









All Exams >
Computer Science Engineering (CSE) >
6 Months Preparation for GATE CSE >
All Questions
All questions of Threads for Computer Science Engineering (CSE) Exam
Which of the following strategy is employed for overcoming the priority inversion problem?- a)Temporarily raise the priority of lower priority level process
- b)Have a fixed priority level scheme
- c)Implement kernel pre-emption scheme
- d)Allow lower priority process to complete its job
Correct answer is option 'A'. Can you explain this answer?
Which of the following strategy is employed for overcoming the priority inversion problem?
a)
Temporarily raise the priority of lower priority level process
b)
Have a fixed priority level scheme
c)
Implement kernel pre-emption scheme
d)
Allow lower priority process to complete its job
|
|
Ravi Singh answered |
Priority inversion is a scenario in scheduling when a higher priority process is indirectly preempted by a lower priority process, thereby inverting the relative priorities of the process. This problem can be eliminated by temporarily raising the priority of lower priority level process, so that it can not preempt the higher priority process.
Option (A) is correct.

User level threads are threads that are visible to the programmer and are unknown to the kernel. The operating system kernel supports and manages kernel level threads. Three different types of models relate user and kernel level threads. Which of the following statements is/are true ?(a)(i) The Many - to - one model maps many user threads to one kernel thread(ii) The one - to - one model maps one user thread to one kernel thread(iii) The many - to - many model maps many user threads to smaller or equal kernel threads(b)(i) Many - to - one model maps many kernel threads to one user thread(ii) One - to - one model maps one kernel thread to one user thread(iii) Many - to - many model maps many kernel threads to smaller or equal user threads- a)(a) is true; (b) is false
- b)(a) is false; (b) is true
- c)Both (a) and (b) are true
- d)Both (a) and (b) are false
Correct answer is option 'A'. Can you explain this answer?
User level threads are threads that are visible to the programmer and are unknown to the kernel. The operating system kernel supports and manages kernel level threads. Three different types of models relate user and kernel level threads. Which of the following statements is/are true ?
(a)
(i) The Many - to - one model maps many user threads to one kernel thread
(ii) The one - to - one model maps one user thread to one kernel thread
(iii) The many - to - many model maps many user threads to smaller or equal kernel threads
(b)
(i) Many - to - one model maps many kernel threads to one user thread
(ii) One - to - one model maps one kernel thread to one user thread
(iii) Many - to - many model maps many kernel threads to smaller or equal user threads
a)
(a) is true; (b) is false
b)
(a) is false; (b) is true
c)
Both (a) and (b) are true
d)
Both (a) and (b) are false
|
|
Ashutosh Mukherjee answered |
Explanation:
User-level threads and kernel-level threads are two different types of threads used in operating systems. The operating system kernel supports and manages kernel-level threads, while user-level threads are managed by the programmer.
User-Level Threads:
- User-level threads are threads that are visible to the programmer and are unknown to the kernel.
- These threads are created and managed by the application or programming language without any intervention from the operating system.
- User-level threads are lightweight and have low overhead since they do not require kernel involvement for thread management.
- However, user-level threads are limited by the fact that if one thread blocks or performs a system call, all other threads in the process are also blocked.
Kernel-Level Threads:
- Kernel-level threads are threads that are managed and supported by the operating system kernel.
- The kernel provides system calls and services for creating, scheduling, and managing kernel-level threads.
- Kernel-level threads have the advantage of being able to run in parallel on multiple processors or cores.
- However, they have higher overhead compared to user-level threads due to the involvement of the kernel in thread management.
Models of User and Kernel Level Threads:
There are three different models that relate user-level threads to kernel-level threads:
1. Many-to-One Model:
- In this model, many user threads are mapped to a single kernel thread.
- All user-level threads of a process share the same kernel-level thread.
- This model has low overhead and is easy to implement but lacks the ability to run threads in parallel on multiple processors or cores.
2. One-to-One Model:
- In this model, each user thread is mapped to a separate kernel thread.
- Each user-level thread has a corresponding kernel-level thread.
- This model allows threads to run in parallel on multiple processors or cores, but it has higher overhead compared to the many-to-one model.
3. Many-to-Many Model:
- In this model, many user threads are mapped to smaller or equal kernel threads.
- The mapping between user and kernel threads can be dynamic and change over time.
- This model provides a balance between the flexibility of the one-to-one model and the efficiency of the many-to-one model.
Correct Answer:
The correct answer is option (a) - (a) is true; (b) is false.
- The many-to-one model maps many user threads to one kernel thread.
- The one-to-one model maps one user thread to one kernel thread.
- The many-to-many model maps many user threads to smaller or equal kernel threads.
User-level threads and kernel-level threads are two different types of threads used in operating systems. The operating system kernel supports and manages kernel-level threads, while user-level threads are managed by the programmer.
User-Level Threads:
- User-level threads are threads that are visible to the programmer and are unknown to the kernel.
- These threads are created and managed by the application or programming language without any intervention from the operating system.
- User-level threads are lightweight and have low overhead since they do not require kernel involvement for thread management.
- However, user-level threads are limited by the fact that if one thread blocks or performs a system call, all other threads in the process are also blocked.
Kernel-Level Threads:
- Kernel-level threads are threads that are managed and supported by the operating system kernel.
- The kernel provides system calls and services for creating, scheduling, and managing kernel-level threads.
- Kernel-level threads have the advantage of being able to run in parallel on multiple processors or cores.
- However, they have higher overhead compared to user-level threads due to the involvement of the kernel in thread management.
Models of User and Kernel Level Threads:
There are three different models that relate user-level threads to kernel-level threads:
1. Many-to-One Model:
- In this model, many user threads are mapped to a single kernel thread.
- All user-level threads of a process share the same kernel-level thread.
- This model has low overhead and is easy to implement but lacks the ability to run threads in parallel on multiple processors or cores.
2. One-to-One Model:
- In this model, each user thread is mapped to a separate kernel thread.
- Each user-level thread has a corresponding kernel-level thread.
- This model allows threads to run in parallel on multiple processors or cores, but it has higher overhead compared to the many-to-one model.
3. Many-to-Many Model:
- In this model, many user threads are mapped to smaller or equal kernel threads.
- The mapping between user and kernel threads can be dynamic and change over time.
- This model provides a balance between the flexibility of the one-to-one model and the efficiency of the many-to-one model.
Correct Answer:
The correct answer is option (a) - (a) is true; (b) is false.
- The many-to-one model maps many user threads to one kernel thread.
- The one-to-one model maps one user thread to one kernel thread.
- The many-to-many model maps many user threads to smaller or equal kernel threads.
A disk drive has 100 cyclinders, numbered 0 to 99. Disk requests come to the disk driver for cyclinders 12, 26, 24, 4, 42, 8 and 50 in that order. The driver is currently serving a request at cyclinder 24. A seek takes 6 msec per cyclinder moved. How much seek time is needed for shortest seek time first (SSTF) algorithm?- a)0.984 sec
- b)0.396 sec
- c)0.738 sec
- d)0.42 sec
Correct answer is option 'D'. Can you explain this answer?
A disk drive has 100 cyclinders, numbered 0 to 99. Disk requests come to the disk driver for cyclinders 12, 26, 24, 4, 42, 8 and 50 in that order. The driver is currently serving a request at cyclinder 24. A seek takes 6 msec per cyclinder moved. How much seek time is needed for shortest seek time first (SSTF) algorithm?
a)
0.984 sec
b)
0.396 sec
c)
0.738 sec
d)
0.42 sec
|
|
Yash Patel answered |
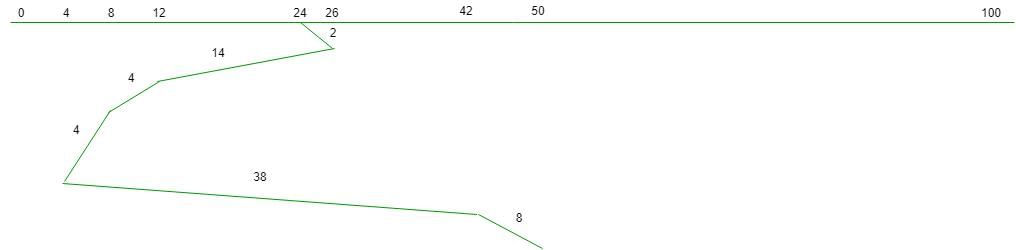
seek time = 2 =(2 + 14 + 4 + 4 + 38 + 8) = 420 msec 1000 msec = 1 sec 420 msec = 0.42 sec So, option (D) is correct.
A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?- a)On per-thread basis, the OS maintains only CPU register state
- b)The OS does not maintain a separate stack for each thread
- c)On per-thread basis, the OS does not maintain virtual memory state
- d)On per-thread basis, the OS maintains only scheduling and accounting information
Correct answer is option 'C'. Can you explain this answer?
A thread is usually defined as a "light weight process" because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the following is TRUE?
a)
On per-thread basis, the OS maintains only CPU register state
b)
The OS does not maintain a separate stack for each thread
c)
On per-thread basis, the OS does not maintain virtual memory state
d)
On per-thread basis, the OS maintains only scheduling and accounting information
|
|
Kiran Reddy answered |
Virtual Memory State for Threads
Maintaining virtual memory state for threads is essential for the operating system to ensure proper memory management and isolation between threads. Each thread typically has its own virtual memory space, which includes its own address space and memory mappings. This allows threads to operate independently and not interfere with each other's memory operations.
Importance of Virtual Memory State
Virtual memory state includes information such as the memory mappings, page tables, and permissions for each thread. Without maintaining this information on a per-thread basis, threads could potentially access or modify memory that belongs to other threads, leading to data corruption or security vulnerabilities.
Operating System Responsibilities
The operating system is responsible for managing virtual memory for each thread, ensuring that memory accesses are properly isolated and protected. By maintaining virtual memory state on a per-thread basis, the OS can enforce memory protection mechanisms and provide a secure environment for thread execution.
Conclusion
In summary, the statement that "On a per-thread basis, the OS does not maintain virtual memory state" is false. Virtual memory state is crucial for proper memory management and isolation between threads, and the operating system must maintain this information for each thread to ensure reliable and secure execution.
Maintaining virtual memory state for threads is essential for the operating system to ensure proper memory management and isolation between threads. Each thread typically has its own virtual memory space, which includes its own address space and memory mappings. This allows threads to operate independently and not interfere with each other's memory operations.
Importance of Virtual Memory State
Virtual memory state includes information such as the memory mappings, page tables, and permissions for each thread. Without maintaining this information on a per-thread basis, threads could potentially access or modify memory that belongs to other threads, leading to data corruption or security vulnerabilities.
Operating System Responsibilities
The operating system is responsible for managing virtual memory for each thread, ensuring that memory accesses are properly isolated and protected. By maintaining virtual memory state on a per-thread basis, the OS can enforce memory protection mechanisms and provide a secure environment for thread execution.
Conclusion
In summary, the statement that "On a per-thread basis, the OS does not maintain virtual memory state" is false. Virtual memory state is crucial for proper memory management and isolation between threads, and the operating system must maintain this information for each thread to ensure reliable and secure execution.
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphorevoid P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}void V (binary_semaphore *s) {
S->value = 0;
}Which one of the following is true?- a)The implementation may not work if context switching is disabled in P.
- b)Instead of using fetch-and-set, a pair of normal load/store can be used
- c)The implementation of V is wrong
- d)The code does not implement a binary semaphore
Correct answer is option 'A'. Can you explain this answer?
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore
void P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
S->value = 0;
}
Which one of the following is true?
a)
The implementation may not work if context switching is disabled in P.
b)
Instead of using fetch-and-set, a pair of normal load/store can be used
c)
The implementation of V is wrong
d)
The code does not implement a binary semaphore
|
|
Yash Patel answered |
Let us talk about the operation P(). It stores the value of s in x, then it fetches the old value of x, stores it in y and sets x as 1. The while loop of a process will continue forever if some other process doesn't execute V() and sets the value of s as 0. If context switching is disabled in P, the while loop will run forever as no other process will be able to execute V().
The state of a process after it encounters an I/O instruction is- a)ready
- b)blocked
- c)idle
- d)running
Correct answer is option 'B'. Can you explain this answer?
The state of a process after it encounters an I/O instruction is
a)
ready
b)
blocked
c)
idle
d)
running
|
|
Yash Patel answered |
Whenever a process is just created, it is kept in Ready queue. When it starts execution, it is in Running state, as soon as it starts doing input/output operation, it is kept in the blocked state.
One of the disadvantages of user level threads compared to Kernel level threads is- a)If a user-level thread of a process executes a system call, all threads in that process are blocked.
- b)Scheduling is application dependent.
- c)Thread switching doesn’t require kernel mode privileges.
- d)The library procedures invoked for thread management in user level threads are local procedures.
Correct answer is option 'A'. Can you explain this answer?
One of the disadvantages of user level threads compared to Kernel level threads is
a)
If a user-level thread of a process executes a system call, all threads in that process are blocked.
b)
Scheduling is application dependent.
c)
Thread switching doesn’t require kernel mode privileges.
d)
The library procedures invoked for thread management in user level threads are local procedures.
|
|
Sanya Agarwal answered |
Advantage of User level thread:
1- Scheduling is application dependent.
2- Thread switching doesn’t require kernel mode privileges.
3- The library procedures invoked for thread management in user level threads are local procedures.
4- User level threads are fast to create and manage.
5- User level thread can run on any operating system.
Disadvantage of User-level thread:
1- Most system calls are blocked on a typical OS.
2- Multiprocessing is not supported for multi-threaded application.
So, Option (A) is correct.
Consider two processors P1 and P2 executing the same instruction set. Assume that under identical conditions, for the same input, a program running on P2 takes 25% less time but incurs 20% more CPI (clock cycles per instruction) as compared to the program running on P1. If the clock frequency of P1 is 1GHz, then the clock frequency of P2 (in GHz) is _________.- a)1.6
- b)3.2
- c)1.2
- d)0.8
Correct answer is option 'A'. Can you explain this answer?
Consider two processors P1 and P2 executing the same instruction set. Assume that under identical conditions, for the same input, a program running on P2 takes 25% less time but incurs 20% more CPI (clock cycles per instruction) as compared to the program running on P1. If the clock frequency of P1 is 1GHz, then the clock frequency of P2 (in GHz) is _________.
a)
1.6
b)
3.2
c)
1.2
d)
0.8
|
|
Yash Patel answered |
For P1 clock period = 1ns
Let clock period for P2 be t.
Now consider following equation based on specification
7.5 ns = 12*t ns
7.5 ns = 12*t ns
We get t and inverse of t will be 1.6GHz
Consider the set of processes with arrival time(in milliseconds), CPU burst time (in milliseconds), and priority(0 is the highest priority) shown below. None of the processes have I/O burst time. The waiting time (in milliseconds) of process P1 using preemptive priority scheduling algorithm is ____.
The waiting time (in milliseconds) of process P1 using preemptive priority scheduling algorithm is ____.- a)26
- b)49
- c)38
- d)29
Correct answer is option 'C'. Can you explain this answer?
Consider the set of processes with arrival time(in milliseconds), CPU burst time (in milliseconds), and priority(0 is the highest priority) shown below. None of the processes have I/O burst time.
The waiting time (in milliseconds) of process P1 using preemptive priority scheduling algorithm is ____.
a)
26
b)
49
c)
38
d)
29
|
|
Sanya Agarwal answered |
The gantt chart is using preemptive priority scheduling algorithm:
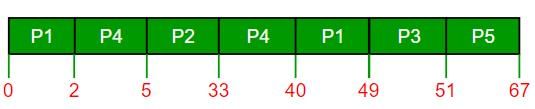
Waiting Time = Completion time - Arrival time - Burst Time Therefore, waiting time of process P1 is = 49 - 0 - 11 = 38 So, option (C) is correct.
In an operating system, indivisibility of operation means:- a)Operation is interruptable
- b)Race - condition may occur
- c)Processor can not be pre-empted
- d)All of the above
Correct answer is option 'C'. Can you explain this answer?
In an operating system, indivisibility of operation means:
a)
Operation is interruptable
b)
Race - condition may occur
c)
Processor can not be pre-empted
d)
All of the above
|
|
Sanya Agarwal answered |
In an operating system, indivisibility of operation means processor can not be pre-empted. One a process starts its execution it will not suspended or stop its execution inside the processor.
So, option (C) is correct.
If the time-slice used in the round-robin scheduling policy is more than the maximum time required to execute any process, then the policy will- a)degenerate to shortest job first
- b)degenerate to priority scheduling
- c)degenerate to first come first serve
- d)none of the above
Correct answer is option 'C'. Can you explain this answer?
If the time-slice used in the round-robin scheduling policy is more than the maximum time required to execute any process, then the policy will
a)
degenerate to shortest job first
b)
degenerate to priority scheduling
c)
degenerate to first come first serve
d)
none of the above
|
|
Sanya Agarwal answered |
RR executes processes in FCFS manner with a time slice. It this time slice becomes long enough, so that a process finishes within it, It becomes FCFS.
Consider three CPU intensive processes, which require 10, 20, 30 units and arrive at times 0, 2, 6 respectively. How many context switches are needed if shortest remaining time first is implemented? Context switch at 0 is included but context switch at end is ignored- a)1
- b)2
- c)3
- d)4
Correct answer is option 'C'. Can you explain this answer?
Consider three CPU intensive processes, which require 10, 20, 30 units and arrive at times 0, 2, 6 respectively. How many context switches are needed if shortest remaining time first is implemented? Context switch at 0 is included but context switch at end is ignored
a)
1
b)
2
c)
3
d)
4
|
|
Sai Basu answered |
Shortest Remaining Time First (SRTF)
In the Shortest Remaining Time First (SRTF) scheduling algorithm, the process with the shortest remaining burst time is executed first. This algorithm preemptively switches between processes based on their remaining burst time.
Given Information:
- Three CPU intensive processes
- Arrival times: 0, 2, 6
- CPU burst times: 10, 20, 30
Step 1: Sorting the processes based on arrival times:
To apply the SRTF algorithm, we first need to sort the processes based on their arrival times in ascending order. This gives us the following order: P1, P2, P3.
Step 2: Executing the processes:
- At time 0, P1 arrives. Since it is the only process, it starts executing.
- At time 2, P2 arrives. However, P1 still has 8 units of burst time remaining, which is shorter than P2's burst time of 20 units. Hence, there is no context switch at this point.
- At time 6, P3 arrives. Again, P1 still has 2 units of burst time remaining, which is shorter than P3's burst time of 30 units. Therefore, there is no context switch.
Step 3: Preemption and context switches:
- At time 10, P1 completes its burst time. Now, P2 has the shortest remaining burst time, so a context switch occurs from P1 to P2.
- At time 12, P2 resumes execution after the context switch.
- At time 30, P2 completes its burst time. Now, P3 has the shortest remaining burst time, so a context switch occurs from P2 to P3.
Total Context Switches:
In this scenario, a total of 3 context switches occur:
1. At time 10, from P1 to P2.
2. At time 12, from P1 to P2.
3. At time 30, from P2 to P3.
Therefore, the correct answer is option 'C' (3 context switches).
In the Shortest Remaining Time First (SRTF) scheduling algorithm, the process with the shortest remaining burst time is executed first. This algorithm preemptively switches between processes based on their remaining burst time.
Given Information:
- Three CPU intensive processes
- Arrival times: 0, 2, 6
- CPU burst times: 10, 20, 30
Step 1: Sorting the processes based on arrival times:
To apply the SRTF algorithm, we first need to sort the processes based on their arrival times in ascending order. This gives us the following order: P1, P2, P3.
Step 2: Executing the processes:
- At time 0, P1 arrives. Since it is the only process, it starts executing.
- At time 2, P2 arrives. However, P1 still has 8 units of burst time remaining, which is shorter than P2's burst time of 20 units. Hence, there is no context switch at this point.
- At time 6, P3 arrives. Again, P1 still has 2 units of burst time remaining, which is shorter than P3's burst time of 30 units. Therefore, there is no context switch.
Step 3: Preemption and context switches:
- At time 10, P1 completes its burst time. Now, P2 has the shortest remaining burst time, so a context switch occurs from P1 to P2.
- At time 12, P2 resumes execution after the context switch.
- At time 30, P2 completes its burst time. Now, P3 has the shortest remaining burst time, so a context switch occurs from P2 to P3.
Total Context Switches:
In this scenario, a total of 3 context switches occur:
1. At time 10, from P1 to P2.
2. At time 12, from P1 to P2.
3. At time 30, from P2 to P3.
Therefore, the correct answer is option 'C' (3 context switches).
Consider a system having ‘m’ resources of the same type. These resources are shared by three processes P1, P2 and P3 which have peak demands of 2, 5 and 7 resources respectively. For what value of ‘m’ deadlock will not occur ?- a)70
- b)14
- c)13
- d)7
Correct answer is option 'B'. Can you explain this answer?
Consider a system having ‘m’ resources of the same type. These resources are shared by three processes P1, P2 and P3 which have peak demands of 2, 5 and 7 resources respectively. For what value of ‘m’ deadlock will not occur ?
a)
70
b)
14
c)
13
d)
7
|
|
Ravi Singh answered |
To avoid deadlock 'm' >= peak demands(P1 + P2 + P3) i.e. m >= peak demands(2 + 5 + 7) m >= peak demands(14) So, option (B) is correct.
Consider the following statements about user level threads and kernel level threads. Which one of the following statement is FALSE?- a)Context switch time is longer for kernel level threads than for user level threads.
- b)User level threads do not need any hardware support.
- c)Related kernel level threads can be scheduled on different processors in a multi-processor system.
- d)Blocking one kernel level thread blocks all related threads.
Correct answer is option 'D'. Can you explain this answer?
Consider the following statements about user level threads and kernel level threads. Which one of the following statement is FALSE?
a)
Context switch time is longer for kernel level threads than for user level threads.
b)
User level threads do not need any hardware support.
c)
Related kernel level threads can be scheduled on different processors in a multi-processor system.
d)
Blocking one kernel level thread blocks all related threads.
|
|
Yash Patel answered |
Kernel level threads are managed by the OS, therefore, thread operations are implemented in the kernel code. Kernel level threads can also utilize multiprocessor systems by splitting threads on different processors. If one thread blocks it does not cause the entire process to block. Kernel level threads have disadvantages as well. They are slower than user level threads due to the management overhead. Kernel level context switch involves more steps than just saving some registers. Finally, they are not portable because the implementation is operating system dependent.
Option (A): Context switch time is longer for kernel level threads than for user level threads. True, As User level threads are managed by user and Kernel level threads are managed by OS. There are many overheads involved in Kernel level thread management, which are not present in User level thread management. So context switch time is longer for kernel level threads than for user level threads.
Option (B): User level threads do not need any hardware support True, as User level threads are managed by user and implemented by Libraries, User level threads do not need any hardware support.
Option (C): Related kernel level threads can be scheduled on different processors in a multi- processor system. This is true.
Option (D): Blocking one kernel level thread blocks all related threads. false, since kernel level threads are managed by operating system, if one thread blocks, it does not cause all threads or entire process to block.
A CPU scheduling algorithm determines an order for the execution of its scheduled processes. Given 'n' processes to be scheduled on one processor, how many possible different schedules are there?- a)n
- b)n2
- c)n!
- d)2n
Correct answer is option 'C'. Can you explain this answer?
A CPU scheduling algorithm determines an order for the execution of its scheduled processes. Given 'n' processes to be scheduled on one processor, how many possible different schedules are there?
a)
n
b)
n2
c)
n!
d)
2n
|
|
Yash Patel answered |
For 'n' processes to be scheduled on one processor, there can be n! different schedules possible. Example: Suppose an OS has 4 processes to schedule P1, P2, P3 and P4. For scheduling the first process, it has 4 choices, then from the remaining three processes it can take 3 choices, and so on. So, total schedules possible are 4*3*2*1 = 4!
Option (C) is correct.
Consider the methods used by processes P1 and P2 for accessing their critical sections whenever needed, as given below. The initial values of shared boolean variables S1 and S2 are randomly assigned.
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;Method Used by P2
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the following statements describes the properties achieved?- a)Mutual exclusion but not progress
- b)Progress but not mutual exclusion
- c)Neither mutual exclusion nor progress
- d)Both mutual exclusion and progress
Correct answer is option 'A'. Can you explain this answer?
Consider the methods used by processes P1 and P2 for accessing their critical sections whenever needed, as given below. The initial values of shared boolean variables S1 and S2 are randomly assigned.
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;
Method Used by P2
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the following statements describes the properties achieved?
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the following statements describes the properties achieved?
a)
Mutual exclusion but not progress
b)
Progress but not mutual exclusion
c)
Neither mutual exclusion nor progress
d)
Both mutual exclusion and progress
|
|
Yash Patel answered |
Mutual Exclusion: A way of making sure that if one process is using a shared modifiable data, the other processes will be excluded from doing the same thing. while one process executes the shared variable, all other processes desiring to do so at the same time moment should be kept waiting; when that process has finished executing the shared variable, one of the processes waiting; while that process has finished executing the shared variable, one of the processes waiting to do so should be allowed to proceed. In this fashion, each process executing the shared data (variables) excludes all others from doing so simultaneously. This is called Mutual Exclusion.
Progress Requirement: If no process is executing in its critical section and there exist some processes that wish to enter their critical section, then the selection of the processes that will enter the critical section next cannot be postponed indefinitely.
Solution: It can be easily observed that the Mutual Exclusion requirement is satisfied by the above solution, P1 can enter critical section only if S1 is not equal to S2, and P2 can enter critical section only if S1 is equal to S2. But here Progress Requirement is not satisfied. Suppose when s1=1 and s2=0 and process p1 is not interested to enter into critical section but p2 want to enter critical section. P2 is not able to enter critical section in this as only when p1 finishes execution, then only p2 can enter (then only s1 = s2 condition be satisfied). Progress will not be satisfied when any process which is not interested to enter into the critical section will not allow other interested process to enter into the critical section.
Which of the following does not interrupt a running process?- a)A device
- b)Timer
- c)Scheduler process
- d)Power failure
Correct answer is option 'C'. Can you explain this answer?
Which of the following does not interrupt a running process?
a)
A device
b)
Timer
c)
Scheduler process
d)
Power failure
|
|
Sanya Agarwal answered |
Scheduler process doesn’t interrupt any process, it’s Job is to select the processes for following three purposes. Long-term scheduler(or job scheduler) –selects which processes should be brought into the ready queue Short-term scheduler(or CPU scheduler) –selects which process should be executed next and allocates CPU. Mid-term Scheduler (Swapper)- present in all systems with virtual memory, temporarily removes processes from main memory and places them on secondary memory (such as a disk drive) or vice versa. The mid-term scheduler may decide to swap out a process which has not been active for some time, or a process which has a low priority, or a process which is page faulting frequently, or a process which is taking up a large amount of memory in order to free up main memory for other processes, swapping the process back in later when more memory is available, or when the process has been unblocked and is no longer waiting for a resource.
Which of the following actions is/are typically not performed by the operating system when switching context from process A to process B?- a)Saving current register values and restoring saved register values for process B.
- b)Changing address translation tables.
- c)Swapping out the memory image of process A to the disk.
- d)Invalidating the translation look-aside buffer.
Correct answer is option 'C'. Can you explain this answer?
Which of the following actions is/are typically not performed by the operating system when switching context from process A to process B?
a)
Saving current register values and restoring saved register values for process B.
b)
Changing address translation tables.
c)
Swapping out the memory image of process A to the disk.
d)
Invalidating the translation look-aside buffer.
|
|
Malavika Tiwari answered |
Explanation:
When switching context from one process to another, the operating system needs to perform various actions to ensure that the new process can run correctly. These actions include saving and restoring register values, changing address translation tables, and invalidating the translation look-aside buffer. However, swapping out the memory image of the current process to the disk is typically not performed during context switching.
Reason:
Swapping out the memory image of a process to the disk is a time-consuming operation that involves transferring large amounts of data between the main memory and the disk. Therefore, it is not practical to perform this operation during context switching, which is intended to be a fast operation to switch between processes quickly. Instead, swapping out a process is typically done when the system is low on memory and needs to free up space to accommodate other processes.
Conclusion:
In summary, swapping out the memory image of a process to the disk is typically not performed during context switching. This operation is reserved for situations where the system needs to free up memory and is not part of the normal process switching mechanism.
When switching context from one process to another, the operating system needs to perform various actions to ensure that the new process can run correctly. These actions include saving and restoring register values, changing address translation tables, and invalidating the translation look-aside buffer. However, swapping out the memory image of the current process to the disk is typically not performed during context switching.
Reason:
Swapping out the memory image of a process to the disk is a time-consuming operation that involves transferring large amounts of data between the main memory and the disk. Therefore, it is not practical to perform this operation during context switching, which is intended to be a fast operation to switch between processes quickly. Instead, swapping out a process is typically done when the system is low on memory and needs to free up space to accommodate other processes.
Conclusion:
In summary, swapping out the memory image of a process to the disk is typically not performed during context switching. This operation is reserved for situations where the system needs to free up memory and is not part of the normal process switching mechanism.
Barrier is a synchronization construct where a set of processes synchronizes globally i.e. each process in the set arrives at the barrier and waits for all others to arrive and then all processes leave the barrier. Let the number of processes in the set be three and S be a binary semaphore with the usual P and V functions. Consider the following C implementation of a barrier with line numbers shown on left.
void barrier (void) {
1: P(S);
2: process_arrived++;
3. V(S);
4: while (process_arrived !=3);
5: P(S);
6: process_left++;
7: if (process_left==3) {
8: process_arrived = 0;
9: process_left = 0;
10: }
11: V(S);
}
The variables process_arrived and process_left are shared among all processes and are initialized to zero. In a concurrent program all the three processes call the barrier function when they need to synchronize globally. The above implementation of barrier is incorrect. Which one of the following is true?- a)The barrier implementation is wrong due to the use of binary semaphore S
- b)The barrier implementation may lead to a deadlock if two barrier in invocations are used in immediate succession
- c)Lines 6 to 10 need not be inside a critical section
- d)The barrier implementation is correct if there are only two processes instead of three
Correct answer is option 'B'. Can you explain this answer?
Barrier is a synchronization construct where a set of processes synchronizes globally i.e. each process in the set arrives at the barrier and waits for all others to arrive and then all processes leave the barrier. Let the number of processes in the set be three and S be a binary semaphore with the usual P and V functions. Consider the following C implementation of a barrier with line numbers shown on left.
void barrier (void) {
1: P(S);
2: process_arrived++;
3. V(S);
4: while (process_arrived !=3);
5: P(S);
6: process_left++;
7: if (process_left==3) {
8: process_arrived = 0;
9: process_left = 0;
10: }
11: V(S);
}
The variables process_arrived and process_left are shared among all processes and are initialized to zero. In a concurrent program all the three processes call the barrier function when they need to synchronize globally. The above implementation of barrier is incorrect. Which one of the following is true?
void barrier (void) {
1: P(S);
2: process_arrived++;
3. V(S);
4: while (process_arrived !=3);
5: P(S);
6: process_left++;
7: if (process_left==3) {
8: process_arrived = 0;
9: process_left = 0;
10: }
11: V(S);
}
The variables process_arrived and process_left are shared among all processes and are initialized to zero. In a concurrent program all the three processes call the barrier function when they need to synchronize globally. The above implementation of barrier is incorrect. Which one of the following is true?
a)
The barrier implementation is wrong due to the use of binary semaphore S
b)
The barrier implementation may lead to a deadlock if two barrier in invocations are used in immediate succession
c)
Lines 6 to 10 need not be inside a critical section
d)
The barrier implementation is correct if there are only two processes instead of three
|
|
Yash Patel answered |
It is possible that process_arrived becomes greater than 3. It will not be possible for process arrived to become 3 again, hence deadlock.
An operating system implements a policy that requires a process to release all resources before making a request for another resource. Select the TRUE statement from the following:- a)Both starvation and deadlock can occur
- b)Starvation can occur but deadlock cannot occur
- c)Starvation cannot occur but deadlock can occur
- d)Neither starvation nor deadlock can occur
Correct answer is option 'B'. Can you explain this answer?
An operating system implements a policy that requires a process to release all resources before making a request for another resource. Select the TRUE statement from the following:
a)
Both starvation and deadlock can occur
b)
Starvation can occur but deadlock cannot occur
c)
Starvation cannot occur but deadlock can occur
d)
Neither starvation nor deadlock can occur
|
|
Yash Patel answered |
Starvation may occur, as a process may want othe resource in ||<sup>al</sup> along with currently hold resources. <br> According to given conditions it will never be possible to collect all at a time.<br> No deadlock.
Two atomic operations permissible on Semaphores are __________ and __________.- a)wait, stop
- b)wait, hold
- c)hold, signal
- d)wait, signal
Correct answer is option 'D'. Can you explain this answer?
Two atomic operations permissible on Semaphores are __________ and __________.
a)
wait, stop
b)
wait, hold
c)
hold, signal
d)
wait, signal
|
|
Ravi Singh answered |
Wait and signal are the atomic operation possible on semaphore.
System calls are usually invoked by using :- a)A privileged instruction
- b)An indirect jump
- c)A software interrupt
- d)Polling
Correct answer is option 'C'. Can you explain this answer?
System calls are usually invoked by using :
a)
A privileged instruction
b)
An indirect jump
c)
A software interrupt
d)
Polling
|
|
Sanya Agarwal answered |
- System calls are usually invoked by using a software interrupt.
- Polling is the process where the computer or controlling device waits for an external device to check for its readiness or state, often with low-level hardware.
- Privileged instruction is an instruction (usually in machine code) that can be executed only by the operating system in a specific mode.
- In direct jump, the target address (i.e. its relative offset value) is encoded into the jump instruction itself.
So, option (C) is correct.
Suppose there are four processes in execution with 12 instances of a Resource R in a system. The maximum need of each process and current allocation are given below: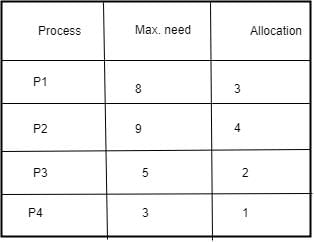 With reference to current allocation, is system safe ? If so, what is the safe sequence ?
With reference to current allocation, is system safe ? If so, what is the safe sequence ?- a)No
- b)Yes, P1P2P3P4
- c)Yes, P4P3P1P2
- d)Yes, P2P1P3P4
Correct answer is option 'C'. Can you explain this answer?
Suppose there are four processes in execution with 12 instances of a Resource R in a system. The maximum need of each process and current allocation are given below:
With reference to current allocation, is system safe ? If so, what is the safe sequence ?
a)
No
b)
Yes, P1P2P3P4
c)
Yes, P4P3P1P2
d)
Yes, P2P1P3P4

|
Cstoppers Instructors answered |
Current allocation of P1P2P3P4 are 3, 4, 2, 1 which is 10 in total. We have 12 total no of resources and out of them 10 are allocated so, we have only 2 resources. There is 5, 5, 3, 2 resources are needed for P1P2P3P4 respectively. So, P4 will run first and free 3 resources after execution. Which are sufficient for P3 So it will execute and do free 5 resources. Now P1 and P2 both require 5 resources each So we can execute any of them first but we will give priority to P1. The execution order will be P4P3P1P2.
SO, option (C) is correct.
Consider the following C code for process P1 and P2. a=4, b=0, c=0 (initialization)
P1 P2
if (a < 0) b = 10;
c = b-a; a = -3;
else
c = b+a;
If the processes P1 and P2 executes concurrently (shared variables a, b and c), which of the following cannot be the value of ‘c’ after both processes complete?- a)4
- b)7
- c)10
- d)13
Correct answer is option 'C'. Can you explain this answer?
Consider the following C code for process P1 and P2. a=4, b=0, c=0 (initialization)
P1 P2
if (a < 0) b = 10;
c = b-a; a = -3;
else
c = b+a;
If the processes P1 and P2 executes concurrently (shared variables a, b and c), which of the following cannot be the value of ‘c’ after both processes complete?
P1 P2
if (a < 0) b = 10;
c = b-a; a = -3;
else
c = b+a;
If the processes P1 and P2 executes concurrently (shared variables a, b and c), which of the following cannot be the value of ‘c’ after both processes complete?
a)
4
b)
7
c)
10
d)
13
|
|
Yash Patel answered |
P1 : 1, 3, 4 → c = 0+4 =4 {hence option a}
P2 : i, ii and P1 : 1, 2 → c = 10-(-3) = 13 {hence option d}
P1 : 1 , P2 : i, ii and P1 : 3, 4 → c= 10+(-3) = 7 { hence option b}
So 10 cannot be c value.
P2 : i, ii and P1 : 1, 2 → c = 10-(-3) = 13 {hence option d}
P1 : 1 , P2 : i, ii and P1 : 3, 4 → c= 10+(-3) = 7 { hence option b}
So 10 cannot be c value.
An Operating System (OS) crashes on the average once in 30 days, that is, the Mean Time Between Failures (MTBF) = 30 days. When this happens, it takes 10 minutes to recover the OS, that is, the Mean Time To Repair (MTTR) = 10 minutes. The availability of the OS with these reliability figures is approximately :- a)96.97%
- b)97.97%
- c)99.009%
- d)99.97%
Correct answer is option 'D'. Can you explain this answer?
An Operating System (OS) crashes on the average once in 30 days, that is, the Mean Time Between Failures (MTBF) = 30 days. When this happens, it takes 10 minutes to recover the OS, that is, the Mean Time To Repair (MTTR) = 10 minutes. The availability of the OS with these reliability figures is approximately :
a)
96.97%
b)
97.97%
c)
99.009%
d)
99.97%
|
|
Sanya Agarwal answered |
System crashes once in 30 days and need 10 minutes to get repaired. Either convert 30 days into minute or 10 minute into days 30 days = 30 ∗ 24 ∗ 60 minute fraction of time system is not available = (10 / (30 ∗ 24 ∗ 60 )) ∗ 100 = 0.023% Availability = 100 - 0.023 = 99.97%
So, option (D) is correct.
A shared variable x, initialized to zero, is operated on by four concurrent processes W, X, Y, Z as follows. Each of the processes W and X reads x from memory, increments by one, stores it to memory, and then terminates. Each of the processes Y and Z reads x from memory, decrements by two, stores it to memory, and then terminates. Each process before reading x invokes the P operation (i.e., wait) on a counting semaphore S and invokes the V operation (i.e., signal) on the semaphore S after storing x to memory. Semaphore S is initialized to two. What is the maximum possible value of x after all processes complete execution? (GATE CS 2013)- a)-2
- b)-1
- c)1
- d)2
Correct answer is option 'D'. Can you explain this answer?
A shared variable x, initialized to zero, is operated on by four concurrent processes W, X, Y, Z as follows. Each of the processes W and X reads x from memory, increments by one, stores it to memory, and then terminates. Each of the processes Y and Z reads x from memory, decrements by two, stores it to memory, and then terminates. Each process before reading x invokes the P operation (i.e., wait) on a counting semaphore S and invokes the V operation (i.e., signal) on the semaphore S after storing x to memory. Semaphore S is initialized to two. What is the maximum possible value of x after all processes complete execution? (GATE CS 2013)
a)
-2
b)
-1
c)
1
d)
2
|
|
Sanya Agarwal answered |
Processes can run in many ways, below is one of the cases in which x attains max value
Semaphore S is initialized to 2
Semaphore S is initialized to 2
Process W executes S=1, x=1 but it doesn't update the x variable.
Then process Y executes S=0, it decrements x, now x= -2 and
signal semaphore S=1
signal semaphore S=1
Now process Z executes s=0, x=-4, signal semaphore S=1
Now process W updates x=1, S=2
Now process W updates x=1, S=2
Then process X executes X=2
So correct option is D
At particular time, the value of a counting semaphore is 10, it will become 7 after: (a) 3 V operations (b) 3 P operations (c) 5 V operations and 2 P operations (d) 2 V operations and 5 P operations Which of the following option is correct?- a)Only (b)
- b)Only(d)
- c)Both (b) and (d)
- d)None of these
Correct answer is option 'C'. Can you explain this answer?
At particular time, the value of a counting semaphore is 10, it will become 7 after: (a) 3 V operations (b) 3 P operations (c) 5 V operations and 2 P operations (d) 2 V operations and 5 P operations Which of the following option is correct?
a)
Only (b)
b)
Only(d)
c)
Both (b) and (d)
d)
None of these
|
|
Ravi Singh answered |
P: Wait operation decrements the value of the counting semaphore by 1. V: Signal operation increments the value of counting semaphore by 1. Current value of the counting semaphore = 10 a) after 3 P operations, value of semaphore = 10-3 = 7 d) after 2 v operations, and 5 operations value of semaphore = 10 + 2 - 5 = 7 Hence option (C) is correct.
Which of the following option is False?- a)An executing instance of a program is called a process while a thread is a subset of the process.
- b)Threads have considerable overhead while processes have almost no overhead.
- c)Execution of processes are independent while execution of threads are dependent.
- d)New processes require duplication of the parent process while new threads are easily created.
Correct answer is option 'B'. Can you explain this answer?
Which of the following option is False?
a)
An executing instance of a program is called a process while a thread is a subset of the process.
b)
Threads have considerable overhead while processes have almost no overhead.
c)
Execution of processes are independent while execution of threads are dependent.
d)
New processes require duplication of the parent process while new threads are easily created.
|
|
Yash Patel answered |
Processes have considerable overhead while threads have almost no overhead. Only option (B) is false.
At a particular time of computation the value of a counting semaphore is 7. Then 20 P operations and xV operations were completed on this semaphore. If the new value of semaphore is 5 ,x will be- a)18
- b)22
- c)15
- d)13
Correct answer is option 'A'. Can you explain this answer?
At a particular time of computation the value of a counting semaphore is 7. Then 20 P operations and xV operations were completed on this semaphore. If the new value of semaphore is 5 ,x will be
a)
18
b)
22
c)
15
d)
13
|
|
Yash Patel answered |
P operation : Decrements the value of semaphore by 1 V operation : Increments the value of semaphore by 1 Initially, value of semaphore = 7 After 20 P operations, value of semaphore = 7 - 20 = -13 Now, after xV operations, value of semaphore = 5 -13 + xV = 5 xV = 5 + 13 = 18 So, option (A) is correct.
Three concurrent processes X, Y, and Z execute three different code segments that access and update certain shared variables. Process X executes the P operation (i.e., wait) on semaphores a, b and c; process Y executes the P operation on semaphores b, c and d; process Z executes the P operation on semaphores c, d, and a before entering the respective code segments. After completing the execution of its code segment, each process invokes the V operation (i.e., signal) on its three semaphores. All semaphores are binary semaphores initialized to one. Which one of the following represents a deadlock-free order of invoking the P operations by the processes?- a)X: P(a)P(b)P(c) Y: P(b)P(c)P(d) Z: P(c)P(d)P(a)
- b)X: P(b)P(a)P(c) Y: P(b)P(c)P(d) Z: P(a)P(c)P(d)
- c)X: P(b)P(a)P(c) Y: P(c)P(b)P(d) Z: P(a)P(c)P(d)
- d)X: P(a)P(b)P(c) Y: P(c)P(b)P(d) Z: P(c)P(d)P(a)
Correct answer is option 'B'. Can you explain this answer?
Three concurrent processes X, Y, and Z execute three different code segments that access and update certain shared variables. Process X executes the P operation (i.e., wait) on semaphores a, b and c; process Y executes the P operation on semaphores b, c and d; process Z executes the P operation on semaphores c, d, and a before entering the respective code segments. After completing the execution of its code segment, each process invokes the V operation (i.e., signal) on its three semaphores. All semaphores are binary semaphores initialized to one. Which one of the following represents a deadlock-free order of invoking the P operations by the processes?
a)
X: P(a)P(b)P(c) Y: P(b)P(c)P(d) Z: P(c)P(d)P(a)
b)
X: P(b)P(a)P(c) Y: P(b)P(c)P(d) Z: P(a)P(c)P(d)
c)
X: P(b)P(a)P(c) Y: P(c)P(b)P(d) Z: P(a)P(c)P(d)
d)
X: P(a)P(b)P(c) Y: P(c)P(b)P(d) Z: P(c)P(d)P(a)
|
|
Sanya Agarwal answered |
Option A can cause deadlock. Imagine a situation process X has acquired a, process Y has acquired b and process Z has acquired c and d. There is circular wait now. Option C can also cause deadlock. Imagine a situation process X has acquired b, process Y has acquired c and process Z has acquired a. There is circular wait now. Option D can also cause deadlock. Imagine a situation process X has acquired a and b, process Y has acquired c. X and Y circularly waiting for each other.Consider option A) for example here all 3 processes are concurrent so X will get semaphore a, Y will get b and Z will get c, now X is blocked for b, Y is blocked for c, Z gets d and blocked for a. Thus it will lead to deadlock. Similarly one can figure out that for B) completion order is Z,X then Y.
The time taken to switch between user and kernel modes of execution be t1 while the time taken to switch between two processes be t2. Which of the following is TRUE?- a)t1 > t2
- b)t1 = t2
- c)t1 < t2
- d)nothing can be said about the relation between t1 and t2
Correct answer is option 'C'. Can you explain this answer?
The time taken to switch between user and kernel modes of execution be t1 while the time taken to switch between two processes be t2. Which of the following is TRUE?
a)
t1 > t2
b)
t1 = t2
c)
t1 < t2
d)
nothing can be said about the relation between t1 and t2
|
|
Yash Patel answered |
Process switches or Context switches can occur in only kernel mode . So for process switches first we have to move from user to kernel mode . Then we have to save the PCB of the process from which we are taking off CPU and then we have to load PCB of the required process . At switching from kernel to user mode is done. But switching from user to kernel mode is a very fast operation(OS has to just change single bit at hardware level) Thus T1< T2
A starvation free job scheduling policy guarantees that no job indefinitely waits for a service. Which of the following job scheduling policies is starvation free?- a)Priority queing
- b)Shortest Job First
- c)Youngest Job First
- d)Round robin
Correct answer is option 'D'. Can you explain this answer?
A starvation free job scheduling policy guarantees that no job indefinitely waits for a service. Which of the following job scheduling policies is starvation free?
a)
Priority queing
b)
Shortest Job First
c)
Youngest Job First
d)
Round robin
|
|
Ravi Singh answered |
Round Robin is a starvation free scheduling algorithm as it imposes a strict time bound on the response time of each process i.e. for a system with 'n' processes running in a round robin system with time quanta tq, no process will wait for more than (n-1) tq time units to get its CPU turn. Option (D) is correct.
Which of the following is/are not shared by all the threads in a process?I. Program CounterII. StackIII. RegistersIV. Address space- a)I and II only
- b)II and III only
- c)I, II and III only
- d)IV only
Correct answer is option 'C'. Can you explain this answer?
Which of the following is/are not shared by all the threads in a process?
I. Program Counter
II. Stack
III. Registers
IV. Address space
a)
I and II only
b)
II and III only
c)
I, II and III only
d)
IV only
|
|
Sanya Agarwal answered |
Every thread have its own stack, register, and PC, so only address space that is shared by all thread for a single process. Option (C) is correct.
The performance of Round Robin algorithm depends heavily on- a)size of the process
- b)the I/O bursts of the process
- c)the CPU bursts of the process
- d)the size of the time quantum
Correct answer is option 'D'. Can you explain this answer?
The performance of Round Robin algorithm depends heavily on
a)
size of the process
b)
the I/O bursts of the process
c)
the CPU bursts of the process
d)
the size of the time quantum
|
|
Ravi Singh answered |
In round robin algorithm, the size of time quanta plays a very important role as: If size of quanta is too small: Context switches will increase and it is counted as the waste time, so CPU utilization will decrease. If size of quanta is too large: Larger time quanta will lead to Round robin regenerated into FCFS scheduling algorithm. So, option (D) is correct.
Names of some of the Operating Systems are given below:(a) MS-DOS(b) XENIX(c) OS/2In the above list, following operating systems didn’t provide multiuser facility.- a)(a) only
- b)(a) and (b) only
- c)(b) and (c) only
- d)(a), (b) and (c)
Correct answer is option 'D'. Can you explain this answer?
Names of some of the Operating Systems are given below:
(a) MS-DOS
(b) XENIX
(c) OS/2
In the above list, following operating systems didn’t provide multiuser facility.
a)
(a) only
b)
(a) and (b) only
c)
(b) and (c) only
d)
(a), (b) and (c)
|
|
Sanya Agarwal answered |
MS-DOS is an operating system for x86-based personal computers mostly developed by Microsoft. It doesn't provide multi-user facility. XENIX is a discontinued version of the Unix operating system for various microcomputer platforms, licensed by Microsoft from AT&T Corporation. It doesn't provide multi-user facility. OS/2 is a series of computer operating systems, initially created by Microsoft and IBM. It doesn't provide multi-user facility. So, Option (D) is correct.
Chapter doubts & questions for Threads - 6 Months Preparation for GATE CSE 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Threads - 6 Months Preparation for GATE CSE in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
6 Months Preparation for GATE CSE
453 videos|1305 docs|700 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup on EduRev and stay on top of your study goals
10M+ students crushing their study goals daily