









All Exams >
Computer Science Engineering (CSE) >
Operating System >
All Questions
All questions of Process Synchronization for Computer Science Engineering (CSE) Exam
Consider the methods used by processes P1 and P2 for accessing their critical sections whenever needed, as given below. The initial values of shared boolean variables S1 and S2 are randomly assigned.
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;Method Used by P2
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the following statements describes the properties achieved?- a)Mutual exclusion but not progress
- b)Progress but not mutual exclusion
- c)Neither mutual exclusion nor progress
- d)Both mutual exclusion and progress
Correct answer is option 'A'. Can you explain this answer?
Consider the methods used by processes P1 and P2 for accessing their critical sections whenever needed, as given below. The initial values of shared boolean variables S1 and S2 are randomly assigned.
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;
Method Used by P2
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the following statements describes the properties achieved?
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the following statements describes the properties achieved?
a)
Mutual exclusion but not progress
b)
Progress but not mutual exclusion
c)
Neither mutual exclusion nor progress
d)
Both mutual exclusion and progress
|
|
Ravi Singh answered |
It can be easily observed that the Mutual Exclusion requirement is satisfied by the above solution, P1 can enter critical section only if S1 is not equal to S2, and P2 can enter critical section only if S1 is equal to S2. But here Progress Requirement is not satisfied. Suppose when s1=1 and s2=0 and process p1 is not interested to enter into critical section but p2 want to enter critical section. P2 is not able to enter critical section in this as only when p1 finishes execution, then only p2 can enter (then only s1 = s2 condition be satisfied). Progress will not be satisfied when any process which is not interested to enter into the critical section will not allow other interested process to enter into the critical section.

Consider the following statements about process state transitions for a system using preemptive scheduling.I. A running process can move to ready state.
II. A ready process can move to running state.
III. A blocked process can move to running state.
IV. A blocked process can move to ready state.Which of the above statements are TRUE ?- a)I, II, and III only
- b)II and III only
- c)I, II, and IV only
- d)I, II, III and IV only
Correct answer is option 'C'. Can you explain this answer?
Consider the following statements about process state transitions for a system using preemptive scheduling.
I. A running process can move to ready state.
II. A ready process can move to running state.
III. A blocked process can move to running state.
IV. A blocked process can move to ready state.
II. A ready process can move to running state.
III. A blocked process can move to running state.
IV. A blocked process can move to ready state.
Which of the above statements are TRUE ?
a)
I, II, and III only
b)
II and III only
c)
I, II, and IV only
d)
I, II, III and IV only
|
|
Yash Patel answered |
According to process state transitions for a system using preemptive scheduling:
So, a blocked process can NOT move to running state. Only statements I, II, and IV are correct. Option (C) is true.
What is Interprocess communication?- a)allows processes to communicate and synchronize their actions when using the same address space
- b)allows processes to communicate and synchronize their actions
- c)allows the processes to only synchronize their actions without communication
- d)none of the mentioned
Correct answer is option 'B'. Can you explain this answer?
What is Interprocess communication?
a)
allows processes to communicate and synchronize their actions when using the same address space
b)
allows processes to communicate and synchronize their actions
c)
allows the processes to only synchronize their actions without communication
d)
none of the mentioned
|
|
Shivam Dasgupta answered |
Interprocess communication (IPC) is a mechanism that allows processes to communicate and synchronize their actions. It enables different processes running on the same or different systems to exchange data and coordinate their activities. IPC is essential in modern operating systems to facilitate collaboration and resource sharing among processes.
IPC provides a standardized way for processes to interact with each other, regardless of their location or architecture. It allows processes to send and receive messages, share data, and coordinate their actions to achieve a common goal. Here, we will explore the reasons why option 'B' is the correct answer.
Allows processes to communicate:
IPC provides a means for processes to communicate with each other. Processes can exchange information, such as messages or data, through various communication channels. These channels can be shared memory regions, pipes, sockets, or message queues. By sending and receiving messages, processes can convey information, request services, or notify each other about significant events.
Allows processes to synchronize their actions:
IPC also enables processes to synchronize their actions. Synchronization ensures that processes coordinate their activities and avoid conflicts or inconsistencies. Processes can use synchronization mechanisms, such as semaphores, locks, or condition variables, to control access to shared resources or coordinate their execution. By synchronizing their actions, processes can cooperate effectively and avoid race conditions or other concurrency issues.
Benefits of IPC:
- Collaboration: IPC allows processes to work together and exchange information, enabling collaboration and coordination among different components of a system.
- Resource sharing: Processes can share resources, such as memory, files, or devices, through IPC mechanisms. This enables efficient utilization of resources and avoids duplication.
- Modularity: IPC facilitates the development of modular systems, where different processes can be developed independently and communicate through well-defined interfaces.
- Fault isolation: IPC can help isolate faulty processes from the rest of the system. By using separate processes for different components, failures in one process do not affect the overall system.
In conclusion, IPC is a crucial mechanism that allows processes to communicate and synchronize their actions. By enabling collaboration and resource sharing, IPC plays a vital role in the efficient and coordinated operation of modern computer systems.
IPC provides a standardized way for processes to interact with each other, regardless of their location or architecture. It allows processes to send and receive messages, share data, and coordinate their actions to achieve a common goal. Here, we will explore the reasons why option 'B' is the correct answer.
Allows processes to communicate:
IPC provides a means for processes to communicate with each other. Processes can exchange information, such as messages or data, through various communication channels. These channels can be shared memory regions, pipes, sockets, or message queues. By sending and receiving messages, processes can convey information, request services, or notify each other about significant events.
Allows processes to synchronize their actions:
IPC also enables processes to synchronize their actions. Synchronization ensures that processes coordinate their activities and avoid conflicts or inconsistencies. Processes can use synchronization mechanisms, such as semaphores, locks, or condition variables, to control access to shared resources or coordinate their execution. By synchronizing their actions, processes can cooperate effectively and avoid race conditions or other concurrency issues.
Benefits of IPC:
- Collaboration: IPC allows processes to work together and exchange information, enabling collaboration and coordination among different components of a system.
- Resource sharing: Processes can share resources, such as memory, files, or devices, through IPC mechanisms. This enables efficient utilization of resources and avoids duplication.
- Modularity: IPC facilitates the development of modular systems, where different processes can be developed independently and communicate through well-defined interfaces.
- Fault isolation: IPC can help isolate faulty processes from the rest of the system. By using separate processes for different components, failures in one process do not affect the overall system.
In conclusion, IPC is a crucial mechanism that allows processes to communicate and synchronize their actions. By enabling collaboration and resource sharing, IPC plays a vital role in the efficient and coordinated operation of modern computer systems.
There are three processes in the ready queue. When the currently running process requests for I/O how many process switches take place?- a)1
- b)2
- c)3
- d)4
Correct answer is option 'A'. Can you explain this answer?
There are three processes in the ready queue. When the currently running process requests for I/O how many process switches take place?
a)
1
b)
2
c)
3
d)
4
|
|
Yash Patel answered |
Single process switch will take place as when the currently running process requests for I/O, it would be placed in the blocked list and the first process residing inside the Ready Queue will be placed in the Running list to start its execution. Option (A) is correct.
Process is:- a)A program in high level language kept on disk
- b)Contents of main memory
- c)A program in execution
- d)A job in secondary memory
Correct answer is option 'C'. Can you explain this answer?
Process is:
a)
A program in high level language kept on disk
b)
Contents of main memory
c)
A program in execution
d)
A job in secondary memory
|
|
Sanya Agarwal answered |
A process is termed as a program in execution. Whenever a program needs to be executed, its process image is created inside the main memory and is placed in the ready queue. Later CPU is assigned to the process and it starts its execution. So, option (C) is correct.
Four jobs to be executed on a single processor system arrive at time 0 in the order A, B, C, D . Their burst CPU time requirements are 4, 1, 8, 1 time units respectively. The completion time of A under round robin scheduling with time slice of one time unit is- a)10
- b)4
- c)8
- d)9
Correct answer is option 'D'. Can you explain this answer?
Four jobs to be executed on a single processor system arrive at time 0 in the order A, B, C, D . Their burst CPU time requirements are 4, 1, 8, 1 time units respectively. The completion time of A under round robin scheduling with time slice of one time unit is
a)
10
b)
4
c)
8
d)
9
|
|
Ravi Singh answered |
The order of execution of the processes with the arrival time of each process = 0, using round robin algorithm with time quanta = 1 A B C D A C A C A, i.e, after 8 context switches, A finally completes it execution So, the correct option is (D).
What is the name of the operating system that reads and reacts in terms of actual time.
- a)Batch system
- b)Quick response time
- c)real time system
- d)Time sharing system
Correct answer is option 'C'. Can you explain this answer?
What is the name of the operating system that reads and reacts in terms of actual time.
a)
Batch system
b)
Quick response time
c)
real time system
d)
Time sharing system
|
|
Ashutosh Mukherjee answered |
Understanding Real-Time Operating Systems
Real-time operating systems (RTOS) are designed to process data and respond to inputs within strict time constraints. Unlike traditional operating systems, which prioritize throughput and resource utilization, RTOS focuses on timely execution of tasks.
Key Characteristics of Real-Time Systems:
- Deterministic Behavior: RTOS guarantees that critical tasks will be completed within a specified time frame, making it suitable for applications like embedded systems, robotics, and industrial control systems.
- Immediate Response: These systems react to events or inputs almost instantaneously, ensuring that time-sensitive operations are performed without delay.
- Task Scheduling: Real-time systems use specialized scheduling algorithms (like Rate Monotonic Scheduling or Earliest Deadline First) to prioritize tasks based on their urgency and timing requirements.
Types of Real-Time Systems:
- Hard Real-Time Systems: Missing deadlines can lead to catastrophic failures, making these systems critical in applications like medical devices or aerospace.
- Soft Real-Time Systems: While timely responses are important, occasional deadline misses are tolerable, such as in video streaming or online gaming.
Applications of Real-Time Operating Systems:
- Automotive Systems: Real-time systems are used in anti-lock braking systems (ABS) and engine control units (ECUs) to ensure safety and performance.
- Telecommunications: Managing call processing and data transmission requires immediate responses to maintain quality of service.
In summary, the correct answer to the question is option 'C' because real-time systems are specifically designed to operate and respond to events and inputs within a defined time frame, ensuring reliability and predictability in critical applications.
Real-time operating systems (RTOS) are designed to process data and respond to inputs within strict time constraints. Unlike traditional operating systems, which prioritize throughput and resource utilization, RTOS focuses on timely execution of tasks.
Key Characteristics of Real-Time Systems:
- Deterministic Behavior: RTOS guarantees that critical tasks will be completed within a specified time frame, making it suitable for applications like embedded systems, robotics, and industrial control systems.
- Immediate Response: These systems react to events or inputs almost instantaneously, ensuring that time-sensitive operations are performed without delay.
- Task Scheduling: Real-time systems use specialized scheduling algorithms (like Rate Monotonic Scheduling or Earliest Deadline First) to prioritize tasks based on their urgency and timing requirements.
Types of Real-Time Systems:
- Hard Real-Time Systems: Missing deadlines can lead to catastrophic failures, making these systems critical in applications like medical devices or aerospace.
- Soft Real-Time Systems: While timely responses are important, occasional deadline misses are tolerable, such as in video streaming or online gaming.
Applications of Real-Time Operating Systems:
- Automotive Systems: Real-time systems are used in anti-lock braking systems (ABS) and engine control units (ECUs) to ensure safety and performance.
- Telecommunications: Managing call processing and data transmission requires immediate responses to maintain quality of service.
In summary, the correct answer to the question is option 'C' because real-time systems are specifically designed to operate and respond to events and inputs within a defined time frame, ensuring reliability and predictability in critical applications.
Bounded capacity and Unbounded capacity queues are referred to as __________- a)Programmed buffering
- b)Automatic buffering
- c)User defined buffering
- d)No buffering
Correct answer is option 'B'. Can you explain this answer?
Bounded capacity and Unbounded capacity queues are referred to as __________
a)
Programmed buffering
b)
Automatic buffering
c)
User defined buffering
d)
No buffering
|
|
Mahi Datta answered |
Unbounded vs Bounded Capacity Queues:
Unbounded and bounded capacity queues are two types of queues that are commonly used in computer science and programming. Let's explore the differences between these two types of queues.
Bounded Capacity Queue:
- A bounded capacity queue has a fixed size limit, meaning it can only hold a specific number of elements.
- Once the queue reaches its maximum capacity, any attempt to add more elements will result in an overflow condition.
- Bounded capacity queues are often used when there is a limited amount of memory available, or when it is important to control the amount of data being processed at any given time.
Unbounded Capacity Queue:
- An unbounded capacity queue, on the other hand, does not have a fixed size limit.
- It can grow dynamically to accommodate any number of elements that are added to it.
- Unbounded capacity queues are useful in situations where the amount of data being processed is not known in advance, or when there is a possibility of a large amount of data being processed.
Automatic Buffering:
- Unbounded capacity queues are often referred to as "automatic buffering" because they automatically handle the storage and retrieval of elements without the need for manual intervention.
- This makes them convenient to use in situations where the amount of data being processed can vary unpredictably.
In conclusion, bounded capacity queues are limited in size and can result in overflow conditions if the size limit is exceeded, while unbounded capacity queues can dynamically grow to accommodate any number of elements. The choice between the two types of queues depends on the specific requirements of the system being designed.
Unbounded and bounded capacity queues are two types of queues that are commonly used in computer science and programming. Let's explore the differences between these two types of queues.
Bounded Capacity Queue:
- A bounded capacity queue has a fixed size limit, meaning it can only hold a specific number of elements.
- Once the queue reaches its maximum capacity, any attempt to add more elements will result in an overflow condition.
- Bounded capacity queues are often used when there is a limited amount of memory available, or when it is important to control the amount of data being processed at any given time.
Unbounded Capacity Queue:
- An unbounded capacity queue, on the other hand, does not have a fixed size limit.
- It can grow dynamically to accommodate any number of elements that are added to it.
- Unbounded capacity queues are useful in situations where the amount of data being processed is not known in advance, or when there is a possibility of a large amount of data being processed.
Automatic Buffering:
- Unbounded capacity queues are often referred to as "automatic buffering" because they automatically handle the storage and retrieval of elements without the need for manual intervention.
- This makes them convenient to use in situations where the amount of data being processed can vary unpredictably.
In conclusion, bounded capacity queues are limited in size and can result in overflow conditions if the size limit is exceeded, while unbounded capacity queues can dynamically grow to accommodate any number of elements. The choice between the two types of queues depends on the specific requirements of the system being designed.
The following C programmain()
{
fork() ; fork() ; printf ("yes");
}
If we execute this core segment, how many times the string yes will be printed ?- a)Only once
- b)2 times
- c)4 times
- d)8 times
Correct answer is option 'C'. Can you explain this answer?
The following C program
main()
{
fork() ; fork() ; printf ("yes");
}
If we execute this core segment, how many times the string yes will be printed ?
{
fork() ; fork() ; printf ("yes");
}
If we execute this core segment, how many times the string yes will be printed ?
a)
Only once
b)
2 times
c)
4 times
d)
8 times
|
|
Sanya Agarwal answered |
Number of times YES printed is equal to number of process created. Total Number of Processes = 2n where n is number of fork system calls. So here n = 2, 24 = 4
fork (); // Line 1
fork (); // Line 2
fork (); // Line 1
fork (); // Line 2
So, there are total 4 processes (3 new child processes and one original process). Option (C) is correct.
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore .
void P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
Which one of the following is true?
- a)The implementation may not work if context switching is disabled in P.
- b)Instead of using fetch-and-set, a pair of normal load/store can be used
- c)The implementation of V is wrong
- d)The code does not implement a binary semaphore
Correct answer is option 'A'. Can you explain this answer?
The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore .
void P (binary_semaphore *s) {
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
unsigned y;
unsigned *x = &(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
S->value = 0;
}
Which one of the following is true?
a)
The implementation may not work if context switching is disabled in P.
b)
Instead of using fetch-and-set, a pair of normal load/store can be used
c)
The implementation of V is wrong
d)
The code does not implement a binary semaphore
|
|
Devanshi Desai answered |
&(s->value); // get the memory location of s
do {
atomic_fetch_and_set(x, 1, &y); // set x to 1 and get the old value in y
} while (y == 1); // keep trying until x was 0 before we set it to 1
}
void V (binary_semaphore *s) {
atomic_fetch_and_set(&(s->value), 0, NULL); // set s to 0 and discard old value
}
This implementation ensures that only one process can enter the critical section at a time, as the P function will block until the semaphore value is 0 before setting it to 1. The V function simply sets the semaphore value back to 0, allowing another process to enter the critical section. The use of atomic_fetch_and_set ensures that these operations are performed atomically, without allowing any other process to access the semaphore value in between.
do {
atomic_fetch_and_set(x, 1, &y); // set x to 1 and get the old value in y
} while (y == 1); // keep trying until x was 0 before we set it to 1
}
void V (binary_semaphore *s) {
atomic_fetch_and_set(&(s->value), 0, NULL); // set s to 0 and discard old value
}
This implementation ensures that only one process can enter the critical section at a time, as the P function will block until the semaphore value is 0 before setting it to 1. The V function simply sets the semaphore value back to 0, allowing another process to enter the critical section. The use of atomic_fetch_and_set ensures that these operations are performed atomically, without allowing any other process to access the semaphore value in between.
Consider the following code fragment:
if (fork() == 0)
{ a = a + 5; printf("%d,%dn", a, &a); }
else { a = a –5; printf("%d, %dn", a, &a); }Let u, v be the values printed by the parent process, and x, y be the values printed by the child process. Which one of the following is TRUE?- a)u = x + 10 and v = y
- b)u = x + 10 and v != y
- c)u + 10 = x and v = y
- d)u + 10 = x and v != y
Correct answer is option 'C'. Can you explain this answer?
Consider the following code fragment:
if (fork() == 0)
{ a = a + 5; printf("%d,%dn", a, &a); }
else { a = a –5; printf("%d, %dn", a, &a); }
if (fork() == 0)
{ a = a + 5; printf("%d,%dn", a, &a); }
else { a = a –5; printf("%d, %dn", a, &a); }
Let u, v be the values printed by the parent process, and x, y be the values printed by the child process. Which one of the following is TRUE?
a)
u = x + 10 and v = y
b)
u = x + 10 and v != y
c)
u + 10 = x and v = y
d)
u + 10 = x and v != y
|
|
Yash Patel answered |
fork() returns 0 in child process and process ID of child process in parent process. In Child (x), a = a + 5 In Parent (u), a = a – 5; Therefore x = u + 10. The physical addresses of ‘a’ in parent and child must be different. But our program accesses virtual addresses (assuming we are running on an OS that uses virtual memory). The child process gets an exact copy of parent process and virtual address of ‘a’ doesn’t change in child process. Therefore, we get same addresses in both parent and child. See this run for example.
A task in a blocked state- a)is executable
- b)is running
- c)must still be placed in the run queues
- d)is waiting for some temporarily unavailable resources
Correct answer is option 'D'. Can you explain this answer?
A task in a blocked state
a)
is executable
b)
is running
c)
must still be placed in the run queues
d)
is waiting for some temporarily unavailable resources
|
|
Luminary Institute answered |
Waiting or Blocked state is when a process has requested some input/output and is waiting for the resource. So, option (D) is correct.
At a particular time of computation, the value of a counting semaphore is 7. Then 20 P operation and x V operations were completed on this semaphore. If the final value of the semaphore is 5, x will be
- a)8
- b)12
- c)18
- d)11
Correct answer is option 'C'. Can you explain this answer?
At a particular time of computation, the value of a counting semaphore is 7. Then 20 P operation and x V operations were completed on this semaphore. If the final value of the semaphore is 5, x will be
a)
8
b)
12
c)
18
d)
11
|
|
Gargi Menon answered |
Understanding the scenario:
Given that the initial value of the counting semaphore is 10, 12 P operations and "x" V operations are performed on it. After these operations, the final value of the semaphore is 7.
Calculating the total change in value:
- P operation decreases the semaphore value by 1 each time it is executed.
- V operation increases the semaphore value by 1 each time it is executed.
- Therefore, the total change in value due to 12 P operations is -12, and the total change in value due to "x" V operations is +x.
Calculating the final value of the semaphore:
Given that the final value of the semaphore is 7, we can write the equation as:
Initial value - total change in value = final value
10 - 12 + x = 7
x = 7 + 12 - 10
x = 9
Therefore, the number of V operations performed on the semaphore is 9. Thus, the correct answer is option C which is 10.
Given that the initial value of the counting semaphore is 10, 12 P operations and "x" V operations are performed on it. After these operations, the final value of the semaphore is 7.
Calculating the total change in value:
- P operation decreases the semaphore value by 1 each time it is executed.
- V operation increases the semaphore value by 1 each time it is executed.
- Therefore, the total change in value due to 12 P operations is -12, and the total change in value due to "x" V operations is +x.
Calculating the final value of the semaphore:
Given that the final value of the semaphore is 7, we can write the equation as:
Initial value - total change in value = final value
10 - 12 + x = 7
x = 7 + 12 - 10
x = 9
Therefore, the number of V operations performed on the semaphore is 9. Thus, the correct answer is option C which is 10.
Three processes arrive at time zero with CPU bursts of 16, 20 and 10 milliseconds. If the scheduler has prior knowledge about the length of the CPU bursts, the minimum achievable average waiting time for these three processes in a non-preemptive scheduler (rounded to nearest integer) is _____________ milliseconds.- a)12
- b)36
- c)46
- d)10
Correct answer is option 'A'. Can you explain this answer?
Three processes arrive at time zero with CPU bursts of 16, 20 and 10 milliseconds. If the scheduler has prior knowledge about the length of the CPU bursts, the minimum achievable average waiting time for these three processes in a non-preemptive scheduler (rounded to nearest integer) is _____________ milliseconds.
a)
12
b)
36
c)
46
d)
10
|
|
Sanya Agarwal answered |
Use SRTF, for the minimum achievable average waiting time : Gantt chart is

Since, TAT = CT - AT and WT = TAT - BT, so WT = CT - AT - BT = CT - (AT+BT) Therefore, Avg, WT = {(26-0-16) + (46-0-20) + (10-0-10)} / 3 = {10 + 26 + 0} / 3 = 36 / 3 = 12
Suppose we want to synchronize two concurrent processes P and Q using binary semaphores S and T. The code for the processes P and Q is shown below.Process P:
while (1) {
W:
print '0';
print '0';
X:
}
Process Q:
while (1) {
Y:
print '1';
print '1';
Z:
}Synchronization statements can be inserted only at points W, X, Y and Z. Which of the following will always lead to an output staring with '001100110011' ?- a)P(S) at W, V(S) at X, P(T) at Y, V(T) at Z, S and T initially 1
- b)P(S) at W, V(T) at X, P(T) at Y, V(S) at Z, S initially 1, and T initially 0
- c)P(S) at W, V(T) at X, P(T) at Y, V(S) at Z, S and T initially 1
- d)P(S) at W, V(S) at X, P(T) at Y, V(T) at Z, S initially 1, and T initially 0
Correct answer is option 'B'. Can you explain this answer?
Suppose we want to synchronize two concurrent processes P and Q using binary semaphores S and T. The code for the processes P and Q is shown below.
Process P:
while (1) {
W:
print '0';
print '0';
X:
}
Process Q:
while (1) {
Y:
print '1';
print '1';
Z:
}
while (1) {
W:
print '0';
print '0';
X:
}
Process Q:
while (1) {
Y:
print '1';
print '1';
Z:
}
Synchronization statements can be inserted only at points W, X, Y and Z. Which of the following will always lead to an output staring with '001100110011' ?
a)
P(S) at W, V(S) at X, P(T) at Y, V(T) at Z, S and T initially 1
b)
P(S) at W, V(T) at X, P(T) at Y, V(S) at Z, S initially 1, and T initially 0
c)
P(S) at W, V(T) at X, P(T) at Y, V(S) at Z, S and T initially 1
d)
P(S) at W, V(S) at X, P(T) at Y, V(T) at Z, S initially 1, and T initially 0
|
|
Sanya Agarwal answered |
P(S) means wait on semaphore ‘S’ and V(S) means signal on semaphore ‘S’. [sourcecode] Wait(S) { while (i <= 0) --S; } Signal(S) { S++; } [/sourcecode] Initially, we assume S = 1 and T = 0 to support mutual exclusion in process P and Q. Since S = 1, only process P will be executed and wait(S) will decrement the value of S. Therefore, S = 0. At the same instant, in process Q, value of T = 0. Therefore, in process Q, control will be stuck in while loop till the time process P prints 00 and increments the value of T by calling the function V(T). While the control is in process Q, semaphore S = 0 and process P would be stuck in while loop and would not execute till the time process Q prints 11 and makes the value of S = 1 by calling the function V(S). This whole process will repeat to give the output 00 11 00 11 … .
Thus, B is the correct choice.
Thus, B is the correct choice.
In a certain operating system, deadlock prevention is attempted using the following scheme. Each process is assigned a unique timestamp, and is restarted with the same timestamp if killed. Let Ph be the process holding a resource R, Pr be a process requesting for the same resource R, and T(Ph) and T(Pr) be their timestamps respectively. The decision to wait or preempt one of the processes is based on the following algorithm.
if T(Pr) < T(Ph)then kill Prelse wait
Which one of the following is TRUE?- a)The scheme is deadlock-free, but not starvation-free
- b)The scheme is not deadlock-free, but starvation-free
- c)The scheme is neither deadlock-free nor starvation-free
- d)The scheme is both deadlock-free and starvation-free
Correct answer is option 'A'. Can you explain this answer?
In a certain operating system, deadlock prevention is attempted using the following scheme. Each process is assigned a unique timestamp, and is restarted with the same timestamp if killed. Let Ph be the process holding a resource R, Pr be a process requesting for the same resource R, and T(Ph) and T(Pr) be their timestamps respectively. The decision to wait or preempt one of the processes is based on the following algorithm.
if T(Pr) < T(Ph)
if T(Pr) < T(Ph)
then kill Pr
else wait
Which one of the following is TRUE?
Which one of the following is TRUE?
a)
The scheme is deadlock-free, but not starvation-free
b)
The scheme is not deadlock-free, but starvation-free
c)
The scheme is neither deadlock-free nor starvation-free
d)
The scheme is both deadlock-free and starvation-free
|
|
Sanya Agarwal answered |
- This scheme is making sure that the timestamp of requesting process is always lesser than holding process
- The process is restarted with same timestamp if killed and that timestamp can NOT be greater than the existing time stamp
From 1 and 2,it is clear that any new process coming having LESSER timestamp will be KILLED.So,NO DEADLOCK possible However, a new process will lower timestamp may have to wait infinitely because of its LOWER timestamp(as killed process will also have same timestamp ,as it was killed earlier).STARVATION IS Definitely POSSIBLE So Answer is A
Which of the following conditions does not hold good for a solution to a critical section problem ?- a)No assumptions may be made about speeds or the number of CPUs.
- b)No two processes may be simultaneously inside their critical sections.
- c)Processes running outside its critical section may block other processes.
- d)Processes do not wait forever to enter its critical section.
Correct answer is option 'C'. Can you explain this answer?
Which of the following conditions does not hold good for a solution to a critical section problem ?
a)
No assumptions may be made about speeds or the number of CPUs.
b)
No two processes may be simultaneously inside their critical sections.
c)
Processes running outside its critical section may block other processes.
d)
Processes do not wait forever to enter its critical section.
|
|
Luminary Institute answered |
In Critical section problem:
- No assumptions may be made about speeds or the number of CPUs.
- No two processes may be simultaneously inside their critical sections.
- Processes running outside its critical section can't block other processes getting enter into critical section.
- Processes do not wait forever to enter its critical section.
Option (C) is correct.
The link between two processes P and Q to send and receive messages is called __________- a)communication link
- b)message-passing link
- c)synchronization link
- d)all of the mentioned
Correct answer is option 'A'. Can you explain this answer?
The link between two processes P and Q to send and receive messages is called __________
a)
communication link
b)
message-passing link
c)
synchronization link
d)
all of the mentioned
|
|
Sudhir Patel answered |
The link between two processes P and Q to send and receive messages is called communication link. Two processes P and Q want to communicate with each other; there should be a communication link that must exist between these two processes so that both processes can able to send and receive messages using that link.
Messages sent by a process __________- a)have to be of a fixed size
- b)have to be a variable size
- c)can be fixed or variable sized
- d)none of the mentioned
Correct answer is option 'C'. Can you explain this answer?
Messages sent by a process __________
a)
have to be of a fixed size
b)
have to be a variable size
c)
can be fixed or variable sized
d)
none of the mentioned
|
|
Sarthak Chakraborty answered |
Introduction:
In distributed systems, processes communicate with each other by sending and receiving messages. These messages can vary in size depending on the information being transmitted. The size of the message can be fixed or variable, depending on the requirements and design of the system.
Fixed-size messages:
Some systems require messages to always have a fixed size. This can simplify the communication process as each message is guaranteed to have a consistent format and length. The receiving process knows exactly how much data to expect and can easily parse the message accordingly. Fixed-size messages are commonly used in systems where efficiency and speed are critical, such as real-time applications or high-performance computing.
Variable-size messages:
In other cases, messages may have a variable size. This allows for more flexibility in the information being transmitted. Variable-size messages are useful when the size of the data being sent can vary significantly. For example, in a file transfer protocol, the size of the files being transmitted can vary greatly. Using fixed-size messages would lead to inefficiencies, as messages would need to be padded or split to fit the fixed size.
Advantages of fixed-size messages:
- Simplifies the communication process as each message has a consistent format and length.
- Allows for efficient processing and parsing of messages.
- Well-suited for real-time applications or high-performance computing where speed and efficiency are critical.
Advantages of variable-size messages:
- Provides flexibility in transmitting data of varying sizes.
- Eliminates the need for padding or splitting messages to fit a fixed size.
- Well-suited for applications where the size of the data being transmitted can vary significantly, such as file transfers.
Conclusion:
In conclusion, messages sent by a process in a distributed system can be of fixed or variable size. The choice between fixed or variable-size messages depends on the requirements and design of the system. Fixed-size messages offer simplicity and efficiency, while variable-size messages provide flexibility and adaptability to varying data sizes.
In distributed systems, processes communicate with each other by sending and receiving messages. These messages can vary in size depending on the information being transmitted. The size of the message can be fixed or variable, depending on the requirements and design of the system.
Fixed-size messages:
Some systems require messages to always have a fixed size. This can simplify the communication process as each message is guaranteed to have a consistent format and length. The receiving process knows exactly how much data to expect and can easily parse the message accordingly. Fixed-size messages are commonly used in systems where efficiency and speed are critical, such as real-time applications or high-performance computing.
Variable-size messages:
In other cases, messages may have a variable size. This allows for more flexibility in the information being transmitted. Variable-size messages are useful when the size of the data being sent can vary significantly. For example, in a file transfer protocol, the size of the files being transmitted can vary greatly. Using fixed-size messages would lead to inefficiencies, as messages would need to be padded or split to fit the fixed size.
Advantages of fixed-size messages:
- Simplifies the communication process as each message has a consistent format and length.
- Allows for efficient processing and parsing of messages.
- Well-suited for real-time applications or high-performance computing where speed and efficiency are critical.
Advantages of variable-size messages:
- Provides flexibility in transmitting data of varying sizes.
- Eliminates the need for padding or splitting messages to fit a fixed size.
- Well-suited for applications where the size of the data being transmitted can vary significantly, such as file transfers.
Conclusion:
In conclusion, messages sent by a process in a distributed system can be of fixed or variable size. The choice between fixed or variable-size messages depends on the requirements and design of the system. Fixed-size messages offer simplicity and efficiency, while variable-size messages provide flexibility and adaptability to varying data sizes.
Fork is- a)the creation of a new job
- b)the dispatching of a task
- c)increasing the priority of a task
- d)the creation of a new process
Correct answer is option 'D'. Can you explain this answer?
Fork is
a)
the creation of a new job
b)
the dispatching of a task
c)
increasing the priority of a task
d)
the creation of a new process
|
|
Sanya Agarwal answered |
fork() creates a new process by duplicating the calling process, The new process, referred to as child, is an exact duplicate of the calling process, referred to as parent, except for the following : The child has its own unique process ID, and this PID does not match the ID of any existing process group. The child’s parent process ID is the same as the parent’s process ID. The child does not inherit its parent’s memory locks and semaphore adjustments. The child does not inherit outstanding asynchronous I/O operations from its parent nor does it inherit any asynchronous I/O contexts from its parent. So, option (D) is correct.
In an operating system, indivisibility of operation means:- a)Operation is interruptable
- b)Race - condition may occur
- c)Processor can not be pre-empted
- d)All of the above
Correct answer is option 'C'. Can you explain this answer?
In an operating system, indivisibility of operation means:
a)
Operation is interruptable
b)
Race - condition may occur
c)
Processor can not be pre-empted
d)
All of the above
|
|
Yash Patel answered |
In an operating system, indivisibility of operation means processor can not be pre-empted. One a process starts its execution it will not suspended or stop its execution inside the processor. So, option (C) is correct.
Which of the following are TRUE for direct communication?- a)A communication link can be associated with N number of process(N = max. number of processes supported by system)
- b)A communication link is associated with exactly two processes
- c)Exactly N/2 links exist between each pair of processes(N = max. number of processes supported by system)
- d)Exactly two link exists between each pair of processes
Correct answer is option 'B'. Can you explain this answer?
Which of the following are TRUE for direct communication?
a)
A communication link can be associated with N number of process(N = max. number of processes supported by system)
b)
A communication link is associated with exactly two processes
c)
Exactly N/2 links exist between each pair of processes(N = max. number of processes supported by system)
d)
Exactly two link exists between each pair of processes
|
|
Mahi Datta answered |
Direct Communication - Explanation
Communication Link Association:
- In direct communication, a communication link is associated with exactly two processes.
- This means that each communication link establishes a direct connection between two specific processes.
Number of Links:
- Each pair of processes in direct communication has exactly one link between them.
- Therefore, there is exactly one link between each pair of processes in direct communication.
Explanation of Correct Answer (Option B):
- The correct answer is option B, which states that a communication link is associated with exactly two processes.
- This statement is true for direct communication as each link connects only two processes directly.
- This ensures a direct and specific communication path between the two processes involved in the communication.
Communication Link Association:
- In direct communication, a communication link is associated with exactly two processes.
- This means that each communication link establishes a direct connection between two specific processes.
Number of Links:
- Each pair of processes in direct communication has exactly one link between them.
- Therefore, there is exactly one link between each pair of processes in direct communication.
Explanation of Correct Answer (Option B):
- The correct answer is option B, which states that a communication link is associated with exactly two processes.
- This statement is true for direct communication as each link connects only two processes directly.
- This ensures a direct and specific communication path between the two processes involved in the communication.
Which of the following need not necessarily be saved on a context switch between processes?- a)General purpose registers
- b)Translation look-aside buffer
- c)Program counter
- d)All of the above
Correct answer is option 'B'. Can you explain this answer?
Which of the following need not necessarily be saved on a context switch between processes?
a)
General purpose registers
b)
Translation look-aside buffer
c)
Program counter
d)
All of the above
|
|
Yash Patel answered |
The values stored in registers, stack pointers and program counters are saved on context switch between the processes so as to resume the execution of the process. There's no need of saving the contents of TLB as it is invalidated after each context switch. So, option (B) is correct
Which is the correct definition of a valid process transition in an operating system?- a)Wake up: ready → running
- b)Dispatch: ready → running
- c)Block: ready → running
- d)Timer runout: ready → running
Correct answer is option 'B'. Can you explain this answer?
Which is the correct definition of a valid process transition in an operating system?
a)
Wake up: ready → running
b)
Dispatch: ready → running
c)
Block: ready → running
d)
Timer runout: ready → running
|
|
Sanya Agarwal answered |
The statetransition diagram of a process(preemptive scheduling):
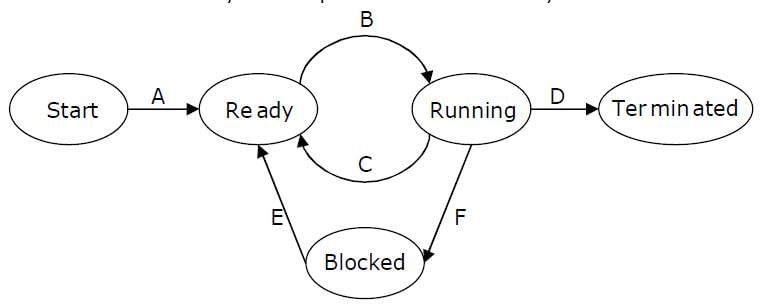
Option 1: Wake up: ready → running It is incorrect as when a process wakes up it is shifted from blocked state to ready state and not from ready to running. Option 2: Dispatch: ready → running It is correct as the dispatcher selectively assigns the CPU to one of the process in the ready queue based on a well defined algorithm. Option 3: Block: ready → running It is incorrect as a process is blocked when it is either pre-empted by some other process or due to some i/o operation. So when a process gets blocked it shifts from running state to blocked state. Option 4: Timer runout: ready → running When the time duration of execution of a process expires, the timer interrupts and the process shifts from the running state to ready queue. So, option (B) is correct.
A task in a blocked state- a)is executable
- b)is running
- c)must still be placed in the run queues
- d)is waiting for some temporarily unavailable resources
Correct answer is option 'D'. Can you explain this answer?
A task in a blocked state
a)
is executable
b)
is running
c)
must still be placed in the run queues
d)
is waiting for some temporarily unavailable resources
|
|
Ravi Singh answered |
Waiting or Blocked state is when a process has requested some input/output and is waiting for the resource. So, option (D) is correct.
Which of the following does not interrupt a running process?- a)A device
- b)Timer
- c)Scheduler process
- d)Power failure
Correct answer is option 'C'. Can you explain this answer?
Which of the following does not interrupt a running process?
a)
A device
b)
Timer
c)
Scheduler process
d)
Power failure
|
|
Preethi Basu answered |
Interrupting a Running Process
A process is an instance of a program in execution. It consists of the program code and its current activity which includes the program counter, registers, and variables. Interrupts are events that occur during the execution of a program that cause the normal sequence of instructions to be temporarily suspended, allowing the system to handle a specific event or condition.
There are several types of interrupts that can occur during the execution of a process, including device interrupts, timer interrupts, scheduler process interrupts, and power failures. Among these options, the scheduler process interrupt does not interrupt a running process.
Device Interrupts:
- A device interrupt occurs when a hardware device needs attention from the CPU.
- For example, when a key is pressed on the keyboard, an interrupt signal is sent to the CPU, causing the current process to be interrupted and the keyboard device driver to handle the input.
Timer Interrupts:
- A timer interrupt occurs when a hardware timer reaches a specific interval.
- Timer interrupts are used to perform various system tasks, such as scheduling processes and preempting the currently running process.
- When a timer interrupt occurs, the currently running process is interrupted, and the CPU switches to a different process based on the scheduling algorithm.
Power Failures:
- Power failures occur when there is a loss of electrical power.
- In the event of a power failure, the entire system, including all running processes, is abruptly terminated as the CPU loses power.
Scheduler Process Interrupts:
- The scheduler process is responsible for determining which processes should be executed and allocating CPU time to them.
- However, the scheduler process itself does not interrupt a running process.
- Instead, it determines when a process should be interrupted based on the scheduling algorithm and initiates a context switch to switch to a different process.
Conclusion:
Among the given options, the scheduler process interrupt does not interrupt a running process. Device interrupts, timer interrupts, and power failures can all cause a running process to be interrupted.
A process is an instance of a program in execution. It consists of the program code and its current activity which includes the program counter, registers, and variables. Interrupts are events that occur during the execution of a program that cause the normal sequence of instructions to be temporarily suspended, allowing the system to handle a specific event or condition.
There are several types of interrupts that can occur during the execution of a process, including device interrupts, timer interrupts, scheduler process interrupts, and power failures. Among these options, the scheduler process interrupt does not interrupt a running process.
Device Interrupts:
- A device interrupt occurs when a hardware device needs attention from the CPU.
- For example, when a key is pressed on the keyboard, an interrupt signal is sent to the CPU, causing the current process to be interrupted and the keyboard device driver to handle the input.
Timer Interrupts:
- A timer interrupt occurs when a hardware timer reaches a specific interval.
- Timer interrupts are used to perform various system tasks, such as scheduling processes and preempting the currently running process.
- When a timer interrupt occurs, the currently running process is interrupted, and the CPU switches to a different process based on the scheduling algorithm.
Power Failures:
- Power failures occur when there is a loss of electrical power.
- In the event of a power failure, the entire system, including all running processes, is abruptly terminated as the CPU loses power.
Scheduler Process Interrupts:
- The scheduler process is responsible for determining which processes should be executed and allocating CPU time to them.
- However, the scheduler process itself does not interrupt a running process.
- Instead, it determines when a process should be interrupted based on the scheduling algorithm and initiates a context switch to switch to a different process.
Conclusion:
Among the given options, the scheduler process interrupt does not interrupt a running process. Device interrupts, timer interrupts, and power failures can all cause a running process to be interrupted.
What is the name of the technique in which the operating system of a computer executes several programs concurrently by switching back and forth between them?- a)Partitioning
- b)Multi-tasking
- c)Windowing
- d)Paging
Correct answer is option 'B'. Can you explain this answer?
What is the name of the technique in which the operating system of a computer executes several programs concurrently by switching back and forth between them?
a)
Partitioning
b)
Multi-tasking
c)
Windowing
d)
Paging
|
|
Luminary Institute answered |
In a multitasking system, a computer executes several programs simultaneously by switching them back and forth to increase the user interactivity. Processes share the CPU and execute in an interleaving manner. This allows the user to run more than one program at a time. Option (B) is correct.
On a system using non-preemptive scheduling, processes with expected run times of 5, 18, 9 and 12 are in the ready queue. In what order should they be run to minimize wait time?- a)5, 12, 9, 18
- b)5, 9, 12, 18
- c)12, 18, 9, 5
- d)9, 12, 18, 5
Correct answer is option 'B'. Can you explain this answer?
On a system using non-preemptive scheduling, processes with expected run times of 5, 18, 9 and 12 are in the ready queue. In what order should they be run to minimize wait time?
a)
5, 12, 9, 18
b)
5, 9, 12, 18
c)
12, 18, 9, 5
d)
9, 12, 18, 5
|
|
Ananya Shah answered |
Explanation:
In non-preemptive scheduling, once a process starts running, it will continue to run until it completes or blocks. Therefore, the order in which the processes are scheduled can have an impact on the wait time.
To minimize the wait time, we need to consider the expected run times of the processes. The idea is to schedule the shorter processes first, so that they complete quickly and reduce the overall wait time for the longer processes.
Order of Processes:
1. Select the process with the shortest expected run time from the ready queue.
2. Schedule the selected process to run.
3. Repeat steps 1 and 2 until all processes are scheduled.
Based on this approach, let's evaluate the given options:
a) 5, 12, 9, 18
- The process with expected run time 5 is the shortest, so we select it first.
- After the process with run time 5 completes, we have processes with run times 12, 9, and 18 remaining.
- The next shortest process is 9, so we schedule it.
- After the process with run time 9 completes, we have processes with run times 12 and 18 remaining.
- The next shortest process is 12, so we schedule it.
- Finally, we schedule the process with run time 18.
- The order is 5, 9, 12, 18.
c) 12, 18, 9, 5
- The process with expected run time 12 is the longest, so selecting it first would increase the overall wait time.
- Similarly, selecting the process with run time 18 next would also increase the wait time.
- Therefore, this order is not optimal.
d) 9, 12, 18, 5
- This order is similar to option a, but the process with run time 9 is scheduled before the process with run time 12.
- Since the process with run time 12 is shorter, it should be scheduled before the longer process with run time 9.
- Therefore, this order is not optimal.
Conclusion:
The optimal order to minimize the wait time is option b) 5, 9, 12, 18.
In non-preemptive scheduling, once a process starts running, it will continue to run until it completes or blocks. Therefore, the order in which the processes are scheduled can have an impact on the wait time.
To minimize the wait time, we need to consider the expected run times of the processes. The idea is to schedule the shorter processes first, so that they complete quickly and reduce the overall wait time for the longer processes.
Order of Processes:
1. Select the process with the shortest expected run time from the ready queue.
2. Schedule the selected process to run.
3. Repeat steps 1 and 2 until all processes are scheduled.
Based on this approach, let's evaluate the given options:
a) 5, 12, 9, 18
- The process with expected run time 5 is the shortest, so we select it first.
- After the process with run time 5 completes, we have processes with run times 12, 9, and 18 remaining.
- The next shortest process is 9, so we schedule it.
- After the process with run time 9 completes, we have processes with run times 12 and 18 remaining.
- The next shortest process is 12, so we schedule it.
- Finally, we schedule the process with run time 18.
- The order is 5, 9, 12, 18.
c) 12, 18, 9, 5
- The process with expected run time 12 is the longest, so selecting it first would increase the overall wait time.
- Similarly, selecting the process with run time 18 next would also increase the wait time.
- Therefore, this order is not optimal.
d) 9, 12, 18, 5
- This order is similar to option a, but the process with run time 9 is scheduled before the process with run time 12.
- Since the process with run time 12 is shorter, it should be scheduled before the longer process with run time 9.
- Therefore, this order is not optimal.
Conclusion:
The optimal order to minimize the wait time is option b) 5, 9, 12, 18.
For switching from a CPU user mode to the supervisor mode following type of interrupt is most appropriate- a)Internal interrupts
- b)External interrupts
- c)Software interrupts
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
For switching from a CPU user mode to the supervisor mode following type of interrupt is most appropriate
a)
Internal interrupts
b)
External interrupts
c)
Software interrupts
d)
None of the above
|
|
Sanya Agarwal answered |
For switching from a CPU user mode to the supervisor mode Software interrupts occurs. Software interrupts is internal interrupt triggered by some some software instruction. And external interrupt is caused by some hardware module. Option (C) is correct.
Round Robin schedule is essentially the pre-emptive version of- a)FIFO
- b)Shortest job first
- c)Shortest remaining time
- d)Longest remaining time
Correct answer is option 'A'. Can you explain this answer?
Round Robin schedule is essentially the pre-emptive version of
a)
FIFO
b)
Shortest job first
c)
Shortest remaining time
d)
Longest remaining time
|
|
Yash Patel answered |
FIFO when implemented in preemptive version, acts like a round-robin algorithm. So, option (A) is correct.
Three concurrent processes X, Y, and Z execute three different code segments that access and update certain shared variables. Process X executes the P operation (i.e., wait) on semaphores a, b and c; process Y executes the P operation on semaphores b, c and d; process Z executes the P operation on semaphores c, d, and a before entering the respective code segments. After completing the execution of its code segment, each process invokes the V operation (i.e., signal) on its three semaphores. All semaphores are binary semaphores initialized to one. Which one of the following represents a deadlockfree order of invoking the P operations by the processes?- a)X: P(a)P(b)P(c) Y:P(b)P(c)P(d) Z:P(c)P(d)P(a)
- b)X: P(b)P(a)P(c) Y:P(b)P(c)P(d) Z:P(a)P(c)P(d)
- c)X: P(b)P(a)P(c) Y:P(c)P(b)P(d) Z:P(a)P(c)P(d)
- d)X: P(a)P(b)P(c) Y:P(c)P(b)P(d) Z:P(c)P(d)P(a)
Correct answer is option 'B'. Can you explain this answer?
Three concurrent processes X, Y, and Z execute three different code segments that access and update certain shared variables. Process X executes the P operation (i.e., wait) on semaphores a, b and c; process Y executes the P operation on semaphores b, c and d; process Z executes the P operation on semaphores c, d, and a before entering the respective code segments. After completing the execution of its code segment, each process invokes the V operation (i.e., signal) on its three semaphores. All semaphores are binary semaphores initialized to one. Which one of the following represents a deadlockfree order of invoking the P operations by the processes?
a)
X: P(a)P(b)P(c) Y:P(b)P(c)P(d) Z:P(c)P(d)P(a)
b)
X: P(b)P(a)P(c) Y:P(b)P(c)P(d) Z:P(a)P(c)P(d)
c)
X: P(b)P(a)P(c) Y:P(c)P(b)P(d) Z:P(a)P(c)P(d)
d)
X: P(a)P(b)P(c) Y:P(c)P(b)P(d) Z:P(c)P(d)P(a)
|
|
Yash Patel answered |
Option A can cause deadlock. Imagine a situation process X has acquired a, process Y has acquired b and process Z has acquired c and d. There is circular wait now. Option C can also cause deadlock. Imagine a situation process X has acquired b, process Y has acquired c and process Z has acquired a. There is circular wait now. Option D can also cause deadlock. Imagine a situation process X has acquired a and b, process Y has acquired c. X and Y circularly waiting for each other.
Consider option A) for example here all 3 processes are concurrent so X will get semaphore a, Y will get b and Z will get c, now X is blocked for b, Y is blocked for c, Z gets d and blocked for a. Thus it will lead to deadlock. Similarly one can figure out that for B) completion order is Z,X then Y.
Dining Philosopher's problem is a:- a)Producer - consumer problem
- b)Classical IPC problem
- c)Starvation problem
- d)Synchronization primitive
Correct answer is option 'B'. Can you explain this answer?
Dining Philosopher's problem is a:
a)
Producer - consumer problem
b)
Classical IPC problem
c)
Starvation problem
d)
Synchronization primitive
|
|
Ravi Singh answered |
Dining Philosopher's problem is a Classical IPC problem. Option (B) is correct.
In indirect communication between processes P and Q _____- a)there is another process R to handle and pass on the messages between P and Q
- b)there is another machine between the two processes to help communication
- c)there is a mailbox to help communication between P and Q
- d)none of the mentioned
Correct answer is option 'C'. Can you explain this answer?
In indirect communication between processes P and Q _____
a)
there is another process R to handle and pass on the messages between P and Q
b)
there is another machine between the two processes to help communication
c)
there is a mailbox to help communication between P and Q
d)
none of the mentioned
|
|
Sudhir Patel answered |
In indirect communication between processes P and Q there is a mailbox to help communication between P and Q. A mailbox can be viewed abstractly as an object into which messages can be placed by processes and from which messages can be removed.
A shared variable x, initialized to zero, is operated on by four concurrent processes W, X, Y, Z as follows. Each of the processes W and X reads x from memory, increments by one, stores it to memory, and then terminates. Each of the processes Y and Z reads x from memory, decrements by two, stores it to memory, and then terminates. Each process before reading x invokes the P operation (i.e., wait) on a counting semaphore S and invokes the V operation (i.e., signal) on the semaphore S after storing x to memory. Semaphore S is initialized to two. What is the maximum possible value of x after all processes complete execution?- a)-2
- b)-1
- c)1
- d)2
Correct answer is option 'D'. Can you explain this answer?
A shared variable x, initialized to zero, is operated on by four concurrent processes W, X, Y, Z as follows. Each of the processes W and X reads x from memory, increments by one, stores it to memory, and then terminates. Each of the processes Y and Z reads x from memory, decrements by two, stores it to memory, and then terminates. Each process before reading x invokes the P operation (i.e., wait) on a counting semaphore S and invokes the V operation (i.e., signal) on the semaphore S after storing x to memory. Semaphore S is initialized to two. What is the maximum possible value of x after all processes complete execution?
a)
-2
b)
-1
c)
1
d)
2
|
|
Ravi Singh answered |
Processes can run in many ways, below is one of the cases in which x attains max value
Semaphore S is initialized to 2
Process W executes S=1, x=1 but it doesn't update the x variable.
Then process Y executes S=0, it decrements x, now x= -2 and signal semaphore S=1
Now process Z executes s=0, x=-4, signal semaphore S=1
Now process W updates x=1, S=2 Then process X executes X=2
So correct option is D
Now process W updates x=1, S=2 Then process X executes X=2
So correct option is D
Which of the following need not necessarily be saved on a Context Switch between processes?- a)General purpose registers
- b)Translation look-aside buffer
- c)Program counter
- d)Stack pointer
Correct answer is option 'B'. Can you explain this answer?
Which of the following need not necessarily be saved on a Context Switch between processes?
a)
General purpose registers
b)
Translation look-aside buffer
c)
Program counter
d)
Stack pointer
|
|
Ravi Singh answered |
The values stored in registers, stack pointers and program counters are saved on context switch between the processes so as to resume the execution of the process. There's no need for saving the contents of TLB as it is being invalid after each context switch. So, option (B) is correct
Feedback queues- a)are very simple to implement
- b)dispatch tasks according to execution characteristics
- c)are used to favour real time tasks
- d)require manual intervention to implement properly
Correct answer is option 'B'. Can you explain this answer?
Feedback queues
a)
are very simple to implement
b)
dispatch tasks according to execution characteristics
c)
are used to favour real time tasks
d)
require manual intervention to implement properly
|
|
Ravi Singh answered |
Multilevel Feedback Queue Scheduling (MLFQ) keep analyzing the behavior (time of execution) of processes and according to which it changes its priority of execution of processes. Option (C) is correct.
The performance of Round Robin algorithm depends heavily on- a)size of the process
- b)the I/O bursts of the process
- c)the CPU bursts of the process
- d)the size of the time quantum
Correct answer is option 'D'. Can you explain this answer?
The performance of Round Robin algorithm depends heavily on
a)
size of the process
b)
the I/O bursts of the process
c)
the CPU bursts of the process
d)
the size of the time quantum
|
|
Ravi Singh answered |
In round robin algorithm, the size of time quanta plays a very important role as: If size of quanta is too small: Context switches will increase and it is counted as the waste time, so CPU utilization will decrease. If size of quanta is too large: Larger time quanta will lead to Round robin regenerated into FCFS scheduling algorithm. So, option (D) is correct.
Two processes X and Y need to access a critical section. Consider the following synchronization construct used by both the processes. Here, varP and varQ are shared variables and both are initialized to false. Which one of the following statements is true?
Here, varP and varQ are shared variables and both are initialized to false. Which one of the following statements is true?- a)The proposed solution prevents deadlock but fails to guarantee mutual exclusion
- b)The proposed solution guarantees mutual exclusion but fails to prevent deadlock
- c)The proposed solution guarantees mutual exclusion and prevents deadlock
- d)The proposed solution fails to prevent deadlock and fails to guarantee mutual exclusion
Correct answer is option 'A'. Can you explain this answer?
Two processes X and Y need to access a critical section. Consider the following synchronization construct used by both the processes.
Here, varP and varQ are shared variables and both are initialized to false. Which one of the following statements is true?
a)
The proposed solution prevents deadlock but fails to guarantee mutual exclusion
b)
The proposed solution guarantees mutual exclusion but fails to prevent deadlock
c)
The proposed solution guarantees mutual exclusion and prevents deadlock
d)
The proposed solution fails to prevent deadlock and fails to guarantee mutual exclusion
|
|
Ravi Singh answered |
When both processes try to enter critical section simultaneously,both are allowed to do so since both shared variables varP and varQ are true.So, clearly there is NO mutual exclusion. Also, deadlock is prevented because mutual exclusion is one of the four conditions to be satisfied for deadlock to happen.Hence, answer is A.
In a dot matrix printer the time to print a character is 6 m.sec., time to space in between characters is 2 m.sec., and the number of characters in a line are 200. The printing speed of the dot matrix printer in characters per second and the time to print a character line are given by which of the following options?- a)125 chars/second and 0.8 seconds
- b)250 chars/second and 0.6 seconds
- c)166 chars/second and 0.8 seconds
- d)250 chars/second and 0.4 seconds
- e)125 chars/second and 1.6 seconds
Correct answer is option 'E'. Can you explain this answer?
In a dot matrix printer the time to print a character is 6 m.sec., time to space in between characters is 2 m.sec., and the number of characters in a line are 200. The printing speed of the dot matrix printer in characters per second and the time to print a character line are given by which of the following options?
a)
125 chars/second and 0.8 seconds
b)
250 chars/second and 0.6 seconds
c)
166 chars/second and 0.8 seconds
d)
250 chars/second and 0.4 seconds
e)
125 chars/second and 1.6 seconds
|
|
Yash Patel answered |
Total no of characters = 200 (each character having one space) Time taken to print one character = 6 ms; Time taken to print one space = 2 ms. character printing = 200 * 6 = 1200 ms space printing = 200 * 2 = 400 ms total printing time = 1200 + 400 = 1600 ms = 1.6 s. The printing speed of the dot matrix printer in characters per second = 200 / 1.6 = 125 / s. So, option (E) is correct.
Message passing system allows processes to __________- a)communicate with each other without sharing the same address space
- b)communicate with one another by resorting to shared data
- c)share data
- d)name the recipient or sender of the message
Correct answer is option 'A'. Can you explain this answer?
Message passing system allows processes to __________
a)
communicate with each other without sharing the same address space
b)
communicate with one another by resorting to shared data
c)
share data
d)
name the recipient or sender of the message
|
|
Sudhir Patel answered |
Message Passing system allows processes to communicate with each other without sharing the same address space.
What is the name of the technique in which the operating system of a computer executes several programs concurrently by switching back and forth between them?- a)Partitioning
- b)Multi-tasking
- c)Windowing
- d)Paging
Correct answer is option 'B'. Can you explain this answer?
What is the name of the technique in which the operating system of a computer executes several programs concurrently by switching back and forth between them?
a)
Partitioning
b)
Multi-tasking
c)
Windowing
d)
Paging
|
|
Yash Patel answered |
In a multitasking system, a computer executes several programs simultaneously by switching them back and forth to increase the user interactivity. Processes share the CPU and execute in an interleaving manner. This allows the user to run more than one program at a time. Option (B) is correct.
Which of the following two operations are provided by the IPC facility?- a)write & delete message
- b)delete & receive message
- c)send & delete message
- d)receive & send message
Correct answer is option 'D'. Can you explain this answer?
Which of the following two operations are provided by the IPC facility?
a)
write & delete message
b)
delete & receive message
c)
send & delete message
d)
receive & send message
|
|
Sudhir Patel answered |
Two operations provided by the IPC facility are receive and send messages. Exchange of data takes place in cooperating processes.
In the non blocking send ______- a)the sending process keeps sending until the message is received
- b)the sending process sends the message and resumes operation
- c)the sending process keeps sending until it receives a message
- d)none of the mentioned
Correct answer is option 'B'. Can you explain this answer?
In the non blocking send ______
a)
the sending process keeps sending until the message is received
b)
the sending process sends the message and resumes operation
c)
the sending process keeps sending until it receives a message
d)
none of the mentioned
|
|
Sudhir Patel answered |
In the non blocking send, the sending process sends the message and resumes operation. Sending process doesn’t care about reception. It is also known as asynchronous send.
Consider a set of n tasks with known runtimes r1, r2....rn to be run on a uniprocessor machine. Which of the following processor scheduling algorithms will result in the maximum throughput?- a)Round Robin
- b)Shortest job first
- c)Highest response ratio next
- d)first come first served
Correct answer is option 'B'. Can you explain this answer?
Consider a set of n tasks with known runtimes r1, r2....rn to be run on a uniprocessor machine. Which of the following processor scheduling algorithms will result in the maximum throughput?
a)
Round Robin
b)
Shortest job first
c)
Highest response ratio next
d)
first come first served
|
|
Ravi Singh answered |
Throughput means total number of tasks executed per unit time i.e. sum of waiting time and burst time. Shortest job first scheduling is a scheduling policy that selects the waiting process with the smallest execution time to execute next. Thus, in shortest job first scheduling, shortest jobs are executed first. This means CPU utilization is maximum. So, maximum number of tasks are completed. Option (B) is correct.
In the Zero capacity queue __________- a)the queue can store at least one message
- b)the sender blocks until the receiver receives the message
- c)the sender keeps sending and the messages don’t wait in the queue
- d)none of the mentioned
Correct answer is option 'B'. Can you explain this answer?
In the Zero capacity queue __________
a)
the queue can store at least one message
b)
the sender blocks until the receiver receives the message
c)
the sender keeps sending and the messages don’t wait in the queue
d)
none of the mentioned
|
|
Sudhir Patel answered |
In the Zero capacity queue the sender blocks until the receiver receives the message. Zero capacity queue has maximum capacity of Zero; thus message queue does not have any waiting message in it.
Chapter doubts & questions for Process Synchronization - Operating System 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Process Synchronization - Operating System in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
Operating System
10 videos|141 docs|33 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup on EduRev and stay on top of your study goals
10M+ students crushing their study goals daily