Human Genome Project & DNA Fingerprinting | Science & Technology for UPSC CSE PDF Download

Genomics
Genomics is the study of genomes and genes based on DNA sequencing. Genome is the total gene complement of a haploid set of chromosomes and inherited as a unit from one parent through the gamete. A haploid (such as prokaryotic) cell contains a single genome, a diploid (such as a cell of higher plant or animal) has two genomes, one paternal and other maternal. Additional DNA is also present in mitochondria which is inherited from one’s mother.
Human Genome Project
Genetic make-up of an organism or an individual lies in the DNA sequences. If two individuals differ, then their DNA sequences should also be different, at least at some places. These assumptions led to the quest of finding out the complete DNA sequence of human genome. With the establishment of genetic engineering techniques where it was possible to isolate and clone any piece of DNA and availability of simple and fast techniques for determining DNA sequences, a very ambitious project of sequencing human genome was launched in the year 1990.
Human Genome Project (HGP) was called a mega project. You can imagine the magnitude and the requirements for the project if we simply define the aims of the project as follows : Human genome is said to have approximately 3 × 109 bp, and if the cost of sequencing required is US $ 3 per bp (the estimated cost in the beginning), the total estimated cost of the project would be approximately 9 billion US dollars. Further, if the obtained sequences were to be stored in typed form in books, and if each page of the book contained 1000 letters and each book contained 1000 pages, then 3300 such books would be required to store the information of DNA sequence from a single human cell. HGP was closely associated with the rapid development of a new area in biology called as Bioinformatics.
Goals of HGP
Some of the important goals of HGP are as follows :
(i) Identify all the genes in human DNA.
(ii) Determine the sequences of the 3 billion chemical base pairs that make up human DNA.
(iii) Store this information in databases.
(iv) Improve tools for data analysis.
(v) Transfer related technologie s to other sectors, such as industries.
(vi) Address the ethical, legal, and social issues (ELSI) that may arise from the project.
The project was completed in 2003.
Knowledge about the effects of DNA variations among individuals can lead to revolutionary new ways to diagnose, treat and someday prevent the thousands of disorders that affect human beings. Besides providing clues to understanding human biology, learning about non-human organisms, DNA sequences can lead to an understanding of their natural capabilities that can be applied toward solving challenges in health care, agriculture, energy production, environmental remediation. Many non-human model organisms, such as bacteria, yeast, Caenorhabditis elegans (a free living non-pathogenic nematode), Drosophila (the fruit fly), plants (rice and Arabidopsis), etc., have also been sequenced.
Methodologies
The methods involved two major approaches:
(1) Expressed Sequence Tags ( ESTs ) -Identifying all the genes that expressed as RNA .
(2) Sequence Annotation - The blind approach of s imply sequencing the whole set of genome that contained all the coding and non-coding sequence, and later assigning different regions in the sequence with functions. For sequencing, the total DNA from a cell is isolated and converted into random fragments of relatively smaller sizes (recall DNA is a very long polymer, and there are technical limitations in sequencing very long pieces of DNA) and cloned in suitable host using specialised vectors.
The cloning resulted into amplification of each piece of DNA fragment so, that is subsequently could be sequenced with ease. The commonly used hosts were bacteria and yeast, and the vectors were called as BAC (bacterial artificial chromosome s), and YAC (yeast artificial chromosome s).
The fragments were sequenced using automated DNA sequencers that worked on the principle of a method developed by Frederick Sanger . (Remember, Sanger is also credited for developing method for determination of amino acid sequences in proteins). These sequences were then arranged based on some overlapping regions present in them. This required generation of overlapping fragments for sequencing. Alignment of these sequences was humanly not possible. Therefore, specialised computer based programmes were developed. These sequences were subsequently annotated and were assigned to each chromosome. The sequence of chromosome I was completed only in May 2006 (this was the last of the 24 human chromosomes -22 autosomes and X and Y- to be sequenced). Another challenging task was assigning the genetic and physical maps on the genome. This was generated using information on polymorphism of restriction endonuclease recognition sites, and some repetitive DNA sequences known as microsatellites.
Salient Features of Human Genome
Some of the salient observations drawn from human genome project are as follows :
(i) The human genome contains 3164.7 million nucleotide bases.
(ii) The average gene consists of 3000 bases, but sizes vary greatly, with the largest known human gene being dystrophin at 2.4 million bases.
(iii) The total number of genes is estimated at 30,000-much lower than previous estimates of 80,000 to 1,40,000 genes. Almost all (99.9 per cent) nucleotide bases are exactly the same in all people.
(iv) The functions are unknown for over 50 per cent of discovered genes.
(v) Less than 2 per cent of the genome codes for proteins.
(vi) Repeated sequences make up very large portion of the human genome.
(vii) Repetitive sequences are stretches of DNA sequences that are repeated many times, sometimes hundred to thousand times. They are thought to have no direct coding functions, but they shed light on chromosome structure, dynamics and evolution.
(viii) Chromosome 1 has most genes (2968). and the Y has the fewest (231).
(ix) Scientists have identified about 1.4 million locations where single-base DNA differences (SNPs- single nucleotide polymorphism, pronounced as 'snips') occur in humans, This information promises to revolutionize the processes of finding chromosomal locations for disease-associated sequences and tracing human history.
Organisms | Base pair | Gene No. |
Bateriophage | 10,000 | ------/----- |
Lily | 106 Billion B.P. | |
E.coli | 4.7 million B.P. | 4,000 |
S. cerviceae | 12 Million B.P. | 6,000 |
D. melangaster | 180 Million B.P. | 13,000 |
Caenorhabditis elegans | 97 Million B.P. | 18,000 |
Human | 3 Billion B.P. | 30,000 |
(a) First prokaryotes in which complete genome was sequenced is Haemophilus influenzae.
(b) First Eukaryote in which complete genome was sequenced is Saccharomyces cerviceae (Yeast).
(c) First plant in which complete genome was sequenced is Arabidopsis thaliana (Small mustard plant).
(d) First animal in which complete genome was sequenced is Caenorhabditis elegans (Nematode). – b – globin and insulin gene are less than 10 kilo base pair T.D.F. gene is the smallest gene (14 base pair) and Duchenne muscular Dystrophy gene is made up of 2400 kilo base pair.(Longest gene)
Gene Library (Genomic DNA Library) and Gene Banks
A gene libraryis a collection of many of the desired genes of DNA fragments maintained in clones of bacterial or some other cells. It is prepared by the following method.
DNA fragments containing one or few desired genes are obtained with the help of specific restriction endonucleases.
Each fragment is joined to a suitable vehicle DNA to form recombinant DNAs of different nature. These are then introduced into host (bacterial, yeast, plant or animal) cells. The cells containing recombinant DNAs are allowed to multiply in cultures. This will produce clones of cells where the daughter cells carry the same genes which are identical to those of parent cells. A collection of clones with recombinant
DNA containing desired genes is a gene library. Gene libraries are maintained through special techniques.
A gene bank is a store house of clones of known DNA fragments, genes, gene maps, seeds, spores, frozen sperms or eggs or embryos. These are stored for possible use in genetic engineering and breeding experiments where species have become extinct. The need of gene banks is being increasingly felt as the rate of extinction is increasing day by day. The human genome project is the most remarkable contribution in this field.
AFLP (Amplified Fragment Length Polymorphisms)
This procedure was described by scientist Zabeau & Vos (1993). In this procedure DNA is cut by restriction enzyme then these restricted fragment are amplified by P.C.R. and band pattern of these restricted fragments is visualised after gel electrophoresis.
Procedure (3 steps)
(1) Digestion of total cellular DNA with one or more restriction enzymes.
(2) Selective amplication of some of these fragments by P.C.R. primer.
(3) Electrophoretic separation on gel matrix followed by visualisation of band pattern of these restricted fragment.
RAPD (Random Amplification of Polymorphic DNA)
This is a type of P.C.R. in which random (unknown) DNA fragments are amplified.
Bioinformatics
Definition : Bioinformatics is application of computer technology to the management of biological information.
Computer techniques are used to gather, store, analyze and integrate biological and genetic information which can be applied to gene based drug discovery and development.
Drug design based on bioinformatics Bioinformatics is a new approach for drug designing. In this procedure all the knowledge about the disease is collected, analysed and find out a 'target molecules' that cause the disease. Structure of these molecules is analysed by X-ray or N.M.R. technique, then drugs are developed which can bind and block the activity of these molecules.
Biological data base Biological data base is collection of genomic, proteomic and metabolic data associated with computer software, which include nucleotide sequence of gene or amino acid sequence of protein, information about structure, function, location of genes and protein.
Importance –
(1) Easy asses to the information.
(2) A method for extracting only required information.
DNA Fingerprinting/DNA Typing/DNA Profiling/DNA Test
- It is technique to identify a person on the basis of his/her DNA specificity.
- This technique was invented by sirAlec. Jeffery(1984). In India DNA Finger printing has been started by Dr. V.K. Kashyap & Dr. Lal Ji Singh.
- DNA of human is almost the same for all individuals but very small amount that differs from person to person that forensic scientists analyze to identify people.
These differences are called Polymorphism (many forms) and are the key of DNA typing. Polymorphisms are most useful to forensic scientist. It is consist of variation in the length of DNA at specific loci is called Restricted fragment. It is most important segment for DNA test made up of short repetitive nucleotide sequences, these are called VNTRs (variable number of tandem repeat).
- VNTR's also called mini satellites were discovered by Alec Jeffery. Restricted fragment consist of hyper-variable repeat region of DNA having a basic repeat sequence of 11-60 bp and flanked on both sites by restriction site. The number and position of minisatellites or VNTR in restriction fragment is different for each DNA and length of restricted fragment is depend on number of VNTR.
- Therefore, when the genome of two people are cut using the same restriction enzyme the length of fragments obtained is different for both the people.
- These variations in length of restricted fragment is called RFLP or Restriction fragment length polymorphism.
- Restriction Fragment Length Polymorphism distributed throughout human genomes are useful for DNA Finger printing.
- DNA Fingerprint can be prepared from extremely minute amount of blood, semen, hair bulb or any other cell of the body.
DNA content of 1 - Microgram is sufficient.
Technique of DNA Finger printing involves the following major stpes.
Steps of DNA Fingerprinting
1. Extraction – DNA extracted from the cell by cell lysis. If the content of DNA is limited then DNA can be amplified by Polymerase chain reaction (PCR). This process is amplification.
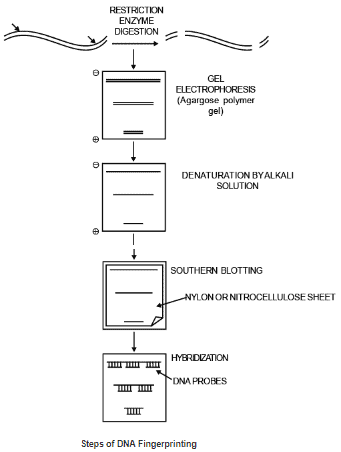
2. Restriction Enzyme Digestion : Restriction enzyme cuts DNA at specific 4 or 6 base pair sequences called restriction site.
Hae III (Haemophilus aegyptius) is most commonly used enzyme. It cuts the DNA, every where the bases are arranged in the sequence GGCC. These restricted fragment transferred to Agarose Polymer gel.
3. Gel Electrophoresis : – Gel electrophoresis is a method that separates macromolecules-either nucleic acid or proteins-on the basis of size, electric charge.
- A gel is a colloid in a solid form. The term electrophoresis describes the migration of charged particles under the influence of an electric field. Electro refers to the energy of electricity. Phoresis, from the Greek verb phoros, means "to carry across." Thus, gel electrophoresis refers to the technique in which molecules are forced across a span of gel, motivated by an electrical current. Activated electrodes at either end of the gel provides the driving force. A molecule's properties determine, how rapidly an electric field can move the molecule through a gelatinous medium.
- Many important biological molecules such as amino acids, peptides, proteins, nucleotides, and nucleic acids posses ionisable groups and, therefore, at any given pH, exist in solution as electrically charged species either as cation (+) or anions (–). Depending on the nature of the net charge, the charged particles will migrate either to the cathode or to the anode. – By the gel electrophoresis these restricted fragments move towards the positive electrode (anode) because DNA has –ve electric charge (PO4–3).
- Smaller Fragment more move towards the positive pole due to less molecular weight. So after the gel electrophoresis DNA fragment arranged according to molecular weight
- These separated fragments can be visualized by staining them with a dye that fluoresces ultraviolet radiation.
- This appears the specific restricted fragment length pattern. This length pattern is different in different individual.
- This is called Restricted Fragment length Polymorphism (RFLP).
4. Southern Transfer / Southern Blotting : The gel is fragile. It is necessary to remove the DNA from the gel and permanently attaches it to a solid support.
This is accomplished by the process of Southern blotting. The first step is to denature the DNA in the gel which means that the double-stranded restriction fragments are chemically separated into the single stranded form.
The DNA then is transferred by the process of blotting to a sheet of nylon. The nylon acts like an ink blotter and "blots" up the separated DNA fragments, the restriction fragments, invisible at this stage are irreversibly attached to the nylon membrane the "blot". This process is called Southern blot by the name of Edward Southern (1970).
5. Hybridization : To detect VNTR locus on restricted fragment, we use single stranded Radioactive (P32) DNA probe which have the base pair sequences complimentary to the DNA sequences at the VNTR locus. Commonly we use a combination of at least 4 to 6 separate DNA probes. Labelled Probes are attached with the VNTR loci of restricted DNA Fragments, this process is called Hybridization.
6. Autoradiography : Nylon membrane containing radio active probe exposed to X-ray. Specific bands appear on X-ray film. These bands are the areas where the radioactive probe bind with the VNTR.
These allow analyzer to identify a particular person DNA, the occurrence and frequency of a particular genetic pattern contained in this X-ray film. These x-ray film called DNA signature of a person which is specific for each individual.
The probability of two unrelated individual having same pattern of location and repeat number of minisatellite (VNTR) is one in ten billion (world population 6.1 billion) In India the centre for DNA finger printing and diagnosis (CDFD - center for DNA finger printing & diagnosis) located at Hyderabad.
Application of DNA Fingerprinting
1. Paternity tests. The major application of DNA finger printing is in determining family relationships. For identifying the true (biological) father, DNA samples of Child, mother and possible fathers are taken and their DNA finger prints are obtained. The prints of child DNA match to the prints of biological parents.
2. Identification of the criminal. DNA finger printing has now become useful technique in forensic (crime detecting) science, specially when serious crimes such as murders and rapes are involved. For identifying a criminal, the DNA fingerprints of the suspects from blood or hair or semen picked up from the scene of crime are prepared and compared. The DNA fingerprint of the person matching the one obtained from sample collected from scene of crime can give a clue to the actual criminal.
Additional Information
Human Genome Project
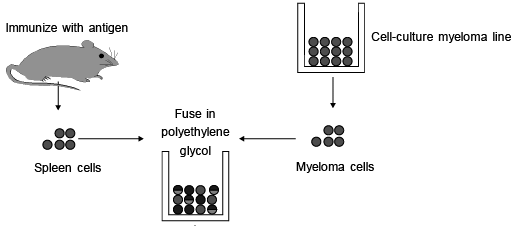
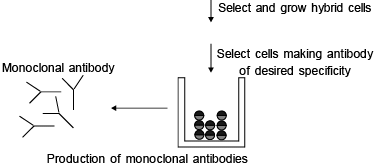
MONOCLONAL ANTIBODY (MAB)– Monoclonal antibodies are specific only for one antigen and synthesize outside the animal body .
– Monoclonal antibody produced by a specialized cells through a technique called as hybridoma technology.
– This technology was discovered by Georges Kohler and Milstein, were awarded with the 1984 nobel prize.
– Each hybrid clone grown in culture medium to produce monoclonal antibody.
– Monoclonal antibody which acts as an enzyme called abzyme.
|
90 videos|491 docs|209 tests
|
FAQs on Human Genome Project & DNA Fingerprinting - Science & Technology for UPSC CSE
| 1. What is genomics and how does it relate to the Human Genome Project? |  |
| 2. What were the goals of the Human Genome Project? | |
| 3. What methodologies were used in the Human Genome Project? | |
| 4. What are the salient features of the Human Genome? | |
| 5. What are gene libraries and gene banks in the context of genomics? | |




Exam
,Human Genome Project & DNA Fingerprinting | Science & Technology for UPSC CSE
,video lectures
,study material
,practice quizzes
,Free
,MCQs
,Summary
,Previous Year Questions with Solutions
,Human Genome Project & DNA Fingerprinting | Science & Technology for UPSC CSE
,shortcuts and tricks
,Objective type Questions
,mock tests for examination
,Viva Questions
,past year papers
,Sample Paper
,ppt
,Extra Questions
,Important questions
,Human Genome Project & DNA Fingerprinting | Science & Technology for UPSC CSE
,Semester Notes
;


Human Genome Project & DNA Fingerprinting Free PDF Download
Importance of Human Genome Project & DNA Fingerprinting
Human Genome Project & DNA Fingerprinting Notes
Human Genome Project & DNA Fingerprinting UPSC Questions
Study Human Genome Project & DNA Fingerprinting on the App
|
© EduRev
|
Education Revolution
|



|





