









All Exams >
NEET >
1 Year Dropper Course for NEET >
All Questions
All questions of Biomolecules for NEET Exam

Cellulose is made up of- a)Fructose
- b)Glucose
- c)Sucrose
- d)Ribose
Correct answer is option 'B'. Can you explain this answer?
Cellulose is made up of
a)
Fructose
b)
Glucose
c)
Sucrose
d)
Ribose
|
|
Ayush Chauhan answered |
Cellulose is a third polymer made from beta glucose molecules and the polymer molecules are straight cellulose serves a very different purpose in nature to starch and glycogen it make up the cell walls in plant cell.
The number of amino acids found in proteins are- a)20
- b)21
- c)18
- d)16
Correct answer is option 'A'. Can you explain this answer?
The number of amino acids found in proteins are
a)
20
b)
21
c)
18
d)
16
|
|
Rohan Singh answered |
Proteinogenic amino acids are amino acids that are incorporated biosynthetically into proteins during translation. ... Throughout known life, there are 22 genetically encoded (proteinogenic) amino acids, 20 in the standard genetic code and an additional 2 that can be incorporated by special translation mechanisms.
A homopolymer has only one type of building block called a monomer repeated ‘n’ number of times. A heteropolymer has more than one type of monomer. Proteins are heteropolymers made of amino acids. While a nucleic acid like DNA or RNA is made of only 4 types of nucleotide monomers, proteins are made of- a)20 types of monomers
- b)3 types of monomers
- c)40 types of monomers
- d)Only one type of monomer
Correct answer is option 'A'. Can you explain this answer?
A homopolymer has only one type of building block called a monomer repeated ‘n’ number of times. A heteropolymer has more than one type of monomer. Proteins are heteropolymers made of amino acids. While a nucleic acid like DNA or RNA is made of only 4 types of nucleotide monomers, proteins are made of
a)
20 types of monomers
b)
3 types of monomers
c)
40 types of monomers
d)
Only one type of monomer

|
Syed Hussain answered |
In living systems, like our own bodies, these larger molecules include carbohydrates, lipids, nucleic acids and proteins. The monomers of these organic groups are: Carbohydrates - monosaccharides. Lipids - glycerol and fatty acids
The most abundant organic molecule present on earth is- a)Protein
- b)Lipid
- c)Steroids
- d)Cellulose
Correct answer is option 'D'. Can you explain this answer?
The most abundant organic molecule present on earth is
a)
Protein
b)
Lipid
c)
Steroids
d)
Cellulose
|
|
Raghavendra Datta answered |
The most abundant organic molecule present on earth is cellulose.
What is Cellulose?
Cellulose is a complex carbohydrate that is found in the cell walls of plants. It is composed of repeating units of glucose molecules that are linked together to form long chains. These chains are then arranged in a way that gives cellulose its characteristic strength and rigidity.
Why is Cellulose Abundant on Earth?
Cellulose is abundant on earth for several reasons:
1. It is found in the cell walls of plants - Plants are the most abundant form of life on earth, and cellulose is a major component of their cell walls. This means that there is a huge amount of cellulose present on earth.
2. It is resistant to degradation - Unlike other organic molecules, cellulose is highly resistant to degradation by enzymes and other biological processes. This means that it can persist in the environment for a long time, contributing to its abundance.
3. It is a major component of biomass - Cellulose is a major component of the biomass of plants. When plants die and decompose, the cellulose in their cell walls is broken down into smaller molecules that can be used by other organisms. This means that there is a constant supply of cellulose being produced and broken down on earth.
Conclusion:
In conclusion, cellulose is the most abundant organic molecule present on earth due to its presence in the cell walls of plants, its resistance to degradation, and its role as a major component of biomass.
What is Cellulose?
Cellulose is a complex carbohydrate that is found in the cell walls of plants. It is composed of repeating units of glucose molecules that are linked together to form long chains. These chains are then arranged in a way that gives cellulose its characteristic strength and rigidity.
Why is Cellulose Abundant on Earth?
Cellulose is abundant on earth for several reasons:
1. It is found in the cell walls of plants - Plants are the most abundant form of life on earth, and cellulose is a major component of their cell walls. This means that there is a huge amount of cellulose present on earth.
2. It is resistant to degradation - Unlike other organic molecules, cellulose is highly resistant to degradation by enzymes and other biological processes. This means that it can persist in the environment for a long time, contributing to its abundance.
3. It is a major component of biomass - Cellulose is a major component of the biomass of plants. When plants die and decompose, the cellulose in their cell walls is broken down into smaller molecules that can be used by other organisms. This means that there is a constant supply of cellulose being produced and broken down on earth.
Conclusion:
In conclusion, cellulose is the most abundant organic molecule present on earth due to its presence in the cell walls of plants, its resistance to degradation, and its role as a major component of biomass.
The bacterial cell wall is formed of- a)Cellulose
- b)Hemicellulose
- c)Peptidoglycan
- d)Glycogen
Correct answer is option 'C'. Can you explain this answer?
The bacterial cell wall is formed of
a)
Cellulose
b)
Hemicellulose
c)
Peptidoglycan
d)
Glycogen
|
|
Pooja Shah answered |
Bacterial cell walls are made of peptidoglycan (also called murein), which is made from polysaccharide chains cross-linked by unusual peptides containing D-amino acids. Bacterial cell walls are different from the cell walls of plants and fungi which are made of cellulose and chitin, respectively.
Double hydrogen bond occurs in DNA between- a)Adenine and guanine
- b)Thymine and cytosine
- c)Adenine and thymine
- d)Uracil and thymine
Correct answer is option 'C'. Can you explain this answer?
Double hydrogen bond occurs in DNA between
a)
Adenine and guanine
b)
Thymine and cytosine
c)
Adenine and thymine
d)
Uracil and thymine
|
|
Gaurav Kumar answered |
The complementary base pairs of guanine with cytosine and adenine with thymine connect to one another using hydrogen bonds. In addition to holding the DNA strands together, the hydrogen bonding between the complementary bases also sequester the bases in the interior of the double helix. Since, the option of Guanine and Cytosine is not provided. Hence, the correct option is Option C.
A segment of DNA has 120 adenine and 120 cytosine bases. The total number of nucleotides present in the segment is- a)480
- b)240
- c)60
- d)120
Correct answer is option 'A'. Can you explain this answer?
A segment of DNA has 120 adenine and 120 cytosine bases. The total number of nucleotides present in the segment is
a)
480
b)
240
c)
60
d)
120
|
|
Pooja Shah answered |
According to Chargaff’s rule, the amount of adenine is always equal to that of thymine and the amount of guanine is always equal to that of cytosine.
A = T(120), G = C(120)
The total number of nucleotides would be 120 × 4 = 480.
The plant cell wall are made up of- a)Cellulose
- b)Starch
- c)Glycogen Bacteria
- d)Inulin
Correct answer is option 'A'. Can you explain this answer?
The plant cell wall are made up of
a)
Cellulose
b)
Starch
c)
Glycogen Bacteria
d)
Inulin

|
Srishti Sen answered |
Plant cell walls are made of cellulose. Paper made from plant pulp is cellulose.
The oils have- a)High melting point
- b)Low melting point
- c)Optimum melting point
- d)No melting point
Correct answer is option 'B'. Can you explain this answer?
The oils have
a)
High melting point
b)
Low melting point
c)
Optimum melting point
d)
No melting point
|
|
Geetika Shah answered |
Oils have lower melting point (e.g., gingely oil) and hence remain as oil in winters.
Proteins perform many physiological functions. For example, some function as enzymes. Which one of the following represents an additional function which some proteins discharge?- a)Antibiotics
- b)Pigments making colours of flowers
- c)Hormones
- d)Pigments conferring colour to skin
Correct answer is option 'C'. Can you explain this answer?
Proteins perform many physiological functions. For example, some function as enzymes. Which one of the following represents an additional function which some proteins discharge?
a)
Antibiotics
b)
Pigments making colours of flowers
c)
Hormones
d)
Pigments conferring colour to skin
|
|
Anjali Iyer answered |
Proteins perform many physiological functions. For example, some proteins function as enzymes. Hormones represents an additional function that some proteins discharge (like insulin).
Enormous diversity of protein molecules is due to- a)R groups of amino acids
- b)Sequence of amino acids
- c)Peptide bonds
- d)Amino groups of amino acids
Correct answer is option 'B'. Can you explain this answer?
Enormous diversity of protein molecules is due to
a)
R groups of amino acids
b)
Sequence of amino acids
c)
Peptide bonds
d)
Amino groups of amino acids
|
|
Rajat Kapoor answered |
The third is tertiary; this is the folding of the secondary structures into the final 3D structure of a protein. Amino acids have properties that guide this; some interact easily with water (hydrophilic) and these orient themselves on the outside of a protein, while others don't interact well with water (hydrophobic) and will try to get themselves on the inside of the folded structure where they will be protected. Hydrophobicity/philicity is the major driving force in protein folding but other bonds will also be formed between amino acids like S-S linkages, other ionic bonds and HYDROGEN BONDS (tons of these are made). These smaller interactions generally stabilize the protein and keep it folded in the most ideal conformation possible.
DNA nucleotides are attached by
- a)Hydrogen bond
- b)Covalent bond
- c)Van der Waals bond
- d)Electrovalent bond
Correct answer is option 'A'. Can you explain this answer?
DNA nucleotides are attached by
a)
Hydrogen bond
b)
Covalent bond
c)
Van der Waals bond
d)
Electrovalent bond
|
|
Gopikas S answered |
Explanation: DNA nucleotides are attached by the Hydrogen bond. A nucleotide is the basic unit of polynucleotide chain of DNA (deoxyribonucleic acid) or RNA (Ribonucleic acid).
The nitrogenous bases are found in the strand's inward direction. The nitrogenous bases of the two antiparallel strands form hydrogen bonds, resulting in the formation of two helical strands.
The nitrogenous bases used in DNA (double-stranded helical structure) are adenine (A), cytosine (C), guanine (G), and thymine (T).
Adenine is joined to thymine with two hydrogen bonds, whereas guanine is joined to cytosine by three hydrogen bonds.
Thus, DNA nucleotides are attached by Hydrogen bond.
The nucleotide chemical components are- a)Heterocyclic compounds, sugar and phosphate
- b)Sugar and Phosphate
- c)Heterocyclic compounds and sugar
- d)Phosphate and heterocyclic compounds
Correct answer is option 'A'. Can you explain this answer?
The nucleotide chemical components are
a)
Heterocyclic compounds, sugar and phosphate
b)
Sugar and Phosphate
c)
Heterocyclic compounds and sugar
d)
Phosphate and heterocyclic compounds

|
Akshat Chavan answered |
The nucleotide has three chemically distinct components. One is a heterocyclic compound, the second is a monosaccharide and the third a phosphoric acid or phosphate.
Which one is not a denaturing factor for protein?- a)High energy radiation
- b)High pressure
- c)Drastic change in pH
- d)High temperature
Correct answer is option 'B'. Can you explain this answer?
Which one is not a denaturing factor for protein?
a)
High energy radiation
b)
High pressure
c)
Drastic change in pH
d)
High temperature

|
Prasenjit Pillai answered |
Protein molecules get denatured due to high temperature, very high or low pH and high energy radiation but there is no effect due to high pressure.
Which of the following is not a conjugated protein?- a)Peptone
- b)Glycoprotein
- c)Chromoprotein
- d)Lipoprotein
Correct answer is option 'A'. Can you explain this answer?
Which of the following is not a conjugated protein?
a)
Peptone
b)
Glycoprotein
c)
Chromoprotein
d)
Lipoprotein
|
|
Suyash Jain answered |
A conjugated protein is a protein that functions in interaction with other (non-polypeptide) chemical groups attached by covalent bonding or weak interactions.
. __________ is a globular protein of 6 kDa consisting of 51 amino acids arranged in 2 polypeptide chains held together by a disulphide bridge- a)Fibrinogen
- b)Keratin
- c)Insulin
- d)Glucagon
Correct answer is option 'C'. Can you explain this answer?
. __________ is a globular protein of 6 kDa consisting of 51 amino acids arranged in 2 polypeptide chains held together by a disulphide bridge
a)
Fibrinogen
b)
Keratin
c)
Insulin
d)
Glucagon
|
|
Pooja Mehta answered |
Human insulin is a peptide hormone composed of 51 ammo acids and has a molecular weight of 5805 Da.(∼6 Kda). In this molecule, there are two polypeptide chains (A and B) held together by disulphide bridge.
The energy currency of cell is—- a)GDP
- b)ATP
- c)ADP
- d)NAD
Correct answer is option 'B'. Can you explain this answer?
The energy currency of cell is—
a)
GDP
b)
ATP
c)
ADP
d)
NAD
|
|
Rohan Singh answered |
When the ATP converts to ADP, the ATP is said to be spent. he molecule is used like a battery within cells and allows the consumption of one of its phosphorous molecules.The energy currency used by all cells from bacteria to man is adenosine triphosphate (ATP).
Which is the most abundant chemical for the living organisms?- a)Lipids
- b)Proteins
- c)Ions
- d)Water
Correct answer is option 'D'. Can you explain this answer?
Which is the most abundant chemical for the living organisms?
a)
Lipids
b)
Proteins
c)
Ions
d)
Water

|
Anand Jain answered |
Water is the most abundant chemical for the living organisms.
Which one of the following is fibrous protein?- a)Collagen
- b)Ribozymes
- c)Haemoglobin
- d)Hemicellulose
Correct answer is option 'A'. Can you explain this answer?
Which one of the following is fibrous protein?
a)
Collagen
b)
Ribozymes
c)
Haemoglobin
d)
Hemicellulose

|
Shanaya Rane answered |
Collagen is a fibrous protein. It is the main structural protein in the extracellular space in thevarious connective tissues. It is the most abundant protein in mammals.
A polysaccharide present as storehouse of energy of plant tissues- a)Chitin
- b)Starch
- c)Hemi cellulose
- d)Cellulose
Correct answer is option 'B'. Can you explain this answer?
A polysaccharide present as storehouse of energy of plant tissues
a)
Chitin
b)
Starch
c)
Hemi cellulose
d)
Cellulose
|
|
Jyoti Kapoor answered |
Polysaccharide
A polysaccharide is a large molecule made of many smaller monosaccharides. Monosaccharides are simple sugars, like glucose. Special enzymes bind these small monomers together creating large sugar polymers, or polysaccharides. A polysaccharide is also called a glycan. A polysaccharide can be a homopolysaccharide, in which all the monosaccharides are the same, or a heteropolysaccharide in which the monosaccharides vary. Depending on which monosaccharides are connected, and which carbons in the monosaccharides connects, polysaccharides take on a variety of forms. A molecule with a straight chain of monosaccharides is called a linear polysaccharide, while a chain that has arms and turns is known as a branched polysaccharide.
One turn of the DNA double helix spans a distance of- a)3.4 nm
- b)4.26 nm
- c)4.56 nm
- d)2.46 nm
Correct answer is option 'A'. Can you explain this answer?
One turn of the DNA double helix spans a distance of
a)
3.4 nm
b)
4.26 nm
c)
4.56 nm
d)
2.46 nm
|
|
Suresh Kumar answered |
Refer biomolecules chapter in Ncert .Its mentioned in that chapter...
DNA differs from RNA in having- a)Thymine but no uracil
- b)Uracil but no thymine
- c)Thymine but no cytosine
- d)Cytosine but no guanine
Correct answer is option 'A'. Can you explain this answer?
DNA differs from RNA in having
a)
Thymine but no uracil
b)
Uracil but no thymine
c)
Thymine but no cytosine
d)
Cytosine but no guanine
|
|
Om Desai answered |
Uracil is energetically less expensive to produce than thymine, which may account for its use in RNA. In DNA, however, uracil is readily produced by chemical degradation of cytosine, so having thymine as the normal base makes detection and repair of such incipient mutations more efficient.
The part of enzyme bound to the protein part by a covalent bond is called- a)Holoenzyme
- b)Cofactor
- c)Prosthetic group
- d)Apoenzyme
Correct answer is option 'C'. Can you explain this answer?
The part of enzyme bound to the protein part by a covalent bond is called
a)
Holoenzyme
b)
Cofactor
c)
Prosthetic group
d)
Apoenzyme

|
Imk Pathsala answered |
A prosthetic group is a tightly covalently bound, specific non-polypeptide unit required for the biological function of some proteins. The prosthetic group may be organic (such as a vitamin, sugar, or lipid) or inorganic (such as a metal ion), but is not composed of amino acids.
In yeast, during fermentation the glycolysis pathway leads to- a)Production of glucose
- b)Production of oxygen
- c)Production of pyruvic acid
- d)Production of ethanol
Correct answer is option 'D'. Can you explain this answer?
In yeast, during fermentation the glycolysis pathway leads to
a)
Production of glucose
b)
Production of oxygen
c)
Production of pyruvic acid
d)
Production of ethanol

|
Jatin Chakraborty answered |
In yeast, during fermentation, the same pathway leads to the production of ethanol(alcohol).
Which of the following carries the hereditary information from parents to progeny?- a)Nucleotides
- b)Nucleoside
- c)Nucleic acids
- d)Proteins
Correct answer is option 'C'. Can you explain this answer?
Which of the following carries the hereditary information from parents to progeny?
a)
Nucleotides
b)
Nucleoside
c)
Nucleic acids
d)
Proteins
|
|
Pooja Mehta answered |
Nucleic acid is the chemical name for the molecules RNA and DNA. The name comes from the fact that these molecules are acids – that is, they are good at donating protons and accepting electron pairs in chemical reactions – and the fact that they were first discovered in the nuclei of our cells.
Assertion (A): Competitive inhibitors bind to the active site of an enzyme, preventing substrate binding. Reason (R): Competitive inhibition can be overcome by increasing the concentration of the substrate.- a)If both Assertion and Reason are true and Reason is the correct explanation of Assertion
- b)If both Assertion and Reason are true but Reason is not the correct explanation of Assertion
- c)If Assertion is true but Reason is false
- d)If both Assertion and Reason are false
Correct answer is option 'A'. Can you explain this answer?
Assertion (A): Competitive inhibitors bind to the active site of an enzyme, preventing substrate binding.
Reason (R): Competitive inhibition can be overcome by increasing the concentration of the substrate.
a)
If both Assertion and Reason are true and Reason is the correct explanation of Assertion
b)
If both Assertion and Reason are true but Reason is not the correct explanation of Assertion
c)
If Assertion is true but Reason is false
d)
If both Assertion and Reason are false

|
Mohit Jat answered |
2
Select the right option regarding the given graph.
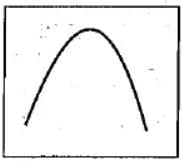
- a)X - axis = Rate of reaction
Y - axis = Enzymatic activity
- b)X - axis = Enzymatic activity
Y - axis = Rate of reaction
- c)X - axis = pH/Temperature
Y - axis = Enzymatic activity
- d)X - axis = Enzymatic activity
Y - axis = pH/Temperature
Correct answer is option 'C'. Can you explain this answer?
Select the right option regarding the given graph.
a)
X - axis = Rate of reaction
Y - axis = Enzymatic activity
Y - axis = Enzymatic activity
b)
X - axis = Enzymatic activity
Y - axis = Rate of reaction
Y - axis = Rate of reaction
c)
X - axis = pH/Temperature
Y - axis = Enzymatic activity
Y - axis = Enzymatic activity
d)
X - axis = Enzymatic activity
Y - axis = pH/Temperature
Y - axis = pH/Temperature
|
|
Jyoti Sengupta answered |
The variable with which we have to find the relation should always have to be on the y axis and the variable which does not show variation and will always increase will be on the x-axis.
Proteins are made up of- a)Monomers
- b)Amino acids
- c)Homopolymers
- d)Nucleosides
Correct answer is option 'B'. Can you explain this answer?
Proteins are made up of
a)
Monomers
b)
Amino acids
c)
Homopolymers
d)
Nucleosides
|
|
Rohan Singh answered |
Proteins are heteropolymers usually made of amino acids. While a nucleic acid like DNA or RNA is made of of only 4 types of nucleotide monomers, proteins are made of 20 types of monomers. Ans: (d) Proteins perform many physiological functions. ... Ans: (a) Glycogen is a homopolymer made of glucose units.
Which of the following is not obtained on hydrolysis of nucleic acid?- a)Purine
- b)Phosphoric acid
- c)Pyrimidine
- d)Pentose sugar
Correct answer is option 'B'. Can you explain this answer?
Which of the following is not obtained on hydrolysis of nucleic acid?
a)
Purine
b)
Phosphoric acid
c)
Pyrimidine
d)
Pentose sugar

|
Ruchi Chopra answered |
Hydrolysis of nucleic acid (DNA and RNA) produces pentose sugar (ribose or deoxyribose) purine and pyrimidine. Phosphoric acid is not released on hydrolysis of DNA or RNA.
Which type of lipid is glycerol classified as?- a)Fatty acid
- b)Triglyceride
- c)Simple lipid
- d)Phospholipid
Correct answer is option 'C'. Can you explain this answer?
a)
Fatty acid
b)
Triglyceride
c)
Simple lipid
d)
Phospholipid
|
|
Mrinalini Basak answered |
Understanding Glycerol and Lipid Classification
Glycerol is classified as a simple lipid, and here's why:
1. Definition of Simple Lipids
- Simple lipids are primarily esters of fatty acids and alcohols, which include glycerol.
- They are the most basic form of lipids and do not contain additional functional groups or complex structures.
2. Structure of Glycerol
- Glycerol is a three-carbon alcohol with a hydroxyl (-OH) group attached to each carbon atom.
- Its chemical formula is C3H8O3, making it a simple molecule.
3. Role in Lipid Formation
- Glycerol serves as a backbone for the formation of triglycerides and phospholipids when it bonds with fatty acids.
- In triglycerides, three fatty acids attach to a glycerol molecule, while in phospholipids, two fatty acids and a phosphate group are attached.
4. Why Not Other Options?
- Fatty acids (Option A) are long hydrocarbon chains that can combine with glycerol but are not glycerol itself.
- Triglycerides (Option B) are complex lipids formed from glycerol and fatty acids, hence glycerol is a component, not a triglyceride itself.
- Phospholipids (Option D) are modified lipids that include glycerol but also contain phosphate groups, making them more complex.
Conclusion
In summary, glycerol is classified as a simple lipid due to its structure and function as a building block for more complex lipids like triglycerides and phospholipids. Understanding this classification is crucial for grasping the fundamental concepts of lipid biochemistry in biological systems.
Glycerol is classified as a simple lipid, and here's why:
1. Definition of Simple Lipids
- Simple lipids are primarily esters of fatty acids and alcohols, which include glycerol.
- They are the most basic form of lipids and do not contain additional functional groups or complex structures.
2. Structure of Glycerol
- Glycerol is a three-carbon alcohol with a hydroxyl (-OH) group attached to each carbon atom.
- Its chemical formula is C3H8O3, making it a simple molecule.
3. Role in Lipid Formation
- Glycerol serves as a backbone for the formation of triglycerides and phospholipids when it bonds with fatty acids.
- In triglycerides, three fatty acids attach to a glycerol molecule, while in phospholipids, two fatty acids and a phosphate group are attached.
4. Why Not Other Options?
- Fatty acids (Option A) are long hydrocarbon chains that can combine with glycerol but are not glycerol itself.
- Triglycerides (Option B) are complex lipids formed from glycerol and fatty acids, hence glycerol is a component, not a triglyceride itself.
- Phospholipids (Option D) are modified lipids that include glycerol but also contain phosphate groups, making them more complex.
Conclusion
In summary, glycerol is classified as a simple lipid due to its structure and function as a building block for more complex lipids like triglycerides and phospholipids. Understanding this classification is crucial for grasping the fundamental concepts of lipid biochemistry in biological systems.
How many subunits are there in human adult haemoglobin?- a)4
- b)5
- c)3
- d)2
Correct answer is option 'A'. Can you explain this answer?
How many subunits are there in human adult haemoglobin?
a)
4
b)
5
c)
3
d)
2

|
Rajat Roy answered |
Proteins human haemoglobin consists of 4 subunits. Two of these are identical toeach other. Hence, two subunits of αα type and two subunits of ββ type together constitute the human haemoglobin (Hb).
Directions: In the following question, two statements are given. One is assertion and the other is reason. Examine the statements carefully and mark the correct option.Assertion: Both amino group and acidic group act as substituents on the same carbon called α-amino acids.Reason: Amino acids are inorganic compounds containing an amino group.- a)Both assertion and reason are true and reason is the correct explanation of assertion.
- b)Assertion is true but the reason is false.
- c)Both assertion and reason are true but reason is not the correct explanation of assertion.
- d)Assertion is false but the reason is true.
Correct answer is option 'B'. Can you explain this answer?
Directions: In the following question, two statements are given. One is assertion and the other is reason. Examine the statements carefully and mark the correct option.
Assertion: Both amino group and acidic group act as substituents on the same carbon called α-amino acids.
Reason: Amino acids are inorganic compounds containing an amino group.
a)
Both assertion and reason are true and reason is the correct explanation of assertion.
b)
Assertion is true but the reason is false.
c)
Both assertion and reason are true but reason is not the correct explanation of assertion.
d)
Assertion is false but the reason is true.

|
Lead Academy answered |
Amino acids are organic compounds containing an amino group and an acidic group as substituents on the same carbon, i.e. the α-carbon. Hence, they are called α-amino acids.
Assertion (A): Secondary metabolites like rubber and essential oils do not play known roles in the normal physiological processes of the organisms that produce them.
Reason (R): Secondary metabolites are often involved in defense mechanisms or ecological functions rather than primary metabolic processes.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true, but R is false.
- d)A is false, but R is true.
Correct answer is option 'A'. Can you explain this answer?
Assertion (A): Secondary metabolites like rubber and essential oils do not play known roles in the normal physiological processes of the organisms that produce them.
Reason (R): Secondary metabolites are often involved in defense mechanisms or ecological functions rather than primary metabolic processes.
Reason (R): Secondary metabolites are often involved in defense mechanisms or ecological functions rather than primary metabolic processes.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true, but R is false.
d)
A is false, but R is true.

|
EduRev NEET answered |
Assertion A is true as secondary metabolites such as rubber and essential oils generally do not have identifiable roles in the normal physiological functions of the organisms that produce them. Reason R correctly explains this by stating that these metabolites are involved in ecological functions such as defense, rather than in primary metabolic processes. Therefore, Option A is correct as R is the correct explanation of A.
Nitrogen is an important component of- a)Polyphosphates
- b)Carbohydrates
- c)Lipids
- d)Proteins
Correct answer is option 'D'. Can you explain this answer?
Nitrogen is an important component of
a)
Polyphosphates
b)
Carbohydrates
c)
Lipids
d)
Proteins
|
|
Neha Menon answered |
**Nitrogen and Proteins**
**Explanation:**
Nitrogen is an essential element for the growth and development of living organisms. It is a vital component of many biomolecules, including proteins. Proteins are large, complex molecules that play crucial roles in the structure, function, and regulation of cells and tissues.
**1. Nitrogen in Amino Acids:**
Proteins are made up of long chains of amino acids. Nitrogen is a key component of these amino acids, which are the building blocks of proteins. Each amino acid contains an amino group (-NH2) that includes a nitrogen atom. The amino group is responsible for the nitrogen content in proteins.
**2. Role of Nitrogen in Protein Structure:**
Nitrogen atoms within amino acids play a crucial role in forming the peptide bonds that link individual amino acids together. These peptide bonds create a polypeptide chain, which folds and twists to form the unique three-dimensional structure of a protein. This structure is essential for the protein's function.
**3. Protein Functions:**
Proteins have diverse functions in living organisms. Some of the important functions of proteins include:
- Enzymes: Proteins act as enzymes, which are catalysts that facilitate biochemical reactions in cells.
- Structural Support: Proteins provide structural support to cells and tissues. For example, collagen is a protein that forms the structural framework of connective tissues like skin, tendons, and bones.
- Transport: Certain proteins transport molecules across cell membranes. For instance, hemoglobin is a protein responsible for carrying oxygen in red blood cells.
- Signaling: Proteins can act as signaling molecules, transmitting signals within and between cells. Examples include hormones and neurotransmitters.
- Immunity: Antibodies, a type of protein, play a crucial role in the immune system by recognizing and neutralizing foreign substances in the body.
**Conclusion:**
Nitrogen is an important component of proteins. Proteins are essential for various biological processes, including cell structure, enzyme function, transport, signaling, and immunity. Therefore, the correct answer is option 'D' - Proteins.
**Explanation:**
Nitrogen is an essential element for the growth and development of living organisms. It is a vital component of many biomolecules, including proteins. Proteins are large, complex molecules that play crucial roles in the structure, function, and regulation of cells and tissues.
**1. Nitrogen in Amino Acids:**
Proteins are made up of long chains of amino acids. Nitrogen is a key component of these amino acids, which are the building blocks of proteins. Each amino acid contains an amino group (-NH2) that includes a nitrogen atom. The amino group is responsible for the nitrogen content in proteins.
**2. Role of Nitrogen in Protein Structure:**
Nitrogen atoms within amino acids play a crucial role in forming the peptide bonds that link individual amino acids together. These peptide bonds create a polypeptide chain, which folds and twists to form the unique three-dimensional structure of a protein. This structure is essential for the protein's function.
**3. Protein Functions:**
Proteins have diverse functions in living organisms. Some of the important functions of proteins include:
- Enzymes: Proteins act as enzymes, which are catalysts that facilitate biochemical reactions in cells.
- Structural Support: Proteins provide structural support to cells and tissues. For example, collagen is a protein that forms the structural framework of connective tissues like skin, tendons, and bones.
- Transport: Certain proteins transport molecules across cell membranes. For instance, hemoglobin is a protein responsible for carrying oxygen in red blood cells.
- Signaling: Proteins can act as signaling molecules, transmitting signals within and between cells. Examples include hormones and neurotransmitters.
- Immunity: Antibodies, a type of protein, play a crucial role in the immune system by recognizing and neutralizing foreign substances in the body.
**Conclusion:**
Nitrogen is an important component of proteins. Proteins are essential for various biological processes, including cell structure, enzyme function, transport, signaling, and immunity. Therefore, the correct answer is option 'D' - Proteins.
Secondary structure of protein refers to- a)Folding patterns of polypeptide chain
- b)Sequence of amino acids in polypeptide chain
- c)Bonds between alternate polypeptide chains
- d)Bonding between NH+3 and COO– of two peptides
Correct answer is option 'A'. Can you explain this answer?
Secondary structure of protein refers to
a)
Folding patterns of polypeptide chain
b)
Sequence of amino acids in polypeptide chain
c)
Bonds between alternate polypeptide chains
d)
Bonding between NH+3 and COO– of two peptides
|
|
Gargi Datta answered |
Secondary Structure of Proteins
Secondary structure of a protein refers to the folding patterns of the polypeptide chain. This structure is primarily determined by hydrogen bonding between amino acids along the polypeptide chain.
Key Points:
- The most common secondary structures are alpha helices and beta sheets.
- In an alpha helix, the polypeptide chain is coiled like a spring.
- In beta sheets, the polypeptide chain folds back and forth on itself.
- These structures are stabilized by hydrogen bonds between the backbone atoms of the amino acids.
Folding Patterns of Polypeptide Chain
The folding patterns of the polypeptide chain in a protein determine its secondary structure. These patterns are essential for the protein to maintain its specific shape and function. The secondary structure is crucial for the overall three-dimensional structure of the protein.
Hydrogen Bonding
Hydrogen bonding plays a significant role in stabilizing the secondary structure of proteins. The hydrogen bonds form between the amino acid residues, specifically between the hydrogen of the amino group and the oxygen of the carbonyl group. These bonds help maintain the structural integrity of the protein.
In conclusion, the secondary structure of a protein is defined by the folding patterns of the polypeptide chain, primarily stabilized by hydrogen bonding between amino acids. This structure is essential for the overall function and stability of the protein.
Secondary structure of a protein refers to the folding patterns of the polypeptide chain. This structure is primarily determined by hydrogen bonding between amino acids along the polypeptide chain.
Key Points:
- The most common secondary structures are alpha helices and beta sheets.
- In an alpha helix, the polypeptide chain is coiled like a spring.
- In beta sheets, the polypeptide chain folds back and forth on itself.
- These structures are stabilized by hydrogen bonds between the backbone atoms of the amino acids.
Folding Patterns of Polypeptide Chain
The folding patterns of the polypeptide chain in a protein determine its secondary structure. These patterns are essential for the protein to maintain its specific shape and function. The secondary structure is crucial for the overall three-dimensional structure of the protein.
Hydrogen Bonding
Hydrogen bonding plays a significant role in stabilizing the secondary structure of proteins. The hydrogen bonds form between the amino acid residues, specifically between the hydrogen of the amino group and the oxygen of the carbonyl group. These bonds help maintain the structural integrity of the protein.
In conclusion, the secondary structure of a protein is defined by the folding patterns of the polypeptide chain, primarily stabilized by hydrogen bonding between amino acids. This structure is essential for the overall function and stability of the protein.
Which of the following is an example of isozyme?- a)α-amylase
- b)Glucokinase
- c)Lactate dehydrogenases
- d)All of these
Correct answer is option 'D'. Can you explain this answer?
Which of the following is an example of isozyme?
a)
α-amylase
b)
Glucokinase
c)
Lactate dehydrogenases
d)
All of these
|
|
Dev Patel answered |
The multiple molecular forms of an enzyme occuring in the same organism and having a similar substrate activity are called isoenymes or isozymes. They have similar properties but different molecular weights and locations. Over 100 enzymes are known to have isoenzymes. α-amylase of wheat endosperm has 16 isozymes, lactate dehydrogenase has 5 isozymes. Glucokinase is an isozyme of hexokinase.
Dihydroxyacetone-3-phosphate and glyceraldehyde-3- phosphate are interconvertible. The enzyme responsible for this interconversion belongs to the cateogry of- a)isomerases
- b)ligases
- c)lyases
- d)hydrolases
Correct answer is option 'A'. Can you explain this answer?
Dihydroxyacetone-3-phosphate and glyceraldehyde-3- phosphate are interconvertible. The enzyme responsible for this interconversion belongs to the cateogry of
a)
isomerases
b)
ligases
c)
lyases
d)
hydrolases
|
|
Dev Patel answered |
Isomerases catalyse the change of a substrate into a related isomeric form by rearrangement of molecules.
What is meant by feedback inhibition?- a)Inhibition of enzyme activity at an active site by an inhibitor, which is structurally similar to a substrate
- b)Inhibition of first step of biosynthesis by the end-product of reaction
- c)Inhibition by a structurally different inhibitor at a place other than active site
- d)Denaturation of enzyme
Correct answer is option 'B'. Can you explain this answer?
What is meant by feedback inhibition?
a)
Inhibition of enzyme activity at an active site by an inhibitor, which is structurally similar to a substrate
b)
Inhibition of first step of biosynthesis by the end-product of reaction
c)
Inhibition by a structurally different inhibitor at a place other than active site
d)
Denaturation of enzyme
|
|
Lead Academy answered |
Inhibition of an enzyme controlling an early stage of a series of biochemical reactions by the end product when it reaches a critical concentration.
Which of the following statements regarding the catalytic cycle of enzyme action is/are correct?i. The substrate binds to the active site of the enzyme, fitting perfectly into it.ii. The enzyme changes shape to fit more tightly around the substrate after binding occurs.iii. The enzyme-product complex is formed when the active site breaks the chemical bonds of the substrate.iv. The enzyme remains permanently altered after releasing the products of the reaction.- a)ii and iii
- b)i and ii
- c)iii and iv
- d)i, ii, and iii
Correct answer is option 'D'. Can you explain this answer?
Which of the following statements regarding the catalytic cycle of enzyme action is/are correct?
i. The substrate binds to the active site of the enzyme, fitting perfectly into it.
ii. The enzyme changes shape to fit more tightly around the substrate after binding occurs.
iii. The enzyme-product complex is formed when the active site breaks the chemical bonds of the substrate.
iv. The enzyme remains permanently altered after releasing the products of the reaction.
a)
ii and iii
b)
i and ii
c)
iii and iv
d)
i, ii, and iii

|
Ciel Knowledge answered |
To determine which statements are correct, let's analyze each one:
- Statement i: This statement describes the initial binding of the substrate to the enzyme's active site, which is accurate as enzymes typically have specific active sites that fit their substrates (the "lock and key" model).
- Statement ii: This statement is also correct. After the substrate binds, the enzyme undergoes an "induced fit," altering its shape for a tighter fit around the substrate.
- Statement iii: This statement correctly describes the formation of the enzyme-product complex, where the active site facilitates the breaking of chemical bonds in the substrate.
- Statement iv: This statement is incorrect. Enzymes are not permanently altered after the reaction; they can be reused to catalyze additional reactions.
Thus, the correct statements are i, ii, and iii, leading to the correct answer being Option D.
Which of the statements given above is/are correct?i. Lipids are generally water soluble and include simple fatty acids.ii. Fatty acids can be either saturated (without double bonds) or unsaturated (with one or more double bonds).iii. Glycerol is a simple sugar that can be esterified with fatty acids to form triglycerides.iv. Phospholipids are found in cell membranes and contain phosphorus.- a)ii and iv
- b)i and iii
- c)i, ii, and iv
- d)ii and iii
Correct answer is option 'A'. Can you explain this answer?
Which of the statements given above is/are correct?
i. Lipids are generally water soluble and include simple fatty acids.
ii. Fatty acids can be either saturated (without double bonds) or unsaturated (with one or more double bonds).
iii. Glycerol is a simple sugar that can be esterified with fatty acids to form triglycerides.
iv. Phospholipids are found in cell membranes and contain phosphorus.
a)
ii and iv
b)
i and iii
c)
i, ii, and iv
d)
ii and iii

|
Top Rankers answered |
To determine the correct statements:
- Statement i is incorrect because lipids are generally water insoluble, not soluble.
- Statement ii is correct as it accurately describes the types of fatty acids.
- Statement iii is incorrect because glycerol is not a simple sugar; it is a trihydroxy alcohol (trihydroxy propane) that combines with fatty acids to form triglycerides.
- Statement iv is correct as phospholipids are indeed found in cell membranes and contain phosphorus.
Thus, the correct statements are ii and iv, making Option A the right choice.
Identify the correct pairing between nitrogen bases in DNA.- a)T+C/G+A
- b)A+G/C+T
- c)A+C/T+G
- d)G+C/A+T
Correct answer is option 'D'. Can you explain this answer?
Identify the correct pairing between nitrogen bases in DNA.
a)
T+C/G+A
b)
A+G/C+T
c)
A+C/T+G
d)
G+C/A+T
|
|
Rawda Al Jallaf answered |
Introduction to DNA Base Pairing
In DNA, the nitrogen bases pair specifically to ensure accurate replication and transcription. The correct base pairing is determined by the structure of the bases and their hydrogen bonding capabilities.
Correct Pairing of Bases
The correct pairs of nitrogen bases in DNA are:
- Adenine (A) pairs with Thymine (T)
- Guanine (G) pairs with Cytosine (C)
Thus, the correct option is D: G + C / A + T.
Importance of Base Pairing
- Complementary Pairing:
- Each base has a specific partner, which helps in maintaining the double helix structure of DNA.
- Complementary base pairing ensures that the genetic code is preserved during DNA replication.
- Hydrogen Bonds:
- A + T pairs are held together by two hydrogen bonds.
- G + C pairs are held together by three hydrogen bonds, making this pairing stronger.
Consequences of Incorrect Pairing
- Incorrect pairing can lead to mutations, which may result in genetic disorders or diseases.
- The accuracy of base pairing is crucial for the fidelity of DNA replication and the overall functionality of genetic information.
Conclusion
Understanding base pairing is fundamental in molecular biology and genetics. The pairing of G with C and A with T is essential for maintaining the integrity of genetic information across generations. Thus, option D correctly represents the vital relationships between nitrogenous bases in DNA.
In DNA, the nitrogen bases pair specifically to ensure accurate replication and transcription. The correct base pairing is determined by the structure of the bases and their hydrogen bonding capabilities.
Correct Pairing of Bases
The correct pairs of nitrogen bases in DNA are:
- Adenine (A) pairs with Thymine (T)
- Guanine (G) pairs with Cytosine (C)
Thus, the correct option is D: G + C / A + T.
Importance of Base Pairing
- Complementary Pairing:
- Each base has a specific partner, which helps in maintaining the double helix structure of DNA.
- Complementary base pairing ensures that the genetic code is preserved during DNA replication.
- Hydrogen Bonds:
- A + T pairs are held together by two hydrogen bonds.
- G + C pairs are held together by three hydrogen bonds, making this pairing stronger.
Consequences of Incorrect Pairing
- Incorrect pairing can lead to mutations, which may result in genetic disorders or diseases.
- The accuracy of base pairing is crucial for the fidelity of DNA replication and the overall functionality of genetic information.
Conclusion
Understanding base pairing is fundamental in molecular biology and genetics. The pairing of G with C and A with T is essential for maintaining the integrity of genetic information across generations. Thus, option D correctly represents the vital relationships between nitrogenous bases in DNA.
The spatial arrangement produced by the twisting and folding of peptide chains in proteins is called:- a)Secondary structure
- b)Primary structure
- c)Tertiary structure
- d)Quaternary structure
Correct answer is option 'A'. Can you explain this answer?
The spatial arrangement produced by the twisting and folding of peptide chains in proteins is called:
a)
Secondary structure
b)
Primary structure
c)
Tertiary structure
d)
Quaternary structure
|
|
EduRev NEET answered |
- The spatial arrangement produced by the twisting and folding of peptide chains in proteins is called secondary structure.
- Secondary structure is comprised of regions stabilized by hydrogen bonds between atoms in the polypeptide backbone.
- Tertiary structure is the three-dimensional shape of the protein determined by regions stabilized by interactions between the side chains.
What are nucleotides that include adenine and a sugar molecule called?- a)Adenine bases
- b)Adenylic acids
- c)Adenosine
- d)Adenosine phosphates
Correct answer is option 'C'. Can you explain this answer?
a)
Adenine bases
b)
Adenylic acids
c)
Adenosine
d)
Adenosine phosphates
|
|
Lead Academy answered |
When adenine is attached to a sugar, the compound is called a nucleoside, specifically Adenosine.
Which of the following pairs is incorrect?- a)Terpenoides: Abrin and Ricin
- b)Alkaloids: Morphine and Codeine
- c)Pigments: Carotenoids and Anthocyanins
- d)Drugs: Vinblastin and Curcumin
Correct answer is option 'A'. Can you explain this answer?
Which of the following pairs is incorrect?
a)
Terpenoides: Abrin and Ricin
b)
Alkaloids: Morphine and Codeine
c)
Pigments: Carotenoids and Anthocyanins
d)
Drugs: Vinblastin and Curcumin
|
|
Pooja Mukherjee answered |
Explanation of Incorrect Pair
The incorrect pair in the given options is:
Terpenoids: Abrin and Ricin
Understanding the Components
- Terpenoids:
- These are a large class of organic compounds produced by a variety of plants, particularly conifers.
- They are derived from isoprene units and are often responsible for the aromatic properties of many plants.
- Examples include menthol and limonene.
- Abrin and Ricin:
- Both are toxic proteins derived from specific plant seeds (Abrus precatorius for abrin and Ricinus communis for ricin).
- They are classified as lectins and not terpenoids, meaning they do not fit into the terpenoid category.
Correct Pairings
- Alkaloids: Morphine and Codeine:
- Alkaloids are nitrogen-containing compounds known for their pharmacological effects.
- Morphine and codeine are both derived from the opium poppy and exhibit analgesic properties.
- Pigments: Carotenoids and Anthocyanins:
- Both are pigments found in plants, carotenoids giving yellow to red hues, and anthocyanins providing red, purple, and blue colors.
- Drugs: Vinblastine and Curcumin:
- Vinblastine is a chemotherapy medication, while curcumin is a compound found in turmeric with anti-inflammatory properties.
Conclusion
The classification of abrin and ricin as terpenoids is incorrect, making option A the right answer. The other pairs accurately represent their respective categories.
The incorrect pair in the given options is:
Terpenoids: Abrin and Ricin
Understanding the Components
- Terpenoids:
- These are a large class of organic compounds produced by a variety of plants, particularly conifers.
- They are derived from isoprene units and are often responsible for the aromatic properties of many plants.
- Examples include menthol and limonene.
- Abrin and Ricin:
- Both are toxic proteins derived from specific plant seeds (Abrus precatorius for abrin and Ricinus communis for ricin).
- They are classified as lectins and not terpenoids, meaning they do not fit into the terpenoid category.
Correct Pairings
- Alkaloids: Morphine and Codeine:
- Alkaloids are nitrogen-containing compounds known for their pharmacological effects.
- Morphine and codeine are both derived from the opium poppy and exhibit analgesic properties.
- Pigments: Carotenoids and Anthocyanins:
- Both are pigments found in plants, carotenoids giving yellow to red hues, and anthocyanins providing red, purple, and blue colors.
- Drugs: Vinblastine and Curcumin:
- Vinblastine is a chemotherapy medication, while curcumin is a compound found in turmeric with anti-inflammatory properties.
Conclusion
The classification of abrin and ricin as terpenoids is incorrect, making option A the right answer. The other pairs accurately represent their respective categories.
Go through the following statements— A. Primary metabolites are biochemicals formed as intermediates and products of normal vital metabolic pathways of organisms
B. Plant tissues produce only secondary metabolites
C. Secondary metabolites have restricted distribution in the plant kingdoms only.
D. Secondary metabolites are derivatives of primary metabolites.
E. Many plants, fungi, and microbes synthesize secondary metabolites.
F. No secondary metabolite has ecological importance.
G. We understand the role of all secondary metabolites in the host organisms.
H. Many secondary metabolites are of economic importance to us.
Which of the above statements are wrong?- a)A, B, C are wrong
- b)D, E, F are wrong
- c)A, D, E are wrong
- d)B, C, F, G are wrong
Correct answer is option 'D'. Can you explain this answer?
B. Plant tissues produce only secondary metabolites
C. Secondary metabolites have restricted distribution in the plant kingdoms only.
D. Secondary metabolites are derivatives of primary metabolites.
E. Many plants, fungi, and microbes synthesize secondary metabolites.
F. No secondary metabolite has ecological importance.
G. We understand the role of all secondary metabolites in the host organisms.
H. Many secondary metabolites are of economic importance to us.
Which of the above statements are wrong?
a)
A, B, C are wrong
b)
D, E, F are wrong
c)
A, D, E are wrong
d)
B, C, F, G are wrong
|
|
Vandana Sharma answered |
Understanding the Statements on Metabolites
The statements provided relate to primary and secondary metabolites in plants and other organisms. Here’s a breakdown of the incorrect statements among options B, C, F, and G.
Analysis of Incorrect Statements
- B: Plant tissues produce only secondary metabolites
This statement is incorrect because plant tissues produce both primary and secondary metabolites. Primary metabolites are essential for growth and development, while secondary metabolites serve various ecological functions.
- C: Secondary metabolites have restricted distribution in the plant kingdoms only
This is misleading. Secondary metabolites are found in a wide variety of organisms, including plants, fungi, and bacteria. Therefore, their distribution is not restricted to just the plant kingdom.
- F: No secondary metabolite has ecological importance
This statement is false. Many secondary metabolites play crucial ecological roles, such as defense against herbivores, attracting pollinators, and inhibiting competing plant species.
- G: We understand the role of all secondary metabolites in the host organisms
This statement is also incorrect. While some secondary metabolites have well-documented roles, many remain poorly understood, and research is ongoing to uncover their functions.
Conclusion
Thus, the correct answer is option D, as statements B, C, F, and G are indeed wrong. Understanding these aspects of primary and secondary metabolites is crucial for fields like ecology, pharmacology, and agriculture.
The statements provided relate to primary and secondary metabolites in plants and other organisms. Here’s a breakdown of the incorrect statements among options B, C, F, and G.
Analysis of Incorrect Statements
- B: Plant tissues produce only secondary metabolites
This statement is incorrect because plant tissues produce both primary and secondary metabolites. Primary metabolites are essential for growth and development, while secondary metabolites serve various ecological functions.
- C: Secondary metabolites have restricted distribution in the plant kingdoms only
This is misleading. Secondary metabolites are found in a wide variety of organisms, including plants, fungi, and bacteria. Therefore, their distribution is not restricted to just the plant kingdom.
- F: No secondary metabolite has ecological importance
This statement is false. Many secondary metabolites play crucial ecological roles, such as defense against herbivores, attracting pollinators, and inhibiting competing plant species.
- G: We understand the role of all secondary metabolites in the host organisms
This statement is also incorrect. While some secondary metabolites have well-documented roles, many remain poorly understood, and research is ongoing to uncover their functions.
Conclusion
Thus, the correct answer is option D, as statements B, C, F, and G are indeed wrong. Understanding these aspects of primary and secondary metabolites is crucial for fields like ecology, pharmacology, and agriculture.
Select the incorrect statement regarding metabolites.- a)Primary metabolites are directly involved in normal growth, development, and reproduction.
- b)Secondary metabolites include antibiotics and pigments that are crucial for human welfare.
- c)All secondary metabolites have been conclusively identified in their roles in host organisms.
- d)Secondary metabolites can have ecological roles such as in plant defense mechanisms.
Correct answer is option 'C'. Can you explain this answer?
a)
Primary metabolites are directly involved in normal growth, development, and reproduction.
b)
Secondary metabolites include antibiotics and pigments that are crucial for human welfare.
c)
All secondary metabolites have been conclusively identified in their roles in host organisms.
d)
Secondary metabolites can have ecological roles such as in plant defense mechanisms.
|
|
Top Rankers answered |
The incorrect statement is Option C. While many secondary metabolites have been identified as beneficial to humans and have ecological roles, the specific roles or functions of all secondary metabolites in their host organisms are not fully understood. Thus, it is incorrect to state that all secondary metabolites' roles have been conclusively identified.
An enzyme extract, when subjected to electric field, separates into two fractions, each catalysing the same reaction. These fractions are:- a)Allosteric enzymes
- b)Inducible enzymes
- c)Isoenzymes
- d)Coenzymes
Correct answer is option 'C'. Can you explain this answer?
An enzyme extract, when subjected to electric field, separates into two fractions, each catalysing the same reaction. These fractions are:
a)
Allosteric enzymes
b)
Inducible enzymes
c)
Isoenzymes
d)
Coenzymes
|
|
EduRev NEET answered |
- Isoenzymes (also called isozymes) are alternative forms of the same enzyme activity that exist in different proportions in different tissues.
- Isoenzymes differ in amino acid composition and sequence and multimeric quaternary structure; mostly, but not always, they have similar (conserved) structures.
Which of the following statements about enzymes are correct?
(i) Enzymes do not alter the overall change in free energy for a reaction.
(ii) Enzymes are proteins whose three dimensional shape is key to their functions.
(iii) Enzymes speed up reactions by lowering activation energy.
(iv) Enzymes are highly specific for reactions.
(v) The energy input needed to start a chemical reaction is called activation energy.- a)(i) and (v)
- b)(ii) and (iv)
- c)(i), (ii) and (iv)
- d)All of these
Correct answer is option 'D'. Can you explain this answer?
Which of the following statements about enzymes are correct?
(i) Enzymes do not alter the overall change in free energy for a reaction.
(ii) Enzymes are proteins whose three dimensional shape is key to their functions.
(iii) Enzymes speed up reactions by lowering activation energy.
(iv) Enzymes are highly specific for reactions.
(v) The energy input needed to start a chemical reaction is called activation energy.
(i) Enzymes do not alter the overall change in free energy for a reaction.
(ii) Enzymes are proteins whose three dimensional shape is key to their functions.
(iii) Enzymes speed up reactions by lowering activation energy.
(iv) Enzymes are highly specific for reactions.
(v) The energy input needed to start a chemical reaction is called activation energy.
a)
(i) and (v)
b)
(ii) and (iv)
c)
(i), (ii) and (iv)
d)
All of these
|
|
Maitri Deshpande answered |
**Enzymes are biological catalysts that play a crucial role in speeding up chemical reactions in living organisms. Let's analyze each statement to determine which ones are correct:**
(i) Enzymes do not alter the overall change in free energy for a reaction.
- This statement is correct. Enzymes do not affect the overall change in free energy for a reaction. They only lower the activation energy required for the reaction to occur, but they do not change the energy difference between the reactants and products.
(ii) Enzymes are proteins whose three-dimensional shape is key to their functions.
- This statement is correct. Enzymes are proteins, and their three-dimensional shape is critical for their proper functioning. The active site of an enzyme, where the substrate binds and the reaction takes place, is precisely shaped to accommodate specific substrates.
(iii) Enzymes speed up reactions by lowering activation energy.
- This statement is correct. Enzymes work by lowering the activation energy required for a chemical reaction to occur. Activation energy is the energy input needed to start a reaction, and enzymes facilitate this process by providing an alternative pathway with a lower energy barrier.
(iv) Enzymes are highly specific for reactions.
- This statement is correct. Enzymes are highly specific for particular reactions. Each enzyme is designed to catalyze a specific chemical reaction or a group of closely related reactions. This specificity is determined by the enzyme's active site and its ability to recognize and bind to specific substrates.
(v) The energy input needed to start a chemical reaction is called activation energy.
- This statement is correct. Activation energy refers to the energy input needed to initiate a chemical reaction. It is the energy required to break the bonds of the reactant molecules and reach the transition state, from which the reaction proceeds to form the products.
**In conclusion, all of the given statements are correct. Enzymes do not alter the overall change in free energy, their three-dimensional shape is crucial for their function, they lower activation energy, they are highly specific for reactions, and activation energy is the energy input needed to start a chemical reaction. Therefore, the correct answer is option 'D'.
(i) Enzymes do not alter the overall change in free energy for a reaction.
- This statement is correct. Enzymes do not affect the overall change in free energy for a reaction. They only lower the activation energy required for the reaction to occur, but they do not change the energy difference between the reactants and products.
(ii) Enzymes are proteins whose three-dimensional shape is key to their functions.
- This statement is correct. Enzymes are proteins, and their three-dimensional shape is critical for their proper functioning. The active site of an enzyme, where the substrate binds and the reaction takes place, is precisely shaped to accommodate specific substrates.
(iii) Enzymes speed up reactions by lowering activation energy.
- This statement is correct. Enzymes work by lowering the activation energy required for a chemical reaction to occur. Activation energy is the energy input needed to start a reaction, and enzymes facilitate this process by providing an alternative pathway with a lower energy barrier.
(iv) Enzymes are highly specific for reactions.
- This statement is correct. Enzymes are highly specific for particular reactions. Each enzyme is designed to catalyze a specific chemical reaction or a group of closely related reactions. This specificity is determined by the enzyme's active site and its ability to recognize and bind to specific substrates.
(v) The energy input needed to start a chemical reaction is called activation energy.
- This statement is correct. Activation energy refers to the energy input needed to initiate a chemical reaction. It is the energy required to break the bonds of the reactant molecules and reach the transition state, from which the reaction proceeds to form the products.
**In conclusion, all of the given statements are correct. Enzymes do not alter the overall change in free energy, their three-dimensional shape is crucial for their function, they lower activation energy, they are highly specific for reactions, and activation energy is the energy input needed to start a chemical reaction. Therefore, the correct answer is option 'D'.
What percentage of the total cellular mass is made up of proteins?- a)Less than 1%
- b)About 2%
- c)Approximately 10-15%
- d)70-90%
Correct answer is option 'C'. Can you explain this answer?
a)
Less than 1%
b)
About 2%
c)
Approximately 10-15%
d)
70-90%

|
Ambition Institute answered |
Proteins constitute a significant portion of the cellular mass, making up about 10-15% of it. This makes them vital for numerous cellular functions, including acting as enzymes, structural components, and signaling molecules.
Chapter doubts & questions for Biomolecules - 1 Year Dropper Course for NEET 2025 is part of NEET exam preparation. The chapters have been prepared according to the NEET exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for NEET 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Biomolecules - 1 Year Dropper Course for NEET in English & Hindi are available as part of NEET exam.
Download more important topics, notes, lectures and mock test series for NEET Exam by signing up for free.
1 Year Dropper Course for NEET
503 videos|1698 docs|628 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up
within 7 days!
within 7 days!
Takes less than 10 seconds to signup