









All Exams >
Computer Science Engineering (CSE) >
Operating System >
All Questions
All questions of Memory Management for Computer Science Engineering (CSE) Exam
A machine has 64-bit virtual addresses and 48-bit physical addresses. Pages are 16K. How many entries are needed for a conventional page table? - a)250
- b)234
- c)214
- d)248
Correct answer is option 'B'. Can you explain this answer?
A machine has 64-bit virtual addresses and 48-bit physical addresses. Pages are 16K. How many entries are needed for a conventional page table?
a)
250
b)
234
c)
214
d)
248
|
|
Alok Chavan answered |
Given information:
- 64-bit virtual addresses
- 48-bit physical addresses
- Pages are 16K
To find: Number of entries needed for a conventional page table
Solution:
1. Calculate the page size:
- Page size is 16K = 2^14 bytes
- 2^14 = 16,384 bytes
2. Calculate the number of pages:
- 64-bit virtual addresses, so the address space is 2^64 bytes
- Divide the address space by the page size to get the number of pages:
- (2^64) / (2^14) = 2^50 pages
3. Calculate the size of each page table entry:
- Physical addresses are 48 bits, so each page table entry needs to store a 48-bit physical address
- Each entry also needs to store some additional information, such as a valid/invalid bit and permission bits
- For simplicity, assume each entry is 64 bits (8 bytes) in size
4. Calculate the size of the page table:
- The page table needs to have one entry for each page, so the size of the page table is:
- (2^50) * 8 bytes = 2^53 bytes
5. Calculate the number of entries needed for the page table:
- Divide the size of the page table by the size of each entry:
- (2^53 bytes) / (8 bytes) = 2^45 entries
6. Choose the closest answer option:
- Option B: 2^34 = 17,179,869,184, which is closest to 2^45 = 35,184,372,088. Therefore, the correct answer is option B.
Final answer: The number of entries needed for a conventional page table is 2^34, which is approximately 17.2 billion.
- 64-bit virtual addresses
- 48-bit physical addresses
- Pages are 16K
To find: Number of entries needed for a conventional page table
Solution:
1. Calculate the page size:
- Page size is 16K = 2^14 bytes
- 2^14 = 16,384 bytes
2. Calculate the number of pages:
- 64-bit virtual addresses, so the address space is 2^64 bytes
- Divide the address space by the page size to get the number of pages:
- (2^64) / (2^14) = 2^50 pages
3. Calculate the size of each page table entry:
- Physical addresses are 48 bits, so each page table entry needs to store a 48-bit physical address
- Each entry also needs to store some additional information, such as a valid/invalid bit and permission bits
- For simplicity, assume each entry is 64 bits (8 bytes) in size
4. Calculate the size of the page table:
- The page table needs to have one entry for each page, so the size of the page table is:
- (2^50) * 8 bytes = 2^53 bytes
5. Calculate the number of entries needed for the page table:
- Divide the size of the page table by the size of each entry:
- (2^53 bytes) / (8 bytes) = 2^45 entries
6. Choose the closest answer option:
- Option B: 2^34 = 17,179,869,184, which is closest to 2^45 = 35,184,372,088. Therefore, the correct answer is option B.
Final answer: The number of entries needed for a conventional page table is 2^34, which is approximately 17.2 billion.

Which one of the following is NOT shared by the threads of the same process?- a)Stack
- b)Address Space
- c)File Descriptor Table
- d)Message Queue
Correct answer is option 'A'. Can you explain this answer?
Which one of the following is NOT shared by the threads of the same process?
a)
Stack
b)
Address Space
c)
File Descriptor Table
d)
Message Queue

|
Cstoppers Instructors answered |
Threads can not share stack (used for maintaining function calls) as they may have their individual function call sequence.
Where does the swap space reside?- a)RAM
- b)Disk
- c)ROM
- d)On-chip cache
Correct answer is option 'B'. Can you explain this answer?
Where does the swap space reside?
a)
RAM
b)
Disk
c)
ROM
d)
On-chip cache
|
|
Sanya Agarwal answered |
Swap space is an area on disk that temporarily holds a process memory image. When memory is full and process needs memory, inactive parts of process are put in swap space of disk.
A virtual memory system uses First In First Out (FIFO) page replacement policy and allocates a fixed number of frames to a process. Consider the following statements:P: Increasing the number of page frames allocated to a
process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference.
Which one of the following is TRUE?- a)Both P and Q are true, and Q is the reason for P
- b)Both P and Q are true, but Q is not the reason for P.
- c)P is false, but Q is true
- d)Both P and Q are false
Correct answer is option 'B'. Can you explain this answer?
A virtual memory system uses First In First Out (FIFO) page replacement policy and allocates a fixed number of frames to a process. Consider the following statements:
P: Increasing the number of page frames allocated to a
process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference.
Which one of the following is TRUE?
process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference.
Which one of the following is TRUE?
a)
Both P and Q are true, and Q is the reason for P
b)
Both P and Q are true, but Q is not the reason for P.
c)
P is false, but Q is true
d)
Both P and Q are false
|
|
Ravi Singh answered |
First In First Out Page Replacement Algorithms: This is the simplest page replacement algorithm. In this algorithm, operating system keeps track of all pages in the memory in a queue, oldest page is in the front of the queue. When a page needs to be replaced page in the front of the queue is selected for removal. FIFO Page replacement algorithms suffers from Belady’s anomaly : Belady’s anomaly states that it is possible to have more page faults when increasing the number of page frames.
Solution: Statement P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate. Correct, as FIFO page replacement algorithm suffers from belady’s anomaly which states above statement.
Statement Q: Some programs do not exhibit locality of reference. Correct, Locality often occurs because code contains loops that tend to reference arrays or other data structures by indices. So we can write a program does not contain loop and do not exhibit locality of reference. So, both statement P and Q are correct but Q is not the reason for P as Belady’s Anomaly occurs for some specific patterns of page references.
Consider six memory partitions of size 200 KB, 400 KB, 600 KB, 500 KB, 300 KB, and 250 KB, where KB refers to kilobyte. These partitions need to be allotted to four processes of sizes 357 KB, 210 KB, 468 KB and 491 KB in that order. If the best fit algorithm is used, which partitions are NOT allotted to any process?- a)200 KB and 300 KB
- b)200 KB and 250 KB
- c)250 KB and 300 KB
- d)300 KB and 400 KB
Correct answer is option 'A'. Can you explain this answer?
Consider six memory partitions of size 200 KB, 400 KB, 600 KB, 500 KB, 300 KB, and 250 KB, where KB refers to kilobyte. These partitions need to be allotted to four processes of sizes 357 KB, 210 KB, 468 KB and 491 KB in that order. If the best fit algorithm is used, which partitions are NOT allotted to any process?
a)
200 KB and 300 KB
b)
200 KB and 250 KB
c)
250 KB and 300 KB
d)
300 KB and 400 KB
|
|
Sanya Agarwal answered |
Best fit allocates the smallest block among those that are large enough for the new process. So the memory blocks are allocated in below order.
357 ---> 400
210 ---> 250
468 ---> 500
491 ---> 600
Sot the remaining blocks are of 200 KB and 300 KB
357 ---> 400
210 ---> 250
468 ---> 500
491 ---> 600
Sot the remaining blocks are of 200 KB and 300 KB
A processor uses 2-level page tables for virtual to physical address translation. Page tables for both levels are stored in the main memory. Virtual and physical addresses are both 32 bits wide. The memory is byte addressable. For virtual to physical address translation, the 10 most significant bits of the virtual address are used as index into the first level page table while the next 10 bits are used as index into the second level page table. The 12 least significant bits of the virtual address are used as offset within the page. Assume that the page table entries in both levels of page tables are 4 bytes wide. Further, the processor has a translation look-aside buffer (TLB), with a hit rate of 96%. The TLB caches recently used virtual page numbers and the corresponding physical page numbers. The processor also has a physically addressed cache with a hit rate of 90%. Main memory access time is 10 ns, cache access time is 1 ns, and TLB access time is also 1 ns. Assuming that no page faults occur, the average time taken to access a virtual address is approximately (to the nearest 0.5 ns)- a)1.5 ns
- b)2 ns
- c)3 ns
- d)4 ns
Correct answer is option 'D'. Can you explain this answer?
A processor uses 2-level page tables for virtual to physical address translation. Page tables for both levels are stored in the main memory. Virtual and physical addresses are both 32 bits wide. The memory is byte addressable. For virtual to physical address translation, the 10 most significant bits of the virtual address are used as index into the first level page table while the next 10 bits are used as index into the second level page table. The 12 least significant bits of the virtual address are used as offset within the page. Assume that the page table entries in both levels of page tables are 4 bytes wide. Further, the processor has a translation look-aside buffer (TLB), with a hit rate of 96%. The TLB caches recently used virtual page numbers and the corresponding physical page numbers. The processor also has a physically addressed cache with a hit rate of 90%. Main memory access time is 10 ns, cache access time is 1 ns, and TLB access time is also 1 ns. Assuming that no page faults occur, the average time taken to access a virtual address is approximately (to the nearest 0.5 ns)
a)
1.5 ns
b)
2 ns
c)
3 ns
d)
4 ns
|
|
Cstoppers Instructors answered |
The possibilities are
TLB Hit*Cache Hit +
TLB Hit*Cache Miss +
TLB Miss*Cache Hit +
TLB Miss*Cache Miss
= 0.96*0.9*2 + 0.96*0.1*12 + 0.04*0.9*22 + 0,04*0.1*32
= 3.8
≈ 4
Why 22 and 32? 22 is because when TLB miss occurs it takes 1ns and the for the physical address it has to go through two level page tables which are in main memory and takes 2 memory access and the that page is found in cache taking 1 ns which gives a total of 22
TLB Hit*Cache Hit +
TLB Hit*Cache Miss +
TLB Miss*Cache Hit +
TLB Miss*Cache Miss
= 0.96*0.9*2 + 0.96*0.1*12 + 0.04*0.9*22 + 0,04*0.1*32
= 3.8
≈ 4
Why 22 and 32? 22 is because when TLB miss occurs it takes 1ns and the for the physical address it has to go through two level page tables which are in main memory and takes 2 memory access and the that page is found in cache taking 1 ns which gives a total of 22
Consider a fully associative cache with 8 cache blocks (numbered 0-7) and the following sequence of memory block requests: 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 If LRU replacement policy is used, which cache block will have memory block 7?- a)4
- b)5
- c)6
- d)7
Correct answer is option 'B'. Can you explain this answer?
Consider a fully associative cache with 8 cache blocks (numbered 0-7) and the following sequence of memory block requests: 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 If LRU replacement policy is used, which cache block will have memory block 7?
a)
4
b)
5
c)
6
d)
7
|
|
Sanya Agarwal answered |
Block size is =8 Given 4, 3, 25, 8, 19, 6, 25, 8, 16, 35, 45, 22, 8, 3, 16, 25, 7 So from 0 to 7 ,we have
4 3 25 8 19 6 16 35 //25,8 LRU so next 16,35 come in the block.
45 3 25 8 19 6 16 35
45 22 25 8 19 6 16 35
45 22 25 8 19 6 16 35
45 22 25 8 3 6 16 35 //16 and 25 already there
45 22 25 8 3 7 16 35 //7 in 5th block Therefore , answer is B
4 3 25 8 19 6 16 35 //25,8 LRU so next 16,35 come in the block.
45 3 25 8 19 6 16 35
45 22 25 8 19 6 16 35
45 22 25 8 19 6 16 35
45 22 25 8 3 6 16 35 //16 and 25 already there
45 22 25 8 3 7 16 35 //7 in 5th block Therefore , answer is B
If LRU and Geek page replacement are compared (in terms of page faults) only for above reference string then find the correct statement from the following:- a)LRU and Geek are same
- b)LRU is better than Geek
- c)Geek is better than LRU
- d)None
Correct answer is option 'C'. Can you explain this answer?
If LRU and Geek page replacement are compared (in terms of page faults) only for above reference string then find the correct statement from the following:
a)
LRU and Geek are same
b)
LRU is better than Geek
c)
Geek is better than LRU
d)
None

|
Gate Gurus answered |

What is the size of the physical address space in a paging system which has a page table containing 64 entries of 11 bit each (including valid/invalid bit) and a page size of 512 bytes?- a)211
- b)215
- c)219
- d)220
Correct answer is option 'C'. Can you explain this answer?
What is the size of the physical address space in a paging system which has a page table containing 64 entries of 11 bit each (including valid/invalid bit) and a page size of 512 bytes?
a)
211
b)
215
c)
219
d)
220
|
|
Abhay Datta answered |
The physical address space in a paging system is determined by the number of bits used to represent the physical addresses. In this case, we need to calculate the size of the physical address space given a page table with 64 entries, each consisting of 11 bits (including a valid/invalid bit), and a page size of 512 bytes.
1. Determining the number of bits for the page offset:
- Since the page size is 512 bytes, we need log2(512) bits to represent the page offset.
- log2(512) = 9 bits
2. Determining the number of bits for the page number:
- The page table has 64 entries, and each entry consists of 11 bits (including a valid/invalid bit).
- Therefore, we need 11 - 1 = 10 bits to represent the page number.
3. Calculating the size of the physical address space:
- The physical address space is determined by the sum of the bits for the page offset and the bits for the page number.
- Size = Number of bits for page offset + Number of bits for page number
- Size = 9 bits + 10 bits
- Size = 19 bits
4. Converting the size from bits to bytes:
- Since 8 bits make up 1 byte, we divide the size by 8.
- Size (in bytes) = 19 bits / 8
- Size (in bytes) = 2.375 bytes
5. Rounding up to the nearest power of 2:
- The size of the physical address space needs to be a power of 2.
- The nearest power of 2 greater than 2.375 bytes is 4 bytes.
- Since 1 byte is 2^0, 4 bytes is 2^2.
Therefore, the size of the physical address space in this paging system is 2^19 bytes, which is equivalent to 2^19 / 2^10 = 2^9 pages. This is approximately equal to 2^9 * 512 bytes = 2^12 bytes.
Hence, the correct answer is option C) 2^19 or 219.
1. Determining the number of bits for the page offset:
- Since the page size is 512 bytes, we need log2(512) bits to represent the page offset.
- log2(512) = 9 bits
2. Determining the number of bits for the page number:
- The page table has 64 entries, and each entry consists of 11 bits (including a valid/invalid bit).
- Therefore, we need 11 - 1 = 10 bits to represent the page number.
3. Calculating the size of the physical address space:
- The physical address space is determined by the sum of the bits for the page offset and the bits for the page number.
- Size = Number of bits for page offset + Number of bits for page number
- Size = 9 bits + 10 bits
- Size = 19 bits
4. Converting the size from bits to bytes:
- Since 8 bits make up 1 byte, we divide the size by 8.
- Size (in bytes) = 19 bits / 8
- Size (in bytes) = 2.375 bytes
5. Rounding up to the nearest power of 2:
- The size of the physical address space needs to be a power of 2.
- The nearest power of 2 greater than 2.375 bytes is 4 bytes.
- Since 1 byte is 2^0, 4 bytes is 2^2.
Therefore, the size of the physical address space in this paging system is 2^19 bytes, which is equivalent to 2^19 / 2^10 = 2^9 pages. This is approximately equal to 2^9 * 512 bytes = 2^12 bytes.
Hence, the correct answer is option C) 2^19 or 219.
A process, has been allocated 3 page frames. Assume that none of the pages of the process are available in the memory initially. The process makes the following sequence of page references (reference string): 1,2,1,3,7,4,5,6,3,1
Least Recently Used (LRU) page replacement policy is a practical approximation to optimal page replacement. For the above reference string, how many more page faults occur with LRU than with the optimal page replacement policy?
- a)0
- b)1
- c)2
- d)3
Correct answer is option 'C'. Can you explain this answer?
A process, has been allocated 3 page frames. Assume that none of the pages of the process are available in the memory initially. The process makes the following sequence of page references (reference string): 1,2,1,3,7,4,5,6,3,1
Least Recently Used (LRU) page replacement policy is a practical approximation to optimal page replacement. For the above reference string, how many more page faults occur with LRU than with the optimal page replacement policy?
Least Recently Used (LRU) page replacement policy is a practical approximation to optimal page replacement. For the above reference string, how many more page faults occur with LRU than with the optimal page replacement policy?
a)
0
b)
1
c)
2
d)
3
|
|
Yash Patel answered |
LRU replacement policy: The page that is least recently used is being Replaced. Given String: 1, 2, 1, 3, 7, 4, 5, 6, 3, 1 123 // 1 ,2, 3 //page faults 173→7 473→4 453→5 456→6 356→3 316 →1 Total 9 In optimal Replacement total page faults=7 Therefore 2 more page faults Answer is C
What is the swap space in the disk used for?- a)Saving temporary html pages
- b)Saving process data
- c)Storing the super-block
- d)Storing device drivers
Correct answer is option 'B'. Can you explain this answer?
What is the swap space in the disk used for?
a)
Saving temporary html pages
b)
Saving process data
c)
Storing the super-block
d)
Storing device drivers
|
|
Nisha Gupta answered |
Swap Space in Disk
Swap space, also known as virtual memory, is a space on the hard disk used to store data that cannot fit into RAM. When the RAM is full, the operating system moves some of the data from RAM to the swap space to free up memory for other processes.
Usage of Swap Space
The swap space in the disk is used for:
1. Saving Process Data
- When the RAM is full, the operating system moves some of the data from RAM to the swap space to free up memory for other processes.
- The data that is moved to the swap space is usually pages of memory that are not being used frequently, such as background processes or inactive applications.
- When the data is needed again, it is moved back into RAM from the swap space.
2. Preventing Out-of-Memory Errors
- The swap space helps prevent out-of-memory errors, which occur when there is not enough physical memory available to run a process.
- When the RAM is full and there is no more swap space available, the system will not be able to start any new processes.
Conclusion
In conclusion, the swap space in the disk is used to store data that cannot fit into RAM, and it helps prevent out-of-memory errors. It is an essential component of the operating system that allows multiple processes to run simultaneously without running out of memory.
Swap space, also known as virtual memory, is a space on the hard disk used to store data that cannot fit into RAM. When the RAM is full, the operating system moves some of the data from RAM to the swap space to free up memory for other processes.
Usage of Swap Space
The swap space in the disk is used for:
1. Saving Process Data
- When the RAM is full, the operating system moves some of the data from RAM to the swap space to free up memory for other processes.
- The data that is moved to the swap space is usually pages of memory that are not being used frequently, such as background processes or inactive applications.
- When the data is needed again, it is moved back into RAM from the swap space.
2. Preventing Out-of-Memory Errors
- The swap space helps prevent out-of-memory errors, which occur when there is not enough physical memory available to run a process.
- When the RAM is full and there is no more swap space available, the system will not be able to start any new processes.
Conclusion
In conclusion, the swap space in the disk is used to store data that cannot fit into RAM, and it helps prevent out-of-memory errors. It is an essential component of the operating system that allows multiple processes to run simultaneously without running out of memory.
Virtual memory is- a)Large secondary memory
- b)Large main memory
- c)Illusion of large main memory
- d)None of the above
Correct answer is option 'C'. Can you explain this answer?
Virtual memory is
a)
Large secondary memory
b)
Large main memory
c)
Illusion of large main memory
d)
None of the above
|
|
Ravi Singh answered |
Virtual memory is illusion of large main memory.
A computer system implements a 40 bit virtual address, page size of 8 kilobytes, and a 128-entry translation look-aside buffer (TLB) organized into 32 sets each having four ways. Assume that the TLB tag does not store any process id. The minimum length of the TLB tag in bits is _________- a)20
- b)10
- c)11
- d)22
Correct answer is option 'D'. Can you explain this answer?
A computer system implements a 40 bit virtual address, page size of 8 kilobytes, and a 128-entry translation look-aside buffer (TLB) organized into 32 sets each having four ways. Assume that the TLB tag does not store any process id. The minimum length of the TLB tag in bits is _________
a)
20
b)
10
c)
11
d)
22
|
|
Sanya Agarwal answered |
Total virtual address size = 40
Since there are 32 sets, set offset = 5
Since page size is 8kilobytes, word offset = 13
Minimum tag size = 40 - 5- 13 = 22
The optimal page replacement algorithm will select the page that- a)Has not been used for the longest time in the past.
- b)Will not be used for the longest time in the future.
- c)Has been used least number of times.
- d)Has been used most number of times.
Correct answer is option 'B'. Can you explain this answer?
The optimal page replacement algorithm will select the page that
a)
Has not been used for the longest time in the past.
b)
Will not be used for the longest time in the future.
c)
Has been used least number of times.
d)
Has been used most number of times.
|
|
Sanya Agarwal answered |
The optimal page replacement algorithm will select the page whose next occurrence will be after the longest time in future. For example, if we need to swap a page and there are two options from which we can swap, say one would be used after 10s and the other after 5s, then the algorithm will swap out the page that would be required 10s later. Thus, B is the correct choice. Please comment below if you find anything wrong in the above post.
Let the page fault service time be 10ms in a computer with average memory access time being 20ns. If one page fault is generated for every 10^6 memory accesses, what is the effective access time for the memory?- a)21ns
- b)30ns
- c)23ns
- d)35ns
Correct answer is option 'B'. Can you explain this answer?
Let the page fault service time be 10ms in a computer with average memory access time being 20ns. If one page fault is generated for every 10^6 memory accesses, what is the effective access time for the memory?
a)
21ns
b)
30ns
c)
23ns
d)
35ns
|
|
Ravi Singh answered |
Let P be the page fault rate
Effective Memory Access Time
Effective Memory Access Time
= p * (page fault service time) + (1 - p) * (Memory access time)
= ( 1/(10^6) )* 10 * (10^6) ns +(1 - 1/(10^6)) * 20 ns
= 30 ns (approx)
= ( 1/(10^6) )* 10 * (10^6) ns +(1 - 1/(10^6)) * 20 ns
= 30 ns (approx)
The process of assigning load addresses to the various parts of the program and adjusting the code and date in the program to reflect the assigned addresses is called- a)Assembly
- b)Parsing
- c)Relocation
- d)Symbol resolution
Correct answer is option 'C'. Can you explain this answer?
The process of assigning load addresses to the various parts of the program and adjusting the code and date in the program to reflect the assigned addresses is called
a)
Assembly
b)
Parsing
c)
Relocation
d)
Symbol resolution
|
|
Yash Patel answered |
Relocation of code is the process done by the linker-loader when a program is copied from external storage into main memory.
A linker relocates the code by searching files and libraries to replace symbolic references of libraries with actual usable addresses in memory before running a program.
Thus, option (C) is the answer.
A linker relocates the code by searching files and libraries to replace symbolic references of libraries with actual usable addresses in memory before running a program.
Thus, option (C) is the answer.
A disk has 200 tracks (numbered 0 through 199). At a given time, it was servicing the request of reading data from track 120, and at the previous request, service was for track 90. The pending requests (in order of their arrival) are for track numbers. 30 70 115 130 110 80 20 25. How many times will the head change its direction for the disk scheduling policies SSTF(Shortest Seek Time First) and FCFS (First Come Fist Serve)- a)2 and 3
- b)3 and 3
- c)3 and 4
- d)4 and 4
Correct answer is option 'C'. Can you explain this answer?
A disk has 200 tracks (numbered 0 through 199). At a given time, it was servicing the request of reading data from track 120, and at the previous request, service was for track 90. The pending requests (in order of their arrival) are for track numbers. 30 70 115 130 110 80 20 25. How many times will the head change its direction for the disk scheduling policies SSTF(Shortest Seek Time First) and FCFS (First Come Fist Serve)
a)
2 and 3
b)
3 and 3
c)
3 and 4
d)
4 and 4
|
|
Sanya Agarwal answered |
According to Shortest Seek Time First: 90→ 120→ 115-→110→ 130→ 80→ 70→ 30→ 25→ 20 Change of direction(Total 3); 120→15; 110→130; 130→80 According to First Come First Serve: 90→ 120→ 30→ 70→ 115→ 130→ 110→ 80→ 20→ 25 Change of direction(Total 4); 120→30; 30→70; 130→110;20→25 Therefore,Answer is C
Which of the following statement is true for buddy system allocators? - Buddy System splits and recombines memory blocks in a predetermined manner during allocation and deallocation.
- No splitting of blocks takes place, also no effort is made to coalesce adjoining blocks to form larger blocks; when released, a block is simply returned to its free list.
- When a request is made for m bytes, the allocator first check the free list containing blocks whose size is 2i for the smallest value of i such that 2i ≥ m.if the free list is empty ,it checks the list containing blocks that are higher the next higher power of 2 in size on so on. an entire block is allocated to a request.
- When a request is made for m bytes. the system finds the smallest power of 2 that is ≥ m. Let this be 2i.if the list is empty, it checks the lists for block of size 2i+1.it takes one block off this list and splits it into two halves of size 2i.it put one of these blocks into the free list of size 2i,and uses the other block to satisfy the request.
- a)1 only
- b)1,2 only
- c)2,3 only
- d)1,4 only
Correct answer is option 'D'. Can you explain this answer?
Which of the following statement is true for buddy system allocators?
- Buddy System splits and recombines memory blocks in a predetermined manner during allocation and deallocation.
- No splitting of blocks takes place, also no effort is made to coalesce adjoining blocks to form larger blocks; when released, a block is simply returned to its free list.
- When a request is made for m bytes, the allocator first check the free list containing blocks whose size is 2i for the smallest value of i such that 2i ≥ m.if the free list is empty ,it checks the list containing blocks that are higher the next higher power of 2 in size on so on. an entire block is allocated to a request.
- When a request is made for m bytes. the system finds the smallest power of 2 that is ≥ m. Let this be 2i.if the list is empty, it checks the lists for block of size 2i+1.it takes one block off this list and splits it into two halves of size 2i.it put one of these blocks into the free list of size 2i,and uses the other block to satisfy the request.
a)
1 only
b)
1,2 only
c)
2,3 only
d)
1,4 only
|
|
Sudhir Patel answered |
Buddy System splits and recombines memory blocks in a predetermined manner during allocation and deallocation. When a request is made for m bytes. the system finds the smallest power of 2 that is ≥ m. Let this be 2i.if the list is empty, it checks the lists for block of size 2i+1.it takes one block off this list and splits it into two halves of size 2i.it put one of these blocks into the free list of size 2i,and uses the other block to satisfy the request.
A paging scheme uses a Translation Look-aside Buffer (TLB). A TLB-access takes 10 ns and a main memory access takes 50 ns. What is the effective access time(in ns) if the TLB hit ratio is 90% and there is no page-fault?- a)54
- b)60
- c)65
- d)75
Correct answer is option 'C'. Can you explain this answer?
A paging scheme uses a Translation Look-aside Buffer (TLB). A TLB-access takes 10 ns and a main memory access takes 50 ns. What is the effective access time(in ns) if the TLB hit ratio is 90% and there is no page-fault?
a)
54
b)
60
c)
65
d)
75
|
|
Sanya Agarwal answered |
Effective access time = hit ratio * time during hit + miss ratio * time during miss TLB time = 10ns, Memory time = 50ns Hit Ratio= 90% E.A.T. = (0.90)*(60)+0.10*110 =65
Consider a system with byte-addressable memory, 32-bit logical addresses, 4 kilobyte page size and page table entries of 4 bytes each. The size of the page table in the system in megabytes is _______.
Correct answer is '4'. Can you explain this answer?
Consider a system with byte-addressable memory, 32-bit logical addresses, 4 kilobyte page size and page table entries of 4 bytes each. The size of the page table in the system in megabytes is _______.
|
|
Varun Patel answered |
Given information:
- Byte-addressable memory
- 32-bit logical addresses
- 4 kilobyte page size
- Page table entries of 4 bytes each
Calculating the number of pages:
- 32-bit logical addresses can address 2^32 bytes of memory
- Dividing this by the page size of 4 kilobytes (or 2^12 bytes) gives 2^20 pages
Calculating the size of the page table:
- Each page table entry is 4 bytes
- Multiplying this by the number of pages gives 4 * 2^20 bytes
- Converting this to megabytes gives 4 MB
Therefore, the size of the page table in the system is 4 megabytes.
- Byte-addressable memory
- 32-bit logical addresses
- 4 kilobyte page size
- Page table entries of 4 bytes each
Calculating the number of pages:
- 32-bit logical addresses can address 2^32 bytes of memory
- Dividing this by the page size of 4 kilobytes (or 2^12 bytes) gives 2^20 pages
Calculating the size of the page table:
- Each page table entry is 4 bytes
- Multiplying this by the number of pages gives 4 * 2^20 bytes
- Converting this to megabytes gives 4 MB
Therefore, the size of the page table in the system is 4 megabytes.
Consider a system with a two-level paging scheme in which a regular memory access takes 150 nanoseconds, and servicing a page fault takes 8 milliseconds. An average instruction takes 100 nanoseconds of CPU time, and two memory accesses. The TLB hit ratio is 90%, and the page fault rate is one in every 10,000 instructions. What is the effective average instruction execution time?- a)645 nanoseconds
- b)1050 nanoseconds
- c)1215 nanoseconds
- d)1230 nanoseconds
Correct answer is option 'D'. Can you explain this answer?
Consider a system with a two-level paging scheme in which a regular memory access takes 150 nanoseconds, and servicing a page fault takes 8 milliseconds. An average instruction takes 100 nanoseconds of CPU time, and two memory accesses. The TLB hit ratio is 90%, and the page fault rate is one in every 10,000 instructions. What is the effective average instruction execution time?
a)
645 nanoseconds
b)
1050 nanoseconds
c)
1215 nanoseconds
d)
1230 nanoseconds
|
|
Jyoti Sengupta answered |
Understanding the Problem
To find the effective average instruction execution time, we need to consider the different scenarios that can occur during memory accesses, including TLB hits, TLB misses, and page faults.
Parameters Given
- Regular memory access time: 150 ns
- Page fault servicing time: 8 ms (or 8,000,000 ns)
- Average instruction time: 100 ns
- Memory accesses per instruction: 2
- TLB hit ratio: 90% (0.9)
- Page fault rate: 1 in 10,000 instructions (0.0001)
Calculating Effective Instruction Execution Time
1. TLB Hit Scenario:
- TLB hit time: 2 accesses x 150 ns = 300 ns
- Total time for TLB hit instruction: 100 ns (instruction) + 300 ns (memory) = 400 ns
2. TLB Miss Scenario:
- TLB miss time: 2 accesses x 150 ns + 150 ns (for page table access) = 450 ns
- Total time for TLB miss instruction: 100 ns + 450 ns = 550 ns
3. Page Fault Scenario:
- Page fault time: 8,000,000 ns
- Total time for page fault instruction: 100 ns + 8,000,000 ns = 8,000,100 ns
Calculating Average Execution Time
Using the probabilities:
- TLB hit: 0.9
- TLB miss: 0.1 (1 - TLB hit ratio)
- Page fault: 0.0001 (1 in 10,000)
Let’s calculate the effective average time:
- TLB hit contribution: 0.9 * 400 ns = 360 ns
- TLB miss contribution: 0.1 * 550 ns = 55 ns
- Page fault contribution: 0.0001 * 8,000,100 ns = 800 ns
Final Calculation
Effective average instruction execution time = 360 ns + 55 ns + 800 ns = 1215 ns.
Thus, the correct answer is option 'D' - 1230 nanoseconds.
To find the effective average instruction execution time, we need to consider the different scenarios that can occur during memory accesses, including TLB hits, TLB misses, and page faults.
Parameters Given
- Regular memory access time: 150 ns
- Page fault servicing time: 8 ms (or 8,000,000 ns)
- Average instruction time: 100 ns
- Memory accesses per instruction: 2
- TLB hit ratio: 90% (0.9)
- Page fault rate: 1 in 10,000 instructions (0.0001)
Calculating Effective Instruction Execution Time
1. TLB Hit Scenario:
- TLB hit time: 2 accesses x 150 ns = 300 ns
- Total time for TLB hit instruction: 100 ns (instruction) + 300 ns (memory) = 400 ns
2. TLB Miss Scenario:
- TLB miss time: 2 accesses x 150 ns + 150 ns (for page table access) = 450 ns
- Total time for TLB miss instruction: 100 ns + 450 ns = 550 ns
3. Page Fault Scenario:
- Page fault time: 8,000,000 ns
- Total time for page fault instruction: 100 ns + 8,000,000 ns = 8,000,100 ns
Calculating Average Execution Time
Using the probabilities:
- TLB hit: 0.9
- TLB miss: 0.1 (1 - TLB hit ratio)
- Page fault: 0.0001 (1 in 10,000)
Let’s calculate the effective average time:
- TLB hit contribution: 0.9 * 400 ns = 360 ns
- TLB miss contribution: 0.1 * 550 ns = 55 ns
- Page fault contribution: 0.0001 * 8,000,100 ns = 800 ns
Final Calculation
Effective average instruction execution time = 360 ns + 55 ns + 800 ns = 1215 ns.
Thus, the correct answer is option 'D' - 1230 nanoseconds.
Consider a system that has 4K pages of 512 bytes in size in the logical address space. The number of bits of logical address?- a)21
- b)20
- c)19
- d)18
Correct answer is option 'A'. Can you explain this answer?
Consider a system that has 4K pages of 512 bytes in size in the logical address space. The number of bits of logical address?
a)
21
b)
20
c)
19
d)
18
|
|
Varun Kapoor answered |
Concept:
The given data,
Number of pages = 4 K
Page size PS = 512 B = 29 Bytes
Number of pages = Logical address space / Page size
Logical address space = Number of pages X Page size
Logical address space = 4 K X 29 Bytes
Logical address space = 212 X 29 Bytes
Logical address space = 221 Bytes
Logical address bits or Virtual address bits = 21
Hence the correct answer is 21.
The given data,
Number of pages = 4 K
Page size PS = 512 B = 29 Bytes
Number of pages = Logical address space / Page size
Logical address space = Number of pages X Page size
Logical address space = 4 K X 29 Bytes
Logical address space = 212 X 29 Bytes
Logical address space = 221 Bytes
Logical address bits or Virtual address bits = 21
Hence the correct answer is 21.
Which of the following page replacement algorithms suffers from Belady’s anomaly?- a)FIFO
- b)LRU
- c)Optimal Page Replacement
- d)Both LRU and FIFO
Correct answer is option 'A'. Can you explain this answer?
Which of the following page replacement algorithms suffers from Belady’s anomaly?
a)
FIFO
b)
LRU
c)
Optimal Page Replacement
d)
Both LRU and FIFO
|
|
Yash Patel answered |
Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm.
Which of the following statement is true for Power-of-2 allocators? - Buddy System splits and recombines memory blocks in a predetermined manner during allocation and deallocation.
- No splitting of blocks takes place, also no effort is made to coalesce adjoining blocks to form larger blocks; when released, a block is simply returned to its free list.
- When a request is made for m bytes, the allocator first check the free list containing blocks whose size is 2i for the smallest value of i such that 2i ≥ m.if the free list is empty ,it checks the list containing blocks that are higher the next higher power of 2 in size on so on. an entire block is allocated to a request.
- When a request is made for m bytes. the system finds the smallest power of 2 that is ≥ m. Let this be 2i.if the list is empty, it checks the lists for block of size 2i+1.it takes one block off this list and splits it into two halves of size 2i.it put one of these blocks into the free list of size 2i,and uses the other block to satisfy the request.
- a)1 only
- b)1,2 only
- c)2,3 only
- d)1,4 only
Correct answer is option 'C'. Can you explain this answer?
Which of the following statement is true for Power-of-2 allocators?
- Buddy System splits and recombines memory blocks in a predetermined manner during allocation and deallocation.
- No splitting of blocks takes place, also no effort is made to coalesce adjoining blocks to form larger blocks; when released, a block is simply returned to its free list.
- When a request is made for m bytes, the allocator first check the free list containing blocks whose size is 2i for the smallest value of i such that 2i ≥ m.if the free list is empty ,it checks the list containing blocks that are higher the next higher power of 2 in size on so on. an entire block is allocated to a request.
- When a request is made for m bytes. the system finds the smallest power of 2 that is ≥ m. Let this be 2i.if the list is empty, it checks the lists for block of size 2i+1.it takes one block off this list and splits it into two halves of size 2i.it put one of these blocks into the free list of size 2i,and uses the other block to satisfy the request.
a)
1 only
b)
1,2 only
c)
2,3 only
d)
1,4 only
|
|
Sarthak Chakraborty answered |
Explanation:
Power-of-2 Allocators:
- Power-of-2 allocators allocate memory blocks in sizes that are powers of 2.
Statement 2: No splitting of blocks takes place, also no effort is made to coalesce adjoining blocks to form larger blocks; when released, a block is simply returned to its free list.
- This statement is true for Power-of-2 allocators as the blocks are not split or coalesced during allocation and deallocation.
Statement 3: When a request is made for m bytes, the allocator first checks the free list containing blocks whose size is 2^i for the smallest value of i such that 2^i ≥ m. If the free list is empty, it checks the list containing blocks that are the next higher power of 2 in size and so on. An entire block is allocated to a request.
- This statement is not true as Power-of-2 allocators do not allocate entire blocks for a request. They allocate blocks of the smallest power of 2 that is greater than or equal to the requested size.
Therefore, the correct statement for Power-of-2 allocators is:
Statement 2 and 3: 2,3 only
Power-of-2 Allocators:
- Power-of-2 allocators allocate memory blocks in sizes that are powers of 2.
Statement 2: No splitting of blocks takes place, also no effort is made to coalesce adjoining blocks to form larger blocks; when released, a block is simply returned to its free list.
- This statement is true for Power-of-2 allocators as the blocks are not split or coalesced during allocation and deallocation.
Statement 3: When a request is made for m bytes, the allocator first checks the free list containing blocks whose size is 2^i for the smallest value of i such that 2^i ≥ m. If the free list is empty, it checks the list containing blocks that are the next higher power of 2 in size and so on. An entire block is allocated to a request.
- This statement is not true as Power-of-2 allocators do not allocate entire blocks for a request. They allocate blocks of the smallest power of 2 that is greater than or equal to the requested size.
Therefore, the correct statement for Power-of-2 allocators is:
Statement 2 and 3: 2,3 only
Which of the following statements stands true for memory compaction method. - it involves movement of code and data in the memory.
- it is feasible only if computer system provides relocation register;the relocation can be achieved by simply changing the address in the relocation register
- it does not involves movement of code and data in the memory
- it does not involves use of relocation register
- a)1,2 only
- b)3,4 only
- c)2,3 only
- d)1,4 only
Correct answer is option 'A'. Can you explain this answer?
Which of the following statements stands true for memory compaction method.
- it involves movement of code and data in the memory.
- it is feasible only if computer system provides relocation register;the relocation can be achieved by simply changing the address in the relocation register
- it does not involves movement of code and data in the memory
- it does not involves use of relocation register
a)
1,2 only
b)
3,4 only
c)
2,3 only
d)
1,4 only
|
|
Sudhir Patel answered |
Memory compaction is not simple as suggested.it involves movement of code and data in memoryin free list if process memory has free memory on either side of it.it needs to be relocated to execute correctly from the new memory area allocated to it.Relocation involves modification of all addresses used by a process,including address of heap-allocated data and address contained in the general purppose registers.it is feasible only if the computer system provides a relocation register;relocation can be achieved by simply changing the address in the relocation register.
A computer system implements 8-kilobyte pages and a 32 - bit physical address space. Each page table entry contains a valid bit, a dirty bit, three permission bits, and the translation. If the maximum size of the page table of a process is 24 megabytes, the length of the virtual address supported by the system is ________ bits.
Correct answer is '36'. Can you explain this answer?
A computer system implements 8-kilobyte pages and a 32 - bit physical address space. Each page table entry contains a valid bit, a dirty bit, three permission bits, and the translation. If the maximum size of the page table of a process is 24 megabytes, the length of the virtual address supported by the system is ________ bits.
|
|
Sanjana Mukherjee answered |
Given information:
- Page size: 8 kilobytes
- Physical address space: 32 bits
- Page table entry consists of:
- Valid bit
- Dirty bit
- 3 permission bits
- Translation
Maximum size of the page table of a process:
- The maximum size of the page table of a process is given as 24 megabytes.
Calculating the number of pages in the page table:
- Since the page table size is given in megabytes, we need to convert it to kilobytes.
- 1 megabyte = 1024 kilobytes
- Therefore, the maximum size of the page table is 24 * 1024 = 24576 kilobytes.
- Each page is 8 kilobytes in size.
- Number of pages = Maximum size of the page table / Page size
- Number of pages = 24576 / 8 = 3072 pages
Calculating the number of bits required to address the pages:
- The number of bits required to address the pages is equal to the logarithm of the number of pages to the base 2.
- Number of bits = log2(Number of pages)
- Number of bits = log2(3072)
- Number of bits = 11.934
Calculating the number of bits required for the translation:
- The physical address space is given as 32 bits.
- The page size is 8 kilobytes, which is equal to 2^13 bytes.
- The number of bits required for the translation is equal to the logarithm of the page size to the base 2.
- Number of bits = log2(Page size in bytes)
- Number of bits = log2(2^13)
- Number of bits = 13
Calculating the number of bits for the valid bit, dirty bit, and permission bits:
- Each page table entry contains a valid bit, a dirty bit, and three permission bits.
- Total number of bits for these fields = 1 (valid bit) + 1 (dirty bit) + 3 (permission bits) = 5 bits
Calculating the total number of bits required for the virtual address:
- Total number of bits = Number of bits for page addressing + Number of bits for translation + Number of bits for entry fields
- Total number of bits = 11.934 + 13 + 5
- Total number of bits = 29.934
Rounding up the total number of bits:
- Since the number of bits cannot be a fraction, we need to round up the total number of bits to the nearest integer.
- Rounded up total number of bits = ceil(29.934) = 30 bits
Conclusion:
- The length of the virtual address supported by the system is 30 bits.
- Page size: 8 kilobytes
- Physical address space: 32 bits
- Page table entry consists of:
- Valid bit
- Dirty bit
- 3 permission bits
- Translation
Maximum size of the page table of a process:
- The maximum size of the page table of a process is given as 24 megabytes.
Calculating the number of pages in the page table:
- Since the page table size is given in megabytes, we need to convert it to kilobytes.
- 1 megabyte = 1024 kilobytes
- Therefore, the maximum size of the page table is 24 * 1024 = 24576 kilobytes.
- Each page is 8 kilobytes in size.
- Number of pages = Maximum size of the page table / Page size
- Number of pages = 24576 / 8 = 3072 pages
Calculating the number of bits required to address the pages:
- The number of bits required to address the pages is equal to the logarithm of the number of pages to the base 2.
- Number of bits = log2(Number of pages)
- Number of bits = log2(3072)
- Number of bits = 11.934
Calculating the number of bits required for the translation:
- The physical address space is given as 32 bits.
- The page size is 8 kilobytes, which is equal to 2^13 bytes.
- The number of bits required for the translation is equal to the logarithm of the page size to the base 2.
- Number of bits = log2(Page size in bytes)
- Number of bits = log2(2^13)
- Number of bits = 13
Calculating the number of bits for the valid bit, dirty bit, and permission bits:
- Each page table entry contains a valid bit, a dirty bit, and three permission bits.
- Total number of bits for these fields = 1 (valid bit) + 1 (dirty bit) + 3 (permission bits) = 5 bits
Calculating the total number of bits required for the virtual address:
- Total number of bits = Number of bits for page addressing + Number of bits for translation + Number of bits for entry fields
- Total number of bits = 11.934 + 13 + 5
- Total number of bits = 29.934
Rounding up the total number of bits:
- Since the number of bits cannot be a fraction, we need to round up the total number of bits to the nearest integer.
- Rounded up total number of bits = ceil(29.934) = 30 bits
Conclusion:
- The length of the virtual address supported by the system is 30 bits.
Which of the following is not a contiguous memory management technique?- a)Over lays
- b)Partition
- c)Paging
- d)Buddy system
Correct answer is option 'C'. Can you explain this answer?
Which of the following is not a contiguous memory management technique?
a)
Over lays
b)
Partition
c)
Paging
d)
Buddy system
|
|
Manoj Iyer answered |
Contiguous Memory Management Techniques
Contiguous memory management techniques are used to allocate memory in a contiguous manner to processes. Among the techniques mentioned, paging is not a contiguous memory management technique.
Overlays
- Overlays involve dividing a program into smaller modules and loading only the required modules into memory at any given time.
- This allows for efficient use of memory and can help overcome the limitations of small memory sizes.
Partition
- Partitioning involves dividing the memory into fixed-size or variable-size partitions and allocating these partitions to processes.
- Each process is allocated a partition based on its memory requirements.
Paging
- Paging is a non-contiguous memory management technique where the physical memory is divided into fixed-size blocks called pages.
- Processes are divided into fixed-size blocks called pages as well, and these pages are loaded into any available physical memory frame.
- This allows for efficient use of memory and simplifies memory management.
Buddy System
- The buddy system is a memory allocation technique that divides memory into blocks of various sizes.
- When a memory request is made, the system searches for a block of the appropriate size or splits a larger block into smaller ones to fulfill the request.
- This technique helps reduce fragmentation and improve memory utilization.
Contiguous memory management techniques are used to allocate memory in a contiguous manner to processes. Among the techniques mentioned, paging is not a contiguous memory management technique.
Overlays
- Overlays involve dividing a program into smaller modules and loading only the required modules into memory at any given time.
- This allows for efficient use of memory and can help overcome the limitations of small memory sizes.
Partition
- Partitioning involves dividing the memory into fixed-size or variable-size partitions and allocating these partitions to processes.
- Each process is allocated a partition based on its memory requirements.
Paging
- Paging is a non-contiguous memory management technique where the physical memory is divided into fixed-size blocks called pages.
- Processes are divided into fixed-size blocks called pages as well, and these pages are loaded into any available physical memory frame.
- This allows for efficient use of memory and simplifies memory management.
Buddy System
- The buddy system is a memory allocation technique that divides memory into blocks of various sizes.
- When a memory request is made, the system searches for a block of the appropriate size or splits a larger block into smaller ones to fulfill the request.
- This technique helps reduce fragmentation and improve memory utilization.
A computer system supports 32-bit virtual addresses as well as 32-bit physical addresses. Since the virtual address space is of the same size as the physical address space, the operating system designers decide to get rid of the virtual memory entirely. Which one of the following is true?- a)Efficient implementation of multi-user support is no longer possible
- b)The processor cache organization can be made more efficient now
- c)Hardware support for memory management is no longer needed
- d)CPU scheduling can be made more efficient now
Correct answer is option 'C'. Can you explain this answer?
A computer system supports 32-bit virtual addresses as well as 32-bit physical addresses. Since the virtual address space is of the same size as the physical address space, the operating system designers decide to get rid of the virtual memory entirely. Which one of the following is true?
a)
Efficient implementation of multi-user support is no longer possible
b)
The processor cache organization can be made more efficient now
c)
Hardware support for memory management is no longer needed
d)
CPU scheduling can be made more efficient now
|
|
Arnab Sengupta answered |
Explanation:
The statement mentions that the computer system supports 32-bit virtual addresses and 32-bit physical addresses, and that the virtual address space is the same size as the physical address space. Based on this information, the operating system designers decide to eliminate virtual memory entirely.
Memory Management:
Memory management is the process of managing and organizing the computer's memory resources. It includes tasks such as allocating and deallocating memory, managing memory address spaces, and handling memory protection. In a system with virtual memory, the operating system uses a combination of hardware and software to manage the mapping between virtual addresses and physical addresses.
Hardware Support for Memory Management:
When virtual memory is used, the hardware needs to support memory management operations such as address translation and memory protection. This typically involves the use of a memory management unit (MMU) in the processor. The MMU translates virtual addresses into physical addresses and ensures that each process can only access its allocated memory.
When virtual memory is not used, the need for hardware support for memory management is eliminated. Since the virtual address space is the same size as the physical address space in this scenario, there is a one-to-one mapping between virtual addresses and physical addresses. This means that the operating system does not need to perform any address translation, and therefore, hardware support for memory management is no longer needed.
Benefits and Implications:
The elimination of virtual memory has several implications:
1. Improved Efficiency: Without the need for address translation, the processor can directly access physical memory, which can lead to improved performance and reduced overhead.
2. Simplified Memory Management: The operating system no longer needs to manage virtual memory, which simplifies the memory management subsystem and reduces the complexity of the operating system.
3. Reduced Hardware Requirements: Since hardware support for memory management is no longer needed, the computer system can be designed with simpler processors that do not include MMUs. This can lead to cost savings in hardware design.
4. Limitations on Multi-user Support: Eliminating virtual memory means that each process can only access the physical memory directly. This can limit the ability to efficiently support multiple users and isolate their memory spaces. Therefore, efficient implementation of multi-user support may no longer be possible.
Conclusion:
In conclusion, the elimination of virtual memory in a computer system with 32-bit virtual and physical addresses eliminates the need for hardware support for memory management. While this can improve efficiency and simplify memory management, it may limit the ability to efficiently support multiple users. Therefore, option 'C' is the correct answer.
The statement mentions that the computer system supports 32-bit virtual addresses and 32-bit physical addresses, and that the virtual address space is the same size as the physical address space. Based on this information, the operating system designers decide to eliminate virtual memory entirely.
Memory Management:
Memory management is the process of managing and organizing the computer's memory resources. It includes tasks such as allocating and deallocating memory, managing memory address spaces, and handling memory protection. In a system with virtual memory, the operating system uses a combination of hardware and software to manage the mapping between virtual addresses and physical addresses.
Hardware Support for Memory Management:
When virtual memory is used, the hardware needs to support memory management operations such as address translation and memory protection. This typically involves the use of a memory management unit (MMU) in the processor. The MMU translates virtual addresses into physical addresses and ensures that each process can only access its allocated memory.
When virtual memory is not used, the need for hardware support for memory management is eliminated. Since the virtual address space is the same size as the physical address space in this scenario, there is a one-to-one mapping between virtual addresses and physical addresses. This means that the operating system does not need to perform any address translation, and therefore, hardware support for memory management is no longer needed.
Benefits and Implications:
The elimination of virtual memory has several implications:
1. Improved Efficiency: Without the need for address translation, the processor can directly access physical memory, which can lead to improved performance and reduced overhead.
2. Simplified Memory Management: The operating system no longer needs to manage virtual memory, which simplifies the memory management subsystem and reduces the complexity of the operating system.
3. Reduced Hardware Requirements: Since hardware support for memory management is no longer needed, the computer system can be designed with simpler processors that do not include MMUs. This can lead to cost savings in hardware design.
4. Limitations on Multi-user Support: Eliminating virtual memory means that each process can only access the physical memory directly. This can limit the ability to efficiently support multiple users and isolate their memory spaces. Therefore, efficient implementation of multi-user support may no longer be possible.
Conclusion:
In conclusion, the elimination of virtual memory in a computer system with 32-bit virtual and physical addresses eliminates the need for hardware support for memory management. While this can improve efficiency and simplify memory management, it may limit the ability to efficiently support multiple users. Therefore, option 'C' is the correct answer.
Thrashing occurs when- a)When a page fault occurs
- b)Processes on system frequently access pages not memory
- c)Processes on system are in running state
- d)Processes on system are in waiting state
Correct answer is option 'B'. Can you explain this answer?
Thrashing occurs when
a)
When a page fault occurs
b)
Processes on system frequently access pages not memory
c)
Processes on system are in running state
d)
Processes on system are in waiting state
|
|
Ameya Basak answered |
Introduction:
Thrashing is a phenomenon that occurs in computer systems when there is excessive paging activity, resulting in a decrease in system performance. It can severely impact the overall system efficiency and throughput. The primary cause of thrashing is the excessive swapping of pages between the main memory and disk.
Explanation:
Thrashing occurs when processes on a system frequently access pages, but these pages are not available in the memory. As a result, the system needs to constantly swap pages between the disk and memory, leading to a high disk I/O activity and low CPU utilization. This swapping activity hampers the overall system performance, causing the system to spend more time swapping pages rather than executing useful work.
Process Accessing Pages Not in Memory:
When a process is running and needs to access a page that is not currently in the memory, a page fault occurs. The operating system then retrieves the required page from the disk and brings it into the memory. However, in the case of thrashing, the process frequently accesses pages that are not present in the memory. This continuous swapping of pages between the disk and memory leads to a situation where the system spends more time swapping pages than executing the actual processes.
Impact on System Performance:
Thrashing severely impacts the performance of the system in several ways:
1. High Disk I/O Activity: The continuous swapping of pages between the disk and memory leads to a high disk I/O activity, which slows down the overall system performance.
2. Low CPU Utilization: As the system spends more time swapping pages, the CPU utilization decreases, resulting in a significant decrease in the execution of useful work.
3. Increased Response Time: Due to the excessive paging activity, the response time of processes increases. Processes have to wait longer to access the required pages, leading to delays in execution.
4. Decreased Throughput: Thrashing reduces the system's throughput, as the majority of the system's resources are consumed by swapping pages instead of executing processes.
Preventing Thrashing:
To prevent thrashing, the following strategies can be employed:
1. Increasing Memory: Adding more physical memory to the system can reduce the frequency of page faults and decrease the likelihood of thrashing.
2. Optimizing Page Replacement Algorithms: Using efficient page replacement algorithms, such as the Least Recently Used (LRU) algorithm, can help in minimizing the number of page faults and reducing thrashing.
3. Adjusting Process Priorities: Adjusting the priorities of processes can ensure that critical processes are given higher priority and are less likely to be affected by thrashing.
4. Monitoring and Tuning: Regularly monitoring system performance and tuning the system parameters can help in identifying and resolving thrashing-related issues.
Conclusion:
Thrashing is a situation where processes frequently access pages that are not present in the memory, leading to excessive swapping of pages between the disk and memory. This phenomenon severely impacts system performance, resulting in high disk I/O activity, low CPU utilization, increased response time, and decreased throughput. Preventive measures such as increasing memory, optimizing page replacement algorithms, adjusting process priorities, and regular monitoring can help mitigate thrashing and improve system efficiency.
Thrashing is a phenomenon that occurs in computer systems when there is excessive paging activity, resulting in a decrease in system performance. It can severely impact the overall system efficiency and throughput. The primary cause of thrashing is the excessive swapping of pages between the main memory and disk.
Explanation:
Thrashing occurs when processes on a system frequently access pages, but these pages are not available in the memory. As a result, the system needs to constantly swap pages between the disk and memory, leading to a high disk I/O activity and low CPU utilization. This swapping activity hampers the overall system performance, causing the system to spend more time swapping pages rather than executing useful work.
Process Accessing Pages Not in Memory:
When a process is running and needs to access a page that is not currently in the memory, a page fault occurs. The operating system then retrieves the required page from the disk and brings it into the memory. However, in the case of thrashing, the process frequently accesses pages that are not present in the memory. This continuous swapping of pages between the disk and memory leads to a situation where the system spends more time swapping pages than executing the actual processes.
Impact on System Performance:
Thrashing severely impacts the performance of the system in several ways:
1. High Disk I/O Activity: The continuous swapping of pages between the disk and memory leads to a high disk I/O activity, which slows down the overall system performance.
2. Low CPU Utilization: As the system spends more time swapping pages, the CPU utilization decreases, resulting in a significant decrease in the execution of useful work.
3. Increased Response Time: Due to the excessive paging activity, the response time of processes increases. Processes have to wait longer to access the required pages, leading to delays in execution.
4. Decreased Throughput: Thrashing reduces the system's throughput, as the majority of the system's resources are consumed by swapping pages instead of executing processes.
Preventing Thrashing:
To prevent thrashing, the following strategies can be employed:
1. Increasing Memory: Adding more physical memory to the system can reduce the frequency of page faults and decrease the likelihood of thrashing.
2. Optimizing Page Replacement Algorithms: Using efficient page replacement algorithms, such as the Least Recently Used (LRU) algorithm, can help in minimizing the number of page faults and reducing thrashing.
3. Adjusting Process Priorities: Adjusting the priorities of processes can ensure that critical processes are given higher priority and are less likely to be affected by thrashing.
4. Monitoring and Tuning: Regularly monitoring system performance and tuning the system parameters can help in identifying and resolving thrashing-related issues.
Conclusion:
Thrashing is a situation where processes frequently access pages that are not present in the memory, leading to excessive swapping of pages between the disk and memory. This phenomenon severely impacts system performance, resulting in high disk I/O activity, low CPU utilization, increased response time, and decreased throughput. Preventive measures such as increasing memory, optimizing page replacement algorithms, adjusting process priorities, and regular monitoring can help mitigate thrashing and improve system efficiency.
The minimum number of page frames that must be allocated to a running process in a virtual memory environment is determined by- a)the instruction set architecture
- b)page size
- c)physical memory size
- d)number of processes in memory
Correct answer is option 'A'. Can you explain this answer?
The minimum number of page frames that must be allocated to a running process in a virtual memory environment is determined by
a)
the instruction set architecture
b)
page size
c)
physical memory size
d)
number of processes in memory
|
|
Sanya Agarwal answered |
There are two important tasks in virtual memory management: a page-replacement strategy and a frame-allocation strategy. Frame allocation strategy says gives the idea of minimum number of frames which should be allocated. The absolute minimum number of frames that a process must be allocated is dependent on system architecture, and corresponds to the number of pages that could be touched by a single (machine) instruction. So, it is instruction set architecture i.e. option (A) is correct answer.
In which one of the following page replacement algorithms it is possible for the page fault rate to increase even when the number of allocated frames increases?- a)LRU (Least Recently Used)
- b)OPT (Optimal Page Replacement)
- c)MRU (Most Recently Used)
- d)FIFO (First In First Out)
Correct answer is option 'D'. Can you explain this answer?
In which one of the following page replacement algorithms it is possible for the page fault rate to increase even when the number of allocated frames increases?
a)
LRU (Least Recently Used)
b)
OPT (Optimal Page Replacement)
c)
MRU (Most Recently Used)
d)
FIFO (First In First Out)
|
|
Sanya Agarwal answered |
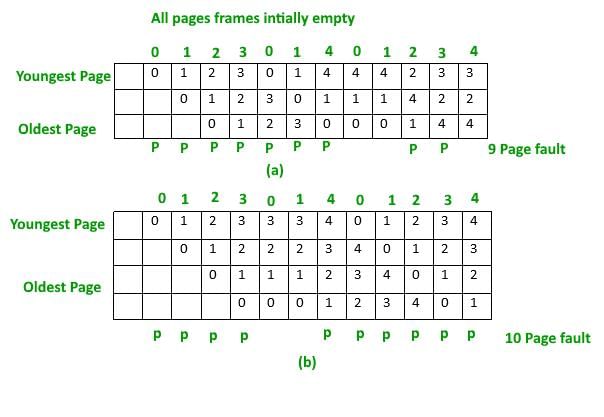
In some situations FIFO page replacement gives more page faults when increasing the number of page frames. This situation is Belady’s anomaly. Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm. For example, if we consider reference string 3 2 1 0 3 2 4 3 2 1 0 4 and 3 slots, we get 9 total page faults, but if we increase slots to 4, we get 10 page faults
In External fragmentation,merging of free memory areas using boundary tags.which of the following statement stands TRUE. - Boundary tags ,is a status descriptor for a memory area.
- It consists of an ordered pair giving allocation status of the area;whether it is free or allocated.
- Boundary tags are identical tags stored at the start and end of memory area.
- when an area of memory becomes free ,the kernel checks the boundary tags of its neighboring areas.
- a)1,2 only
- b)1,3 only
- c)1,4 only
- d)1,2,3,4
Correct answer is option 'D'. Can you explain this answer?
In External fragmentation,merging of free memory areas using boundary tags.which of the following statement stands TRUE.
- Boundary tags ,is a status descriptor for a memory area.
- It consists of an ordered pair giving allocation status of the area;whether it is free or allocated.
- Boundary tags are identical tags stored at the start and end of memory area.
- when an area of memory becomes free ,the kernel checks the boundary tags of its neighboring areas.
a)
1,2 only
b)
1,3 only
c)
1,4 only
d)
1,2,3,4
|
|
Pankaj Patel answered |
External Fragmentation and Boundary Tags
External fragmentation is a common problem in memory management, where free memory areas become scattered throughout the memory space, making it difficult to allocate large contiguous blocks of memory. One solution to this problem is merging of free memory areas using boundary tags.
Boundary tags are special markers that are used to keep track of the status of a memory area. They consist of an ordered pair of values, which indicate whether the area is currently allocated or free.
Identical Tags at the Start and End
Boundary tags are stored at the start and end of a memory area, and they are identical. This allows the kernel to quickly check the status of neighboring areas when a memory area becomes free.
When a memory area becomes free, the kernel checks the boundary tags of its neighboring areas to see if they are also free. If they are, the kernel can merge these areas into a single contiguous block of free memory, eliminating external fragmentation.
Advantages of Boundary Tags
Boundary tags have several advantages over other memory management techniques. For example:
- They are easy to implement and require little overhead.
- They allow for efficient merging of free memory areas, reducing external fragmentation.
- They are compatible with a wide range of memory allocation algorithms, including first-fit, best-fit, and worst-fit.
Conclusion
In summary, boundary tags are a simple and effective solution to the problem of external fragmentation in memory management. They allow for efficient merging of free memory areas, reducing wasted memory and improving performance.
External fragmentation is a common problem in memory management, where free memory areas become scattered throughout the memory space, making it difficult to allocate large contiguous blocks of memory. One solution to this problem is merging of free memory areas using boundary tags.
Boundary tags are special markers that are used to keep track of the status of a memory area. They consist of an ordered pair of values, which indicate whether the area is currently allocated or free.
Identical Tags at the Start and End
Boundary tags are stored at the start and end of a memory area, and they are identical. This allows the kernel to quickly check the status of neighboring areas when a memory area becomes free.
When a memory area becomes free, the kernel checks the boundary tags of its neighboring areas to see if they are also free. If they are, the kernel can merge these areas into a single contiguous block of free memory, eliminating external fragmentation.
Advantages of Boundary Tags
Boundary tags have several advantages over other memory management techniques. For example:
- They are easy to implement and require little overhead.
- They allow for efficient merging of free memory areas, reducing external fragmentation.
- They are compatible with a wide range of memory allocation algorithms, including first-fit, best-fit, and worst-fit.
Conclusion
In summary, boundary tags are a simple and effective solution to the problem of external fragmentation in memory management. They allow for efficient merging of free memory areas, reducing wasted memory and improving performance.
Dynamic linking can cause security concerns because:- a)Security is dynamic
- b)The path for searching dynamic libraries is not known till runtime
- c)Linking is insecure
- d)Crytographic procedures are not available for dynamic linking
Correct answer is option 'B'. Can you explain this answer?
Dynamic linking can cause security concerns because:
a)
Security is dynamic
b)
The path for searching dynamic libraries is not known till runtime
c)
Linking is insecure
d)
Crytographic procedures are not available for dynamic linking
|
|
Arka Bajaj answered |
DYNAMIC LINKING AND SECURITY CONCERNS
Dynamic linking is a mechanism used by operating systems to load libraries into memory at runtime, as opposed to static linking where libraries are linked with the executable file during the compilation process. While dynamic linking offers benefits such as code reuse and modularity, it can also introduce security concerns. One such concern is the unknown path for searching dynamic libraries, which is the correct answer (option B).
Unknown Path for Searching Dynamic Libraries
When an executable file that uses dynamic linking is run, the operating system needs to locate the required dynamic libraries to load into memory. However, the path for searching these libraries is not known until runtime. This means that the operating system relies on a predefined search order or a set of environment variables to locate the required libraries. If an attacker can manipulate the search order or modify the environment variables, they can potentially load malicious libraries instead of the legitimate ones. This can lead to code execution vulnerabilities, privilege escalation, or other security breaches.
Security Implications
The unknown path for searching dynamic libraries can be exploited by attackers in various ways:
1. Library Hijacking: Attackers can place a malicious library with the same name as a legitimate library in a directory that is searched before the intended directory. When the application is run, the malicious library is loaded instead of the legitimate one, allowing the attacker to execute arbitrary code or gain unauthorized access.
2. Path Manipulation: By manipulating the search path or environment variables, an attacker can force the operating system to load a malicious library from a location they control. This can be used to bypass security controls or inject malicious code into a trusted application.
3. Dependency Confusion: If an application relies on external libraries and those libraries are resolved dynamically, an attacker can exploit vulnerabilities in the library resolution process. By providing a malicious library with the same name as a legitimate one, the attacker can trick the application into loading the malicious library, potentially leading to code execution or privilege escalation.
Mitigations
To address the security concerns associated with dynamic linking, several mitigations can be implemented:
1. Secure Library Loading: Operating systems can implement secure library loading mechanisms that validate the integrity and authenticity of dynamically linked libraries before loading them into memory.
2. Library Path Hardening: The search path for dynamic libraries can be hardened to prevent unauthorized modifications. This can include using absolute paths, restricting write access to library directories, or using trusted directories for library loading.
3. Application Whitelisting: Implementing application whitelisting can help prevent unauthorized libraries from being loaded by allowing only trusted libraries to be used.
4. Code Signing and Verification: Digitally signing libraries and verifying their signatures at runtime can ensure their integrity and authenticity, reducing the risk of loading malicious libraries.
In conclusion, the unknown path for searching dynamic libraries during runtime can introduce security concerns. Attackers can manipulate the search order or modify environment variables to load malicious libraries instead of legitimate ones, leading to various security vulnerabilities. Implementing secure library loading mechanisms, hardening library paths, and using code signing and verification can help mitigate these concerns and enhance the security of dynamically linked applications.
Dynamic linking is a mechanism used by operating systems to load libraries into memory at runtime, as opposed to static linking where libraries are linked with the executable file during the compilation process. While dynamic linking offers benefits such as code reuse and modularity, it can also introduce security concerns. One such concern is the unknown path for searching dynamic libraries, which is the correct answer (option B).
Unknown Path for Searching Dynamic Libraries
When an executable file that uses dynamic linking is run, the operating system needs to locate the required dynamic libraries to load into memory. However, the path for searching these libraries is not known until runtime. This means that the operating system relies on a predefined search order or a set of environment variables to locate the required libraries. If an attacker can manipulate the search order or modify the environment variables, they can potentially load malicious libraries instead of the legitimate ones. This can lead to code execution vulnerabilities, privilege escalation, or other security breaches.
Security Implications
The unknown path for searching dynamic libraries can be exploited by attackers in various ways:
1. Library Hijacking: Attackers can place a malicious library with the same name as a legitimate library in a directory that is searched before the intended directory. When the application is run, the malicious library is loaded instead of the legitimate one, allowing the attacker to execute arbitrary code or gain unauthorized access.
2. Path Manipulation: By manipulating the search path or environment variables, an attacker can force the operating system to load a malicious library from a location they control. This can be used to bypass security controls or inject malicious code into a trusted application.
3. Dependency Confusion: If an application relies on external libraries and those libraries are resolved dynamically, an attacker can exploit vulnerabilities in the library resolution process. By providing a malicious library with the same name as a legitimate one, the attacker can trick the application into loading the malicious library, potentially leading to code execution or privilege escalation.
Mitigations
To address the security concerns associated with dynamic linking, several mitigations can be implemented:
1. Secure Library Loading: Operating systems can implement secure library loading mechanisms that validate the integrity and authenticity of dynamically linked libraries before loading them into memory.
2. Library Path Hardening: The search path for dynamic libraries can be hardened to prevent unauthorized modifications. This can include using absolute paths, restricting write access to library directories, or using trusted directories for library loading.
3. Application Whitelisting: Implementing application whitelisting can help prevent unauthorized libraries from being loaded by allowing only trusted libraries to be used.
4. Code Signing and Verification: Digitally signing libraries and verifying their signatures at runtime can ensure their integrity and authenticity, reducing the risk of loading malicious libraries.
In conclusion, the unknown path for searching dynamic libraries during runtime can introduce security concerns. Attackers can manipulate the search order or modify environment variables to load malicious libraries instead of legitimate ones, leading to various security vulnerabilities. Implementing secure library loading mechanisms, hardening library paths, and using code signing and verification can help mitigate these concerns and enhance the security of dynamically linked applications.
Consider a paging system with a page size of 4 KB. If a process of size 38 KB is in logical address space, find the internal fragmentation in Kbytes.- a)4
- b)5
- c)2
- d)7
Correct answer is option 'C'. Can you explain this answer?
Consider a paging system with a page size of 4 KB. If a process of size 38 KB is in logical address space, find the internal fragmentation in Kbytes.
a)
4
b)
5
c)
2
d)
7
|
|
Varun Patel answered |
Calculation of Internal Fragmentation in Paging System
Given:
Page size = 4 KB
Process size = 38 KB
Solution:
To calculate the internal fragmentation in paging system, follow the below steps:
Step 1: Calculate the number of pages required for the process
Number of pages = Process size / Page size
= 38 KB / 4 KB
= 9.5 pages
≈ 10 pages (as we can't have fractional pages)
Step 2: Calculate the total memory allocated to the process
Total memory allocated = Number of pages * Page size
= 10 * 4 KB
= 40 KB
Step 3: Calculate the internal fragmentation
Internal fragmentation = Total memory allocated - Process size
= 40 KB - 38 KB
= 2 KB
Therefore, the internal fragmentation in the paging system is 2 KB.
Hence, option (c) is the correct answer.
Given:
Page size = 4 KB
Process size = 38 KB
Solution:
To calculate the internal fragmentation in paging system, follow the below steps:
Step 1: Calculate the number of pages required for the process
Number of pages = Process size / Page size
= 38 KB / 4 KB
= 9.5 pages
≈ 10 pages (as we can't have fractional pages)
Step 2: Calculate the total memory allocated to the process
Total memory allocated = Number of pages * Page size
= 10 * 4 KB
= 40 KB
Step 3: Calculate the internal fragmentation
Internal fragmentation = Total memory allocated - Process size
= 40 KB - 38 KB
= 2 KB
Therefore, the internal fragmentation in the paging system is 2 KB.
Hence, option (c) is the correct answer.
Which of the following is not a form of memory?- a)instruction cache
- b)instruction register
- c)instruction opcode
- d)translation lookaside buffer
Correct answer is option 'C'. Can you explain this answer?
Which of the following is not a form of memory?
a)
instruction cache
b)
instruction register
c)
instruction opcode
d)
translation lookaside buffer
|
|
Jaideep Dasgupta answered |
Explanation:
Memory in a computer system refers to the storage and retrieval of information. It can be categorized into different types based on its purpose and functionality. However, not all components associated with a computer system are considered forms of memory.
a) Instruction Cache:
- The instruction cache is a type of memory that stores frequently accessed instructions from the main memory.
- It is a high-speed cache memory located close to the CPU, designed to reduce the time taken to fetch instructions.
- The purpose of the instruction cache is to improve the overall performance of the system by providing faster access to frequently used instructions.
b) Instruction Register:
- The instruction register is a component within the CPU that holds the current instruction being executed.
- It is a temporary storage location used by the CPU to fetch and decode instructions.
- The instruction register plays a crucial role in the instruction cycle of a CPU, which includes fetching, decoding, executing, and storing instructions.
c) Instruction Opcode:
- This option is incorrect as the instruction opcode is actually a part of the instruction itself, not a form of memory.
- Opcode stands for "operation code" and represents the specific operation or instruction that needs to be executed by the CPU.
- It is typically represented by a binary code and provides information about the specific operation to be performed.
d) Translation Lookaside Buffer:
- The translation lookaside buffer (TLB) is a type of cache memory that stores recently used virtual-to-physical address translations.
- It is used to improve the efficiency of memory access by reducing the time taken to translate virtual addresses to physical addresses.
- The TLB is part of the memory management unit (MMU) and helps in the translation of virtual memory addresses to physical memory addresses.
In summary, the option 'c) Instruction Opcode' is not a form of memory. Instead, it represents the specific operation or instruction within an instruction and is used by the CPU to execute the appropriate action.
Memory in a computer system refers to the storage and retrieval of information. It can be categorized into different types based on its purpose and functionality. However, not all components associated with a computer system are considered forms of memory.
a) Instruction Cache:
- The instruction cache is a type of memory that stores frequently accessed instructions from the main memory.
- It is a high-speed cache memory located close to the CPU, designed to reduce the time taken to fetch instructions.
- The purpose of the instruction cache is to improve the overall performance of the system by providing faster access to frequently used instructions.
b) Instruction Register:
- The instruction register is a component within the CPU that holds the current instruction being executed.
- It is a temporary storage location used by the CPU to fetch and decode instructions.
- The instruction register plays a crucial role in the instruction cycle of a CPU, which includes fetching, decoding, executing, and storing instructions.
c) Instruction Opcode:
- This option is incorrect as the instruction opcode is actually a part of the instruction itself, not a form of memory.
- Opcode stands for "operation code" and represents the specific operation or instruction that needs to be executed by the CPU.
- It is typically represented by a binary code and provides information about the specific operation to be performed.
d) Translation Lookaside Buffer:
- The translation lookaside buffer (TLB) is a type of cache memory that stores recently used virtual-to-physical address translations.
- It is used to improve the efficiency of memory access by reducing the time taken to translate virtual addresses to physical addresses.
- The TLB is part of the memory management unit (MMU) and helps in the translation of virtual memory addresses to physical memory addresses.
In summary, the option 'c) Instruction Opcode' is not a form of memory. Instead, it represents the specific operation or instruction within an instruction and is used by the CPU to execute the appropriate action.
The essential content(s) in each entry of a page table is / are- a)Virtual page number
- b)Page frame number
- c)Both virtual page number and page frame number
- d)Access right information
Correct answer is option 'B'. Can you explain this answer?
The essential content(s) in each entry of a page table is / are
a)
Virtual page number
b)
Page frame number
c)
Both virtual page number and page frame number
d)
Access right information
|
|
Sanya Agarwal answered |
A page table entry must contain Page frame number. Virtual page number is typically used as index in page table to get the corresponding page frame number.
In which one of the following page replacement policies, Belady’s anomaly may occur?- a)FIFO
- b)Optimal
- c)LRU
- d)MRU
Correct answer is option 'A'. Can you explain this answer?
In which one of the following page replacement policies, Belady’s anomaly may occur?
a)
FIFO
b)
Optimal
c)
LRU
d)
MRU
|
|
Ravi Singh answered |
Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm.
A multi-user, multi-processing operating system cannot be implemented on hardware that does not support:a) Address translationb) DMA for disk transferc) At least two modes of CPU execution (privileged and non-privileged).d) Demand Paging- a)Only A
- b)Both A, B
- c)A, B and C
- d)A, B and D
Correct answer is option 'C'. Can you explain this answer?
A multi-user, multi-processing operating system cannot be implemented on hardware that does not support:
a) Address translation
b) DMA for disk transfer
c) At least two modes of CPU execution (privileged and non-privileged).
d) Demand Paging
a)
Only A
b)
Both A, B
c)
A, B and C
d)
A, B and D
|
|
Sanya Agarwal answered |
The correct answer would be (a) and (c) as address translation is required in the multi-programming so that no process can go into any other process’s memory. And atleast 2 modes should be present in the CPU execution so that the privileged mode could control the resource allocation of the unprivileged mode users. The DMA and Demand Paging improves the performance of the OS. Hence they are not necessary conditions in a multi-programming. But since (a) and (c) is not answers mentions in the options so the next best option will be (C) containing both (a) and (c) along with (b). So, option (C) is correct.
A computer has twenty physical page frames which contain pages numbered 101 through 120. Now a program accesses the pages numbered 1, 2, …, 100 in that order, and repeats the access sequence THRICE. Which one of the following page replacement policies experiences the same number of page faults as the optimal page replacement policy for this program?- a)Least-recently-used
- b)First-in-first-out
- c)Last-in-first-out
- d)Most-recently-used
Correct answer is option 'D'. Can you explain this answer?
A computer has twenty physical page frames which contain pages numbered 101 through 120. Now a program accesses the pages numbered 1, 2, …, 100 in that order, and repeats the access sequence THRICE. Which one of the following page replacement policies experiences the same number of page faults as the optimal page replacement policy for this program?
a)
Least-recently-used
b)
First-in-first-out
c)
Last-in-first-out
d)
Most-recently-used
|
|
Ravi Singh answered |
The optimal page replacement algorithm swaps out the page whose next use will occur farthest in the future. In the given question, the computer has 20 page frames and initially page frames are filled with pages numbered from 101 to 120. Then program accesses the pages numbered 1, 2, …, 100 in that order, and repeats the access sequence THRICE. The first 20 accesses to pages from 1 to 20 would definitely cause page fault. When 21st is accessed, there is another page fault. The page swapped out would be 20 because 20 is going to be accessed farthest in future. When 22nd is accessed, 21st is going to go out as it is going to be the farthest in future. The above optimal page replacement algorithm actually works as most recently used in this case. Iteration 1: (1-100) Not present - all replaced 1-20 in 20 frames, 21-100 in 20th frame. hence, page faults = 100 Iteration 2: (1-19) present | (20-99) NOT present | (100) present - the replacements are done at the 19th frame hence, page faults = 100 - 19 - 1 = 80 Iteration 3: (1-18) present | (19-98) NOT present | (99-100) present - the replacements are done at the 18th frame hence page faults = 100 - 18 - 2 = 80 Iteration 4: (1-17) present | (17-97) NOT present | (98-100) present - the replacements are done at the 17th frame hence page faults = 100 - 17 - 3 = 80 Total page faults = 100 + 80 + 80 +80 = 340 Along with generating same number of page faults M.R.U also generates replacements at the same positions as in the Optimal algorithm.(Assuming the given 101-120 pages are INVALID (not belonging to the same process) or Empty). While the LIFO replacement does not behave like Optimal replacement algorithm as it generates 343 page faults. Because from 21st page all pages are placed in 20th frame, therefore hits per iteration reduces down to 19 from the 2nd iteration of pages. Whereby Total Page faults = 100 + 81 + 81 + 81 = 343
The power of 2 allocators is faster than the Buddy System allocators.- a)True
- b)False
- c)Can not be determined
- d)None of the above
Correct answer is option 'A'. Can you explain this answer?
The power of 2 allocators is faster than the Buddy System allocators.
a)
True
b)
False
c)
Can not be determined
d)
None of the above
|
|
Sarthak Chakraborty answered |
Power of 2 Allocators vs. Buddy System Allocators
There are several factors to consider when comparing the performance of Power of 2 allocators and Buddy System allocators.
Memory Fragmentation
- Power of 2 allocators generally have lower memory fragmentation compared to Buddy System allocators. This is because Power of 2 allocators allocate memory in chunks that are powers of 2, which can lead to more efficient memory utilization.
Allocation Overhead
- Power of 2 allocators have lower allocation overhead compared to Buddy System allocators. This is because Power of 2 allocators use a simpler allocation strategy, which can result in faster allocation times.
Deallocation Efficiency
- Buddy System allocators may have better deallocation efficiency compared to Power of 2 allocators. This is because Buddy System allocators can merge adjacent free blocks to create larger contiguous blocks, which can reduce fragmentation over time.
Overall Performance
- In general, the Power of 2 allocators are faster than Buddy System allocators due to their lower memory fragmentation and allocation overhead. However, the performance difference may vary depending on the specific use case and workload.
Therefore, it can be concluded that the Power of 2 allocators are indeed faster than the Buddy System allocators.
There are several factors to consider when comparing the performance of Power of 2 allocators and Buddy System allocators.
Memory Fragmentation
- Power of 2 allocators generally have lower memory fragmentation compared to Buddy System allocators. This is because Power of 2 allocators allocate memory in chunks that are powers of 2, which can lead to more efficient memory utilization.
Allocation Overhead
- Power of 2 allocators have lower allocation overhead compared to Buddy System allocators. This is because Power of 2 allocators use a simpler allocation strategy, which can result in faster allocation times.
Deallocation Efficiency
- Buddy System allocators may have better deallocation efficiency compared to Power of 2 allocators. This is because Buddy System allocators can merge adjacent free blocks to create larger contiguous blocks, which can reduce fragmentation over time.
Overall Performance
- In general, the Power of 2 allocators are faster than Buddy System allocators due to their lower memory fragmentation and allocation overhead. However, the performance difference may vary depending on the specific use case and workload.
Therefore, it can be concluded that the Power of 2 allocators are indeed faster than the Buddy System allocators.
Match the following flag bits used in the context of virtual memory management on the left side with the different purposes on the right side of the table below.
- a)I-d, II-a, III-b, IV-c
- b)I-b, II-c, III-a, IV-d
- c)I-c, II-d, III-a, IV-b
- d)I-b, II-c, III-d, IV-a
Correct answer is option 'D'. Can you explain this answer?
Match the following flag bits used in the context of virtual memory management on the left side with the different purposes on the right side of the table below.
a)
I-d, II-a, III-b, IV-c
b)
I-b, II-c, III-a, IV-d
c)
I-c, II-d, III-a, IV-b
d)
I-b, II-c, III-d, IV-a
|
|
Sanya Agarwal answered |
Dirty:- Dirty bit is used for whenever a page has been modify and we try to replace it and then this has to be written back so it write-back or leave it. Therefore dirty bit is used for write-back policy.
R/W:- R/W is used for page protection. Reference:- It says which page has not referred recently. Hence it is used for page replacement policy.
Valid:- It says wether the page page you are looking for it present in MM or not. If not present in MM then load into the SM i.e. called page intiallisation. Option (d) is correct.
Buddy system and power of 2 allocators leads to ___________- a)External fragmentation
- b)Internal Fragmentation
- c)No fragmentation
- d)None of the above
Correct answer is option 'B'. Can you explain this answer?
Buddy system and power of 2 allocators leads to ___________
a)
External fragmentation
b)
Internal Fragmentation
c)
No fragmentation
d)
None of the above
|
|
Sudhir Patel answered |
It performs allocation of memory in blocks of a few standard sizes.this features leads to internal fragmentation because some memory in each allocated memory block may be wasted.
A computer uses 46-bit virtual address, 32-bit physical address, and a three-level paged page table organization. The page table base register stores the base address of the first-level table (T1), which occupies exactly one page. Each entry of T1 stores the base address of a page of the second-level table (T2). Each entry of T2 stores the base address of a page of the third-level table (T3). Each entry of T3 stores a page table entry (PTE). The PTE is 32 bits in size. The processor used in the computer has a 1 MB 16-way set associative virtually indexed physically tagged cache. The cache block size is 64 bytes.
What is the minimum number of page colours needed to guarantee that no two synonyms map to different sets in the processor cache of this computer?
- a)2
- b)4
- c)8
- d)16
Correct answer is option 'C'. Can you explain this answer?
A computer uses 46-bit virtual address, 32-bit physical address, and a three-level paged page table organization. The page table base register stores the base address of the first-level table (T1), which occupies exactly one page. Each entry of T1 stores the base address of a page of the second-level table (T2). Each entry of T2 stores the base address of a page of the third-level table (T3). Each entry of T3 stores a page table entry (PTE). The PTE is 32 bits in size. The processor used in the computer has a 1 MB 16-way set associative virtually indexed physically tagged cache. The cache block size is 64 bytes.
What is the minimum number of page colours needed to guarantee that no two synonyms map to different sets in the processor cache of this computer?
What is the minimum number of page colours needed to guarantee that no two synonyms map to different sets in the processor cache of this computer?
a)
2
b)
4
c)
8
d)
16
|
|
Pankaj Patel answered |
To understand the minimum number of page colours required to guarantee that no two synonyms map to different sets in the processor cache, let's break down the problem step by step:
1. Cache Size and Block Size:
The cache size is given as 1 MB (1 megabyte), and the block size is given as 64 bytes.
2. Number of Cache Sets:
Since the cache is 16-way set associative, we can calculate the number of cache sets using the formula:
Number of Cache Sets = (Cache Size) / (Associativity * Block Size)
Substituting the given values, we get:
Number of Cache Sets = (1 MB) / (16 * 64 bytes)
= (2^20 bytes) / (16 * 2^6 bytes)
= 2^(20-6-4) sets = 2^10 sets = 1024 sets
3. Number of Bits for Cache Index:
The number of bits required to represent the cache index is given by:
Number of Bits for Cache Index = log2(Number of Cache Sets)
= log2(1024) = 10 bits
4. Virtual Address Space:
The computer uses a 46-bit virtual address. This means the virtual address space is 2^46.
5. Number of Bits for Virtual Page Number:
To determine the number of bits used for the virtual page number, we need to subtract the number of bits used for the page offset from the total number of bits in the virtual address. The page offset is determined by the block size, which is 64 bytes or 2^6.
Number of Bits for Virtual Page Number = Total Bits - Bits for Page Offset
= 46 bits - 6 bits
= 40 bits
6. Number of Levels in Page Table:
The page table organization is three-level paged, which means we have three levels of page tables: T1, T2, and T3.
7. Number of Bits for Page Table Entry:
The size of each page table entry (PTE) is given as 32 bits.
8. Number of Entries in Each Level:
Since the base address of T1 occupies exactly one page, and each entry of T1 stores the base address of a page of T2, and each entry of T2 stores the base address of a page of T3, we can calculate the number of entries in each level using the formula:
Number of Entries = (Size of Page) / (Size of PTE)
= (2^12 bytes) / (2^5 bytes)
= 2^7 entries = 128 entries
9. Number of Bits for Each Level:
To determine the number of bits required to represent each level of the page table, we need to calculate the number of bits required to represent the number of entries in each level.
Number of Bits for Each Level = log2(Number of Entries)
= log2(128) = 7 bits
10. Number of Bits for Page Table Offset:
To determine the number of bits required for the page table offset, we need to subtract the number of bits used for the page table entry from the total number of bits in the virtual address. The page table entry is 32 bits or 2^5.
Number of Bits for Page Table Offset = Total Bits - Bits for PTE
= 46 bits - 5 bits
= 41
1. Cache Size and Block Size:
The cache size is given as 1 MB (1 megabyte), and the block size is given as 64 bytes.
2. Number of Cache Sets:
Since the cache is 16-way set associative, we can calculate the number of cache sets using the formula:
Number of Cache Sets = (Cache Size) / (Associativity * Block Size)
Substituting the given values, we get:
Number of Cache Sets = (1 MB) / (16 * 64 bytes)
= (2^20 bytes) / (16 * 2^6 bytes)
= 2^(20-6-4) sets = 2^10 sets = 1024 sets
3. Number of Bits for Cache Index:
The number of bits required to represent the cache index is given by:
Number of Bits for Cache Index = log2(Number of Cache Sets)
= log2(1024) = 10 bits
4. Virtual Address Space:
The computer uses a 46-bit virtual address. This means the virtual address space is 2^46.
5. Number of Bits for Virtual Page Number:
To determine the number of bits used for the virtual page number, we need to subtract the number of bits used for the page offset from the total number of bits in the virtual address. The page offset is determined by the block size, which is 64 bytes or 2^6.
Number of Bits for Virtual Page Number = Total Bits - Bits for Page Offset
= 46 bits - 6 bits
= 40 bits
6. Number of Levels in Page Table:
The page table organization is three-level paged, which means we have three levels of page tables: T1, T2, and T3.
7. Number of Bits for Page Table Entry:
The size of each page table entry (PTE) is given as 32 bits.
8. Number of Entries in Each Level:
Since the base address of T1 occupies exactly one page, and each entry of T1 stores the base address of a page of T2, and each entry of T2 stores the base address of a page of T3, we can calculate the number of entries in each level using the formula:
Number of Entries = (Size of Page) / (Size of PTE)
= (2^12 bytes) / (2^5 bytes)
= 2^7 entries = 128 entries
9. Number of Bits for Each Level:
To determine the number of bits required to represent each level of the page table, we need to calculate the number of bits required to represent the number of entries in each level.
Number of Bits for Each Level = log2(Number of Entries)
= log2(128) = 7 bits
10. Number of Bits for Page Table Offset:
To determine the number of bits required for the page table offset, we need to subtract the number of bits used for the page table entry from the total number of bits in the virtual address. The page table entry is 32 bits or 2^5.
Number of Bits for Page Table Offset = Total Bits - Bits for PTE
= 46 bits - 5 bits
= 41
Increasing the RAM of a computer typically improves performance because:- a)Virtual memory increases
- b)Larger RAMs are faster
- c)Fewer page faults occur
- d)Fewer segmentation faults occur
Correct answer is option 'C'. Can you explain this answer?
Increasing the RAM of a computer typically improves performance because:
a)
Virtual memory increases
b)
Larger RAMs are faster
c)
Fewer page faults occur
d)
Fewer segmentation faults occur
|
|
Sanya Agarwal answered |
When there is more RAM, there would be more mapped virtual pages in physical memory, hence fewer page faults. A page fault causes performance degradation as the page has to be loaded from secondary device.
Consider the following statements:
S1: A small page size causes large page tables.
S2: Internal fragmentation is increased with small pages.
S3: I/O transfers are more efficient with large pages.
Which of the following is true?- a)S1 and S2 are true
- b)S1 is true and S2 is false
- c)S2 and S3 are true
- d)S1 is true S3 is false
Correct answer is option 'B'. Can you explain this answer?
Consider the following statements:
S1: A small page size causes large page tables.
S2: Internal fragmentation is increased with small pages.
S3: I/O transfers are more efficient with large pages.
Which of the following is true?
S1: A small page size causes large page tables.
S2: Internal fragmentation is increased with small pages.
S3: I/O transfers are more efficient with large pages.
Which of the following is true?
a)
S1 and S2 are true
b)
S1 is true and S2 is false
c)
S2 and S3 are true
d)
S1 is true S3 is false
|
|
Anita Menon answered |
Concept:
Paging is a memory management scheme. Paging reduces the external fragmentation. Size of the page table depends upon the number of entries in the table and bytes stored in one entry.
Paging is a memory management scheme. Paging reduces the external fragmentation. Size of the page table depends upon the number of entries in the table and bytes stored in one entry.
S1: A small page size causes large page tables.
This statement is correct. Smaller page size means more pages required per process. It means large page tables are needed.
This statement is correct. Smaller page size means more pages required per process. It means large page tables are needed.
S2: internal fragmentation is increased with small pages.
Internal fragmentation means when process size is smaller than the available space. When pages are small, then available space becomes less and there will be less chances of internal fragmentation.
Internal fragmentation means when process size is smaller than the available space. When pages are small, then available space becomes less and there will be less chances of internal fragmentation.
S3: I/O transfers are more efficient with large pages.
An I/O system is required to take an application I/O request and send it to the physical device. Transferring of I/O requests are more efficient with large pages. So, given statement is correct.
An I/O system is required to take an application I/O request and send it to the physical device. Transferring of I/O requests are more efficient with large pages. So, given statement is correct.
A CPU generates 32-bit virtual addresses. The page size is 4 KB. The processor has a translation look-aside buffer (TLB) which can hold a total of 128 page table entries and is 4-way set associative. The minimum size of the TLB tag is:- a)11 bits
- b)13 bits
- c)15 bits
- d)20 bits
Correct answer is option 'C'. Can you explain this answer?
A CPU generates 32-bit virtual addresses. The page size is 4 KB. The processor has a translation look-aside buffer (TLB) which can hold a total of 128 page table entries and is 4-way set associative. The minimum size of the TLB tag is:
a)
11 bits
b)
13 bits
c)
15 bits
d)
20 bits
|
|
Ravi Singh answered |
Size of a page = 4KB = 2^12 Total number of bits needed to address a page frame = 32 – 12 = 20 If there are ‘n’ cache lines in a set, the cache placement is called n-way set associative. Since TLB is 4 way set associative and can hold total 128 (2^7) page table entries, number of sets in cache = 2^7/4 = 2^5. So 5 bits are needed to address a set, and 15 (20 – 5) bits are needed for tag.
A CPU generates 32-bit virtual addresses. The page size is 4 KB. The processor has a translation look-aside buffer (TLB) which can hold a total of 128 page table entries and is 4-way set associative. The minimum size of the TLB tag is:- a)11 bits
- b)13 bits
- c)15 bits
- d)20 bits
Correct answer is option 'C'. Can you explain this answer?
A CPU generates 32-bit virtual addresses. The page size is 4 KB. The processor has a translation look-aside buffer (TLB) which can hold a total of 128 page table entries and is 4-way set associative. The minimum size of the TLB tag is:
a)
11 bits
b)
13 bits
c)
15 bits
d)
20 bits
|
|
Ravi Singh answered |
Virtual Memory would not be very effective if every memory address had to be translated by looking up the associated physical page in memory. The solution is to cache the recent translations in a Translation Lookaside Buffer (TLB). A TLB has a fixed number of slots that contain page table entries, which map virtual addresses to physical addresses.
Solution : Size of a page = 4KB = 2^12 means 12 offset bits CPU generates 32-bit virtual addresses Total number of bits needed to address a page frame = 32 – 12 = 20 If there are ‘n’ cache lines in a set, the cache placement is called n-way set associative. Since TLB is 4 way set associative and can hold total 128 (2^7) page table entries, number of sets in cache = 2^7/4 = 2^5. So 5 bits are needed to address a set, and 15 (20 – 5) bits are needed for tag. Option (C) is the correct answer.
In ________ memory binding are changed in such manner that all free memory area can be merged to form a single free memory area.- a)Memory Paging
- b)Memory Swapping
- c)Memory Compaction
- d)Memory segmentation
Correct answer is option 'C'. Can you explain this answer?
In ________ memory binding are changed in such manner that all free memory area can be merged to form a single free memory area.
a)
Memory Paging
b)
Memory Swapping
c)
Memory Compaction
d)
Memory segmentation
|
|
Anisha Chavan answered |
Memory Compaction
Memory compaction is a technique used in memory management to optimize the utilization of memory resources. It involves rearranging the memory by merging all free memory areas into a single contiguous block.
Why Memory Compaction is Needed?
In computer systems, memory is allocated and deallocated dynamically as programs run. Over time, memory becomes fragmented, resulting in small free memory areas scattered throughout the memory space. This fragmentation can lead to inefficient memory utilization and can limit the system's ability to allocate large blocks of memory.
The Process of Memory Compaction
Memory compaction involves the following steps:
1. Identification of Free Memory Areas: The memory management system identifies all the free memory areas available in the system.
2. Merging Free Memory Areas: The free memory areas are merged together to form a single contiguous block of free memory. This is done by adjusting the memory allocation data structures and updating the memory allocation tables.
3. Relocation of Allocated Memory: Once the free memory areas are merged, the allocated memory blocks need to be relocated to fit within the new memory layout. This involves updating the memory references and pointers in the running programs.
4. Updating Memory Pointers: The memory pointers and references within the running programs are updated to reflect the new memory layout. This ensures that the programs continue to access the correct memory locations.
5. Releasing Unused Memory: After the memory compaction process is complete, any unused memory areas are released back to the operating system for other programs to use.
Benefits of Memory Compaction
- Improved Memory Utilization: Memory compaction optimizes the use of memory resources by merging free memory areas into a single contiguous block. This allows larger memory blocks to be allocated, improving overall memory utilization.
- Reduced Fragmentation: Memory compaction reduces memory fragmentation by consolidating free memory areas. This helps to minimize the occurrence of fragmented memory blocks and ensures efficient memory allocation.
- Enhanced Performance: By optimizing memory utilization and reducing fragmentation, memory compaction can improve the overall performance of the system. It allows programs to allocate memory more efficiently and reduces the need for frequent memory allocation and deallocation operations.
In conclusion, memory compaction is a technique used to merge free memory areas into a single contiguous block, improving memory utilization and reducing fragmentation. It plays a crucial role in optimizing memory management in computer systems.
Memory compaction is a technique used in memory management to optimize the utilization of memory resources. It involves rearranging the memory by merging all free memory areas into a single contiguous block.
Why Memory Compaction is Needed?
In computer systems, memory is allocated and deallocated dynamically as programs run. Over time, memory becomes fragmented, resulting in small free memory areas scattered throughout the memory space. This fragmentation can lead to inefficient memory utilization and can limit the system's ability to allocate large blocks of memory.
The Process of Memory Compaction
Memory compaction involves the following steps:
1. Identification of Free Memory Areas: The memory management system identifies all the free memory areas available in the system.
2. Merging Free Memory Areas: The free memory areas are merged together to form a single contiguous block of free memory. This is done by adjusting the memory allocation data structures and updating the memory allocation tables.
3. Relocation of Allocated Memory: Once the free memory areas are merged, the allocated memory blocks need to be relocated to fit within the new memory layout. This involves updating the memory references and pointers in the running programs.
4. Updating Memory Pointers: The memory pointers and references within the running programs are updated to reflect the new memory layout. This ensures that the programs continue to access the correct memory locations.
5. Releasing Unused Memory: After the memory compaction process is complete, any unused memory areas are released back to the operating system for other programs to use.
Benefits of Memory Compaction
- Improved Memory Utilization: Memory compaction optimizes the use of memory resources by merging free memory areas into a single contiguous block. This allows larger memory blocks to be allocated, improving overall memory utilization.
- Reduced Fragmentation: Memory compaction reduces memory fragmentation by consolidating free memory areas. This helps to minimize the occurrence of fragmented memory blocks and ensures efficient memory allocation.
- Enhanced Performance: By optimizing memory utilization and reducing fragmentation, memory compaction can improve the overall performance of the system. It allows programs to allocate memory more efficiently and reduces the need for frequent memory allocation and deallocation operations.
In conclusion, memory compaction is a technique used to merge free memory areas into a single contiguous block, improving memory utilization and reducing fragmentation. It plays a crucial role in optimizing memory management in computer systems.
Which of the following technique is not implemented for free space management- a)Bitmap or Bit vector
- b)Counting
- c)Paging
- d)Grouping
Correct answer is option 'C'. Can you explain this answer?
Which of the following technique is not implemented for free space management
a)
Bitmap or Bit vector
b)
Counting
c)
Paging
d)
Grouping
|
|
Nishanth Iyer answered |
Free Space Management Techniques
Bitmap or Bit vector:
- In this technique, each block of free space is represented by a bit in a bitmap.
- If the bit is 1, it means the block is free; if it is 0, the block is allocated.
- This method is efficient for quickly finding free blocks but can be memory-intensive for large storage systems.
Counting:
- This technique involves keeping track of the number of free blocks in a specific range.
- It requires maintaining a count of free blocks, which may be updated whenever a block is allocated or deallocated.
- Counting can provide a quick way to determine available space but may not be as efficient as other methods for large storage systems.
Paging:
- Paging is not typically used for free space management but rather for memory management in virtual memory systems.
- It involves dividing memory into fixed-size blocks called pages and managing these pages for efficient memory allocation.
- While paging can help optimize memory usage, it is not directly related to free space management in storage systems.
Grouping:
- Grouping is a technique where free blocks are organized into groups or clusters based on their physical location.
- This method can help optimize disk access and improve performance by grouping related blocks together.
- Grouping is not as commonly used as bitmap or counting for free space management but can be beneficial in certain storage systems.
Bitmap or Bit vector:
- In this technique, each block of free space is represented by a bit in a bitmap.
- If the bit is 1, it means the block is free; if it is 0, the block is allocated.
- This method is efficient for quickly finding free blocks but can be memory-intensive for large storage systems.
Counting:
- This technique involves keeping track of the number of free blocks in a specific range.
- It requires maintaining a count of free blocks, which may be updated whenever a block is allocated or deallocated.
- Counting can provide a quick way to determine available space but may not be as efficient as other methods for large storage systems.
Paging:
- Paging is not typically used for free space management but rather for memory management in virtual memory systems.
- It involves dividing memory into fixed-size blocks called pages and managing these pages for efficient memory allocation.
- While paging can help optimize memory usage, it is not directly related to free space management in storage systems.
Grouping:
- Grouping is a technique where free blocks are organized into groups or clusters based on their physical location.
- This method can help optimize disk access and improve performance by grouping related blocks together.
- Grouping is not as commonly used as bitmap or counting for free space management but can be beneficial in certain storage systems.
Chapter doubts & questions for Memory Management - Operating System 2025 is part of Computer Science Engineering (CSE) exam preparation. The chapters have been prepared according to the Computer Science Engineering (CSE) exam syllabus. The Chapter doubts & questions, notes, tests & MCQs are made for Computer Science Engineering (CSE) 2025 Exam. Find important definitions, questions, notes, meanings, examples, exercises, MCQs and online tests here.
Chapter doubts & questions of Memory Management - Operating System in English & Hindi are available as part of Computer Science Engineering (CSE) exam.
Download more important topics, notes, lectures and mock test series for Computer Science Engineering (CSE) Exam by signing up for free.
Operating System
10 videos|141 docs|33 tests
|
|
© EduRev
|
Education Revolution
|



|









Signup to see your scores
go up within 7 days!
Access 1000+ FREE Docs, Videos and Tests
Takes less than 10 seconds to signup