NEET Exam > NEET Notes > Biology Class 12 > Important Diagrams: Molecular Basis of Inheritance
Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET PDF Download

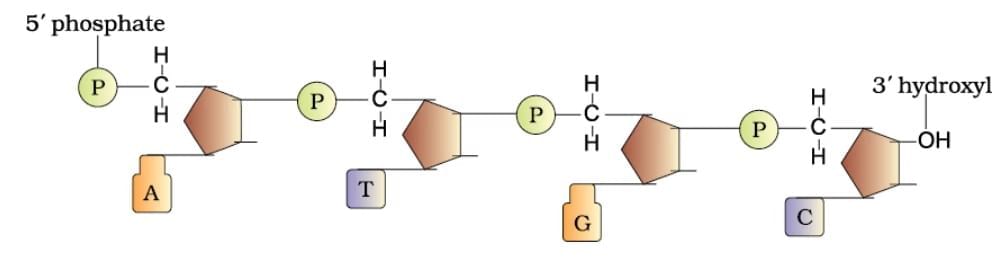
Polynucleotide Chain
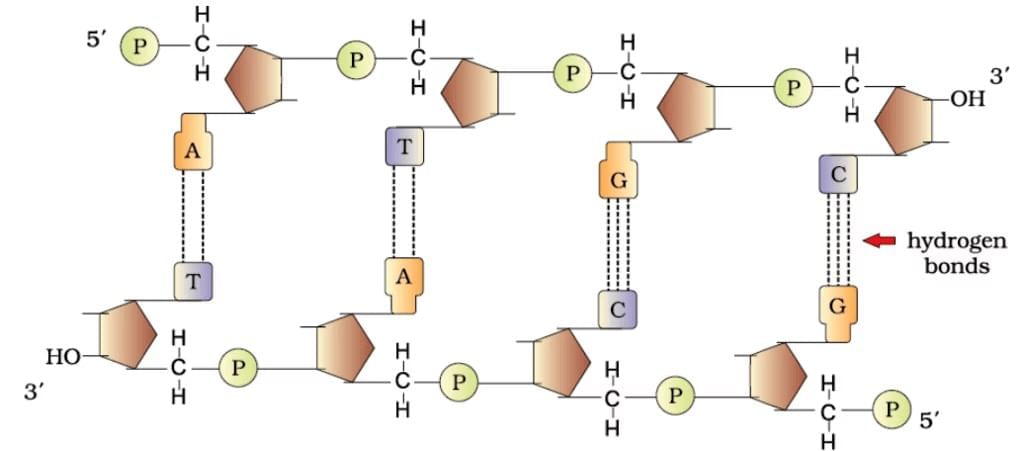
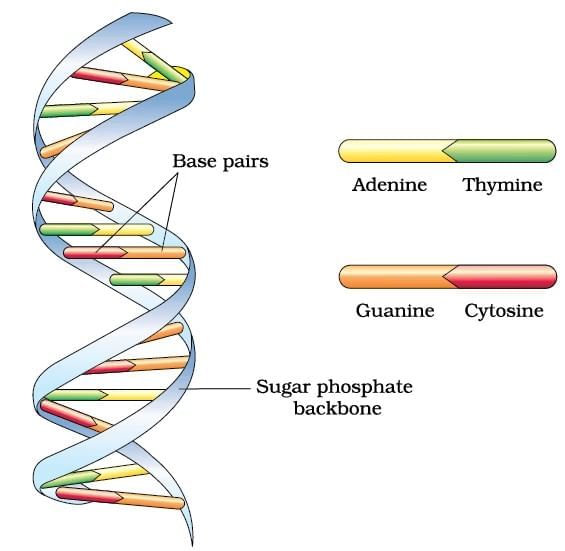
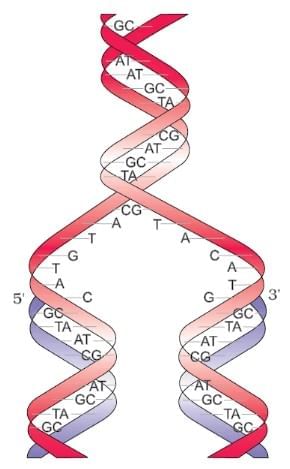
DNA Double Helix
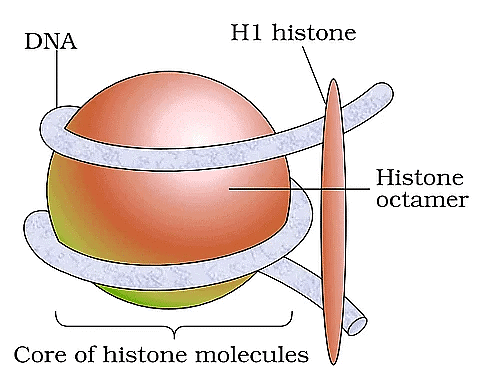
Nucleosome
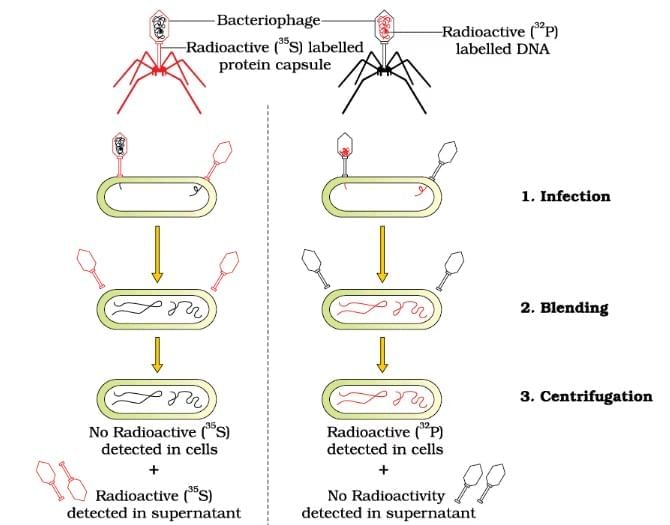
Hershey & Chase Experiment
Semi Conservative DNA Replication ( Watson & Crick Model)
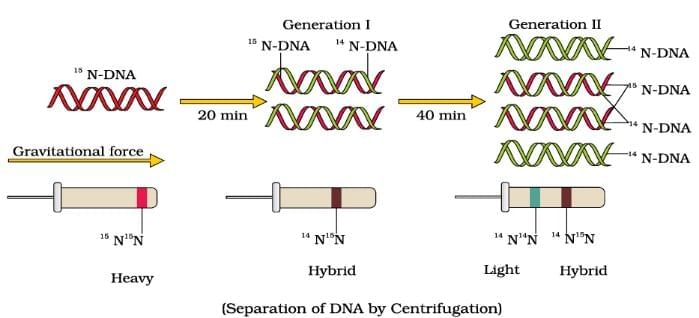
Meselson and Stahl’s Experiment
Replicating Fork
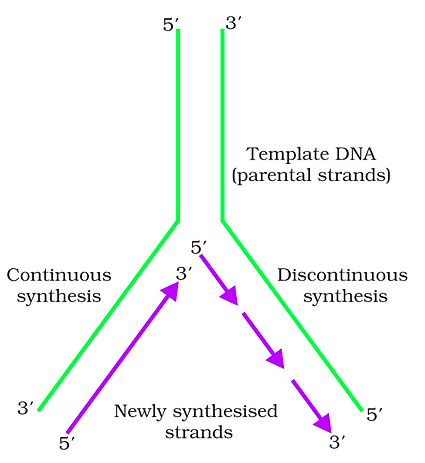
Transcription unit
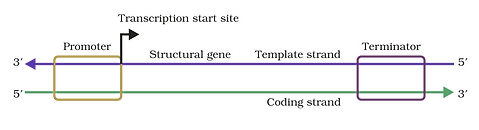
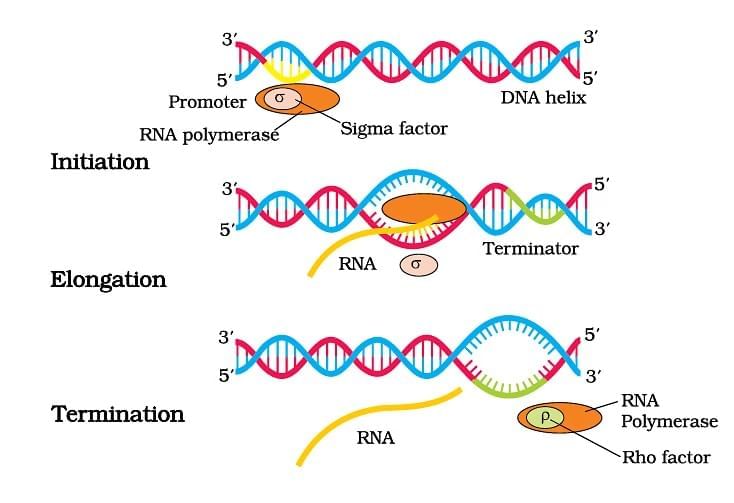
Transcription in Prokaryotes ( Bacteria)
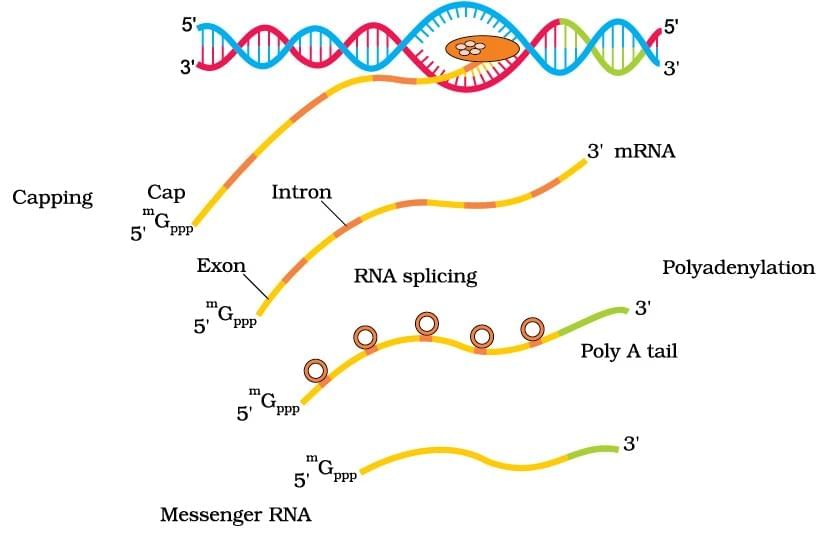
Transcription in Eukaryotes
Genetic Code
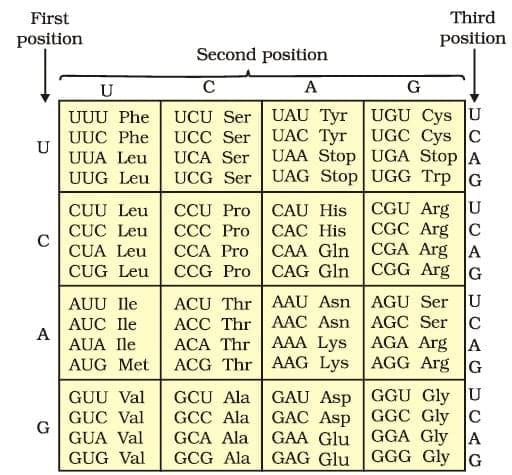
tRNA– the Adapter Molecule
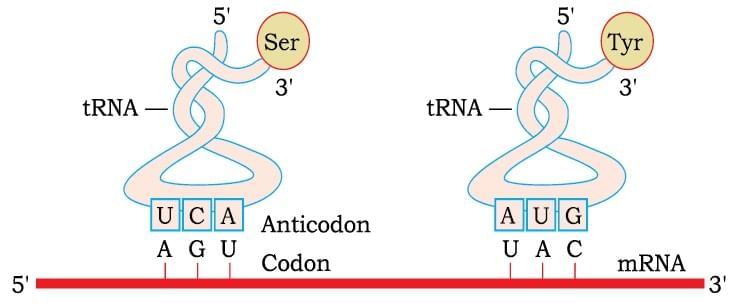
Translation
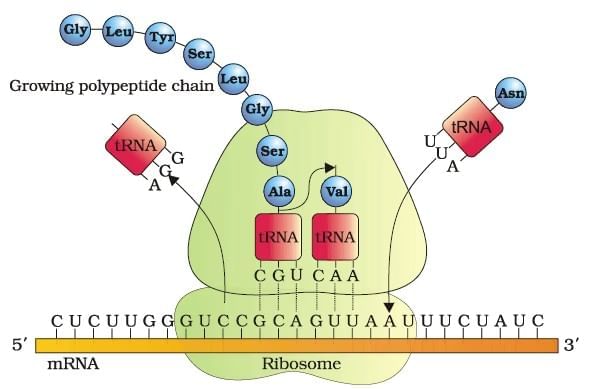
Lac operon
Human Genome Project
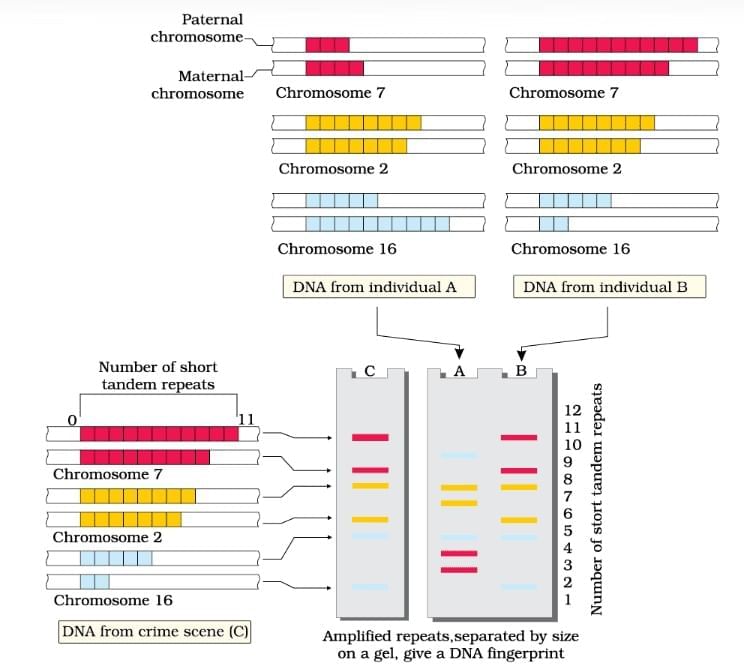
DNA Fingerprinting
The document Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET is a part of the NEET Course Biology Class 12.
All you need of NEET at this link: NEET
|
59 videos|290 docs|168 tests
|
FAQs on Important Diagrams: Molecular Basis of Inheritance - Biology Class 12 - NEET
| 1. What is the structure of polynucleotide chains in DNA? |  |
Ans. Polynucleotide chains in DNA consist of long sequences of nucleotides, which are the building blocks of DNA. Each nucleotide is made up of three components: a phosphate group, a deoxyribose sugar, and a nitrogenous base (adenine, thymine, cytosine, or guanine). The nucleotides are linked together by phosphodiester bonds, forming a sugar-phosphate backbone, with the nitrogenous bases extending from the sugar. The two strands of DNA run in opposite directions (antiparallel) and twist to form a double helix.
| 2. How does DNA get packaged into a compact structure? | |
Ans. DNA is packaged into a compact structure through a series of hierarchical levels of organization. Initially, DNA wraps around histone proteins to form nucleosomes, resembling "beads on a string." These nucleosomes further coil and fold into a more compact structure called chromatin. During cell division, chromatin condenses to form visible chromosomes, allowing for efficient segregation of genetic material.
| 3. What was the significance of the Hershey and Chase experiment? | |
Ans. The Hershey and Chase experiment, conducted in 1952, provided crucial evidence that DNA is the genetic material in organisms. By using radioactive labeling, they tracked the DNA and protein components of bacteriophages (viruses that infect bacteria). Their results showed that only the viral DNA entered the bacterial cells and directed the production of new viruses, while the protein coat remained outside. This experiment confirmed that DNA carries genetic information.
| 4. What is semi-conservative DNA replication according to the Watson and Crick model? | |
Ans. Semi-conservative DNA replication is a process where each of the two strands of the original DNA molecule serves as a template for the formation of new complementary strands. According to the Watson and Crick model, when DNA replicates, the double helix unwinds, and each strand is used to synthesize a new strand. As a result, each daughter DNA molecule consists of one old (parental) strand and one newly synthesized strand, preserving half of the original DNA.
| 5. What are the key differences in transcription between prokaryotes and eukaryotes? | |
Ans. Transcription in prokaryotes occurs in the cytoplasm and involves a single RNA polymerase that synthesizes mRNA directly from the DNA template. In contrast, eukaryotic transcription takes place in the nucleus, where the primary mRNA undergoes processing (capping, polyadenylation, and splicing) before it is exported to the cytoplasm. Additionally, eukaryotic transcription involves multiple RNA polymerases and various transcription factors, whereas prokaryotes rely on simpler mechanisms.
About this Document

4.84/5
Rating

Oct 17, 2025
Last updated
Document Description: Important Diagrams: Molecular Basis of Inheritance for NEET 2025 is part of Biology Class 12 preparation.
The notes and questions for Important Diagrams: Molecular Basis of Inheritance have been prepared according to the NEET exam syllabus. Information about Important Diagrams: Molecular Basis of Inheritance covers topics
like Polynucleotide Chain, DNA Double Helix, Nucleosome, Hershey & Chase Experiment, Semi Conservative DNA Replication ( Watson & Crick Model), Meselson and Stahl’s Experiment, Replicating Fork, Transcription unit, Transcription in Prokaryotes ( Bacteria), Transcription in Eukaryotes, Genetic Code, tRNA– the Adapter Molecule, Translation, Lac operon , Human Genome Project, DNA Fingerprinting and Important Diagrams: Molecular Basis of Inheritance Example, for NEET 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises and tests below for Important Diagrams: Molecular Basis of Inheritance.
Introduction of Important Diagrams: Molecular Basis of Inheritance in English is available as part of our Biology Class 12
for NEET & Important Diagrams: Molecular Basis of Inheritance in Hindi for Biology Class 12 course.
Download more important topics related with notes, lectures and mock test series for NEET
Exam by signing up for free. NEET: Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET
Description
Full syllabus notes, lecture & questions for Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET - NEET | Plus excerises question with solution to help you revise complete syllabus for Biology Class 12 | Best notes, free PDF download
Information about Important Diagrams: Molecular Basis of Inheritance
In this doc you can find the meaning of Important Diagrams: Molecular Basis of Inheritance defined & explained in the simplest way possible. Besides explaining types of
Important Diagrams: Molecular Basis of Inheritance theory, EduRev gives you an ample number of questions to practice Important Diagrams: Molecular Basis of Inheritance tests, examples and also practice NEET
tests

Related Searches
Objective type Questions
,study material
,Semester Notes
,practice quizzes
,shortcuts and tricks
,past year papers
,video lectures
,Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET
,MCQs
,Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET
,Viva Questions
,Exam
,Summary
,mock tests for examination
,Free
,Important questions
,Sample Paper
,Previous Year Questions with Solutions
,ppt
,Important Diagrams: Molecular Basis of Inheritance | Biology Class 12 - NEET
,Extra Questions
;


Additional Information about Important Diagrams: Molecular Basis of Inheritance for NEET Preparation
Important Diagrams: Molecular Basis of Inheritance Free PDF Download
The Important Diagrams: Molecular Basis of Inheritance is an invaluable resource that delves deep into the core of the NEET exam.
These study notes are curated by experts and cover all the essential topics and concepts, making your preparation more efficient and effective.
With the help of these notes, you can grasp complex subjects quickly, revise important points easily,
and reinforce your understanding of key concepts. The study notes are presented in a concise and easy-to-understand manner,
allowing you to optimize your learning process. Whether you're looking for best-recommended books, sample papers, study material,
or toppers' notes, this PDF has got you covered. Download the Important Diagrams: Molecular Basis of Inheritance now and kickstart your journey towards success in the NEET exam.
Importance of Important Diagrams: Molecular Basis of Inheritance
The importance of Important Diagrams: Molecular Basis of Inheritance cannot be overstated, especially for NEET aspirants.
This document holds the key to success in the NEET exam.
It offers a detailed understanding of the concept, providing invaluable insights into the topic.
By knowing the concepts well in advance, students can plan their preparation effectively.
Utilize this indispensable guide for a well-rounded preparation and achieve your desired results.
Important Diagrams: Molecular Basis of Inheritance Notes
Important Diagrams: Molecular Basis of Inheritance Notes offer in-depth insights into the specific topic to help you master it with ease.
This comprehensive document covers all aspects related to Important Diagrams: Molecular Basis of Inheritance.
It includes detailed information about the exam syllabus, recommended books, and study materials for a well-rounded preparation.
Practice papers and question papers enable you to assess your progress effectively.
Additionally, the paper analysis provides valuable tips for tackling the exam strategically.
Access to Toppers' notes gives you an edge in understanding complex concepts.
Whether you're a beginner or aiming for advanced proficiency, Important Diagrams: Molecular Basis of Inheritance Notes on EduRev are your ultimate resource for success.
Important Diagrams: Molecular Basis of Inheritance NEET Questions
The "Important Diagrams: Molecular Basis of Inheritance NEET Questions" guide is a valuable resource for all aspiring students preparing for the
NEET exam. It focuses on providing a wide range of practice questions to help students gauge
their understanding of the exam topics. These questions cover the entire syllabus, ensuring comprehensive preparation.
The guide includes previous years' question papers for students to familiarize themselves with the exam's format and difficulty level.
Additionally, it offers subject-specific question banks, allowing students to focus on weak areas and improve their performance.
Study Important Diagrams: Molecular Basis of Inheritance on the App
Students of NEET can study Important Diagrams: Molecular Basis of Inheritance alongwith tests & analysis from the EduRev app,
which will help them while preparing for their exam. Apart from the Important Diagrams: Molecular Basis of Inheritance,
students can also utilize the EduRev App for other study materials such as previous year question papers, syllabus, important questions, etc.
The EduRev App will make your learning easier as you can access it from anywhere you want.
The content of Important Diagrams: Molecular Basis of Inheritance is prepared as per the latest NEET syllabus.
|
© EduRev
|
Education Revolution
|



|






Signup to see your scores
go up
within 7 days!
within 7 days!
Takes less than 10 seconds to signup