
Best Study Material for Computer Science Engineering (CSE) Exam
Computer Science Engineering (CSE) Exam > Computer Science Engineering (CSE) Notes > Theory of Computation > Regular Expression to DFA
Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE) PDF Download
| Table of contents |
|
| Finite automata |
|
| Rules for Conversion of Regular Expression to NFA |
|
| Ɛ –closure |
|
| Sub-set Construction |
|
| Direct Method |
|
| Computation of followpos |
|
Finite automata
Language Recognizer: A program that accepts a string x and determines whether x is a sentence in a particular language, responding with "yes" or "no".
Regular Expression to Recognizer Conversion: This involves creating a Finite Automaton (FA) from a regular expression to function as a recognizer.
Finite Automata (FA): Finite Automata can be either:
- Non-deterministic Finite Automata (NFA): Characterized by multiple transitions for a single input symbol from a state, including transitions on an empty string (Ɛ).
- Deterministic Finite Automata (DFA): Defined by a single transition for each state and input symbol combination.
Components of Finite Automata: Represented as M=(Q,Σ,q0,F,δ), where:
- Q is the Set of states.
- Σ is the Set of input symbols.
- q0 is the Start state.
- F is the Set of final states.
- δ is the Transition function, mapping states to input symbols, represented as
δ:Q×Σ→Q.
Regular Expression to DFA Conversion Methods:
- Thompson’s Subset Construction:
- Converts a given regular expression into an NFA.
- Then transforms the resultant NFA into a DFA.
- Direct Method:
- Directly converts a given regular expression into a DFA.
- Thompson’s Subset Construction:
Rules for Conversion of Regular Expression to NFA
Union in Regular Expressions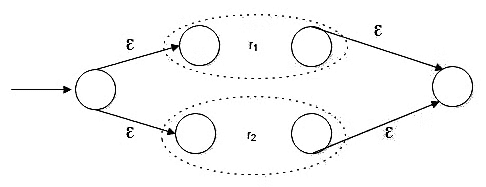
- Expressed as r=r1+r2.
- Represents the union operation, where r is a regular expression that matches either r1 or r2.
Concatenation in Regular Expressions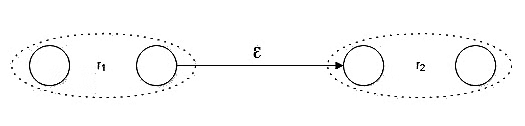
- Denoted by r=r1r2.
- Signifies the concatenation operation, where r is a regular expression that matches the sequence of r1 followed by r2.
Closure in Regular Expressions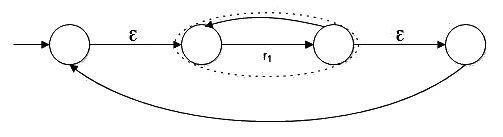
- Indicated as r=r1∗.
- Refers to the closure operation, where r is a regular expression that matches zero or more consecutive occurrences of r1.
Ɛ –closure
Ɛ-Closure Definition:
Ɛ-Closure refers to the set of states in a Non-deterministic Finite Automaton (NFA) that can be reached from a given state by traversing paths that consume the empty string (Ɛ). It describes the transitions that occur without consuming any input symbol.
Examples of Ɛ-Closure:
Example 1: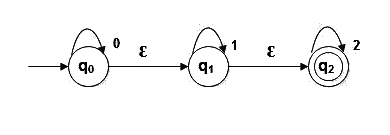
- Ɛ-Closure(q0) = { q0, q1, q2 }: From state q0, states q0, q1, and q2 are reachable by paths that consume an empty string.
- Ɛ-Closure(q1) = { q1, q2 }: From state q1, states q1 and q2 are reachable by paths that consume an empty string.
- Ɛ-Closure(q2) = { q0 }: From state q2, state q0 is reachable by a path that consumes an empty string.
Example 2: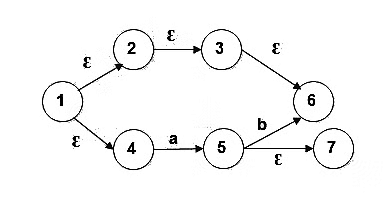
- Ɛ-Closure(1) = {1, 2, 3, 4, 6}: From state 1, states 1, 2, 3, 4, and 6 are reachable by paths that consume an empty string.
- Ɛ-Closure(2) = {2, 3, 6}: From state 2, states 2, 3, and 6 are reachable by paths that consume an empty string.
- Ɛ-Closure(3) = {3, 6}: From state 3, states 3 and 6 are reachable by paths that consume an empty string.
- Ɛ-Closure(4) = {4}: From state 4, state 4 is reachable by a path that consumes an empty string.
- Ɛ-Closure(5) = {5, 7}: From state 5, states 5 and 7 are reachable by paths that consume an empty string.
- Ɛ-Closure(6) = {6}: From state 6, state 6 is reachable by a path that consumes an empty string.
- Ɛ-Closure(7) = {7}: From state 7, state 7 is reachable by a path that consumes an empty string.
Sub-set Construction
Initial NFA Creation: Begin by transforming the given regular expression into a Non-deterministic Finite Automaton (NFA). This is achieved by applying standard rules for operators like union, concatenation, and closure, while respecting their precedence.
Epsilon-Closure Identification: Determine the epsilon-closure (Ɛ-closure) for every state in the NFA. The epsilon-closure of a state includes the state itself and any states that can be reached from it through epsilon transitions (transitions that don’t consume any input symbol).
Starting with Epsilon-Closure: Consider the epsilon closure of the NFA’s starting state as your initial point.
Transition Function Application: For each state and input symbol, apply the transition function. This involves moving from a state using an input symbol and then finding the epsilon-closure of the resulting state. The formula for the transition function in a Deterministic Finite Automaton (DFA) is: Dtran[state, input symbol] = Ɛ-closure(move(state, input symbol)), where Dtran represents the DFA's transition function.
State Analysis: After applying the transition function, analyze the resultant state to ascertain if it is a newly encountered state in the context of the DFA.
Iterative State Exploration: If a new state is discovered, continue applying steps 4 and 5 iteratively until no further new states emerge.
Transition Table Construction: Create a transition table for the DFA's transition function (Dtran), which maps combinations of states and input symbols to resulting states.
DFA Transition Diagram: Finally, draw the transition diagram for the DFA. This diagram should start from the epsilon-closure of the NFA’s starting state and conclude at a final state, which includes the NFA’s final state.
These steps systematically guide the conversion from a regular expression to a DFA, ensuring a thorough and accurate process.
 |
Download the notes
Regular Expression to DFA
|
Download as PDF |
Download as PDF
Direct Method
- Direct Conversion Method: The direct method is employed to transform a given regular expression straight into a Deterministic Finite Automaton (DFA), bypassing the intermediate step of creating a Non-deterministic Finite Automaton (NFA).
- Augmented Regular Expression: This process utilizes an augmented regular expression, denoted as r#, to facilitate the conversion.
- NFA States and Regular Expression Positions: In this method, the significant states of the corresponding NFA are associated with positions in the regular expression that contain alphabet symbols.
- Syntax Tree Representation: The regular expression is represented as a syntax tree. In this tree, interior nodes correspond to operators that signify union, concatenation, and closure operations.
- Leaf Nodes: The leaf nodes of the syntax tree represent the input symbols of the regular expression.
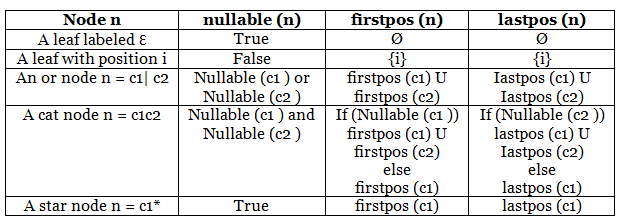
- Direct DFA Construction: The DFA is constructed directly from the regular expression by calculating specific functions from the syntax tree. These functions are nullable(n), firstpos(n), lastpos(n), and followpos(i).
- Nullable Function: The nullable(n) function is true for nodes marked with an asterisk (*) and for nodes labeled with epsilon (Ɛ). For all other nodes, this function is false.
- Firstpos Function: The firstpos(n) function is a set of positions at node 'n' that correspond to the first symbol of the sub-expression rooted at 'n'.
- Lastpos Function: The lastpos(n) function identifies a set of positions at node 'n' that correspond to the last symbol of the sub-expression rooted at 'n'.
- Followpos Function: The followpos(i) function determines a set of positions that follow a given position, matching the first or last symbol of a string generated by the sub-expression of the regular expression.
- Computational Rules: There are specific rules for computing the functions nullable, firstpos, and lastpos, which are vital for this direct conversion process.
- Rules for computing nullable, firstpos and lastpos
 |
Take a Practice Test
Test yourself on topics from Computer Science Engineering (CSE) exam
|
Practice Now |
Practice Now
Computation of followpos
Rule for Concatenation (Cat) Nodes:
- In a syntax tree, if 'n' represents a concatenation (cat) node with a left child 'c1' and a right child 'c2', then a specific relationship between their positions is established.
- For every position 'i' that is in the lastpos(c1), which means the set of positions corresponding to the last symbol of the sub-expression rooted at the left child 'c1', every position in firstpos(c2) will be included in followpos(i).
- This rule implies that in a concatenation node, each position 'i' in the last set of positions of its left child directly leads to (or is followed by) all the positions in the first set of positions of its right child.
Rule for Star (*) Nodes:
- When dealing with a star (*) node, denoted as 'n', a different rule applies.
- If 'i' is a position in lastpos(n), meaning it's in the set of positions corresponding to the last symbol of the sub-expression rooted at the star node, then all positions in firstpos(n) are included in followpos(i).
- Essentially, this rule states that for a star node, the set of positions at the beginning (firstpos) of that node will be in the follow set (followpos) of every position in the last set (lastpos) of that node.
These rules are essential for understanding the relationship between different positions in a regular expression, particularly in the context of constructing a DFA directly from a regular expression's syntax tree. They define how positions are linked in the context of concatenation and closure operations within the regular expression.
The document Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE) is a part of the Computer Science Engineering (CSE) Course Theory of Computation.
All you need of Computer Science Engineering (CSE) at this link: Computer Science Engineering (CSE)
|
18 videos|70 docs|44 tests
|


FAQs on Regular Expression to DFA - Theory of Computation - Computer Science Engineering (CSE)
| 1. What is a regular expression? |  |
| 2. What is the role of regular expressions in Computer Science Engineering (CSE)? | |
Ans. Regular expressions play a crucial role in CSE as they are used for tasks such as pattern matching, text searching, and string manipulation. They provide a powerful and efficient way to perform complex operations on strings, making them an essential tool for CSE professionals.
| 3. How can regular expressions be converted into DFA (Deterministic Finite Automaton)? | |
Ans. Regular expressions can be converted into DFA using a process called the Thompson's Construction algorithm. This algorithm involves creating a set of states and transitions based on the regular expression, resulting in a DFA that can efficiently recognize strings matching the given pattern.
| 4. What are the advantages of using regular expressions in CSE? | |
Ans. Regular expressions offer several advantages in CSE. They provide a concise and flexible way to describe patterns, making it easier to search for specific strings or patterns in large amounts of data. Regular expressions also allow for efficient string manipulation, enabling tasks such as data validation, text extraction, and data transformation.
| 5. Can regular expressions be used for more than just string manipulation? | |
Ans. Yes, regular expressions can be used for more than just string manipulation. They can also be applied to tasks such as lexical analysis, parsing, and pattern recognition. Regular expressions provide a versatile toolset that can be utilized in various domains of computer science engineering, extending their usefulness beyond simple string operations.
Related Exams
About this Document

4.83/5
Rating

Apr 11, 2025
Last updated
Document Description: Regular Expression to DFA for Computer Science Engineering (CSE) 2025 is part of Theory of Computation preparation.
The notes and questions for Regular Expression to DFA have been prepared according to the Computer Science Engineering (CSE) exam syllabus. Information about Regular Expression to DFA covers topics
like Finite automata, Rules for Conversion of Regular Expression to NFA, Ɛ –closure, Sub-set Construction, Direct Method, Computation of followpos and Regular Expression to DFA Example, for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Regular Expression to DFA.
Introduction of Regular Expression to DFA in English is available as part of our Theory of Computation
for Computer Science Engineering (CSE) & Regular Expression to DFA in Hindi for Theory of Computation course.
Download more important topics related with notes, lectures and mock test series for Computer Science Engineering (CSE)
Exam by signing up for free. Computer Science Engineering (CSE): Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE)
Description
Full syllabus notes, lecture & questions for Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE) - Computer Science Engineering (CSE) | Plus excerises question with solution to help you revise complete syllabus for Theory of Computation | Best notes, free PDF download
Information about Regular Expression to DFA
In this doc you can find the meaning of Regular Expression to DFA defined & explained in the simplest way possible. Besides explaining types of
Regular Expression to DFA theory, EduRev gives you an ample number of questions to practice Regular Expression to DFA tests, examples and also practice Computer Science Engineering (CSE)
tests

Related Searches
MCQs
,Previous Year Questions with Solutions
,ppt
,Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE)
,mock tests for examination
,Semester Notes
,video lectures
,past year papers
,Extra Questions
,Viva Questions
,Summary
,Free
,Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE)
,Objective type Questions
,shortcuts and tricks
,Regular Expression to DFA | Theory of Computation - Computer Science Engineering (CSE)
,study material
,Important questions
,practice quizzes
,Sample Paper
,Exam
;






Additional Information about Regular Expression to DFA for Computer Science Engineering (CSE) Preparation
Regular Expression to DFA Free PDF Download
The Regular Expression to DFA is an invaluable resource that delves deep into the core of the Computer Science Engineering (CSE) exam.
These study notes are curated by experts and cover all the essential topics and concepts, making your preparation more efficient and effective.
With the help of these notes, you can grasp complex subjects quickly, revise important points easily,
and reinforce your understanding of key concepts. The study notes are presented in a concise and easy-to-understand manner,
allowing you to optimize your learning process. Whether you're looking for best-recommended books, sample papers, study material,
or toppers' notes, this PDF has got you covered. Download the Regular Expression to DFA now and kickstart your journey towards success in the Computer Science Engineering (CSE) exam.
Importance of Regular Expression to DFA
The importance of Regular Expression to DFA cannot be overstated, especially for Computer Science Engineering (CSE) aspirants.
This document holds the key to success in the Computer Science Engineering (CSE) exam.
It offers a detailed understanding of the concept, providing invaluable insights into the topic.
By knowing the concepts well in advance, students can plan their preparation effectively.
Utilize this indispensable guide for a well-rounded preparation and achieve your desired results.
Regular Expression to DFA Notes
Regular Expression to DFA Notes offer in-depth insights into the specific topic to help you master it with ease.
This comprehensive document covers all aspects related to Regular Expression to DFA.
It includes detailed information about the exam syllabus, recommended books, and study materials for a well-rounded preparation.
Practice papers and question papers enable you to assess your progress effectively.
Additionally, the paper analysis provides valuable tips for tackling the exam strategically.
Access to Toppers' notes gives you an edge in understanding complex concepts.
Whether you're a beginner or aiming for advanced proficiency, Regular Expression to DFA Notes on EduRev are your ultimate resource for success.
Regular Expression to DFA Computer Science Engineering (CSE) Questions
The "Regular Expression to DFA Computer Science Engineering (CSE) Questions" guide is a valuable resource for all aspiring students preparing for the
Computer Science Engineering (CSE) exam. It focuses on providing a wide range of practice questions to help students gauge
their understanding of the exam topics. These questions cover the entire syllabus, ensuring comprehensive preparation.
The guide includes previous years' question papers for students to familiarize themselves with the exam's format and difficulty level.
Additionally, it offers subject-specific question banks, allowing students to focus on weak areas and improve their performance.
Study Regular Expression to DFA on the App
Students of Computer Science Engineering (CSE) can study Regular Expression to DFA alongwith tests & analysis from the EduRev app,
which will help them while preparing for their exam. Apart from the Regular Expression to DFA,
students can also utilize the EduRev App for other study materials such as previous year question papers, syllabus, important questions, etc.
The EduRev App will make your learning easier as you can access it from anywhere you want.
The content of Regular Expression to DFA is prepared as per the latest Computer Science Engineering (CSE) syllabus.
|
© EduRev
|
Education Revolution
|



|






Signup to see your scores
go up within 7 days!
Access 1000+ FREE Docs, Videos and Tests
Takes less than 10 seconds to signup