Protoplasm - Biomolecules, Biology, Class 11 PDF Download

Protoplasm - Biomolecules, Class 11, Biology
PROTOPLASM
INTRODUCTION :
Fluid along with all the structures of cell bounded within the limits of cell membrance, is known as protoplasm. So protoplasm includes plasma membrane, cytoplasm and Nucleus. Protoplasm of a single cell is called Protoplast (wall less cell).
Origin of the word protoplasm has taken from a greek work (Protos = first, Plasma = organisation).
Protoplasm was first observed by Corti, 1772.
Felix Dujardin, 1835 observed jelly like substance in animal cells (protozoa) and gave the name ‘Sarcode’.
J.E. Purkinje, 1840 observed similar substance in plant cells and coined the term ‘Protoplasm’.
Hugo Van Mohl, 1846 studied the nature of protoplasm present in the embryonic cell of plants and explained the importance of protoplasm in the cell division.
Max schultze, 1861 established similarity between sarcode and protoplasm. Schultz proposed protoplasm theory (name given by O. Hertwig). Max schultze firstly told that protoplasm is physical basis of life.
J.S. Huxley, 1868 wrote a book ‘‘Protoplasm is physical basis of life’’
Rinke and Roderwald, 1881 first of all performed the chemical analysis of protoplasm.
PHYSICAL NATURE OF PROTOPLASM :
Several theories are proposed to explain physical nature of protoplasm.
(1) Alveolar theory - ''Butschli'' (1892). Protoplasm is a foamy emulsion consists of bubbles of high density fluid.
(2) Granular theory - ''Altman'' (1893). Fine granules are homogenously distributed into the homogenous medium of Protoplasm. Granules were termed as ''Bioplast or Cytoplast''
(3) Fibrillar theory - ''Flemming,'' (1894). Microscopic filaments (Micelles or mitomes) like structures are dispersed in a liquid matrix (Paramitome or Hyaloplasm).
(4) Reticular theory - ''Hanstein, Klein and Carnoy,'' (1898) Protoplasm is a mesh work of microscopic filaments.
(5) Colloidal theory - ''Fisher 1894, Hardy'' 1899 and ''Wilson'' 1925.
This is most acceptable theory for protoplasm. According to this theory, the protoplasm is a Polyphasic Colloidal System.
Physical Properties of Protoplasm :
(1) Protoplasm is a translucent, odourless and polyphasic fluid.
(2) Protoplasm is a crystallo-colloid type of solution.
Protoplasm is a mixture of such chemical substances among which some form crystalloid i.e. true solution (Sugars, Salts, Acids, Bases etc.) and others which form colloidal solution (Proteins, lipids etc.)
(3) Size of colloidal particles (0.001 to 0.1 mm) is between true solution and suspension.
(4) Colloidal systems composed of two stages. (i) Dispersion phase or continuous form or intermicelleus and (ii) Dispersed phase or discontinuous phase or Micellus
TYPE OF COLLOIDS :
On the basis of dispersion and dispersed phases there are four types of colloids -
(1) Sol = Dispersion phase is liquid and dispersed phase is solid. In sol stage, protoplasm is less viscous. Protoplasm in sol stage occurs in majority of living cells.
(2) Gel = Dispersion phase is solid and dispersed phase is liquid. Protoplasm is more viscous e.g. Skin Cells.
(3) Emulsion - Both stages are liquid i.e. fluid colloidal particles are dispersed in a liquid matrix e.g. blood plasma composed of both sol and emulsion.
(4) Aerosol - solid particles remain suspended in gas e.g. smoke. Aerosol does not occur in living system.
(5) Protoplasm mainly composed of either sol or gel.
(6) sol stage provides cyclosis, Brownian movements and high reactivity to protoplasm.
(7) Gelation of protoplasm provide elasticity, contractibility, rigidity and viscosity.
(8) Colloid particles have electric charge and due to charges these remain in a continuous random motion, called Brownian movement.
(9) Environmental conditions like temperature, pressure and pH cause changes in the properties of protoplasm. This change brings endocellular movement of protoplasm called cyclosis.
(10) Browninan movement and cyclosis are more, significant in sol stage of protoplasm.
(11) Being a liquid mixture, the protoplasm has a surface tension. Solutes (Porteins and lipids) having less surface tension, form a delimiting membrane at surface. This membrance is called interface membrance (Plasma membrane). Interface membrane has power of rapid generation.
(12) Being colloid, protoplasm exhibits ''Tyndal effect'' i.e.
Scattering of incident light rays. If colloidal particles are large, then white and if they are small then blue light is observed.
(13) Sol and gel stages of protoplasm are interconvertible so the proptoplasm is a reversible colloidal system. Non living colloids are irreversible.
(14) Ageing-with age, charges of colloid particles diminishes, brownian movements stops so ultimately it becomes non reactive (death of protoplasm).
(15) Viscocity of protoplasm = 2 – 20 centipoises
(16) pH = 6-8
(17) Refractive index = 1.4
Biological properties of protoplasm :
Protoplams is a living substance so it possoses biological properties also.
(1) Protoplasm has motion because of cyclosis, amoeboid and Brownian movement. These movements depend on age of cells, amount of water, genetic factors and chemical composition of protoplasm.
(2) Protoplasm exhibits irritability when provided stimuli.
Sensitivity of protoplasm to external stimuli is called irritability. Transmission of stimuli from one place to another is called conductivity.
Besides irritability, conductivity also occurs in protoplasm of many cells e.g. Nerve cells, muscle cells etc.
(3) Different chemical reactions takes place in protoplasm. Constructive reactions are called Anabolic processes like synthesis of different types of biomolecules. Destructive reaction like oxidation of food called catabolic processes. Anabolic and Catabolic Processes collectively called metabolism.
(4) Protoplasm has the capacity to take external material and resynthesize them in a new form (assimillation).
(5) Respiration and excretion.
Chemical nature of protoplasm :
Approximatey 34 elements participate in the composition of protoplasm but only 13 elements are main or universal elements in protoplasm i.e. C, H, O, N, Cl, Ca, P, Na, K, S, Mg, I, Fe.
Carbon, Hydrogen, Oxygen and Nitrogen from the 96% part of protoplasm.
Rest of the elements of protoplasm occur in very small quantity (0.756%). These are, therefore called Trace elements. These includes Copper, Cobalt, Manganese, Zinc, Boron, Vanadium, Chromium, Tin, Silicon, Fluorine, Molybdenum, Nickel, Selenium, Arsenic.
COMPOUNDS OF PROTOPLASM :
Although some elements occurs in protoplasm as free ions but mostly two or more elements are variously combined to form different kinds of compounds.
Inorganic compounds :
1. Water = 70-90 %
2. Salt, acids, bases, gases = 1-3%
Organic Compounds :
1. Proteins = 7-14%
2. Lipids = 1-3 %
3. Carbohydrates = 1-2%
4. Nucleic acids, enzymes and other = 1-3%
Water :
(1) It is a Best solvent in nature, it forms the matrix of protoplasm. All other constituents of protoplasm are its solutes.
(2) Being an ideal dispersion medium, it causes Brownian movement of colloid particles, resulting into their collision and mutual bombardment. This facilities relativity between the various compounds necessary for maintaining protoplasm in live state.
(3) It causes streaming or cyclosis in protoplasm, facilitating its chemical exchange with the environment and transportation of solutes from one part to the others.
(4) It itself participates in certain types of chemical reactions, particularly in the hydrolytic breakdown of complex compounds.
(5) Having a high specific heat, it minimizes temperature variations and thus protects protoplasm against ill effects of sudden rise or fall of temperature in the environment.
(6) Of total water, 95% water is free water and 5% water occurs as bound water.
(7) Water – Human body – 65-70% of total body weight.
(8) Human body = 40 litre :
55% (22 litre) – intracellular fluid
45% (18 litre) – extracellular fluid
(9) Animal kingdom – Hardest material : Enamel
(10) Plant kingdom – Hardest material : Sporopollenin
SALTS :
(1) Salts in protoplasm occur in ionised form. These ions are responsible for electric conductivity, rendering protoplasm irritable and response to environmental changes.
(2) These provides linkage or chemical bonds in many chemical reactions. Such type of linkage called Salt linkage''.
(3) Some metallic and other ions such as Mg, Fe, Zn, Mo, Mn etc. act as cofactors in enzymatic activitites.
(4) These regulate the osmotic pressure and chemical exchange of protoplasm from its environement.
(5) Some ions also act as co-factor :
Zn+2 – carbonic anhydrase Fe+2 – Aconitase, catalase
Cu+2 – Tyrosinase [CBSE 2004] Mo – Nitrogenase
Mg+2 – Co-factor of many respiratory enzymes like Kinase, Enolase, Dehydrogenase
Ni – Urease enzyme
(6) Some other functions of ions :
Na+ , K+ ions – Nerve induction
Ca+2 , Mg+2 ions – Muscles contractions, Reduce more excitability of nerves and muscle.
Ca+2 ion – Blood clotting, Bone formation
– Most abundant mineral element in animal body
Na+ , K+ ions – Main component of ringer solution.
K+ ion – Helpful in seismonastic movement, stomatal opening and closing.
ACIDS AND BASES :
These prevent pH variations by forming a buffer system in protoplasm, for e.g. carbonic acid-Bicarbonate buffer system.
==========================================================
Carbohydrates- Biomolecules, Biology, Class 11
ORGANIC COMPOUNDS OF PROTOPLASM :
(1) Carbohydrates –
Main source of energy
First respiratory substrate – carbohydrate
R.Q. =
Compounds of carbon, Hydrogen and Oxygen with ratio of H and O is 2 : 1, so they are also called hydrates of carbon.
Generalised formula of carbohydrates is Cx(H2O)y.
Simple carbohydrates which are soluble in water and sweet in taste are called ''Sugar''.
Carbohydrates are main source of energy in body. In a normal man 55-56% of energy is available to him in the form of carbohydrates present in his diet.
CLASSIFICATION OF CARBOHYDRATES :
On the basis of numbers of saccharides in hydrolysis, Carbohydrates are classified as Monosaccharides, oligosaccharides and Polysaccharides.
A. Monosaccharides : -
(i) They are simplest sugars which can not be further hydrolysed.
(ii) In their generalized formula x is always equal to y i.e. number of Carbon and Oxygen atoms same.
(iii) First step of oxidation – Phosphorylation
(iv) All monosaccharides occur in d and l form, except the DHAP.
(v) The structure of saccharides is either ring or straight chain.
(vi) A six membered ring is known as pyranose and five membered ring is furanose.
Pyranose and furanose names were given by ''Haworth.''
(vii) Anomers – In aqueous solution, Glucose occurs in cyclic structure. In anomers, position of –H and –OH groups are changed on C1 carbon atom.
Epimer : Isomer formed as result interchange of the –OH and –H groups on carbon atom 2,3 and 4 of glucose, are know as epimer.
Epimer of Glucose :
Mannose (Difference on C2 carbon)
Galactose (Difference on C4 carbon)
CLASSIFICATION OF MONOSACCHARIDE
On the basis of number of carbon atoms monosaccharides are classified in following groups.
(i) Trioses – C3H6O3 e.g. Glyceraldehyde and Dihydroxy acetone. PGAL and DHAP are percursors of all other carbohydrates.
(ii) Tetroses – C4H8O4 e.g. Erythrose, Erythrulose
(iii) Pentoses – C5H10O5 e.g. Ribose, Ribulose, Xylulose, Arabinose, *Deoxyribose (C5H10O4)
(iv) Hexoses – C6H12O6 e.g. Glucose Fructose, Galactose, Mannose, *Rhamnose (C6H12O5)
(v) Heptose – C7H14O7 e.g. Sedoheptulose
Chemically all carbohydrates are polyhydroxy aldehyde or ketones.
Monosaccharides with free aldehyde group are termed as Aldoses (PGAL, Erythrose, Ribose, Arabinose, Deoxyribose, Glucose, Galactose, Mannose).
While monosaccharides with free ketone group are called ketoses (DHAP, Erythrolose, Ribulose, Xylulose, Fructose, Sedoheptulose).
All monosaccharides are ''reducing sugars'' as their free aldehyde or ketone groups are capable of reducing Cu++ to Cu+.
This property is the basis of Benedict's test or fehling's test used to detect the presence of glucose in urine.
Beside RNA ribose sugar is an important component of ATP, NAD, NADP and FAD
In deoxyribose the second carbon is devoid of oxygen atom
Arabinose occurs in ''Gum arabic''.
Glucose is dextrorotatory so it is called ''dextrose''
Glucose is found in grapes in abundant quantity so it is known as ''grape sugar''
Glucose is the main respiratory substrate in the body. Other types of hexose are converted into glucose by liver.
Fructose is Laevorotatory so it is called ''Laevulose''
Fructose is found in honey and sweet fruits so it is called as ''Fruit Sugar''.
Fructose is the sweetest sugar.
Galactose is not found in free stage.
In mammalian body, galactose occurs as a part of milk sugar lactose.
Galactose is also found as a component of glycolipids (for e.g. cerebrosides) and pectin, Hemi cellulose etc.
Mannose not found in free state.
Mannose occurs in albumin of egg and in wood as component of hemicellulose.
Most sweetest chemical substance is Thaumatine, Obtained from a bacteria Thaumatococcus danielli
Glucose is also known as blood sugar. Aspartame is most commonly used artificial sweetner.
Galactose is known brain-sugar
=====================================================
DERIVATIVES OF MONOSACCHARIDES - Biomolecules, Biology, Class 11
DERIVATIVES OF MONOSACCHARIDES :
(1) Amino sugars – Formed by the displacement of hydroxyl group from second carbon atom by amino group e.g. Glucosamine, Galactosamine.
(2) Sugar alcohol – Aldehyde group (–CHO) of the sugar is changed to primary alcohol (–CH2OH). Sorbitol and Mannitol are respectively formed from glucose and mannose.
(3) Sugar acids – They are formed by the oxidation of terminal –CHO or –CH2OH group of sugar to produce carboxyl group –COOH e.g. Glucoronic acid, Galacturonic acid.
(4) Glycoside – They are compounds formed by condensation reaction between a sugar (eg. glucose) and hydroxyl group of another substance which may be a sugar, a sterole, methanol in presence of dry HCl. They are acetel which can be hydrolysed by strong reagents like HCN, NH2OH, C6H5NHNH2. They cannot be hydrolysed in acidic condition. Streptomycin is a glycoside.
B. Oligo – Saccharides
Oligo – Saccharides are those carbohydrates which on hydrolysis yield 2 to 10 monosaccharide units (monomers). In oligosaccharides, monosaccharides are linked together by glycosidic bonds. Aldehyde or ketone group of one monosaccharide reacts with alcoholic group of another monosaccharide to form glycosidic bond. One molecule of H2O eliminates during glycosidic bond formation (dehydration synthesis). Direction of glycosidic bonds is usually 1'.4''.
Types of Oligosaccharides : -
(i) Disaccharides – composed of two monosaccharide units e.g. Maltose, Sucrose, Lactose, Trehalose.
All disaccharides are water soluble and sweet in taste, so they are known as sugar.
Maltose is commonly called malt sugar. It is intermediate compound in starch digestion. Maltose has 1'-4'' glycosidic linkage between a-D glucose and a-D glucose
Lactose is milk sugar with b-1'-4'' glycosidic linkage between glucose and galactose
Lactose is least sweetest sugar.
Maximum % of lactose = Human milk » 7%
In plants transport of sugar is present in form of sucrose.
Sucrose is also known as invert sugar.
Sucrose is called Cane Sugar or Table Sugar or Commercial Sugar. Sucrose composed of a-D Glucose and fructose.
Trehalose is present in haemolymph of insects. It has glycosidic linkage between two anomeric carbon
(a-glucose and b-Glucose).
(ii) Trisaccharides – e.g Raffinose (Galactose + Fructose)
(iii) Tetrasaccharides – e.g Stachyose (Gal. + Gal. + Glu. + Fructose)
(iv) Pentasaccharides – e.g Barbascose (Gal + Gal + Glu + Glu + Fructose)
Raffinose and stachyose occur in phloem and may be employed for translocation carbohydrates.
C. Polysaccharides : -
Poly saccharides composed of large number of monosaccharide units.
Suffix '–an' added in their names and they are known as glycans.
Pentose polysaccharides are called pentosans for e.g.
Araban (from L-arabinose), xylan (from D-xylose), all these found in cell wall.
Hexose polysaccharides are called ''hexans'' . for e.g. mannan (from mannose) cellulose, starch etc.
Polysaccharides are insoluble in water and do not taste sweet.
All polysaccharide are non-reducing
Accroding to function, they are classified as nutritive and structural.
On structural basis polysaccharides are of two types.
(I) Homopolysaccharides : -
Composed of same monomers. Biologically important homopolysaccharides are as follows :
(a) Cellulose : - Linear polymer of b-D-glucose units (6000 to 10,000) . It has b 1'-4'' linkage. Partial digestion yields a cellobiose units (Disaccharide).
Cellulose is main component of plant cell wall. In wood, cellulose is 50% and in cotton, it is 90%.
Most abundant organic molecule on earth.
In urochordates animals their occur cellulose like material and it is called ''Tunicine'' It is also called animal cellulose.
It is also used to form Rayon fibre (Artificial silk).
(b) Starch – It is main stored food in plants. Starch is polymer of a-D-glucose units. Starch consists of two types of chains.
(i) Amylose – 250-300 glucose units are arranged in an unbranched chain by a 1'-4'' linkage.
(ii) Amylopectin – A branched chain molecule. Approximately 30 glucose units are linked by a-1' 4'' and a-1', 6'' linkage.
· Amylose gives blue colour with iodine.
· Amylopectin gives red colour with iodine.
· Starch present in potato contains 20% amylose and 80% amylopectin.
(c) Glycogen – storage form of carbohydrate in animals, storage region of glycogen is liver and muscles.
Storage of glycogen liver > muscle. Glycogen is also called as animal starch. Glycogen is highly branched polymer of a-D-glucose.
· Glycogen is formed by the 1'-4'' bond linkage at long chain and 1', 6'' bond linkage at branching point.
· Glycogen gives red colour with iodine.
· Glycogen is store food of fungi.
(d) Chitin – Linear polymer of N-acetyl-D-glucosamine with b-1', 4''-linkage.
· N-acetyl D-glucosamine is an amino acyl (-NH-CO-CH3) derivative of b-D-glucose.
· Chitin is an important component of exoskeleton of Arthropods and cell walls of fungi.
· Second most abundant organic molecule on earth.
· It is also called Fungal cellulose.
(e) Inulin – Linear polymer of fructose units linked with b-1', 2'' bonds. Inulin is found in roots of Dahalia and Artichoke. It is water soluble polysaccharide and it is used to know the glomerular filteration rate.
· It is smallest storage polysaccharide.
(f) Dextrin – Dextrin is an intermediate substance in the digestion of glycogen and starch. By hydrolysis of dextrin, glucose and maltose are formed. It also occurs as stored food in yeast and bacteria.
(II) Heteropolysaccharide –
Composed of different monosaccharide units.
(a) Hyaluronic acid – Found in vitreous humour, umbillical cord, joints and connective tissue in the form of lubricating agent. It also occurs in animal cell coat as binding material (Animal cement).
· Hyaluronic acid is made up of D-glucouronic acid and N-acetyl – D-glucosamine arranged in alternate orders. These different monosaccharides have b-1'-4'' bonds and such disaccharides have b -1- 4 bonds.
(b) Chondriotin – D-glucuronic acid + N-acetyl galactosamine.
· Chondriotin occurs in connective tissue.
· Sulphate ester of chondriotin is main structural component of cartilages, tendons and bones.
(c) Heparin – It is anticoagulant of blood. Heparin is made up of D-glucuronic acid and N-sulphate glucosamine arranged in alternate order
(d) Pectins – Methylated galacturonic acid + galactose + arabinose.
· Pectin found in cell wall where it binds cellulose fibrils in bundles.
· Salts of pectin i.e Ca and Mg-pectates form middle lamella in plants.
· It is also called Plant cement.
(e) Hemicellulose – Mannose + Galactose + Arabinose + Xylulose.
· Store material – Phytalophus (Ivory palm). Hemicellulose which is obtained from this plant is white, hard and shiny and it is used to form billiard ball and artificial ivory.
MUCOPOLYSACCHARIDES :
Slimy polysaccharides with capacity to bind proteins and water are called mucopolysaccharides. In plants mucilage is a common mucopolysaccharide formed of galactose and mannose units.
Hyaluronic acid, chondriotin, heparin are other examples.
Special Points :
1. Peptidoglycan – Present in cell wall of bacteria.
– Composed of N-acetyl Glucosamine + N-acetyl muramic acid + peptide chain of 4-5 amino acids.
2. Agar-Agar – It is a mucopolysaccharide which is obtained from some red algae – Gracilaria, Gelidium, Chondrus. Its is composed of D-galactose and L-galactose unit and after every 10th unit a sulphate group is present it is used for preparing culture medium (1, 3 linkage)
==========================================
Lipids: Fatty acids, Phospholipids - Biomolecules, Biology, Class 11
LIPIDS :
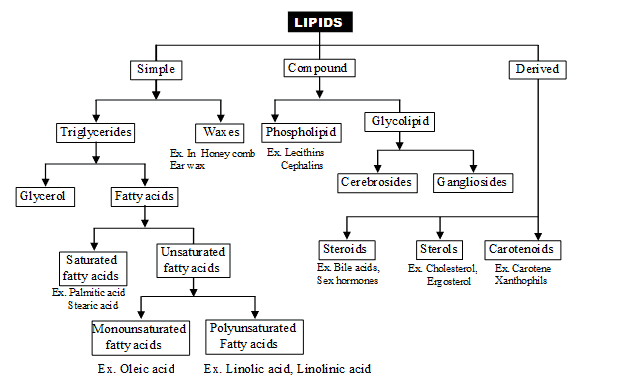
Fat and its derivatives are combindly known as lipid.
Lipid term coined by Bloor.
Compounds of C, H, O but the ratio of Hydrogen and Oxygen is not 2 : 1. The amount of oxygen is considerably very less.
Lipids are insoluble in water and soluble in organic solvents like acetones, chloroform, benzene, hot alcohol, ether etc.
Lipids occur in protoplasm as minute globules.
Lipids do not form polymer.
Lipids provide more than double energy as compare to carbohydrate.
In animals, fat present in subcutaneous layer and working as food reservior and shock-absorber.
Lipid require less space for storage as compare to carbohydrate because lipid molecule is hydrophobic and condense.
Animal store maximum amount of food in the form of lipid.
Lipid provides maximum amount of metabolic water as compare to carbohydrate and protein on oxidation.
Lipids are not strictly macromolecules.
(A) Simple Lipid or Neutral Fats -
These are esters of long chain fatty acids and alcohol. In majority of simple lipids, the alcohol is a trihydroxy sugar alcohol i.e. glycerol.
Three molecules of fatty acid linked with one molecule of glycerol. The linkage is called ''ester bond''. such type of lipids called Triglycerides. Three molecules of water are released during formation of triglycerides (dehydration synthesis)
Similar or different fatty acids participate in the composition of a fat molecule. Simple lipids contain two types of fatty acids.
(i) Saturated Fatty acids – are those in which all the carbon atoms of hydro-carbon chain are saturated with hydrogen atoms
e.g. Palmitic acid – CH3(CH2)14 – COOH
Stearic acid – CH3(CH2)16 – COOH
(ii) Unsaturated fatty acids –are those in which some carbon atom are not fully occupied by hydrogen atoms
e.g. Oleic acid – CH3(CH2)7 CH=CH(CH2)7COOH
Linoleic acid – CH3(CH2)4 –(CH=CH–CH2)2 –(CH2)6 –COOH
Linolenic acid–CH3–CH2 –(CH=CH–CH2)3 –(CH2)6 –COOH
Polyunsaturated = fatty acids with more than one double bonds in their structure e.g. Linoleic acid, Linolenic acid, Arachidonic acid, Prostagladins (derived from archidonic acid)
Unsaturated fatty acid also called as essential fatty acids because no animal is able to synthesize them.
Simple lipids with saturated fatty acid remain solid at normal room temperature e.g. fats
Simple lipids with unsaturated fatty acids remain liquid at room temperature e.g. oils.
Saturated fatty acids are less reactive so they tend to store in body and cause obesity.
Unsaturated fatty acids are more reactive so they tend to metabolise in body and provide energy.
Oils with poly unsaturates are recommended by physicians for persons who suffer from high blood cholesterol or cardio-vascular diseases. This is because increasing the proportion of poly unsaturated fatty acids to saturated fatty acids, without decreasing the fats in the diet tend to lower the cholesterol level in blood.
Waxes – are monoglycerides with only one molecule of fatty acid attached to a long chain monohydroxy alcohol. Waxes are more resistant to hydrolysis as compared to triglycerides. Waxes have an important role in protection. They form water insoluble coatings on hair and skin in animals and stem, leaves and fruits of plants.
e.g.
Bees Wax (Hexacosyl palmitate)
Carnauba (Myricyl cerotate)which occurs on leaves, stem and fruits.
Spermaceti in skull of whale and Dolphin.
Cerumen or ear wax – occurs in external auditory canal.
Lanoline or cholesterol ester – occurs in blood, sebum and gonadial ducts as lubricating agent.
It is also obtained from wool of sheep.
(B) Conjugated or Compound Lipids –
(i) Phospholipids or phosphatide or phospholipins –
2 Molecules of fatty acid + Glycerol + H3PO4 + Nitrogenous compound. Phospholipids are most abundant type of lipids in protoplasm.
Phospholipids have both hydrophilic polar end (H3PO4 and nitrogenous compound) and hydrophobic non polar end (fattty acids). Such molecules are called amphipathic. Due to this property, phospholipids form bimolecular layer in cell membrance.
Some biologically important phospholipids are as following :
(a) Lecithin or Phosphatidyl choline
- Nitrogenous compound in lecithin is choline.
- Lecithin occurs in egg yolk, oil seeds and blood.
- In blood lecithin functions are carrier molecule. It helps in transportation of other lipid.
(b) Cephalin – Similar to lecithin but the nitrogenous compound is ethanolamine, cephalin occurs in nervous tissue, egg yolk and blood platelets.
(c) Sphingolipids or sphingomylins similar to lecithin but in place of glycerol it contains an amino alcohol sphingosine.
Sphingolipids occur in myelin-sheath of nerves, other examples of phospholipids are phosphatidyl serine, phosphatidyl inositol, plasmologens.
(ii) Glycolipid – 2 fatty acid + sphingosine + galactose
eg. Cerebroiside which occurs in white matter of brain –
Gangliosides – These occur in nerve ganglia and spleen. These also contain N-acetyl neurominic acid and glucose beside other compounds.
(iii) Derived Lipids – Lipid derived from simple or conjugated lipid. Derived lipids are complex in structure.
They are insoluble in water and soluble in organic solvents.
(A) Steroids – Steroids exhibit tetracyclic structure called ''Cyclo pentano perhydrophenanthrene nucleus ''
On the basis of functional group, steroids are of two types –
(a) Sterols – Alcoholic steroids e.g. cholesterol – Cholesterol abundantly occurs in brain, nervous tissue, Adrenal gland and skin. Cholestrol is a parent steroid. Several other biologically important steroids are derived from cholesterol. 7-dehydro cholesterol which occurs in skin is a provitamin. On exposure to ultraviolet radiation, it transforms in cholecalciferol i.e. vitamin D.
Cholesterol is also called ''most decorated micromolecule in biology''.
Ergosterol – It occurs in oil seed, fungi like ergot and yeast. Ergosterol is precursor of another form of Vitamin D-Ergocalciferol.
Coprosterol – Occurs in faecal matter. It forms decomposition of cholesterol by colon bacteria.
Bile acid – Bile juice contains different types of steroid acids. E.g. cholic acid, Lithocholic acid etc. They help in emulsification of fats.
(b) Sterones – Ketonic steroids, for e.g. sex hormones, Adreno corticoids, ecdyson hormone of insects, Diosgenin obtained from yam plant (Dioscorea), is used in manufacture of antifertility pills.
(B) Chromolipid = It is also called terpene.
Most complex lipid in protoplasm.
Chromolipids composed of repeated isoprene units
Example : Carotenoids, vitamin A, E, K, Natural Rubber (Polyterpene).
Special Points :
Prostaglandins – It is Derived lipid. Prostaglandins are derivatives of PUFA (Polyunsaturated fatty acid) They are helpful in contraction of uterus and fallopian tube, blood clotting, Muscle contraction.
===============================================================
Protein - Biomolecules, Biology, Class 11
PROTEINS :
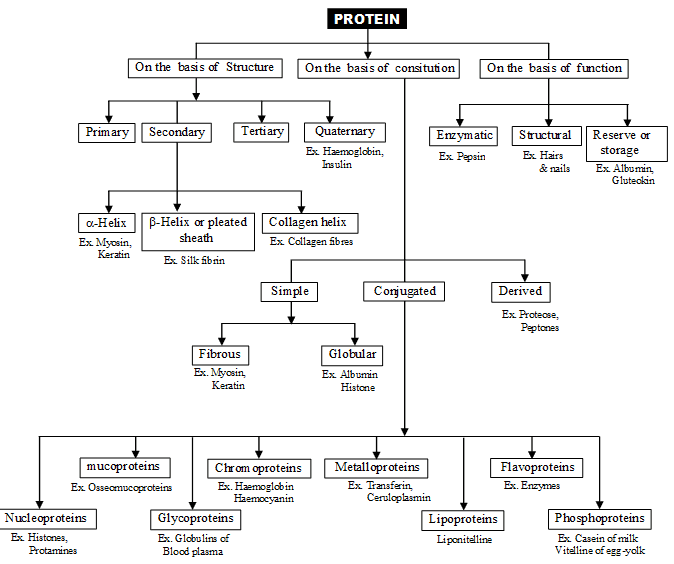
Protein name is derived from a greek word which means '' holding first place '' (Berzelius and Mulder)
Essential elements in protein are C, H, O, N,
Most of the proteins contain sulphur. In some proteins iodine, iron and phosphorus are present.
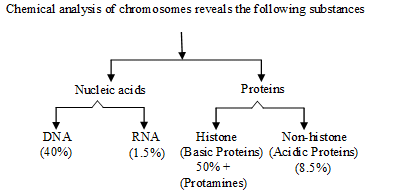
After water proteins are most abundant compounds in protoplasm. (7-14%)
Proteins are polymer of amino acid (Fisher and Hofmeister). There are approximately 300 amino acids known to exist but only 20 types of amino acids are used in formation of proteins.
Each amino acid is amphoteric compound because it contains one weak acidic group –COOH and a weak alkaline group –NH2
In protoplasm free amino acid occurs as ions (at iso electric point)
Iso electric point is that point of pH at which amino acids do not move in electric field.
Out of 20 amino acids, 10 amino acids are not synthesized in body of animals so they are must in diet. These called Essential amino acid. e.g. Threonine, Valine, Leucine, Isoleucine, Lysine, Methionine, Phenylalanine Tryptophan, arginine, Histidine. Arginine and Histidine are semi essential.
10 amino acids are synthesized in animal body so these called Non essential amino acids. for e.g. Glycine, Alanine, Serine, Cysteine, Aspartic acid, Glutamic acid, Asparagine, Glutamine, Tyrosine, Proline
Classification of Amino Acids –
(A) Amino acids can be classified on the basis of their group –
(i) Non-polar R group – Glycine, Alanine, Valine, Leucine, Isoleucine, Proline, Methionine, Phenyl alanine, Tryptophan.
(ii) Polar but uncharged R group – Serine, Threonine, Cysteine, Tyrosine, Asparagine, Glutamine
(iii) Positively charge polar R-group – Lysine, Arginine, Histidine (Basic Amino acid)
(iv) Negatively charged polar R-group – Aspartic acid, Glutamic acid (Acidic Amino acid)
Except glycine, each amino acid has two enantiomeric isomers
Eukaryotic proteins have L-amino acid while D-amino acid occurs in bacteria and antibodies :
Amino acids join with peptide bond to form protein.
Peptidyl transferase enzyme catalyses the synthesis of peptide bond.
Property of protein depends on sequence of amino acid and configuration of protein molecules.
Special points on Amino acid :
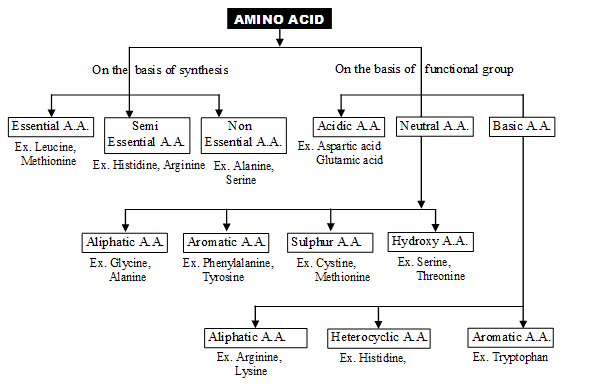
Glycine is the simplest and tryptophan is complex Amino acid.
Cysteine, Cystine, Methionine are the sulphar containing Amino acid.
Phenyl alanine, Tyrosine, Tryptophan Amino acids are aromatic Amino acid.
Serine & Threonine are alcoholic amino acid.
Histidine, Proline & hydroxyproline are heterocyclic amino acid.
All the amino acids are laevo-rotatory, except Glycine which is non-rotatory.
Amino acids which participate in protein synthesis called protein Amino acid and which do not participate called non-Protein.
eg. GABA, Ornithine, Citrulline.
Proline, Hydroxy proline contain imino group  instead of amino group so they are also called Amino acid.
instead of amino group so they are also called Amino acid.
Configuration of Protein Molecule –
- Primary configuration or structure – A straight chain of amino acids linked by peptide bonds form primary structure of proteins. This structure of protein is most unstable. Newly formed proteins on ribosomes have primary structure .
(2) Secondary configuration – Protein molecules of sec. structure are spirally coiled. In addition to peptide bond, amino acids are linked by hydrogen bonds form between oxygen of one amide group and hydrogen of another amide group. This structure is of two types –
(i) a–Helix – Right handed rotation of spirally coiled chain with approximately amino acids in each turn. This structure has intramolecular hydrogen bonding i.e. between two amino acids of same chain e.g. Keratin, Myosin, Tropomyosin.
(ii) b-Helix or pleated sheath structure – Protein molecule has zig – zag structure. Two or more protein molecules are held together by intermolecular hydrogen bonding. e.g. fibroin (silk).
(3) Tertiary Structure – Protein of tertiary structure are highly folded to give a globular appearance. They are soluble in water (colloid solution). This structure of protein has following bonds –
(i) Peptide bond = strongest bond in proteins.
(ii) Hydrogen bonds
(iii) Disulphide bond – These bonds form between – SH group of amino acid (Methionine, Cysteine). These bonds are second strongest bond and stabilize tertiary structure of protein.
(iv) Hydrophobic bond – Between amino acids which have hydrophobic side chains for e.g. Aromatic amino acid
(v) Ionic bond – Formation of ionic bond occus between two opposite ends of protein molecule due to electrostatic attraction
Majority of proteins and enzymes in protoplasm exhibit tertiary structure.
Quaternary Structure – Two or more poly peptide chains of tertiary structure unite by different types of bond to form quaternary structure of protein. Different polypeptide chains may be similar lactic - dehydrogenas or dissimilar types (Haemoglobin, insulin).
Quaternary structure is most stable structure of protein.
Significance of Structure of Protein –
E The most important constituents of animals are protein and their derivatives. Proteins form approximately 15% of animal protoplasm. The physical and biological properties of proteins are
dependant upon their secondary and tertiary configurations. Protein is electrically charged because it has and –COO– ionic components. In an acidic medium the –COO– group of protein converts in COOH and the protein itself becomes positively charged. In contrast, in an alkaline medium the group of protein changes to – NH2 + H2O and as a result it becomes negatively charged. Therefore, at a specific pH a protein will possess an equal number of both negative and positive charges and it is at this specific pH a protein becomes soluble.
If the pH changes towards either acidic or alkaline side, then the protein begins to precipitate. This property of protein has great biological significance. The cytoplasm of cells of organisms has an approximate pH of 7 but the pH of proteins present in it is about 6 and thus, the proteins are present in a relatively alkaline medium. Therefore, the proteins are negatively charged and also are not in a fully dissolved state. It is because of this insolubility, proteins form the structural skeleton of organismal cells. Similarly, the pH of nucleoplasm is about 7 but the pH of proteins, namely, histones and protamines, in it is relatively more. Therefore, as a result they are positively charged and do not remain fully dissolved in the nucleoplasm forming minute organelles, the most important being the chromosomes.
As has been described above, the structural units namely amino acids of proteins contain both a carboxyl group (–COOH) or acidic group and an amino group (–NH2) or alkaline group attached to the same carbon atom. Therefore, proteins depending upon the pH of the medium can exhibit both alkaline and acidic properties. Such compounds which exhibit both acidic and alkaline properties are called amphoteric compounds or zwitter ions. In the protoplasm, this dual property of proteins is utilized for neutralisation of strong acids and alkalis since the protein acts an an ideal buffer in either of the situations.
Besides changes in pH, salts, heavy metals, temperature, pressure, etc. also cause precipitation of proteins. Because of these changes, the secondary and tertiary configuration of proteins is destroyed and many times the tertiary structured globular proteins become converted to secondary configuration fibrous proteins . Such alternations in the physical state of proteins is called denaturation. If the change in the medium of proteins is mild and for a short period, then denaturation of the proteins is also temporary, however, if the change in medium is strong and prolonged then denaturation is permanent and the protein becomes coagulated. For example, the white or albumen of egg is a soluble globular protein but on heating it permanently coagulates into fibrous insoluble form. It is clear, that strong alternations result in the denaturation of proteins and they lose their biological properties and significance. It is this reason, that cells of organisms are unable to bear strong changes and they ultimately die.
TYPES OF PROTEINS :
1. Simple Proteins - proteins which composed of only amino acid.
(i) Fibrous Protein – e.g. Collagen, Elastin, Keratin
(ii) Globular Proteins – e.g. Albumin, Histones, Globin, Protemines, Prolamines (Glaidin, Gluten, Zein), Gluteline – slimy part of gluten of wheat.
2. Conjugated Proteins – Simple protein + non protein part (Prosthetic group)
(i) Nucleoproteins – e.g. Chromatin, Ribosomes etc.
(ii) Chromoprotein – Prosthetic group is a porphyrin pigment e.g Haemoglobin, Haemocyanin, Cytochromes etc.
(iii) Lipoprotein eg. Cell membrane, Lipovitelline of Yolk.
(iv) Phospho proteins – Casienogen, Pepsin, Ovovitelline, Phosvitin.
(v) Lecitho protein – Fibrinogen.
(vi) Metallo protein – Cu-tyrosinase, Zn-Carbonic anhydrase, Mn-Arginase, Mo-Zanthine Oxidase Mg- Kinase
(vii) Glycoproteins and Mucoproteins – Glyco proteins have less than 4% Carbohydrates in their structure. They are most specific type proteins e.g. a, b g-globuline of blood group proteins, mucin, Erythropoetin etc.
Muco proteins have more than 4% Carbohydrate e.g. Mucoids of synovial fluid, Osteomucoprotein of bones, Tendomucoprotein of tendons, Chodro mucoprotein of cartilage.
3. Derived Protein – These are formed by denaturation or hydrolysis of protein.
(i) Primary derived proteins are denaturation product of normal proteins e.g. Fibrin, Myosin
(ii) Secondary derived proteins are digestion products of proteins e.g. Proteoses, peptones, Peptides.
Special Point on Protein :
Monomeric protein : Protein composed of one polypeptide chain.
Oligomeric/Polymeric/Multimeric protein : Protein composed of more then one polypeptide chains.
Peptide : A molecule short than 20 Amino acids.
Polypeptide : It usually has more than 20 Amino acids.
Protein : It contains miniumum 50 Amino acids or more than 50 Amino acids.
======================================================
Nucleic Acids: Structure, bond - Biomolecules, Biology, Class 11
NUCLEIC ACIDS :
CHEMICAL COMPOSITION :
Meischer discovered nucleic acids in nucleus of pus cell and called it ''nuclein''. The name nucleic acid proposed by ''Altaman''.
Nucleic acids are polymer of nucleotides.
= Nitrogen base + pentose + phosphate
On the basis of structure nitrogen bases are broadly of two types :
1. Pyrimidines – Consist of one pyrimidine ring. Skeleton of ring composed of two nitrogen and four Carbon atoms e.g. Cytosine, Thymine and Uracil.
2. Purines – Consist of two rings i.e. one pyrimidine ring (2N + 4C) and one imidazole ring (2N + 3C) e.g. Adenine and Guanine.
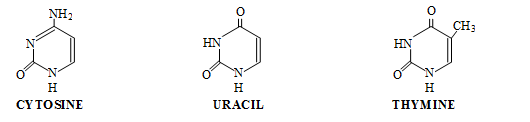
Pentose Sugar :-
Nitrogen base forms bond with first carbon of pentose sugar to form a nucleoside. Nitrogen of first place (N1) forms bond with sugar in case of Pyrimidines while in purines nitrogen of ninth place (N9) forms bond with sugar.
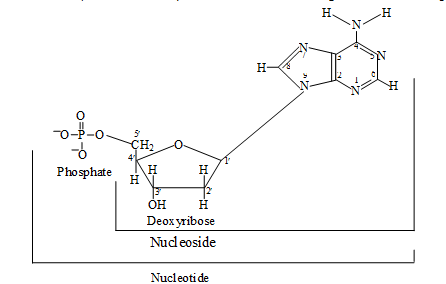
Phosphate forms ester bond (covalent bond ) with fifth carbon of sugar to form a complete nucleotide.
Types of Nucleosides and Nucleotides
1. Adenine + Ribose = Adenosine
Adenosine + Phosphate = Adenylic acid
2. Adenine + Deoxyribose = Deoxy adenosine
Deoxy adenosine + P = Deoxy adenylic acid
3. Guanine + Ribose = Guanosine
Guanosine + P = Guanylic acid
4. Guanine + Deoxyribose = Deoxy guanosine
Deoxy guanosine + P = Deoxy guanylic acid
5. Cytosine + Ribose = Cytidine
Cytidine + P = Cytidylic acid
6. Cytosine + Deoxyribose = Deoxycytidine
Deoxycytidine + P = Deoxycytidylic acid
7. Uracil + Ribose = Uridine
Uridine + P = Uridylic acid
8. Thymine + Deoxyribose = Deoxy thymidine
Deoxythymidine + P = Deoxythymidylic acid
====================================================================
Nucleic Acids: DNA, RNA - Biomolecules, Biology, Class 11
DNA :
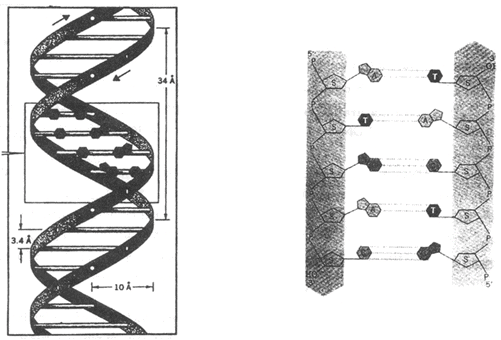
Discovered by – Meischer
DNA term given by – Zacharis
In DNA pentose sugar is deoxyribose sugar and four types of nitrogen bases A, T, G, C
Wilkins and Franklin studied DNA molecule with the help of X-Ray crystallography.
With the help of this study, Watson and Crick (1953) proposed a double helix molel for DNA. For this model Watson, Crick and Wilkins were awarded by noble prize in 1962.
According to this model, DNA is composed of two polynucleotide chains.
Both polynucleotide chains are complementary and antiparallel to each other.
In both strand of DNA direction of phosphodiester bond is opposite. i.e. If direction of phosphodiester bond in one strand is 5'-3' then it is 3'-5' in another strand.
Both strand of DNA held together by Hydrogen bonds. These hydrogen bond are present between Nitrogen bases of both strand.
Adenine binds to Thymine by two hydrogen bonds and cytosine binds to Guanine by three hydrogen bonds.
chargaff's equivalency rule – In a double stranded DNA amount of purine nucleotides is equal to amount of pyrimidine nucleotides.
Purine = Pyrimidine
[A] + [G] = [T] + [C]
Base ratio = = constant for a given species.
In a DNA A + T > G + C Þ A – T type DNA. Base ratio of A – T type of DNA is more than one. eg. Eucaryotic DNA
In a DNA G + C > A + T Þ G – C type DNA. Base ratio of G –C type of DNA is less than one. eg. Procaryotic DNA
Melting point of DNA depends on G – C contents.
More G – C contents then more Melting point.
Tm = Temperature of melting.
Tm = of prokaryotic DNA > Tm of Eucaryotic DNA
DNA absorbs U.V. rays means 2600Å wavelength.
Out of two strand of DNA only one strand participates in transcription, it is called Antisense strand/ Non coding strand/Template strand.
Other strand of DNA which does not participate in transcription is called sense strand/Coding strand.
Denaturation and renaturation of DNA – If a normal DNA molecule is placed at high temperature
(80 – 90°C) then both strand of DNA will separate to each other due to breaking of hydrogen bonds. It is called DNA-denaturation.
When denatured DNA molecule is placed at normal temperature then both strand of DNA attached and recoiled to each other. It is called Renaturation of DNA.
Hyperchromicity – When a double stranded DNA is denatured by heating then denatured DNA molecule absorbs more amount of light, this phenomenon is called hyperchromicity.
Hypochromicity – When denatured DNA molecule cool slowly then it becomes double stranded and it absorb less amount of light. This phenomenon is called hypochromicity.
Configuration of DNA Molecule –
Two strands of DNA are helically coiled like a revolving ladder. Back bone of this ladder (Reiling) is composed of phosphates and sugars while steps (bars) composed of pairs of nitrogen bases.
Distance between two successive steps is 3.4Å. In one complete turn of DNA molecule there are such 10 steps (10 pairs of nitrogen bases.) So the length of one complete turn is 34Å. This is called helix length.
Diameter of DNA molecule i.e. distance between phosphates of two strands is 20Å.
Distance between sugar of two strands is 11.1 Å.
Length of hydrogen bonds between nitrogen bases is 2.8-3.0 Å. Angle between nitrogen base and C1 Carbon of pentose is 51°.
Molecular weight of DNA is 106 to 109 dalton.
In nucleus of eukaryotes the DNA is associated with histone protein to form nucleoprotein. Histone occupies major groove of DNA at 30° angle.
Bond between DNA and Histone is salt linkage (Mg+2).
DNA in chromosomes is linear while in prokaryotes, mitochondria and chloroplast is circular.
In f × 174 bacteriophage the DNA is single stranded and circular isolated by Sinsheimer.
G–4, S–13, M–13, F1 and Fd–Bacteriophages also contain ss–circular DNA.
Types of DNA
On the basis of direction of twisting, there are two types of DNA.
1. Right Handed DNA –
Clockwise twisting e.g. The DNA for which Watson and Crick proposed model was 'B' DNA.
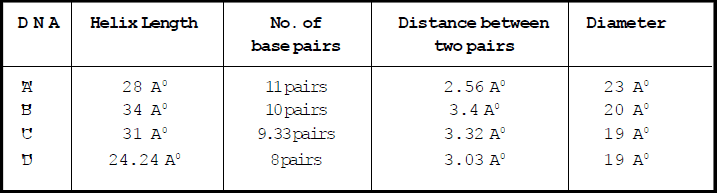
2. Left handed DNA –
Anticlockwise twisting e.g. Z-DNA-discovered by Rich. Phosphate and sugar backbone is zig-zag. Units of Z-DNA are dinucleotides (Purine and pyrimidine in alternate order )
Helix length – 45.6 Å
Diameter – 18.4 Å
No. of Base pairs – 12 (6 dimers)
Distance between base – pairs – 3.75 Å
Palindromic DNA – Wilson and Thomas
–®
C C G G T A C C G G
G G C C A T G G C C
Sequence of nucleotides same from both ends.
Special Points :
DNA molecule is Dextrorotatory while RNA molecule is Laevorotatory.
C–value = Total amount of DNA in a haploid genome of organism.
RIBO NUCLEIC ACID (RNA) :
Structure of RNA is fundamentally the same as DNA, but there are some differences. The differences are as follows .:
(1) In place of De – Oxyribose sugar of DNA, there is present Ribose sugar in RNA.
(2) In place of nitrogen base Thymine present in DNA, there is nitrogen base uracil in RNA.
(3) RNA is made up of only one polynucleotide chain i.e. R.N.A. is Single stranded.
Exception –
RNA found in Reo – virus is double stranded, i.e. it has two polynucleotide chains.
Types of RNA :
1. Genetic RNA or Genomic RNA - In the absence of DNA, sometime RNA working as genetic material and genomic RNA transfer informations from one generation to next generation.
eg. Reo virus, TMV, QB bacteriophage.
Non-genetic RNA - 3 types –
(A) r- RNA (B) t – RNA (C) m – RNA
(1) Ribosomal RNA (r - RNA) :
This RNA is 80% of the cell's total RNA
It is found in ribosomes and it is produced in nucleolus.
It is the most stable form of RNA.
There are present 80s type of ribosomes in Eukaryotic cells. Their subunits are 60s and 40s . In 60s sub unit of ribosome three type of r-RNA are found – 5s, 5.8s, 28s
In the same way 40s sub unit of ribosome has only one type of r-RNA = 18s.
So 80s ribosome has total 4 types of r-RNA.
prokaryotic cells have 70s type of ribosomes and its subunits are 50s and 30s.
50s sub unit of ribosome contains 2 molecules of r-RNA = 5s and 23s.
30s sub unit of ribosome has 16s type of r-RNA.
So 70s RNA has total 3 types of r-RNA.
Functions –
At the time of protein synthesis r-RNA provides attachment site to t-RNA and m-RNA and attaches them on the Ribosome.
The bonds formed between them are known as Salt linkages. It attaches t-RNA to the larger subunit on the Ribosome and m - RNA to smaller sub-unit of ribosome.
(2) Transfer – RNA (t-RNA) –
It is 10-15% of total RNA.
It is synthesized in the nucleus by DNA.
It is also known as soluble RNA (sRNA)
It is also known as Adapter RNA.
It is the smallest RNA (4s).
Function - At the time of protein synthesis it acts as a carrier of amino-acids.
Discovery – t-RNA was discovered by Hogland, zemecknike and Stephenson.
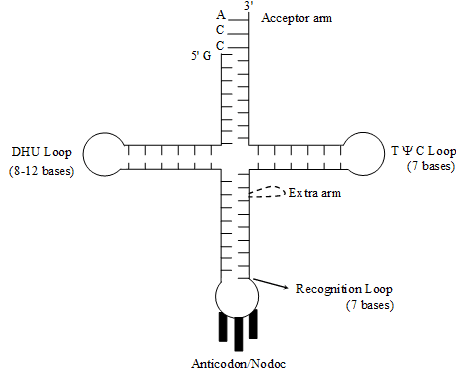
Structure – The structure of t-RNA is most complicated.
A scientist named Holley presented Clover leaf model of its structure. In two dimensional structure the
t-RNA appears clover leaf like but in three dimensional structure (by Kim) it appears L-shaped.
The molecule of t-RNA is of single strand.
There are present three nucleotides in a particular sequence at 3' end of t RNA and that sequence is = CCA.
All the 5' ends i.e. last ends are having G(guanine).
3' end is known as Acceptor end.
t-RNA accepts amino acids at acceptor points. Amino acids binds to 3' end by its –COOH group.
The molecule of t-RNA is folded and due to folding some complementary nitrogenous bases comes across with each other and form hydrogen bonds.
There are some places where hydrogen bonds are not formed, these places are known as loop.
Loops –
There are some abnormal nitrogenous bases in the loops, that is why hydrogen bonds are not formed.
e.g. Inosine (I) Pseudouracil (Y) Dihydrouridine (DHU)
(i) T Y C Loop or Attachment loop –
This loop connects t-RNA to the larger subunit of ribosome.
(ii) Recognition Loop –
E This is the most specific loop of t-RNA and different types of t-RNA are different due to this loop. There is a specific sequence of three nucleotides called Anticodon, is present at the end of this loop.
On the basis of Anticodon, there are total 61 types of t-RNA, or, we can also say that there are 61 types of Anticodon.
t-RNA recognizes its place on m-RNA with the help of Anticodon.
The anticodon of t-RNA recognizes its complementary sequence on m-RNA. This complimentary sequence is known as codon.
(iii) DHU Loop –
It is also known as Amino-acyl synthetase recognition loop. Amino-acyl synthetase is a specific type of enzyme. The function of this enzyme is to activate a specific type of amino acid. After activation this enzyme attaches the aminoacid to the 3' end of t-RNA.
There are 20 types of enzymes for 20 types of aminoacids.
The function of DHU loop is to recognize this specific Aminoacyl synthetase enzyme.
(3) Messenger RNA (m-RNA) -
The m-RNA is 1-5% of the cell's total RNA.
Discovery – Messenger RNA was discovered by Huxley, Volkin and Astrachan. The name m-RNA was given by Jacob and Monad.
The m-RNA is produced by genetic DNA in the nucleus. This process is known as Transription.
D.N.A REPLICATION :
D.N.A. is the only molecule capable of self duplication so it is termed as a ''Living molecule''
All living beings have the capacity to reproduce because of this characteristic of D.N.A.
D.N.A replication takes place in '''S - Phase'' of the cell cycle. At the time of cell division, it divides in equal parts in the daughter cells. Delbruck suggested three methods of DNA-replication i.e.
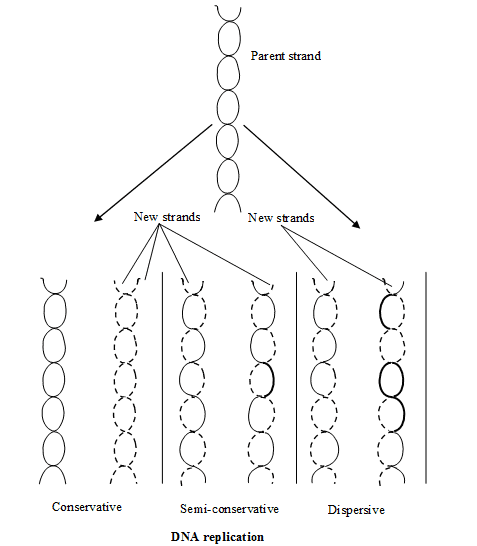
(1) Dispersive
(2) Conservative
(3) Semi-conservative
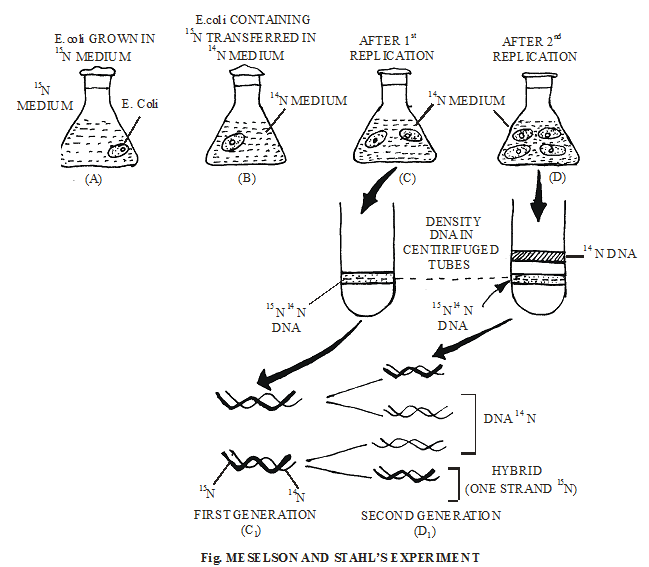
SEMI CONSERVATIVE MODE OF D.N.A. REPLICATION :
Semi conservative mode of D.N.A. replication was first theoritically proposed by Watson & Crick. Later on it was experimentally proved by Meselson & Stahl (1958) on E-Coli and Taylor on Vicia faba. To prove this method , they used Radiotracer Technique in which Radioisotops are used. Meselson and Stahl used N15 and Cairns (1963) used radioactive Thymidine (with H3).
Due to the replication of active Thymidine containing D.N.A., two D.N.A. molecules were obtained in which 50% radioactivity was found.
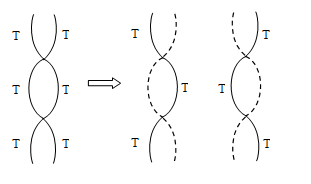
When these two D.N.A. molecules containing active Thymidine were made to replicate, the next time four D.N.A. molecules were obtained. Out of these 4 D.N.A., 2 D.N.A. molecules were radioactive and remaining 2 were not radioactive.
In the same sequence, the obtained D.N.A. molecules were further made to replicate then also, the no. of radioactive D.N.A remains 2.
MECHANISM OF D.N.A. REPLICATION :
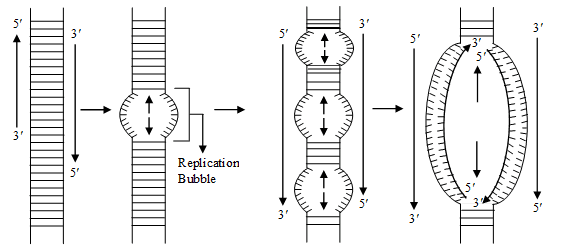
The following steps are included in D.N.A replication –
(1) Unzipping E The separation of 2 chains of D.N.A. is termed as unzipping and it takes place due to the braking of H bonds. The process of unzipping starts at a certain specific point which is termed as initiation point or origin of replication . In procaryotes there occur only one origin of replication but in eucaryotes there occur
many origin of replication i.e. unzipping starts at many points simultaneously.
The enzyme responsible for unzipping (breaking the hydrogen bonds) is Helicase (= Swivelase). In the process of unzipping Mg+2 act as cofactor. Unzipping takes place in alkaline medium.
At the place of origin, the topoisomerase enzyme (a type of endonuclease) induces a cut in one strand of DNA (Nicking) to relax the two strands of DNA.
A protein, ''Helix destabilizing protein'' prevents recoiling of two separated strands during the process of replication. An another protein SSB (single stranded DNA binding protein) prevents the formation of bends of loops in separated strands.
DNA-Gyrase – A type of topoisomerase prevent supercoiling of DNA.
Note –
The process of D.N.A replication takes a few minutes in prokaryotes and few hours in Eukaryotes.
(2) Formation of New Chain –
To start the synthesis of new chain, special type of R.N.A. is required which is termed as R.N.A Primer. The formation of R.N.A. primer is catalysed by an enzyme – R.N.A. Polymerase (primase) Synthesis of RNA – primer takes place in 5' ® 3'' direction. After the formation of new chain, this R.N.A. is removed. For the formation of new chain Nucleotides are obtained from Nucleoplasm. In the nucleoplasm, Nucleotides are present in the form of triphosphate like dATP, dGTP, dCTP, dTTP etc.
During replication, the 2 phosphate groups of all Nucleotides are separated. In this process energy is yielded which is consumed in D.N.A replication. So, it is clear that D.N.A. does not depend on mitochondria for it's energy requirements.
The formation of new chain always takes place in 5' - 3'' direction. As a result of this, one chain of D.N.A is continuously formed and it is termed as Leading strand. The formation of second chain begins from the centre and not from the terminal points, so this chain is discontinuous and is made up of small segement called Okazaki Fragments. This discontinous chain is termed as Lagging strand. Ultimately all these segments joined together and complete new chain is formed.
The Okazaki segment are joined together by an enzyme DNA Ligase. (Khorana)
The formation of new chains is catalysed by an enzyme DNA polymerase. In prokaryotes it is of 3 types :
(1) DNA - Polymerase I : This was discovered by KORNBERG (1957). So it is also called as ' Kornberg 's enzyme'. Kornberg also synthesized DNA first of all, in the laboratory. This enzyme functions
as exonuclease. It separates RNA – primer from DNA and also fills the gap. It is also known as
DNA- repair enzyme.
(2) DNA - Polymerase II : It is least reactive in replication process. It is also helpful in DNA-repairing in absence of DNA-polymerase-I and DNA polymerase-III
(3) DNA - Polymerase III : This is the main enzyme in DNA – Replication . It is most important. It was discovered by Delucia and Cairns. The larger chains are formed by this enzyme. This is also known as Replicase.
DNA – polymerase III is a complex enzyme composed of seven polypeptides a, e, q, b, g, d, g2.
In Eucaryotes, there occur five types of DNA-polymerase enzyme.
(i) a-DNA – polymerase = Similar to DNA – polymerase I
(ii) b-DNA – polymerase = It concerned with DNA repair.
(iii) g-DNA – polymerase = It concerned with replication of cytoplasmic DNA
(iv) d-DNA – polymerase = Similar to DNA – polymerase II
(v) e-DNA – polymerase = Similar to DNA – polymerase III
Thus DNA – Replication process is completed with the effect of different enzymes.
In the semi conservative mode of replication each daughter DNA molecule receives one chain of polynucleotides from the mother DNA – molecule and the second chain is synthesized.
Special Point :
All DNA polymerase I, II and III enzymes have 5'-3'' polymerisation activity and 3'-5'' exonuclease activity.
TRANSCRIPTION :
Formation of RNA over DNA templet is called transcription. Out of two strand of DNA only one strand participates in transcription and called ''Antisense strand''.
The segment of DNA involved in transcription is ''Cistron''.
RNA polymerase enzyme involved in transcription. In eukaryotes there are three types of RNA polymerases.
· RNA polymerase-I for 28s rRNA, 18s RNA, 5.8s rRNA
· RNA polymerase-II for m-RNA.
· RNA polymerase enzyme-III for t-RNA, 5s RNA, SnRNA
In eukaryotes RNA polymerase enzyme composed of 10-15 polypeptide chains.
Prokaryotes have one type of RNA polymerase which synthesizes all types of RNAs.
RNA polymerase of E. Coli has six polypeptide chains b, b', a, a, w and s.
s polypeptide chain is also known as s factor (sigma factor).
Core enzyme + Sigma factor Þ RNA Polymerase
(b, b', a, a, w) + (s)
Following steps are present in transcription –
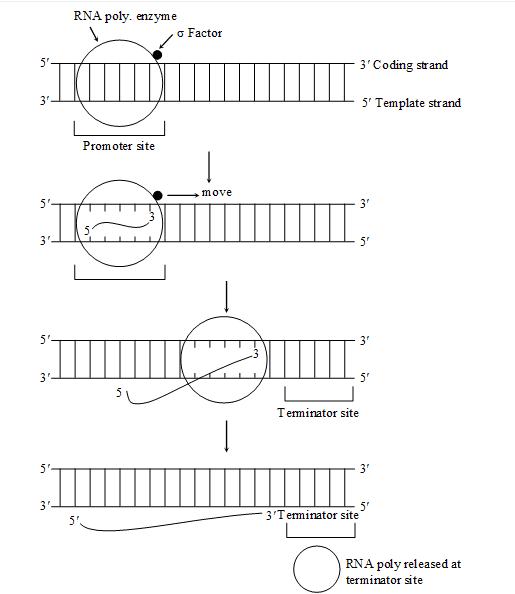
(1) INITIATION –
DNA has a ''Promoter site or initiation site'' where transcription begins and a ''Terminator site'' where transcription stops.
Sigma factor (s) recognizes the promoter site of DNA.
With the help of sigma factor RNA polymerase attached to a specific site of DNA called ''Promoter site'' .
In prokaryotes before the 10 N2 base from ''Structural site'' a sequence of 6 base pairs (TATAAT) is present on DNA, Which is called ''Pribnow box''.
In eukaryotes before the 20 N2 base from ''Structural site'' a sequence of 7 base pairs (TATAAA) or (TATATAT) is present on DNA which is called ''TATA box or Hogness box''
At promoter site RNA polymerase enzyme breaks H-bonds between two DNA strands and separates them One of them strand takes part in Transcription. Transcription proceeds in 5' ® 3'' direction.
Ribonucleotide triphosphate come to lie opposite complementary nitrogen bases of anti sense strand.
These Ribonucleotides present in the form of triphosphate ATP, GTP, UTP and CTP in nucleoplasm. When they used in transcription, pyrophosphates hydrolyse two phosphates from each activated nucleotide. This releases energy.
This energy used in process of transcription.
(2) ELONGATION –
RNA polymerase enzyme establishes phosphodiester bond between adjacent ribonucleotides.
Sigma factor separates and core enzyme moves along the anti sense strand till it reaches terminator site.
(3) TERMINATION –
When RNA polymerase enzyme reaches at terminator site, it separates from DNA templet.
In terminator site on DNA, N2 bases are present in palindromic sequence.
In most cases RNA polymerase enzyme can recognize the ''Terminator site'' and stop the synthesis of RNA chain, but in prokaryotes, it recognizes the terminator site with the help of Rho factor (r factor).
Rho (r) factor is a specific protein which helps RNA polymerase enzyme to recognize the terminator site.
PROTEIN-SYNTHESIS :
- Activation of Amino acid –
20 types of amino acid participate in protein synthesis.
Amino acid reacts with ATP to form ''Amino acyl AMP enzyme complex'', which is also known as 'Activated Amino acid.'
This reaction is catalyzed by a specific 'Amino acyl t-RNA synthetas' enzyme
There is a separate 'Amino acyl t-RNA synthetase' enzyme for each kind of amino acid.
(2) Charging of t-RNA –
Specific activated amino acid is recognized by its specific t-RNA.
Now amino acid attaches to the 'Amino acid attachment site' of its specific t-RNA and AMP and enzyme are separated from it.
Amino acyl t-RNA complex is also called 'Charged t-RNA'
Now Amino acyl t-RNA moves to the ribosome for protein synthesis
(3) Translation :
(A) Initiation of polypeptide chain
In this step 30 's' and 50 's' sub units of Ribosome, GTP, Mg+2, charged t-RNA, m-RNA and some
initiation factors are required
In prokaryotes there are three initiation factors present – IF1, IF2, IF3
In Eukaryotes there are more than 3 initiation factors are present. 16 initiation factors have been identified in red blood cells–
elF1, elF2, elF3, elF4A, elF4B, elF4C, elF4D, elF4F, elF5, elF6
Initiation factors are specific protein.
GTP and initiation factors promote the initiation process.
In starting the both sub units of ribosome are separated with the help of IF3 factor.
In prokaryotes with the help of "S D sequences" (Shine-Delgarno sequence) m-RNA recognizes the smaller sub unit of ribosome. A sequence of 8 N2 base is present before the 4-12 N2 base of initiation Condon on mRNA, called "SD sequence" In smaller subunit of ribosome, a complementary sequence of "SD sequence" is present on 16 'S' rRNA, which is called "Anti Shine-delgarno sequence"
(ASD sequence)
With the help of 'SD' and 'ASD' sequence m-RNA recognizes the smaller sub unit of ribosome.
While in Eukaryotes smaller sub unit of ribosome is recognised by "7mG cap"
In Eukaryotes, 18 'S' rRNA of smaller sub unit has a complementary sequence of "7mG cap"
This "30 'S' m–RNA – complex" reacts with 'Formyl methionyl t-RNA–complex' and "30 'S' mRNA –Formyl methionyl t-RNA–complex" form. This t–RNA attaches with codon part of m–RNA. A GTP molecule is required.
Now larger sub unit of ribosome (50'S' Sub unit) joins this complex. The initiation factor released and complete 70 'S' ribosome is formed.
In larger sub unit of ribosome there are three sites for t-RNA
'P' site = Peptidyl site
'A' site = amino acyl site
E-site = exit site
Starting codon of m-RNA is near to 'P' site of ribosome, so t-RNA with formyl methionine amino acid first attached to 'P' site of ribosome and next codon of m-RNA is near to 'A' site of ribosome. So new t-RNA with new amino acid always attach at 'A' site of ribosome but in initiation step 'A' site is empty
(B) Chain elongation
New tRNA with new Amino acid at 'A' site of Ribosome.
First of all t-RNA of P-site is discharged so-COOH of p-site A.A. becomes free.
Now peptide bond formation takes place between –COOH group of P site amino acid and –NH2 group of A site amino acid.
Peptidyl transferase enzyme induces the formation of peptide bond. In Peptide bond formation, a
23 'S' r-RNA, 28 'S' r-RNA in eukaryotes is also helpful. This r-RNA acylt acts as an enzyme so it is also called "Ribozyme"
After formation of peptide bond t-RNA of P site released from ribosome via E-site and dipeptide attaches with A site.
Now t-RNA of A site is transferred to P site and A site becomes emplty.
Now ribosome slides over m-RNA strand in 5' ® 3" direction. Due to sliding of ribosome on m-RNA, new condon of m–RNA continously available at A site of ribosome and according to new codon of
m-RNA new amino acid attaches in polypeptide chain.
Translocase enzyme helpful in movement of ribosome. GTP provides energy for sliding of ribosome.
In elongation process some protein factors are also helpful, which known as 'Elongation factors'
In prokaryotes three 'Elongation factors' are present –EF – Tu, EF – Ts, EF – G.
In Eukaryotes two elongation factors are present–eEF1, eEF2.
(C) Chain – Termination
Due to sliding of ribosome over m–RNA when any Nonsense codon (UAA, UAG, UGA) available at A site of ribosome, then polypeptide chain terminate.
The linkage between the last t-RNA and the polypeptide chain is broken by three release factor called RF1, RF2, RF3 with the help of GTP.
Peptidyl transferase enzyme also catalysed the releasing process.
In eukaryotes only one Release factor is known – eRF1.
GENETIC CODE :
Term Given by George Gamow.
E The relationship between the sequence of amino acids in a polypeptide chain and nucleotide sequence of DNA or m-RNA is called genetic code.
E There occur 20 types of amino acids which participate in protein synthesis. DNA contains information for the synthesis of any types of polypeptide chain. In the process of transcription, information transfer from DNA to m-RNA in the form of complementary N2-base sequence.
E m-RNA contains code for each amino acid and it is called codon. A codon is the nucleotide sequence in
m-RNA which codes for particular amino acid ; wherease the genetic code is the sequence of nucleotides in m-RNA molecule, which contains information for the synthesis of polypeptide chain.
Triplet Code –
E The main problem of genetic code was to determine the exact number of nucleotide in a codon which codes for one amino acid.
E There are four types of N2-bases in m-RNA (A, U, G, C) for 20 type amino acids.
Fig : Triplet codons of mRNA for amino acids represented in tabular form.
E If genetic code is singlet i.e. codon is the combination of only one nitrogen base, then only four codons are possible A, C, G and U. These are insufficient to code for 20 types amino acids.
· Singlet code = 4' = 4 × 1 = 4 codons
· If genetic code is doublet (i.e. codon is the combination of two nitrogen bases) then 16 codons are formed.
· Doublet code = 42 = 4 × 4 = 16 codons.
· 16 codons insufficient for 20 amino acid
Gamow –
(1954) Pointed out the possibility of three letter code (Triplet code).
Genetic code is triplet i.e. one codon consists of three nitrogen base.
Triplet code = 43 = 4 × 4 × 4 = 64 codons
In this case there occurs 64 codons in dictionary of genetic code.
64 codons are sufficient to code 20 types of amino acids.
Characteristic of Genetic Code –
(1) Triplet in Nature
E A codon is composed of three adjacent nitrogen bases which specifies the one amino acid in polypeptide chain.
For Ex. :
· In m-RNA if there are total 90 N2 – bases.
· Then this m-RNA determines 30 amino acids in polypeptide chain.
· In above example, number of Nitrogen bases are 90 so codons Þ 30 and 30 codons decide 30 amino acid in polypeptide chain.
(2) Universality
The genetic code is applicable universally. The same genetic code is present in all kinds of living organism including viruses, bacteria, unicellular and multicellular organism.
(3) Non-Ambiguous –
Genetic code is non ambiguous i.e. one codon specifies only one amino acid and not any other.
In this case one codon never code two different amino acids. Exception GUG codon which code both valine and methionine amino acid.
(4) Non-Overlapping –
A nitrogen base is a constituent of only one codon.
(5) Comma less –
There is no punctuation (comma) between the adjacent codon i.e. each codon is immediately followed by the next codon.
If a nucleotide is deleted or added, the whole genetic code read differently.
A Polypeptide chain having 50 amino acids shall be specialized by a linear sequence of 150 nucleotides. If a nucleotide is added in the middle of this sequence, the first 25 amino acids of polypeptide will be same but next 25 amino acids will be different.
(6) Degeneracy of Genetic code –
There are 64 codons for 20 types of amino acids, so most of the amino acids (except two) can be coded by more than one codon. Single amino acid coded by more than one codon is called ''Degeneracy of genetic code''. This incident was discovered by Baurnfield and Nirenberg.
Only two amino acids Tryptophan and Methionine are specified by single codon.
All the other amino acid are specified or coded by 2 to 6 codons.
Leucine, serine and arginine are coded or specified by 6-codons.
Leucine = CUU, CUC, CUA, CUG, UUA & UUG
Serine = UCU, UCC, UCA, UCG, AGU, AGC
Arginine = CGU, CGC, CGA, CGG, AGA, AGG
Degeneracy of genetic code is related to third position (3' – end of triplet codon). The third base is described as ''Wobby base''
Exception –
Different Codon –
Normally UAA and UGA are chain termination codon but in Paramecium and some other ciliated, UAA and UGA code for glutamine amino acid.
Mitochondrial Gene –
Normally AGG and AGA code for Arginine amino acid but in human mitochondria these function as stop codon.
UGA, a termination codon corresponds to tryptophan while AUA (Codon for isoleucine) denotes methionine in human mitochondria.
Chain Initiation and Chain Termination Codon –
Polypeptide chain synthesis is signalled by two initiation codons AUG or GUG.
AUG codes methionine amino acid in eukaryotes and in prokaryotes AUG codes N-formyl methionine.
Some times GUG also functions as start codon it codes for valine amino acid normally but when it is present at starting position it code for methionine amino acid.
E Out of 64 codons 3-codons are stopping or nonsense or termination codon.
Nonsense codons do not specify any amino acid.
UAA (Ochre)
UAG (Amber) Non-Sense Codon
UGA (Opal)
So only 61 codons are sense codons which specify 20 amino acid.
WOBBLE HYPOTHESIS :
It was propounded by CRICK.
Normally an anticodon recognizes only one codon, but sometimes an anticodon recognise more than one codon. This known as Wobbling. Wobbling normally occurs for third nucleotide of codon.
For e.g. Anticodon AAG can recognize two anticodons i.e. UUU and UUC, both stand for phenyl alanine.
Types of m-RNA – m-RNA is of 2 types –
- Monocistronic – The m- RNA in which genetic signal for the formation of only one polypeptide chain.
(2) Polycistronic – The m-RNA, in which genetic signal is present for the formation of more than one polypeptide chains.
E Non sense codons are found in middle position in polycistronic m-RNA.
CENTRAL DOGMA :
Central dogma term was given by Crick.
The formation (production) of m-RNA from DNA and then synthesis of protein from it, is known as Central Dogma.
It means, it includes transcription and translation.
The central dogma scheme of protein synthesis was presented by Jacob and Monad.
The delailed study of central dogmas is done by Nirenberg, Mathai and Khorana.
Beedle and Tatum studied central dogma in a fungus Neurospora.
Reverse Transcription –
E The formation of DNA from RNA is known as Reverse - transcription. It was discovered by Temin and Baltimore in Rous – sarcoma virus. So it is also called Teminism.
E ss-RNA of Rous-Sarcoma virus (Retro virus) produces ds-DNA in host's cell with the help of enzyme reverse transcriptase (DNA Polymerase). This DNA is called c-DNA (Complimentary DNA). Some times this DNA moves in host genome. Such mobile DNA is called ''Retroposon'' (Oncogene).
SPECIAL POINTS :
(1) The chargraff's rule is not valid (true) for RNA. It is valid only for double helical DNA.
(2) The duplication of DNA was first of all proved in E. coli bacterium.
(3) E. coli Bacterium is mostly used for the study of DNA duplication.
(4) Hargovind singh Khurana first of all recognized the triple codon for Cysteine and Valine amino acids
(5) Cytoplasmic DNA is 1-5% of total cells DNA.
(6) Three lady scientists named Avery, Mc–Leod and Mc Carty (by their transrformation experiments on bacteria) proved that DNA is a genetic material.
(7) Hershey and chase first of all proved that DNA is genetic material in bacteriophages.
(8) Frankel and Conret proved, RNA as a genetic material in viruses (g-RNA).
(9)
(10) The structure formed by the combination of m-RNA and Ribosomes is known as polyribosomes / Polysomes / Ergosomes.
(11) The formation of t-RNA takes place from the heterochromatin part of DNA.
(12) The formation of m-RNA takes place from the Euchromatin part of DNA.
(13) m-RNA is least stable. It is continuosly formed and finished.
(14) In cytoplasm, t-RNA is present in the form of soluble colloid
(15) Nucleases – These breaking enzyme of nucleic acids are of two types.
(i) Endo – Nucleases – These break down the nucleic acids from the inside.
(ii) Exo-nucleases – These break down the nucleic acids from the ends (terminals ends)
These separate each nucleotide
(16) Tay–Sachs–diseases
This disease takes place due to excess storage of glycolipids
(17) Excess storage of cerebrosides leads to Guacher's disease
Some Inhibitors of Bacterial Protein Synthesis
Antibiotic
Effect
Tetracycline
Inhibits binding of amino-acyl tRNA to ribosome
Streptomycin
Inhibits initiation of translation and causes misreading
Chloramphenicol
Inhibits peptidyl transferase and so formation of peptide bonds
Erythromycin
Inhibits translocation of ribosome along mRNA
Neomycin
Inhibits interaction between t-RNA and mRNA
(19) Spilt gene : Discovered by sharp and Roberts in Adenovirus 2 They were awarded by Nobel Prize in 1993. Gene which contains non functional part along with functional part is known as split gene. Non functional part is called intron and functional part is called exon. By transcription split gene produces a RNA which contains coding and non coding sequence and called hn RNA (Hetero genous nuclear RNA)/ This hn RNA is unstable. Now 200 nucletides of adenylic acid are added to its 3' end, which is called poly 'A' tail. Now it becomes stable. 7 methyl guanosine is also added to its 5' end a cap like structure is formed. It is called capping. By the process of RNA splicing hn-RNA produces functional RNA that is exonic RNA. In RNA splicing non coding parts removed with the help of ribonuclease enzyme and coding part join together with the help of RNA ligase. Some specific proteins are also helpful in RNA-splicing called 'Small nuclear ribonucleoprotein' or 'SnRNP' or 'Snurps'. These SnRNP proteins combine with some other proteins and SnRNA and form spliceosome complex. This spliceosome complex uses energy of ATP to cut the RNA, releases the non-coding part and joins the coding-part to produce functional RNA.
Noncoding part of hn RNA remained inside the nucleus and not translated into protein. Only coding part moves from nucleus to cytoplasm and translated into protein.
Mostly prokaryotic genes are example of non split gene.
Special Points
E In human mitochondria, 4 initiation codons present : AUG, AUA, AUU, AUC.
E Higher Energy Nucleotide : Nucleotides which contain more than one phosphate i.e. ATP, ADP.
ATP : Discover-Karl Lohmann. It is made up by Adenine, D-Ribose and three phosphate. It is a high energy compound that release energy when the bond between the phosphate is broken. In ATP two high energy bonds are present. ATP is also called energy currency of cell.
E Iodine number : It is the amount of iodine in gram absorbed by 100 gram fat. It is used to determine the degree of unsaturation of fat
E Second genetic code : Interaction between specific t-RNA and amino acyl synthetase enzyme is known as second genetic code.
GLUT-4 (Glucose transport 4) Proteins : It is a transport protein that allows glucose to enter a cell. GLUT-4 moves into the plasma membrane in response to insulin or muscle contraction. When amount of glucose increased in blood, more insulin is secreted GLUT-4 then responds to the presence of the insulin and enters the plasma membrane, allowing glucose to enter the cell.
E DNA-quenching : Rapid cooling of denatured DNA, fix it in permanently denatured from, it is called DNA quenching.
E f × 174 bacteriophage has 5386 nucleotides, l-bacteriophage has 48502 base pairs, Escherichia coli has 4.6 × 106 base pair and 6.6 ×106 base pairs in human (2n).
E 2-OH groups present at everynucleotide in RNA as reactive group and makes RNA labile and easily degradable and RNA also has catalytic function so it is more reactive. DNA is chemically less reactive and structurally more stable as compared to RNA.
- DNA is more stable so preferred for storage of genetic information but for the transmission of genetic information RNA is better.
- An mRNA also have some additional sequences that are not translated and are referred as untranslated regions (UTR). The UTRs are present at both 5'end (before start codon) and at 3' end (after stop codon).
- Mic RNA : It is synthesized sometime on the sense of DNA which is complementary of Antisense strand which is used for mRNA synthesis. Such RNA is used for regulation of gene expression at the level of translation.
- RNA Interference : It is a method of gene silencing. In this method a ds RNA is inserted in a cell and enzyme Dicer break this ds RNA into small ds fragments of 20-25 base pairs with a few unpaired overhang bases on each end. This short ds fragments are called small interfering RNA (si RNA). Now siRNA associated with specific protein to form a complex RISC (RNA induced silencing complex). Now RISC attached with targeted m-RNA and inhibit its translation.
- For RNA-interference in Caenorhabditis elegans Andrew fire and Craig C. Mello got Noble Prize in 2006 in physiology and medicine.
FAQs on Protoplasm - Biomolecules, Biology, Class 11
| 1. What are biomolecules? |  |
| 2. What is the significance of protoplasm in biology? | |
| 3. How are biomolecules related to protoplasm? | |
| 4. What is the role of proteins in protoplasm? | |
| 5. How do nucleic acids contribute to the protoplasm? | |



Class 11
,Biology
,Summary
,Important questions
,Class 11
,Class 11
,Biology
,MCQs
,mock tests for examination
,Sample Paper
,Protoplasm - Biomolecules
,video lectures
,practice quizzes
,shortcuts and tricks
,Viva Questions
,past year papers
,Semester Notes
,Protoplasm - Biomolecules
,Previous Year Questions with Solutions
,Protoplasm - Biomolecules
,Objective type Questions
,study material
,Biology
,ppt
,Extra Questions
,Free
,Exam
;


Protoplasm - Biomolecules, Biology, Class 11 Free PDF Download
Importance of Protoplasm - Biomolecules, Biology, Class 11
Protoplasm - Biomolecules, Biology, Class 11 Notes
Protoplasm - Biomolecules, Biology, Class 11 Class 11 Questions
Study Protoplasm - Biomolecules, Biology, Class 11 on the App
|
© EduRev
|
Education Revolution
|



|






within 7 days!