A grammar that is both left and right recursive for a non-terminal, is- a)Ambiguous
- b)Unambiguous
- c)Information is not sufficient to decide whether it is ambiguous or unambiguous
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
A grammar that is both left and right recursive for a non-terminal, is
a)
Ambiguous
b)
Unambiguous
c)
Information is not sufficient to decide whether it is ambiguous or unambiguous
d)
None of the above
|
|
Vaishnavi Kaur answered |
Let grammar is like this :
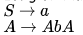
This grammar is left as well as right recursive but still unambiguous.. A is useless production but still part of grammar..
A grammar having both left as well as right recursion may or may not be ambiguous ..
Let's take a grammar say
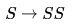
Now, according to the link https://en.wikipedia.org/wiki/Formal_grammar
For a grammar G, if we have L(G) then all the strings/sentences in this language can be produced after some finite number of steps .
But, for the grammar
Can we produce any string after a finite number of steps ? NO, and hence language of this grammar is empty set {} .
Hence, If a grammar is having both left and right recursion, then grammar may or may not be ambiguous .
A linker reads four modules whose lengths are 200,800,600,and 500 words, respectively. If they are loaded in that order, what are the relocation constants?- a)0,200,500,600
- b)0,200,1000,1600
- c)200,500,600,800
- d)200,700,1300,2100
Correct answer is option 'B'. Can you explain this answer?
A linker reads four modules whose lengths are 200,800,600,and 500 words, respectively. If they are loaded in that order, what are the relocation constants?
a)
0,200,500,600
b)
0,200,1000,1600
c)
200,500,600,800
d)
200,700,1300,2100
|
|
Madhurima Iyer answered |
first module loaded starting at address 0. Size is 200. hence it will occup first 200 address last address being 199. Second module will be present from 200 and so on.
Consider the grammarS → (S) | aLet the number of states in SLR(1), LR(1) and LALR(1) parsers for the grammar be n1, n2 and n3 respectively. The following relationship holds good- a)n1 < n2 < n3
- b)n1 = n3 < n2
- c)n1 = n2 = n3
- d)n1 ≥ n3 ≥ n2
Correct answer is option 'B'. Can you explain this answer?
Consider the grammar
S → (S) | a
Let the number of states in SLR(1), LR(1) and LALR(1) parsers for the grammar be n1, n2 and n3 respectively. The following relationship holds good
a)
n1 < n2 < n3
b)
n1 = n3 < n2
c)
n1 = n2 = n3
d)
n1 ≥ n3 ≥ n2
|
|
Madhurima Chakraborty answered |
LALR(1) is formed by merging states of LR(1) (also called CLR(1)), hence no of states in LALR(1) is less than no of states in LR(1), therefore n3 < n2. And SLR(1) and LALR(1) have same no of states, i.e (n1 = n3).
Hence n1 = n3 < n2
Consider the following issues:
1. Simplify the phases.
2. Compiler efficiency is improved.
3. Compiler works faster.
4. Compiler portability is enhanced.Which is/are true in context of lexical analysis?- a)1,2 and 3
- b)1,3 and 4
- c)1,2 and 4
- d)All of these
Correct answer is option 'C'. Can you explain this answer?
Consider the following issues:
1. Simplify the phases.
2. Compiler efficiency is improved.
3. Compiler works faster.
4. Compiler portability is enhanced.
1. Simplify the phases.
2. Compiler efficiency is improved.
3. Compiler works faster.
4. Compiler portability is enhanced.
Which is/are true in context of lexical analysis?
a)
1,2 and 3
b)
1,3 and 4
c)
1,2 and 4
d)
All of these
|
|
Pranjal Sen answered |
Lexical Analysis
Lexical analysis is the first phase of a compiler, where the source code is analyzed and divided into a sequence of lexemes or tokens. These tokens are then used by the subsequent phases of the compiler for further processing. The main objective of lexical analysis is to simplify the code and make it easier for the compiler to understand and process.
Issues related to Lexical Analysis
1. Simplify the phases: This issue refers to simplifying the overall compilation process by dividing it into smaller and more manageable phases. By simplifying the phases, the compiler becomes more modular and easier to implement and maintain.
2. Compiler efficiency is improved: Improving compiler efficiency involves optimizing the lexical analysis phase to minimize the time and resources required for tokenizing the source code. This can be achieved by using efficient algorithms and data structures for token recognition and processing.
3. Compiler works faster: Making the compiler faster is a desirable goal as it reduces the overall compilation time. By improving the speed of the lexical analysis phase, the compiler can process the source code more quickly and provide faster feedback to the programmer.
4. Compiler portability is enhanced: Enhancing compiler portability involves making the compiler compatible with different platforms and operating systems. By improving the portability of the lexical analysis phase, the compiler can be easily adapted to different environments without significant changes to the code.
True statements in context of lexical analysis
From the given options, the following statements are true in the context of lexical analysis:
1. Simplify the phases: Simplifying the phases helps in making the compiler more modular and easier to implement and maintain. It breaks down the compilation process into smaller, manageable steps.
2. Compiler efficiency is improved: Improving the efficiency of the lexical analysis phase helps in optimizing the tokenization process, resulting in faster and more accurate parsing of the source code.
4. Compiler portability is enhanced: Enhancing the portability of the lexical analysis phase ensures that the compiler can be easily adapted to different platforms and operating systems without significant modifications.
Therefore, the correct answer is option 'C' - 1, 2, and 4.
Lexical analysis is the first phase of a compiler, where the source code is analyzed and divided into a sequence of lexemes or tokens. These tokens are then used by the subsequent phases of the compiler for further processing. The main objective of lexical analysis is to simplify the code and make it easier for the compiler to understand and process.
Issues related to Lexical Analysis
1. Simplify the phases: This issue refers to simplifying the overall compilation process by dividing it into smaller and more manageable phases. By simplifying the phases, the compiler becomes more modular and easier to implement and maintain.
2. Compiler efficiency is improved: Improving compiler efficiency involves optimizing the lexical analysis phase to minimize the time and resources required for tokenizing the source code. This can be achieved by using efficient algorithms and data structures for token recognition and processing.
3. Compiler works faster: Making the compiler faster is a desirable goal as it reduces the overall compilation time. By improving the speed of the lexical analysis phase, the compiler can process the source code more quickly and provide faster feedback to the programmer.
4. Compiler portability is enhanced: Enhancing compiler portability involves making the compiler compatible with different platforms and operating systems. By improving the portability of the lexical analysis phase, the compiler can be easily adapted to different environments without significant changes to the code.
True statements in context of lexical analysis
From the given options, the following statements are true in the context of lexical analysis:
1. Simplify the phases: Simplifying the phases helps in making the compiler more modular and easier to implement and maintain. It breaks down the compilation process into smaller, manageable steps.
2. Compiler efficiency is improved: Improving the efficiency of the lexical analysis phase helps in optimizing the tokenization process, resulting in faster and more accurate parsing of the source code.
4. Compiler portability is enhanced: Enhancing the portability of the lexical analysis phase ensures that the compiler can be easily adapted to different platforms and operating systems without significant modifications.
Therefore, the correct answer is option 'C' - 1, 2, and 4.
Consider the following grammar.S -> S * E
S -> E
E -> F + E
E -> F
F -> idConsider the following LR(0) items corresponding to the grammar above.(i) S -> S * .E
(ii) E -> F. + E
(iii) E -> F + .E Q. Given the items above, which two of them will appear in the same set in the canonical sets-of-items for the grammar?- a)(i) and (ii)
- b)(ii) and (iii)
- c)(i) and (iii)
- d)None of the above
Correct answer is option 'D'. Can you explain this answer?
Consider the following grammar.
S -> S * E
S -> E
E -> F + E
E -> F
F -> id
S -> E
E -> F + E
E -> F
F -> id
Consider the following LR(0) items corresponding to the grammar above.
(i) S -> S * .E
(ii) E -> F. + E
(iii) E -> F + .E
(ii) E -> F. + E
(iii) E -> F + .E
Q. Given the items above, which two of them will appear in the same set in the canonical sets-of-items for the grammar?
a)
(i) and (ii)
b)
(ii) and (iii)
c)
(i) and (iii)
d)
None of the above
|
|
Yashvi Das answered |
Let's make the LR(0) set of items. First we need to augment the grammar with the production rule S' -> .S , then we need to find closure of items in a set to complete a set. Below are the LR(0) sets of items.
A canonical set of items is given belowS --> L. > R
Q --> R.On input symbol < the set has- a)a shift-reduce conflict and a reduce-reduce conflict.
- b)a shift-reduce conflict but not a reduce-reduce conflict.
- c)a reduce-reduce conflict but not a shift-reduce conflict.
- d)neither a shift-reduce nor a reduce-reduce conflict
Correct answer is option 'D'. Can you explain this answer?
A canonical set of items is given below
S --> L. > R
Q --> R.
Q --> R.
On input symbol < the set has
a)
a shift-reduce conflict and a reduce-reduce conflict.
b)
a shift-reduce conflict but not a reduce-reduce conflict.
c)
a reduce-reduce conflict but not a shift-reduce conflict.
d)
neither a shift-reduce nor a reduce-reduce conflict
|
|
Ipsita Dasgupta answered |
The question is asked with respect to the symbol ' < ' which is not present in the given canonical set of items. Hence it is neither a shift-reduce conflict nor a reduce-reduce conflict on symbol '<'. Hence D is the correct option. But if the question would have asked with respect to the symbol ' > ' then it would have been a shift-reduce conflict.
in a context-free grammar- a)∈ can’t be the right hand side of any production.
- b)Terminal symbols can’t be present in the left hand side of any production.
- c)The number of grammar symbols in the left hand side is not greater than that of in the right hand side.
- d)All of the above
Correct answer is option 'B'. Can you explain this answer?
in a context-free grammar
a)
∈ can’t be the right hand side of any production.
b)
Terminal symbols can’t be present in the left hand side of any production.
c)
The number of grammar symbols in the left hand side is not greater than that of in the right hand side.
d)
All of the above
|
|
Shruti Basak answered |
A context-free grammar is a formal grammar that consists of a set of production rules, where each rule defines how to rewrite a nonterminal symbol into a sequence of terminal and/or nonterminal symbols. The rules are applied in any context and do not depend on the surrounding symbols or context.
Context-free grammars are commonly used to describe the syntax of programming languages, natural languages, and other formal languages. They provide a concise and systematic way to generate valid sentences or expressions in these languages.
For example, consider a simple context-free grammar that describes the syntax of arithmetic expressions:
1. S -> E
2. E -> E + T
3. E -> E - T
4. E -> T
5. T -> T * F
6. T -> T / F
7. T -> F
8. F -> (E)
9. F -> num
In this grammar, S is the start symbol, and the rules define how to rewrite nonterminal symbols (S, E, T, F) into sequences of terminal symbols (num, +, -, *, /, (, )). The rules specify the various ways to combine numbers and arithmetic operators to form valid arithmetic expressions.
For example, using this grammar, the expression "2 + 3 * (4 - 1)" can be generated as follows:
S -> E (by applying rule 1)
E -> E + T (by applying rule 2)
E -> T + T (by applying rule 4)
T -> F + T (by applying rule 7)
F -> num + T (by applying rule 9)
F -> 2 + T (by applying rule 9)
F -> 2 + T * F (by applying rule 5)
F -> 2 + F * F (by applying rule 7)
F -> 2 + (E) * F (by applying rule 8)
F -> 2 + (E) * (E) (by applying rule 4)
F -> 2 + (T) * (E) (by applying rule 7)
F -> 2 + (F) * (E) (by applying rule 8)
F -> 2 + (4) * (E) (by applying rule 9)
F -> 2 + (4) * (T) (by applying rule 7)
F -> 2 + (4) * (F) (by applying rule 8)
F -> 2 + (4) * (1) (by applying rule 9)
This sequence of rule applications generates the desired arithmetic expression.
Context-free grammars are commonly used to describe the syntax of programming languages, natural languages, and other formal languages. They provide a concise and systematic way to generate valid sentences or expressions in these languages.
For example, consider a simple context-free grammar that describes the syntax of arithmetic expressions:
1. S -> E
2. E -> E + T
3. E -> E - T
4. E -> T
5. T -> T * F
6. T -> T / F
7. T -> F
8. F -> (E)
9. F -> num
In this grammar, S is the start symbol, and the rules define how to rewrite nonterminal symbols (S, E, T, F) into sequences of terminal symbols (num, +, -, *, /, (, )). The rules specify the various ways to combine numbers and arithmetic operators to form valid arithmetic expressions.
For example, using this grammar, the expression "2 + 3 * (4 - 1)" can be generated as follows:
S -> E (by applying rule 1)
E -> E + T (by applying rule 2)
E -> T + T (by applying rule 4)
T -> F + T (by applying rule 7)
F -> num + T (by applying rule 9)
F -> 2 + T (by applying rule 9)
F -> 2 + T * F (by applying rule 5)
F -> 2 + F * F (by applying rule 7)
F -> 2 + (E) * F (by applying rule 8)
F -> 2 + (E) * (E) (by applying rule 4)
F -> 2 + (T) * (E) (by applying rule 7)
F -> 2 + (F) * (E) (by applying rule 8)
F -> 2 + (4) * (E) (by applying rule 9)
F -> 2 + (4) * (T) (by applying rule 7)
F -> 2 + (4) * (F) (by applying rule 8)
F -> 2 + (4) * (1) (by applying rule 9)
This sequence of rule applications generates the desired arithmetic expression.
For the grammar below, a partial LL(1) parsing table is also presented along with the grammar. Entries that need to be filled are indicated as E1, E2, and E3.  is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions.
is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions.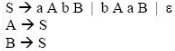
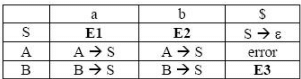 Q.The appropriate entries for E1, E2, and E3 are
Q.The appropriate entries for E1, E2, and E3 are- a)
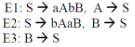
- b)
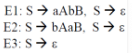
- c)
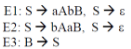
- d)

Correct answer is option 'C'. Can you explain this answer?
For the grammar below, a partial LL(1) parsing table is also presented along with the grammar. Entries that need to be filled are indicated as E1, E2, and E3. is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions.
is the empty string, $ indicates end of input, and, | separates alternate right hand sides of productions.Q.
The appropriate entries for E1, E2, and E3 are
a)
b)
c)
d)
|
|
Diya Kumar answered |
As we need to find entries E1, E2 and E3 which are against Non terminals S and B, so we will deal with only those productions which have S and B on LHS. Here representing the parsing table as M[X , Y], where X represents rows( Non terminals) and Y represents columns(terminals).
Rule 1: if P --> Q is a production, for each terminal 't' in FIRST(Q) add P-->Q to M [ P , t ]
Rule 2 : if epsilon is in FIRST(Q), add P --> Q to M [P , f] for each f in FOLLOW(P).
Rule 2 : if epsilon is in FIRST(Q), add P --> Q to M [P , f] for each f in FOLLOW(P).
For the production rule S--> aAbB, it will be added to parsing table at the position M[ S , FIRST(aAbB)], Now FIRST(aAbB) = {a}, hence add S--> aAbB to M[S , a] which is E1. For the production rule S--> bAaB, it will be added to parsing table at the position M[ S , FIRST(bAaB)], Now FIRST(bAaB) = {b}, hence add S--> bAaB to M[ S , b] which is E2 For the production rule S--> epsilon , it will be added to parsing table at the position M[ S , FOLLOW(S)], Now FOLLOW(S) = {a , b , $}, hence add S --> epsilon to M[ S , a] and M[ S , b] which are again E1 and E2 respectively. For the production rule B --> S, it will be added to parsing table at the position M[ B , FIRST(S)], Now FIRST(S) also contains epsilon, hence add B --> S to M[ S , FOLLOW(B)], and FOLLOW(B) contains {$}, i.e. M[S , $] which is E3. epsilon corresponds to empty string.
Consider an ambiguous grammar G and its disambiguated version D. Let the language recognized by the two grammars be denoted by L(G) and L(D) respectively. Which one of the following is true?- a)L (D) ⊂ L (G)
- b)L (D) ⊃ L (G)
- c)L (D) = L (G)
- d)L (D) is empty
Correct answer is option 'C'. Can you explain this answer?
Consider an ambiguous grammar G and its disambiguated version D. Let the language recognized by the two grammars be denoted by L(G) and L(D) respectively. Which one of the following is true?
a)
L (D) ⊂ L (G)
b)
L (D) ⊃ L (G)
c)
L (D) = L (G)
d)
L (D) is empty
|
|
Nandini Khanna answered |
L (D) = L (G) , Both must represent same language .Also if we are converting a grammar from Ambiguous to UnAmbiguous form , we must ensure that our new new grammar represents the same language as previous grammar.
For ex G1: S->Sa/aS/a; {Ambiguous (2 parse trees for string 'aa')}
G1':S->aS/a;{Unambiguous}
Both represents language represented by regular expression: a^+
Consider the grammar rule E → E1 – E2 for arithmetic expressions. The code generated is targeted to a CPU having a single user register. The subtraction operation requires the first operand to be in the register. If E1 and E2 do not have any common sub expression, in order to get the shortest possible code- a)E1 should be evaluated first
- b)E2 should be evaluated first
- c)Evaluation of E1 and E2 should necessarily be interleaved
- d)Order of evaluation of E1 and E2 is of no consequence
Correct answer is option 'B'. Can you explain this answer?
Consider the grammar rule E → E1 – E2 for arithmetic expressions. The code generated is targeted to a CPU having a single user register. The subtraction operation requires the first operand to be in the register. If E1 and E2 do not have any common sub expression, in order to get the shortest possible code
a)
E1 should be evaluated first
b)
E2 should be evaluated first
c)
Evaluation of E1 and E2 should necessarily be interleaved
d)
Order of evaluation of E1 and E2 is of no consequence
|
|
Nitin Mukherjee answered |
E2 should be evaluated first
After evaluating E2 first and then E1, we will have E1 in the register and thus we can simply do SUB operation with E2 which will be in memory (as we have only a single register). If we do E1 first and then E2, we must move E2 to memory and E1 back to register before doing SUB, which will increase the code size.
Generation of intermediate code based on an abstract machine model is useful in compilers because- a)It makes implementation of lexical analysis and syntax analysis easier.
- b)Syntax-directed translations can be written for intermediate code generation.
- c)It enhances the portability of the front end of the compiler.
- d)It is not possible to generate code for real machines directly from high level language programs
Correct answer is option 'C'. Can you explain this answer?
Generation of intermediate code based on an abstract machine model is useful in compilers because
a)
It makes implementation of lexical analysis and syntax analysis easier.
b)
Syntax-directed translations can be written for intermediate code generation.
c)
It enhances the portability of the front end of the compiler.
d)
It is not possible to generate code for real machines directly from high level language programs
|
|
Shubham Chawla answered |
Explanation:
Intermediate code is code that is generated by a compiler between the source code and the target code. It is an abstraction of the target machine's code and is used to make it easier to translate the source code into machine code. The intermediate code is generally optimized and platform-independent, which makes it easier to port the compiler front end to different platforms.
The use of an abstract machine model in the generation of intermediate code has several advantages:
1. Easier implementation of lexical analysis and syntax analysis: The abstract machine model provides a simplified representation of the target machine's instruction set, making the implementation of the lexical and syntax analysis stages of the compiler easier.
2. Syntax-directed translations: Intermediate code generation can be done using syntax-directed translation techniques, which facilitates the construction of compilers.
3. Enhanced portability: The use of intermediate code makes it easier to port the front end of the compiler to different platforms. Since the intermediate code is platform-independent, only the back end of the compiler needs to be modified to generate code for different target machines.
4. Direct generation of code for real machines: Although it is possible to generate code for real machines directly from high-level language programs, the use of an abstract machine model provides a layer of abstraction that makes the process easier and more efficient.
Therefore, option C is the correct answer.
Intermediate code is code that is generated by a compiler between the source code and the target code. It is an abstraction of the target machine's code and is used to make it easier to translate the source code into machine code. The intermediate code is generally optimized and platform-independent, which makes it easier to port the compiler front end to different platforms.
The use of an abstract machine model in the generation of intermediate code has several advantages:
1. Easier implementation of lexical analysis and syntax analysis: The abstract machine model provides a simplified representation of the target machine's instruction set, making the implementation of the lexical and syntax analysis stages of the compiler easier.
2. Syntax-directed translations: Intermediate code generation can be done using syntax-directed translation techniques, which facilitates the construction of compilers.
3. Enhanced portability: The use of intermediate code makes it easier to port the front end of the compiler to different platforms. Since the intermediate code is platform-independent, only the back end of the compiler needs to be modified to generate code for different target machines.
4. Direct generation of code for real machines: Although it is possible to generate code for real machines directly from high-level language programs, the use of an abstract machine model provides a layer of abstraction that makes the process easier and more efficient.
Therefore, option C is the correct answer.
A non relocatable program is one which- a)Cannot be made to execute in any area of storage other than the one designated for it at the time of its coding or translation.
- b)Consists of a program and relevant information for its relocation.
- c)Can itself perform the relocation of its address sensitive portions.
- d)All of the above
Correct answer is option 'A'. Can you explain this answer?
A non relocatable program is one which
a)
Cannot be made to execute in any area of storage other than the one designated for it at the time of its coding or translation.
b)
Consists of a program and relevant information for its relocation.
c)
Can itself perform the relocation of its address sensitive portions.
d)
All of the above
|
|
Gargi Menon answered |
The phases of compiler
1. Lexical
2. Syntax
3. Semantic
4. Intermediate code generation, are all machine dependent phases and are not relocatable.
The together make pass-1 of the compiler. This program hence can not be made to execute in any area of storage other than the one designated for it at the time of its coding or translation.
1. Lexical
2. Syntax
3. Semantic
4. Intermediate code generation, are all machine dependent phases and are not relocatable.
The together make pass-1 of the compiler. This program hence can not be made to execute in any area of storage other than the one designated for it at the time of its coding or translation.
Consider the following expression grammar. The semantic rules for expression calculation are stated next to each grammar production.E → number E.val = number. val
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val Q. The above grammar and the semantic rules are fed to a yacc tool (which is an LALR (1) parser generator) for parsing and evaluating arithmetic expressions. Which one of the following is true about the action of yacc for the given grammar?- a)It detects recursion and eliminates recursion
- b)It detects reduce-reduce conflict, and resolves
- c)It detects shift-reduce conflict, and resolves the conflict in favor of a shift over a reduce action
- d)It detects shift-reduce conflict, and resolves the conflict in favor of a reduce over a shift action
Correct answer is option 'C'. Can you explain this answer?
Consider the following expression grammar. The semantic rules for expression calculation are stated next to each grammar production.
E → number E.val = number. val
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val
| E '+' E E(1).val = E(2).val + E(3).val
| E '×' E E(1).val = E(2).val × E(3).val
Q. The above grammar and the semantic rules are fed to a yacc tool (which is an LALR (1) parser generator) for parsing and evaluating arithmetic expressions. Which one of the following is true about the action of yacc for the given grammar?
a)
It detects recursion and eliminates recursion
b)
It detects reduce-reduce conflict, and resolves
c)
It detects shift-reduce conflict, and resolves the conflict in favor of a shift over a reduce action
d)
It detects shift-reduce conflict, and resolves the conflict in favor of a reduce over a shift action

|
Shivam Sharma answered |
E→ number |E '+'E|E'x' E
Shift reduce conflict and resolves the conflict in favor of a shift over a reduce action.
Consider the following configuration where shift-reduce conflict occurs.
Stack Input ...
E+Ex E..$
To evaluate an expression without any embedded function calls- a)One stack is enough
- b)Two stacks are needed
- c)As many stacks as the height of the expression tree are needed
- d)A Turing machine is needed in the general case
Correct answer is option 'A'. Can you explain this answer?
To evaluate an expression without any embedded function calls
a)
One stack is enough
b)
Two stacks are needed
c)
As many stacks as the height of the expression tree are needed
d)
A Turing machine is needed in the general case

|
Anirban Khanna answered |
Any expression can be converted into Postfix or Prefix form.
Prefix and postfix evaluation can be done using a single stack.
For example : Expression ’10 2 8 * + 3 -‘ is given.
PUSH 10 in the stack.
PUSH 2 in the stack.
PUSH 8 in the stack.
When operator ‘*’ occurs, POP 2 and 8 from the stack.
PUSH 2 * 8 = 16 in the stack.
When operator ‘+’ occurs, POP 16 and 10 from the stack.
PUSH 10 * 16 = 26 in the stack.
PUSH 3 in the stack.
When operator ‘-‘ occurs, POP 26 and 3 from the stack.
PUSH 26 – 3 = 23 in the stack.
So, 23 is the answer obtained using single stack.
Thus, option (A) is correct.
In a two pass assembler pseudo code EQU is to be evaluated during- a)Pass 1
- b)Pass 2
- c)Not evaluated by the assembler
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
In a two pass assembler pseudo code EQU is to be evaluated during
a)
Pass 1
b)
Pass 2
c)
Not evaluated by the assembler
d)
None of the above
|
|
Jay Basu answered |
In 2-pass assembler during pass-1 pseudo code EQU is to be evaluated.
Some code optimizations are carried out on the intermediate code because- a)They enhance the portability of the compiler to other target processors.
- b)Program analysis is more accurate on intermediate code than on machine code.
- c)The information from data flow analysis cannot otherwise be used for optimization.
- d)The information from the front end cannot otherwise be used for optimization.
Correct answer is option 'B'. Can you explain this answer?
Some code optimizations are carried out on the intermediate code because
a)
They enhance the portability of the compiler to other target processors.
b)
Program analysis is more accurate on intermediate code than on machine code.
c)
The information from data flow analysis cannot otherwise be used for optimization.
d)
The information from the front end cannot otherwise be used for optimization.
|
|
Samarth Kapoor answered |
Some code optimizations are carried out on the intermediate code because program analysis is more accurate on intermediate code than on machine code.
Which one of the following is a top-down parser?- a)Recursive descent parser.
- b)Operator precedence parser.
- c)An LR(k) parser.
- d)An LALR(k) parser
Correct answer is option 'A'. Can you explain this answer?
Which one of the following is a top-down parser?
a)
Recursive descent parser.
b)
Operator precedence parser.
c)
An LR(k) parser.
d)
An LALR(k) parser
|
|
Shubham Ghoshal answered |
Recursive Descent parsing is LL(1) parsing which is top down parsing.
A compiler is- a)A program that places programs into memory and prepares them for execution.
- b)A program that automates the translation of assembly language into machine language.
- c)Program that accepts a program written in a high level language and produces an object program.
- d)A program that appears to execute a source program as if it were machine language.
Correct answer is option 'C'. Can you explain this answer?
A compiler is
a)
A program that places programs into memory and prepares them for execution.
b)
A program that automates the translation of assembly language into machine language.
c)
Program that accepts a program written in a high level language and produces an object program.
d)
A program that appears to execute a source program as if it were machine language.
|
|
Pritam Chatterjee answered |
A compiler is a software program that transforms high-level source code that is written by a developer in a high-level programming language into a low level object code (binary code) in machine language, which can be understood by the processor. The process of converting high-level programming into machine language is known as compilation.
The processor executes object code, which indicates when binary high and low signals are required in the arithmetic logic unit of the processor.
A linker is given object modules for a set of programs that were compiled separately. What information need to be included in an object module?- a)Object code
- b)Relocation bits
- c)Names and locations of all external symbols defined in the object module
- d)Absolute addresses of internal symbols
Correct answer is option 'C'. Can you explain this answer?
A linker is given object modules for a set of programs that were compiled separately. What information need to be included in an object module?
a)
Object code
b)
Relocation bits
c)
Names and locations of all external symbols defined in the object module
d)
Absolute addresses of internal symbols
|
|
Ameya Basak answered |
(c) is the answer. For linker to link external symbols (for example in C, to link an extern variable in one module to a global variable in another module), it must know the location of all external symbols. In C external symbols includes all global variables and function names.
(a) is trivially there is an object module. (b) must be there if we need to have relocation capability.
(a) is trivially there is an object module. (b) must be there if we need to have relocation capability.
A pictorial representation of the value computed by each statement in the basic block is- a)Tree
- b)DAG
- c)Graph
- d)None of these
Correct answer is option 'C'. Can you explain this answer?
A pictorial representation of the value computed by each statement in the basic block is
a)
Tree
b)
DAG
c)
Graph
d)
None of these
|
|
Krithika Kaur answered |
A pictorial representation of the value computed by. each statement in the basic block is control flow graph.
In the context of abstract-syntax-tree (AST) and control-flow-graph (CFG), which one of the following is True?- a)In both AST and CFG, let node N2 be the successor of node N1. In the input program, the code corresponding to N2 is present after the code corresponding to N1
- b)For any input program, neither AST nor CFG will contain a cycle
- c)The maximum number of successors of a node in an AST and a CFG depends on the input program
- d)Each node in AST and CFG corresponds to at most one statement in the input program
Correct answer is option 'C'. Can you explain this answer?
In the context of abstract-syntax-tree (AST) and control-flow-graph (CFG), which one of the following is True?
a)
In both AST and CFG, let node N2 be the successor of node N1. In the input program, the code corresponding to N2 is present after the code corresponding to N1
b)
For any input program, neither AST nor CFG will contain a cycle
c)
The maximum number of successors of a node in an AST and a CFG depends on the input program
d)
Each node in AST and CFG corresponds to at most one statement in the input program
|
|
Ishaan Saini answered |
(A) is false, In CFG (Control Flow Graph), code of N2 may be present before N1 when there is a loop or goto.
(B) is false, CFG (Control Flow Graph) contains cycle when input program has loop.
(C) is true, successors in AST and CFG depedend on input program
(D) is false, a single statement may belong to a block of statements.
(B) is false, CFG (Control Flow Graph) contains cycle when input program has loop.
(C) is true, successors in AST and CFG depedend on input program
(D) is false, a single statement may belong to a block of statements.
Consider the following code segment.x = u - t;y = x * v;x = y + w;y = t - z;y = x * y;The minimum number of total variables required to convert the above code segment to static single assignment form is __________.
Correct answer is '10'. Can you explain this answer?
Consider the following code segment.
x = u - t;
y = x * v;
x = y + w;
y = t - z;
y = x * y;
The minimum number of total variables required to convert the above code segment to static single assignment form is __________.
|
|
Madhurima Mukherjee answered |
Static Single Assignment (SSA) form:
Static Single Assignment (SSA) form is a property of an intermediate representation (IR) in compilers where each variable is assigned only once and is defined before its use. In SSA form, each assignment creates a new variable, which ensures that there is no variable reassignment.
Given code segment:
x = u - t;
y = x * v;
x = y + w;
y = t - z;
y = x * y;
Converting to SSA form:
To convert the given code segment to SSA form, we need to create new variables for each assignment. Let's go step by step:
1. x = u - t;
- In SSA form, we create a new variable for x: x1 = u - t;
2. y = x * v;
- In SSA form, we create a new variable for y: y1 = x1 * v;
3. x = y + w;
- In SSA form, we create a new variable for x: x2 = y1 + w;
4. y = t - z;
- In SSA form, we create a new variable for y: y2 = t - z;
5. y = x * y;
- In SSA form, we create a new variable for y: y3 = x2 * y2;
Variables required:
To convert the given code segment to SSA form, we need to create new variables for each assignment. The minimum number of total variables required is 10, including the original variables and the new variables created in SSA form.
Original variables:
- u
- t
- v
- w
- z
New variables created in SSA form:
- x1
- y1
- x2
- y2
- y3
Total variables required = 5 (original variables) + 5 (new variables) = 10
Therefore, the minimum number of total variables required to convert the given code segment to SSA form is 10.
Static Single Assignment (SSA) form is a property of an intermediate representation (IR) in compilers where each variable is assigned only once and is defined before its use. In SSA form, each assignment creates a new variable, which ensures that there is no variable reassignment.
Given code segment:
x = u - t;
y = x * v;
x = y + w;
y = t - z;
y = x * y;
Converting to SSA form:
To convert the given code segment to SSA form, we need to create new variables for each assignment. Let's go step by step:
1. x = u - t;
- In SSA form, we create a new variable for x: x1 = u - t;
2. y = x * v;
- In SSA form, we create a new variable for y: y1 = x1 * v;
3. x = y + w;
- In SSA form, we create a new variable for x: x2 = y1 + w;
4. y = t - z;
- In SSA form, we create a new variable for y: y2 = t - z;
5. y = x * y;
- In SSA form, we create a new variable for y: y3 = x2 * y2;
Variables required:
To convert the given code segment to SSA form, we need to create new variables for each assignment. The minimum number of total variables required is 10, including the original variables and the new variables created in SSA form.
Original variables:
- u
- t
- v
- w
- z
New variables created in SSA form:
- x1
- y1
- x2
- y2
- y3
Total variables required = 5 (original variables) + 5 (new variables) = 10
Therefore, the minimum number of total variables required to convert the given code segment to SSA form is 10.
Consider the following two sets of LR(1) items of an LR(1) grammar.
X -> c.X, c/d
X -> .cX, c/d
X -> .d, c/d
X -> c.X, $
X -> .cX, $
X -> .d, $Q. Which of the following statements related to merging of the two sets in the corresponding LALR parser is/are FALSE?1. Cannot be merged since look aheads are different.
2. Can be merged but will result in S-R conflict.
3. Can be merged but will result in R-R conflict.
4. Cannot be merged since goto on c will lead to two different sets.- a)1 only
- b)2 only
- c)1 and 4 only
- d)1, 2, 3, and 4
Correct answer is option 'D'. Can you explain this answer?
Consider the following two sets of LR(1) items of an LR(1) grammar.
X -> c.X, c/d
X -> .cX, c/d
X -> .d, c/d
X -> c.X, $
X -> .cX, $
X -> .d, $
X -> c.X, c/d
X -> .cX, c/d
X -> .d, c/d
X -> c.X, $
X -> .cX, $
X -> .d, $
Q. Which of the following statements related to merging of the two sets in the corresponding LALR parser is/are FALSE?
1. Cannot be merged since look aheads are different.
2. Can be merged but will result in S-R conflict.
3. Can be merged but will result in R-R conflict.
4. Cannot be merged since goto on c will lead to two different sets.
2. Can be merged but will result in S-R conflict.
3. Can be merged but will result in R-R conflict.
4. Cannot be merged since goto on c will lead to two different sets.
a)
1 only
b)
2 only
c)
1 and 4 only
d)
1, 2, 3, and 4
|
|
Pritam Chatterjee answered |
The given two LR(1) set of items are :
X -> c.X, c/d
X -> .cX, c/d
X -> .d, c/d
and
X -> c.X, $
X -> .cX, $
X -> .d, $
X -> c.X, c/d
X -> .cX, c/d
X -> .d, c/d
and
X -> c.X, $
X -> .cX, $
X -> .d, $
The symbols/terminals after the comma are Look-Ahead symbols. These are the sets of LR(1) (LR(1) is also called CLR(1)) items. The LALR(1) parser combines those set of LR(1) items which are identical with respect to their 1st component but different with respect to their 2nd component. In a production rule of a LR(1) set of items, (A -> B , c) , A->B is the 1st component , and the Look-Ahead set of symbols, which is c here, is the second component. Now we can see that in the sets given, 1st component of the corresponding production rule is identical in both sets, and they only differ in 2nd component (i.e. their look-ahead symbols) hence we can combine these sets to make a a single set which would be :
X -> c.X, c/d/$
X -> .cX, c/d/$
X -> .d, c/d/$
X -> .cX, c/d/$
X -> .d, c/d/$
This is done to reduce the total number of parser states. Now we can check the statements given. Statement 1 : The statement is false, as merging has been done because 2nd components i.e. look-ahead were different. Statement 2 : In the merged set, we can't see any Shift-Reduce conflict ( because no reduction even possible, reduction would be possible when a production of form P -> q. is present) Statement 3 : In the merged set, we can't see any Reduce-Reduce conflict ( same reason as above, no reduction even possible, so no chances of R-R conflict ) Statement 4: This statement is also wrong, because goto is carried on Non-Terminals symbols, not on terminal symbols, and c is a terminal symbol. Thus, all statements are wrong, hence option D.
Consider the grammar defined by the following production rules, with two operators ∗ and +S --> T * P
T --> U | T * U
P --> Q + P | Q
Q --> Id
U --> Id Q. Which one of the following is TRUE?- a)+ is left associative, while ∗ is right associative
- b)+ is right associative, while ∗ is left associative
- c)Both + and ∗ are right associative
- d)Both + and ∗ are left associative
Correct answer is option 'B'. Can you explain this answer?
Consider the grammar defined by the following production rules, with two operators ∗ and +
S --> T * P
T --> U | T * U
P --> Q + P | Q
Q --> Id
U --> Id
T --> U | T * U
P --> Q + P | Q
Q --> Id
U --> Id
Q. Which one of the following is TRUE?
a)
+ is left associative, while ∗ is right associative
b)
+ is right associative, while ∗ is left associative
c)
Both + and ∗ are right associative
d)
Both + and ∗ are left associative
|
|
Mrinalini Menon answered |
From the grammar we can find out associative by looking at grammar.
Let us consider the 2nd production T -> T * U
T is generating T*U recursively (left recursive) so * is left associative.
Similarly
P -> Q + P
Right recursion so + is right associative. So option B is correct.
T is generating T*U recursively (left recursive) so * is left associative.
Similarly
P -> Q + P
Right recursion so + is right associative. So option B is correct.
NOTE: Above is the shortcut trick that can be observed after drawing few parse trees. One can also find out correct answer by drawing the parse tree.
DAG representation of a basic block allows- a)Automatic detection of local common subexpressions.
- b)Automatic detection of induction variables.
- c)Automatic detection of loop invariant.
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
DAG representation of a basic block allows
a)
Automatic detection of local common subexpressions.
b)
Automatic detection of induction variables.
c)
Automatic detection of loop invariant.
d)
None of the above
|
|
Athira Reddy answered |
DAG Representation of a Basic Block
DAG (Directed Acyclic Graph) representation of a basic block is a data structure that represents the dependencies between instructions in a basic block. It allows for the automatic detection of local common subexpressions.
1. Automatic Detection of Local Common Subexpressions
- A common subexpression refers to a subexpression that appears multiple times within a basic block.
- By representing the basic block as a DAG, common subexpressions can be easily identified.
- In a DAG, each node represents an expression, and the edges represent the dependencies between expressions.
- If two nodes in the DAG have the same expression, it indicates that there is a common subexpression in the basic block.
- By detecting and eliminating common subexpressions, the compiler can optimize the code by reducing redundant computations.
- This optimization technique is known as common subexpression elimination (CSE).
2. Benefits of Automatic Detection of Local Common Subexpressions
- Reduces the number of computations, improving the performance of the code.
- Improves code readability and maintainability by eliminating redundant code.
- Helps in reducing the register pressure by reusing the results of common subexpressions.
3. Automatic Detection of Induction Variables and Loop Invariants
- While DAG representation of a basic block can help with common subexpression elimination, it does not directly enable automatic detection of induction variables or loop invariants.
- Induction variables and loop invariants are specific to loops and require additional analysis beyond the basic block level.
- Automatic detection of induction variables involves identifying variables that change in a predictable manner within a loop.
- Automatic detection of loop invariants involves identifying expressions that do not change within a loop.
- These optimizations are typically performed using loop analysis techniques such as loop invariant code motion and induction variable analysis.
Conclusion
The DAG representation of a basic block allows for the automatic detection of local common subexpressions. It enables the compiler to identify and eliminate redundant computations, resulting in improved code performance and maintainability. However, it does not directly enable the automatic detection of induction variables or loop invariants, which require additional loop-level analysis techniques.
DAG (Directed Acyclic Graph) representation of a basic block is a data structure that represents the dependencies between instructions in a basic block. It allows for the automatic detection of local common subexpressions.
1. Automatic Detection of Local Common Subexpressions
- A common subexpression refers to a subexpression that appears multiple times within a basic block.
- By representing the basic block as a DAG, common subexpressions can be easily identified.
- In a DAG, each node represents an expression, and the edges represent the dependencies between expressions.
- If two nodes in the DAG have the same expression, it indicates that there is a common subexpression in the basic block.
- By detecting and eliminating common subexpressions, the compiler can optimize the code by reducing redundant computations.
- This optimization technique is known as common subexpression elimination (CSE).
2. Benefits of Automatic Detection of Local Common Subexpressions
- Reduces the number of computations, improving the performance of the code.
- Improves code readability and maintainability by eliminating redundant code.
- Helps in reducing the register pressure by reusing the results of common subexpressions.
3. Automatic Detection of Induction Variables and Loop Invariants
- While DAG representation of a basic block can help with common subexpression elimination, it does not directly enable automatic detection of induction variables or loop invariants.
- Induction variables and loop invariants are specific to loops and require additional analysis beyond the basic block level.
- Automatic detection of induction variables involves identifying variables that change in a predictable manner within a loop.
- Automatic detection of loop invariants involves identifying expressions that do not change within a loop.
- These optimizations are typically performed using loop analysis techniques such as loop invariant code motion and induction variable analysis.
Conclusion
The DAG representation of a basic block allows for the automatic detection of local common subexpressions. It enables the compiler to identify and eliminate redundant computations, resulting in improved code performance and maintainability. However, it does not directly enable the automatic detection of induction variables or loop invariants, which require additional loop-level analysis techniques.
Consider the translation scheme shown belowS → T R
R → + T {print ('+');} R | ε
T → num {print (num.val);}Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string '9 + 5 + 2', this translation scheme will print- a)9 + 5 + 2
- b)9 5 + 2 +
- c)9 5 2 + +
- d)+ + 9 5 2
Correct answer is option 'B'. Can you explain this answer?
Consider the translation scheme shown below
S → T R
R → + T {print ('+');} R | ε
T → num {print (num.val);}
R → + T {print ('+');} R | ε
T → num {print (num.val);}
Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string '9 + 5 + 2', this translation scheme will print
a)
9 + 5 + 2
b)
9 5 + 2 +
c)
9 5 2 + +
d)
+ + 9 5 2
|
|
Aniket Kulkarni answered |
Let us make the parse tree for 9+5+2 in top down manner, left first derivation.
Steps:
1) Exapnd S->TR
2) apply T->Num...
3) apply R -> +T...
4) appy T->Num...
5) apply R-> +T..
6) apply T-> Num..
7) apply R-> epsilon
1) Exapnd S->TR
2) apply T->Num...
3) apply R -> +T...
4) appy T->Num...
5) apply R-> +T..
6) apply T-> Num..
7) apply R-> epsilon
After printing through the print statement in the parse tree formed you will get the answer as 95+2+
Resolution is externally defined symbols is performed by- a)Linker
- b)Loader
- c)Compiler
- d)Assembler
Correct answer is option 'A'. Can you explain this answer?
Resolution is externally defined symbols is performed by
a)
Linker
b)
Loader
c)
Compiler
d)
Assembler
|
|
Athul Pillai answered |
Resolution is generally done during linking. Hence, linker does this
Chapter doubts & questions for Compiler Design - GATE Computer Science Engineering(CSE) 2026 Mock Test Series 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Compiler Design - GATE Computer Science Engineering(CSE) 2026 Mock Test Series in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up
within 7 days!
within 7 days!
Takes less than 10 seconds to signup