









All Exams >
MCAT >
Biology and Biochemistry for MCAT >
All Questions
All questions of Biologically Important Molecules for MCAT Exam
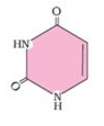

The number of amino acids found in proteins are- a)20
- b)21
- c)18
- d)16
Correct answer is option 'A'. Can you explain this answer?
The number of amino acids found in proteins are
a)
20
b)
21
c)
18
d)
16
|
|
Rohan Singh answered |
Proteinogenic amino acids are amino acids that are incorporated biosynthetically into proteins during translation. ... Throughout known life, there are 22 genetically encoded (proteinogenic) amino acids, 20 in the standard genetic code and an additional 2 that can be incorporated by special translation mechanisms.
The most abundant organic molecule present on earth is- a)Protein
- b)Lipid
- c)Steroids
- d)Cellulose
Correct answer is option 'D'. Can you explain this answer?
The most abundant organic molecule present on earth is
a)
Protein
b)
Lipid
c)
Steroids
d)
Cellulose
|
|
Raghavendra Datta answered |
The most abundant organic molecule present on earth is cellulose.
What is Cellulose?
Cellulose is a complex carbohydrate that is found in the cell walls of plants. It is composed of repeating units of glucose molecules that are linked together to form long chains. These chains are then arranged in a way that gives cellulose its characteristic strength and rigidity.
Why is Cellulose Abundant on Earth?
Cellulose is abundant on earth for several reasons:
1. It is found in the cell walls of plants - Plants are the most abundant form of life on earth, and cellulose is a major component of their cell walls. This means that there is a huge amount of cellulose present on earth.
2. It is resistant to degradation - Unlike other organic molecules, cellulose is highly resistant to degradation by enzymes and other biological processes. This means that it can persist in the environment for a long time, contributing to its abundance.
3. It is a major component of biomass - Cellulose is a major component of the biomass of plants. When plants die and decompose, the cellulose in their cell walls is broken down into smaller molecules that can be used by other organisms. This means that there is a constant supply of cellulose being produced and broken down on earth.
Conclusion:
In conclusion, cellulose is the most abundant organic molecule present on earth due to its presence in the cell walls of plants, its resistance to degradation, and its role as a major component of biomass.
What is Cellulose?
Cellulose is a complex carbohydrate that is found in the cell walls of plants. It is composed of repeating units of glucose molecules that are linked together to form long chains. These chains are then arranged in a way that gives cellulose its characteristic strength and rigidity.
Why is Cellulose Abundant on Earth?
Cellulose is abundant on earth for several reasons:
1. It is found in the cell walls of plants - Plants are the most abundant form of life on earth, and cellulose is a major component of their cell walls. This means that there is a huge amount of cellulose present on earth.
2. It is resistant to degradation - Unlike other organic molecules, cellulose is highly resistant to degradation by enzymes and other biological processes. This means that it can persist in the environment for a long time, contributing to its abundance.
3. It is a major component of biomass - Cellulose is a major component of the biomass of plants. When plants die and decompose, the cellulose in their cell walls is broken down into smaller molecules that can be used by other organisms. This means that there is a constant supply of cellulose being produced and broken down on earth.
Conclusion:
In conclusion, cellulose is the most abundant organic molecule present on earth due to its presence in the cell walls of plants, its resistance to degradation, and its role as a major component of biomass.
The plant cell wall are made up of- a)Cellulose
- b)Starch
- c)Glycogen Bacteria
- d)Inulin
Correct answer is option 'A'. Can you explain this answer?
The plant cell wall are made up of
a)
Cellulose
b)
Starch
c)
Glycogen Bacteria
d)
Inulin

|
Srishti Sen answered |
Plant cell walls are made of cellulose. Paper made from plant pulp is cellulose.
The oils have- a)High melting point
- b)Low melting point
- c)Optimum melting point
- d)No melting point
Correct answer is option 'B'. Can you explain this answer?
The oils have
a)
High melting point
b)
Low melting point
c)
Optimum melting point
d)
No melting point
|
|
Geetika Shah answered |
Oils have lower melting point (e.g., gingely oil) and hence remain as oil in winters.
The nucleotide chemical components are- a)Heterocyclic compounds, sugar and phosphate
- b)Sugar and Phosphate
- c)Heterocyclic compounds and sugar
- d)Phosphate and heterocyclic compounds
Correct answer is option 'A'. Can you explain this answer?
The nucleotide chemical components are
a)
Heterocyclic compounds, sugar and phosphate
b)
Sugar and Phosphate
c)
Heterocyclic compounds and sugar
d)
Phosphate and heterocyclic compounds

|
Akshat Chavan answered |
The nucleotide has three chemically distinct components. One is a heterocyclic compound, the second is a monosaccharide and the third a phosphoric acid or phosphate.
Which is the most abundant chemical for the living organisms?- a)Lipids
- b)Proteins
- c)Ions
- d)Water
Correct answer is option 'D'. Can you explain this answer?
Which is the most abundant chemical for the living organisms?
a)
Lipids
b)
Proteins
c)
Ions
d)
Water

|
Anand Jain answered |
Water is the most abundant chemical for the living organisms.
The energy currency of cell is—- a)GDP
- b)ATP
- c)ADP
- d)NAD
Correct answer is option 'B'. Can you explain this answer?
The energy currency of cell is—
a)
GDP
b)
ATP
c)
ADP
d)
NAD
|
|
Rohan Singh answered |
When the ATP converts to ADP, the ATP is said to be spent. he molecule is used like a battery within cells and allows the consumption of one of its phosphorous molecules.The energy currency used by all cells from bacteria to man is adenosine triphosphate (ATP).
Which one is not a denaturing factor for protein?- a)High energy radiation
- b)High pressure
- c)Drastic change in pH
- d)High temperature
Correct answer is option 'B'. Can you explain this answer?
Which one is not a denaturing factor for protein?
a)
High energy radiation
b)
High pressure
c)
Drastic change in pH
d)
High temperature

|
Prasenjit Pillai answered |
Protein molecules get denatured due to high temperature, very high or low pH and high energy radiation but there is no effect due to high pressure.
Which one of the following is fibrous protein?- a)Collagen
- b)Ribozymes
- c)Haemoglobin
- d)Hemicellulose
Correct answer is option 'A'. Can you explain this answer?
Which one of the following is fibrous protein?
a)
Collagen
b)
Ribozymes
c)
Haemoglobin
d)
Hemicellulose

|
Shanaya Rane answered |
Collagen is a fibrous protein. It is the main structural protein in the extracellular space in thevarious connective tissues. It is the most abundant protein in mammals.
A polysaccharide present as storehouse of energy of plant tissues- a)Chitin
- b)Starch
- c)Hemi cellulose
- d)Cellulose
Correct answer is option 'B'. Can you explain this answer?
A polysaccharide present as storehouse of energy of plant tissues
a)
Chitin
b)
Starch
c)
Hemi cellulose
d)
Cellulose
|
|
Jyoti Kapoor answered |
Polysaccharide
A polysaccharide is a large molecule made of many smaller monosaccharides. Monosaccharides are simple sugars, like glucose. Special enzymes bind these small monomers together creating large sugar polymers, or polysaccharides. A polysaccharide is also called a glycan. A polysaccharide can be a homopolysaccharide, in which all the monosaccharides are the same, or a heteropolysaccharide in which the monosaccharides vary. Depending on which monosaccharides are connected, and which carbons in the monosaccharides connects, polysaccharides take on a variety of forms. A molecule with a straight chain of monosaccharides is called a linear polysaccharide, while a chain that has arms and turns is known as a branched polysaccharide.
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.Assertion : Palmitic acid is an unsaturated fatty acid.Reason : These are fatty acids with double bond.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)Both A and R are false.
Correct answer is option 'D'. Can you explain this answer?
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.
Assertion : Palmitic acid is an unsaturated fatty acid.
Reason : These are fatty acids with double bond.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
Both A and R are false.
|
|
Dev Patel answered |
Palmitic acid is a saturated fatty acid. These are fatty acids without double bond.
Which of the following carries the hereditary information from parents to progeny?- a)Nucleotides
- b)Nucleoside
- c)Nucleic acids
- d)Proteins
Correct answer is option 'C'. Can you explain this answer?
Which of the following carries the hereditary information from parents to progeny?
a)
Nucleotides
b)
Nucleoside
c)
Nucleic acids
d)
Proteins
|
|
Pooja Mehta answered |
Nucleic acid is the chemical name for the molecules RNA and DNA. The name comes from the fact that these molecules are acids – that is, they are good at donating protons and accepting electron pairs in chemical reactions – and the fact that they were first discovered in the nuclei of our cells.
In yeast, during fermentation the glycolysis pathway leads to- a)Production of glucose
- b)Production of oxygen
- c)Production of pyruvic acid
- d)Production of ethanol
Correct answer is option 'D'. Can you explain this answer?
In yeast, during fermentation the glycolysis pathway leads to
a)
Production of glucose
b)
Production of oxygen
c)
Production of pyruvic acid
d)
Production of ethanol

|
Jatin Chakraborty answered |
In yeast, during fermentation, the same pathway leads to the production of ethanol(alcohol).
The part of enzyme bound to the protein part by a covalent bond is called- a)Holoenzyme
- b)Cofactor
- c)Prosthetic group
- d)Apoenzyme
Correct answer is option 'C'. Can you explain this answer?
The part of enzyme bound to the protein part by a covalent bond is called
a)
Holoenzyme
b)
Cofactor
c)
Prosthetic group
d)
Apoenzyme

|
Imk Pathsala answered |
A prosthetic group is a tightly covalently bound, specific non-polypeptide unit required for the biological function of some proteins. The prosthetic group may be organic (such as a vitamin, sugar, or lipid) or inorganic (such as a metal ion), but is not composed of amino acids.
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.Assertion : Glutamate pyruvate transaminase is a transferase enzyme.Reason : They transfer group from one molecule to another.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)Both A and R are false.
Correct answer is option 'A'. Can you explain this answer?
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.
Assertion : Glutamate pyruvate transaminase is a transferase enzyme.
Reason : They transfer group from one molecule to another.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
Both A and R are false.
|
|
Dev Patel answered |
Transferases transfer group from one molecule to another e.g., glutamate pyruvate transaminase.
Assertion (A): Competitive inhibitors bind to the active site of an enzyme, preventing substrate binding. Reason (R): Competitive inhibition can be overcome by increasing the concentration of the substrate.- a)If both Assertion and Reason are true and Reason is the correct explanation of Assertion
- b)If both Assertion and Reason are true but Reason is not the correct explanation of Assertion
- c)If Assertion is true but Reason is false
- d)If both Assertion and Reason are false
Correct answer is option 'A'. Can you explain this answer?
Assertion (A): Competitive inhibitors bind to the active site of an enzyme, preventing substrate binding.
Reason (R): Competitive inhibition can be overcome by increasing the concentration of the substrate.
a)
If both Assertion and Reason are true and Reason is the correct explanation of Assertion
b)
If both Assertion and Reason are true but Reason is not the correct explanation of Assertion
c)
If Assertion is true but Reason is false
d)
If both Assertion and Reason are false

|
Mohit Jat answered |
2
Proteins are made up of- a)Monomers
- b)Amino acids
- c)Homopolymers
- d)Nucleosides
Correct answer is option 'B'. Can you explain this answer?
Proteins are made up of
a)
Monomers
b)
Amino acids
c)
Homopolymers
d)
Nucleosides
|
|
Rohan Singh answered |
Proteins are heteropolymers usually made of amino acids. While a nucleic acid like DNA or RNA is made of of only 4 types of nucleotide monomers, proteins are made of 20 types of monomers. Ans: (d) Proteins perform many physiological functions. ... Ans: (a) Glycogen is a homopolymer made of glucose units.
Read the following passage to answer the following questions:The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.Direction : In the following questions the Assertions (A) and Reasons (R) have been put forward. Read both the statements and choose the correct option from the following:Assertion : Enzyme and substrate respectively have active and reactive sites on their surface.Reason : Active and reactive sites push the enzyme and substrate molecules away from each other.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)A is false but R is true.
Correct answer is option 'D'. Can you explain this answer?
Read the following passage to answer the following questions:
The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.
Direction : In the following questions the Assertions (A) and Reasons (R) have been put forward. Read both the statements and choose the correct option from the following:
Assertion : Enzyme and substrate respectively have active and reactive sites on their surface.
Reason : Active and reactive sites push the enzyme and substrate molecules away from each other.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
A is false but R is true.

|
Abhishek Mishraclasses answered |
Active and reactive sites of enzyme and substrate do not push away each either but make them to unite to form the ES complex.
Which of the following is not obtained on hydrolysis of nucleic acid?- a)Purine
- b)Phosphoric acid
- c)Pyrimidine
- d)Pentose sugar
Correct answer is option 'B'. Can you explain this answer?
Which of the following is not obtained on hydrolysis of nucleic acid?
a)
Purine
b)
Phosphoric acid
c)
Pyrimidine
d)
Pentose sugar

|
Ruchi Chopra answered |
Hydrolysis of nucleic acid (DNA and RNA) produces pentose sugar (ribose or deoxyribose) purine and pyrimidine. Phosphoric acid is not released on hydrolysis of DNA or RNA.
Read the following passage to answer the following questions:
Proteins are polypeptide chains made up of amino acids. There are 20 types of amino acids joined together by peptide bond between amino and carboxylic group. There are two kinds of amino acids, Essential amino acids and Non-essential amino acids. The Primary structure of protein is the linear sequence of amino acids in a polypeptide chain. The first amino acid of sequence is called N-terminal amino acids and last amino acid of peptide chain is called C-terminal amino acids. The secondary structure proteins forms helix. There are three types of secondary structure: a helix, P pleated and collagen helix. In tertiary structure long protein chain is folded upon itself like a hollow woollen ball to give three-dimensional view of protein. In quaternary structure, each polypeptide develops its own tertiary structure and function as subunit of protein.
Direction: In the following questions the Assertions (A) and Reasons (R) have been put forward. Read both the statements and choose the correct option from the following:
Assertion : Amino acids are monomers of nucleic acid.
Reason : Protein amino acids have an unlimited variety.
- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)If both Assertion and Reason are false.
Correct answer is option 'D'. Can you explain this answer?
Read the following passage to answer the following questions:
Proteins are polypeptide chains made up of amino acids. There are 20 types of amino acids joined together by peptide bond between amino and carboxylic group. There are two kinds of amino acids, Essential amino acids and Non-essential amino acids. The Primary structure of protein is the linear sequence of amino acids in a polypeptide chain. The first amino acid of sequence is called N-terminal amino acids and last amino acid of peptide chain is called C-terminal amino acids. The secondary structure proteins forms helix. There are three types of secondary structure: a helix, P pleated and collagen helix. In tertiary structure long protein chain is folded upon itself like a hollow woollen ball to give three-dimensional view of protein. In quaternary structure, each polypeptide develops its own tertiary structure and function as subunit of protein.
Direction: In the following questions the Assertions (A) and Reasons (R) have been put forward. Read both the statements and choose the correct option from the following:
Assertion : Amino acids are monomers of nucleic acid.
Reason : Protein amino acids have an unlimited variety.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
If both Assertion and Reason are false.
|
|
Dev Patel answered |
Amino acids are monomers of protein and are not of nucleic acid. Proteins are built from a set of only 20 amino acid.
An amino acid that yields acetoacetyl CoA during the catabolism of its carbon skeleton will be considered as ________.- a)Glycogenic
- b)Ketogenic
- c)Both glycogenic and ketogenic
- d)Essential
Correct answer is option 'B'. Can you explain this answer?
An amino acid that yields acetoacetyl CoA during the catabolism of its carbon skeleton will be considered as ________.
a)
Glycogenic
b)
Ketogenic
c)
Both glycogenic and ketogenic
d)
Essential

|
Orion Classes answered |
In case of Glycogenic amino acids pyruvate metabolites are formed and in case of ketogenic amino acids acetoacyl CoA is formed during the catabolism.
Which of the statements given above is/are correct?i. Lipids are generally water soluble and include simple fatty acids.ii. Fatty acids can be either saturated (without double bonds) or unsaturated (with one or more double bonds).iii. Glycerol is a simple sugar that can be esterified with fatty acids to form triglycerides.iv. Phospholipids are found in cell membranes and contain phosphorus.- a)ii and iv
- b)i and iii
- c)i, ii, and iv
- d)ii and iii
Correct answer is option 'A'. Can you explain this answer?
Which of the statements given above is/are correct?
i. Lipids are generally water soluble and include simple fatty acids.
ii. Fatty acids can be either saturated (without double bonds) or unsaturated (with one or more double bonds).
iii. Glycerol is a simple sugar that can be esterified with fatty acids to form triglycerides.
iv. Phospholipids are found in cell membranes and contain phosphorus.
a)
ii and iv
b)
i and iii
c)
i, ii, and iv
d)
ii and iii

|
Top Rankers answered |
To determine the correct statements:
- Statement i is incorrect because lipids are generally water insoluble, not soluble.
- Statement ii is correct as it accurately describes the types of fatty acids.
- Statement iii is incorrect because glycerol is not a simple sugar; it is a trihydroxy alcohol (trihydroxy propane) that combines with fatty acids to form triglycerides.
- Statement iv is correct as phospholipids are indeed found in cell membranes and contain phosphorus.
Thus, the correct statements are ii and iv, making Option A the right choice.
How many subunits are there in human adult haemoglobin?- a)4
- b)5
- c)3
- d)2
Correct answer is option 'A'. Can you explain this answer?
How many subunits are there in human adult haemoglobin?
a)
4
b)
5
c)
3
d)
2

|
Rajat Roy answered |
Proteins human haemoglobin consists of 4 subunits. Two of these are identical toeach other. Hence, two subunits of αα type and two subunits of ββ type together constitute the human haemoglobin (Hb).
Directions: In the following question, two statements are given. One is assertion and the other is reason. Examine the statements carefully and mark the correct option.Assertion: Both amino group and acidic group act as substituents on the same carbon called α-amino acids.Reason: Amino acids are inorganic compounds containing an amino group.- a)Both assertion and reason are true and reason is the correct explanation of assertion.
- b)Assertion is true but the reason is false.
- c)Both assertion and reason are true but reason is not the correct explanation of assertion.
- d)Assertion is false but the reason is true.
Correct answer is option 'B'. Can you explain this answer?
Directions: In the following question, two statements are given. One is assertion and the other is reason. Examine the statements carefully and mark the correct option.
Assertion: Both amino group and acidic group act as substituents on the same carbon called α-amino acids.
Reason: Amino acids are inorganic compounds containing an amino group.
a)
Both assertion and reason are true and reason is the correct explanation of assertion.
b)
Assertion is true but the reason is false.
c)
Both assertion and reason are true but reason is not the correct explanation of assertion.
d)
Assertion is false but the reason is true.

|
Lead Academy answered |
Amino acids are organic compounds containing an amino group and an acidic group as substituents on the same carbon, i.e. the α-carbon. Hence, they are called α-amino acids.
Secondary structure of protein refers to- a)Folding patterns of polypeptide chain
- b)Sequence of amino acids in polypeptide chain
- c)Bonds between alternate polypeptide chains
- d)Bonding between NH+3 and COO– of two peptides
Correct answer is option 'A'. Can you explain this answer?
Secondary structure of protein refers to
a)
Folding patterns of polypeptide chain
b)
Sequence of amino acids in polypeptide chain
c)
Bonds between alternate polypeptide chains
d)
Bonding between NH+3 and COO– of two peptides
|
|
Gargi Datta answered |
Secondary Structure of Proteins
Secondary structure of a protein refers to the folding patterns of the polypeptide chain. This structure is primarily determined by hydrogen bonding between amino acids along the polypeptide chain.
Key Points:
- The most common secondary structures are alpha helices and beta sheets.
- In an alpha helix, the polypeptide chain is coiled like a spring.
- In beta sheets, the polypeptide chain folds back and forth on itself.
- These structures are stabilized by hydrogen bonds between the backbone atoms of the amino acids.
Folding Patterns of Polypeptide Chain
The folding patterns of the polypeptide chain in a protein determine its secondary structure. These patterns are essential for the protein to maintain its specific shape and function. The secondary structure is crucial for the overall three-dimensional structure of the protein.
Hydrogen Bonding
Hydrogen bonding plays a significant role in stabilizing the secondary structure of proteins. The hydrogen bonds form between the amino acid residues, specifically between the hydrogen of the amino group and the oxygen of the carbonyl group. These bonds help maintain the structural integrity of the protein.
In conclusion, the secondary structure of a protein is defined by the folding patterns of the polypeptide chain, primarily stabilized by hydrogen bonding between amino acids. This structure is essential for the overall function and stability of the protein.
Secondary structure of a protein refers to the folding patterns of the polypeptide chain. This structure is primarily determined by hydrogen bonding between amino acids along the polypeptide chain.
Key Points:
- The most common secondary structures are alpha helices and beta sheets.
- In an alpha helix, the polypeptide chain is coiled like a spring.
- In beta sheets, the polypeptide chain folds back and forth on itself.
- These structures are stabilized by hydrogen bonds between the backbone atoms of the amino acids.
Folding Patterns of Polypeptide Chain
The folding patterns of the polypeptide chain in a protein determine its secondary structure. These patterns are essential for the protein to maintain its specific shape and function. The secondary structure is crucial for the overall three-dimensional structure of the protein.
Hydrogen Bonding
Hydrogen bonding plays a significant role in stabilizing the secondary structure of proteins. The hydrogen bonds form between the amino acid residues, specifically between the hydrogen of the amino group and the oxygen of the carbonyl group. These bonds help maintain the structural integrity of the protein.
In conclusion, the secondary structure of a protein is defined by the folding patterns of the polypeptide chain, primarily stabilized by hydrogen bonding between amino acids. This structure is essential for the overall function and stability of the protein.
Which of the following statements regarding the catalytic cycle of enzyme action is/are correct?i. The substrate binds to the active site of the enzyme, fitting perfectly into it.ii. The enzyme changes shape to fit more tightly around the substrate after binding occurs.iii. The enzyme-product complex is formed when the active site breaks the chemical bonds of the substrate.iv. The enzyme remains permanently altered after releasing the products of the reaction.- a)ii and iii
- b)i and ii
- c)iii and iv
- d)i, ii, and iii
Correct answer is option 'D'. Can you explain this answer?
Which of the following statements regarding the catalytic cycle of enzyme action is/are correct?
i. The substrate binds to the active site of the enzyme, fitting perfectly into it.
ii. The enzyme changes shape to fit more tightly around the substrate after binding occurs.
iii. The enzyme-product complex is formed when the active site breaks the chemical bonds of the substrate.
iv. The enzyme remains permanently altered after releasing the products of the reaction.
a)
ii and iii
b)
i and ii
c)
iii and iv
d)
i, ii, and iii

|
Ciel Knowledge answered |
To determine which statements are correct, let's analyze each one:
- Statement i: This statement describes the initial binding of the substrate to the enzyme's active site, which is accurate as enzymes typically have specific active sites that fit their substrates (the "lock and key" model).
- Statement ii: This statement is also correct. After the substrate binds, the enzyme undergoes an "induced fit," altering its shape for a tighter fit around the substrate.
- Statement iii: This statement correctly describes the formation of the enzyme-product complex, where the active site facilitates the breaking of chemical bonds in the substrate.
- Statement iv: This statement is incorrect. Enzymes are not permanently altered after the reaction; they can be reused to catalyze additional reactions.
Thus, the correct statements are i, ii, and iii, leading to the correct answer being Option D.
If pK1 = 2.34 and pK2 = 9.60, then the isoelectric point pI is?- a)5.87
- b)5.97
- c)3.67
- d)11.94
Correct answer is option 'B'. Can you explain this answer?
If pK1 = 2.34 and pK2 = 9.60, then the isoelectric point pI is?
a)
5.87
b)
5.97
c)
3.67
d)
11.94
|
|
Orion Classes answered |
pI = 1⁄2 (pK1 + pK2) = 1⁄2 (2.34 + 9.60) = 5.97.
Which of the following represents the two-dimensional structure of proteins?- a)Quaternary
- b)Tertiary
- c)Secondary
- d)Primary
Correct answer is option 'D'. Can you explain this answer?
Which of the following represents the two-dimensional structure of proteins?
a)
Quaternary
b)
Tertiary
c)
Secondary
d)
Primary
|
|
Orion Classes answered |
The primary structure of Protein represents the two-dimensional structure of proteins. The primary structure of proteins just contains amino acids linked together to form a long chain of a polypeptide. Quaternary, tertiary, and secondary structure refers to the three-dimensional structure of proteins.
Assertion (A): The acid insoluble fraction of biomolecules includes proteins, nucleic acids, polysaccharides, and lipids, which are all classified as macromolecules. Reason (R): Lipids, despite having lower molecular weights than 800 Da, are classified as macromolecules because they exhibit polymeric characteristics.- a)If both Assertion and Reason are true and Reason is the correct explanation of Assertion
- b)If both Assertion and Reason are false
- c)If both Assertion and Reason are true but Reason is not the correct explanation of Assertion
- d)If Assertion is true but Reason is false
Correct answer is option 'C'. Can you explain this answer?
Assertion (A): The acid insoluble fraction of biomolecules includes proteins, nucleic acids, polysaccharides, and lipids, which are all classified as macromolecules.
Reason (R): Lipids, despite having lower molecular weights than 800 Da, are classified as macromolecules because they exhibit polymeric characteristics.
a)
If both Assertion and Reason are true and Reason is the correct explanation of Assertion
b)
If both Assertion and Reason are false
c)
If both Assertion and Reason are true but Reason is not the correct explanation of Assertion
d)
If Assertion is true but Reason is false
|
|
Sanaya Dey answered |
Understanding the Assertion and Reason
The question presents an Assertion (A) and a Reason (R) regarding the classification of biomolecules. Let’s analyze both statements for clarity.
Assertion (A)
- The acid insoluble fraction of biomolecules includes:
- Proteins
- Nucleic acids
- Polysaccharides
- Lipids
- These are all categorized as macromolecules due to their large size and complex structures.
Reason (R)
- Lipids are mentioned as having lower molecular weights than 800 Da.
- The classification of lipids as macromolecules is attributed to their polymeric characteristics.
Analysis of the Statements
- Assertion:
- True: All the mentioned biomolecules are indeed macromolecules, which are typically defined as large molecules composed of smaller structural units (monomers).
- Reason:
- True: While lipids can have molecular weights lower than 800 Da, they are classified as macromolecules because of their complex structures and functions in biological systems. However, lipids do not exhibit true polymeric characteristics like proteins and nucleic acids, which are formed from repeating monomer units.
Conclusion
- Both Assertion and Reason are true, but the Reason does not correctly explain the Assertion. Lipids are categorized as macromolecules based on their functional roles and structural complexity rather than their molecular weight or polymeric nature.
Thus, the correct answer is option C: Both Assertion and Reason are true, but Reason is not the correct explanation of Assertion.
The question presents an Assertion (A) and a Reason (R) regarding the classification of biomolecules. Let’s analyze both statements for clarity.
Assertion (A)
- The acid insoluble fraction of biomolecules includes:
- Proteins
- Nucleic acids
- Polysaccharides
- Lipids
- These are all categorized as macromolecules due to their large size and complex structures.
Reason (R)
- Lipids are mentioned as having lower molecular weights than 800 Da.
- The classification of lipids as macromolecules is attributed to their polymeric characteristics.
Analysis of the Statements
- Assertion:
- True: All the mentioned biomolecules are indeed macromolecules, which are typically defined as large molecules composed of smaller structural units (monomers).
- Reason:
- True: While lipids can have molecular weights lower than 800 Da, they are classified as macromolecules because of their complex structures and functions in biological systems. However, lipids do not exhibit true polymeric characteristics like proteins and nucleic acids, which are formed from repeating monomer units.
Conclusion
- Both Assertion and Reason are true, but the Reason does not correctly explain the Assertion. Lipids are categorized as macromolecules based on their functional roles and structural complexity rather than their molecular weight or polymeric nature.
Thus, the correct answer is option C: Both Assertion and Reason are true, but Reason is not the correct explanation of Assertion.
Read the following passage to answer the following questions:The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.Q. Khosland's model of enzyme action implies that:- a)Enzyme and substrate unit at the active site like lock and key fits a lock.
- b)Inducible change is brought about at the active site of enzyme by substrate.
- c)Active site of enzyme brings about the conformational change in the substrate.
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Read the following passage to answer the following questions:
The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.
Q. Khosland's model of enzyme action implies that:
a)
Enzyme and substrate unit at the active site like lock and key fits a lock.
b)
Inducible change is brought about at the active site of enzyme by substrate.
c)
Active site of enzyme brings about the conformational change in the substrate.
d)
None of the above
|
|
Raghav Bansal answered |
The substrate brings about the conformational change in the active site of enzyme thus forming suitable ES complex This is in accordance with the Khosland's induced fit model of enzyme action.
Identify the correct pairing between nitrogen bases in DNA.- a)T+C/G+A
- b)A+G/C+T
- c)A+C/T+G
- d)G+C/A+T
Correct answer is option 'D'. Can you explain this answer?
Identify the correct pairing between nitrogen bases in DNA.
a)
T+C/G+A
b)
A+G/C+T
c)
A+C/T+G
d)
G+C/A+T

|
Pallabi Reddy answered |
There are two hydrogen bonds between A and T pairing. There are three hydrogen bonds between G andC pairing. Each strand appears like a helical staircase.
Which of the following pairs is incorrect?- a)Terpenoides: Abrin and Ricin
- b)Alkaloids: Morphine and Codeine
- c)Pigments: Carotenoids and Anthocyanins
- d)Drugs: Vinblastin and Curcumin
Correct answer is option 'A'. Can you explain this answer?
Which of the following pairs is incorrect?
a)
Terpenoides: Abrin and Ricin
b)
Alkaloids: Morphine and Codeine
c)
Pigments: Carotenoids and Anthocyanins
d)
Drugs: Vinblastin and Curcumin
|
|
Pooja Mukherjee answered |
Explanation of Incorrect Pair
The incorrect pair in the given options is:
Terpenoids: Abrin and Ricin
Understanding the Components
- Terpenoids:
- These are a large class of organic compounds produced by a variety of plants, particularly conifers.
- They are derived from isoprene units and are often responsible for the aromatic properties of many plants.
- Examples include menthol and limonene.
- Abrin and Ricin:
- Both are toxic proteins derived from specific plant seeds (Abrus precatorius for abrin and Ricinus communis for ricin).
- They are classified as lectins and not terpenoids, meaning they do not fit into the terpenoid category.
Correct Pairings
- Alkaloids: Morphine and Codeine:
- Alkaloids are nitrogen-containing compounds known for their pharmacological effects.
- Morphine and codeine are both derived from the opium poppy and exhibit analgesic properties.
- Pigments: Carotenoids and Anthocyanins:
- Both are pigments found in plants, carotenoids giving yellow to red hues, and anthocyanins providing red, purple, and blue colors.
- Drugs: Vinblastine and Curcumin:
- Vinblastine is a chemotherapy medication, while curcumin is a compound found in turmeric with anti-inflammatory properties.
Conclusion
The classification of abrin and ricin as terpenoids is incorrect, making option A the right answer. The other pairs accurately represent their respective categories.
The incorrect pair in the given options is:
Terpenoids: Abrin and Ricin
Understanding the Components
- Terpenoids:
- These are a large class of organic compounds produced by a variety of plants, particularly conifers.
- They are derived from isoprene units and are often responsible for the aromatic properties of many plants.
- Examples include menthol and limonene.
- Abrin and Ricin:
- Both are toxic proteins derived from specific plant seeds (Abrus precatorius for abrin and Ricinus communis for ricin).
- They are classified as lectins and not terpenoids, meaning they do not fit into the terpenoid category.
Correct Pairings
- Alkaloids: Morphine and Codeine:
- Alkaloids are nitrogen-containing compounds known for their pharmacological effects.
- Morphine and codeine are both derived from the opium poppy and exhibit analgesic properties.
- Pigments: Carotenoids and Anthocyanins:
- Both are pigments found in plants, carotenoids giving yellow to red hues, and anthocyanins providing red, purple, and blue colors.
- Drugs: Vinblastine and Curcumin:
- Vinblastine is a chemotherapy medication, while curcumin is a compound found in turmeric with anti-inflammatory properties.
Conclusion
The classification of abrin and ricin as terpenoids is incorrect, making option A the right answer. The other pairs accurately represent their respective categories.
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.Assertion : In peroxidase, haemoglobin, myoglobin and catalase, haem is prosthetic group.Reason : Prosthetic groups are non-protein organic factors which are firmly attached to the apoenzyme.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)Both A and R are false.
Correct answer is option 'A'. Can you explain this answer?
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.
Assertion : In peroxidase, haemoglobin, myoglobin and catalase, haem is prosthetic group.
Reason : Prosthetic groups are non-protein organic factors which are firmly attached to the apoenzyme.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
Both A and R are false.
|
|
Dev Patel answered |
Prosthetic groups are non-protein organic factors which are firmly attached to the apoenzyme. e.g. In peroxidase, haemoglobin, myoglobin and catalase, haem is prosthetic group.
Read the following passage to answer the following questions:
Neutral or true fats are esters of fatty acid with glycerol. They are also called glycerol. A fat molecule consists of one molecule of glycerol and one to three molecules of the same or different long-chain fatty acids. Glycerol has 3 carbons each bearing a hydroxyl (OH) group. Whereas fatty acid molecule is an unbranched chain of carbon atoms having a carboxylic group attached to an R group. The R group could be a methyl (-CH3) or ethyl (-C2H5) or higher number of -CH2 groups (C1 to 19-C). eg. Palmitic acid has 16-C. Saturated fatty acid are without double bonds whereas unsaturated fatty acid are with one or more double bonds. Neutral fats may be monoglycerides if there is only one molecule of fatty acid attached to a glycerol molecule. If the number of fatty acids attached is two then it is a diglyceride or triglyceride if it is three. Esters of fatty acid with high molecular weight alcohol are called waxes. Compound lipids are also esters but contain some other substances also. Steroids and prostaglandins are derived lipids.
Q. Paraffin wax is
- a)Ester
- b)Acid
- c)Monohydric alcohol
- d)Cholesterol
Correct answer is option 'A'. Can you explain this answer?
Read the following passage to answer the following questions:
Neutral or true fats are esters of fatty acid with glycerol. They are also called glycerol. A fat molecule consists of one molecule of glycerol and one to three molecules of the same or different long-chain fatty acids. Glycerol has 3 carbons each bearing a hydroxyl (OH) group. Whereas fatty acid molecule is an unbranched chain of carbon atoms having a carboxylic group attached to an R group. The R group could be a methyl (-CH3) or ethyl (-C2H5) or higher number of -CH2 groups (C1 to 19-C). eg. Palmitic acid has 16-C. Saturated fatty acid are without double bonds whereas unsaturated fatty acid are with one or more double bonds. Neutral fats may be monoglycerides if there is only one molecule of fatty acid attached to a glycerol molecule. If the number of fatty acids attached is two then it is a diglyceride or triglyceride if it is three. Esters of fatty acid with high molecular weight alcohol are called waxes. Compound lipids are also esters but contain some other substances also. Steroids and prostaglandins are derived lipids.
Q. Paraffin wax is
a)
Ester
b)
Acid
c)
Monohydric alcohol
d)
Cholesterol
|
|
Neha Menon answered |
Understanding Paraffin Wax
Paraffin wax is primarily classified as an ester, and here's why:
Definition of Esters
- Esters are organic compounds formed from the reaction of an alcohol and a carboxylic acid.
- They have the general structure RCOOR', where R and R' represent hydrocarbon chains.
Composition of Paraffin Wax
- Paraffin wax is derived from long-chain hydrocarbons, typically containing 20 to 40 carbon atoms.
- It is produced through the distillation of petroleum and consists of a mixture of straight-chain or branched-chain hydrocarbons.
Relation to Lipids
- In the context of fats and oils, esters are formed when fatty acids react with alcohols.
- While paraffin wax is not a fatty acid ester in the classical sense, it is categorized as an ester due to its formation from hydrocarbon chains, similar to how fats form from glycerol and fatty acids.
Characteristics of Paraffin Wax
- Paraffin wax is solid at room temperature and is commonly used in candles, cosmetics, and food packaging.
- Its properties, such as low reactivity and hydrophobic nature, are typical of esters.
Conclusion
- Therefore, the correct answer is option 'A' because paraffin wax can be understood as a type of ester derived from long-chain hydrocarbons, aligning with the broader definition of esters in organic chemistry.
This classification is crucial in understanding the chemical properties and uses of paraffin wax in various applications.
Paraffin wax is primarily classified as an ester, and here's why:
Definition of Esters
- Esters are organic compounds formed from the reaction of an alcohol and a carboxylic acid.
- They have the general structure RCOOR', where R and R' represent hydrocarbon chains.
Composition of Paraffin Wax
- Paraffin wax is derived from long-chain hydrocarbons, typically containing 20 to 40 carbon atoms.
- It is produced through the distillation of petroleum and consists of a mixture of straight-chain or branched-chain hydrocarbons.
Relation to Lipids
- In the context of fats and oils, esters are formed when fatty acids react with alcohols.
- While paraffin wax is not a fatty acid ester in the classical sense, it is categorized as an ester due to its formation from hydrocarbon chains, similar to how fats form from glycerol and fatty acids.
Characteristics of Paraffin Wax
- Paraffin wax is solid at room temperature and is commonly used in candles, cosmetics, and food packaging.
- Its properties, such as low reactivity and hydrophobic nature, are typical of esters.
Conclusion
- Therefore, the correct answer is option 'A' because paraffin wax can be understood as a type of ester derived from long-chain hydrocarbons, aligning with the broader definition of esters in organic chemistry.
This classification is crucial in understanding the chemical properties and uses of paraffin wax in various applications.
Read the following passage to answer the following questions:The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.Q. Model of Emil Fisher implies that:- a)Active site of enzyme is flexible and adjust to the substrate.
- b)An enzyme and a substrate unit at the active site thus forming the enzyme substrate complex.
- c)The active site requires removal of PO4 group.
- d)Active site is complementary to that of substrate.
Correct answer is option 'D'. Can you explain this answer?
Read the following passage to answer the following questions:
The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.
Q. Model of Emil Fisher implies that:
a)
Active site of enzyme is flexible and adjust to the substrate.
b)
An enzyme and a substrate unit at the active site thus forming the enzyme substrate complex.
c)
The active site requires removal of PO4 group.
d)
Active site is complementary to that of substrate.
|
|
Abhijeet Sengupta answered |
Understanding Emil Fischer's Model
Emil Fischer proposed the "lock and key" model to explain how enzymes interact with substrates, highlighting the specificity of enzyme-substrate binding.
Key Concepts of the Model:
- Complementary Shapes:
- The active site of the enzyme is shaped specifically to fit its substrate, much like a key fits into a lock. This shape complementarity is crucial for the enzyme's function.
- Enzyme-Substrate Complex Formation:
- When the substrate enters the active site, an enzyme-substrate complex is formed. This interaction is highly specific due to the precise matching of shapes between the enzyme's active site and the substrate.
- Mechanism of Action:
- Once the substrate binds, the enzyme catalyzes the conversion of the substrate into products. This process relies on the unique shape of the active site, which allows for efficient binding and reaction.
- Release of Products:
- After the reaction, the products have a different shape than the substrate and are released from the active site, allowing the enzyme to return to its original state and be ready to catalyze another reaction.
Conclusion
The correct answer, option D, emphasizes that the active site of the enzyme is complementary to that of the substrate. This specificity is what allows enzymes to function effectively, ensuring that they catalyze only particular reactions with their respective substrates. Understanding this model is fundamental in biochemistry and plays a critical role in fields like drug design and metabolic engineering.
Emil Fischer proposed the "lock and key" model to explain how enzymes interact with substrates, highlighting the specificity of enzyme-substrate binding.
Key Concepts of the Model:
- Complementary Shapes:
- The active site of the enzyme is shaped specifically to fit its substrate, much like a key fits into a lock. This shape complementarity is crucial for the enzyme's function.
- Enzyme-Substrate Complex Formation:
- When the substrate enters the active site, an enzyme-substrate complex is formed. This interaction is highly specific due to the precise matching of shapes between the enzyme's active site and the substrate.
- Mechanism of Action:
- Once the substrate binds, the enzyme catalyzes the conversion of the substrate into products. This process relies on the unique shape of the active site, which allows for efficient binding and reaction.
- Release of Products:
- After the reaction, the products have a different shape than the substrate and are released from the active site, allowing the enzyme to return to its original state and be ready to catalyze another reaction.
Conclusion
The correct answer, option D, emphasizes that the active site of the enzyme is complementary to that of the substrate. This specificity is what allows enzymes to function effectively, ensuring that they catalyze only particular reactions with their respective substrates. Understanding this model is fundamental in biochemistry and plays a critical role in fields like drug design and metabolic engineering.
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.Assertion : Haemoglobin has quaternary structure.Reason : Haemoglobin has four chains, two α-chains and two β-chains.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)Both A and R are false.
Correct answer is option 'A'. Can you explain this answer?
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.
Assertion : Haemoglobin has quaternary structure.
Reason : Haemoglobin has four chains, two α-chains and two β-chains.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
Both A and R are false.
|
|
Bijoy Rane answered |
Assertion: Haemoglobin has quaternary structure.
Reason: Haemoglobin has four chains, two α-chains and two β-chains.
Explanation:
The quaternary structure of a protein refers to its arrangement of multiple protein subunits. In the case of hemoglobin, it is composed of four protein chains, two α-chains, and two β-chains. Each chain is associated with a heme group, which contains an iron atom that binds to oxygen.
Quaternary Structure of Hemoglobin:
Hemoglobin is a globular protein found in red blood cells and is responsible for transporting oxygen throughout the body. It consists of four subunits arranged in a quaternary structure. These subunits are designated as α1, α2, β1, and β2.
Reasoning:
The reason provided, stating that hemoglobin has four chains, two α-chains, and two β-chains, supports the assertion that hemoglobin has a quaternary structure. The quaternary structure of hemoglobin arises from the association of these four protein chains. Each chain contributes to the overall structure and function of the protein.
Importance of Quaternary Structure:
The quaternary structure of hemoglobin is crucial for its function. The four subunits come together to form a functional hemoglobin molecule, which can bind and transport oxygen. The association of the α-chains and β-chains is necessary for the proper folding and stability of the protein. Any disruption in the quaternary structure of hemoglobin can lead to functional abnormalities, such as sickle cell anemia.
Conclusion:
Both the assertion and reason are true. The reason correctly explains why the assertion is true. Hemoglobin indeed has a quaternary structure due to the presence of four protein chains, two α-chains, and two β-chains. This quaternary structure is vital for the proper functioning of hemoglobin in oxygen transport.
Reason: Haemoglobin has four chains, two α-chains and two β-chains.
Explanation:
The quaternary structure of a protein refers to its arrangement of multiple protein subunits. In the case of hemoglobin, it is composed of four protein chains, two α-chains, and two β-chains. Each chain is associated with a heme group, which contains an iron atom that binds to oxygen.
Quaternary Structure of Hemoglobin:
Hemoglobin is a globular protein found in red blood cells and is responsible for transporting oxygen throughout the body. It consists of four subunits arranged in a quaternary structure. These subunits are designated as α1, α2, β1, and β2.
Reasoning:
The reason provided, stating that hemoglobin has four chains, two α-chains, and two β-chains, supports the assertion that hemoglobin has a quaternary structure. The quaternary structure of hemoglobin arises from the association of these four protein chains. Each chain contributes to the overall structure and function of the protein.
Importance of Quaternary Structure:
The quaternary structure of hemoglobin is crucial for its function. The four subunits come together to form a functional hemoglobin molecule, which can bind and transport oxygen. The association of the α-chains and β-chains is necessary for the proper folding and stability of the protein. Any disruption in the quaternary structure of hemoglobin can lead to functional abnormalities, such as sickle cell anemia.
Conclusion:
Both the assertion and reason are true. The reason correctly explains why the assertion is true. Hemoglobin indeed has a quaternary structure due to the presence of four protein chains, two α-chains, and two β-chains. This quaternary structure is vital for the proper functioning of hemoglobin in oxygen transport.
Which of the following are aromatic amino acids?- a)Phenylalanine, tryptophan
- b)Serine, glutamic acid
- c)Alanine, glycine
- d)Lysine, valine
Correct answer is option 'A'. Can you explain this answer?
Which of the following are aromatic amino acids?
a)
Phenylalanine, tryptophan
b)
Serine, glutamic acid
c)
Alanine, glycine
d)
Lysine, valine

|
Ashwini Khanna answered |
Based on number of amino and carboxyl groups, there are acidic (e.g., glutamic acid), basic (lysine) and neutral (valine) amino acids. Similarly, there are aromatic amino acids (tyrosine, phenylalanine, tryptophan).
What happens to enzymes at low temperature?- a)They get inactivated.
- b)They get over activated.
- c)They remain unaffected.
- d)They get denatured.
Correct answer is option 'A'. Can you explain this answer?
What happens to enzymes at low temperature?
a)
They get inactivated.
b)
They get over activated.
c)
They remain unaffected.
d)
They get denatured.
|
|
Prasenjit Khanna answered |
Effect of Low Temperature on Enzymes
Enzymes are biological catalysts that speed up chemical reactions in living organisms. Temperature plays a crucial role in their activity.
1. Enzyme Activity at Low Temperatures
- At low temperatures, enzymes do not function optimally.
- Enzyme-catalyzed reactions typically slow down because molecular movement decreases.
2. Kinetic Energy Reduction
- Enzymes rely on kinetic energy to facilitate interactions with substrates.
- Lower temperatures result in reduced kinetic energy, leading to fewer effective collisions between enzymes and substrates.
3. Inactivation of Enzymes
- Although enzymes are not denatured at low temperatures, their activity can be significantly diminished.
- The result is a state of inactivation where the enzyme is present but not catalyzing reactions effectively.
4. Temperature and Reaction Rates
- The general rule is that for every 10°C decrease in temperature, the reaction rate can drop by about half.
- This is why many biological processes slow down during colder conditions.
5. Reversible Nature of Enzyme Inactivation
- It is important to note that this inactivation is often reversible.
- When temperatures rise back to optimal levels, enzyme activity can resume.
Conclusion
In summary, at low temperatures, enzymes can become inactivated due to reduced kinetic energy and decreased reaction rates. This impact is critical to understanding enzyme functionality, particularly in biological and biochemical contexts.
Enzymes are biological catalysts that speed up chemical reactions in living organisms. Temperature plays a crucial role in their activity.
1. Enzyme Activity at Low Temperatures
- At low temperatures, enzymes do not function optimally.
- Enzyme-catalyzed reactions typically slow down because molecular movement decreases.
2. Kinetic Energy Reduction
- Enzymes rely on kinetic energy to facilitate interactions with substrates.
- Lower temperatures result in reduced kinetic energy, leading to fewer effective collisions between enzymes and substrates.
3. Inactivation of Enzymes
- Although enzymes are not denatured at low temperatures, their activity can be significantly diminished.
- The result is a state of inactivation where the enzyme is present but not catalyzing reactions effectively.
4. Temperature and Reaction Rates
- The general rule is that for every 10°C decrease in temperature, the reaction rate can drop by about half.
- This is why many biological processes slow down during colder conditions.
5. Reversible Nature of Enzyme Inactivation
- It is important to note that this inactivation is often reversible.
- When temperatures rise back to optimal levels, enzyme activity can resume.
Conclusion
In summary, at low temperatures, enzymes can become inactivated due to reduced kinetic energy and decreased reaction rates. This impact is critical to understanding enzyme functionality, particularly in biological and biochemical contexts.
Which of the following statements regarding nucleic acids is/are correct?i. Nucleic acids are comprised of polynucleotides that contain ribose or deoxyribose sugars.ii. The building blocks of nucleic acids are amino acids.iii. The nitrogenous bases adenine, guanine, uracil, cytosine, and thymine are found in nucleic acids.iv. DNA is a type of nucleic acid that contains ribose sugar.- a)A: i and iii
- b)B: ii and iv
- c)C: i, iii, and iv
- d)D: i, ii, and iii
Correct answer is option 'A'. Can you explain this answer?
Which of the following statements regarding nucleic acids is/are correct?
i. Nucleic acids are comprised of polynucleotides that contain ribose or deoxyribose sugars.
ii. The building blocks of nucleic acids are amino acids.
iii. The nitrogenous bases adenine, guanine, uracil, cytosine, and thymine are found in nucleic acids.
iv. DNA is a type of nucleic acid that contains ribose sugar.
a)
A: i and iii
b)
B: ii and iv
c)
C: i, iii, and iv
d)
D: i, ii, and iii
|
|
Devanshi Banerjee answered |
Understanding Nucleic Acids
Nucleic acids are fundamental biomolecules essential for all forms of life. Let’s analyze each statement individually to determine their correctness.
Statement i: Nucleic acids are comprised of polynucleotides that contain ribose or deoxyribose sugars.
- This statement is correct. Nucleic acids, such as RNA and DNA, are polymers (polynucleotides) made up of nucleotides, which include ribose (in RNA) and deoxyribose (in DNA) sugars.
Statement ii: The building blocks of nucleic acids are amino acids.
- This statement is incorrect. The building blocks of nucleic acids are nucleotides, not amino acids. Amino acids are the building blocks of proteins.
Statement iii: The nitrogenous bases adenine, guanine, uracil, cytosine, and thymine are found in nucleic acids.
- This statement is correct. These nitrogenous bases are integral to nucleic acids. Adenine, guanine, cytosine, and thymine are found in DNA, while adenine, guanine, cytosine, and uracil are found in RNA.
Statement iv: DNA is a type of nucleic acid that contains ribose sugar.
- This statement is incorrect. DNA contains deoxyribose sugar, not ribose.
Conclusion
Based on the analysis:
- The correct statements are i and iii.
- Thus, the correct answer is option C: i, iii, and iv.
However, the provided answer option "A" is incorrect, as it states that only statements i and iii are correct. The answer should consider the analysis of all statements accurately.
Nucleic acids are fundamental biomolecules essential for all forms of life. Let’s analyze each statement individually to determine their correctness.
Statement i: Nucleic acids are comprised of polynucleotides that contain ribose or deoxyribose sugars.
- This statement is correct. Nucleic acids, such as RNA and DNA, are polymers (polynucleotides) made up of nucleotides, which include ribose (in RNA) and deoxyribose (in DNA) sugars.
Statement ii: The building blocks of nucleic acids are amino acids.
- This statement is incorrect. The building blocks of nucleic acids are nucleotides, not amino acids. Amino acids are the building blocks of proteins.
Statement iii: The nitrogenous bases adenine, guanine, uracil, cytosine, and thymine are found in nucleic acids.
- This statement is correct. These nitrogenous bases are integral to nucleic acids. Adenine, guanine, cytosine, and thymine are found in DNA, while adenine, guanine, cytosine, and uracil are found in RNA.
Statement iv: DNA is a type of nucleic acid that contains ribose sugar.
- This statement is incorrect. DNA contains deoxyribose sugar, not ribose.
Conclusion
Based on the analysis:
- The correct statements are i and iii.
- Thus, the correct answer is option C: i, iii, and iv.
However, the provided answer option "A" is incorrect, as it states that only statements i and iii are correct. The answer should consider the analysis of all statements accurately.
The amino acids are linked together serially by- a)Peptide bonds
- b)Hydrogen bonds
- c)Covalent bonds
- d)Ionic bonds
Correct answer is option 'A'. Can you explain this answer?
The amino acids are linked together serially by
a)
Peptide bonds
b)
Hydrogen bonds
c)
Covalent bonds
d)
Ionic bonds

|
Prashanth Dasgupta answered |
The amino acids are linked together one after the other by peptide bonds. This bond is formed between NH3 of one amino acids with carboxyl end of another amino acids to release water.
The formation of both peptide and glycosidic bonds involves- a)Acidification
- b)Dehydration
- c)Esterification
- d)Hydration
Correct answer is option 'B'. Can you explain this answer?
The formation of both peptide and glycosidic bonds involves
a)
Acidification
b)
Dehydration
c)
Esterification
d)
Hydration
|
|
Palak Roy answered |
Dehydration is the correct answer because the formation of both peptide and glycosidic bonds involves the removal of a water molecule. Let's explore this in more detail:
Peptide Bonds:
- A peptide bond is a covalent bond that forms between the carboxyl group of one amino acid and the amino group of another amino acid.
- The formation of a peptide bond involves a condensation reaction, also known as a dehydration synthesis reaction.
- In this reaction, the carboxyl group of one amino acid undergoes a nucleophilic attack by the amino group of another amino acid.
- The resulting intermediate is an unstable tetrahedral intermediate, which then undergoes dehydration.
- During dehydration, a water molecule is eliminated, and the amino acids are joined together by a peptide bond.
- This process is repeated to form a polypeptide chain, which is the basis for protein synthesis.
Glycosidic Bonds:
- A glycosidic bond is a covalent bond that forms between the anomeric carbon of a sugar molecule and a hydroxyl group of another sugar molecule.
- The formation of a glycosidic bond also involves a condensation reaction or dehydration synthesis reaction.
- In this reaction, the anomeric carbon of one sugar molecule reacts with the hydroxyl group of another sugar molecule.
- The reaction results in the elimination of a water molecule, and the two sugar molecules are joined together by a glycosidic bond.
- This process is repeated to form complex carbohydrates, such as polysaccharides.
In both peptide and glycosidic bond formation, the removal of a water molecule is essential for the formation of a covalent bond between two molecules. This process is known as dehydration because it involves the loss of a water molecule. It is important to note that dehydration is a general term used to describe the removal of water in various chemical reactions, not just peptide and glycosidic bond formation.
Peptide Bonds:
- A peptide bond is a covalent bond that forms between the carboxyl group of one amino acid and the amino group of another amino acid.
- The formation of a peptide bond involves a condensation reaction, also known as a dehydration synthesis reaction.
- In this reaction, the carboxyl group of one amino acid undergoes a nucleophilic attack by the amino group of another amino acid.
- The resulting intermediate is an unstable tetrahedral intermediate, which then undergoes dehydration.
- During dehydration, a water molecule is eliminated, and the amino acids are joined together by a peptide bond.
- This process is repeated to form a polypeptide chain, which is the basis for protein synthesis.
Glycosidic Bonds:
- A glycosidic bond is a covalent bond that forms between the anomeric carbon of a sugar molecule and a hydroxyl group of another sugar molecule.
- The formation of a glycosidic bond also involves a condensation reaction or dehydration synthesis reaction.
- In this reaction, the anomeric carbon of one sugar molecule reacts with the hydroxyl group of another sugar molecule.
- The reaction results in the elimination of a water molecule, and the two sugar molecules are joined together by a glycosidic bond.
- This process is repeated to form complex carbohydrates, such as polysaccharides.
In both peptide and glycosidic bond formation, the removal of a water molecule is essential for the formation of a covalent bond between two molecules. This process is known as dehydration because it involves the loss of a water molecule. It is important to note that dehydration is a general term used to describe the removal of water in various chemical reactions, not just peptide and glycosidic bond formation.
Which of the following nitrogenous base produces nucleoside only with ribose sugar?- a)Thymine
- b)Guanine
- c)Uracil
- d)Adenine
Correct answer is option 'C'. Can you explain this answer?
Which of the following nitrogenous base produces nucleoside only with ribose sugar?
a)
Thymine
b)
Guanine
c)
Uracil
d)
Adenine

|
Ruchi Chakraborty answered |
Uracil nitrogenous base is produces nucleoside only with ribose sugar. This nucleoside is present only inside the RNA and absent in DNA.
Which of the following statements given above is/are correct?i. In the absence of any enzyme, the formation of H2CO3 is very slow, with about 200 molecules produced in an hour.ii. Carbonic anhydrase accelerates the reaction rate by approximately 10 million times, producing about 600,000 molecules of H2CO3 every second.iii. The metabolic pathway from glucose to pyruvic acid involves ten enzyme-catalyzed reactions.iv. Under anaerobic conditions in skeletal muscle, pyruvic acid is formed instead of lactic acid.- a)i and ii
- b) i, ii and iii
- c)i, iii and iv
- d)ii and iii
Correct answer is option 'B'. Can you explain this answer?
Which of the following statements given above is/are correct?
i. In the absence of any enzyme, the formation of H2CO3 is very slow, with about 200 molecules produced in an hour.
ii. Carbonic anhydrase accelerates the reaction rate by approximately 10 million times, producing about 600,000 molecules of H2CO3 every second.
iii. The metabolic pathway from glucose to pyruvic acid involves ten enzyme-catalyzed reactions.
iv. Under anaerobic conditions in skeletal muscle, pyruvic acid is formed instead of lactic acid.
a)
i and ii
b)
i, ii and iii
c)
i, iii and iv
d)
ii and iii

|
Bs Academy answered |
To analyze the statements:
- Statement i is correct; it describes the slow reaction rate in the absence of an enzyme.
- Statement ii is also correct; it accurately describes the function of carbonic anhydrase and its dramatic acceleration of the reaction rate.
- Statement iii is accurate; it notes that the pathway from glucose to pyruvic acid consists of ten enzyme-catalyzed reactions.
- Statement iv is incorrect; under anaerobic conditions, lactic acid is produced in skeletal muscle, not pyruvic acid.
Therefore, the correct answer, which includes statements i, ii and iii, is Option B.
Identify the amino acids containing nonpolar, aliphatic R groups.- a)Phenylalanine, tyrosine, and tryptophan
- b)Glycine, alanine, leucine
- c)Lysine, arginine, histidine
- d)Serine, threonine, cysteine
Correct answer is option 'B'. Can you explain this answer?
Identify the amino acids containing nonpolar, aliphatic R groups.
a)
Phenylalanine, tyrosine, and tryptophan
b)
Glycine, alanine, leucine
c)
Lysine, arginine, histidine
d)
Serine, threonine, cysteine
|
|
Ava Brown answered |
Understanding Nonpolar, Aliphatic Amino Acids
Amino acids are the building blocks of proteins, and their properties are determined by their R groups (side chains). Nonpolar, aliphatic amino acids have hydrophobic side chains that do not interact favorably with water.
Identifying Nonpolar, Aliphatic Amino Acids
The correct answer to the question is option 'B', which includes the following amino acids:
Why Options A, C, and D Are Incorrect
Conclusion
In summary, the amino acids listed in option 'B' are characterized by their nonpolar, aliphatic side chains, distinguishing them from the other options that include polar or aromatic amino acids. Understanding these classifications is essential for grasping protein structure and function in biochemistry.
Amino acids are the building blocks of proteins, and their properties are determined by their R groups (side chains). Nonpolar, aliphatic amino acids have hydrophobic side chains that do not interact favorably with water.
Identifying Nonpolar, Aliphatic Amino Acids
The correct answer to the question is option 'B', which includes the following amino acids:
- Glycine - The simplest amino acid with a hydrogen as its side chain, making it nonpolar.
- Alanine - Contains a methyl group as its R group, also classified as nonpolar.
- Leucine - Has a branched-chain structure, contributing to its nonpolar nature.
Why Options A, C, and D Are Incorrect
- Option A (Phenylalanine, Tyrosine, Tryptophan) - Contains aromatic rings, making them more polar than purely aliphatic amino acids.
- Option C (Lysine, Arginine, Histidine) - These are polar and positively charged amino acids due to their side chains containing nitrogen.
- Option D (Serine, Threonine, Cysteine) - These amino acids contain hydroxyl or thiol groups, which are polar and can form hydrogen bonds.
Conclusion
In summary, the amino acids listed in option 'B' are characterized by their nonpolar, aliphatic side chains, distinguishing them from the other options that include polar or aromatic amino acids. Understanding these classifications is essential for grasping protein structure and function in biochemistry.
Which among the following is both glucogenic and ketogenic?- a)Isoleucine
- b)Leucine
- c)Lysine
- d)Histidine
Correct answer is option 'A'. Can you explain this answer?
Which among the following is both glucogenic and ketogenic?
a)
Isoleucine
b)
Leucine
c)
Lysine
d)
Histidine
|
|
Orion Classes answered |
Isoleucine produces both glucose and ketone bodies as an energy source.
A polypeptide chain contains two terminals – one carboxyl-terminal (C terminal) and the other amino-terminal (N terminal). Which of the following is true?- a)N terminal is synthesized last during translation
- b)C terminal is synthesized first during translation
- c)N terminal is represented on the right side and C terminal on the left side
- d)N terminal is represented on the left side and C terminal on the right side
Correct answer is option 'D'. Can you explain this answer?
A polypeptide chain contains two terminals – one carboxyl-terminal (C terminal) and the other amino-terminal (N terminal). Which of the following is true?
a)
N terminal is synthesized last during translation
b)
C terminal is synthesized first during translation
c)
N terminal is represented on the right side and C terminal on the left side
d)
N terminal is represented on the left side and C terminal on the right side
|
|
Wyatt Gonzales answered |
Understanding Polypeptide Chains
A polypeptide chain is a sequence of amino acids linked by peptide bonds, and it has distinct ends: the amino-terminal (N terminal) and carboxyl-terminal (C terminal).
Translation Process
- During protein synthesis (translation), the ribosome assembles amino acids in a specific order.
- The synthesis begins at the N terminal and proceeds toward the C terminal.
Synthesis Directionality
- The N terminal is synthesized first, and thus it is represented on the left side of the polypeptide chain.
- The C terminal, being the last part synthesized, is found on the right side.
Visual Representation
- In a linear representation of a polypeptide:
- N terminal is on the left side (amino group, -NH2).
- C terminal is on the right side (carboxyl group, -COOH).
Correct Answer Explanation
- Therefore, the statement "N terminal is represented on the left side and C terminal on the right side" is correct.
- This understanding is crucial for interpreting protein structure and function, as the orientation plays a significant role in biochemical interactions.
In summary, the N terminal is always on the left, while the C terminal is on the right, which aligns with the synthesis direction in translation.
A polypeptide chain is a sequence of amino acids linked by peptide bonds, and it has distinct ends: the amino-terminal (N terminal) and carboxyl-terminal (C terminal).
Translation Process
- During protein synthesis (translation), the ribosome assembles amino acids in a specific order.
- The synthesis begins at the N terminal and proceeds toward the C terminal.
Synthesis Directionality
- The N terminal is synthesized first, and thus it is represented on the left side of the polypeptide chain.
- The C terminal, being the last part synthesized, is found on the right side.
Visual Representation
- In a linear representation of a polypeptide:
- N terminal is on the left side (amino group, -NH2).
- C terminal is on the right side (carboxyl group, -COOH).
Correct Answer Explanation
- Therefore, the statement "N terminal is represented on the left side and C terminal on the right side" is correct.
- This understanding is crucial for interpreting protein structure and function, as the orientation plays a significant role in biochemical interactions.
In summary, the N terminal is always on the left, while the C terminal is on the right, which aligns with the synthesis direction in translation.
Read the following passage to answer the following questions:The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.Q. Which of the following is the best evidence for the lock and key theory of enzyme reaction:- a)All enzymes are proteins.
- b)Compounds similar in structure to substrate inhibit the reaction.
- c)Certain enzymes speed up certain reactions.
- d)Direction of reaction is determine by enzyme.
Correct answer is option 'B'. Can you explain this answer?
Read the following passage to answer the following questions:
The enzyme molecule operates by chemically binding with the substrate molecule, to form an enzyme-substrate complex. The enzyme's tertiary structure consists of a unique pocket or site on which the substrate molecules can become attached and interact subsequently. This brings about an interaction between the specific active sites in the enzyme molecule and the reactive sites in the substrate molecule. The enzyme now breaks down the substrate into- products. The products initially remain attached to the enzyme for a short while forming an enzyme product complex. The products get released from the enzyme molecule subsequently. The enzyme is now ready to receive another substrate molecule again. Thus, the same enzyme can be used again and again.
Q. Which of the following is the best evidence for the lock and key theory of enzyme reaction:
a)
All enzymes are proteins.
b)
Compounds similar in structure to substrate inhibit the reaction.
c)
Certain enzymes speed up certain reactions.
d)
Direction of reaction is determine by enzyme.
|
|
Priya Menon answered |
The compound similar in structure to substrate block the active site of the enzyme. Therefore, the substrate fail to unite with the enzyme and thus the reaction is inhibited.
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.Assertion : Nucleic acids exhibit secondary structure.Reason : It is the linear sequence of amino acids in a polypeptide chain.- a)Both A and R are true, and R is the correct explanation of A.
- b)Both A and R are true, but R is not the correct explanation of A.
- c)A is true but R is false.
- d)Both A and R are false.
Correct answer is option 'C'. Can you explain this answer?
Directions : In the following question, the Assertions (A) and Reason (R) have been put forward. Read both the statements and choose the correct option from the following.
Assertion : Nucleic acids exhibit secondary structure.
Reason : It is the linear sequence of amino acids in a polypeptide chain.
a)
Both A and R are true, and R is the correct explanation of A.
b)
Both A and R are true, but R is not the correct explanation of A.
c)
A is true but R is false.
d)
Both A and R are false.
|
|
Dev Patel answered |
It is a linear sequences of nucleotides in a polynucleotide chain. Primary structure of protein is the linear sequence of amino acids in a polypeptide chain reveals primary structure of protein.
Read the following passage to answer the following questions:Proteins are polypeptide chains made up of amino acids. There are 20 types of amino acids joined together by peptide bond between amino and carboxylic group. There are two kinds of amino acids, Essential amino acids and Non-essential amino acids. The Primary structure of protein is the linear sequence of amino acids in a polypeptide chain. The first amino acid of sequence is called N-terminal amino acids and last amino acid of peptide chain is called C-terminal amino acids. The secondary structure proteins forms helix. There are three types of secondary structure: a helix, P pleated and collagen helix. In tertiary structure long protein chain is folded upon itself like a hollow woollen ball to give three-dimensional view of protein. In quaternary structure, each polypeptide develops its own tertiary structure and function as subunit of protein.Q. The smallest amino acid is- a)Phenol
- b)Formic acid
- c)Glycine
- d)Methane
Correct answer is option 'C'. Can you explain this answer?
Read the following passage to answer the following questions:
Proteins are polypeptide chains made up of amino acids. There are 20 types of amino acids joined together by peptide bond between amino and carboxylic group. There are two kinds of amino acids, Essential amino acids and Non-essential amino acids. The Primary structure of protein is the linear sequence of amino acids in a polypeptide chain. The first amino acid of sequence is called N-terminal amino acids and last amino acid of peptide chain is called C-terminal amino acids. The secondary structure proteins forms helix. There are three types of secondary structure: a helix, P pleated and collagen helix. In tertiary structure long protein chain is folded upon itself like a hollow woollen ball to give three-dimensional view of protein. In quaternary structure, each polypeptide develops its own tertiary structure and function as subunit of protein.
Q. The smallest amino acid is
a)
Phenol
b)
Formic acid
c)
Glycine
d)
Methane
|
|
Priya Menon answered |
The simplest, and smallest, amino acid is glycine for which the R-group is a hydrogen (H).
Chapter doubts & questions for Biologically Important Molecules - Biology and Biochemistry for MCAT 2025 is part of MCAT exam preparation. The chapters have been prepared according to the MCAT exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for MCAT 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Biologically Important Molecules - Biology and Biochemistry for MCAT in English & Hindi are available as part of MCAT exam.
Download more important topics, notes, lectures and mock test series for MCAT Exam by signing up for free.
Biology and Biochemistry for MCAT
129 videos|60 docs|24 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup on EduRev and stay on top of your study goals
10M+ students crushing their study goals daily